八股文-spring
spring
【问题】 谈谈你对Spring的理解?Spring能帮我们做什么?
【参考答案】 Spring是一个开源的轻量级Java企业级应用开发框架,其核心是控制反转(IoC,Inversion of Control)和面向切面编程(AOP,Aspect-Oriented Programming)。Spring通过IoC容器管理对象的生命周期和依赖关系,通过AOP实现横切关注点(如日志、事务)的解耦,从而简化了企业级应用的开发。Spring框架不仅仅是一个IoC容器,它提供了一整套完整的解决方案,涵盖了数据访问、事务管理、Web层开发、消息传递、测试等多个方面,使开发者能够专注于业务逻辑,而无需关心底层基础设施的复杂性。
具体来说,Spring能帮我们做以下事情:
IoC容器管理对象(Bean)
Spring IoC容器负责创建、配置、组装对象(称为Bean),并管理它们的完整生命周期。开发者只需通过配置(XML、注解、Java Config)定义Bean之间的依赖关系,容器会自动完成依赖注入,降低了组件之间的耦合度。面向切面编程(AOP)
Spring AOP允许开发者将横切关注点(如日志记录、性能监控、安全控制、事务管理)从业务代码中分离出来,通过声明式的方式动态织入,提高代码的模块化和可维护性。声明式事务管理
Spring提供了统一的事务抽象层,支持编程式事务和声明式事务(基于AOP)。开发者只需通过注解或XML配置事务属性(如传播行为、隔离级别),即可实现复杂的事务管理,无需手动处理连接、提交、回滚等操作。数据访问集成
Spring对主流的数据访问技术(JDBC、Hibernate、JPA、MyBatis等)提供了无缝集成,简化了数据访问代码的编写。例如,Spring的JdbcTemplate消除了传统的JDBC样板代码,而ORM集成则通过一致的异常体系简化了异常处理。Web层开发(Spring MVC)
Spring MVC是一个基于Servlet API的轻量级Web框架,它实现了MVC设计模式,提供了强大的请求映射、数据绑定、验证、视图解析等功能。开发者可以快速构建灵活的Web应用程序,并与其他视图技术(JSP、Thymeleaf、FreeMarker)无缝集成。与其他框架和技术的集成
Spring能够轻松地与各种企业级技术整合,如JavaMail(邮件发送)、任务调度(Quartz、@Scheduled)、缓存(Ehcache、Redis)、消息中间件(JMS、RabbitMQ)等。Spring的“集成”能力使得它成为企业级应用开发的事实标准。测试支持
Spring提供了一套测试框架,支持单元测试和集成测试。通过@TestContext框架,可以在测试中轻松加载Spring容器,进行依赖注入,并对事务进行回滚控制,方便数据层测试。Spring生态的扩展
基于Spring Framework,后续发展出了Spring Boot(快速配置)、Spring Cloud(微服务)、Spring Security(安全)、Spring Data(数据访问)等一系列子项目,形成了一个庞大的技术生态,能够应对从简单应用到复杂微服务架构的各种需求。
总之,Spring通过其核心的IoC和AOP,提供了一致、透明、高效的编程模型,极大地简化了Java企业级应用的开发、测试和部署。
【大白话解释于举例说明】 可以把Spring想象成一个万能管家,你只需要告诉它你需要什么,它就会帮你准备好,并协调好它们之间的关系。
IoC(控制反转):以前你自己去市场买菜、洗菜、炒菜(自己创建对象、管理依赖),现在你告诉管家你想吃鱼香肉丝(声明依赖),管家会自动把菜做好端到你面前(容器创建对象并注入依赖)。你只需要关注怎么吃(业务逻辑),不用管菜怎么来的。
AOP(面向切面编程):比如你每次吃饭前都要洗手(日志记录),吃饭后要擦嘴(事务提交)。如果每顿饭都自己去做这些事,太麻烦。管家可以在你吃饭前自动帮你洗手,吃饭后自动帮你擦嘴,你只管吃饭。这就是AOP,把通用操作从业务中剥离出来。
事务管理:就像管家帮你记账:你每次花钱(数据库操作),管家会自动记录(开启事务),如果钱不够了(异常),他会取消这笔交易(回滚),如果一切顺利,他会帮你确认支付(提交)。你只需要说“买一瓶水”,其他交给管家。
数据访问集成:你想查订单数据,以前要自己连接数据库、写JDBC、处理异常。现在你告诉管家“我要查订单”,管家会帮你用最顺手的方式(比如Hibernate)去查,你只管拿结果。
Web MVC:就像管家帮你处理前台接待:有客人(HTTP请求)来了,管家会根据门牌号(URL)找到对应的人(Controller),然后把客人的话(请求参数)转达给他,再把他的话翻译成客人能听懂的语言(视图)返回。
总之,Spring就是这样一个管家,把繁杂的底层工作都包了,让你专注于业务本身。
【扩展知识点详解】
Spring框架的模块化组成
Spring Framework由约20个模块组成,分为核心容器、数据访问/集成、Web、AOP/仪器、消息、测试等。核心容器包括spring-core、spring-beans、spring-context、spring-expression等,其中spring-context支持国际化、事件传播等。数据访问层包括JDBC、ORM、OXM、JMS、事务管理模块。- IoC容器的两种实现
- BeanFactory:基础容器,提供基本的DI功能,采用延迟初始化(第一次调用
getBean()时才创建Bean)。 - ApplicationContext:高级容器,继承自BeanFactory,添加了国际化、事件传播、AOP集成、声明式机制等特性,通常使用它作为容器。常见实现有
ClassPathXmlApplicationContext、AnnotationConfigApplicationContext等。
- BeanFactory:基础容器,提供基本的DI功能,采用延迟初始化(第一次调用
- 依赖注入的方式
- 构造器注入:强制依赖,保证不可变性。
- Setter注入:可选依赖,允许重新配置。
- 字段注入(通过注解如
@Autowired):简洁但不利于测试和不可变性。
AOP的实现原理
Spring AOP基于动态代理实现:如果目标类实现了接口,则使用JDK动态代理;否则使用CGLIB生成子类代理。通知(Advice)有五种类型:前置(Before)、后置(AfterReturning)、异常(AfterThrowing)、最终(After)、环绕(Around)。切面(Aspect)通过Pointcut表达式定义连接点。事务管理的核心接口
Spring事务抽象的核心接口是PlatformTransactionManager,针对不同持久化技术有不同的实现,如DataSourceTransactionManager(JDBC/MyBatis)、HibernateTransactionManager、JpaTransactionManager。声明式事务通过@Transactional注解配置,可定义传播行为(Propagation)、隔离级别(Isolation)、超时、只读等属性。传播行为详解
常见的传播行为:REQUIRED(支持当前事务,无则新建)、REQUIRES_NEW(挂起当前,新建独立事务)、SUPPORTS(支持当前,无则以非事务方式执行)、MANDATORY(必须存在当前事务,否则抛异常)、NOT_SUPPORTED、NEVER、NESTED(嵌套事务)等。- Spring MVC的核心组件
DispatcherServlet:前端控制器,接收请求并分发。HandlerMapping:根据请求URL找到对应的Controller。HandlerAdapter:调用Controller的方法。ViewResolver:根据逻辑视图名解析实际视图。ModelAndView:封装模型数据和视图信息。
Spring Boot与Spring的关系
Spring Boot是基于Spring Framework的快速开发脚手架,它通过自动配置、起步依赖、嵌入式服务器等特性,极大地简化了Spring应用的初始搭建和开发过程。Spring Boot本身并不替代Spring,而是让Spring更容易使用。- Spring的常用注解
- 声明Bean:
@Component、@Service、@Repository、@Controller。 - 注入依赖:
@Autowired、@Resource、@Inject。 - 配置类:
@Configuration、@Bean、@ComponentScan。 - 事务:
@Transactional。 - MVC:
@RequestMapping、@GetMapping、@PostMapping、@RequestBody、@ResponseBody等。
- 声明Bean:
- Spring的设计思想
- 非侵入式:应用代码无需继承Spring特定类,减少对框架的依赖。
- 开闭原则:通过IoC和AOP实现扩展开放、修改封闭。
- 约定优于配置:尤其在Spring Boot中体现。
- 分层架构:各模块职责清晰,可单独使用。
- Spring与Java EE的关系
Spring早期是对Java EE(当时叫J2EE)的补充,提供了更轻量级的替代方案。随着Java EE演进(现在是Jakarta EE),Spring依然保持活力,并且在微服务时代通过Spring Cloud成为主流选择。
【问题】 BeanFactory和ApplicationContext有什么区别?
【参考答案】 BeanFactory和ApplicationContext都是Spring框架中用于管理Bean的容器接口,其中ApplicationContext是BeanFactory的子接口,提供了更多企业级功能。它们的核心区别如下:
- 功能范围
- BeanFactory:是Spring最底层的IoC容器接口,提供了基础的依赖注入和Bean生命周期管理功能,包括Bean的加载、实例化、依赖维护等。
- ApplicationContext:继承自BeanFactory,除BeanFactory的所有功能外,还扩展了:
- 国际化支持(通过MessageSource)
- 资源访问(如URL和文件资源)
- 事件发布与监听机制(ApplicationEvent)
- 多配置文件加载
- 与Spring AOP、Web应用等更紧密的集成
- Bean的加载时机
- BeanFactory:采用延迟加载(Lazy-loading),只有在调用
getBean()获取Bean时,才进行实例化和依赖注入。 - ApplicationContext:采用预加载(Pre-loading),在容器启动时就会实例化所有单例Bean(默认)。这种方式可以尽早发现配置错误,但会增加启动时间和内存占用。
- BeanFactory:采用延迟加载(Lazy-loading),只有在调用
- 创建方式
- BeanFactory:通常通过编程方式创建,如
new XmlBeanFactory(new ClassPathResource("beans.xml"))(现已废弃,但原理类似)。 - ApplicationContext:支持声明式创建,如在web.xml中配置
ContextLoaderListener,或通过new ClassPathXmlApplicationContext("applicationContext.xml")等。
- BeanFactory:通常通过编程方式创建,如
- 后置处理器的注册
- BeanFactory:需要手动注册
BeanPostProcessor和BeanFactoryPostProcessor。 - ApplicationContext:会自动检测并注册这些后置处理器,无需手动配置。
- BeanFactory:需要手动注册
- 事件发布
- BeanFactory:不支持事件机制。
- ApplicationContext:内置事件发布机制,允许Bean通过实现
ApplicationListener接口监听容器事件(如上下文刷新、关闭等)。
- 应用场景
- BeanFactory:适用于资源有限、对内存敏感的环境,如移动设备或嵌入式系统。但在标准企业应用中较少直接使用。
- ApplicationContext:适用于大多数企业级应用,因为它提供了更丰富的功能,且与Spring生态无缝集成。
【大白话解释于举例说明】 可以把Spring容器想象成一个智能仓库,里面存放着各种零件(Bean)。
BeanFactory 是一个基础仓库,只提供最基本的存取功能。你什么时候需要零件,它什么时候给你拿出来(延迟加载)。仓库里没有广播系统(事件),没有多语言说明书(国际化),也没有统一的物资搬运车(资源访问)。它很省电(内存占用少),但功能单一。
ApplicationContext 是一个高级仓库,不仅存零件,还配备了各种便利设施:它有公告栏(事件机制),可以贴通知让大家知道仓库几点开门;有翻译员(国际化),能看懂多国语言的操作手册;有物流系统(资源访问),可以统一调配物资;还有质检员(后置处理器),自动检查零件质量。虽然每天开门时要把所有零件都摆出来(预加载),有点费电(启动慢),但用起来特别顺手。
举例:如果你写一个简单的Demo,只用到IoC,用BeanFactory就够了。但如果你需要事务管理、AOP、Web支持,那必须用ApplicationContext,因为它在启动时就帮你把复杂配置都处理好了。
【扩展知识点详解】
- BeanFactory的常见实现类
XmlBeanFactory:基于XML配置的经典实现(已废弃,建议使用DefaultListableBeanFactory配合XmlBeanDefinitionReader)。DefaultListableBeanFactory:当前最常用的BeanFactory实现,支持多种Bean定义读取方式。
- ApplicationContext的常见实现类
ClassPathXmlApplicationContext:从类路径加载XML配置文件。FileSystemXmlApplicationContext:从文件系统加载XML配置文件。AnnotationConfigApplicationContext:基于注解和Java配置类的容器,常用于Spring Boot。WebApplicationContext:专为Web应用设计,通过ContextLoaderListener初始化。
- Bean的生命周期管理
- 两者都支持Bean的生命周期回调,如
InitializingBean、DisposableBean接口,以及自定义的init-method和destroy-method。 - ApplicationContext在预加载时会立即调用Bean的初始化方法,而BeanFactory则等到获取时才会调用。
- 两者都支持Bean的生命周期回调,如
- 延迟加载与预加载的选择
- 预加载的优势:提前发现配置错误,提高首次访问速度;适合单例Bean较多的场景。
- 延迟加载的优势:节省启动时间,降低内存占用;适合原型Bean(多例)或资源受限环境。
- 可以通过
@Lazy注解或在XML中配置lazy-init="true"让ApplicationContext中的某些Bean延迟加载。
- BeanFactory和ApplicationContext与BeanPostProcessor的交互
BeanPostProcessor允许在Bean初始化前后进行自定义处理(如代理包装)。- ApplicationContext会自动扫描并注册所有实现了
BeanPostProcessor的Bean;而BeanFactory需要手动调用addBeanPostProcessor方法添加。
- 事件机制详解
- ApplicationContext通过
ApplicationEvent和ApplicationListener实现观察者模式。 - 内置事件:
ContextRefreshedEvent(刷新)、ContextStartedEvent(启动)、ContextStoppedEvent(停止)、ContextClosedEvent(关闭)。 - 开发者也可自定义事件并发布。
- ApplicationContext通过
- 国际化(i18n)支持
- 通过
MessageSource接口实现,ApplicationContext继承了该接口,可以直接使用getMessage方法获取国际化消息,底层依赖于ResourceBundle。
- 通过
- 资源访问
- ApplicationContext实现了
ResourceLoader接口,可以通过getResource方法获取Resource对象,支持类路径、文件系统、URL等多种资源类型。
- ApplicationContext实现了
- Web应用中的ApplicationContext
- Web应用通常有两个上下文:根上下文(由
ContextLoaderListener加载,包含所有Web层之外的Bean)和Web层上下文(由DispatcherServlet加载,包含控制器等)。两者构成父子关系,子上下文可以访问父上下文中的Bean。
- Web应用通常有两个上下文:根上下文(由
- 为什么开发中几乎不使用BeanFactory
- 因为Spring生态(如Spring MVC、Spring Boot)大量依赖于ApplicationContext提供的功能(如事件、资源加载、AOP自动代理等)。BeanFactory过于底层,无法满足企业级开发的需求,除非在极度受限环境中。
IOC与AOP
【问题】 请谈谈你对Spring核心(IoC和AOP)的理解,包括IoC的初始化过程、AOP的核心概念和通知类型。
【参考答案】 Spring框架的核心是控制反转(IoC)和面向切面编程(AOP)。
一、Spring IoC(控制反转)
IoC与DI的概念
IoC(Inversion of Control)是一种设计思想,指将传统上由程序代码直接控制的对象创建权交给容器来实现。Spring通过IoC容器管理对象的生命周期和依赖关系。DI(Dependency Injection)是IoC的一种实现方式,即容器在创建对象时动态地将依赖注入到对象中(通常通过构造方法、setter方法或字段)。IoC容器的核心作用
Spring IoC容器负责读取配置元数据(XML、注解或Java Config),将其解析为BeanDefinition,然后根据BeanDefinition实例化、配置和组装Bean。容器本质上是一个工厂,内部维护了一个Bean定义注册表和单例缓存池(可理解为Map结构)。IoC容器的初始化过程
以ApplicationContext为例,初始化主要分为三个步骤:- 定位:通过ResourceLoader加载配置资源(如XML文件、注解类)。
- 解析与注册:将配置信息解析为BeanDefinition,并注册到BeanDefinitionRegistry中。
- 实例化与依赖注入:容器启动时(或首次请求时)通过反射实例化Bean,并执行依赖注入,同时调用BeanPostProcessor等扩展点完成初始化。
二、Spring AOP(面向切面编程)
AOP的概念
AOP通过预编译方式和运行期动态代理,将那些与业务无关但被多个模块共享的行为(如日志、事务、安全)封装成可重用的模块(称为切面),从而减少代码重复,降低耦合。- AOP的核心概念
- 切面(Aspect):横切关注点的模块化,如日志切面。
- 连接点(Joinpoint):程序执行过程中可插入切面的点(如方法调用)。
- 切入点(Pointcut):定义一组连接点,通知将在这些点上执行。
- 通知(Advice):切面在特定连接点执行的动作,Spring支持五种通知类型。
- 目标对象(Target):被代理的原始对象。
- 织入(Weaving):将切面应用到目标对象并创建代理对象的过程。
- 引入(Introduction):在不修改代码的前提下,为类动态添加新方法或属性。
- 通知类型
- 前置通知(@Before):在目标方法执行前执行。
- 后置通知(@After):在目标方法执行后执行(无论是否异常)。
- 返回通知(@AfterReturning):在目标方法正常返回后执行。
- 异常通知(@AfterThrowing):在目标方法抛出异常后执行。
- 环绕通知(@Around):包围目标方法,可自定义方法执行前后行为。
- AOP的实现机制
Spring AOP基于动态代理实现:若目标类实现了接口,则使用JDK动态代理;否则使用CGLIB生成子类代理。AspectJ则提供静态代理(编译时织入),性能更好但需要特定编译器。
【大白话解释于举例说明】
- IoC:好比你想吃饭,传统方式是自己买菜、做饭、洗碗(new对象、维护依赖)。有了IoC容器(餐厅),你只需点菜(声明依赖),服务员(容器)就会把做好的菜端给你,你只管吃(业务逻辑)。
- DI:餐厅做菜时,需要根据你的口味(配置)自动放入盐、辣椒(依赖对象),这就是依赖注入。
- AOP:餐厅为了记录每个顾客点了什么菜(日志),会在每个菜品制作前后自动拍照记录,而不需要在每个菜谱里写拍照代码。这个拍照功能就是一个切面。
- 通知类型举例:
- 前置通知:上菜前检查餐具是否干净。
- 后置通知:上菜后收拾桌子。
- 返回通知:顾客吃完满意离席时送上一句祝福。
- 异常通知:顾客投诉时及时处理。
- 环绕通知:服务员全程跟踪,从点菜到结账全流程掌控。
【扩展知识点详解】
Bean的生命周期
Spring IoC中Bean的完整生命周期包括:实例化→属性赋值→初始化前(BeanPostProcessor前置处理)→初始化(InitializingBean或init-method)→初始化后(BeanPostProcessor后置处理)→使用中→销毁前(DisposableBean或destroy-method)→销毁。作用域
Spring Bean支持多种作用域:singleton(默认)、prototype、request、session、application、websocket。不同作用域影响Bean的创建和缓存策略。循环依赖
Spring通过三级缓存解决单例Bean的循环依赖问题。一级缓存(成品池)、二级缓存(早期暴露池)、三级缓存(工厂池)。构造器循环依赖无法解决。- AOP的织入时机
- 编译时织入(AspectJ):需要特殊编译器。
- 类加载时织入(AspectJ LTW):通过类加载器实现。
- 运行时织入(Spring AOP):通过动态代理,在运行时创建代理对象。
Spring AOP与AspectJ的关系
Spring AOP集成了AspectJ的注解风格(如@Aspect),但底层仍使用自己的动态代理实现。若需要更强大的AOP功能(如对字段、构造器进行切面),可单独使用AspectJ。- JDK动态代理与CGLIB的对比
- JDK动态代理:要求目标类实现接口,通过反射调用方法,性能稍低。
- CGLIB:通过生成目标类的子类,覆盖方法实现增强,不能代理final类和方法。性能较高(但生成代理类较慢)。
Spring Boot 2.x默认使用CGLIB(通过spring.aop.proxy-target-class=true)。
- Spring IoC容器的高级特性
- 国际化(MessageSource)
- 事件发布(ApplicationEventPublisher)
- 资源加载(ResourceLoader)
- 类型转换(ConversionService)
- 属性解析(Environment)
BeanFactory与ApplicationContext的补充
ApplicationContext除了具备BeanFactory的所有功能外,还自动注册BeanPostProcessor、支持事件发布、国际化等,是更强大的容器。- 常用注解
- 定义Bean:@Component、@Service、@Repository、@Controller、@Bean
- 注入:@Autowired、@Resource、@Inject
- 配置:@Configuration、@ComponentScan、@PropertySource
- AOP:@Aspect、@Pointcut、@Before等
- 设计模式
Spring大量使用设计模式,如:工厂模式(BeanFactory)、单例模式(Bean默认作用域)、代理模式(AOP)、模板方法(JdbcTemplate)、观察者模式(事件机制)等。
设计模式
【问题】 Spring中的设计模式有哪些?
【参考答案】 Spring框架在其设计和实现中广泛运用了经典的设计模式,这些模式使得Spring具有高度的可扩展性、灵活性和可维护性。以下是Spring中常见的设计模式及其具体体现:
单例模式(Singleton)
Spring容器管理的Bean默认作用域为单例(singleton),即每个Bean名称在容器中只存在一个实例。单例模式减少了对象创建和垃圾回收的开销,并保证共享资源的唯一性。工厂模式(Factory)
Spring的IoC容器本质上是一个大工厂,通过BeanFactory和ApplicationContext接口生产和管理Bean。工厂模式将对象的创建与使用分离,降低了客户端与具体实现类的耦合。代理模式(Proxy)
Spring AOP基于动态代理实现,为目标对象生成代理对象,并在代理对象中织入增强逻辑。JDK动态代理(针对接口)和CGLIB代理(针对类)是两种具体实现。模板方法模式(Template Method)
Spring中大量模板类如JdbcTemplate、RestTemplate、JmsTemplate等,它们定义了算法的骨架(如获取连接、处理结果、关闭资源),将可变步骤延迟到回调接口或子类实现,从而减少重复代码。策略模式(Strategy)
Spring的资源访问接口Resource具有不同实现(如ClassPathResource、FileSystemResource),对应不同资源获取策略。此外,Bean的实例化策略、事务管理策略等也体现了策略模式。观察者模式(Observer)
Spring的事件机制基于ApplicationEvent和ApplicationListener实现了观察者模式。当容器发布事件时,所有注册的监听器自动触发相应逻辑,实现组件间的解耦。适配器模式(Adapter)
Spring MVC中的HandlerAdapter用于适配不同类型的处理器(如@Controller方法、HttpRequestHandler),统一调用方式。AOP中的AdvisorAdapter将通知(Advice)适配为拦截器链。责任链模式(Chain of Responsibility)
Spring MVC的拦截器链(HandlerInterceptor)和AOP的通知链(MethodInterceptor)均采用责任链模式,将请求依次传递给多个处理器,每个处理器可决定是否继续执行。前端控制器模式(Front Controller)
Spring MVC的DispatcherServlet作为前端控制器,集中处理所有请求,进行分发、视图解析、异常处理等,简化了Web层的请求处理流程。原型模式(Prototype)
Spring允许将Bean的作用域配置为prototype,每次请求(getBean)都会创建一个新实例,体现了原型模式。适用于有状态的Bean,避免线程安全问题。装饰器模式(Decorator)
Spring中BeanDefinitionDecorator用于扩展Bean定义,例如<context:component-scan>内部通过装饰器添加注解处理器。此外,HttpServletResponseWrapper等包装类也体现了装饰器思想。建造者模式(Builder)
Spring的BeanDefinitionBuilder以流式方式构建BeanDefinition,简化了编程式配置。EmbeddedDatabaseBuilder等也使用了建造者模式。桥接模式(Bridge)
Spring的视图解析体系将视图(View)和视图解析器(ViewResolver)分离,两者可以独立变化,通过桥接模式组合使用。组合模式(Composite)
Spring Cache中的CompositeCacheManager组合多个缓存管理器,统一管理;CompositeClassLoader等也体现了组合模式。
此外,依赖注入(DI)本身虽然不是GoF设计模式,但它是Spring实现控制反转的核心机制,可视为一种更宏观的模式。
【大白话解释于举例说明】
- 单例模式:就像公司只有一个CEO,所有人都找他都是同一个人。Spring的Bean默认是单例,节省内存,避免重复创建。
- 工厂模式:像汽车工厂,你只需要告诉它你想要什么车(配置),它帮你造好(
getBean)。你不需要知道造车细节。 - 代理模式:明星的经纪人,你找明星拍戏要先找经纪人,经纪人帮你谈合同、收钱,明星只负责演戏。Spring AOP就是给方法加个经纪人(代理),在方法前后做日志、事务。
- 模板方法模式:做饭的菜谱,步骤固定(备菜、炒菜、装盘),但具体做什么菜由你做。
JdbcTemplate固定了数据库操作步骤,你只需提供SQL和回调。 - 策略模式:去上班可以选择公交、地铁、打车,不同方式就是不同策略。Spring的
Resource接口让你用统一方式访问不同来源的资源(文件、类路径、URL)。 - 观察者模式:公众号订阅,你关注了公众号,当有新文章发布,你会收到通知。Spring事件机制中,监听者订阅事件,发布者触发事件后监听者自动执行。
- 适配器模式:手机充电器,将220V电压转换为手机需要的5V。Spring MVC中,不同的Controller类型(注解式、接口式)通过适配器统一调用。
- 责任链模式:公司报销流程,员工提交申请,先经组长审批,再到经理,再到财务。Spring拦截器链就是请求依次经过多个拦截器处理。
- 前端控制器模式:公司前台,所有来访客人先找前台,前台再引导到具体部门。
DispatcherServlet就是前台,统一接收请求,分发给Controller。 - 原型模式:每次去复印店复印同一份文件,每次拿到的复印件都是新的。
prototype作用域的Bean每次获取都是新实例。 - 装饰器模式:给蛋糕加上奶油、水果,但蛋糕本身还是蛋糕。Spring的
BeanDefinitionDecorator就是在原有Bean定义上添加额外信息。 - 建造者模式:点餐时,你可以一步一步定制汉堡(加肉、加酱、加蔬菜),最后拿到成品。
BeanDefinitionBuilder让你逐步构建Bean定义。 - 桥接模式:遥控器和电视,不同品牌的遥控器可以控制不同品牌的电视。Spring的
View和ViewResolver可以自由组合。 - 组合模式:文件夹里可以包含文件和其他文件夹。
CompositeCacheManager可以包含多个缓存管理器,统一操作。
【扩展知识点详解】
单例模式的实现细节
Spring通过DefaultSingletonBeanRegistry中的ConcurrentHashMap(singletonObjects)缓存单例Bean,保证每个名称对应唯一实例。单例Bean需注意线程安全问题,因为多个线程可能同时访问。- 工厂模式的层次
- 简单工厂:
BeanFactory根据名称返回实例。 - 工厂方法:
FactoryBean接口允许自定义创建逻辑,如SqlSessionFactoryBean用于创建MyBatis的SqlSessionFactory。 - 抽象工厂:
ApplicationContext本身可视为抽象工厂,负责创建不同配置来源的容器。
- 简单工厂:
代理模式的选择
Spring AOP默认根据目标类是否实现接口选择代理方式:有接口则JDK动态代理,否则CGLIB。可通过<aop:aspectj-autoproxy proxy-target-class="true"/>或Spring Boot的spring.aop.proxy-target-class=true强制使用CGLIB。模板方法模式的扩展
JdbcTemplate内部封装了获取连接、创建语句、处理结果集、异常处理、关闭资源等固定流程,将变化的SQL、参数设置、结果提取通过回调接口(如PreparedStatementCallback、RowCallbackHandler)实现。- 策略模式的更多实例
InstantiationStrategy:Bean实例化策略,有CglibSubclassingInstantiationStrategy(支持方法注入)和SimpleInstantiationStrategy(普通反射)。PlatformTransactionManager:事务管理器策略,如DataSourceTransactionManager、JpaTransactionManager。
- 观察者模式的进阶
- 除了内置事件,开发者可自定义事件(继承
ApplicationEvent)和监听器(实现ApplicationListener或使用@EventListener)。 - 事件发布通过
ApplicationEventPublisher(通常是ApplicationContext)完成。 - 支持异步监听(配合
@Async)。
- 除了内置事件,开发者可自定义事件(继承
- 适配器模式的应用
HandlerAdapter有多个实现:RequestMappingHandlerAdapter(处理@RequestMapping方法)、HttpRequestHandlerAdapter(处理HttpRequestHandler)、SimpleControllerHandlerAdapter(处理旧式Controller接口)。AdvisorAdapter将MethodBeforeAdvice、AfterReturningAdvice、ThrowsAdvice适配为MethodInterceptor。
- 责任链模式的流程
- 拦截器链:
HandlerExecutionChain包含多个HandlerInterceptor,按顺序执行preHandle(返回false可中断)、postHandle(在Controller之后、视图渲染之前)、afterCompletion(请求完成之后)。 - AOP通知链:
ReflectiveMethodInvocation递归调用多个MethodInterceptor,实现环绕通知的链式调用。
- 拦截器链:
前端控制器的职责
DispatcherServlet初始化时会加载HandlerMapping、HandlerAdapter、ViewResolver等组件。请求流程:接收请求 → 通过HandlerMapping获取HandlerExecutionChain→ 通过HandlerAdapter执行处理器 → 返回ModelAndView→ 通过ViewResolver解析视图 → 渲染视图。原型模式的使用场景
原型Bean适用于状态ful的场景,如每个用户独有的购物车。Spring通过反射创建新实例,不会缓存。- 装饰器模式的源码示例
org.springframework.context.annotation.ConfigurationClassPostProcessor内部使用BeanDefinitionDecorator增强配置类。org.springframework.web.util.ContentCachingRequestWrapper装饰请求,缓存内容以便多次读取。
- 建造者模式的更多例子
EmbeddedDatabaseBuilder用于构建嵌入式数据库(如H2)。UriComponentsBuilder构建URI。
桥接模式的理解
View接口负责渲染模型数据,ViewResolver负责根据视图名解析出View实例。两者独立发展,可以通过配置组合使用。组合模式的应用
CompositeCacheManager实现了CacheManager接口,内部持有多个CacheManager,调用其方法时会遍历所有子管理器。CompositeClassLoader也类似。- 设计模式在Spring源码中的位置
可通过阅读Spring源码包名或类名推测模式,例如:org.springframework.beans.factory.support.DefaultSingletonBeanRegistry→ 单例org.springframework.beans.factory.FactoryBean→ 工厂方法org.springframework.aop.framework.ProxyFactory→ 代理org.springframework.jdbc.core.JdbcTemplate→ 模板方法org.springframework.transaction.PlatformTransactionManager→ 策略
注解
【问题】 Spring的常用注解有哪些?@RestController和@Controller的区别?@Component 和 @Bean 的区别是什么?将一个类声明为Spring的 bean 的注解有哪些?@PathVariable 和 @RequestParam 的区别是什么?读取配置文件的注解有哪些?
【参考答案】 Spring框架提供了丰富的注解,用于简化配置、依赖注入、Web开发、事务管理等。以下是针对各子问题的详细解答:
- Spring常用注解概览 按功能分类如下:
- 声明Bean的注解:
@Component、@Service、@Repository、@Controller、@RestController、@Configuration、@Bean - 依赖注入注解:
@Autowired、@Resource、@Inject、@Qualifier、@Primary - 配置相关注解:
@Configuration、@ComponentScan、@PropertySource、@PropertySources、@Import、@ImportResource - 属性绑定注解:
@Value、@ConfigurationProperties - MVC相关注解:
@RequestMapping及其派生注解(@GetMapping、@PostMapping等)、@PathVariable、@RequestParam、@RequestBody、@ResponseBody、@RestController、@ControllerAdvice、@ExceptionHandler - 事务注解:
@Transactional - AOP注解:
@Aspect、@Before、@After、@Around等 - 测试注解:
@SpringBootTest、@MockBean等
- 声明Bean的注解:
- @RestController和@Controller的区别
- @Controller:传统Spring MVC控制器注解,用于标记类为控制器。通常与视图解析器配合返回页面(如JSP、Thymeleaf)。若方法需要返回JSON/XML数据,需在方法上额外添加
@ResponseBody。 - @RestController:从Spring 4引入,是
@Controller和@ResponseBody的组合注解。它表示该类中所有处理器方法的返回值默认直接写入HTTP响应体(即返回JSON/XML),无需在每个方法上加@ResponseBody。适用于RESTful API开发。
- @Controller:传统Spring MVC控制器注解,用于标记类为控制器。通常与视图解析器配合返回页面(如JSP、Thymeleaf)。若方法需要返回JSON/XML数据,需在方法上额外添加
- @Component 和 @Bean 的区别
- 作用对象不同:
@Component是类级别注解,标注在类上,通过类路径扫描自动检测并注册为Bean。@Bean是方法级别注解,通常写在@Configuration类中,方法返回值被注册为Bean。 - 使用场景不同:
@Component适用于自定义编写的类,可通过注解直接标记。@Bean适用于第三方类库或需要复杂初始化逻辑的Bean,因为无法在第三方类上添加@Component,故通过@Bean方法显式创建。 - 实现方式不同:
@Component通过组件扫描(@ComponentScan)自动装配;@Bean通过显式定义方法生成Bean,可灵活控制实例化过程。
- 作用对象不同:
- 将一个类声明为Spring的Bean的注解有哪些
- @Component:通用注解,任何Spring管理的Bean都可使用。
- @Service:标注业务层组件。
- @Repository:标注数据访问层组件,并提供持久化异常转换。
- @Controller:标注控制器层组件。
- @RestController:标注RESTful控制器。
- @Configuration:标注配置类,该类中通过
@Bean声明Bean。 - @Bean:在配置类中显式声明Bean(方法级别)。
- 此外,符合JSR-250规范的
@ManagedBean和JSR-330规范的@Named也可用于声明Bean(需配合相应扫描)。
- @PathVariable 和 @RequestParam 的区别
- @PathVariable:用于获取URI模板中的变量,即URL路径中的占位符。例如
/users/{id},通过@PathVariable("id")获取路径中的id值。 - @RequestParam:用于获取请求参数(查询参数或表单参数),即URL中
?后面的参数。例如/users?id=123,通过@RequestParam("id")获取id值。可设置required(是否必需)和defaultValue(默认值)。
- @PathVariable:用于获取URI模板中的变量,即URL路径中的占位符。例如
- 读取配置文件的注解有哪些
- @Value:用于将配置文件中的属性值注入到字段、方法参数或构造函数参数中,支持SpEL表达式(如
${my.property})。 - @ConfigurationProperties:将配置文件中的属性绑定到Java Bean中,支持前缀绑定和类型安全配置。需配合
@EnableConfigurationProperties或@Component使用。 - @PropertySource:指定要加载的配置文件(如
.properties文件),常与@Configuration搭配,结合@Value或@ConfigurationProperties使用。 - @PropertySources:用于指定多个
@PropertySource。 - 在Spring Boot中,还有
@TestPropertySource(测试环境)、@ConfigurationPropertiesScan等。
- @Value:用于将配置文件中的属性值注入到字段、方法参数或构造函数参数中,支持SpEL表达式(如
【大白话解释于举例说明】
- @RestController vs @Controller:就像餐厅服务员。
@Controller是堂食服务员,你点菜后,他跑去厨房拿菜,然后端到你桌上(返回页面)。而@RestController是外卖员,他直接在厨房把菜打包好(JSON数据)递给你,不用再摆盘上桌。 - @Component vs @Bean:
@Component好比“自动报名”,你在自己身上贴个标签,Spring就自动把你登记在册。@Bean好比“手动推荐”,你写一个方法,在方法里new一个对象,然后告诉Spring:“这是我创建好的对象,你帮我保管”。 - @PathVariable vs @RequestParam:
@PathVariable是从路径里抠数字,比如/user/123,抠出123。@RequestParam是从问号后面拿参数,比如/user?id=123,拿到123。 - 读取配置文件:
@Value就像你去食堂打饭,直接告诉师傅“我要2两米饭”,师傅根据要求打饭。@ConfigurationProperties就像你拿着一个饭盒(配置类),把师傅打的各种菜(配置项)全部装进去,统一带回去。
【扩展知识点详解】
@Component的派生性
@Service、@Repository、@Controller都是@Component的派生注解,它们的功能相同,但用于不同分层,便于代码语义化和AOP切面指定(如事务管理针对@Repository)。@Bean与@Configuration
@Bean方法所在的类通常需标注@Configuration,以确保方法间调用返回的是同一个单例Bean(通过CGLIB代理)。若标注在普通@Component类上,则为“Lite模式”,方法调用每次都会新建实例。- @Autowired与@Resource的区别
@Autowired是Spring注解,默认按类型装配,可通过@Qualifier按名称装配。@Resource是JSR-250注解,默认按名称装配,名称可通过name指定,找不到再按类型。
@Qualifier和@Primary
当存在多个同类型Bean时,@Qualifier指定具体名称,@Primary指定首选Bean,解决歧义。@RequestMapping派生注解
Spring 4.3引入了@GetMapping、@PostMapping、@PutMapping、@DeleteMapping、@PatchMapping,简化路由配置。- @RequestParam常用属性
value/name:参数名称。required:是否必需,默认true。defaultValue:默认值,当参数缺失或值为空时使用。
- @PathVariable常用属性
value/name:路径变量名称。required:是否必需,默认true。
- @Value的用法
- 注入普通字符串:
@Value("张三") - 注入配置文件属性:
@Value("${my.name}") - 注入SpEL表达式:
@Value("#{systemProperties['user.name']}")
- 注入普通字符串:
- @ConfigurationProperties详解
- 需配合
prefix指定前缀,如@ConfigurationProperties(prefix = "my.app")。 - 支持松散绑定(如
my-app-name映射到myAppName)。 - 支持JSR-303校验(配合
@Validated)。 - 需要将配置类注册为Bean(通过
@Component或@EnableConfigurationProperties)。
- 需配合
- @PropertySource的使用
- 加载自定义properties文件:
@PropertySource("classpath:config.properties") - 可指定多个文件,支持占位符。
- 从Spring 4.2起支持
@PropertySources组合多个。
- 加载自定义properties文件:
Spring Boot中的配置文件加载顺序
Spring Boot自动加载application.properties/yml,也支持通过@PropertySource加载自定义文件。@TestPropertySource用于测试环境覆盖。- @ControllerAdvice与@RestControllerAdvice
@ControllerAdvice用于全局异常处理、数据绑定等,可结合@ExceptionHandler、@InitBinder、@ModelAttribute。@RestControllerAdvice=@ControllerAdvice+@ResponseBody,返回JSON格式的异常信息。
常用组合注解
@SpringBootApplication=@Configuration+@EnableAutoConfiguration+@ComponentScan。元注解与组合注解
Spring许多注解是元注解组合而成,例如@RestController由@Controller和@ResponseBody组成。- 注解的扫描配置
通过@ComponentScan指定扫描包,可包含或排除特定注解类。Spring Boot中@SpringBootApplication默认扫描主类所在包及子包。
【问题】 常用的参数校验注解有哪些?
【参考答案】 Java Bean Validation规范(JSR 303/JSR 380)定义了一套注解,用于对Java对象属性进行声明式校验。Spring框架集成了该规范,并提供了与Spring MVC的整合。以下是最常用的校验注解(均位于javax.validation.constraints包下,推荐使用标准注解而非Hibernate扩展):
- 空值检查
@Null:被注释的元素必须为null@NotNull:被注释的元素必须不为null@NotEmpty:被注释的字符串、集合、数组或Map不能为null,且长度/大小必须大于0@NotBlank:被注释的字符串不能为null,且去除首尾空格后长度必须大于0(只能用于字符串)
- 布尔检查
@AssertTrue:被注释的元素必须为true(通常用于Boolean类型)@AssertFalse:被注释的元素必须为false
- 数值范围检查
@Min(value):被注释的元素必须是数字,且值 ≥ 指定的最小值@Max(value):被注释的元素必须是数字,且值 ≤ 指定的最大值@DecimalMin(value):被注释的元素必须是数字,且值 ≥ 指定的最小值(支持字符串表示的浮点数)@DecimalMax(value):被注释的元素必须是数字,且值 ≤ 指定的最大值@Negative:被注释的元素必须是负数(JSR 380新增)@NegativeOrZero:被注释的元素必须是负数或零@Positive:被注释的元素必须是正数@PositiveOrZero:被注释的元素必须是正数或零
- 大小检查
@Size(max, min):被注释的元素的大小必须在指定范围内(可用于字符串、集合、数组、Map)
- 字符串格式检查
@Pattern(regexp, flags):被注释的字符串必须符合指定的正则表达式@Email:被注释的字符串必须是有效的电子邮件格式(JSR 380支持,之前为Hibernate扩展)
- 日期/时间检查
@Past:被注释的日期必须是一个过去的日期@PastOrPresent:被注释的日期必须是过去或现在(JSR 380新增)@Future:被注释的日期必须是一个将来的日期@FutureOrPresent:被注释的日期必须是将来或现在
- 其他
@Digits(integer, fraction):被注释的元素必须是数字,且整数位数和小数位数在指定范围内
在Spring中启用校验
- 对于
@RequestBody参数,使用@Valid(JSR标准)或@Validated(Spring扩展)触发校验,校验失败抛出MethodArgumentNotValidException。 - 对于
@PathVariable、@RequestParam等非Bean参数,需要在类上标注@Validated,然后在参数上直接使用校验注解,校验失败抛出ConstraintViolationException。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@RestController
@Validated // 必须添加以启用方法参数校验
public class UserController {
@PostMapping("/user")
public User createUser(@RequestBody @Valid User user) { // 校验请求体
return user;
}
@GetMapping("/user/{id}")
public User getUser(@PathVariable @Min(1) @Max(100) Long id) { // 校验路径变量
return userService.getById(id);
}
}
【大白话解释于举例说明】
- @NotNull:就像“必须带身份证”,不能没有。
- @NotBlank:不仅要有身份证,而且身份证上的名字不能是空格(至少得有个字)。
- @NotEmpty:就像吃饭的碗,碗不能没有(null),也不能空着(size=0)。
- @Min/@Max:比如年龄必须≥18且≤60,就像“只接待18-60岁顾客”。
- @Pattern:手机号必须符合“1开头的11位数字”的格式。
- @Email:输入的字符串必须看起来像邮箱(有@和域名)。
- @Past:生日必须是过去的日子,不能是未来。
- @Future:预约时间必须是将来的。
- @Size:密码长度必须在6-20位之间,太短或太长都不行。
- @AssertTrue:比如同意条款必须勾选(true)。
【扩展知识点详解】
- JSR 303/380 与 Hibernate Validator
- JSR 303(Bean Validation 1.0)定义了基础注解,JSR 380(Bean Validation 2.0)增加了新注解(如
@Email、@Positive等)。 - Hibernate Validator是JSR的参考实现,并提供了一些扩展注解(如
@Length、@Range、@URL),但不推荐使用,以便于切换实现。
- JSR 303(Bean Validation 1.0)定义了基础注解,JSR 380(Bean Validation 2.0)增加了新注解(如
- @Valid 与 @Validated 的区别
@Valid是JSR标准注解,支持嵌套校验(即校验对象内部的字段)。@Validated是Spring提供的注解,是@Valid的变体,支持分组校验(通过groups属性指定校验组),但不支持嵌套校验(嵌套需配合@Valid)。- 在Controller中,通常对
@RequestBody使用@Valid;对方法参数(如@RequestParam)校验,需在类上加@Validated。
分组校验(Groups)
有时同一个实体在不同场景下需要不同校验规则(如新增时ID必填,更新时ID可选)。可通过定义分组接口(空接口),在注解中指定groups,并在@Validated中指定激活的分组。- 自定义校验注解
通过组合已有注解或自定义逻辑实现。步骤:- 定义注解,元注解
@Constraint(validatedBy = YourValidator.class)。 - 实现
ConstraintValidator接口编写校验逻辑。 - 在注解中指定默认消息(message)、分组等。
- 定义注解,元注解
- 校验失败异常处理
@RequestBody校验失败:抛出MethodArgumentNotValidException,可通过@ControllerAdvice+@ExceptionHandler统一处理。- 方法参数校验失败:抛出
ConstraintViolationException。 - 可自定义响应格式,返回友好的错误信息。
国际化消息
校验消息可以通过ValidationMessages.properties文件自定义,Spring也支持MessageSource整合。手动触发校验
可以通过Validator接口手动校验对象:validator.validate(obj)。Spring Boot自动配置
Spring Boot在spring-boot-starter-validation中自动引入Hibernate Validator,并配置好校验器。无需额外配置即可使用。嵌套校验
如果对象属性是另一个复杂对象,需要在属性上加上@Valid才能递归校验。性能考虑
校验通常发生在请求进入Controller时,对于高并发场景需注意校验开销。复杂校验可考虑异步或精简规则。- 注意事项
- 对于
@RequestParam、@PathVariable等参数校验,必须使用@Validated(类级别)并直接在参数上标注注解,否则校验不生效。 @NotNull与@NotBlank的区别:@NotBlank会自动去除空格,比@NotEmpty更严格。- 数值类型推荐使用包装类型(如
Integer),以便null能被@NotNull检测。
- 对于
生命周期
【问题】 介绍一下Spring Bean的生命周期?
【参考答案】 Spring Bean的生命周期是指Bean从创建到销毁的整个过程,由Spring IoC容器进行管理。完整的生命周期分为以下几个阶段:
实例化(Instantiation) 容器根据Bean定义(BeanDefinition)通过反射(或CGLIB)创建Bean的实例。此时Bean还是一个“空”对象,属性尚未赋值。
属性赋值(Populate Properties) Spring根据依赖注入配置(如XML、注解)对Bean的属性进行填充,包括通过setter方法、构造器或字段注入。
- 初始化(Initialization) 初始化阶段包含一系列回调,使Bean能够感知容器并执行自定义初始化逻辑。具体步骤顺序如下:
- Aware接口回调:如果Bean实现了特定的Aware接口,容器会调用相应的方法注入容器资源。常见的Aware接口有:
BeanNameAware:传入Bean在容器中的名称。BeanClassLoaderAware:传入加载Bean的类加载器。BeanFactoryAware:传入当前BeanFactory实例。ApplicationContextAware:传入ApplicationContext(若容器为ApplicationContext)。
- BeanPostProcessor前置处理:调用所有注册的
BeanPostProcessor的postProcessBeforeInitialization()方法,允许对Bean进行加工(如生成代理)。 - 初始化方法调用:
- 如果Bean实现了
InitializingBean接口,调用其afterPropertiesSet()方法。 - 如果配置了自定义的
init-method(如@Bean(initMethod = "init")),调用该方法。
- 如果Bean实现了
- BeanPostProcessor后置处理:调用
BeanPostProcessor的postProcessAfterInitialization()方法,通常用于生成最终代理对象(如AOP)。
- Aware接口回调:如果Bean实现了特定的Aware接口,容器会调用相应的方法注入容器资源。常见的Aware接口有:
使用中(In Use) Bean已准备就绪,可以被应用程序使用。此时Bean驻留在容器中,直到容器关闭或被显式销毁。
- 销毁(Destruction) 当容器关闭时,如果Bean是单例(singleton)且需要销毁,会执行以下销毁回调:
- 如果Bean实现了
DisposableBean接口,调用其destroy()方法。 - 如果配置了自定义的
destroy-method(如@Bean(destroyMethod = "close")),调用该方法。
- 如果Bean实现了
注意:对于原型(prototype)作用域的Bean,Spring容器只负责创建和初始化,不负责销毁,客户端需自行管理。
【大白话解释于举例说明】 将Spring Bean的生命周期比作一个人的一生:
- 实例化:婴儿出生(刚创建对象,但还没有名字、身份)。
- 属性赋值:父母给婴儿取名、穿衣服(设置属性)。
- Aware接口:婴儿开始认识自己是谁(BeanNameAware),认识自己的家庭(BeanFactoryAware),认识周围环境(ApplicationContextAware)。
- BeanPostProcessor前置处理:出门前家人帮忙整理衣服、检查物品(前置处理)。
- 初始化方法:举行成人礼,正式宣告成年(afterPropertiesSet/init-method),可以开始工作。
- BeanPostProcessor后置处理:穿上工作服,佩戴徽章(后置处理,如AOP代理增强)。
- 使用中:成年人正常工作,为社会创造价值。
- 销毁:老年退休,办理后事(DisposableBean/destroy-method),生命结束。
对于原型Bean,就像临时工,干完活就走,公司不负责他的后续(销毁由自己负责)。
【扩展知识点详解】
BeanPostProcessor的作用
BeanPostProcessor是Spring的扩展点,允许在所有Bean初始化前后进行自定义处理(如包装代理、属性修改)。多个BeanPostProcessor可通过Ordered接口排序。常见的实现有AutowiredAnnotationBeanPostProcessor(处理@Autowired)和AbstractAutoProxyCreator(AOP代理创建)。- Aware接口体系
Spring提供了多种Aware接口,用于注入容器相关对象:BeanNameAwareBeanClassLoaderAwareBeanFactoryAwareApplicationContextAware(需要容器为ApplicationContext)EnvironmentAwareResourceLoaderAwareMessageSourceAwareApplicationEventPublisherAware等
这些接口通常用于框架内部组件,普通业务Bean应避免使用,以降低对Spring的耦合。
- InitializingBean和DisposableBean
InitializingBean:只有一个afterPropertiesSet()方法,在属性赋值后、自定义init-method之前调用。DisposableBean:只有一个destroy()方法,在容器关闭时调用。
使用这些接口会使得Bean与Spring API耦合,推荐使用@PostConstruct和@PreDestroy(JSR-250注解)或自定义init/destroy方法。
@PostConstruct和@PreDestroy
JSR-250规范定义的注解,更优雅且不依赖Spring。它们分别对应初始化后和销毁前回调,在Spring中由CommonAnnotationBeanPostProcessor处理。执行顺序:@PostConstruct→afterPropertiesSet()→init-method。- 初始化方法多种方式的执行顺序
若同时存在,顺序为:@PostConstruct标注的方法InitializingBean.afterPropertiesSet()init-method指定的方法
销毁顺序类似:@PreDestroy→DisposableBean.destroy()→destroy-method。
- 作用域对生命周期的影响
- singleton:Bean由容器管理完整生命周期,包括实例化、初始化、销毁。
- prototype:容器负责实例化和初始化,但销毁回调(
@PreDestroy、DisposableBean)不会执行,因为容器不持有其引用,需由客户端自行清理。 - request/session/application(Web作用域):生命周期与Web请求相关,销毁时机由容器管理。
FactoryBean的特殊性
FactoryBean本身是一个Bean,用于创建其他Bean。其生命周期与普通Bean类似,但通过getObject()返回的对象不受容器完整生命周期管理(除非被标记为单例且容器管理)。循环依赖与三级缓存
在单例Bean的创建过程中,Spring通过三级缓存解决循环依赖。实例化后的Bean会提前暴露(放入三级缓存),允许其他Bean引用尚未初始化完成的Bean,但此时的Bean仅完成实例化,属性尚未填充。- Bean的完整流程(包含循环依赖)
- 实例化(通过构造器)
- 提前暴露(放入三级缓存)
- 属性赋值(可能依赖其他Bean)
- 初始化(Aware → BeanPostProcessor前置 → 初始化方法 → BeanPostProcessor后置)
- 放入一级缓存(成品)
- 实际应用
理解Bean生命周期有助于:- 在合适的阶段进行自定义扩展(如实现
BeanPostProcessor)。 - 排查依赖注入问题(如属性未赋值)。
- 理解AOP代理的生成时机(在
BeanPostProcessor后置阶段)。 - 合理使用初始化/销毁回调管理资源(如线程池、连接池的关闭)。
- 在合适的阶段进行自定义扩展(如实现
【问题】 分析一下Spring各个模块?
【参考答案】 Spring框架采用模块化设计,根据功能划分为多个独立的模块,开发者可以根据需求选择使用。以下基于Spring 5.x版本介绍主要模块及其作用:
- 核心容器(Core Container)
- spring-core:框架底层基础,提供资源访问、类型转换、常用工具类等核心功能。
- spring-beans:支持控制反转(IoC)和依赖注入(DI),包含BeanFactory接口及其实现,负责Bean的定义、加载、实例化和依赖管理。
- spring-context:在core和beans基础上构建,提供ApplicationContext(IoC容器的高级实现),并添加了国际化(MessageSource)、事件传播(ApplicationEvent)、资源加载、数据绑定、校验、以及Java EE集成等企业级功能。
- spring-expression:提供强大的表达式语言(SpEL),支持在运行时查询和操作对象图,可用于属性赋值、方法调用等。
- AOP与Aspects
- spring-aop:提供面向切面编程的实现,支持JDK动态代理和CGLIB,允许将横切关注点(如日志、事务)与业务逻辑分离。
- spring-aspects:集成AspectJ框架,提供更强大、更灵活的AOP功能(如编译时织入、加载时织入),通过注解或XML配置即可使用AspectJ切面。
- 数据访问/集成
- spring-jdbc:简化JDBC编程,提供JdbcTemplate等模板类,消除重复代码,并统一异常处理。
- spring-tx:提供声明式和编程式事务管理,支持本地事务和分布式事务,可与各种持久化技术(JDBC、ORM)集成。
- spring-orm:集成主流ORM框架(如Hibernate、JPA、MyBatis),提供一致的异常转换和事务管理。
- spring-oxm:支持对象与XML之间的映射(Object/XML Mapping),集成JAXB、Castor、XStream等实现。
- spring-jms:简化Java消息服务(JMS)的编程,提供JmsTemplate等工具,支持消息生产者和消费者的异步通信。
- Web模块
- spring-web:提供基础的Web集成功能,如多文件上传、HTTP客户端(RestTemplate)、Servlet监听器等,以及与其他Web框架(如JSF)的集成。
- spring-webmvc:基于Servlet API的MVC框架,提供控制器、视图解析、处理器映射等组件,支持RESTful风格的开发。
- spring-websocket:支持WebSocket通信,实现全双工、低延迟的浏览器与服务器交互。
- spring-webflux:响应式Web框架,基于Reactive Streams,支持非阻塞、事件驱动的编程模型(Spring 5引入)。
- 消息通信
- spring-messaging:作为消息抽象模块,提供对消息协议(如STOMP)的支持,为WebSocket和响应式编程提供基础。
- 测试
- spring-test:支持单元测试和集成测试,提供与JUnit、TestNG的集成,以及Mock对象、事务测试、Web测试等功能。
- 其他模块
- spring-context-support:提供对第三方库的集成支持,如缓存(Ehcache)、任务调度(Quartz)、邮件发送(JavaMail)等。
- spring-instrument:提供类加载时的增强支持,用于特定应用服务器。
注意:早期的spring-web-struts模块在Spring 3.x后已废弃,因为Struts 1.x已停止维护,Struts 2.x可通过其他方式集成。现代开发中,Spring Boot和Spring Cloud进一步简化了模块的依赖管理。
【大白话解释于举例说明】 把Spring比作一个多功能的工具箱,每个模块就是不同功能的工具层:
- core/beans/context:工具箱的基础框架和架子(核心容器),负责摆放和管理工具(Bean)。你告诉它需要什么工具,它自动给你拿出来,不用自己满仓库找。
- AOP:像给工具加上自动记录功能的贴膜(切面),比如给螺丝刀贴上“每次使用后自动计数”的标签,不用在螺丝刀本身写代码。
- 数据访问模块:专门处理数据库的工具套件:
jdbc:简化JDBC,像一把万能扳手,拧螺丝(操作数据库)变得简单。tx:自动帮你管好“交易记录”(事务),比如你要转账,它保证钱要么同时转出和转入,要么都不转。orm:让你用Hibernate/MyBatis这些高级工具,不用自己造轮子。
- Web模块:搭建网站的工具:
webmvc:像一个接待员(DispatcherServlet),把客户请求(HTTP)分配给对应的处理员(Controller)。websocket:像对讲机,浏览器和服务器可以随时通话。webflux:像超级接待员,能同时处理成千上万请求而不堵塞。
- 测试模块:自带质检工具,确保组装好的工具(应用)没问题。
总之,Spring模块化设计让你可以根据项目需要,只拿必要的工具,轻装上阵。
【扩展知识点详解】
- 模块依赖关系
spring-core和spring-beans是所有模块的基础,其他模块都直接或间接依赖它们。spring-context依赖spring-core、spring-beans、spring-aop、spring-expression等。spring-webmvc依赖spring-web,而spring-web依赖spring-context。
Spring Boot与模块关系
Spring Boot基于Spring Framework,通过起步依赖(starter)封装了常用模块的组合。例如spring-boot-starter-web包含了spring-webmvc、spring-web、spring-boot-starter-tomcat等,简化配置。- 模块的JAR命名与Maven坐标
Spring模块的JAR包命名通常为spring-模块名,如spring-core。Maven坐标示例:1 2 3 4 5
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.3.30</version> </dependency>
- 可选模块与集成
spring-orm与具体ORM框架(如Hibernate)搭配时,需额外引入ORM框架本身的依赖。spring-oxm需配合具体的OXM实现库使用。
- 模块演进
- Spring 4.x引入
spring-websocket模块,支持WebSocket和STOMP。 - Spring 5.x引入
spring-webflux模块,提供响应式编程支持。 - 旧版
spring-struts已在Spring 3.2.x中标记为废弃,后续版本移除。
- Spring 4.x引入
- 模块功能扩展
Spring通过spring-context-support模块集成多种第三方技术,如:- 缓存:
EhCacheCacheManager、RedisCacheManager - 调度:
Quartz、TaskScheduler - 邮件:
JavaMailSender
- 缓存:
- 测试模块的高级特性
@ContextConfiguration加载Spring上下文。@Transactional和@Rollback用于数据库测试自动回滚。MockMvc模拟HTTP请求测试Controller。
- 模块化设计的优点
- 按需引入,避免依赖臃肿。
- 各模块职责清晰,便于维护和扩展。
- 可替换性:如事务模块可独立用于非Spring环境。
bean
【问题】 Spring中的bean的作用域有哪些?单例bean的线程安全问题了解吗?
【参考答案】 Spring Bean的作用域(Scope)定义了Bean的生命周期和可见范围。Spring框架支持多种作用域,其中常用的有:
- 标准作用域(在任何Spring环境中可用)
- singleton(单例):默认作用域。每个Spring IoC容器中只存在一个Bean实例,所有对该Bean的请求都返回同一个对象。适用于无状态的服务层、数据访问层等。
- prototype(原型):每次请求(注入或通过
getBean()获取)都会创建一个新的Bean实例。Spring不管理原型Bean的完整生命周期,销毁回调需要由客户端自行处理。适用于有状态的Bean,如每个用户独立的购物车。
- Web作用域(仅在Web-aware的ApplicationContext中可用)
- request:每个HTTP请求创建一个新的Bean实例,仅在当前请求内有效。请求结束后Bean被销毁。基于
RequestContextListener或RequestContextFilter实现。 - session:每个HTTP会话(Session)创建一个Bean实例,在整个会话周期内有效。不同会话拥有不同实例。
- application:整个ServletContext生命周期内创建一个Bean实例,类似于单例但作用域在ServletContext级别。在Spring 5中引入,也可使用
global session(在Portlet环境中)。 - websocket:每个WebSocket会话创建一个Bean实例(Spring 4+引入,5+完善)。
- request:每个HTTP请求创建一个新的Bean实例,仅在当前请求内有效。请求结束后Bean被销毁。基于
- 自定义作用域 开发者可实现
Scope接口并注册到容器,以支持自定义作用域(如线程作用域、任务作用域)。
单例Bean的线程安全问题 单例Bean由于在整个容器中只有一个实例,当多个线程同时访问该Bean时,如果Bean中存在可变的成员变量(状态),并且对这些变量进行写操作,就可能出现线程安全问题(数据不一致、脏读等)。例如,一个单例的服务类中有一个int count字段,多个线程同时调用增加count的方法,就会导致竞态条件。
原因:Spring容器默认不会对单例Bean进行同步处理,也不保证线程安全。线程安全与否完全取决于Bean本身的实现。
解决方案:
- 无状态Bean:尽量将Bean设计为无状态,即不包含可变的成员变量。所有需要的状态通过方法参数传入。这是最佳实践,例如Controller、Service通常应该是无状态的。
- 使用ThreadLocal:如果必须保存线程隔离的状态,可以使用
ThreadLocal将变量与当前线程绑定,每个线程持有自己的副本,避免共享。 - 同步控制:对可变状态的访问加锁(如
synchronized或Lock),但会降低并发性能,不推荐。 - 改用原型作用域:如果Bean需要持有用户特有的状态,可以将其作用域改为
prototype或request/session,确保每个线程或请求有自己的实例。 - 使用不可变对象:将成员变量设为
final,或使用只读对象,避免修改。
需要注意的是,即使Bean是无状态的,如果它调用了线程不安全的第三方组件(如非线程安全的集合),也可能引发问题。
【大白话解释于举例说明】
- 作用域比喻:
- singleton:公司只有一个饮水机,所有人都用同一个。适合大家共享的东西(如配置信息)。
- prototype:公司有一次性纸杯,每次喝水都拿一个新杯子。适合每个人独立使用的东西(如一次性餐具)。
- request:餐厅里,每个顾客(请求)有自己的菜单(Bean),用完就收走。适合存储本次请求的数据(如表单对象)。
- session:健身房会员卡,每个会员(会话)有自己的储物柜(Bean),会籍期间一直有效。适合存储用户登录信息。
- 线程安全问题:假设饮水机(单例Bean)上有一个计数器,记录总共被用过多少次。如果多个人同时去按计数器(并发写),数字可能不准(比如少记了)。解决办法:
- 无状态:把计数器去掉,每次记录用笔写在本子上(作为参数传入方法),不共享状态。
- ThreadLocal:给每个人发一个私人记事本,自己记自己的次数(线程隔离)。
- 同步:给饮水机加一把锁,一次只能一个人用(性能差)。
【扩展知识点详解】
- 作用域的实现原理
- singleton:Bean实例被缓存到
singletonObjects(ConcurrentHashMap)中。 - prototype:容器不缓存,每次请求都通过反射创建新实例。
- request/session:通过
RequestContextHolder将当前请求/会话绑定到ThreadLocal中,Bean实例存储在请求或会话的属性中。需在web.xml配置RequestContextListener或RequestContextFilter。
- singleton:Bean实例被缓存到
单例Bean的线程安全误区
很多人误以为Spring单例Bean是线程安全的,实际上Spring只是管理Bean的生命周期,并不负责同步。常见的线程安全类如JdbcTemplate、HibernateTemplate等本身就是线程安全的,因为它们是无状态的。- @Scope注解的使用
1 2 3
@Component @Scope("prototype") public class MyPrototypeBean { ... }
在Web环境中,可使用
@RequestScope、@SessionScope、@ApplicationScope等组合注解。 原型Bean的销毁
原型Bean的销毁不由Spring容器管理,但可以通过自定义DestructionAwareBeanPostProcessor或@PreDestroy(实际上不生效)来处理。通常无需关心原型Bean销毁,除非持有需要释放的资源(如连接池)。作用域依赖问题
如果将短作用域Bean(如request)注入到长作用域Bean(如singleton)中,会因Bean创建时机不同导致问题。解决方案:使用@Lazy代理(<aop:scoped-proxy/>),Spring会生成一个代理对象,每次调用时从当前作用域获取真实Bean。- 线程安全的其他解决方案
- 原子变量:如
AtomicInteger,适用于简单计数。 - 并发集合:如
ConcurrentHashMap代替普通HashMap。 - 不可变对象:对象一旦创建就不变,天然线程安全。
- 函数式编程:避免共享状态。
- 原子变量:如
测试中的注意事项
测试单例Bean时,由于上下文会缓存Bean,多次测试可能共享状态,需注意重置状态或使用@DirtiesContext。Spring Boot中的作用域
Spring Boot自动配置的Bean大多是单例且无状态的,如RestTemplate、ObjectMapper。若需要自定义作用域,可通过@Bean配合@Scope实现。- 线程作用域(自定义)
可以通过实现Scope接口创建线程作用域,使Bean在每个线程中保持单例,常与ThreadLocal配合,用于异步任务中传递上下文。
循环依赖
【问题】 Spring是怎样解决循环依赖的?
【参考答案】 Spring容器通过三级缓存机制解决单例Bean之间的循环依赖问题。循环依赖是指两个或多个Bean相互引用,例如A依赖B,B依赖A,形成闭环。Spring只能解决单例作用域下通过setter注入或字段注入的循环依赖,对于构造器注入的循环依赖无法解决(会抛出BeanCurrentlyInCreationException)。
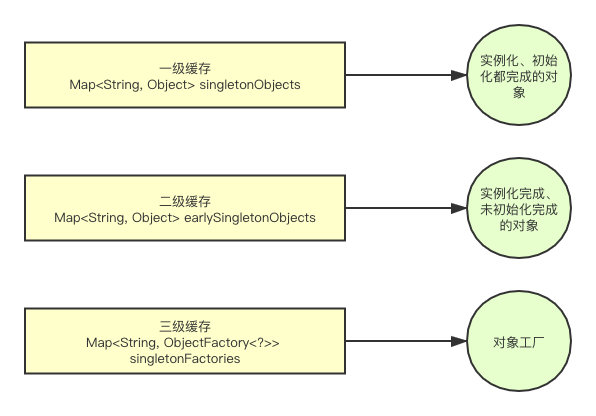
三级缓存的结构 Spring内部维护了三个缓存Map,用于存储不同阶段的Bean实例:
- 一级缓存(
singletonObjects):存放已经完成初始化的单例Bean(成品Bean)。 - 二级缓存(
earlySingletonObjects):存放提前暴露的、尚未完成初始化的Bean实例(半成品Bean),用于解决循环依赖。 - 三级缓存(
singletonFactories):存放Bean的ObjectFactory,用于生成提前暴露的Bean实例。当Bean需要提前暴露时,会将一个工厂对象放入三级缓存,后续通过该工厂获取实例。
解决循环依赖的流程(以A依赖B,B依赖A为例)
- 开始创建A:
getBean(A),先从一级缓存查找,不存在,且A正在创建中,于是准备创建A。 - 实例化A:调用构造器创建A的原始对象(此时属性尚未填充),并将其包装为
ObjectFactory放入三级缓存(singletonFactories)。 - 填充A的属性:发现A依赖B,开始
getBean(B)。 - 创建B:同样先查缓存,不存在,则实例化B,并将B的工厂放入三级缓存。
- 填充B的属性:发现B依赖A,调用
getBean(A)。- 先查一级缓存:没有。
- 查二级缓存:没有。
- 查三级缓存:找到A的工厂,通过工厂获取A的早期引用(半成品),并将该引用放入二级缓存(
earlySingletonObjects),同时删除三级缓存中的工厂。
- B获取到A的引用:B完成属性填充,接着执行初始化步骤(如
BeanPostProcessor),最终将B放入一级缓存,并删除二级和三级缓存中的B。 - B创建完成:回到A的创建过程,此时A已经能从二级缓存或通过
getBean(B)获取到B的完整实例(B已在一级缓存),A完成属性填充和初始化,然后放入一级缓存。
关键点
- 三级缓存中的
ObjectFactory允许在需要时生成早期引用,如果Bean需要被AOP代理,工厂返回的是代理对象而非原始对象,从而保证依赖注入的是代理对象。 - 二级缓存存储早期引用,用于避免重复从三级缓存获取工厂创建对象。
- 只有单例Bean且允许循环引用(默认允许)时才会使用三级缓存。原型Bean无法解决循环依赖,因为容器不缓存原型Bean。
【大白话解释于举例说明】 可以把Spring容器想象成一个婚介所,要介绍对象A和B,但A说“我要B才结婚”,B说“我要A才结婚”,这成了死循环。婚介所怎么办呢?
- 一级缓存:已领证的新人(完整Bean)。
- 二级缓存:订婚但还没领证的(半成品Bean)。
- 三级缓存:婚介所掌握的“准新人资料卡”(ObjectFactory),可以随时约见面。
流程:
- A来登记,婚介所先看已领证的没有,于是给A拍照(实例化),并把资料卡(工厂)放入三级缓存。
- A说“我要B才结婚”,婚介所去找B。
- B来登记,同样拍照,资料卡放三级缓存。
- B说“我要A才结婚”,婚介所查已领证没有,查订婚没有,然后从三级缓存找到A的资料卡,打电话让A来见面(获取早期引用),A虽然还没领证,但可以先订婚(放入二级缓存)。
- B见到A后,满意,于是领证(完成初始化),放入一级缓存。
- 然后婚介所通知A:“B已经领证了,你们可以继续”,A得到B的完整信息,也完成领证,放入一级缓存。
这样,通过“先订婚再领证”的方式,解决了死循环。如果A或B要求必须领完证才能见面(构造器注入),那就没法解决了。
【扩展知识点详解】
为什么需要三级缓存,两级不够吗?
两级缓存(一级+二级)理论上可以解决普通循环依赖,但无法处理AOP代理的情况。因为AOP代理对象需要在Bean初始化最后阶段(BeanPostProcessor后置处理)才生成,而早期暴露的必须是代理对象(否则注入的是原始对象,导致代理失效)。三级缓存通过ObjectFactory允许在暴露早期引用时根据情况返回原始对象或代理对象,实现了延迟生成代理的能力。如果只用两级缓存,则必须在实例化后立即创建代理,破坏了AOP的正常流程。- 哪些循环依赖无法解决?
- 构造器注入:因为构造器在实例化阶段就必须传入依赖,此时Bean尚未创建,无法提前暴露。
- 原型作用域:原型Bean不缓存,无法提前暴露。
- 非单例作用域(如request、session):作用域范围导致无法缓存。
@Async注解的Bean:由于@Async通过代理实现,且代理创建时机特殊,可能导致循环依赖异常。
循环依赖的检测
Spring在创建Bean时,会将当前正在创建的Bean名称放入一个“正在创建集合”(singletonsCurrentlyInCreation)中。当检测到递归依赖时,会判断是否允许循环引用(setAllowCircularReferences),默认允许。如果不允许,则抛出异常。- 三级缓存的具体代码位置
DefaultSingletonBeanRegistry类中定义了三个缓存:1 2 3 4 5 6
/** 一级缓存:成品Bean */ private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); /** 二级缓存:早期暴露的半成品Bean */ private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16); /** 三级缓存:Bean工厂,用于生成早期引用 */ private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
- 解决构造器循环依赖的方案
- 改用setter注入或字段注入。
- 使用
@Lazy注解,延迟加载其中一个依赖,例如在构造器参数上加@Lazy,使其通过代理延迟初始化。 - 重新设计类结构,避免循环依赖。
循环依赖与AOP
当Bean需要AOP代理时,三级缓存中的ObjectFactory会返回代理对象(通过SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法)。这样早期暴露的就是代理对象,保证了后续注入的正确性。三级缓存与性能
三级缓存中的工厂只在需要时才调用,避免了不必要的代理创建。二级缓存则缓存了工厂生成的早期引用,防止多次调用工厂导致重复创建。如何禁用循环依赖
可以通过设置AbstractAutowireCapableBeanFactory的setAllowCircularReferences(false)来禁止循环依赖,这样一旦检测到循环引用就会抛出异常。- 常见面试题
- “Spring如何解决循环依赖?”:核心是三级缓存。
- “为什么需要三级缓存而不是两级?”:因为AOP需要延迟生成代理对象。
- “构造器循环依赖能解决吗?”:不能,因为构造器调用时Bean还未实例化。
理解Spring解决循环依赖的原理,有助于深入掌握IoC容器的内部工作机制,并在实际开发中避免不合理的设计。
事务
【问题】 事务的特性是什么?Spring 管理事务的方式有几种?
【参考答案】 事务(Transaction)是数据库操作的基本单元,具有四大特性(ACID):
- 原子性(Atomicity):事务是一个不可分割的工作单元,事务中的所有操作要么全部成功,要么全部失败回滚。如果事务执行过程中发生错误,已执行的操作会被撤销,回到事务开始前的状态。
- 一致性(Consistency):事务执行前后,数据库的完整性约束(如主键、外键、唯一性约束等)必须保持一致。即事务将数据库从一个一致状态转换到另一个一致状态。
- 隔离性(Isolation):多个事务并发执行时,彼此之间应该相互隔离,避免互相干扰。隔离性通过不同隔离级别来控制并发事务的可见性,防止脏读、不可重复读、幻读等问题。
- 持久性(Durability):事务一旦提交,其对数据库的修改就是永久性的,即使系统发生故障也不会丢失。
Spring 管理事务的方式主要有两种:
- 编程式事务:通过编写代码手动管理事务,例如使用
TransactionTemplate或PlatformTransactionManager直接控制事务的开启、提交、回滚。这种方式灵活但代码侵入性强,实际开发中较少使用。 - 声明式事务:基于AOP实现,通过XML配置或注解(如
@Transactional)来声明事务边界。开发者只需在方法或类上添加注解,Spring会自动在方法调用前后进行事务管理,无需编写额外代码。声明式事务降低了耦合度,是推荐的使用方式。
【大白话解释于举例说明】
- 事务的ACID特性:想象你去银行转账,从A账户扣100元,给B账户加100元。
- 原子性:要么两个操作都成功(转账完成),要么都失败(钱没动)。不能只扣A不加B。
- 一致性:转账前后,两个账户的总余额不变(比如都是1000元),且满足账户不能为负等业务规则。
- 隔离性:如果你和另一人同时操作同一个账户,系统会通过锁等机制避免数据混乱。比如你转账的同时,别人查询余额,应该看到的是转账前或转账后的稳定状态,而不是中间状态。
- 持久性:转账成功后,即使银行系统突然断电,重启后钱也不会丢。
- Spring事务管理方式:
- 编程式事务:就像你自己写一份详细的流程说明:先开启事务,执行操作,如果成功就提交,失败就回滚。代码里到处都是try-catch和commit/rollback。
- 声明式事务:就像你在方法上贴个标签“@Transactional”,告诉Spring这个方法需要事务管理,Spring会在背后帮你自动处理开启、提交、回滚,你只需专注业务逻辑。
【扩展知识点详解】
- 事务的ACID深入理解
- 原子性由事务日志(undo log)保证,回滚时利用日志恢复数据。
- 一致性由应用层和数据库约束共同保证。
- 隔离性由锁机制和MVCC实现,不同隔离级别对应不同的并发控制策略。
- 持久性通过redo log保证,事务提交时日志刷盘,即使内存数据丢失也能恢复。
- Spring事务管理的核心接口
- PlatformTransactionManager:Spring事务抽象的核心接口,定义了获取事务、提交、回滚等方法。常见实现类有
DataSourceTransactionManager(JDBC/MyBatis)、HibernateTransactionManager、JpaTransactionManager等。 - TransactionDefinition:定义事务的属性,包括隔离级别、传播行为、超时时间、只读标志等。
- TransactionStatus:表示当前事务的状态,可用于编程式事务中控制回滚等。
- PlatformTransactionManager:Spring事务抽象的核心接口,定义了获取事务、提交、回滚等方法。常见实现类有
- 声明式事务的实现原理
基于AOP,通过@Transactional注解(或XML配置)标记需要事务管理的方法。Spring会为目标Bean创建代理对象,在方法调用前后通过TransactionInterceptor拦截器织入事务逻辑。当方法正常返回时提交事务,抛出异常时根据配置决定是否回滚。 - @Transactional注解的常用属性
- propagation:事务传播行为,如
REQUIRED(默认)、REQUIRES_NEW、SUPPORTS等。 - isolation:事务隔离级别,如
READ_COMMITTED、REPEATABLE_READ等。 - timeout:事务超时时间(秒),默认-1(使用底层数据库的超时)。
- readOnly:是否为只读事务,用于优化(如JDBC的只读提示)。
- rollbackFor:指定触发回滚的异常类型,默认运行时异常(
RuntimeException)和错误(Error)回滚,受检异常(Exception)不回滚。 - noRollbackFor:指定不触发回滚的异常类型。
- propagation:事务传播行为,如
- 事务传播行为详解
传播行为定义了事务方法被另一个事务方法调用时,事务如何传递。常见传播行为:- REQUIRED:支持当前事务,如果不存在则新建事务(默认)。
- SUPPORTS:支持当前事务,如果不存在则以非事务方式执行。
- MANDATORY:必须存在当前事务,否则抛出异常。
- REQUIRES_NEW:新建事务,如果当前存在事务则挂起当前事务。
- NOT_SUPPORTED:以非事务方式执行,如果当前存在事务则挂起。
- NEVER:以非事务方式执行,如果当前存在事务则抛出异常。
- NESTED:嵌套事务,基于保存点实现,允许部分回滚。
传播行为总结表:
| 传播行为 | 当前存在事务 | 当前无事务 | 特点 |
|---|---|---|---|
| REQUIRED | 加入 | 新建 | 默认,最常用 |
| REQUIRES_NEW | 挂起当前,新建 | 新建 | 独立事务,互不影响 |
| SUPPORTS | 加入 | 非事务运行 | 可选事务 |
| NOT_SUPPORTED | 挂起当前 | 非事务运行 | 强制非事务 |
| MANDATORY | 加入 | 抛异常 | 必须已有事务 |
| NEVER | 抛异常 | 非事务运行 | 禁止事务 |
| NESTED | 嵌套事务 | 新建 | 基于保存点,可部分回滚 |
示例详解:
REQUIRED(默认) 行为:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新事务。 适用场景:大多数业务操作,需要保证在同一个事务中完成。 示例: ```java @Service public class UserService { @Autowired private AccountService accountService;
@Transactional(propagation = Propagation.REQUIRED) public void register(User user) { // 保存用户 userDao.save(user); // 调用账户服务创建账户(该方法也使用REQUIRED) accountService.createAccount(user.getId()); } }
@Service public class AccountService { @Transactional(propagation = Propagation.REQUIRED) public void createAccount(Long userId) { accountDao.create(userId); // 如果这里抛出异常,整个register事务回滚 } }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
**结果**:`createAccount`方法加入到`register`的事务中,两者在同一事务中。任何地方抛出异常都会导致整个事务回滚。
52. REQUIRES_NEW
**行为**:无论当前是否存在事务,都创建一个新事务。如果当前存在事务,则将当前事务挂起,新事务独立提交或回滚,不影响原事务。
**适用场景**:需要独立提交的操作,如记录日志、审计,即使主事务回滚也不应影响。
**示例**:
```java
@Service
public class OrderService {
@Autowired
private LogService logService;
@Transactional(propagation = Propagation.REQUIRED)
public void placeOrder(Order order) {
orderDao.save(order);
// 记录日志(使用独立事务)
logService.log("Order placed: " + order.getId());
// 模拟异常
if (true) throw new RuntimeException("订单创建失败");
}
}
@Service
public class LogService {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void log(String message) {
logDao.insert(message);
}
}
结果:placeOrder方法抛出异常后,订单保存回滚,但logService.log方法已经在独立事务中提交,日志被持久化。因为REQUIRES_NEW会挂起主事务,新事务独立提交。
- SUPPORTS 行为:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。 适用场景:查询方法,有事务时可利用事务一致性,无事务时也可执行。 示例:
1 2 3 4
@Transactional(propagation = Propagation.SUPPORTS) public User findUser(Long id) { return userDao.findById(id); }
结果:如果调用方有事务,则加入;否则以非事务方式执行。
- NOT_SUPPORTED 行为:以非事务方式执行,如果当前存在事务,则挂起当前事务。 适用场景:执行不需要事务的操作,如发送短信、邮件,避免长事务占用连接。 示例:
1 2 3 4 5 6 7 8
@Service public class NotificationService { @Transactional(propagation = Propagation.NOT_SUPPORTED) public void sendEmail(String to, String content) { // 发送邮件(无需事务) mailSender.send(to, content); } }
- MANDATORY 行为:必须在一个已有的事务中执行,否则抛出异常。 适用场景:强制要求在事务内执行的操作,如数据修改。 示例:
1 2 3 4
@Transactional(propagation = Propagation.MANDATORY) public void updateUser(User user) { userDao.update(user); }
结果:如果调用该方法时没有事务,则抛出
IllegalTransactionStateException。 - NEVER 行为:必须以非事务方式执行,如果当前存在事务,则抛出异常。 适用场景:不允许在事务中执行的操作,如某些只读操作或可能引起死锁的操作。 示例:
1 2 3 4
@Transactional(propagation = Propagation.NEVER) public void generateReport() { // 生成报表,无需事务 }
- NESTED 行为:如果当前存在事务,则在嵌套事务内执行;如果没有事务,则行为类似
REQUIRED。嵌套事务基于数据库保存点(savepoint)实现,允许部分回滚。 适用场景:需要部分回滚的场景,如复杂的批量处理,某一条失败不影响整体。 示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
@Service public class BatchService { @Transactional(propagation = Propagation.REQUIRED) public void processBatch(List<Item> items) { for (Item item : items) { try { processItem(item); // 该方法使用NESTED } catch (Exception e) { // 记录失败项,继续处理其他 } } } @Transactional(propagation = Propagation.NESTED) public void processItem(Item item) { itemDao.save(item); if (item.isInvalid()) { throw new RuntimeException("无效项"); } } }
结果:
processItem在嵌套事务中执行,如果某个项无效,仅回滚该项的操作,不影响外层事务中已保存的其他项。注意:嵌套事务需要底层数据库支持保存点(如MySQL InnoDB支持)。 - 编程式事务的两种实现方式
- 使用TransactionTemplate:通过回调接口执行事务代码,由模板管理事务。
1 2 3 4 5 6 7 8 9
@Autowired private TransactionTemplate transactionTemplate; public void doSomething() { transactionTemplate.execute(status -> { // 业务操作 return result; }); }
- 使用PlatformTransactionManager:直接获取事务状态,手动commit/rollback。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
@Autowired private PlatformTransactionManager transactionManager; public void doSomething() { DefaultTransactionDefinition def = new DefaultTransactionDefinition(); TransactionStatus status = transactionManager.getTransaction(def); try { // 业务操作 transactionManager.commit(status); } catch (Exception e) { transactionManager.rollback(status); throw e; } }
- 使用TransactionTemplate:通过回调接口执行事务代码,由模板管理事务。
- 声明式事务的注意事项
@Transactional注解只能应用于public方法上,因为代理机制只能拦截public方法。- 同一个类中的方法调用(如A方法调用B方法,两者都有
@Transactional)会导致事务失效,因为调用不经过代理对象。解决方案:注入自身代理或使用AopContext.currentProxy()。 - 事务回滚默认仅对运行时异常(
RuntimeException)和Error生效,对受检异常(如IOException)不回滚。可通过rollbackFor属性配置。 - 合理设置
readOnly可提高性能,但仅对某些数据库有效(如MySQL的InnoDB在只读事务中可优化)。 - 隔离级别需要底层数据库支持,如MySQL默认可重复读(REPEATABLE_READ),Oracle默认读已提交(READ_COMMITTED)。
- 事务隔离级别与并发问题
- 脏读:一个事务读到另一个事务未提交的数据。
- 不可重复读:一个事务内两次读取同一行数据,结果不一致(因其他事务修改并提交)。
- 幻读:一个事务内两次查询(范围)得到不同行数(因其他事务插入或删除)。
- 隔离级别从低到高:READ_UNCOMMITTED(可能脏读)→ READ_COMMITTED(避免脏读)→ REPEATABLE_READ(避免脏读、不可重复读)→ SERIALIZABLE(避免所有并发问题,但性能低)。
隔离级别详解(以MySQL InnoDB为例)
- READ_UNCOMMITTED(读未提交) 行为:最低级别,允许脏读,即可能读到未提交的数据。 问题:可能导致脏读、不可重复读、幻读。 示例:
1 2 3 4 5 6
@Transactional(isolation = Isolation.READ_UNCOMMITTED) public void readUncommittedDemo() { // 事务A:读取账户余额 BigDecimal balance = accountDao.getBalance(1L); // 此时事务B可能正在修改余额但未提交,balance可能是脏数据 }
- READ_COMMITTED(读已提交) 行为:一个事务只能读到其他事务已提交的数据,避免了脏读,但可能出现不可重复读和幻读。 问题:不可重复读(同一事务内两次读取可能不同)、幻读。 示例:
1 2 3 4 5 6 7 8 9
@Transactional(isolation = Isolation.READ_COMMITTED) public void readCommittedDemo() { // 第一次读取 BigDecimal balance1 = accountDao.getBalance(1L); // 此时事务B修改了余额并提交 // 第二次读取 BigDecimal balance2 = accountDao.getBalance(1L); // balance1 != balance2,发生不可重复读 }
- REPEATABLE_READ(可重复读) 行为:确保同一事务中多次读取同一行数据结果一致(通过行锁或MVCC),避免了脏读和不可重复读,但可能出现幻读(MySQL InnoDB通过间隙锁在一定程度上避免幻读)。 问题:可能幻读(但InnoDB在可重复读级别下使用间隙锁,基本避免了幻读)。 示例:
1 2 3 4 5 6 7 8 9
@Transactional(isolation = Isolation.REPEATABLE_READ) public void repeatableReadDemo() { // 第一次范围查询 List<Account> list1 = accountDao.findByBalanceGreaterThan(100); // 此时事务B插入一条余额大于100的记录并提交 // 第二次范围查询 List<Account> list2 = accountDao.findByBalanceGreaterThan(100); // InnoDB通过间隙锁阻止了幻读,list1和list2相同(但理论上可能不同) }
- SERIALIZABLE(可串行化) 行为:最高级别,通过强制事务串行执行,完全避免脏读、不可重复读、幻读,但并发性能最低。 示例:
1 2 3 4 5
@Transactional(isolation = Isolation.SERIALIZABLE) public void serializableDemo() { // 所有操作都会被锁定,直到事务提交 accountDao.updateBalance(1L, newBalance); }
隔离级别对比表 | 隔离级别 | 脏读 | 不可重复读 | 幻读 | 说明 | |—————–|——|————|——|——————————| | READ_UNCOMMITTED| 可能 | 可能 | 可能 | 极少使用,数据一致性差 | | READ_COMMITTED | 避免 | 可能 | 可能 | Oracle默认,大多数场景可接受 | | REPEATABLE_READ | 避免 | 避免 | 可能 | MySQL默认,InnoDB通过间隙锁避免幻读 | | SERIALIZABLE | 避免 | 避免 | 避免 | 完全串行,性能低 |
选择隔离级别的建议
- 一般情况下使用数据库默认级别(如MySQL的REPEATABLE_READ,Oracle的READ_COMMITTED)即可。
- 对一致性要求极高且并发较低的场景可考虑SERIALIZABLE。
- 通过应用层锁或乐观锁(如版本号)来替代高隔离级别,以平衡性能。
注意:隔离级别的设置依赖于底层数据库的支持,Spring只是将隔离级别传递给数据库连接,具体实现由数据库完成。
- 事务的超时属性
@Transactional(readOnly = false, timeout = -1)
所谓事务超时,就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。在 TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒,默认值为-1,这表示事务的超时时间取决于底层事务系统或者没有超时时间。 对于只有读取数据查询的事务,可以指定事务类型为 readonly,即只读事务。只读事务不涉及数据的修改,数据库会提供一些优化手段,适合用在有多条数据库查询操作的方法中。 如果你一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持 SQL 执行期间的读一致性; 如果你一次执行多条查询语句,例如统计查询,报表查询,在这种场景下,多条查询 SQL 必须保证整体的读一致性,否则,在前条 SQL 查询之后,后条 SQL 查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态,此时,应该启用事务支持
Spring事务与数据库事务的关系
Spring事务是对数据库事务的抽象和扩展。实际事务控制由底层数据库连接完成,Spring通过事务管理器协调多个数据源事务(如JTA分布式事务),但通常使用本地事务。事务的回滚规则 1:这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常(RuntimeException 的子类)时才会回滚,Error 也会导致事务回滚,但是,在遇到检查型(Checked)异常时不会回滚。 2:当
@Transactional注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。 3:如果你想要回滚你定义的特定的异常类型的话,可以这样:@Transactional(rollbackFor= MyException.class)4:被@Transactional注解的方法所在的类必须被 Spring 管理,否则不生效; 5:底层使用的数据库必须支持事务机制,否则不生效;常见问题
- 事务失效场景:方法非public、自调用、异常被捕获未抛出、数据源未配置事务管理器、传播行为配置不当等。
- 大事务问题:事务内包含耗时操作或大量数据操作,会导致长事务,引发锁竞争、连接池耗尽等问题。应尽量缩小事务范围。
- 分布式事务:跨多个数据库或服务的事务,需使用JTA、TCC、Seata等方案,Spring提供了
JtaTransactionManager支持。
【问题】 详细讲一下@Transactional注解可以吗?
【参考答案】 @Transactional是Spring框架中用于声明式事务管理的核心注解,它基于AOP实现,能够将事务管理逻辑从业务代码中分离出来,大大简化了数据库事务的开发。以下从多个维度详细介绍:
一. 作用范围
- 方法级别:最推荐的使用方式。将注解标注在具体的
public方法上,仅对该方法生效。注意:注解只能作用于public方法,否则事务不会生效(Spring代理机制限制)。 - 类级别:标注在类上,表示该类中所有
public方法都启用事务管理。此时事务属性(如传播行为、隔离级别等)对所有方法统一适用,但方法级别注解可以覆盖类级别的配置。 - 接口级别:不推荐使用。因为Spring代理默认基于接口(JDK动态代理)或类(CGLIB),但注解在接口上时,只有当使用接口代理且方法也在接口中声明时才会生效,容易产生混乱,建议避免。
二. 常用配置参数 | 参数 | 说明 | 默认值 | 示例 | |——|——|——–|——| | propagation | 事务传播行为,定义事务方法被调用时事务的创建策略 | Propagation.REQUIRED | @Transactional(propagation = Propagation.REQUIRES_NEW) | | isolation | 事务隔离级别,解决并发事务的读问题 | Isolation.DEFAULT(使用数据库默认级别) | @Transactional(isolation = Isolation.REPEATABLE_READ) | | timeout | 事务超时时间(秒),超过该时间未完成则自动回滚 | -1(无超时) | @Transactional(timeout = 30) | | readOnly | 是否为只读事务,可用于优化(如底层数据库可能跳过锁) | false | @Transactional(readOnly = true) | | rollbackFor | 指定触发回滚的异常类型,默认仅运行时异常(RuntimeException)和Error回滚 | {} | @Transactional(rollbackFor = Exception.class) | | rollbackForClassName | 同上,使用异常类名指定 | {} | @Transactional(rollbackForClassName = {"java.lang.Exception"}) | | noRollbackFor | 指定不触发回滚的异常类型 | {} | @Transactional(noRollbackFor = BusinessException.class) | | noRollbackForClassName | 同上,使用类名 | {} | @Transactional(noRollbackForClassName = {"com.example.BusinessException"}) |
三. 工作原理 @Transactional基于Spring AOP实现,核心流程如下:
- 代理对象的创建:当Spring容器启动时,会为标注了
@Transactional的类(或方法)生成代理对象。若目标类实现了接口,默认使用JDK动态代理;否则使用CGLIB生成子类代理。 - 事务拦截器:代理对象的方法调用会被
TransactionInterceptor拦截。该拦截器通过PlatformTransactionManager获取事务状态,并根据注解配置执行事务逻辑。 - 执行流程:
- 方法执行前:根据传播行为决定是开启新事务、加入现有事务还是挂起当前事务。
- 方法执行中:通过
invocation.proceed()调用目标方法。 - 方法执行后:若无异常,则提交事务;若出现异常,则根据
rollbackFor配置决定是否回滚事务。
- 事务提交/回滚:最终由具体的
PlatformTransactionManager实现(如DataSourceTransactionManager)执行数据库的提交或回滚操作。
四. 事务失效的常见场景
- 方法非
public:Spring AOP只能拦截public方法,若注解在private、protected或默认方法上,事务不生效。 - 同一类中方法调用:如A方法调用B方法(两者都在同一个类中,且B有
@Transactional),此时调用不经过代理对象,事务不生效。可通过注入自身代理(AopContext.currentProxy())或拆分类解决。 - 异常被捕获未抛出:若方法内捕获了异常且未抛出,事务拦截器无法感知异常,就不会回滚。
- 传播行为配置不当:如内层方法使用
Propagation.NOT_SUPPORTED,外层事务会被挂起,内层方法以非事务方式执行。 - 数据源未配置事务管理器:如果没有配置
PlatformTransactionManager的Bean,事务注解无效。 - 使用了不支持事务的存储引擎:如MySQL的MyISAM引擎不支持事务,即使注解也不会生效。
- 代理方式问题:如果使用JDK动态代理,但目标类没有实现接口,则无法生成代理对象,事务失效(需强制使用CGLIB)。
【大白话解释于举例说明】 可以把@Transactional想象成给一个操作贴上了“官方授权”的标签。贴上这个标签后,Spring就会像一个尽职的管家,在你执行操作前自动打开一个“工作日志”(开启事务),操作过程中如果一切顺利,就帮你在日志上盖章确认(提交事务);如果操作中出了问题(抛出异常),管家就会把日志撕掉,让你之前的所有操作都像没发生过一样(回滚事务)。
- 作用范围:你可以在一个班级(类)的所有同学(方法)上都贴标签,也可以只给某个同学贴。但注意,只有公开课(public方法)才需要管家服务,私下小动作(非public)管家看不到。
- 配置参数:就像你可以给管家指定不同的服务细则。比如:
propagation:告诉管家遇到别人已经在记账时,是加入别人的账本(REQUIRED),还是另开一个新账本(REQUIRES_NEW)。isolation:告诉管家记账时要注意隐私,防止别人偷看未完成的内容(隔离级别)。timeout:规定这个账必须在30分钟内记完,超时就不记了。rollbackFor:指定什么类型的错误必须撕账本,比如遇到“金额错误”这种严重问题必须回滚,而“备注写错”这种小问题可以忽略。
- 失效场景:
- 如果同一个班里的小明(方法)在班里内部偷偷叫小红帮忙(自调用),没有经过管家,那么小红的事务标签就失效了。
- 如果小明在记账过程中自己把错误掩盖了(捕获异常没抛出),管家不知道出了问题,就不会回滚。
【扩展知识点详解】
@Transactional的底层依赖- Spring事务抽象的核心接口:
PlatformTransactionManager、TransactionDefinition、TransactionStatus。 @Transactional本质是TransactionDefinition的一种声明式表达,通过TransactionInterceptor将其转化为事务操作。
- Spring事务抽象的核心接口:
- 不同事务管理器的选择
DataSourceTransactionManager:适用于单数据源的JDBC、MyBatis等。HibernateTransactionManager:适用于Hibernate。JpaTransactionManager:适用于JPA。JtaTransactionManager:适用于分布式事务(JTA)。
Spring Boot会根据依赖自动配置合适的事务管理器。
事务传播行为的源码解析
Propagation枚举定义了7种行为,在AbstractPlatformTransactionManager的handleExistingTransaction等方法中处理。例如REQUIRES_NEW会挂起当前事务,创建新事务,提交或回滚后恢复原事务。隔离级别的实现依赖
Spring只是将隔离级别传递给数据库连接,最终由数据库的锁机制和MVCC实现。例如MySQL的REPEATABLE_READ通过间隙锁防止幻读,而Oracle的READ_COMMITTED通过快照读避免脏读。只读事务的优化
readOnly=true会向底层数据库传递只读提示,某些数据库(如MySQL InnoDB)可以优化查询,避免加锁。但注意,如果实际执行了写操作,数据库会抛出异常。回滚规则的详细逻辑
默认情况下,事务只在遇到运行时异常(RuntimeException)和Error时回滚,而受检异常(如IOException)不会触发回滚。这是因为受检异常通常代表可预期的业务问题,而非系统级错误。可通过rollbackFor强制指定回滚。@Transactional的自调用失效解决方案- 方法一:通过
ApplicationContext.getBean()获取自身代理,再调用方法。 - 方法二:使用
AopContext.currentProxy()(需配置exposeProxy=true)。 - 方法三:将事务方法拆分到另一个Service类中,通过依赖注入调用。
- 方法一:通过
事务的嵌套与保存点
Propagation.NESTED使用数据库保存点(savepoint)实现部分回滚。当事务回滚到保存点时,仅撤销保存点后的操作,外层事务仍可继续。注意:需要底层数据库支持保存点(如MySQL InnoDB)。Spring事务与多线程
事务是与线程绑定的(通过ThreadLocal实现),因此在多线程环境下,子线程中的操作默认不在父线程的事务中。可通过编程式事务或手动传递事务上下文实现。测试中的事务行为
Spring测试框架提供了@Transactional注解(在spring-test中),用于测试方法的事务回滚,默认测试完成后回滚,避免污染数据库。- 常见误区
- 误区:
@Transactional可以保证所有数据库操作都在一个事务中。实际上,如果涉及多个数据源,需要使用分布式事务。 - 误区:方法内调用其他
@Transactional方法一定会加入同一事务。取决于传播行为,REQUIRES_NEW会新建独立事务。 - 误区:
readOnly=true一定能提高性能。对于某些数据库,可能没有实际优化效果,甚至增加额外开销。
- 误区:
- 最佳实践
- 在Service层的方法上使用
@Transactional,而非DAO层。 - 尽量缩小事务范围,避免在事务中执行远程调用、IO操作等耗时任务。
- 合理设置
rollbackFor,确保预期异常也能触发回滚。 - 对于仅查询的方法,可设置
readOnly=true,但需确认实际效果。
- 在Service层的方法上使用
springmvc
【问题】 Spring MVC的作用是什么?优点有哪些?工作流程是什么?主要组件有哪些?
【参考答案】 Spring MVC是Spring框架基于Servlet API构建的Web层框架,它实现了经典的Model-View-Controller(MVC)设计模式,旨在简化Web应用程序的开发,提供高度灵活、可扩展的架构。
一、Spring MVC的作用 Spring MVC的主要作用是将Web层进行职责分离,通过将输入逻辑、业务逻辑和显示逻辑解耦,使应用程序更易于开发和维护。它作为前端控制器(DispatcherServlet)接收所有请求,协调不同的组件处理请求并生成响应,从而简化了基于Java的Web开发。
二、Spring MVC的优点
- 角色清晰:框架明确了控制器、验证器、命令对象、模型对象、分发器、处理器映射、视图解析器等角色的职责,便于开发人员理解和分工。
- 与Spring无缝集成:作为Spring家族的一部分,可以直接利用Spring的IoC容器、AOP、事务管理等特性,实现依赖注入和横切关注点的统一管理。
- 灵活的URL映射:通过注解(如
@RequestMapping及其派生注解)或XML配置,可以灵活地将URL映射到控制器方法,支持RESTful风格。 - 强大的数据绑定与验证:支持将HTTP请求参数自动绑定到Java对象的属性,并与JSR-303/JSR-380 Bean Validation集成,简化了数据校验。
- 多种视图技术支持:可与JSP、Thymeleaf、FreeMarker、Velocity等视图技术无缝集成,同时支持JSON、XML等数据格式输出。
- 开箱即用的功能:内置文件上传、国际化、主题解析、异常处理等功能,减少重复开发。
- 测试友好:框架组件可轻松进行单元测试,例如通过
MockMvc模拟HTTP请求测试控制器。 - 高度可扩展:通过实现
HandlerMapping、HandlerAdapter、ViewResolver等接口,可自定义扩展框架行为。
三、工作流程(执行步骤) Spring MVC处理请求的典型流程如下(以传统Servlet容器为例):
- 客户端发送请求:用户通过浏览器或客户端发送HTTP请求,请求到达
DispatcherServlet(前端控制器)。 - 查找处理器:
DispatcherServlet根据请求信息(URL、HTTP方法等)调用HandlerMapping(处理器映射器),找到匹配的处理器(Handler)和拦截器链。处理器通常是一个控制器(Controller)的方法。 - 调用处理器:
DispatcherServlet通过HandlerAdapter(处理器适配器)执行处理器方法。HandlerAdapter负责适配不同类型的处理器(如基于注解的@Controller方法、实现Controller接口的旧式控制器等)。 - 执行处理器方法:控制器方法执行业务逻辑,处理请求参数,调用服务层,最后返回一个
ModelAndView对象(包含模型数据和视图名)。 - 视图解析:
DispatcherServlet将ModelAndView对象交给ViewResolver(视图解析器),根据视图名解析出具体的View对象。 - 视图渲染:
View对象负责将模型数据填充到视图中,生成最终的响应内容(如HTML、JSON等)。 - 返回响应:
DispatcherServlet将渲染后的结果通过HTTP响应返回给客户端。
注:如果控制器方法直接返回@ResponseBody或ResponseEntity,则跳过视图解析步骤,由HandlerAdapter直接将结果写入响应体。
四、主要组件及其作用 | 组件 | 作用 | 说明/常见实现 | |——|——|—————| | DispatcherServlet | 前端控制器,Spring MVC的核心。负责接收所有请求,协调其他组件完成请求处理。 | 配置在web.xml或通过Servlet 3.0+初始化,是框架的入口。 | | HandlerMapping | 处理器映射器,根据请求查找对应的处理器(Handler)和拦截器链。 | 常见实现:RequestMappingHandlerMapping(基于注解)、SimpleUrlHandlerMapping(基于URL配置)。 | | HandlerAdapter | 处理器适配器,帮助DispatcherServlet调用不同类型的处理器,屏蔽具体处理器的差异。 | 常见实现:RequestMappingHandlerAdapter(处理@RequestMapping方法)、HttpRequestHandlerAdapter(处理HttpRequestHandler)、SimpleControllerHandlerAdapter(处理旧式Controller接口)。 | | Controller | 处理器,也称页面控制器,包含具体的业务逻辑。负责处理请求,返回ModelAndView或直接写入响应。 | 通常使用@Controller注解标识,方法上使用@RequestMapping等注解映射URL。 | | ViewResolver | 视图解析器,根据逻辑视图名解析出具体的View对象。 | 常见实现:InternalResourceViewResolver(解析JSP)、ThymeleafViewResolver、BeanNameViewResolver等。 | | View | 视图,负责渲染模型数据,生成最终输出(HTML、JSON等)。 | 常见实现:JstlView、ThymeleafView、MappingJackson2JsonView等。 | | HandlerInterceptor | 处理器拦截器(非必需),允许在请求处理前后进行自定义处理(如登录检查、日志记录)。 | 实现HandlerInterceptor接口,在HandlerMapping中配置。 | | MultipartResolver | 文件上传解析器,处理multipart/form-data类型的请求。 | 常见实现:CommonsMultipartResolver(基于Apache Commons FileUpload)、StandardServletMultipartResolver(基于Servlet 3.0+)。 | | LocaleResolver | 国际化解析器,解析客户端的区域信息,用于国际化。 | 常见实现:AcceptHeaderLocaleResolver、SessionLocaleResolver等。 | | ThemeResolver | 主题解析器,支持主题切换功能。 | 较少使用,如CookieThemeResolver。 | | HandlerExceptionResolver | 异常解析器,统一处理控制器抛出的异常。 | 常见实现:ExceptionHandlerExceptionResolver(支持@ExceptionHandler)、DefaultHandlerExceptionResolver等。 |
【大白话解释于举例说明】 可以把Spring MVC比作一家餐厅的运作流程:
- DispatcherServlet:餐厅的前台接待员。所有客人(请求)进门先找他,他负责安排后续服务。
- HandlerMapping:点餐牌(菜单),接待员根据客人点的菜名(URL)找到对应的厨师(控制器)。
- HandlerAdapter:厨房的传菜员,他负责把客人订单(请求)交给厨师,并把做好的菜(模型数据)取回来。
- Controller:厨师,根据订单做菜(执行业务逻辑),做好后放在托盘(
ModelAndView)上。 - ViewResolver:摆盘员,根据厨师说的“用盘子A装菜”(逻辑视图名),找到具体的盘子(视图)。
- View:盘子,负责把菜(模型数据)摆好,呈现给客人。
- HandlerInterceptor:餐厅的监控摄像头,在客人点菜前后记录日志、检查会员权限等。
整个流程:客人(请求)→ 前台接待(DispatcherServlet)→ 看菜单(HandlerMapping)→ 传菜员(HandlerAdapter)→ 厨师(Controller)做菜 → 摆盘员(ViewResolver)找盘子 → 盘子(View)装盘 → 前台把菜端给客人(响应)。
【扩展知识点详解】
DispatcherServlet的初始化
Spring MVC在Web容器启动时,通过DispatcherServlet的init()方法初始化WebApplicationContext,并扫描配置或注解装配所有组件(如HandlerMapping、HandlerAdapter等)。Spring Boot则通过自动配置完成。请求处理链中的拦截器
HandlerInterceptor的preHandle()在处理器方法执行前调用,postHandle()在处理器方法执行后、视图渲染前调用,afterCompletion()在整个请求完成后调用(通常用于资源清理)。多个拦截器按配置顺序形成链式调用。基于注解的控制器
使用@Controller和@RequestMapping(及其派生注解)简化开发。@RestController是@Controller和@ResponseBody的组合,用于RESTful服务。数据绑定与类型转换
Spring MVC通过DataBinder将请求参数绑定到JavaBean,并支持自定义PropertyEditor或Converter进行类型转换。@InitBinder可在控制器中自定义数据绑定器。验证机制
配合JSR-303/380 Bean Validation,在控制器方法参数上使用@Valid或@Validated触发验证,验证结果通过BindingResult或Errors对象获取,或抛出异常统一处理。- 异常处理
- 使用
@ExceptionHandler在控制器内部处理特定异常。 - 使用
@ControllerAdvice或@RestControllerAdvice实现全局异常处理。 - 实现
HandlerExceptionResolver自定义异常解析器。
- 使用
RESTful支持
@ResponseBody将返回值直接写入响应体,@RequestBody将请求体转换为对象。ResponseEntity允许设置响应状态码和头信息。异步处理
Spring MVC 3.2+支持基于Callable和DeferredResult的异步请求处理,提高服务器吞吐量。Spring MVC与Spring Boot
Spring Boot通过spring-boot-starter-web自动配置DispatcherServlet、内置Tomcat、提供默认的视图解析器等,简化了部署和配置。- 常用配置
- 在XML中配置:
<mvc:annotation-driven/>启用注解驱动。 - 在Java配置中:
@EnableWebMvc启用Spring MVC配置,配合实现WebMvcConfigurer自定义。
- 在XML中配置:
【问题】 SpringMVC怎么样设定重定向和转发的?SpringMvc怎么和AJAX相互调用的?
【参考答案】 (1)转发:在返回值前面加”forward:”,譬如”forward:user.do?name=method4” (2)重定向:在返回值前面加”redirect:”,譬如”redirect:http://www.baidu.com” 通过Jackson框架就可以把Java里面的对象直接转化成Js可以识别的Json对象 (1)加入Jackson.jar (2)在配置文件中配置json的映射 (3)在接受Ajax方法里面可以直接返回Object,List等,但方法前面要加上@ResponseBody注解。
【问题】 Spring MVC常用的注解有哪些?怎么用?
【参考答案】 Spring MVC提供了一系列注解,用于简化Web层开发,实现请求映射、参数绑定、数据校验、异常处理等功能。以下是常用注解的分类详解及使用示例:
一、控制器声明注解 | 注解 | 作用 | 用法示例 | |——|——|———-| | @Controller | 标记类为Spring MVC的控制器,负责处理HTTP请求。 | @Controller public class UserController { ... } | | @RestController | @Controller和@ResponseBody的组合,类中所有方法默认返回JSON/XML,不进行视图解析。 | @RestController public class UserController { ... } | | @RequestMapping | 映射HTTP请求到控制器方法,可配置URL、请求方法、参数等。可标注在类或方法上。 | @RequestMapping("/users") public class UserController { @RequestMapping(value = "/{id}", method = RequestMethod.GET) public User get(@PathVariable Long id) { ... } } |
二、请求映射注解(@RequestMapping的派生注解,通常用于方法) | 注解 | 作用 | 用法示例 | |——|——|———-| | @GetMapping | 处理GET请求,等价于@RequestMapping(method = RequestMethod.GET) | @GetMapping("/{id}") public User get(@PathVariable Long id) { ... } | | @PostMapping | 处理POST请求 | @PostMapping public User create(@RequestBody User user) { ... } | | @PutMapping | 处理PUT请求 | @PutMapping("/{id}") public User update(@PathVariable Long id, @RequestBody User user) { ... } | | @DeleteMapping | 处理DELETE请求 | @DeleteMapping("/{id}") public void delete(@PathVariable Long id) { ... } | | @PatchMapping | 处理PATCH请求 | @PatchMapping("/{id}") public User partialUpdate(@PathVariable Long id, @RequestBody Map<String, Object> updates) { ... } |
三、参数绑定注解 | 注解 | 作用 | 用法示例 | |——|——|———-| | @PathVariable | 从URL路径模板中获取变量值。 | @GetMapping("/users/{id}") public User get(@PathVariable("id") Long userId) { ... } | | @RequestParam | 获取请求参数(查询参数或表单参数),支持默认值、必需等属性。 | @GetMapping("/users") public List<User> list(@RequestParam(value = "page", defaultValue = "1") int page) { ... } | | @RequestBody | 将HTTP请求体(JSON/XML等)绑定到方法参数,通常用于POST/PUT请求。 | @PostMapping("/users") public User create(@RequestBody @Valid User user) { ... } | | @RequestHeader | 获取请求头中的某个值。 | @GetMapping("/header") public String getHeader(@RequestHeader("User-Agent") String userAgent) { ... } | | @CookieValue | 获取Cookie中的值。 | @GetMapping("/cookie") public String getCookie(@CookieValue("JSESSIONID") String sessionId) { ... } | | @ModelAttribute | 用于将请求参数绑定到模型对象,或向模型添加数据。有三种使用方式:
1. 在方法参数上:将请求参数绑定到该对象,并自动添加到模型。
2. 在方法上:该方法会在控制器每个请求方法执行前调用,返回值添加到模型。
3. 在方法上且无返回值,但参数包含Model:手动添加属性。 | @PostMapping("/users") public String create(@ModelAttribute User user) { ... }@ModelAttribute("commonData") public String populateCommon() { return "commonValue"; } | | @SessionAttributes | 将模型中的指定属性存储到HTTP Session中,用于跨请求共享数据(如表单步骤)。需标注在类上。 | @Controller @SessionAttributes("user") public class UserController { ... } | | @RequestPart | 用于处理multipart/form-data请求中的文件上传部分,与@RequestParam类似但更适用于文件。 | @PostMapping("/upload") public String handleUpload(@RequestPart("file") MultipartFile file) { ... } |
四、响应相关注解 | 注解 | 作用 | 用法示例 | |——|——|———-| | @ResponseBody | 将方法返回值直接写入HTTP响应体(JSON/XML等),不进行视图解析。可标注在方法或类上(配合@Controller)。 | @GetMapping("/users/{id}") @ResponseBody public User get(@PathVariable Long id) { ... } | | @ResponseStatus | 设置HTTP响应的状态码,可标注在方法或异常类上。 | @ResponseStatus(HttpStatus.CREATED) @PostMapping public User create(@RequestBody User user) { ... } |
五、数据校验注解(与JSR-303/380结合) | 注解 | 作用 | 用法示例 | |——|——|———-| | @Valid | 激活对方法参数的校验,通常与@RequestBody或@ModelAttribute配合。校验失败抛出MethodArgumentNotValidException。 | @PostMapping("/users") public User create(@Valid @RequestBody User user, BindingResult result) { ... } | | @Validated | Spring对@Valid的扩展,支持分组校验。可标注在类或方法参数上。 | @PostMapping("/users") public User create(@Validated(GroupA.class) @RequestBody User user) { ... } |
六、异常处理与增强注解 | 注解 | 作用 | 用法示例 | |——|——|———-| | @ControllerAdvice | 全局控制器增强,可定义全局的@ExceptionHandler、@InitBinder、@ModelAttribute方法。 | @ControllerAdvice public class GlobalExceptionHandler { @ExceptionHandler(Exception.class) public ResponseEntity<String> handle(Exception e) { ... } } | | @RestControllerAdvice | @ControllerAdvice和@ResponseBody的组合,用于REST API的全局异常处理。 | @RestControllerAdvice public class GlobalRestExceptionHandler { @ExceptionHandler(ResourceNotFoundException.class) @ResponseStatus(HttpStatus.NOT_FOUND) public ErrorResponse handle(ResourceNotFoundException e) { ... } } | | @ExceptionHandler | 处理控制器中特定异常的方法,可定义在控制器内或全局@ControllerAdvice中。 | @ExceptionHandler(ResourceNotFoundException.class) public ResponseEntity<String> handleNotFound(ResourceNotFoundException e) { ... } | | @InitBinder | 在控制器中自定义数据绑定器,用于注册自定义PropertyEditor或格式化器。 | @InitBinder public void initBinder(WebDataBinder binder) { binder.registerCustomEditor(Date.class, new CustomDateEditor(new SimpleDateFormat("yyyy-MM-dd"), true)); } |
七、其他注解 | 注解 | 作用 | 用法示例 | |——|——|———-| | @CrossOrigin | 启用跨域资源共享(CORS),可标注在类或方法上。 | @CrossOrigin(origins = "http://example.com") @GetMapping("/users") public List<User> list() { ... } | | @MatrixVariable | 从URL矩阵变量中获取值(较少使用)。 | @GetMapping("/cars/{path}") public String get(@MatrixVariable(name = "color", pathVar = "path") String color) { ... } |
示例场景:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
@RestController // 外卖员模式
@RequestMapping("/api/users")
public class UserController {
@GetMapping("/{id}") // GET请求,路径参数
public User getUser(@PathVariable Long id) {
return userService.findById(id);
}
@PostMapping
public User createUser(@Valid @RequestBody User user) { // 请求体绑定并校验
return userService.save(user);
}
@ExceptionHandler(ResourceNotFoundException.class) // 本店处理特定异常
@ResponseStatus(HttpStatus.NOT_FOUND)
public ErrorResponse handleNotFound(ResourceNotFoundException e) {
return new ErrorResponse(e.getMessage());
}
}
@ControllerAdvice // 全局助手
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public ResponseEntity<String> handleGeneric(Exception e) {
return ResponseEntity.status(500).body("系统繁忙,请稍后重试");
}
}
【扩展知识点详解】
@RequestMapping的常用属性value/path:映射的URL路径。method:允许的HTTP方法,如RequestMethod.GET。params:限制请求必须包含某些参数,如params = "myParam=myValue"。headers:限制请求头。consumes:限制请求的Content-Type,如consumes = "application/json"。produces:限制响应的Content-Type,如produces = "application/json"。
@RequestParam的常用属性value/name:参数名称。required:是否必需,默认true。defaultValue:默认值(当参数缺失或值为空时使用)。
@PathVariable的常用属性value/name:路径变量名称。required:是否必需,默认true(路径变量通常必需)。
@RequestBody与@ResponseBody的底层
通过HttpMessageConverter实现,Spring会根据请求的Content-Type和响应的Accept头自动选择转换器(如MappingJackson2HttpMessageConverter处理JSON)。- 数据绑定与校验流程
- 使用
@Valid或@Validated标记参数,Spring会调用Validator进行校验。 - 如果参数后紧跟
BindingResult或Errors参数,则校验结果放入该对象,不会抛出异常;否则校验失败抛出异常。 - 可结合分组校验(
@Validated的groups属性)在不同场景使用不同校验规则。
- 使用
@ModelAttribute的详细用法- 作为方法参数:将请求参数绑定到该对象,并自动添加到模型中,相当于
new User()+ 属性绑定 +model.addAttribute(user)。 - 作为方法级注解:该方法在控制器每个
@RequestMapping方法执行前调用,返回值放入模型(可指定key)。常用于准备下拉列表数据等。
- 作为方法参数:将请求参数绑定到该对象,并自动添加到模型中,相当于
@SessionAttributes的使用注意事项- 必须与
@ModelAttribute配合使用,将模型中的属性提升到Session中。 - 清除Session数据可使用
SessionStatus.setComplete()。 - 注意线程安全问题,Session中的属性可能被多个请求共享。
- 必须与
@InitBinder的用途- 自定义数据绑定,例如注册日期格式、禁止绑定某些字段(
setDisallowedFields)。 - 在每个控制器方法执行前调用,仅对当前控制器生效。全局化可通过
@ControllerAdvice中的@InitBinder实现。
- 自定义数据绑定,例如注册日期格式、禁止绑定某些字段(
@ControllerAdvice的高级用法- 可指定
annotations、basePackages、assignableTypes等属性限定增强的范围。 - 除了异常处理,还可包含
@ModelAttribute(全局模型数据)、@InitBinder(全局数据绑定)方法。
- 可指定
- RESTful与注解组合
Spring推荐使用@RestController和映射注解组合,如:1 2 3 4 5 6 7 8 9 10
@RestController @RequestMapping("/api/users") public class UserController { @GetMapping("/{id}") public User get(@PathVariable Long id) { ... } @PostMapping @ResponseStatus(HttpStatus.CREATED) public User post(@RequestBody User user) { ... } }
跨域注解
@CrossOrigin
可配置origins(允许的域)、methods(允许的方法)、allowedHeaders、allowCredentials等,用于解决CORS问题。- Spring Boot中的自动配置
Spring Boot通过spring-boot-starter-web自动注册了RequestMappingHandlerMapping、RequestMappingHandlerAdapter等,无需额外配置即可使用这些注解。
【问题】 Spring MVC中函数的返回值是什么?怎么样把ModelMap里面的数据放入Session里面?
【参考答案】 一、Spring MVC中控制器方法的返回值类型 Spring MVC支持多种返回值类型,以适应不同的业务场景。常见的有:
String类型- 返回逻辑视图名,由
ViewResolver解析为实际视图。 - 可以添加
redirect:或forward:前缀实现重定向或转发,例如"redirect:/user/list"。 - 配合
Model参数传递数据到视图。
- 返回逻辑视图名,由
ModelAndView类型- 封装了视图名和模型数据,可手动添加模型属性,并指定视图。
- 适用于需要同时设置视图和数据且不想使用Model参数的情况。
void类型- 方法可通过
HttpServletResponse直接输出响应内容(如response.getWriter().write()),或配合@ResponseStatus设置状态码。 - 如果方法返回
void且没有写入响应,通常视图解析器会根据请求URL推断视图名(默认的RequestToViewNameTranslator)。
- 方法可通过
Model、Map、ModelMap类型- 这些类型作为方法参数时,可以在方法体内添加数据,它们会暴露给视图,此时方法返回值通常为
String逻辑视图名。
- 这些类型作为方法参数时,可以在方法体内添加数据,它们会暴露给视图,此时方法返回值通常为
HttpEntity/ResponseEntity类型- 可完全控制HTTP响应(包括状态码、头信息、响应体)。例如返回
ResponseEntity<User>。
- 可完全控制HTTP响应(包括状态码、头信息、响应体)。例如返回
- 标注了
@ResponseBody的方法- 返回值直接作为HTTP响应体,通过
HttpMessageConverter转换为JSON/XML等格式。支持任意Java类型(如User、List、Map等)。
- 返回值直接作为HTTP响应体,通过
Callable、DeferredResult、WebAsyncTask等异步类型- 用于异步请求处理,提升服务器吞吐量。
- 其他类型
View对象:直接返回View实现。ModelAndViewResolver等自定义类型。
二、如何将ModelMap中的数据放入Session Spring MVC提供了@SessionAttributes注解,用于将模型(Model)中的指定属性自动存储到HTTP Session中,从而实现跨请求的数据共享。具体步骤:
- 在控制器类上标注
@SessionAttributes1 2 3 4 5
@Controller @SessionAttributes("user") // 指定需要存入Session的模型属性名 public class UserController { // ... }
可以指定多个属性名:
@SessionAttributes({"user", "address"})。 - 在处理方法中添加同名模型属性
通过Model、ModelMap或@ModelAttribute向模型中添加与@SessionAttributes同名的属性时,该属性会自动同步到Session中。1 2 3 4 5
@GetMapping("/login") public String login(User user, Model model) { model.addAttribute("user", user); // 该属性会被自动存入Session return "home"; }
- 在后续请求中从Session获取数据
可以使用@SessionAttribute注解从Session中获取属性,或通过HttpSession手动获取。1 2 3 4 5
@GetMapping("/profile") public String profile(@SessionAttribute("user") User user) { // 使用Session中的user对象 return "profile"; }
- 清除Session中的属性
如果需要手动移除Session中的属性,可以使用SessionStatus的setComplete()方法,或在HttpSession上调用removeAttribute。1 2 3 4 5
@GetMapping("/logout") public String logout(SessionStatus status) { status.setComplete(); // 清除当前控制器管理的所有@SessionAttributes属性 return "redirect:/login"; }
注意:@SessionAttributes通常用于在多个请求之间保持临时数据(如表单步骤、向导模式),而不是替代业务层面的Session管理。另外,它会将数据同时存储在Model和Session中,需注意线程安全和数据一致性。
【大白话解释于举例说明】
- 返回值类型比喻:
控制器方法就像厨师做菜,返回值告诉服务员(Spring MVC)如何把菜端给客人。- 返回
String:厨师说“按菜单名‘鱼香肉丝’去装盘”,服务员根据菜单名找盘子。 - 返回
ModelAndView:厨师直接把菜和盘子一起交给服务员。 - 返回
void:厨师自己直接把菜端给客人(通过HttpServletResponse)。 - 标注
@ResponseBody:厨师把菜直接打包成外卖盒(JSON)递给客人,不用盘子。
- 返回
- ModelMap放入Session:
想象你在餐厅点了一份套餐,但套餐分量太大一次吃不完,你想把剩下的寄存在餐厅(Session)下次来再吃。@SessionAttributes就像你告诉服务员:“这道菜(属性名)我还没吃完,帮我存起来。”之后每次来,服务员都会自动帮你把存的菜端出来。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
@Controller
@SessionAttributes("cart") // 告诉Spring,购物车数据要存Session
public class CartController {
@GetMapping("/add")
public String addItem(Item item, Model model) {
List<Item> cart = (List<Item>) model.getAttribute("cart");
if (cart == null) {
cart = new ArrayList<>();
}
cart.add(item);
model.addAttribute("cart", cart); // 存入Model,同时自动同步到Session
return "cartView";
}
@GetMapping("/checkout")
public String checkout(@SessionAttribute("cart") List<Item> cart) { // 从Session获取
// 处理结算
return "checkout";
}
@GetMapping("/clear")
public String clear(SessionStatus status) {
status.setComplete(); // 清空Session中的cart
return "redirect:/cart";
}
}
【扩展知识点详解】
@SessionAttributes的原理
Spring MVC通过SessionAttributesHandler管理标注的属性。当请求处理方法向Model中添加同名属性时,Model的addAttribute操作会被拦截,同时调用HttpSession.setAttribute()。这些属性在Model和Session中保持同步,直到调用SessionStatus.setComplete()清除。@SessionAttributes的注意事项- 只对当前控制器有效,不会影响其他控制器。
- 可能导致数据在多个请求间意外共享,需注意并发修改。
- 通常用于短生命周期的会话数据(如表单填写步骤),而不是长期用户会话(如登录用户信息应通过
HttpSession直接管理)。 - 使用
setComplete()只会清除当前控制器管理的@SessionAttributes属性,不会清除Session中其他属性。
- 其他从Session获取数据的方式
- 使用
@SessionAttribute注解在方法参数上获取特定属性(与@RequestParam类似)。 - 直接注入
HttpSession对象,调用getAttribute()。 - 在JSP中通过
${sessionScope.attributeName}访问。
- 使用
- 返回值类型的详细说明
- String:配合
Model参数使用,是最常见的方式。 - ModelAndView:适合在旧式控制器或需要同时设置视图和数据时使用。
- void:通常用于直接输出响应(如下载文件)或异步处理。
- ResponseEntity:可精细控制响应,如返回
ResponseEntity.ok().header("Custom", "value").body(data)。 @ResponseBody:常用于REST API,返回JSON/XML,可结合HttpEntity作为参数获取请求体。- 异步返回值:
Callable在独立线程中执行,DeferredResult允许从其他线程异步设置结果。
- String:配合
视图解析器与返回值
返回String或ModelAndView时,视图解析器根据配置(如InternalResourceViewResolver)将逻辑视图名转换为物理视图路径。若返回void且没有显式写入响应,默认视图名由RequestToViewNameTranslator根据请求URL生成。- @ModelAttribute的变体
- 作为方法参数:将请求参数绑定到对象,并自动加入
Model。 - 作为方法级注解:在控制器每个请求方法前执行,返回值放入
Model,常用于准备公共数据。
如果方法级@ModelAttribute返回的对象与@SessionAttributes同名,也会存入Session。
- 作为方法参数:将请求参数绑定到对象,并自动加入
Session属性的清除时机
除了手动调用SessionStatus.setComplete(),还可以通过HttpSession.invalidate()使整个会话失效,但需注意影响范围。- 与Spring Session的集成
Spring Session提供了集群环境下Session管理的解决方案,可透明地将Session存储到Redis等外部存储,与@SessionAttributes不冲突,但需注意序列化问题。
【问题】 Spring MVC中过滤器和拦截器的区别是什么?联系是什么?什么时候用过滤器什么时候用拦截器?执行顺序是怎样的?
【参考答案】 一、过滤器(Filter)和拦截器(Interceptor)的概念
- 过滤器:是Java Servlet规范中的一部分,基于函数回调(doFilter方法),可以对请求和响应进行预处理和后处理。过滤器可以拦截任何Web资源(包括Servlet、JSP、静态资源等),在请求到达Servlet之前和响应离开Servlet之后执行。
- 拦截器:是Spring MVC框架提供的组件,基于Java反射和AOP机制,通过实现
HandlerInterceptor接口来拦截对处理器(Controller方法)的调用。拦截器仅在请求进入DispatcherServlet后、到达Controller之前,以及Controller执行后、视图渲染前等时机执行,可以获取处理器方法的信息。
二、两者的联系
- 两者都实现了对请求的拦截,可以用于实现横切关注点(如日志、权限检查、性能监控等),且都支持链式调用。
- 在Spring MVC应用中,过滤器先于拦截器执行,共同完成请求的处理。
三、两者的主要区别 | 区别点 | 过滤器(Filter) | 拦截器(Interceptor) | |——–|——————|————————| | 规范归属 | Servlet规范,与Spring无关 | Spring框架规范,依赖Spring容器 | | 作用范围 | 可拦截所有Web资源(包括静态资源、JSP、Servlet等) | 仅拦截Spring MVC的控制器请求(即经过DispatcherServlet的请求) | | 细粒度 | 基于请求和响应对象,无法获取具体处理器方法的信息 | 可以获取处理器方法(HandlerMethod)的信息,如方法名、参数等 | | 执行时机 | 在请求进入Servlet容器后、进入Servlet之前执行,以及在Servlet处理后、响应返回前执行 | 在请求进入DispatcherServlet后、进入Controller之前,Controller之后、视图渲染之前,以及整个请求完成后执行 | | 依赖容器 | 依赖于Servlet容器,无法直接注入Spring Bean(但可通过特殊方式获取) | 依赖于Spring容器,可以方便地注入Spring Bean | | 配置方式 | 在web.xml中配置或通过@WebFilter注解(需Servlet 3.0+) | 实现HandlerInterceptor接口,并在Spring配置中注册(如WebMvcConfigurer) | | 使用场景 | 适用于全局性的、与业务无关的操作,如字符编码设置、跨域处理、请求日志记录、XSS/SQL注入防护等 | 适用于与业务相关的、需要获取处理器方法信息的操作,如权限验证、性能监控、日志记录(记录具体方法)、多语言处理等 |
四、使用场景选择
- 使用过滤器:当你需要处理所有请求(包括静态资源),或者操作与Spring无关时,例如设置请求编码、压缩响应内容、添加通用响应头、防止缓存等。
- 使用拦截器:当你需要针对Spring MVC的控制器方法进行精细化处理,例如判断用户是否登录(需获取请求的URL对应的方法权限)、记录方法执行时间、在方法执行前后添加公共数据等。
五、执行顺序
- 过滤器链执行(按配置顺序):
- 请求到达时,依次执行所有过滤器的
doFilter方法中chain.doFilter之前的代码(前置处理)。 - 调用
chain.doFilter将请求传递给下一个过滤器或目标资源(Servlet)。
- 请求到达时,依次执行所有过滤器的
- 拦截器链执行(按注册顺序):
- 进入
DispatcherServlet后,按注册顺序执行所有拦截器的preHandle方法。 - 若某个
preHandle返回false,则中断请求,后续拦截器及控制器不再执行,但已执行的拦截器的afterCompletion方法会逆序调用。 - 控制器方法执行后,按注册逆序执行拦截器的
postHandle方法(在视图渲染前)。 - 视图渲染后,按注册逆序执行拦截器的
afterCompletion方法(在整个请求完成之后,可用于资源清理)。
- 进入
- 过滤器后置处理:
- 请求处理完成后(包括视图渲染),响应会沿着过滤器链反向传递,执行
doFilter方法中chain.doFilter之后的代码(后置处理)。
- 请求处理完成后(包括视图渲染),响应会沿着过滤器链反向传递,执行
总结:请求执行顺序为:过滤器前置 → 拦截器前置 → 控制器 → 拦截器后置 → 视图渲染 → 拦截器完成 → 过滤器后置。
【大白话解释于举例说明】
- 过滤器好比小区大门:无论你是业主(动态请求)还是外卖员(静态资源),进小区都要先经过大门。大门可以检查健康码(编码设置)、登记信息(日志),然后放行。出小区时也可能检查。
- 拦截器好比单元门禁:只有业主(经过DispatcherServlet的请求)才会走到单元门口。门禁可以识别你是谁(权限验证),记录你进入和离开的时间(性能监控),甚至在你进门前提醒你带钥匙(前置处理),出门后关门(后置处理)。
例子:假设一个网站需要记录所有请求的日志(包括图片等静态资源),同时需要对每个控制器方法进行权限检查。
- 过滤器可以用来记录请求URL、IP、耗时(因为所有请求都会经过)。
- 拦截器可以用来检查用户是否有权限访问某个具体方法,因为拦截器能知道请求的是哪个方法,以及方法的注解信息。
【扩展知识点详解】
- 过滤器的核心接口与方法
- 实现
javax.servlet.Filter接口,重写init()、doFilter()、destroy()方法。 - 在
doFilter中通过FilterChain调用下一个过滤器或目标资源。
- 实现
- 拦截器的核心接口与方法
- 实现
org.springframework.web.servlet.HandlerInterceptor接口,重写preHandle()、postHandle()、afterCompletion()方法。 preHandle返回true则继续执行,返回false则中断请求。
- 实现
拦截器的注册
通过实现WebMvcConfigurer接口并重写addInterceptors方法,添加自定义拦截器实例,并可指定拦截路径(addPathPatterns)和排除路径(excludePathPatterns)。过滤器与拦截器的混合使用
在Spring Boot应用中,可以通过@WebFilter和@ServletComponentScan注册过滤器,也可以通过FilterRegistrationBean注册。拦截器则通过@Configuration类配置。过滤器获取Spring Bean
过滤器本身不受Spring管理,但可以通过@Autowired注入(需将过滤器声明为Spring Bean,并使用DelegatingFilterProxy代理)或从WebApplicationContext中手动获取。- 拦截器的执行细节
postHandle在视图渲染前执行,可以修改ModelAndView。afterCompletion在视图渲染后执行,可以用于清理资源、记录最终异常等。
性能考虑
过滤器在Servlet容器层面执行,适合全局性操作;拦截器在Spring MVC内部执行,适合业务相关操作。如果业务不需要Spring上下文,优先使用过滤器以减少依赖。- 常见问题
- 过滤器中对请求体的读取可能导致后续无法再次读取(因为流只能读一次),可使用
ContentCachingRequestWrapper包装。 - 拦截器中可以获取处理器方法上的注解,用于权限控制,例如检查方法是否有
@RequiresPermission注解。
- 过滤器中对请求体的读取可能导致后续无法再次读取(因为流只能读一次),可使用
- 执行顺序图示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
客户端请求 ↓ Filter1.doFilter() 前置 ↓ Filter2.doFilter() 前置 ↓ DispatcherServlet ↓ Interceptor1.preHandle() ↓ Interceptor2.preHandle() ↓ Controller方法 ↓ Interceptor2.postHandle() ↓ Interceptor1.postHandle() ↓ 视图渲染 ↓ Interceptor2.afterCompletion() ↓ Interceptor1.afterCompletion() ↓ Filter2.doFilter() 后置 ↓ Filter1.doFilter() 后置 ↓ 客户端响应
springBoot
启动流程
【问题】 什么是Spring Boot?和Spring有什么关系?优点是什么?启动流程具体是怎样的?什么是starter?怎么自定义一个starter?什么是autoconfiguation?如何在Spring Boot应用程序中使用Jetty而不是Tomcat?
【参考答案】 一、什么是Spring Boot?和Spring有什么关系? Spring Boot 是Spring家族中的一个子项目,旨在简化Spring应用程序的创建和开发过程。它基于“约定优于配置”的原则,提供了自动配置、起步依赖、嵌入式Web服务器等特性,使开发者能够快速构建独立、生产级的Spring应用。
与Spring的关系:
- Spring Boot 建立在Spring Framework之上,是对Spring框架的进一步封装和增强,而不是替代品。
- Spring Framework提供了IoC、AOP、事务管理等核心功能,而Spring Boot则通过自动配置和起步依赖,降低了使用Spring的复杂性,让开发者无需手动配置大量的XML或Java配置。
- 使用Spring Boot可以更方便地使用Spring生态中的其他项目(如Spring Data、Spring Security等)。
二、优点是什么?
- 快速构建:通过
spring-boot-starter起步依赖,可以快速引入所需功能,简化Maven/Gradle配置。 - 自动配置:Spring Boot根据类路径中的依赖自动配置Spring应用,减少手动配置工作。
- 嵌入式Web服务器:内置Tomcat、Jetty或Undertow,无需部署WAR包,可直接运行JAR包启动应用。
- 生产就绪特性:提供健康检查、指标监控、外部化配置等(通过Spring Actuator),便于运维和监控。
- 无代码生成和XML配置:完全基于注解和Java配置,无需编写繁琐的XML。
- 与Spring生态无缝集成:轻松整合Spring Data、Spring Security、Spring Cloud等。
- 易于测试:提供
@SpringBootTest等注解,简化集成测试。
三、启动流程具体是怎样的? Spring Boot应用的启动入口通常是包含main方法的类,并使用@SpringBootApplication注解。启动流程分为两个阶段:构造SpringApplication实例和执行run方法。
- 构造
SpringApplication实例 当调用SpringApplication.run(主类.class, args)时,首先会创建SpringApplication对象,初始化工作包括:- 将传入的
sources参数(通常是主类)保存到SpringApplication属性中。 - 根据类路径推断当前应用类型(是否为Web应用,通过是否存在
javax.servlet.Servlet和Spring的WebApplicationContext类判断),并设置webApplicationType。 - 从
META-INF/spring.factories中加载所有ApplicationContextInitializer实现类,并设置到initializers属性中。 - 从
META-INF/spring.factories中加载所有ApplicationListener实现类,并设置到listeners属性中。 - 通过堆栈信息推断并设置主类(
mainApplicationClass)。
- 将传入的
- 执行
run方法 构造完成后调用run方法,步骤如下: - 启动计时器:创建
StopWatch实例并开始计时,用于记录启动耗时。 - 初始化监听器:从
spring.factories加载SpringApplicationRunListener(默认只有一个EventPublishingRunListener),并遍历调用它们的starting()方法,通知监听器应用正在启动。 - 创建应用参数对象:封装命令行参数
args为ApplicationArguments实例。 - 准备环境:
- 根据应用类型创建对应的
ConfigurableEnvironment(如StandardServletEnvironment)。 - 将命令行参数和系统属性等添加到环境中。
- 调用
SpringApplicationRunListener的environmentPrepared()方法,发布ApplicationEnvironmentPreparedEvent事件,允许监听器对环境进行修改(如添加配置文件中的属性)。 - 将环境与SpringApplication绑定。
- 根据应用类型创建对应的
- 打印Banner:根据配置在控制台打印Banner(可自定义或关闭)。
- 创建Spring容器:
- 根据应用类型创建对应的
ApplicationContext(如AnnotationConfigServletWebServerApplicationContext)。 - 将准备好的环境设置到容器中。
- 调用
ApplicationContextInitializer对容器进行初始化(此时会发布ApplicationContextInitializedEvent事件)。 - 将
ApplicationArguments和Banner等作为Bean注册到容器。
- 根据应用类型创建对应的
- 刷新容器:调用
AbstractApplicationContext.refresh()方法,执行Spring容器的核心刷新流程,包括Bean的扫描、创建、自动配置等。在此过程中,内嵌Web服务器(如Tomcat)会启动。 - 刷新后处理:刷新完成后,调用
SpringApplicationRunListener的started()方法,发布ApplicationStartedEvent事件。 - 调用Runner:获取容器中所有
ApplicationRunner和CommandLineRunner类型的Bean,并执行它们的回调方法(用于在启动后执行自定义逻辑)。 - 发布就绪事件:调用
SpringApplicationRunListener的ready()方法,发布ApplicationReadyEvent事件,表示应用已完全启动,可以处理请求。 - 返回容器:
run方法返回ConfigurableApplicationContext实例,通常由应用持有。
注:若启动过程中发生异常,会调用监听器的failed()方法,并抛出异常。
四、什么是starter? Starter 是Spring Boot中的一种特殊依赖描述符,它聚合了一组相关的依赖库,并提供了自动配置的支持。开发者只需引入一个starter,即可获得该功能所需的所有依赖和默认配置,无需手动添加各个库的依赖。
例如,spring-boot-starter-web包含了Spring MVC、内嵌Tomcat、Jackson等依赖,并自动配置了DispatcherServlet、视图解析器等组件。
五、怎么自定义一个starter? 自定义starter的步骤:
- 创建两个模块(通常):
- autoconfigure模块:包含自动配置代码。
- starter模块:空项目,仅依赖autoconfigure模块和其他必要依赖。 也可以合并为一个模块,但官方推荐分离。
- 编写自动配置类:
- 使用
@Configuration和@Conditional系列注解(如@ConditionalOnClass、@ConditionalOnProperty)定义在什么条件下创建哪些Bean。 - 在
META-INF/spring.factories文件中注册自动配置类:org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.example.MyAutoConfiguration。
- 使用
- 提供配置属性(可选):
- 创建
@ConfigurationProperties类,用于绑定配置文件中的属性。 - 在自动配置类中通过
@EnableConfigurationProperties启用。
- 创建
- 编写starter模块的pom:
- 引入autoconfigure模块和所需依赖。
- 通常无需代码,仅作为依赖聚合。
- 安装到Maven仓库,供其他项目使用。
六、什么是autoconfiguration? AutoConfiguration(自动配置)是Spring Boot的核心机制,它根据类路径中的依赖、定义的Bean以及配置文件,自动配置Spring应用所需的组件。其实现原理:
- 使用
@EnableAutoConfiguration注解导入AutoConfigurationImportSelector。 AutoConfigurationImportSelector通过SpringFactoriesLoader加载META-INF/spring.factories中配置的自动配置类。- 自动配置类通常带有
@Conditional条件注解,确保在满足条件时才生效(如某个类存在、某个属性被设置等)。 - 自动配置类会创建一系列默认的Bean,同时允许用户通过自定义Bean覆盖。
七、如何在Spring Boot应用程序中使用Jetty而不是Tomcat? Spring Boot默认使用Tomcat作为嵌入式Servlet容器。要替换为Jetty,只需排除Tomcat依赖并引入Jetty starter:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>
如果是Gradle:
1
2
3
4
implementation('org.springframework.boot:spring-boot-starter-web') {
exclude group: 'org.springframework.boot', module: 'spring-boot-starter-tomcat'
}
implementation 'org.springframework.boot:spring-boot-starter-jetty'
Spring Boot会自动检测Jetty的依赖并配置JettyServletWebServerFactory。
【大白话解释于举例说明】
- Spring Boot是什么:好比你要建一栋房子,Spring Framework提供了砖瓦、水泥(基础功能),但你需要自己设计图纸、搬运材料。而Spring Boot就像一个精装房开发商,不仅提供了建筑材料,还帮你设计好了户型、装修好了(自动配置),你只需拎包入住(写业务代码)。
- 优点:快速、省事、自带家具(嵌入式服务器)、还配有物业(Actuator)。
- 启动流程:就像楼盘开盘,先确定楼盘类型(普通住宅还是别墅),然后通知物业(监听器),接着平整土地(准备环境),搭建框架(创建上下文),装修(刷新上下文),最后交付使用(运行Runner)。
- starter:一个“装修套餐”,比如“北欧风套餐”包含了地板、灯具、家具,你只需选这个套餐,所有东西自动配齐。
- 自定义starter:你自己设计一个“智能家居套餐”,把需要的设备打包,并写明在什么条件下安装(自动配置),然后发布到市场(Maven仓库),别人引入就能用。
- autoconfiguration:自动判断你的房子里有没有智能灯泡,如果有就自动安装智能开关。
- 替换Jetty:原来房子默认配了Tomcat牌门锁,你不喜欢,就把它拆了(排除依赖),换成Jetty牌门锁(引入Jetty starter),房子会自动识别并装上。
【扩展知识点详解】
- @SpringBootApplication注解:组合了
@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan。 - SpringApplication的run方法:核心入口,内部会创建
SpringApplication实例,调用run方法。 - spring.factories文件:位于
META-INF下,用于注册自动配置类、监听器、初始化器等,是Spring Boot SPI机制的关键。 - 条件注解:如
@ConditionalOnClass、@ConditionalOnMissingBean、@ConditionalOnProperty等,是自动配置的基石。 - 嵌入式Web容器的切换:除了Jetty,还有Undertow,可通过类似方式切换。同时可配置SSL、端口等。
- 自定义starter的命名规范:通常命名为
xxx-spring-boot-starter,官方starter以spring-boot-starter-xxx命名。 - 自动配置的优先级:用户自定义Bean优先于自动配置,可以通过
@Primary或@ConditionalOnMissingBean实现覆盖。 - 启动流程中的关键事件:
ApplicationStartingEvent、ApplicationEnvironmentPreparedEvent、ApplicationPreparedEvent、ApplicationStartedEvent、ApplicationReadyEvent等,可用于扩展。 - ApplicationRunner和CommandLineRunner:用于在启动后执行特定代码,区别在于参数类型不同。
- 外部化配置:Spring Boot支持从
application.properties/yml、环境变量、命令行参数等多种来源加载配置,优先级明确。
【问题】 请详细讲一下@SpringBootApplication和@EnableAutoConfiguration两个注解。
【参考答案】 一、@SpringBootApplication 注解 @SpringBootApplication 是 Spring Boot 中最核心的注解,通常标注在启动类上。它是一个复合注解,组合了以下三个注解的功能:
- @SpringBootConfiguration:本质上是
@Configuration,表明该类是一个配置类,可以声明 Bean 或导入其他配置。 - @EnableAutoConfiguration:启用 Spring Boot 的自动配置机制,尝试根据类路径依赖自动配置 Spring 应用。
- @ComponentScan:启用组件扫描,默认扫描启动类所在包及其子包下的所有带有
@Component及其派生注解(如@Service、@Repository、@Controller)的类,并将其注册为 Bean。
等价关系:
1
2
3
4
5
6
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
等同于:
1
2
3
4
5
6
7
8
@Configuration
@EnableAutoConfiguration
@ComponentScan
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
作用:通过一个注解简化了 Spring Boot 应用的配置,无需手动编写三个注解。
二、@EnableAutoConfiguration 注解 @EnableAutoConfiguration 是 Spring Boot 自动配置功能的核心开关。它告诉 Spring Boot 基于添加的 jar 依赖和配置,自动配置 Spring 应用程序所需的 Bean。
注解定义
1
2
3
4
5
6
7
8
9
10
11
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
关键点:
@AutoConfigurationPackage:将主配置类(即标注了@EnableAutoConfiguration的类)所在的包注册为“自动配置包”,以便后续自动配置类可以扫描该包下的组件(比如 JPA 实体)。@Import(AutoConfigurationImportSelector.class):导入AutoConfigurationImportSelector,这是自动配置的核心实现类,负责从META-INF/spring.factories中加载所有候选的自动配置类,并根据条件(@Conditional)决定哪些配置生效。
工作原理
加载候选自动配置类:
AutoConfigurationImportSelector实现了ImportSelector接口,其selectImports方法会扫描所有META-INF/spring.factories文件中 key 为org.springframework.boot.autoconfigure.EnableAutoConfiguration的 value,这些 value 是自动配置类的全限定名列表。Spring Boot 自动配置模块(如spring-boot-autoconfigure)提供了大量预定义的自动配置类,例如WebMvcAutoConfiguration、DataSourceAutoConfiguration等。过滤与排序:
加载后,会应用一系列的过滤机制,如排除指定的自动配置类(通过exclude属性)、根据条件注解进行判断。排序确保配置类的顺序符合要求(通过@AutoConfigureOrder、@AutoConfigureBefore、@AutoConfigureAfter)。条件化配置:
每个自动配置类通常都带有@Conditional注解(如@ConditionalOnClass、@ConditionalOnBean、@ConditionalOnProperty等),只有在满足特定条件时才会生效。例如,DataSourceAutoConfiguration只有在类路径中存在DataSource类且用户没有自定义DataSourceBean 时才会自动配置数据源。注册 Bean:
最终,符合条件的自动配置类会被导入为普通的@Configuration类,其中的@Bean方法会被执行,将所需的 Bean 注册到容器中。
三、两者的关系 @SpringBootApplication 包含 @EnableAutoConfiguration,所以标注了 @SpringBootApplication 的启动类自动开启了自动配置功能。此外,@SpringBootApplication 还包含了组件扫描和配置类功能,三者共同构成了 Spring Boot 应用的基石。
四、常用配置与扩展
- 排除特定自动配置:
如果不想启用某个自动配置,可以在@SpringBootApplication或@EnableAutoConfiguration中使用exclude属性:1 2
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class) public class Application { ... }
或者在配置文件中通过
spring.autoconfigure.exclude属性指定。 自定义自动配置:
可以编写自己的自动配置类,并注册到META-INF/spring.factories中,实现自定义的自动配置。- 条件注解:
自动配置的强大之处在于条件注解,了解常用的条件注解有助于理解自动配置的生效时机:@ConditionalOnClass:当类路径中存在指定类时。@ConditionalOnMissingClass:当类路径中不存在指定类时。@ConditionalOnBean:当容器中存在指定 Bean 时。@ConditionalOnMissingBean:当容器中不存在指定 Bean 时(常用于覆盖默认配置)。@ConditionalOnProperty:当配置文件中有指定属性且符合要求时。@ConditionalOnResource:当类路径中存在指定资源文件时。@ConditionalOnWebApplication:当应用是 Web 应用时。@ConditionalOnNotWebApplication:当应用不是 Web 应用时。
【大白话解释】
- @SpringBootApplication:就像是一个“全家桶”套餐,包含了主食(配置类)、配菜(自动配置)和餐具(组件扫描)。你只需要点这个套餐,就能直接开吃。
- @EnableAutoConfiguration:好比一个“智能家居总开关”,打开它后,家里会根据你添置的家电(依赖)自动开启相应的功能。比如你买了智能灯泡(引入
spring-boot-starter-data-redis),它就会自动帮你配好 Redis 的连接;你买了智能音箱(引入spring-boot-starter-web),它就自动配好 Web 服务器。
【扩展知识点】
- spring.factories 文件的位置:位于每个 jar 包的
META-INF目录下,Spring Boot 通过SpringFactoriesLoader加载。 - 自动配置类的命名规范:通常以
AutoConfiguration结尾,例如DataSourceAutoConfiguration。 - 自动配置的覆盖原则:如果用户自定义了同类型的 Bean,通常自动配置的 Bean 不会生效(通过
@ConditionalOnMissingBean保证),因此用户可以轻松覆盖默认配置。 - @AutoConfigurationPackage 的作用:它注册了一个
AutoConfigurationPackages的 Bean,用于保存基础包路径,供其他自动配置类(如 JPA 实体扫描)使用。 - 调试自动配置:可以在配置文件中设置
debug=true或启用--debug,启动时控制台会输出自动配置报告,显示哪些自动配置类生效(positive matches)和哪些未生效(negative matches)。
mybatis
【问题】 什么是Mybatis?为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?mybatis的优点有哪些?缺点有哪些?
【答案】 一、什么是 MyBatis? MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 封装了 JDBC 的重复代码,通过简单的 XML 或注解配置,将 Java 对象与数据库中的记录进行映射,使得开发者可以专注于 SQL 本身和业务逻辑,而无需处理 JDBC 的繁琐细节(如注册驱动、获取连接、处理结果集等)。
二、为什么说 MyBatis 是半自动 ORM 映射工具? ORM(Object-Relational Mapping,对象关系映射)是指将 Java 对象与数据库表记录自动映射的技术。MyBatis 被称为半自动 ORM,因为它只完成了结果集到对象的映射(即自动封装结果集),以及对象参数到 SQL 参数的映射,但需要开发者手动编写 SQL 语句。与之相对,全自动 ORM(如 Hibernate)不仅负责映射,还会根据对象操作自动生成 SQL,开发者几乎不需要编写 SQL。
三、MyBatis 与全自动 ORM(如 Hibernate)的区别
| 对比维度 | MyBatis(半自动) | Hibernate(全自动) |
|---|---|---|
| SQL 生成 | 开发者手动编写 SQL | 框架根据对象状态自动生成 SQL(HQL 或 SQL) |
| 控制权 | 开发者完全控制 SQL,便于优化和定制 | 框架控制 SQL,优化空间有限 |
| 学习曲线 | 较低,只需熟悉 SQL 和映射配置 | 较高,需理解 HQL、缓存、懒加载等复杂概念 |
| 移植性 | 差,SQL 可能依赖特定数据库方言 | 好,可通过配置切换数据库(Hibernate 适配多种方言) |
| 开发效率 | 较高,但需要编写 SQL | 极高,无需编写 SQL,纯对象操作 |
| 性能调优 | 灵活,可直接优化 SQL | 复杂,需通过缓存、抓取策略等手段 |
四、MyBatis 的优点
- 灵活可控:开发者手写 SQL,可以针对复杂查询和特定数据库优化,性能达到最优。
- 易于学习:相比 Hibernate,MyBatis 概念简单,只需要掌握 SQL 和基本配置即可上手。
- 动态 SQL:提供强大的动态 SQL 标签(如
<if>、<foreach>),方便拼接复杂查询条件。 - 与 JDBC 相比:消除了大量重复代码,简化了数据访问层开发。
- 轻量级:无侵入性,不会强制继承或实现特定接口(只需配置映射即可)。
- 良好的集成:可与 Spring、Spring Boot 无缝集成,支持缓存(一级、二级缓存)。
五、MyBatis 的缺点
- 工作量大:需要手动编写 SQL 和映射配置,尤其在表字段多、关联复杂时,工作量较大。
- 数据库移植性差:SQL 语句可能包含特定数据库的语法,切换数据库时需修改 SQL。
- 配置文件较多:早期版本需要配置 XML 文件,虽然现在支持注解,但复杂 SQL 仍需 XML。
- 缺乏全自动 ORM 的高级特性:如懒加载、缓存策略等需要额外配置,不如 Hibernate 开箱即用。
- SQL 注入风险:如果使用
${}拼接参数,可能导致 SQL 注入(需使用#{}预编译)。
【大白话解释】
- MyBatis 是什么:就像你去餐厅吃饭,不用自己洗菜、切菜(JDBC 的重复工作),但需要亲自点菜(写 SQL)。厨房(MyBatis)会按你的菜单做好菜,并把菜端到你面前(结果映射)。
- 为什么叫半自动:好比“半自动洗衣机”,你需要自己把衣服放进去、倒洗衣液(写 SQL),然后它帮你洗好甩干(映射结果)。而“全自动洗衣机”(Hibernate)你只需把衣服扔进去,它会自动加洗衣液、选模式、洗完烘干(自动生成 SQL 和映射)。
- 优点:自己写 SQL,就像自己炒菜,味道可控,可以加辣加麻(优化性能);容易学会,会 SQL 就能用。
- 缺点:每次都要自己写菜单,如果菜品复杂,点菜也累(工作量大);换了个餐厅(换数据库),菜单可能不适用(移植性差)。
【扩展知识点详解】
- MyBatis 核心组件:
- SqlSessionFactoryBuilder:根据配置构建 SqlSessionFactory。
- SqlSessionFactory:生产 SqlSession 的工厂,通常是单例的。
- SqlSession:代表一次数据库会话,提供执行 SQL、获取映射器的方法。
- Mapper:接口,通过动态代理绑定 SQL 语句,是推荐的使用方式。
- 工作原理:
- 读取配置文件(mybatis-config.xml)和映射文件(或注解)。
- 构建 SqlSessionFactory。
- 通过 SqlSessionFactory 打开 SqlSession。
- 通过 SqlSession 获取 Mapper 接口代理,或直接调用 API 执行 SQL。
- 执行 SQL 并映射结果返回。
- 动态 SQL:
<if>:条件判断<choose> (<when> <otherwise>):多分支选择<where>、<set>:动态处理 WHERE 和 SET 子句<foreach>:遍历集合<trim>:自定义前缀后缀
- 与 Hibernate 的详细对比:
- 开发速度:Hibernate 在简单 CRUD 上更快,MyBatis 在复杂查询上更灵活。
- 性能:MyBatis 由于手写 SQL,通常性能更高,但 Hibernate 通过缓存优化也能达到相近水平。
- 适用场景:MyBatis 适合需要精细控制 SQL、遗留数据库、或 SQL 较复杂的项目;Hibernate 适合业务逻辑简单、快速开发、对数据库移植性要求高的项目。
- 缓存机制:
- 一级缓存:SqlSession 级别,默认开启。
- 二级缓存:Mapper 级别,需配置,可跨 SqlSession 共享。
- 最佳实践:
- 使用 Mapper 接口,避免直接调用 SqlSession API。
- 参数尽量用
#{}防止 SQL 注入。 - 对于复杂查询,结合动态 SQL 和分页插件(如 PageHelper)。
- 与 Spring 集成时,使用
@MapperScan或MapperFactoryBean。
【问题】 在MyBatis中,#{}和${}的区别是什么?
【答案】 在MyBatis中,#{} 和 ${} 都是用于参数替换的占位符,但它们在处理方式和安全性上有本质区别:
- 预编译与直接拼接:
#{}:会被解析为 JDBC 的预编译语句(PreparedStatement)中的占位符?,并在执行时通过参数安全地设置值。MyBatis 会将其替换为?,然后使用PreparedStatement的setXxx()方法赋值。这可以有效防止 SQL 注入。${}:是简单的字符串替换,MyBatis 在解析 SQL 时,会直接将${}中的内容替换为参数的实际值,然后拼接成最终的 SQL 语句。这可能导致 SQL 注入风险,因为参数值可能包含恶意的 SQL 片段。
- 使用场景:
#{}:用于绝大多数参数传递,如字段值、条件值等。因为它安全可靠,且能自动处理数据类型和引号(例如字符串类型会自动加单引号)。${}:通常用于动态传入数据库对象,如表名、列名、排序字段等。因为这些对象不能使用占位符,只能通过字符串拼接。使用时需确保传入的值是可信的,避免注入风险。
- 类型处理:
#{}:会根据参数类型自动进行类型转换和加引号处理。例如,传入字符串会自动加单引号,传入数字则不加。${}:不会做任何类型处理,直接替换为字符串,因此需要手动处理引号。例如,如果传入字符串值,需要在 SQL 中显式加单引号,如'${name}'。
- 执行效率:
#{}:由于使用了预编译,数据库可以缓存执行计划,对于重复执行相同 SQL 的场景效率更高。${}:每次都会生成新的 SQL 语句,数据库无法缓存,可能影响性能。
【大白话解释】
#{}就像去餐厅点菜,你告诉服务员你要的菜名,服务员记下来,然后后厨按标准流程做菜。无论谁点同样的菜,流程都一样,安全可靠(预编译)。${}就像你直接冲进后厨,告诉厨师“给我炒个菜,再加点特殊调料”,厨师直接按你的要求做,但你可能会不小心把厨房弄乱(SQL 注入风险)。
例如:
1
2
3
4
5
6
7
8
9
10
-- 使用 #{}
SELECT * FROM user WHERE name = #{name}
-- 实际执行:SELECT * FROM user WHERE name = ?
-- 参数 '张三' 会安全设置
-- 使用 ${}
SELECT * FROM user WHERE name = '${name}'
-- 如果传入 "张三' OR '1'='1",拼接后变成:
-- SELECT * FROM user WHERE name = '张三' OR '1'='1'
-- 这就是 SQL 注入攻击。
【扩展知识点详解】
- SQL 注入原理:
${}直接拼接参数,攻击者可构造恶意参数改变 SQL 语义,导致数据泄露或破坏。例如,传入' OR 1=1; --可能使查询返回所有数据。 - 使用 ${} 的安全措施:如果必须使用
${}(如动态表名),应对参数进行严格校验,例如使用白名单,只允许预定义的几个表名,或通过代码逻辑控制。 - MyBatis 的解析顺序:MyBatis 首先解析
${}进行字符串替换,然后再处理#{}生成占位符。这意味着如果${}替换的内容中包含#{},#{}仍会被处理。 - 与 JDBC 的对应:
#{}对应PreparedStatement的setObject或setString等,参数独立传递;${}对应Statement的字符串拼接,参数直接嵌入 SQL。 - OGNL 表达式:在
${}中可以使用 OGNL 表达式进行复杂运算(如${1+1}),但#{}不支持,#{}只能直接引用参数。 - 动态 SQL 中的使用:在
<if test="...">等标签中,使用的是 OGNL 表达式,与参数传递的占位符不同。注意区分 test 表达式中的参数引用(直接写 param)和 SQL 语句中的占位符。 - 最佳实践:
- 优先使用
#{},除非必须动态传入表名、列名等。 - 对于排序字段,建议使用
#{}结合OrderBy的列名白名单,或者通过 Java 代码控制拼接。 - 对用户输入的任何内容都不要直接使用
${},如果必须,则进行严格过滤。
- 优先使用
- 常见误区:误认为
${}可以解决#{}无法处理的情况,如模糊查询。实际上,模糊查询可以用#{}配合数据库函数实现,如WHERE name LIKE '%' || #{name} || '%'(Oracle)或WHERE name LIKE CONCAT('%', #{name}, '%')(MySQL)。
【问题】 在MyBatis中,当实体类中的属性名和表中的字段名不一样时有几种处理方法?
【答案】 当实体类中的属性名与数据库表中的字段名不一致时,MyBatis 提供了多种映射方式来解决这一问题,确保查询结果能正确封装到实体对象中。主要有以下四种处理方法:
使用 SQL 别名
在编写 SQL 语句时,为查询字段指定与实体类属性名一致的别名。这是最简单直接的方法,适用于简单的字段不一致场景。
示例:1
SELECT user_id AS userId, user_name AS userName FROM user WHERE id = #{id}
使用 resultMap 结果映射
通过<resultMap>标签显式定义字段与属性的映射关系,这是 MyBatis 最强大、最灵活的配置方式。可以处理复杂的映射,如关联对象、嵌套集合等。
示例:1 2 3 4 5 6 7
<resultMap id="userMap" type="com.example.User"> <id property="userId" column="user_id"/> <result property="userName" column="user_name"/> </resultMap> <select id="selectUser" resultMap="userMap"> SELECT * FROM user WHERE id = #{id} </select>
开启驼峰命名自动映射
在 MyBatis 全局配置中开启驼峰命名转换,将数据库字段的 下划线命名 自动映射为实体类的 驼峰命名。例如,数据库字段user_name会自动映射到实体类属性userName。
配置方式(在 mybatis-config.xml 中):1 2 3
<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings>
或者在 Spring Boot 的 application.yml 中:
1 2 3
mybatis: configuration: map-underscore-to-camel-case: true
使用注解 @Results 和 @Result
在 Mapper 接口的方法上使用注解直接定义映射关系,适用于简单映射且不想写 XML 的场景。
示例:1 2 3 4 5 6
@Select("SELECT * FROM user WHERE id = #{id}") @Results({ @Result(property = "userId", column = "user_id"), @Result(property = "userName", column = "user_name") }) User selectUser(int id);
【大白话解释】
- SQL 别名:就像你给数据库字段起个小名,让 MyBatis 能认出它对应实体类的哪个属性。比如数据库字段叫
user_name,你查出来时把它改名叫userName,实体类就能接住。 - resultMap:好比画一张“对照表”,告诉 MyBatis 数据库的哪一列对应实体类的哪个属性。即使名字完全不同,也能按表里的一一对应关系映射。
- 驼峰命名自动映射:如果数据库习惯用下划线(如
user_name),而实体类习惯用小驼峰(如userName),MyBatis 可以自动识别这种模式,省去手动配置的麻烦。就像开启了一个“自动翻译器”。 - 注解映射:把对照关系直接写在代码里,适合简单情况,不用去翻 XML 文件。
【扩展知识点详解】
- 优先级:如果同时使用多种方式,MyBatis 的优先级规则大致为:
resultMap> SQL 别名 > 全局驼峰配置。即显式定义的 resultMap 会覆盖其他设置。 - resultMap 的复杂用法:可以配置继承(
extends)、关联(association,用于一对一)、集合(collection,用于一对多)等高级映射。 - 自动映射级别:MyBatis 提供了
autoMappingBehavior设置(NONE、PARTIAL、FULL),控制自动映射的程度。驼峰转换与自动映射配合使用。 - 注解的局限性:注解方式不适合复杂映射(如多表关联),且当 SQL 较长时,代码可读性较差,建议使用 XML。
- 混合使用:可以在 resultMap 中部分字段自动映射,部分手动指定。例如设置
autoMapping="true"后,未显式配置的字段会自动根据列名和属性名匹配(考虑驼峰)。 - MyBatis-Plus 增强:如果使用 MyBatis-Plus,其默认开启驼峰映射,并提供
@TableId、@TableField等注解,可以更便捷地指定映射关系。例如@TableField("user_name")。 - 注意事项:
- 使用别名时,要注意 SQL 关键字冲突,可能需要加引号。
- 开启驼峰映射后,只对下划线转驼峰有效,其他命名风格(如大小写混用)需手动处理。
- 在关联查询中,如果多个表有同名字段,建议使用别名或 resultMap 明确指定。
【问题】 在MyBatis中,模糊查询有几种实现方式?
【答案】 在 MyBatis 中,实现模糊查询主要有以下四种常见方式,每种方式在参数处理和 SQL 拼接上有所区别:
使用
${}直接拼接
在 SQL 语句中直接用${}将参数值拼接到 LIKE 子句中。这种方式简单直观,但存在 SQL 注入风险,且需要手动添加百分号。
示例:1 2 3
<select id="selectByName" resultType="User"> SELECT * FROM user WHERE name LIKE '%${name}%' </select>
使用
#{}结合数据库函数
在 SQL 中使用#{}作为占位符,并通过数据库的字符串连接函数(如CONCAT)将百分号与参数拼接。这种方式安全,可防止 SQL 注入。
示例:1 2 3
<select id="selectByName" resultType="User"> SELECT * FROM user WHERE name LIKE CONCAT('%', #{name}, '%') </select>
使用 MyBatis 的
<bind>标签
在映射文件中使用<bind>标签定义一个变量,将参数与百分号拼接,然后在 SQL 中使用该变量。这种方式既安全又灵活,尤其适用于多数据库兼容的场景。
示例:1 2 3 4
<select id="selectByName" resultType="User"> <bind name="pattern" value="'%' + name + '%'"/> SELECT * FROM user WHERE name LIKE #{pattern} </select>
在 Java 代码中拼接
在调用 Mapper 之前,由业务层将参数拼接好(如name = "%"+name+"%"),然后直接传入 Mapper。这种方式也能防止注入,但将拼接逻辑混入业务层。
示例:1 2
String name = "%" + userName + "%"; List<User> users = userMapper.selectByName(name);
对应的 Mapper:
1 2 3
<select id="selectByName" resultType="User"> SELECT * FROM user WHERE name LIKE #{name} </select>
推荐做法:优先使用 方式2(CONCAT) 或 **方式3(
【大白话解释】
- 方式1(${}):直接把用户输入的内容塞进 SQL 语句里,就像把陌生人带进你家厨房,万一他包里藏了危险品(恶意 SQL 代码),就可能搞破坏(SQL 注入)。不推荐。
- 方式2(CONCAT):用数据库的函数把百分号和参数粘在一起,然后通过安全的
#{}传进去。就像你让服务员把配料加好,再端上桌,安全省心。 - **方式3(
)**:在 SQL 映射文件里,用 MyBatis 自带的 ` ` 标签把参数和百分号拼好,再放进去。相当于你自己在厨房门口把配料组合好,再交给厨师,既安全又灵活。 - 方式4(Java拼接):在 Java 代码里先把参数加工好,再传给 Mapper。就像你在外面把菜洗好切好,然后直接给厨师下锅,同样安全,但可能让代码不够整洁。
【扩展知识点详解】
SQL 注入风险:使用
${}时,如果参数直接来源于用户输入,攻击者可构造' OR '1'='1等字符串,导致 SQL 语义改变,查询所有数据。因此,除非参数完全可信(如程序内部生成),否则禁止使用${}进行模糊查询。数据库兼容性:
CONCAT('%', #{name}, '%')在 MySQL、PostgreSQL 中可用,但在 SQL Server 中应使用'%' + #{name} + '%'。<bind>标签与数据库无关,MyBatis 负责拼接,因此具有更好的移植性。
性能考虑:使用
LIKE '%...%'会导致全表扫描(索引失效),因为前导通配符%使得数据库无法使用 B+ 树索引。如果数据量大,应考虑使用全文搜索引擎(如 Elasticsearch)或优化查询条件(如仅后通配...%)。特殊字符转义:当参数本身包含百分号(
%)或下划线(_)时,需要转义。例如,用户想查询包含%的内容,此时需要在 SQL 中使用ESCAPE子句。使用<bind>标签可以更方便地处理转义。动态 SQL 组合:模糊查询常与
<if>标签结合,实现可选条件。例如:1 2 3 4 5 6 7 8
<select id="selectByCondition" resultType="User"> SELECT * FROM user <where> <if test="name != null and name != ''"> AND name LIKE CONCAT('%', #{name}, '%') </if> </where> </select>
MyBatis-Plus 扩展:如果使用 MyBatis-Plus,可以直接使用
like方法,如queryWrapper.like("name", name),底层封装了安全的拼接,极大简化代码。
【问题】 什么是MyBatis的接口绑定?有哪些实现方式?Mapper接口的工作原理是什么?Mapper接口里的方法,参数不同时,方法能重载吗?使用MyBatis的mapper接口调用时有哪些要求?
【答案】 一、什么是MyBatis的接口绑定? MyBatis的接口绑定是指通过定义一个Java接口,将接口中的方法与映射文件(XML)中的SQL语句或注解中的SQL关联起来,从而可以通过调用接口方法的方式来执行对应的SQL操作。这种方式消除了传统DAO层手动实现类的繁琐,由MyBatis动态生成接口的代理对象,开发者只需定义接口即可。
二、接口绑定的实现方式
基于XML配置
在XML映射文件中,通过namespace属性指定接口的全限定名,并将接口中的方法与XML中的<select>、<insert>等标签通过方法名对应起来。例如:1 2 3 4 5
<mapper namespace="com.example.UserMapper"> <select id="selectUser" resultType="User"> SELECT * FROM user WHERE id = #{id} </select> </mapper>
基于注解
直接在接口方法上使用@Select、@Insert等注解编写SQL语句。例如:1 2 3 4
public interface UserMapper { @Select("SELECT * FROM user WHERE id = #{id}") User selectUser(int id); }
三、Mapper接口的工作原理 MyBatis启动时,会扫描映射文件或注解,为每个Mapper接口创建代理对象(通过JDK动态代理)。当调用接口方法时,代理对象根据方法名和参数找到对应的SQL语句,执行并返回结果。具体流程:
- 注册映射:MyBatis解析配置文件,将每个
namespace与接口关联,并将SQL语句以方法名为键存入配置中。 - 获取代理:通过
SqlSession.getMapper(Class)方法,MyBatis使用MapperProxyFactory创建接口的动态代理对象。 - 执行调用:代理对象拦截方法调用,根据方法名从配置中查找对应的SQL语句,然后通过
SqlSession执行SQL,并将结果映射返回。
四、Mapper接口里的方法,参数不同时,方法能重载吗? 不能重载。MyBatis通过方法名(在namespace下)唯一确定要执行的SQL语句,不区分参数类型或个数。即使参数不同,只要方法名相同,MyBatis会认为它们是同一个映射,导致冲突。因此,在同一个Mapper接口中,不能定义同名方法,无论参数是否相同。
五、使用MyBatis的mapper接口调用时有哪些要求?
- 接口名与映射文件namespace一致:XML中的
namespace必须等于接口的全限定名。 - 方法名与SQL id一致:接口中的方法名必须等于XML中
<select>等标签的id,或注解中定义的SQL对应。 - 返回值类型匹配:方法返回值类型必须与映射文件中定义的
resultType或resultMap兼容。 - 参数类型匹配:方法参数需与SQL语句中占位符的参数类型一致,可通过
@Param注解指定参数名(多参数时必用)。 - 接口不能有重载方法:如前述。
- 接口中方法不能使用修饰符:必须是
public的(默认),但无需显式写。 - 需要注册接口:在Spring中,需通过
@MapperScan或@Mapper注解将接口纳入IoC容器。
【大白话解释】
- 接口绑定:就像你给餐厅打电话订餐,你不需要亲自去厨房(不用写实现类),只要报上菜名(方法名),餐厅就会按菜单(SQL映射)做好送过来。MyBatis就是那个帮你拨电话、传话的接线员(代理对象)。
- 实现方式:可以写一张纸菜单(XML),或者直接在电话里说菜名(注解),两种方式都能让接线员明白你的需求。
- 工作原理:MyBatis启动时,会给每个菜单(接口)配一个机器人(代理对象)。你点菜(调用方法),机器人就去后厨找对应的厨师(SQL),做好后端给你(返回结果)。
- 不能重载:就像菜单上不能有两道菜都叫“鱼香肉丝”,即使配料不同,也会让厨师混乱。所以方法名必须唯一。
- 调用要求:就像点菜时,菜名必须准确(方法名一致),你说“我要一份鱼香肉丝”时,服务员知道该记在哪个菜单(namespace匹配),而且你指定的口味(参数类型)也要对得上。
【扩展知识点详解】
- 命名空间的作用:
namespace不仅用于绑定接口,还用于区分不同Mapper接口中相同的方法名,避免冲突。 - 参数处理:
- 单参数:可以直接使用参数名(如
#{id})。 - 多参数:必须使用
@Param注解指定参数名,如List<User> selectByNameAndAge(@Param("name") String name, @Param("age") int age);,否则MyBatis会以param1、param2等形式引用。
- 单参数:可以直接使用参数名(如
- 返回类型:
- 查询单条记录:返回实体对象或
Map。 - 查询多条记录:返回
List或Set。 - 插入/更新:返回
int表示影响行数。
- 查询单条记录:返回实体对象或
- 动态代理的实现:MyBatis使用JDK动态代理,代理对象实现了Mapper接口,所有方法调用都会被
MapperProxy的invoke方法拦截,最终调用SqlSession的相应方法。 - Spring集成:在Spring中,通过
MapperFactoryBean或@MapperScan将Mapper接口注册为Bean,Spring在启动时会自动创建代理对象并注入。 - 接口方法与SQL映射的对应关系:MyBatis通过
方法签名(包括方法名和参数类型)查找SQL,但只使用方法名。因此,如果两个方法名相同但参数不同,会抛出异常,提示重复的statement。 - 泛型支持:接口方法返回值可以是泛型,如
List<T>,但需要在XML中配置resultType为具体类型,或使用resultMap。 - 批量操作:接口方法可以使用
List参数实现批量插入,通过<foreach>标签遍历。 - 注意事项:
- 接口方法不能重载,但可以通过默认方法(Java 8+)提供默认实现,但默认方法不会被代理,需注意。
- 如果使用注解和XML同时配置相同的方法,XML会覆盖注解(通常以XML为准)。
- 确保
mybatis.mapper-locations(Spring Boot)或mapperLocations(Spring)配置正确,以便MyBatis扫描到XML文件。
分页和插件
【问题】 Mybatis是如何进行分页的?分页插件的原理是什么?简述Mybatis的插件运行原理以及如何编写一个插件?
【答案】 一、Mybatis 如何进行分页? Mybatis 提供以下几种分页方式:
内存分页(RowBounds)
使用RowBounds对象在 SQL 查询时传入偏移量和限制条数。Mybatis 会执行 SQL 获取所有数据,然后在内存中进行截取。这种方式适用于小数据量,大数据量时性能极差(消耗内存和网络)。
示例:List<User> list = sqlSession.selectList("getUserList", null, new RowBounds(0, 10));物理分页(手动编写 SQL)
在 Mapper 的 SQL 语句中直接编写数据库特定的分页语法,如 MySQL 的LIMIT #{offset}, #{pageSize}。这种方式性能好,但需要为不同数据库编写不同 SQL,且每个查询都要手动处理。
示例:SELECT * FROM user LIMIT #{offset}, #{pageSize}使用分页插件
最常见的方式,通过插件(如 PageHelper)自动拦截 SQL,在运行时动态拼接分页语句,并自动执行 count 查询获取总记录数。对业务代码无侵入,只需在调用前设置分页参数。
示例:PageHelper.startPage(pageNum, pageSize); List<User> list = userMapper.selectAll();
二、分页插件的原理是什么? 分页插件基于 Mybatis 的插件(Interceptor)机制,核心原理如下:
- 分页插件实现了
Interceptor接口,通过@Intercepts注解拦截 Executor 的query方法(或StatementHandler的prepare方法)。 - 在拦截方法中,插件判断当前操作是否需要分页(通常通过线程上下文中的分页参数)。
- 如果需要分页,插件会:
- 拦截原始的 SQL 语句。
- 根据数据库方言(如 MySQL、Oracle)将 SQL 包装成分页查询语句(例如在原 SQL 后添加
LIMIT)。 - 同时,自动生成一个 count 查询(将原 SQL 包装为
SELECT COUNT(*) FROM (原SQL) temp),并执行以获取总记录数。 - 将分页参数设置到 SQL 中,执行分页查询。
- 最后将分页结果封装为
PageInfo等分页对象返回。
以 PageHelper 为例,它在 Executor 的 query 方法前拦截,通过 Dialect 接口适配不同数据库,完成动态 SQL 改写。
三、Mybatis 的插件运行原理以及如何编写一个插件?
- 插件运行原理 Mybatis 允许在四大核心对象的方法执行过程中进行拦截:
- Executor(执行器):负责增删改查操作。
- StatementHandler(语句处理器):负责处理 SQL 语句的预编译、参数设置和结果集处理。
- ParameterHandler(参数处理器):负责设置预编译语句的参数。
- ResultSetHandler(结果集处理器):负责将结果集映射为 Java 对象。
Mybatis 通过 JDK 动态代理为这些核心对象创建代理对象。当调用它们的方法时,会经过插件链,每个插件都有机会执行增强逻辑。插件需要实现 Interceptor 接口,并使用 @Intercepts 注解声明要拦截的方法签名。
- 如何编写一个插件? 编写一个自定义插件通常包含以下步骤:
步骤 1:实现 Interceptor 接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class MyPlugin implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 在目标方法执行前可以加入增强逻辑
System.out.println("Before method: " + invocation.getMethod());
// 执行目标方法(即被拦截的原方法)
Object result = invocation.proceed();
// 在目标方法执行后可以加入增强逻辑
System.out.println("After method");
return result;
}
@Override
public Object plugin(Object target) {
// 使用 Mybatis 提供的 Plugin 工具生成代理对象
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
// 可以获取配置文件中传入的参数
}
}
步骤 2:使用 @Intercepts 和 @Signature 指定拦截的目标
1
2
3
4
5
6
7
8
9
10
@Intercepts({
@Signature(
type = Executor.class, // 拦截的对象类型
method = "query", // 要拦截的方法名
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class} // 方法参数类型
)
})
public class MyPlugin implements Interceptor {
// ...
}
步骤 3:在 Mybatis 配置文件中注册插件
1
2
3
4
5
<plugins>
<plugin interceptor="com.example.MyPlugin">
<property name="someProperty" value="someValue"/>
</plugin>
</plugins>
或者在 Spring Boot 中通过 @Configuration 注册 Interceptor 到 SqlSessionFactory。
插件执行流程:当 Mybatis 创建核心对象(如 Executor)时,会遍历所有已注册的插件,调用每个插件的 plugin 方法生成代理对象,最终形成一个代理链。当调用目标方法时,会依次执行插件的 intercept 方法,直到最后一个代理才执行真正的方法。
【大白话解释】
- 分页方式:Mybatis 分页有三种方法:第一种是“假分页”,把所有数据查出来再在内存里切分(RowBounds),就像去图书馆把所有书搬回家,再挑几本看,书少还行,书多了累死。第二种是“手动分页”,写 SQL 时自己加 LIMIT,就像告诉图书管理员只要第1-10本书,但每次都要自己说。第三种是“插件分页”,用一个智能助手(PageHelper),你只要说“我要第2页,每页10本”,助手会自动帮你改 SQL,还帮你数总共有多少本书,省心省力。
- 分页插件原理:插件就像给 Mybatis 装了个“监听器”,在执行 SQL 前偷看你的指令,如果发现有分页要求,就悄悄把 SQL 改成分页形式,再执行。
- 插件原理:Mybatis 把核心对象都包了一层代理,就像给每个核心员工配了个“监督员”。你可以在监督员那里设规则(插件),当员工做某些事(方法调用)时,监督员就会插一脚,先干点别的,再让员工继续干。
- 编写插件:就像自己设计一个监督员,需要告诉他:你要监督谁(Executor 等)、他做什么事时你要干预(方法名和参数)、干预时做什么(intercept 方法)。写好后注册到 Mybatis 的“监督员名单”里。
【扩展知识点详解】
- 插件拦截的四大对象和方法:
Executor:update、query、commit、rollback等。StatementHandler:prepare、parameterize、batch、update、query等。ParameterHandler:getParameterObject、setParameters。ResultSetHandler:handleResultSets、handleOutputParameters等。
多个插件的执行顺序:按照配置文件中
plugin标签的先后顺序组成责任链,先配置的先执行其intercept方法中的前置逻辑,后配置的后执行前置逻辑;执行proceed()时会进入下一个插件,最后才执行真实方法;后置逻辑的执行顺序与前置相反。- PageHelper 分页插件的内部实现:
- 使用
ThreadLocal存储分页参数,确保线程隔离。 - 在拦截器中判断是否有分页参数,有则调用
Dialect的getCountSql和getPageSql方法生成 count 查询和分页查询。 - 执行 count 查询后,将结果封装到
Page对象中,并继续执行分页查询,最后将分页数据放入PageInfo。
- 使用
- 编写插件的注意事项:
- 必须正确声明
@Signature的args,必须与原方法参数类型完全一致,否则无法拦截。 plugin方法通常直接使用Plugin.wrap(target, this),它会自动创建代理对象。- 在
intercept方法中,一定要调用invocation.proceed()以执行原方法,否则会阻断调用链。 - 插件可能影响性能,应谨慎使用,避免在频繁调用的方法中做耗时操作。
- 必须正确声明
- 常见插件用途:
- 分页插件(如 PageHelper)
- 性能监控插件(打印 SQL 执行时间)
- 数据权限插件(动态拼接权限条件)
- 逻辑删除插件(自动追加未删除条件)
- Mybatis 的插件限制:只能拦截上述四大对象,不能拦截自定义对象。如果需要更灵活的控制,可以考虑使用 Mybatis-Plus 的扩展功能。
标签
【问题】 Mybatis 映射文件中,如果A 标签通过include 引用了B 标签的内容,请问,B 标签能否定义在A 标签的后面,还是说必须定义在A 标签的前面?
【答案】 在 MyBatis 的映射文件(XML)中,通过 <include> 标签引用的 SQL 片段(<sql> 标签)可以定义在被引用的位置之后,即 B 标签可以定义在 A 标签的后面,不需要强制放在前面。
这是因为 MyBatis 在解析 XML 映射文件时,会先读取整个文档,建立所有 <sql> 片段的 ID 与内容的映射关系,然后再处理其他标签中的 <include> 引用。因此,无论 <sql> 片段定义在文件中的哪个位置(前后均可),只要其 ID 唯一且在同一个文件中,<include> 都能正确找到并引用。
需要注意的是:如果通过 refid 引用其他文件中的 <sql> 片段(如 namespace.sqlId),则必须确保被引用的 namespace 对应的映射文件已被加载,且该文件的 <sql> 片段定义在引用之前或之后并无影响,因为所有映射文件在加载后都会合并到全局配置中。
【大白话解释】 MyBatis 读取 XML 文件就像老师批改试卷:老师会先把整张卷子(整个 XML 文件)浏览一遍,把所有填空题(<sql> 标签)的答案先记在心里,然后再去看其他题目(<include>)里引用这些答案的地方。所以,即使某道题的答案写在卷子的最后一页,也不影响前面题目引用它。
【扩展知识点详解】
MyBatis 解析 XML 的顺序:MyBatis 使用 XML 解析器(如 XPath)加载整个文档到 DOM 树,然后递归处理各个节点。在解析过程中,会先收集所有的
<sql>节点存入 Configuration 对象中,之后当遇到<include>时,直接从 Configuration 中根据refid获取对应的 SQL 片段,因此不依赖物理顺序。<include>的refid属性:可以引用本文件内的 SQL 片段(直接写 ID),也可以引用其他文件中的 SQL 片段(格式为namespace.sqlId)。跨文件引用时,被引用的 namespace 必须在 MyBatis 配置中已经注册,且该 SQL 片段的 ID 在对应 namespace 中唯一。<include>支持属性传递:可以通过<property>子标签向被引用的 SQL 片段传递参数,例如:1 2 3 4 5
<sql id="userColumns">${alias}.id, ${alias}.name</sql> <select id="selectUser"> SELECT <include refid="userColumns"><property name="alias" value="u"/></include> FROM user u </select>
在解析时,
${alias}会被替换为u。注意事项:
<sql>片段的 ID 在同一个映射文件中必须唯一。- 如果
<include>引用的 SQL 片段不存在,MyBatis 会在启动时抛出异常,提示找不到对应的 SQL 片段。 - 在使用
<include>时,可以结合动态 SQL 标签(如<if>),但要注意被包含的 SQL 片段本身可能也包含动态标签,解析时会递归处理。
实践建议:虽然顺序不重要,但从代码可读性和维护性角度,通常将公共的
<sql>片段放在文件顶部,以便快速查找和管理。但这仅仅是编码风格问题,不影响功能。
【问题】 如何用MyBatis优化批量插入?
【答案】 MyBatis 中优化批量插入主要从减少SQL执行次数、合理使用批处理和控制事务粒度三个方面入手。以下是几种常用的优化方案:
- 使用 foreach 标签拼接多行插入(适用于 MySQL、PostgreSQL 等) 利用 MyBatis 的动态 SQL 功能,在一个
insert语句中拼接多个values,一次请求插入多条记录。这种方式能显著减少网络往返次数和数据库解析 SQL 的开销。
示例:
1
2
3
4
5
6
<insert id="batchInsert" parameterType="list">
INSERT INTO user (name, age) VALUES
<foreach collection="list" item="item" separator=",">
(#{item.name}, #{item.age})
</foreach>
</insert>
注意:
- 拼接的 SQL 长度受数据库
max_allowed_packet限制,需控制单次插入的记录数(如每次 500-1000 条)。 - 适用于 MySQL,Oracle 等数据库需要改用其他语法(如 Oracle 的
INSERT ALL)。
- 使用 MyBatis 的 BatchExecutor MyBatis 支持三种执行器类型:
SIMPLE、REUSE、BATCH。通过开启BATCH执行器,可以将多次 insert 语句的预编译和参数设置合并为一次网络往返,大幅提升性能。
实现方式:
- 在 Spring 中配置
SqlSessionTemplate的executorType为BATCH。 - 或者手动获取
SqlSession:sqlSessionFactory.openSession(ExecutorType.BATCH)。
示例:
1
2
3
4
5
6
7
try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false)) {
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
for (User user : userList) {
mapper.insert(user);
}
sqlSession.commit(); // 批量提交
}
- 设置 JDBC 批处理参数 对于 MySQL,可以在 JDBC URL 中添加
rewriteBatchedStatements=true,驱动会将executeBatch()中的多条 insert 语句重写为一条多值 insert 语句,进一步提升效率。
1
jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true
分批次提交 无论使用哪种方式,都不应一次性插入海量数据(如几十万条),否则可能占用过多内存或导致事务锁过长。建议采用分片提交,每批次插入一定数量(如 1000 条)后提交事务,并清空缓存。
使用 MyBatis-Plus 的批量插入 如果使用 MyBatis-Plus,可以直接调用
saveBatch()方法,其内部封装了分批 + 批处理的逻辑,非常便捷。异步或并行插入 对于极端性能要求,可采用多线程并行插入不同批次,但需注意事务隔离和数据库连接池大小。
【大白话解释】
- foreach 拼接:就像写一封信,把多条记录合并成一条长清单寄出去,而不是每一条单独寄一封信。省去了反复拆信、读信的麻烦。
- BatchExecutor:好比让邮递员(MyBatis)把一堆信先攒起来,等攒够一捆再一起送去邮局(数据库)。邮局可以一次性处理这捆信,效率大大提高。
- rewriteBatchedStatements:相当于邮局的工作人员(JDBC驱动)看到一捆信,主动帮你在信封上合并地址,变成一封包含多个收件人的大信(多行 insert),进一步减少了处理步骤。
- 分批次提交:就像搬家,不能一次把所有家具都搬过去,否则车装不下、人也累。分几次搬,每次搬适量,既轻松又安全。
【扩展知识点详解】
- ExecutorType 的区别:
SIMPLE:每次执行 SQL 都创建一个新的预处理语句(PreparedStatement),执行完立即关闭。REUSE:复用预处理语句,避免重复创建,但仍是单条执行。BATCH:将多条 SQL 的预处理语句缓存起来,调用commit()或flushStatements()时一次性发送到数据库执行,减少网络往返。
批处理原理:JDBC 的
PreparedStatement支持addBatch()和executeBatch()。当开启BATCH执行器后,MyBatis 会调用addBatch()累积参数,最终由驱动批量发送。如果驱动不支持(如旧版本 MySQL),则可能回退为逐条执行。- 数据库限制:
- MySQL:
max_allowed_packet限制单次 SQL 包大小。若 foreach 拼接的 SQL 过大,需减小批次大小。 - Oracle:使用
INSERT ALL或批处理,但 Oracle 的批处理需要手动控制事务大小。 - SQL Server:支持
VALUES多行插入,但同样有大小限制。
- MySQL:
事务与缓存:批处理时,通常需要手动控制提交频率,避免长事务占用锁和连接。同时,一级缓存(SqlSession 级别)会在批处理中累积对象,需定期清理或分批次创建新的 SqlSession。
- 性能对比:
- 逐条插入:最慢,网络开销大。
- foreach 拼接多行:快,但 SQL 可能过长。
- BATCH 执行器 + 分片:通常是最佳平衡,兼具速度和可控性。
- BATCH + rewriteBatchedStatements:对于 MySQL,接近极限性能。
- 注意事项:
- 使用 BATCH 执行器时,返回的受影响行数可能不准确(驱动合并执行后返回的可能是总和)。
- 批处理中若某条数据失败,默认行为是抛异常,且可能无法回滚已成功的部分(取决于驱动和事务)。建议在业务允许的情况下分批+事务。
- 在 Spring 中,若使用
@Transactional且事务传播行为导致多个 SqlSession 共享同一事务,需确保使用相同的ExecutorType。
- 代码示例(Spring + MyBatis):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Autowired
private SqlSessionTemplate sqlSessionTemplate;
public void batchInsert(List<User> list) {
// 获取新的 SqlSession,使用 BATCH 执行器
SqlSession newSqlSession = sqlSessionTemplate.getSqlSessionFactory()
.openSession(ExecutorType.BATCH, false);
try {
UserMapper mapper = newSqlSession.getMapper(UserMapper.class);
for (int i = 0; i < list.size(); i++) {
mapper.insert(list.get(i));
if (i % 1000 == 0 || i == list.size() - 1) {
newSqlSession.commit(); // 每1000条提交一次
newSqlSession.clearCache();
}
}
} finally {
newSqlSession.close();
}
}
【问题】 在MyBatis中如何获取自动生成的主键值?
【答案】 在 MyBatis 中获取自动生成的主键值主要有三种方式:基于 XML 配置、基于注解配置以及使用 <selectKey> 标签。具体如下:
- 基于 XML 配置(推荐) 在
<insert>标签中使用useGeneratedKeys="true"和keyProperty属性。执行插入后,MyBatis 会将数据库自动生成的主键值设置到传入实体对象的指定属性中。
示例:
1
2
3
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(name, age) VALUES(#{name}, #{age})
</insert>
调用后,user.getId() 即可获取生成的主键值。
如果需要指定数据库中的列名,可额外添加 keyColumn 属性(例如当主键列名与属性名不一致时)。
- 基于注解配置 在 Mapper 接口的方法上使用
@Options注解,同样设置useGeneratedKeys = true和keyProperty。
示例:
1
2
3
@Insert("INSERT INTO user(name, age) VALUES(#{name}, #{age})")
@Options(useGeneratedKeys = true, keyProperty = "id")
int insertUser(User user);
- 使用
<selectKey>标签(适用于非自增主键或特殊需求) 对于不支持自动生成主键的数据库(如 Oracle 的序列),或需要自定义主键生成逻辑的场景,可以使用<selectKey>标签在插入前(或后)执行查询获取主键值。
示例(Oracle 序列):
1
2
3
4
5
6
<insert id="insertUser">
<selectKey keyProperty="id" resultType="long" order="BEFORE">
SELECT SEQ_USER.NEXTVAL FROM DUAL
</selectKey>
INSERT INTO user(id, name, age) VALUES(#{id}, #{name}, #{age})
</insert>
order="BEFORE" 表示先查询序列值并设置到实体中,再执行插入;order="AFTER" 则先插入再查询(适用于 MySQL 自增主键,但通常不如 useGeneratedKeys 高效)。
- 批量插入获取主键 对于批量插入,需要数据库驱动支持返回批量生成的主键(如 MySQL)。配置方式与单条类似,但需注意:
- XML 中设置
useGeneratedKeys="true"和keyProperty,且keyProperty需指定为实体类中接收主键的属性(如list.id)。 - JDBC URL 中应添加
rewriteBatchedStatements=true以启用批量重写。
示例:
1
2
3
4
5
6
<insert id="batchInsert" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(name, age) VALUES
<foreach collection="list" item="item" separator=",">
(#{item.name}, #{item.age})
</foreach>
</insert>
插入后,list 中每个元素的 id 属性都会被自动填充。
【大白话解释】 MyBatis 获取自动生成的主键,就像你在超市购物结账时,收银员扫描完商品后,系统自动生成一个小票号。你希望收银员把这个小票号也写在你手上的购物清单(实体对象)上,这样你就不用再回去查了。
- useGeneratedKeys:告诉 MyBatis “帮我取回数据库自动生成的 ID”。
- keyProperty:指定要把 ID 塞到实体对象的哪个属性里(比如
id字段)。 - **
**:对于像 Oracle 这样不自增的数据库,你得先去“取号机”拿个号(查询序列),然后把号贴在商品上再结账。
【扩展知识点详解】
- 底层原理:
useGeneratedKeys依赖于 JDBC 的Statement.getGeneratedKeys()方法,数据库驱动需支持返回生成的主键(MySQL、PostgreSQL 等支持,Oracle 不自增故不支持)。 - keyColumn 的作用:当数据库主键列名与实体属性名不同时,可通过
keyColumn指定列名,确保正确映射。例如keyColumn="user_id"。 - 批量插入主键的限制:并非所有数据库驱动都支持批量返回主键。MySQL 需要驱动版本 5.1.7+ 并设置
rewriteBatchedStatements=true;Oracle 不支持批量返回,需用其他方式。 - selectKey 的适用场景:
- order=”BEFORE”:适用于序列、UUID 等需要在插入前生成主键的场景。
- order=”AFTER”:适用于自增主键(如 MySQL),但通常
useGeneratedKeys更简洁高效。
- 不同数据库的配置差异:
- MySQL:
useGeneratedKeys直接支持自增主键。 - PostgreSQL:支持
useGeneratedKeys,但需指定keyColumn为返回的列名(如id)。 - Oracle:使用序列 +
<selectKey>。 - SQL Server:支持
useGeneratedKeys,但需在 insert 语句中包含OUTPUT子句(或使用selectKey)。
- MySQL:
- MyBatis-Plus 的增强:MyBatis-Plus 通过
@TableId注解的type属性可配置主键生成策略(如IdType.AUTO、IdType.INPUT、IdType.SEQUENCE),底层自动处理主键获取,无需手动配置。 - 注意事项:
useGeneratedKeys仅对<insert>语句有效,对<update>、<delete>无效。- 如果实体对象中对应属性已有值,可能会被生成的主键覆盖。
- 对于批量插入,驱动返回的主键顺序可能与参数列表顺序不一致,需谨慎处理。
【问题】 Mybatis的xml中有哪些常用标签?一对一和一对多映射分别是如何实现的?如何用标签实现动态sql?
【答案】 一、Mybatis XML 中的常用标签 Mybatis 的映射文件中提供了丰富的标签,用于定义 SQL 语句、结果映射、动态 SQL 等。主要分为以下几类:
- 基础 CRUD 标签:
<select>:定义查询语句。<insert>:定义插入语句。<update>:定义更新语句。<delete>:定义删除语句。<sql>:定义可重用的 SQL 片段,可通过<include>引用。<include>:引用<sql>定义的片段。
- 结果映射标签:
<resultMap>:定义结果集与 Java 对象的映射规则。<id>:标记主键字段的映射。<result>:标记普通字段的映射。<association>:用于一对一关联的映射。<collection>:用于一对多关联的映射。<discriminator>:根据结果值决定使用不同的映射。
- 动态 SQL 标签:
<if>:条件判断。<choose>、<when>、<otherwise>:多条件分支。<where>:自动处理 WHERE 子句中的 AND/OR 前缀。<set>:自动处理 UPDATE 语句中的 SET 子句逗号。<foreach>:遍历集合,用于 IN 查询或批量操作。<trim>:自定义前缀、后缀以及要覆盖的字符串。<bind>:创建一个变量并绑定到上下文,用于模糊查询等。
二、一对一和一对多映射的实现方式 MyBatis 通过 <resultMap> 中的 <association> 和 <collection> 标签实现关联查询的映射。
- 一对一映射(使用
<association>) 场景:一个用户对应一个身份证(假设User类中有IdCard属性)。
嵌套结果:通过连接查询一次性查出所有字段,然后通过
<association>指定如何将结果集中的列映射到关联对象的属性。1 2 3 4 5 6 7 8 9 10 11 12 13 14
<resultMap id="userMap" type="User"> <id property="id" column="user_id"/> <result property="name" column="user_name"/> <association property="idCard" javaType="IdCard"> <id property="id" column="card_id"/> <result property="number" column="card_number"/> </association> </resultMap> <select id="selectUserWithIdCard" resultMap="userMap"> SELECT u.id as user_id, u.name as user_name, c.id as card_id, c.number as card_number FROM user u LEFT JOIN id_card c ON u.id = c.user_id WHERE u.id = #{id} </select>
嵌套查询:执行多条 SQL,先查用户,再根据用户 id 查身份证。通过
<association>的select属性指定另一个查询的 id,并传入参数。1 2 3 4 5 6 7 8
<resultMap id="userMap" type="User"> <id property="id" column="id"/> <result property="name" column="name"/> <association property="idCard" column="id" select="selectIdCardByUserId"/> </resultMap> <select id="selectIdCardByUserId" resultType="IdCard"> SELECT * FROM id_card WHERE user_id = #{userId} </select>
- 一对多映射(使用
<collection>) 场景:一个用户有多条订单(User类中有List<Order>属性)。
嵌套结果:连接查询,结果集中可能有多行(一个用户对应多个订单),MyBatis 会自动去重并填充集合。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
<resultMap id="userMap" type="User"> <id property="id" column="user_id"/> <result property="name" column="user_name"/> <collection property="orders" ofType="Order"> <id property="id" column="order_id"/> <result property="amount" column="order_amount"/> </collection> </resultMap> <select id="selectUserWithOrders" resultMap="userMap"> SELECT u.id as user_id, u.name as user_name, o.id as order_id, o.amount as order_amount FROM user u LEFT JOIN orders o ON u.id = o.user_id WHERE u.id = #{id} </select>
嵌套查询:先查用户,再根据用户 id 查询订单列表。
1 2 3 4 5 6 7 8
<resultMap id="userMap" type="User"> <id property="id" column="id"/> <result property="name" column="name"/> <collection property="orders" column="id" select="selectOrdersByUserId"/> </resultMap> <select id="selectOrdersByUserId" resultType="Order"> SELECT * FROM orders WHERE user_id = #{userId} </select>
三、如何用标签实现动态 SQL? 动态 SQL 通过组合标签在运行时根据条件生成不同的 SQL 语句。
<if>:用于条件判断,满足条件则拼接内部 SQL。1 2 3 4 5 6 7 8 9
<select id="findByCondition" resultType="User"> SELECT * FROM user WHERE 1=1 <if test="name != null and name != ''"> AND name LIKE CONCAT('%', #{name}, '%') </if> <if test="age != null"> AND age = #{age} </if> </select>
<where>:自动处理 WHERE 关键字,并去掉多余的 AND/OR。1 2 3 4 5 6 7 8 9 10 11
<select id="findByCondition" resultType="User"> SELECT * FROM user <where> <if test="name != null"> AND name = #{name} </if> <if test="age != null"> AND age = #{age} </if> </where> </select>
<choose>、<when>、<otherwise>:类似 Java 的 switch-case。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
<select id="findByCondition" resultType="User"> SELECT * FROM user <where> <choose> <when test="name != null"> AND name = #{name} </when> <when test="age != null"> AND age = #{age} </when> <otherwise> AND status = 'active' </otherwise> </choose> </where> </select>
<set>:用于 update 语句,自动处理 SET 子句中的逗号。1 2 3 4 5 6 7 8
<update id="updateUser"> UPDATE user <set> <if test="name != null">name = #{name},</if> <if test="age != null">age = #{age},</if> </set> WHERE id = #{id} </update>
<foreach>:遍历集合,常用于 IN 查询或批量插入。1 2 3 4 5 6
<select id="findByIds" resultType="User"> SELECT * FROM user WHERE id IN <foreach collection="list" item="id" open="(" separator="," close=")"> #{id} </foreach> </select>
<trim>:可以自定义前缀、后缀,以及要覆盖的字符串(如AND、OR、逗号),是<where>和<set>的基础。1 2 3 4
<trim prefix="WHERE" prefixOverrides="AND |OR "> <if test="name != null">AND name = #{name}</if> <if test="age != null">AND age = #{age}</if> </trim>
<bind>:在 XML 中定义一个变量,常用于模糊查询。1 2 3 4
<select id="findByName" resultType="User"> <bind name="pattern" value="'%' + name + '%'"/> SELECT * FROM user WHERE name LIKE #{pattern} </select>
【大白话解释】
- 常用标签:就像乐高积木,每种标签都有特定形状和用途。
<select>是“查询积木”,<if>是“条件积木”,<where>是“自动修正 WHERE 的积木”,把它们拼起来就能搭出复杂的 SQL 语句。 - 一对一映射:好比一个人(User)随身带着一张身份证(IdCard),你要把这两个对象组装起来。MyBatis 提供两种方式:
- 嵌套结果:一次 SQL 把人和身份证的信息都查出来,然后按字段分装到两个对象里。就像你一次性拿到人的资料和身份证复印件,然后手动把身份证复印件塞到人的档案袋里。
- 嵌套查询:先查人,拿到人后再根据人的 id 去查身份证,然后塞进去。就像先找到人的档案,再根据档案里的身份证号去另一个柜子找身份证原件。
- 一对多映射:好比一个人有多个订单,你要把订单列表塞到人的对象里。同样有两种方式:
- 嵌套结果:一次 SQL 查出人和他的所有订单(可能多条),MyBatis 会自动识别哪些列是人的信息(根据主键去重),哪些是订单信息,然后组装成列表。
- 嵌套查询:先查人,然后根据人的 id 执行另一条 SQL 查出所有订单,再把订单列表塞给人。
- 动态 SQL:就像根据不同情况自动调整 SQL 语句。比如用户搜索时,可能填了姓名,也可能填了年龄,用
<if>判断哪个条件有值,就拼接到 SQL 里。<where>会自动处理多余的 AND,<foreach>可以生成IN (1,2,3)这样的语句。
【扩展知识点详解】
- **
和 的常用属性**: property:关联的属性名。javaType/ofType:关联对象的类型(ofType用于集合,指定泛型类型)。column:传递给嵌套查询的字段(可多个,用{key1=col1, key2=col2}形式)。select:指定嵌套查询的 statement id。fetchType:设置懒加载(lazy或eager),可覆盖全局配置。
懒加载:通过配置
lazyLoadingEnabled=true和aggressiveLazyLoading=false,可以实现关联对象的按需加载,提高性能。动态 SQL 的底层原理:MyBatis 使用 OGNL 表达式解析参数,通过 XML 解析器将标签组合成 SQL 源,在运行时动态生成最终的 SQL 语句。
- **
的详细用法**: prefix:添加的前缀。suffix:添加的后缀。prefixOverrides:忽略的前缀(如AND、OR)。suffixOverrides:忽略的后缀(如逗号)。
**
的 collection 取值**:可以是 `List`、`Array`、`Map` 等。当参数为 `List` 时,默认使用 `list` 作为 key;数组默认使用 `array`;`@Param` 注解可指定名称。 **
的作用域**:定义的变量仅在当前 SQL 语句中有效,可以用于拼接模糊查询、动态表名等。 映射继承:
<resultMap>支持通过extends属性继承另一个 resultMap,减少重复配置。**鉴别器
**:根据某列的值,选择不同的 resultMap,实现多态映射(例如,根据用户类型映射不同子类)。 SQL 片段的复用:使用
<sql id="baseColumns">定义常用列,然后用<include refid="baseColumns"/>引用,避免重复编写。- 最佳实践:
- 对于关联查询,优先考虑嵌套结果(一条 SQL)以减少数据库交互。
- 如果数据量较大,可使用嵌套查询并开启懒加载。
- 动态 SQL 中注意判断 null 和空字符串,避免生成无效条件。
- 使用
<bind>处理模糊查询可以避免不同数据库的兼容性问题。
懒加载和缓存
【问题】 Mybatis的一级、二级缓存分别是如何实现的?Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
【答案】 一、Mybatis 一级缓存的实现 一级缓存是 Mybatis 默认开启且无法关闭的缓存,其作用域是 SqlSession 级别(也称为会话级缓存)。
- 存储结构:每个 SqlSession 对应一个
Executor执行器对象,在执行器BaseExecutor中维护了一个PerpetualCache实例,而PerpetualCache内部核心就是一个简单的HashMap。 - 缓存 Key 的生成:缓存的 Key 由以下要素共同决定,用于唯一标识一次查询:
- Mapper 的 statementId(命名空间 + SQL id)。
- 查询条件中的参数对象。
- 分页所需的 RowBounds 对象。
- 具体的 SQL 语句字符串。
- 生命周期与失效:
- 在同一个 SqlSession 中执行两次完全相同的查询,第二次会直接从缓存中获取结果。
- 如果在 SqlSession 中执行了 insert、update、delete 等 DML 操作,无论是否提交,都会清空该 SqlSession 的一级缓存,以保证数据一致性。
- 当 SqlSession 执行
close()或clearCache()方法时,缓存也会被清空或释放。
二、Mybatis 二级缓存的实现 二级缓存是 mapper 级别(namespace 级别) 的缓存,可被多个 SqlSession 共享,默认关闭,需要手动开启。
- 开启方式:
- 全局开关:在 Mybatis 核心配置文件中设置
<setting name="cacheEnabled" value="true"/>(默认为 true)。 - 局部开关:在具体的 Mapper XML 文件中添加
<cache/>标签,并可配置缓存策略(如 LRU、FIFO)、刷新间隔、大小和只读属性等。
- 全局开关:在 Mybatis 核心配置文件中设置
- 实现机制:
- 当二级缓存开启后,Mybatis 会使用
CachingExecutor装饰器模式对原有的Executor进行包装。 CachingExecutor在真正执行查询前,会先根据缓存 Key 在二级缓存中查找。- 二级缓存的 Key 生成规则与一级缓存相同,但其缓存对象存储在全局的
Configuration对象中,供所有 SqlSession 共享。
- 当二级缓存开启后,Mybatis 会使用
- 查询顺序:当二级缓存开启后,数据的查询流程为 二级缓存 -> 一级缓存 -> 数据库。
- 失效机制:执行 DML 操作时,不仅会清空一级缓存,也会清空对应的二级缓存。
三、Mybatis 延迟加载的支持与实现原理 Mybatis 支持延迟加载(Lazy Loading),也称为懒加载。
什么是延迟加载: 在进行对象关联查询(如一对一、一对多)时,并不立即执行关联对象的 SQL,而是先返回一个代理对象。只有当真正调用关联对象的属性或方法时,才会触发 SQL 去数据库加载数据。
- 配置方式:
- 全局配置:在 Mybatis 主配置文件中设置
<setting name="lazyLoadingEnabled" value="true"/>。 - 局部配置:在
<association>或<collection>标签中设置fetchType="lazy"(优先级高于全局配置)。
- 全局配置:在 Mybatis 主配置文件中设置
- 实现原理(动态代理):
- 当 Mybatis 解析到关联映射配置了延迟加载后,它并不会直接创建目标对象,而是使用 Javassist 或 CGLIB 动态代理技术为目标属性创建一个代理对象。
- 该代理对象持有执行查询所需的信息(如 statementId、参数、SqlSession 等)。
- 当应用程序首次访问该代理对象的任何方法(如
getXxx())时,代理对象会拦截这次调用,检查数据是否已加载。 - 若未加载,代理对象会通过持有的信息发起一次数据库查询,将结果填充到代理对象中,并最终返回真实数据。后续对同一属性的访问将直接返回已加载的数据。
【大白话解释】
- 一级缓存:就像你(SqlSession)办公桌上放着一个个人笔记本。每次查数据都先看看笔记本里有没有记过,有就直接用,没有才去大档案室(数据库)翻,并把结果记下来。如果此时你在桌上改了任何数据(DML操作),为了避免出错,你会立刻把这个笔记本全部撕掉,保证下次查的是最新的。
- 二级缓存:就像是整个部门(同一个 namespace)公用的一个公共文件柜。你桌子上的笔记本(一级缓存)找不到数据时,会先去公共柜子里找找有没有其他同事留下的记录。如果公共柜子开启了(需要手动配置),大家都可以共享。
- 延迟加载:就像你点了一份“豪华套餐”,里面包含一个主餐和一个甜品。服务员(Mybatis)先只把主餐端上来,甜品没上。当你吃完主餐,喊了一声“该上甜品了”(第一次调用关联属性的
get方法),服务员才去后厨把甜品端过来给你。这就避免了如果你没喊甜品,后厨就白做的资源浪费。
【扩展知识点详解】
- 一级缓存的特殊配置:虽然一级缓存无法关闭,但可以通过配置
localCacheScope为STATEMENT,使得每次查询结束后都清空缓存,相当于在 Statement 级别禁用缓存效果。 - Spring 整合的影响:在 Spring 环境中,如果没有开启事务,每次 Mapper 方法调用都会创建一个新的 SqlSession,此时一级缓存将失效。只有在开启了事务的同一个方法内,多个查询才会共享一级缓存。
- 分布式系统下的缓存:Mybatis 的一、二级缓存均为本地缓存。在分布式部署中,如果一个节点更新了数据库,其他节点的缓存无法感知,会导致数据一致性问题。因此,在分布式环境下通常建议禁用二级缓存,并将一级缓存设置为
STATEMENT级别,或使用 Redis 等分布式缓存方案自定义 Cache 实现。 - 自定义二级缓存:Mybatis 允许通过实现
org.apache.ibatis.cache.Cache接口来集成第三方缓存框架,如 Redis 或 Ehcache,以实现更强大的分布式缓存能力。 - 延迟加载的触发条件:除了直接调用关联对象的
getter方法外,配置项aggressiveLazyLoading默认为 false,当为 true 时,对主对象的任何属性调用都会触发所有关联对象的加载。