深度学习
关键概念:神经网络,CNNS,RNNS,Transformer
人工智能(AI):人工智能是使计算机模拟人类智能行为的科学,包括学习、推理和自我改进。
机器学习(ML):机器学习是人工智能的一个分支,它使计算机能够通过数据和算法自动学习并改进其性能。
深度学习(DL):深度学习是机器学习的一种方法,通过使用复杂的神经网络结构来处理大量数据,使得机器能够执行高级模式识别和预测。
深度学习算法试图模拟人类大脑的工作方式,其灵感来源于神经生物学,它通过对大量数据的学习,自动提取出数据的高层次特征和模式,从而实现图像识别语音识别、自然语言处理等任务。
按照架构的不同,神经网络可以分为:卷积神经网络(CNNs)、循环神经网络(RNNs)、Transformer网络等等。
同样是区分不同水果,这次你带着孩子去了超市那里有各种不同的水果,你没有解释每种水果的特点只是给孩子指出了哪些是苹果哪些是香蕉,他通过观察和比较,慢慢学会了辨认各种水果。在这个过程中,孩子的大脑(在这里比喻为深度学习模型)自动从复杂的视觉、嗅觉等信号中提取层次化的特征。比如圆形、条纹、颜色深浅、气味等,从而达到识别水果的目的。
自然语言处理(NLP)是人工智能和计算机科学的一个重要分支,旨在使计算机能够理解、解释和生成人类语言。它结合了计算机科学、语言学和数据科学的元素,用于解决与语言相关的各种问题。NLP的应用包括机器翻译、语音识别、情感分析、文本摘要、聊天机器人等。通过算法和大量的数据训练,NLP模型能够从复杂的语言输入中提取有意义的信息,从而在自动化服务、数据分析、内容生成等多个领域发挥重要作用。
SFT监督微调
SFT的过程类似于从中学生成长为大学生的阶段,在这个阶段我们会学习到专业知识,比如金融、法律等领域,我们的头脑会更专注于特定领域。对于大模型来说,在这个阶段它可以学习各种人类的对话语料,甚至是非常专业的垂直领域知识,在监督微调过程之后,它可以按照人类的意图去回答专业领域的问题。这时候我们向经过SFT的模型提问:“埃菲尔铁塔在哪个国家?”模型大概率会回答“法国”,而不是去补全后边的句子。这时候的模型已经可以按照人类的意图去完成基本的对话功能了,但是模型的回答有时候可能并不符合人类的偏好,它可能会输出一些涉黄、涉政、涉暴或者种族歧视等言论,这时候我们就需要对模型进行RLHF(基于人类反馈的强化学习)。
模型优化 微调是对预训练的人工智能模型进行进一步训练,以便它更好地适应特定的任务或数据集。
数据适应性 通过使用特定领域或任务的数据,微调调整模型的参数使其更适合于该特定环境。
性能提升 微调的目的是提高模型在特定任务上的表现,比如提升精度、减少错误率或提高处理速度。
Transformer架构
输入层,隐藏层,输出层
神经网络
模拟人脑判断
输入层:
X(光照强度),Y=0表示关灯,Y=1表示开灯
隐藏层:
Z=W(模型权重)X+B(模型偏移)
输出层:
Z<0.5则Y=0;Z>=0.5则Y=1
大模型
特点:
规模和参数量大,适应性和灵活性强,广泛数据集的预训练,计算资源需求量大
工作流程
分词化和词表映射
分词化(Tokenization)是自然语言处理(NLP)中的重要概念,它是将段落和句子分割成更小的分词(token)的过程。举一个实际的例子,以下是一个英文句子:I want to study ACA.为了让机器理解这个句子,对字符串执行分词化,将其分解为独立的单元。使用分词化,我们会得到这样的结果:[‘l’ ,’want’ ,’to’ ,’study’ ,’ACA’,.”] 将一个句子分解成更小的、独立的部分可以帮助计算机理解句子的各个部分,以及它们在上下文中的作用,这对于进行大量上下文的分析尤其重要。分词化有不同的粒度分类: -词粒度(Word-Level Tokenization)分词化,如上文中例子所示,适用于大多数西方语言,如英语。 -字符粒度(Character-Level)分词化是中文最直接的分词方法,它是以单个汉字为单位进行分词化。 -子词粒度(Subword-Level)分词化,它将单词分解成更小的单位,比如词根、词缀等。这种方法对于处理新词(比如专有名词、网络用语等)特别有效,因为即使是新词,它的组成部分(子词)很可能已经存在于词表中了。每一个token都会通过预先设置好的词表,映射为一个 tokenid,这是token 的“身份证”一句话最终会被表示为一个元素为token id的列表,供计算机进行下一步处理。
推理过程
大语言模型的工作概括来说是根据给定的文本预测下一个token。对我们来说,看似像在对大模型提问,但实际上是给了大模型一串提示文本,让它可以对后续的文本进行推理。大模型的推理过程不是一步到位的,当大模型进行推理时,它会基于现有的token,根据概率最大原则预测出下一个最有可能的token,然后将该预测的token加入到输入序列中,并将更新后的输入序列继续输入大模型预测下一个token,这个过程叫做自回归。直到输出特殊token(如
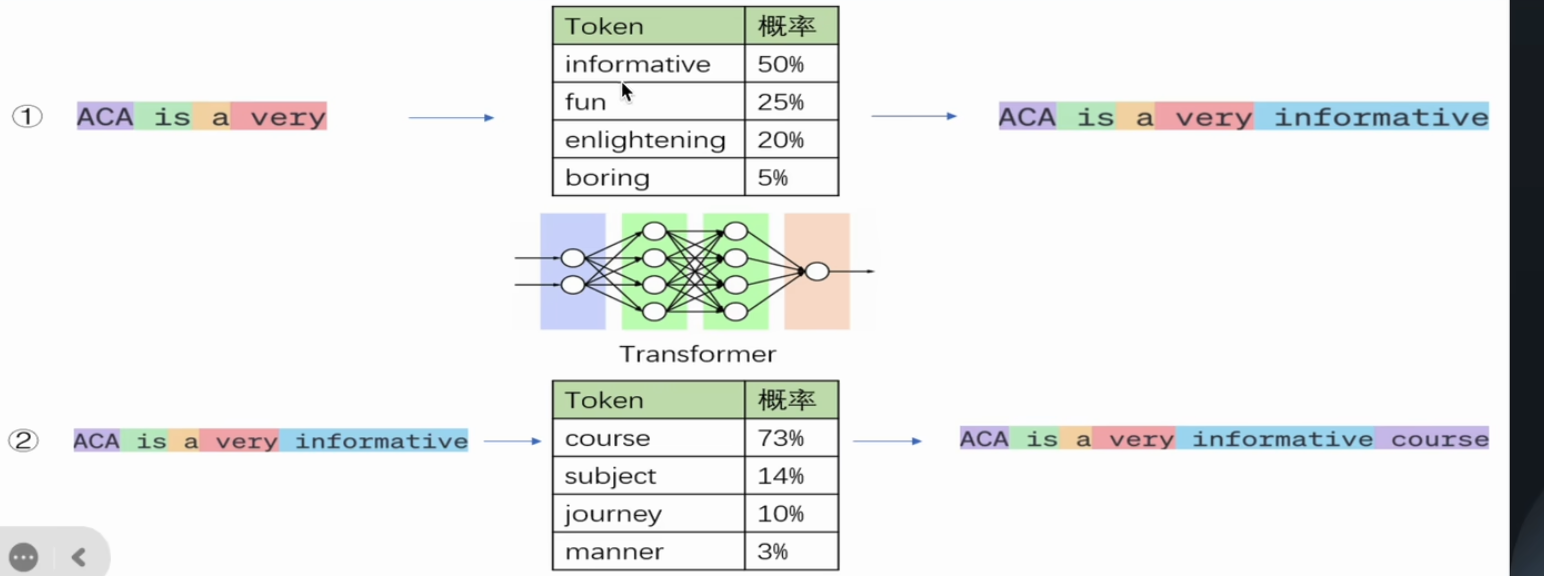
大语言模型LLM
这类大模型专注于自然语言处理(NLP),旨在处理语言、文章、对话等自然语言文本。它们通常基于深度学习架构(如Transformer模型),经过大规模文本数据集训练而成,能够捕捉语言的复杂性,包括语法、语义、语境以及蕴含的文化和社会知识。语言大模型典型应用包括文本生成、问答系统、文本分类、机器翻译、对话系统等。
示例包括:GPT系列(OpenAl):如GPT-3、GPT-3.5、GPT-4等。Bard(Google):谷歌推出的大型语言模型用于提供信息丰富的、有创意的文本输出。通义千问(阿里云):阿里云自主研发的超大规模的语言模型
多模态模型
多模态大模型能够同时处理和理解来自不同感知通道(如文本、图像、音频、视频等)的数据,并在这些模态之间建立关联和交互。它们能够整合不同类型的输入信息,进行跨模态推理、生成和理解任务。多模态大模型的应用涵盖视觉问答、图像描述生成、跨模态检索、多媒体内容理解等领域。
Agent
Agents是什么? 大语言模型可以接受输入,可以分析&推理、可以输出文字、代码、媒体。然而,其无法像人类一样,拥有规划思考能力、运用各种工具与物理世界互动,以及拥有人类的记忆能力。
AI Agents是基于LLM的能够自主理解、自主规划决策、执行复杂任务的智能体。
Agent的设计目的是为了处理那些简单的语言模型可能无法直接解决的问题,尤其是当这些任务涉及到多个步骤或者需要外部数据源的情况。
LLM:接受输入、思考、输出
人类:LLM(接受输入、思考、输出)+记忆+工具 +规划 ——>Agents
Agents工作与决策流程
工作流程:
规划(Planning):智能体会把大型任务分解为子任务,并规划执行任务的流程;智能体会对任务执行的过程进行思考和反思,从而决定是继续执行任务,或判断任务完结并终止运行。
记忆(Memory):短期记忆,是指在执行任务的过程中的上下文,会在子任务的执行过程产生和暂存,在任务完结后被清空。长期记忆是长时间保留的信息,一般是指外部知识库,通常用向量数据库来存储和检索。
工具使用(Tools):为智能体配备工具 AP,比如:计算器、搜索工具、代码执行器、数据库查询工具等。有了这些工具 AP,,智能体就可以是物理世界交互,解决实际的问题,比如当询问当日天气时,agent本身是不具备这种知识储备的,他需要去连接其他工具来获取。
执行(Action):根据规划和记忆来实施具体行动,这可能会涉及到与外部世界的互动或通过工具来完成任务
用一个流程图来表示
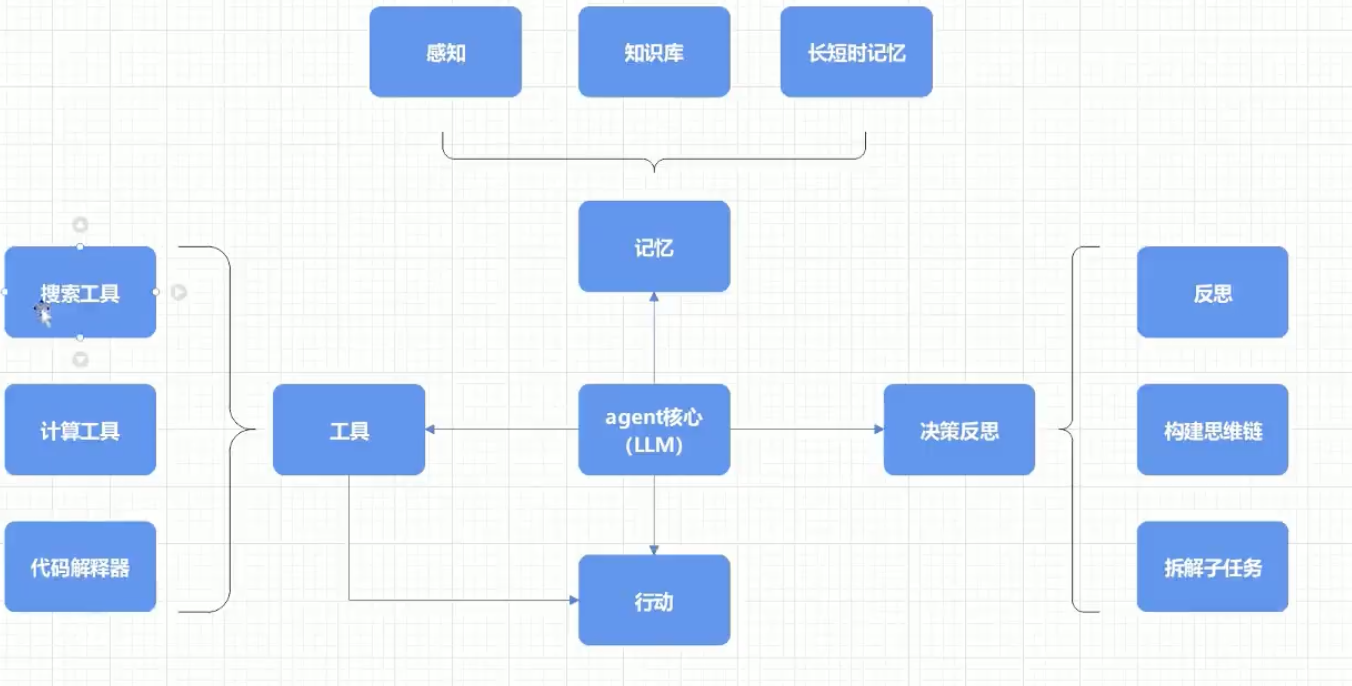
决策流程:
感知—》规划—》行动—》观察—》感知
Agents的决策流程,一个循环是一个task
一个实例场景:智能家居系统,根据语音指令调节室内环境
感知(Perception):语音助手监听到用户语言指令:“我感觉有点冷,把温度调高一些”
规划(planning):系统可能会定制以下计划:检测当前室内温度,根据用户指令决定升高几度合适,调整温度并告知用户
行动(action):系统执行计划
观察(Observation):系统检测室内温度,以及用户反馈,如果用户几分钟后再次说“温度刚好”,系统感知环境调节成功;如果用户还觉得冷,系统会调整计划
记忆
智能体中的记忆机制:
形成记忆:大模型在大量包含世界知识的数据集上进行预训练。在预训练中,大模型通过调整神经元的权重来学习理解和生成人类语言,这可以被视为”记忆”的形成过程。通过使用深度学习和梯度下降等技术,大模型可以不断提高基于预测或生产文本的能力,进而形成世界记忆或长期记忆
短期记忆:在当前任务执行过程中所产生的信息,比如某个工具或某个子任务执行的结果、会写入短期记忆中。记忆在当前任务过程中产生和暂存,在任务完结后被清空。
长期记忆:长期记忆是长时间保留的信息。一般是指外部知识库,通常用向量数据库来存储和检索。
工具使用
Agent可以通过学习调用外部API来获取模型权重中所缺少的额外信息,这些信息包括当前信息、代码执行能力和访问专有信息源等。这对于预训练后难以修改的模型权重来说是非常重要的。
常握使用工具是人类最独特和重要的特质之一,我们通过创造、修改和利用外部工具来突破我们身体和认知的限制。同样地,我们也可以为语言模型(LLM)提供外部工具来显著提升其能力。
ReAct框架
提示词工程
定义 Prompt Engineering 指的是在与人工智能系统交互时,如何精心设计和优化输入语句(prompts)的过程。这个过程关注于如何构造问题或命令,以从 AI 系统获取最有效和相关的回应。
关键性质 Prompt Engineering 重视语言的选择、上下文的应用,以及用户意图的明确表达。通过细致调整输入语句,可以优化AI的理解和响应,从而提升整体的交互体验。
1:明确目标,希望大模型为你做什么
2:优化提示,给大模型更加具体的指示
3:评估和迭代,通过不同的提示词问大模型同样的问题,以达到最佳效果
提示词工程的两大核心技术:
N-gram:原理是统计通过计算N个词共同出现的概率来预测下一个词,其中N是不固定参数,比如2-gram是使用前一个词来预测下一个词
深度学习:深度学习模型由多层神经网络组成的,可以自动从数据中学习的特征,让模型不断自我学习不断成长
提示词
Prompt(提示词)是指在使用大模型时,向模型提供的一些指令或问题。这些指令作为模型的输入,引导模型产生所需要的输出。例如,在生成文本时,Prompt 可能是一个问题或者一个句子开始的部分,模型需要根据这个提示来生成接下来的内容。
Embedding向量化
Embedding是一种将高维数据(如文本、图像或音频)转化为低维数值向量的技术。通过将复杂的特征信息映射到向量空间中,embedding能够捕捉数据的语义或特征相似性,使得机器能够更有效地处理、比较和搜索信息。
它的主要作用是将自然世界的文字、图片、语音、视频转化成计算机能识别的形式,也就是数字矩阵。
这个过程中大概有12000个维度
案例图
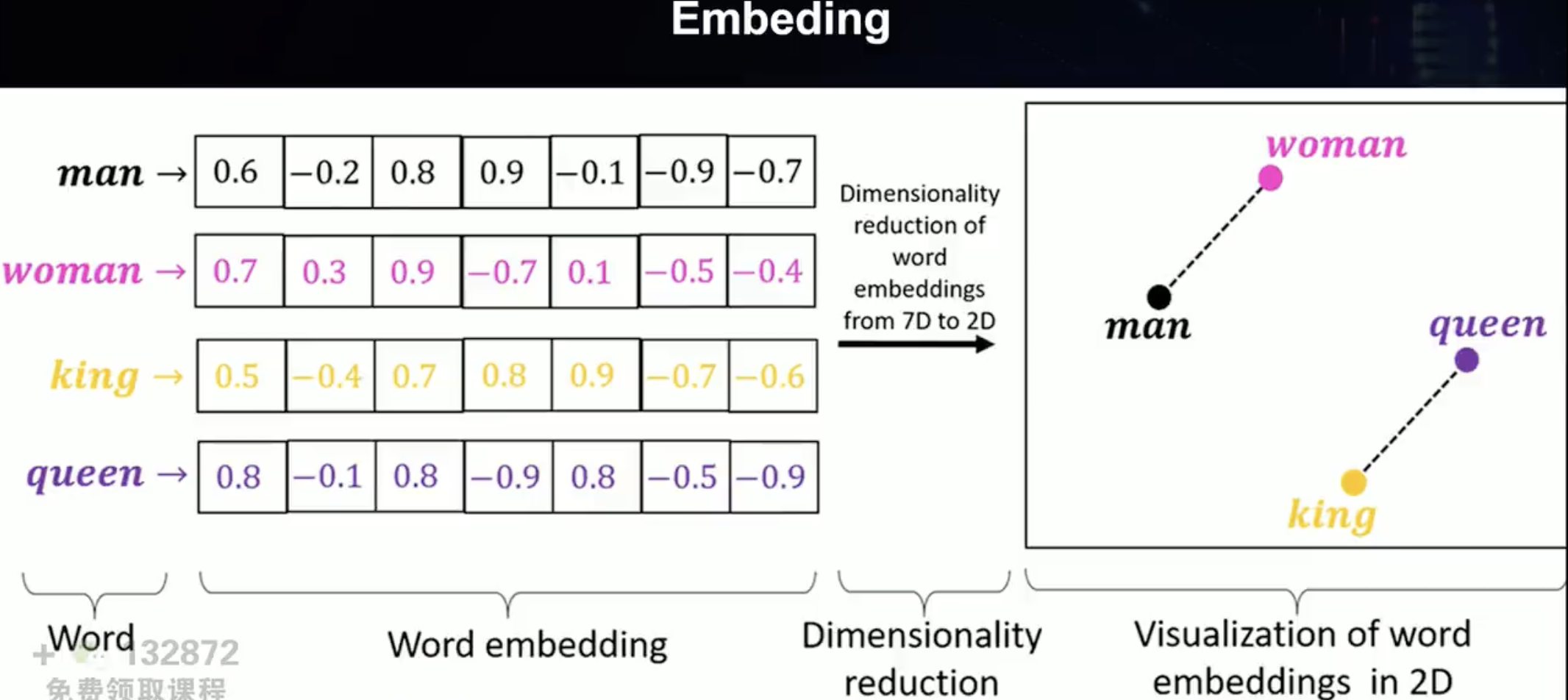
我们可以把每一列看成是一个维度,比如第一列以人类维度划分男人,女人,国王,王后,他们的得分基本相同,也就是相似度
RAG检索增强生成
宗旨是提高文本的准确性和丰富性
结合检索与生成:RAG融合了信息检索和文本生成两种技术,先从大数据中检索信息,再基于这些信息生成文本
增强生成质量:通过使用检索到的相关信息,RAG旨在提高文本生成的相关性,准确性和深度。
应用于复杂查询:RAG适用于需要广泛知识和深度理解的复杂查询,能够提供更丰富,更精确的回答。
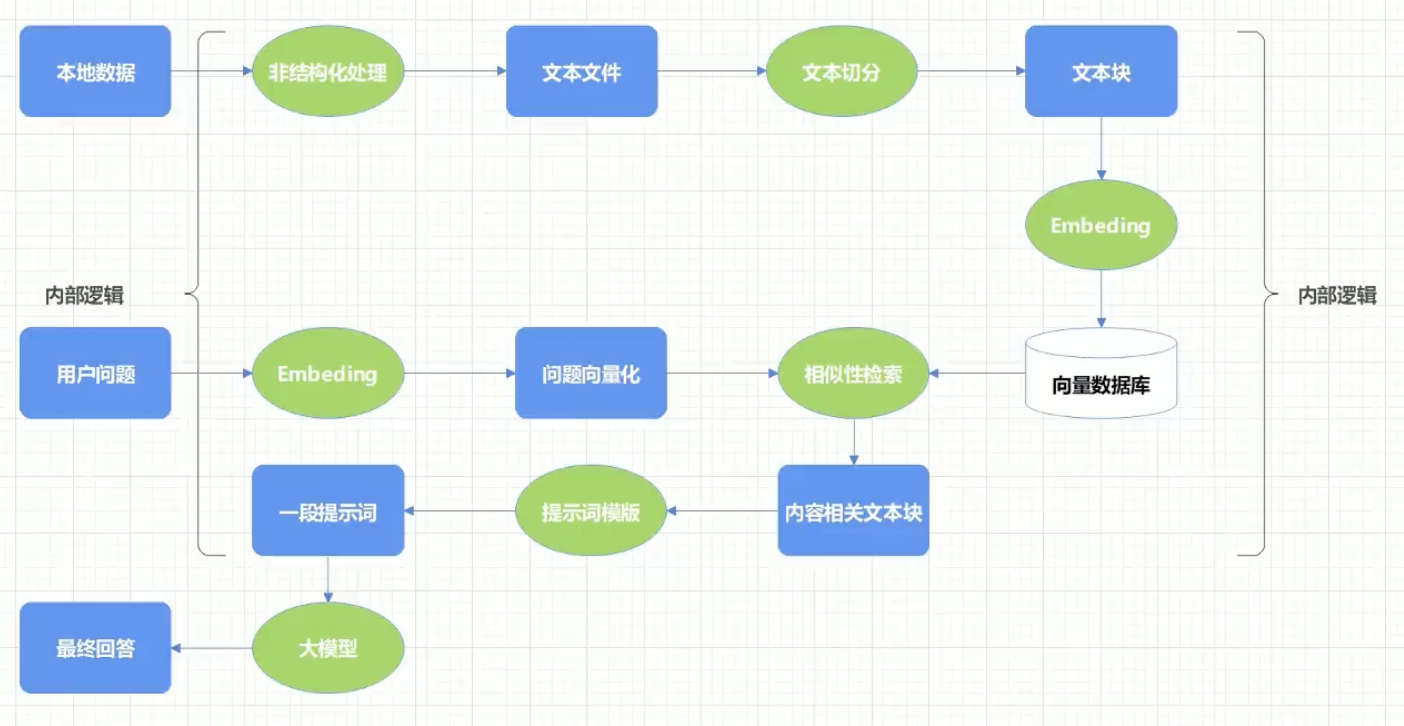
RAG流程图大致如下
为什么要使用RAG技术?RAG和模型微调的区别?
微调技术和RAG技术: 微调:在已有的预训练模型基础上,再结合特定任务的数据集进一步对其进行训练,使得模型在这一领域中表现更 好; RAG:在生成回答之前,通过信息检索从外部知识库中查找与问题相关的知识,增强生成过程中的信息来源,从 而提升生成的质量和准确性。
共同点:都是为了赋予模型某个领域的特定知识,解决大模型的幻觉问题。
RAG(Retrieval-Augmented Generation)的原理:
检索(Retrieval):当用户提出问题时,系统会从外部的知识库中检索出与用户输入相关的内容。
增强(Augmentation):系统将检索到的信息与用户的输入结合,扩展模型的上下文。然后再传给生成模型(也就是Deepseek);
生成(Generation):生成模型基于增强后的输入生成最终的回答。由于这一回答参考了外部知识库中的内容因此更加准确可读。
美团对于查询改写技术的探索与实践:https://tech.meituan.com/2022/02/17/exploration-and-practice-of-query-rewriting-in-meituan-search.html
Advanced RAG
高级 RAG 可以通过 LangChain4j 实现,涉及以下核心组件:
QueryTransformer(查询转换器) QueryRouter(查询路由器) ContentRetriever(内容检索器) ContentAggregator(内容聚合器) ContentInjector(内容注入器)
协同关系如下图
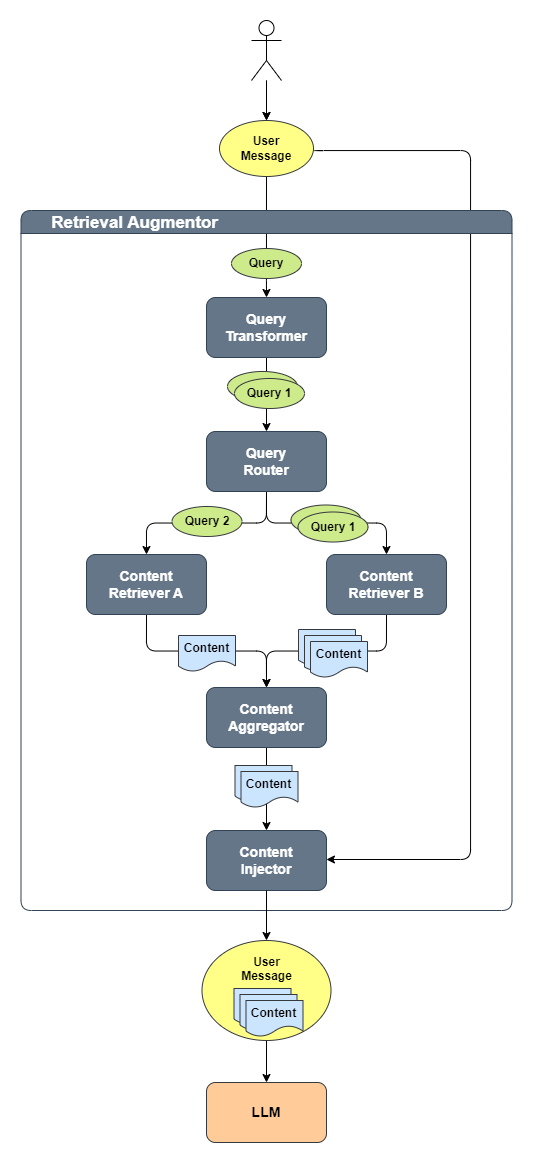
Retrieval Augmentor 检索增强器,是 Advanced RAG 管道的入口,主要分为以下几个步骤;
第一步,将 UserMessage 转换为 Query。 第二步,通过 QueryTransformer 组件将用户的 Query 转换为一个或者多个 Query。 第三步,通过 QueryRouter 将第二步转换的 Query 路由到其对应的 Content Retriever 检索内容。 第四步,ContentAggregator 将 Content Retriever 检索的内容合并到一个最终的排名列表中。 最后,将第四步产生的 Content 与 UserMessage组合,发给大模型。
LangChain框架
langchain是language和chain的组合,直译过来就是语言的链路,它代表了一种专门用于文本分析的先进链式处理工具
langchain的原理就是数据输入(手动输入,文件上传,数据库链接),数据分析,数据输出
langchain4j
Java版本的langchain框架
MCP协议
mcp