Redis数据类型实战
list有序列表
Redis的列表List中添加数据时,具有“先进先出”的特性,即所谓的“FIFO”(有点队列Queue的特性!),而且数据是紧凑、一个挨着一个存储的!
当我们在往缓存Redis的列表List添加数据时,可以采用“LPush 即从左边的方向添加”的方式往缓存Redis的List中添加,然后再采用“LPop 即从左边的方向弹出数据”或者“RPop 即从右边的方向弹出数据”的方式获取这一有序存储的列表数据!
上下架商品
电商平台~商家添加/下架商品时如何将其商品列表有序存储至缓存Redis的List中,每次获取商家当前的商品列表时可以直接从缓存中读取,减少每个商家在每次登陆之后都需要走数据库DB频繁查询 所带来的压力!
产品信息表
1
2
3
4
5
6
7
8
9
CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 NOT NULL COMMENT '商品名称',
`user_id` int(11) NOT NULL COMMENT '所属商户id',
`scan_total` int(255) DEFAULT NULL COMMENT '浏览量',
`is_active` tinyint(255) DEFAULT '1' COMMENT '是否有效',
PRIMARY KEY (`id`),
KEY `indx_scan_total` (`scan_total`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商户商品表';
主逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
@Service
public class ListService {
public static final Logger log= LoggerFactory.getLogger(ListService.class);
@Autowired
private ProductMapper productMapper;
@Autowired
private RedisTemplate redisTemplate;
//添加商品
@Transactional(rollbackFor = Exception.class)
public Integer addProduct(Product product) throws Exception{
if (product!=null){
product.setId(null);
//将该商品塞入数据库DB中
productMapper.insertSelective(product);
Integer id=product.getId();
if (id>0){
//将该商品塞入缓存Redis中
this.pushRedisService(product);
}
return id;
}
return -1;
}
//TODO:往缓存中塞信息-可以抽取到ListRedisService
private void pushRedisService(final Product product) throws Exception{
ListOperations<String,Product> listOperations=redisTemplate.opsForList();
listOperations.leftPush(Constant.RedisListPrefix+product.getUserId(),product);
}
//获取历史发布的商品列表
public List<Product> getHistoryProducts(final Integer userId) throws Exception{
List<Product> list= Lists.newLinkedList();
ListOperations<String,Product> listOperations=redisTemplate.opsForList();
final String key=Constant.RedisListPrefix+userId;
//TODO:倒序->userID=10010 ->Rabbitmq入门与实战,Redis入门与实战,SpringBoot项目实战
list=listOperations.range(key,0,listOperations.size(key));
log.info("--倒序:{}",list);
//TODO:顺序->userID=10010 ->SpringBoot项目实战,Redis入门与实战,Rabbitmq入门与实战
//Collections.reverse(list);
//log.info("--顺序:{}",list);
//TODO:弹出来移除的方式
//Product entity=listOperations.rightPop(key);
//while (entity!=null){
//list.add(entity);
//entity=listOperations.rightPop(key);
//}
return list;
}
}
队列广播消息
电商应用~平台管理员在平台发布活动公告信息之后,除了将公告信息塞入数据库DB之外,同时以LPush的方式将其塞入缓存Redis的列表List中,并在接口的另一端开启定时检测的方式,随时检测缓存中指定的列表Redis是否有通告信息过来,如果有,则采取RPop的方式弹出该公告信息,并以邮件的形式发送给商户!

通告信息表
1
2
3
4
5
6
7
CREATE TABLE `notice` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '通告标题',
`content` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '内容',
`is_active` tinyint(4) DEFAULT '1',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8 COMMENT='通告';
主逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Autowired
private NoticeMapper noticeMapper;
//创建通告
@Transactional(rollbackFor = Exception.class)
public void pushNotice(Notice notice) throws Exception{
if (notice!=null){
notice.setId(null);
//TODO:将通告信息塞入数据库DB中
noticeMapper.insertSelective(notice);
final Integer id=notice.getId();
if (id>0){
//TODO:塞入List列表中(队列),准备被拉取异步通知至不同的商户的邮箱 - applicationEvent&Listener;Rabbitmq;jms
ListOperations<String,Notice> listOperations=redisTemplate.opsForList();
listOperations.leftPush(Constant.RedisListNoticeKey,notice);
}
}
}
定时任务调度器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
//Redis列表-队列的消费者监听器
@Component
@EnableScheduling
public class ListListenerScheduler {
private static final Logger log=
LoggerFactory.getLogger(ListListenerScheduler.class);
private static final String listenKey= Constant.RedisListNoticeKey;
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private UserMapper userMapper;
@Autowired
private EmailService emailService;
//TODO:近实时的定时任务检测
//@Scheduled(cron = "0/10 * * * * ?")
@Scheduled(cron = "0/59 * * * * ?")
public void schedulerListenNotice(){
log.info("----定时任务调度队列监听、检测通告消息,监听list中的数据");
ListOperations<String,Notice> listOperations=redisTemplate.opsForList();
Notice notice=listOperations.rightPop(listenKey);
while (notice!=null){
//TODO:发送给到所有的商户的邮箱
this.noticeUser(notice);
notice=listOperations.rightPop(listenKey);
}
}
//TODO:发送通知给到不同的商户
@Async("threadPoolTaskExecutor")
private void noticeUser(Notice notice){
if (notice!=null){
//TODO:查询获取所有商户信息
List<User> list=userMapper.selectList();
//TODO:线程池/多线程触发群发邮件
try {
if (list!=null && !list.isEmpty()){
ExecutorService executorService=Executors.newFixedThreadPool(4);
List<NoticeThread> threads= Lists.newLinkedList();
list.forEach(user -> {
threads.add(new NoticeThread(user,notice,emailService));
});
executorService.invokeAll(threads);
}
}catch (Exception e){
log.error("近实时的定时任务检测-发送通知给到不同的商户-法二-线程池/多线程触发-发生异常:",e.fillInStackTrace());
}
}
}
}
set无序列表
Set “无序”、“唯一”,即集合Set中存储的元素是没有顺序且不重复的!
其底层设计亦具有“异曲同工”之妙,即采用哈希表来实现的,故而其相应的操作如添加、删除、查找的复杂度都是 O(1) 。
用户注册过滤重复提交信息
用户在前端提交信息时重复点击按钮多次,如果此时不采取相应的限制措施,那么很有可能会在数据库表中出现多条相同的数据条目
用户信息表user
1
2
3
4
5
6
7
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '姓名',
`email` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_email` (`email`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';
主逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
//集合set服务处理逻辑
@Service
public class SetService {
private static final Logger log= LoggerFactory.getLogger(SetService.class);
@Autowired
private UserMapper userMapper;
@Autowired
private RedisTemplate redisTemplate;
//TODO:用户注册
@Transactional(rollbackFor = Exception.class)
public Integer registerUser(User user) throws Exception{
if (this.exist(user.getEmail())){
throw new RuntimeException(StatusCode.UserEmailHasExist.getMsg());
}
int res=userMapper.insertSelective(user);
if (res>0){
SetOperations<String,String> setOperations=redisTemplate.opsForSet();
setOperations.add(Constant.RedisSetKey,user.getEmail());
}
return user.getId();
}
//TODO:判断邮箱是否已存在于缓存中
private Boolean exist(final String email) throws Exception{
//TODO:写法二
SetOperations<String,String> setOperations=redisTemplate.opsForSet();
Long size=setOperations.size(Constant.RedisSetKey);
if (size>0 && setOperations.isMember(Constant.RedisSetKey,email)){
return true;
}else{
User user=userMapper.selectByEmail(email);
if (user!=null){
setOperations.add(Constant.RedisSetKey,user.getEmail());
return true;
}else{
return false;
}
}
}
在插入用户信息进入数据库之前,我们需要判断该用户是否存在于缓存集合Set中,如果已经存在,则告知前端该“用户邮箱”已经存在(在这里我们认为用户的邮箱是唯一的,当然啦,你可以调整为“用户名”唯一),如果缓存集合Set中不存在该邮箱,则插入数据库中,并在“插入数据库表成功” 之后,将该用户邮箱塞到缓存集合Set中去即可。
在“判断缓存Set中是否已经存在该邮箱”的逻辑中,是先判断缓存中是否存在,如果不存在,为了保险,我们会再去数据库查询邮箱是否真的不存在,如果真的是不存在,则将其“第一次”添加进缓存Set中(这样子可以在某种程度避免前端在重复点击提交按钮时,产生瞬时高并发的现象,从而降低并发安全的风险)!
如果在插入数据库时“掉链子”了,即发生异常了导致没有插进去,但是这个时候我们在“判断缓存集合Set中是否存在该邮箱时已经将该邮箱添加进缓存中一次了”,故而该邮箱将永远不能注册了(但是实际上该邮箱并没有真正插入到数据库中哦!)
改造后的主逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
@Transactional(rollbackFor = Exception.class)
public Integer registerUser(User user) throws Exception{
if (this.exist(user.getEmail())){
throw new RuntimeException(StatusCode.UserEmailHasExist.getMsg());
}
int res=0;
try{
res=userMapper.insertSelective(user);
if (res>0){
redisTemplate.opsForSet().add(Constant.RedisSetKey,user.getEmail());
}
}catch (Exception e){
throw e;
}finally {
//TODO:如果res不大于0,即代表插入到数据库发生了异常,
//TODO:这个时候得将缓存Set中该邮箱移除掉
//TODO:因为在判断是否存在时 加入了一次,不移除掉的话,就永远注册不了该邮箱了
if (res<=0){
redisTemplate.opsForSet().remove(Constant.RedisSetKey,user.getEmail());
}
}
return user.getId();
}
试卷题目乱序
当我们向集合Set伸手要一个元素时,其底层会随机地给我们发一个元素!
业务流程
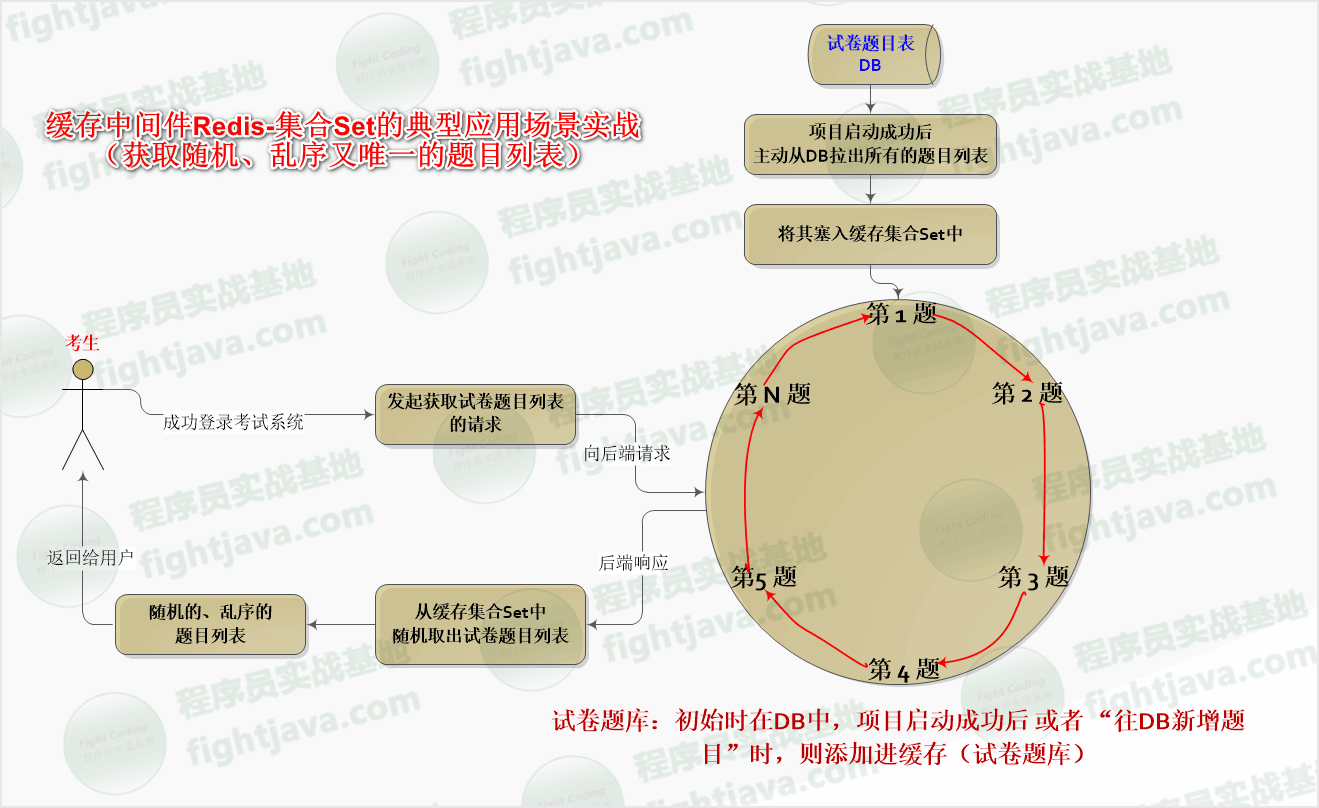
我们将主要做两件事情:
A、项目启动后从数据库DB中拉出所有的试卷题目列表,并将其塞入缓存Set集合中
B、开发一请求方法,用于从缓存中获取随机、无序且唯一的 N 道试题,并将其返回给当前成功登录考试系统的考生
试卷题目表
1
2
3
4
5
6
7
8
9
10
CREATE TABLE `problem` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(150) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '问题标题',
`choice_a` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '选项A',
`choice_b` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '选项B',
`is_active` tinyint(4) DEFAULT '1' COMMENT '是否有效(1=是;0=否)',
`order_by` tinyint(4) DEFAULT '0' COMMENT '排序',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_title` (`title`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='试卷题目表';
试卷题目服务逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
@Service
public class ProblemService {
private static final Logger log= LoggerFactory.getLogger(ProblemService.class);
@Autowired
private ProblemMapper problemMapper;
@Autowired
private RedisTemplate redisTemplate;
//TODO:项目启动拉取出数据库中的题库,并塞入缓存Set集合中
@PostConstruct
public void init(){
initDBToCache();
}
//TODO:拉取出数据库中的所有题目列表,并塞入缓存Set集合中
private void initDBToCache(){
try {
//redisTemplate.delete(Arrays.asList(Constant.RedisSetProblemKey,Constant.RedisSetProblemsKey));
SetOperations<String,Problem> setOperations=redisTemplate.opsForSet();
Set<Problem> set=problemMapper.getAll();
if (set!=null && !set.isEmpty()){
set.forEach(problem -> setOperations.add(Constant.RedisSetProblemKey,problem));
set.forEach(problem -> setOperations.add(Constant.RedisSetProblemsKey,problem));
}
}catch (Exception e){
log.error("项目启动拉取出数据库中的题库,并塞入缓存Set集合中-发生异常:",e.fillInStackTrace());
}
}
//TODO:从缓存中获取随机的、乱序的试题列表
public Set<Problem> getRandomEntitys(Integer total){
Set<Problem> problems=Sets.newHashSet();
try {
SetOperations<String,Problem> setOperations=redisTemplate.opsForSet();
problems=setOperations.distinctRandomMembers(Constant.RedisSetProblemsKey,total);
}catch (Exception e){
log.error("从缓存中获取随机的、乱序的试题列表-发生异常:",e.fillInStackTrace());
}
return problems;
}
}
SortedSet有序集合
有序集合SortedSet,这种数据结构延伸了集合Set的“元素唯一/不重复”的特性,但却有一点不同于集合Set,那就是SortedSet的成员元素具有“有序性”,而其“有序性”的实现是通过“添加成员时附带一个double类型的参数:分数”
游戏充值排行榜
用户充值模块流程
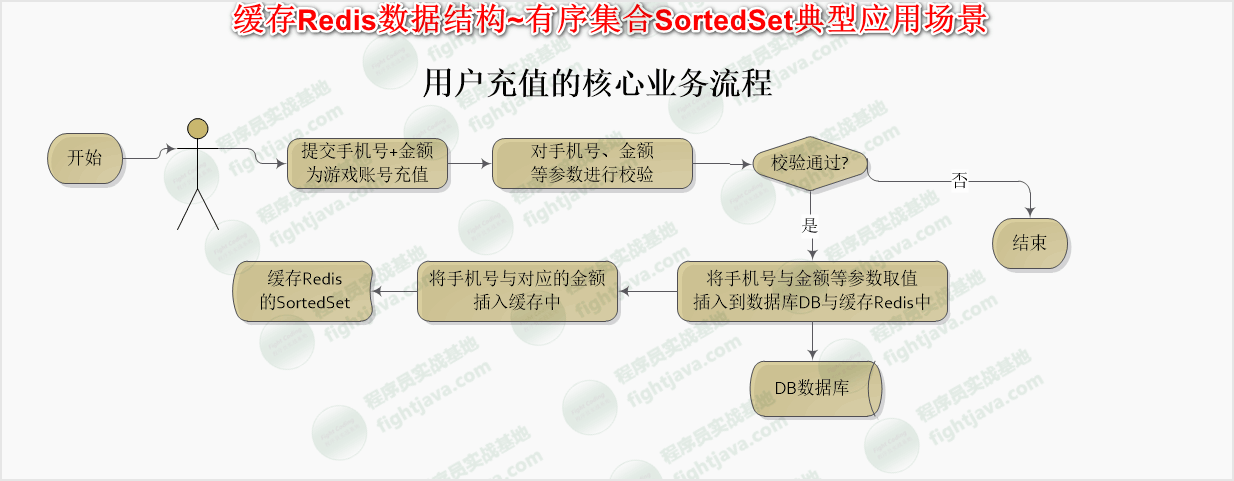
用户充值表
1
2
3
4
5
6
7
8
CREATE TABLE `phone_fare` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`phone` varchar(50) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '手机号码',
`fare` decimal(10,2) DEFAULT NULL COMMENT '充值金额',
`is_active` tinyint(4) DEFAULT '1' COMMENT '是否有效(1=是;0=否)',
PRIMARY KEY (`id`),
KEY `idx_phone` (`phone`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='手机充值记录';
业务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
//TODO:新增/手机话费充值 记录 v2
@Transactional(rollbackFor = Exception.class)
public Integer addRecordV2(PhoneFare fare) throws Exception{
log.info("----sorted set话费充值记录新增V2:{} ",fare);
// 先入库,入库成功塞缓存
int res=fareMapper.insertSelective(fare);
if (res>0){
FareDto dto=new FareDto(fare.getPhone());
ZSetOperations<String,FareDto> zSetOperations=redisTemplate.opsForZSet();
Double oldFare=zSetOperations.score(Constant.RedisSortedSetKey2,dto);
if (oldFare!=null){
//TODO:表示之前该手机号对应的用户充过值了,需要进行叠加
zSetOperations.incrementScore(Constant.RedisSortedSetKey2,dto,fare.getFare().doubleValue());
}else{
//TODO:表示第一次充值
zSetOperations.add(Constant.RedisSortedSetKey2,dto,fare.getFare().doubleValue());
}
}
return fare.getId();
}
获取充值排行榜
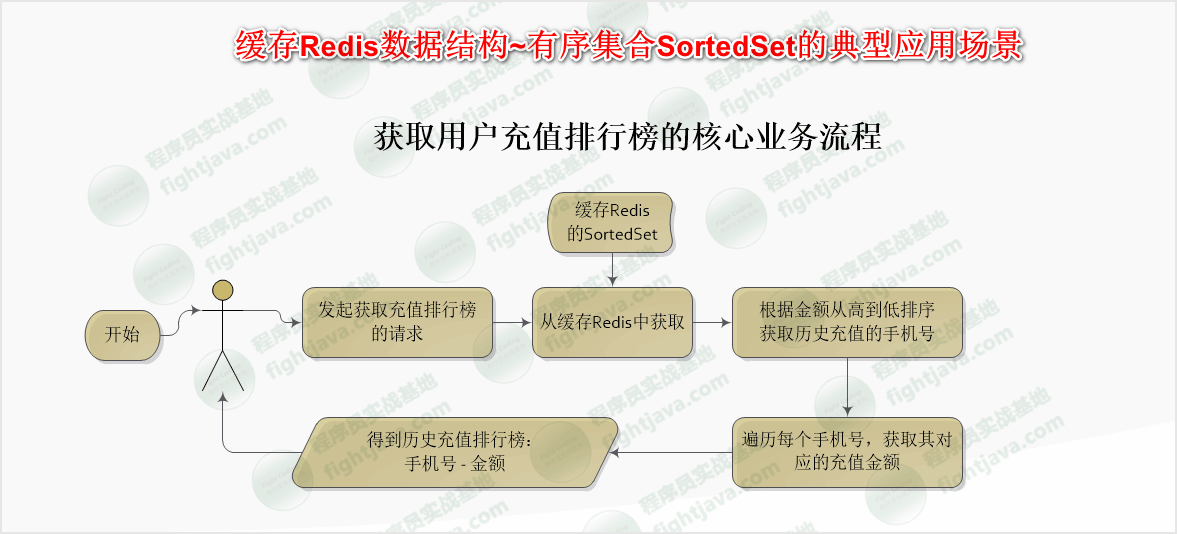
业务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
//TODO:获取充值排行榜V2
public List<PhoneFare> getSortFaresV2(){
List<PhoneFare> list= Lists.newLinkedList();
final String key=Constant.RedisSortedSetKey2;
ZSetOperations<String,FareDto> zSetOperations=redisTemplate.opsForZSet();
final Long size=zSetOperations.size(key);
Set<ZSetOperations.TypedTuple<FareDto>> set=zSetOperations.reverseRangeWithScores(key,0L,size);
if (set!=null && !set.isEmpty()){
set.forEach(tuple -> {
PhoneFare fare=new PhoneFare();
// 金额
fare.setFare(BigDecimal.valueOf(tuple.getScore()));
//手机号
fare.setPhone(tuple.getValue().getPhone());
list.add(fare);
});
}
return list;
}
虽然我们基本上已经实现了该业务场景几乎所有的功能模块,但是我们却忽略了其他两种情况:
A.如果“充值排行榜”这一功能模块是增量式的需求,那么上线时如何去处理历史的用户充值记录呢?你总不能说我们的“充值排行榜”对于以往充值的用户记录不生效吧?
B.如果用户充值后插入数据库DB成功、但是插入缓存Cache失败(DB事务不回滚的前提),那毫无疑问,最终得出来的“充值排行榜”一定是不准确的(因为我们是直接从缓存Redis中获取的)!
能保证“最终一致性”的充值排行榜的解决方案,那就是万能的定时任务调度!
它要完成的任务就是开启一个定时时钟,基于数据库DB中的“用户充值记录表”,借助数据库提供的Order By、Group By等查询得出目前为止所有有效用户的“充值排行榜”
定时任务调度类PhoneFareScheduler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
//补偿机制:手机号码充值排行榜
@Component
public class PhoneFareScheduler {
private static final Logger log= LoggerFactory.getLogger(PhoneFareScheduler.class);
@Autowired
private PhoneFareMapper phoneFareMapper;
@Autowired
private RedisTemplate redisTemplate;
//时间频度设定为30min,当然啦,具体的设定要根据实际情况而定
@Scheduled(cron = "0 0/30 * * * ?")
public void sortFareScheduler(){
log.info("--补偿性手机号码充值排行榜-定时任务");
this.cacheSortResult();
}
@Async("threadPoolTaskExecutor")
private void cacheSortResult(){
try {
ZSetOperations<String,FareDto> zSetOperations=redisTemplate.opsForZSet();
List<PhoneFare> list=phoneFareMapper.getAllSortFares();
if (list!=null && !list.isEmpty()){
redisTemplate.delete(Constant.RedisSortedSetKey2);
list.forEach(fare -> {
FareDto dto=new FareDto(fare.getPhone());
zSetOperations.add(Constant.RedisSortedSetKey2,dto,fare.getFare().doubleValue());
});
}
}catch (Exception e){
log.error("--补偿性手机号码充值排行榜-定时任务-发生异常:",e.fillInStackTrace());
}
}
}
其中,phoneFareMapper.getAllSortFares() 的作用就是前往数据库Mysql,通过Group By、Order By和SUM等查询得到排行榜,其完整的动态SQL如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
<!--基于数据库的补偿排名机制-->
<select id="getAllSortFares" resultType="com.boot.debug.redis.model.entity.PhoneFare">
SELECT
phone,
SUM(fare) AS fare
FROM
phone_fare
GROUP BY
phone
ORDER BY
fare DESC
</select>
除此之外,@Async(“threadPoolTaskExecutor”) 的作用便是采用“线程池-多线程的方式异步执行定时任务”,故而我们需要作一个全局的Config,用于配置线程池-多线程的相关信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//线程池-多线程配置
public class ThreadConfig {
@Bean("threadPoolTaskExecutor")
public Executor threadPoolTaskExecutor(){
ThreadPoolTaskExecutor executor=new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(8);
executor.setKeepAliveSeconds(10);
executor.setQueueCapacity(8);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
}
hash表
哈希Hash跟其他的数据结构还是有诸多不同之处的。其他的据结构几乎都是:Key-Value的存储,而Hash则是:Key – [Field-Value] 的存储,也就是说其他数据结构的Value一般是确切的值,而Hash的Value是一系列的键值对,通常我们是这样子称呼Hash的存储的:大Key为实际的Key,小Key为Field,而具体的取值为Field对应的值
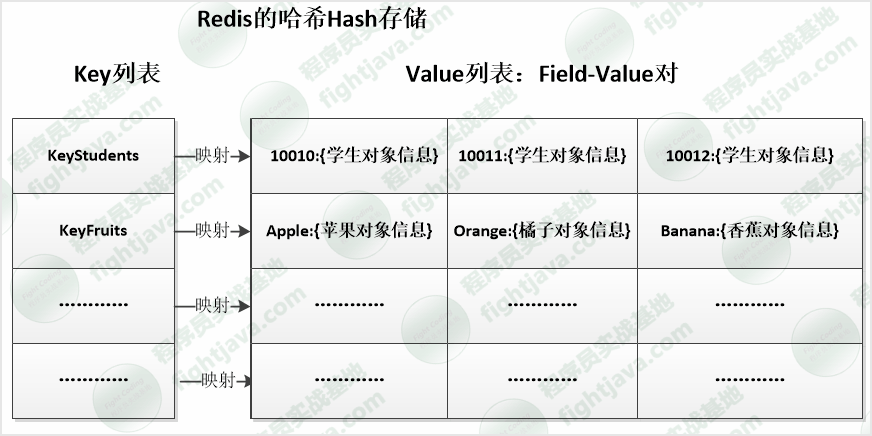
它的作用还是很强大的,特别是在存储“同种对象类型”的数据列表时哈希Hash更能体现其优势,除此之外,其最大的、直观上的作用便是“减少了缓存Key的数量”
数据字典模块实时触发存储
经常可以见到的数据字典:“性别Sex~其取值可以有:男=1;女=0;未知=2”;比如“支付状态PayStatus~其取值可以有:1=未支付;2=已支付;3=已取消支付;4=已退款…”;再比如“订单审核状态ReviewStatus~1=已保存/未审核;2=已审核;3=审核成功;4=审核失败…”等等可以将其配置在“数据字典功能模块”中将其维护起来
数据库表sys_config
1
2
3
4
5
6
7
8
9
10
11
12
CREATE TABLE `sys_config` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`type` varchar(100) CHARACTER SET utf8mb4 NOT NULL COMMENT '字典类型',
`name` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '字典名称',
`code` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '选项编码',
`value` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '选项取值',
`order_by` int(11) DEFAULT '1' COMMENT '排序',
`is_active` tinyint(4) DEFAULT '1' COMMENT '是否有效(1=是;0=否)',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_type_code` (`type`,`code`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='字典配置表';
业务逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
//hash数据类型-service
@Service
public class HashService {
private static final Logger log= LoggerFactory.getLogger(HashService.class);
@Autowired
private SysConfigMapper sysConfigMapper;
@Autowired
private HashRedisService hashRedisService;
//TODO:添加数据字典及其对应的选项(field-value)
@Transactional(rollbackFor = Exception.class)
public Integer addSysConfig(SysConfig config) throws Exception{
int res=sysConfigMapper.insertSelective(config);
if (res>0){
//TODO:实时触发数据字典的hash存储
hashRedisService.cacheConfigMap();
}
return config.getId();
}
//TODO:取出缓存中所有的数据字典列表
public Map<String,List<SysConfig>> getAll() throws Exception{
return hashRedisService.getAllCacheConfig();
}
//TODO:取出缓存中特定的数据字典列表
public List<SysConfig> getByType(final String type) throws Exception{
return hashRedisService.getCacheConfigByType(type);
}
}
HashRedisService相应的方法逻辑处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
@Service
public class HashRedisService {
private static final Logger log= LoggerFactory.getLogger(HashRedisService.class);
@Autowired
private SysConfigMapper sysConfigMapper;
@Autowired
private RedisTemplate redisTemplate;
//TODO:实时获取所有有效的数据字典列表-转化为map-存入hash缓存中
@Async
public void cacheConfigMap(){
try {
List<SysConfig> configs=sysConfigMapper.selectActiveConfigs();
if (configs!=null && !configs.isEmpty()){
Map<String,List<SysConfig>> dataMap= Maps.newHashMap();
//TODO:所有的数据字典列表遍历 -> 转化为 hash存储的map
configs.forEach(config -> {
List<SysConfig> list=dataMap.get(config.getType());
if (list==null || list.isEmpty()){
list= Lists.newLinkedList();
}
list.add(config);
dataMap.put(config.getType(),list);
});
//TODO:存储到缓存hash中
HashOperations<String,String,List<SysConfig>> hashOperations=redisTemplate.opsForHash();
hashOperations.putAll(Constant.RedisHashKeyConfig,dataMap);
}
}catch (Exception e){
log.error("实时获取所有有效的数据字典列表-转化为map-存入hash缓存中-发生异常:",e.fillInStackTrace());
}
}
//TODO:从缓存hash中获取所有的数据字典配置map
public Map<String,List<SysConfig>> getAllCacheConfig(){
Map<String,List<SysConfig>> map=Maps.newHashMap();
try {
HashOperations<String,String,List<SysConfig>> hashOperations=redisTemplate.opsForHash();
map=hashOperations.entries(Constant.RedisHashKeyConfig);
}catch (Exception e){
log.error("从缓存hash中获取所有的数据字典配置map-发生异常:",e.fillInStackTrace());
}
return map;
}
//TODO:从缓存hash中获取特定的数据字典列表
public List<SysConfig> getCacheConfigByType(final String type){
List<SysConfig> list=Lists.newLinkedList();
try {
HashOperations<String,String,List<SysConfig>> hashOperations=redisTemplate.opsForHash();
list=hashOperations.get(Constant.RedisHashKeyConfig,type);
}catch (Exception e){
log.error("从缓存hash中获取特定的数据字典列表-发生异常:",e.fillInStackTrace());
}
return list;
}
}