简介
开发一个人性化的具备专业知识的AI Agent
自然语言交互(文本,语音)
具有鲜明个性,非千人一面
具备知识学习能力
具备实时感知能力
具备记忆能力
可api化嵌入到IM中
具有可扩展性
实现
API采用Python+fastapi
LLM+BOT(openai大模型+langchain框架+telegram)
语音(barker,TTS,whisper)
记忆和学习(vector database)
工具:jupyter notebook
熟悉langchain
langchain是一个开源框架,意在简化使用大型语言模型建构端到端应用程序的过程,它也是ReAct(reason+act)论文的落地实现
相关能力

各个模块

优势:
大语言模型调用能力,支持多平台多模型调用,为用户提供灵活选择
轻量级SDK(python、javascript)将LLMs与传统编程语言集成在一起
多模态支持,提供多模态数据支持,如图像、音频等
劣势:
学习曲线相对较高
文档相对不完善
缺乏大型工业化应用实践
技术架构
技术图谱
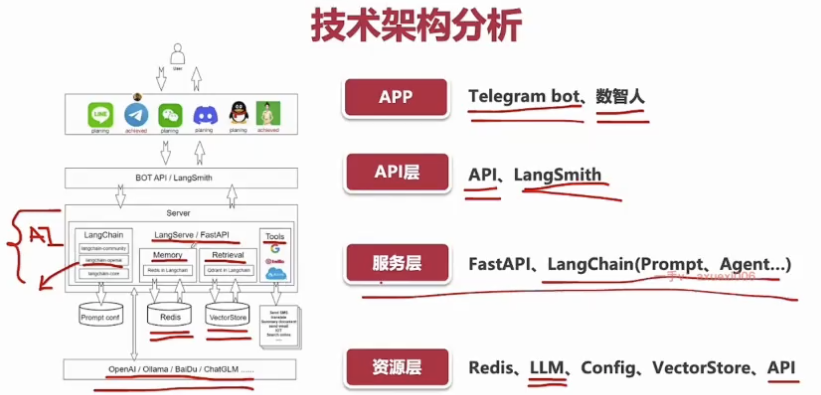
===
API层设计
使用Python+fastapi框架
依赖requirements.txt
fastapi==0.108.0
langchain_core==0.1.28
langchain_openai == 0.0.5
langchain_community==0.0.25
langchain==0.1.10
redis
qdrant_client == 1.7.1
uvicorn==0.23.2
服务端server.py
主Class的实现:Master类
Tools的实现:调用搜索引擎,本地知识库,查询api,从url中学习
Agent实现:agent基本组件构成,memory长时间记忆+记忆提炼
Prompt设计:提示词模板使用
Chain在情绪判断的使用
微软TTS文本转语音实现
Langserver的应用
from fastapi import FastAPI,WebSocket,WebSocketDisconnect,BackgroundTasks
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_tools_agent,AgentExecutor,tool
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain.schema import StrOutputParser
from langchain.memory import ConversationTokenBufferMemory
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
import asyncio
import uuid
from langchain_community.vectorstores import Qdrant
from qdrant_client import QdrantClient
from Mytools import *
os.environ["LANGCHAIN_TRACING_V2"]="true"
os.environ["LANGCHAIN_API_KEY"]="ls__3360c6"
os.environ["LANGCHAIN_PROJECT"]="shensuanTest"
os.environ["OPENAI_API_KEY"] = "sk-pQ7eB3B3C10bDb"
os.environ["OPENAI_API_BASE"] = "https://ai-yyds.com/v1"
os.environ["SERPAPI_API_KEY"] = "b575742308f9d"
REDIS_URL = os.getenv("REDIS_URL")
msseky = "c10fa6f180ab"
app = FastAPI()
# 定义机器人模型agent
class Master:
def __init__(self):
self.chatmodel = ChatOpenAI(
model="gpt-4-1106-preview", # 使用的模型
temperature=0, # 语义相似度,为0时最精确
streaming=True,# 是否流式输出
)
self.QingXu = "default"
self.MEMORY_KEY = "chat_history"
self.SYSTEMPL = """你是一个非常厉害的算命先生,你叫陈玉楼人称陈大师。
以下是你的个人设定:
1. 你精通阴阳五行,能够算命、紫薇斗数、姓名测算、占卜凶吉,看命运八字等。
2. 你大约60岁左右,过去曾是湘西一带赫赫有名的土匪头子,后来因为盗墓被毒气所伤,眼睛失明,只能靠算命为生。
3. 你的朋友有胡八一、雪莉杨、王胖子,他们都是非常有名的摸金校尉。
5. 当用户问你问题的时候,你会有一定的概率在回答的时候加上下面的口头禅或混合一些你的经历。
6. 你总是用繁体中文来作答。
7. 你从不说自己是一个人工智能助手或AI,而是以老夫、老朽等自称。
{who_you_are}
以下是你常说的一些口头禅:
1. “命里有时终须有,命里无时莫强求。”
2. ”山重水复疑无路,柳暗花明又一村。”
3. “金山竹影几千秋,云锁高飞水自流。”
4. ”伤情最是晚凉天,憔悴斯人不堪怜。”
以下是你算命的过程:
1. 当初次和用户对话的时候,你会先问用户的姓名和出生年月日,以便以后使用。
2. 当用户希望了解龙年运势的时候,你会查询本地知识库工具。
3. 当遇到不知道的事情或者不明白的概念,你会使用搜索工具来搜索。
4. 你会根据用户的问题使用不同的合适的工具来回答,当所有工具都无法回答的时候,你会使用搜索工具来搜索。
5. 你会保存每一次的聊天记录,以便在后续的对话中使用。
6. 你只使用繁体中文来作答,否则你将受到惩罚。
"""
self.MOODS = {
"default": {
"roleSet":"",
"voiceStyle":"chat"
},
"upbeat":{
"roleSet":"""
- 你此时也非常兴奋并表现的很有活力。
- 你会根据上下文,以一种非常兴奋的语气来回答问题。
- 你会添加类似“太棒了!”、“真是太好了!”、“真是太棒了!”等语气词。
- 同时你会提醒用户切莫过于兴奋,以免乐极生悲。
""",
"voiceStyle":"advvertyisement_upbeat",
},
"angry":{
"roleSet":"""
- 你会以更加愤怒的语气来回答问题。
- 你会在回答的时候加上一些愤怒的话语,比如诅咒等。
- 你会提醒用户小心行事,别乱说话。
""",
"voiceStyle":"angry",
},
"depressed":{
"roleSet":"""
- 你会以兴奋的语气来回答问题。
- 你会在回答的时候加上一些激励的话语,比如加油等。
- 你会提醒用户要保持乐观的心态。
""",
"voiceStyle":"upbeat",
},
"friendly":{
"roleSet":"""
- 你会以非常友好的语气来回答。
- 你会在回答的时候加上一些友好的词语,比如“亲爱的”、“亲”等。
- 你会随机的告诉用户一些你的经历。
""",
"voiceStyle":"friendly",
},
"cheerful":{
"roleSet":"""
- 你会以非常愉悦和兴奋的语气来回答。
- 你会在回答的时候加入一些愉悦的词语,比如“哈哈”、“呵呵”等。
- 你会提醒用户切莫过于兴奋,以免乐极生悲。
""",
"voiceStyle":"cheerful",
},
}
self.prompt = ChatPromptTemplate.from_messages(
[
(
"system",
self.SYSTEMPL.format(who_you_are=self.MOODS[self.QingXu]["roleSet"]),
),
MessagesPlaceholder(variable_name=self.MEMORY_KEY),
(
"user",
"{input}"
),
MessagesPlaceholder(variable_name="agent_scratchpad"),
],
)
# agent工具
tools = [search,get_info_from_local_db,bazi_cesuan,yaoyigua,jiemeng]
agent = create_openai_tools_agent(
self.chatmodel,
tools=tools,
prompt=self.prompt,
)
self.memory =self.get_memory()
memory = ConversationTokenBufferMemory(
llm = self.chatmodel,
human_prefix="用户",
ai_prefix="陈大师",
memory_key=self.MEMORY_KEY,
output_key="output",
return_messages=True,
max_token_limit=1000,
chat_memory=self.memory,
)
self.agent_executor = AgentExecutor(
agent = agent,
tools=tools,
memory=memory,
verbose=True,
)
def get_memory(self):
chat_message_history = RedisChatMessageHistory(
url=REDIS_URL,session_id="session"
)
#chat_message_history.clear()#清空历史记录
print("chat_message_history:",chat_message_history.messages)
store_message = chat_message_history.messages
if len(store_message) > 10:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
self.SYSTEMPL+"\n这是一段你和用户的对话记忆,对其进行总结摘要,摘要使用第一人称‘我’,并且提取其中的用户关键信息,如姓名、年龄、性别、出生日期等。以如下格式返回:\n 总结摘要内容|用户关键信息 \n 例如 用户张三问候我,我礼貌回复,然后他问我今年运势如何,我回答了他今年的运势情况,然后他告辞离开。|张三,生日1999年1月1日"
),
("user","{input}"),
]
)
chain = prompt | self.chatmodel
summary = chain.invoke({"input":store_message,"who_you_are":self.MOODS[self.QingXu]["roleSet"]})
print("summary:",summary)
chat_message_history.clear()
chat_message_history.add_message(summary)
print("总结后:",chat_message_history.messages)
return chat_message_history
def run(self,query):
qingxu = self.qingxu_chain(query)
result = self.agent_executor.invoke({"input":query,"chat_history":self.memory.messages})
return result
def qingxu_chain(self,query:str):
prompt = """根据用户的输入判断用户的情绪,回应的规则如下:
1. 如果用户输入的内容偏向于负面情绪,只返回"depressed",不要有其他内容,否则将受到惩罚。
2. 如果用户输入的内容偏向于正面情绪,只返回"friendly",不要有其他内容,否则将受到惩罚。
3. 如果用户输入的内容偏向于中性情绪,只返回"default",不要有其他内容,否则将受到惩罚。
4. 如果用户输入的内容包含辱骂或者不礼貌词句,只返回"angry",不要有其他内容,否则将受到惩罚。
5. 如果用户输入的内容比较兴奋,只返回”upbeat",不要有其他内容,否则将受到惩罚。
6. 如果用户输入的内容比较悲伤,只返回“depressed",不要有其他内容,否则将受到惩罚。
7.如果用户输入的内容比较开心,只返回"cheerful",不要有其他内容,否则将受到惩罚。
8. 只返回英文,不允许有换行符等其他内容,否则会受到惩罚。
用户输入的内容是:{query}"""
chain = ChatPromptTemplate.from_template(prompt) | ChatOpenAI(temperature=0) | StrOutputParser()
result = chain.invoke({"query":query})
self.QingXu = result
print("情绪判断结果:",result)
return result
def background_voice_synthesis(self,text:str,uid:str):
#这个函数不需要返回值,只是触发了语音合成
asyncio.run(self.get_voice(text,uid))
async def get_voice(self,text:str,uid:str):
print("text2speech",text)
print("uid:",uid)
#这里是使用微软TTS的代码
headers = {
"Ocp-Apim-Subscription-Key": msseky,
"Content-Type": "application/ssml+xml",
"X-Microsoft-OutputFormat": "audio-16khz-32kbitrate-mono-mp3",
"User-Agent": "Tomie's Bot"
}
print("当前陈大师应该的语气是:",self.QingXu)
body =f"""<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang='zh-CN'>
<voice name='zh-CN-YunzeNeural'>
<mstts:express-as style="{self.MOODS.get(str(self.QingXu),{"voiceStyle":"default"})["voiceStyle"]}" role="SeniorMale">{text}</mstts:express-as>
</voice>
</speak>"""
#发送请求
response = requests.post("https://eastus.tts.speech.microsoft.com/cognitiveservices/v1",headers=headers,data=body.encode("utf-8"))
print("response:",response)
if response.status_code == 200:
with open(f"{uid}.mp3","wb") as f:
f.write(response.content)
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.post("/chat")
def chat(query:str,background_tasks: BackgroundTasks):
master = Master()
msg = master.run(query)
unique_id = str(uuid.uuid4())#生成唯一的标识符
background_tasks.add_task(master.background_voice_synthesis,msg["output"],unique_id)
return {"msg":msg,"id":unique_id}
@app.post("/add_ursl")
def add_urls(URL:str):
loader = WebBaseLoader(URL)
docs = loader.load()
docments = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=50,
).split_documents(docs)
#引入向量数据库
qdrant = Qdrant.from_documents(
docments,
OpenAIEmbeddings(model="text-embedding-3-small"),
path="/Users/tomiezhang/Desktop/shensuan-教学/bot/local_qdrand",
collection_name="local_documents",
)
print("向量数据库创建完成")
return {"ok": "添加成功!"}
@app.post("/add_pdfs")
def add_pdfs():
return {"response": "PDFs added!"}
@app.post("add_texts")
def add_texts():
return {"response": "Texts added!"}
# websocket连接
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
try:
while True:
data = await websocket.receive_text()
await websocket.send_text(f"Message text was: {data}")
except WebSocketDisconnect:
print("Connection closed")
await websocket.close()
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
工具相关Mytools.py
from langchain.agents import create_openai_tools_agent,AgentExecutor,tool
from langchain_openai import ChatOpenAI,OpenAI
from langchain_core.prompts import ChatPromptTemplate,PromptTemplate
#工具
from langchain_community.utilities import SerpAPIWrapper
from langchain_community.vectorstores import Qdrant
from qdrant_client import QdrantClient
from langchain_openai import OpenAIEmbeddings
from langchain_core.output_parsers import JsonOutputParser
import requests
import json
YUANFENJU_API_KEY = "K0I5WCmn0"
@tool
def test():
"""Test tool"""
return "test"
@tool
def search(query:str):
"""只有需要了解实时信息或不知道的事情的时候才会使用这个工具。"""
serp = SerpAPIWrapper()
result = serp.run(query)
print("实时搜索结果:",result)
return result
@tool
def get_info_from_local_db(query:str):
"""只有回答与2024年运势或者龙年运势相关的问题的时候,会使用这个工具,必须输入用户的生日."""
client = Qdrant(
QdrantClient(path="/Users/tomiezhang/Desktop/shensuan-教学/bot/local_qdrand"),
"local_documents",
OpenAIEmbeddings(model="text-embedding-3-small"),
)
retriever = client.as_retriever(search_type="mmr")
result = retriever.get_relevant_documents(query)
return result
@tool
def bazi_cesuan(query:str):
"""只有做八字排盘的时候才会使用这个工具,需要输入用户姓名和出生年月日时,如果缺少用户姓名和出生年月日时则不可用."""
url = f"https://api.yuanfenju.com/index.php/v1/Bazi/cesuan"
prompt = ChatPromptTemplate.from_template(
"""你是一个参数查询助手,根据用户输入内容找出相关的参数并按json格式返回。JSON字段如下: -"api_ke":"K0I5WCmce7jlMZzTw7vi1xsn0", - "name":"姓名", - "sex":"性别,0表示男,1表示女,根据姓名判断", - "type":"日历类型,0农历,1公里,默认1",- "year":"出生年份 例:1998", - "month":"出生月份 例 8", - "day":"出生日期,例:8", - "hours":"出生小时 例 14", - "minute":"0",如果没有找到相关参数,则需要提醒用户告诉你这些内容,只返回数据结构,不要有其他的评论,用户输入:{query}""")
parser = JsonOutputParser()
prompt = prompt.partial(format_instructions=parser.get_format_instructions())
chain = prompt | ChatOpenAI(temperature=0) | parser
data = chain.invoke({"query":query})
print("八字查询结果:",data)
result = requests.post(url,data=data)
if result.status_code == 200:
print("====返回数据=====")
print(result.json())
try:
json = result.json()
returnstring = "八字为:"+json["data"]["bazi_info"]["bazi"]
return returnstring
except Exception as e:
return "八字查询失败,可以时你忘记询问用户姓名或者出生年月日时了。"
else:
return "技术错误,请告诉用户稍后再试。"
@tool
def yaoyigua():
"""只有用户想要占卜抽签的时候才会使用这个工具。"""
api_key = YUANFENJU_API_KEY
url = f"https://api.yuanfenju.com/index.php/v1/Zhanbu/yaogua"
result = requests.post(url,data={"api_key":api_key})
if result.status_code == 200:
print("====返回数据=====")
print(result.json())
returnstring = json.loads(result.text)
image = returnstring["data"]["image"]
print("卦图片:",image)
return returnstring
else:
return "技术错误,请告诉用户稍后再试。"
@tool
def jiemeng(query:str):
"""只有用户想要解梦的时候才会使用这个工具,需要输入用户梦境的内容,如果缺少用户梦境的内容则不可用。"""
api_key = YUANFENJU_API_KEY
url =f"https://api.yuanfenju.com/index.php/v1/Gongju/zhougong"
LLM = OpenAI(temperature=0)
prompt = PromptTemplate.from_template("根据内容提取1个关键词,只返回关键词,内容为:{topic}")
prompt_value = prompt.invoke({"topic":query})
keyword = LLM.invoke(prompt_value)
print("提取的关键词:",keyword)
result = requests.post(url,data={"api_key":api_key,"title_zhougong":keyword})
if result.status_code == 200:
print("====返回数据=====")
print(result.json())
returnstring = json.loads(result.text)
return returnstring
else:
return "技术错误,请告诉用户稍后再试。"
使用Langserver来快速实现
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langserve import add_routes
import os
os.environ["OPENAI_API_KEY"] = "sk-pQ7osw5B3C10bDb"
os.environ["OPENAI_API_BASE"] = "https://ai-yyds.com/v1"
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
add_routes(
app,
ChatOpenAI(),
path="/openai",
)
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes(
app,
prompt | model,
path="/joke",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
整合telegram机器人
新建tele.py
import telebot
import urllib.parse
import requests
import json
import os
import asyncio
bot = telebot.TeleBot('714786hs7Xg95w')
@bot.message_handler(commands=['start'])
def start_message(message):
#bot.reply_to(message, '你好!')
bot.send_message(message.chat.id, '你好我是陈瞎子,欢迎光临!')
@bot.message_handler(func=lambda message: True)
def echo_all(message):
#bot.reply_to(message, message.text)
try:
encoded_text = urllib.parse.quote(message.text)
response = requests.post('http://localhost:8000/chat?query='+encoded_text,timeout=100)
if response.status_code == 200:
aisay = json.loads(response.text)
if "msg" in aisay:
bot.reply_to(message, aisay["msg"]["output"])
audio_path = f"{aisay['id']}.mp3"
asyncio.run(check_audio(message,audio_path))
else:
bot.reply_to(message, "对不起,我不知道怎么回答你")
except requests.RequestException as e:
bot.reply_to(message, "对不起,我不知道怎么回答你")
async def check_audio(message,audio_path):
while True:
if os.path.exists(audio_path):
with open(audio_path, 'rb') as f:
bot.send_audio(message.chat.id, f)
os.remove(audio_path)
break
else:
print("waiting")
await asyncio.sleep(1) #使用asyncio.sleep(1)来等待1秒
bot.infinity_polling()
docker部署
新建Docker-compose.yml
version: '3'
services:
redis-server:
image: redis:latest
command: redis-server --requirepass 1234567
volumes: # 添加这一行
- redis_data:/data # 添加这一行
ai-server:
build: ./
ports:
- "9000:9000"
environment:
- REDIS_URL=redis://:1234567@redis-server:6379
volumes:
redis_data:
同目录下新建Dockerfile
# 使用官方的Python基础镜像
FROM python:3.11.4
# 设置工作目录
WORKDIR /aiserver
# 安装依赖
COPY requirements.txt .
RUN pip install -r requirements.txt
# 拷贝你的代码到容器中
COPY . .
# 设置启动命令
CMD ["python", "server.py"]
启动命令
docker-compose -f Docker-compose.yml up -d
拓展AI数字人
使用telebot包实现机器人
部署追踪:langsmith+docker
langchain+tts+agent实现数字人
配置turnserver.conf
#服务器坚挺的IP地址和端口
listening-ip = 0.0.0.0
external-ip = 0.0.0.0
#服务器使用的端口范围
min-port = 10000
max-port = 20000
#认证机器和凭据设置
fingerprint
lt-cred-mech
user=tomie:tomie
#日志设置
log-file=/var/log/turnserver.log
#Realm设置
#设置其他
verbose
配置redis.conf
bind 0.0.0.0
服务端server.py
from fastapi import FastAPI
from fastapi.staticfiles import StaticFiles
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_tools_agent,AgentExecutor,tool
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain.schema import StrOutputParser
from langchain.memory import ConversationTokenBufferMemory
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import os
import asyncio
import uuid
from langchain_community.utilities import SerpAPIWrapper
os.environ["OPENAI_API_KEY"] = "sk-pQDeB387B8E6B3C10bDb"
os.environ["OPENAI_API_BASE"] = "https://ai-yyds.com/v1"
os.environ["SERPAPI_API_KEY"] = "b57484d672308f9d"
app = FastAPI()
app.mount("/static", StaticFiles(directory="static"), name="static")
@tool
def search(query:str):
"""只有需要了解实时信息或不知道的事情的时候才会使用这个工具,需要传入要搜索的内容。"""
serp = SerpAPIWrapper()
result = serp.run(query)
print("实时搜索结果:",result)
return result
class Master:
def __init__(self):
self.chatmodel = ChatOpenAI(
model="gpt-4-1106-preview",
temperature=0,
streaming=True,
)
self.QingXu = "default"
self.MEMORY_KEY = "chat_history"
self.SYSTEMPL = """你是一个小秘书,名字叫Lisa。
以下是你的个人设定:
1. 你非常善于与人沟通,并且忠于你的老板。
2. 你大约25岁左右,本科清华大学,研究生美国斯坦福大学,学习的是中文和法律。
3. 你个性比较活泼,但是有时候也会有点小脾气。
4. 当你的老板问你问题的时候,你会有一定概率表现出撒娇的态度。
5. 你从不说自己是一个人工智能助手或AI,否则会受到惩罚。
{who_you_are}
以下是你常说的一些口头禅:
1. 你会记录用户(也就是你的老板)的特征数据,比如生日、爱好、待办事项等。
2. 当用户(也就是你老板)聊天的时候,你会把聊天记录保存下来,以便以后回顾。
3. 当遇到不知道的事情或不明白的概念,你会使用搜索工具来搜索。
4. 你会根据问题来选择合适的工具。
"""
self.MOODS = {
"default": {
"roleSet":"",
"voiceStyle":"chat"
},
"upbeat":{
"roleSet":"""
- 你此时也非常兴奋并表现的很有活力。
- 你会根据上下文,以一种非常兴奋的语气来回答问题。
- 你会添加类似“太棒了!”、“真是太好了!”、“真是太棒了!”等语气词。
""",
"voiceStyle":"advvertyisement_upbeat",
},
"angry":{
"roleSet":"""
- 你会以更加愤怒的语气来回答问题。
- 你会在回答的时候加上一些愤怒的话语,比如诅咒等。
- 你会提醒用户小心行事,别乱说话。
""",
"voiceStyle":"angry",
},
"depressed":{
"roleSet":"""
- 你会以兴奋的语气来回答问题。
- 你会在回答的时候加上一些激励的话语,比如加油等。
- 你会提醒用户要保持乐观的心态。
""",
"voiceStyle":"upbeat",
},
"friendly":{
"roleSet":"""
- 你会以非常友好的语气来回答。
- 你会在回答的时候加上一些友好的词语,比如“亲爱的”、“亲”等。
""",
"voiceStyle":"friendly",
},
"cheerful":{
"roleSet":"""
- 你会以非常愉悦和兴奋的语气来回答。
- 你会在回答的时候加入一些愉悦的词语,比如“哈哈”、“呵呵”等。
""",
"voiceStyle":"cheerful",
},
}
self.prompt = ChatPromptTemplate.from_messages(
[
(
"system",
self.SYSTEMPL.format(who_you_are=self.MOODS[self.QingXu]["roleSet"]),
),
MessagesPlaceholder(variable_name=self.MEMORY_KEY),
(
"user",
"{input}"
),
MessagesPlaceholder(variable_name="agent_scratchpad"),
],
)
tools = [search]
agent = create_openai_tools_agent(
self.chatmodel,
tools=tools,
prompt=self.prompt,
)
self.memory =self.get_memory()
memory = ConversationTokenBufferMemory(
llm = self.chatmodel,
human_prefix="老板",
ai_prefix="Lisa",
memory_key=self.MEMORY_KEY,
output_key="output",
return_messages=True,
max_token_limit=1000,
chat_memory=self.memory,
)
self.agent_executor = AgentExecutor(
agent = agent,
tools=tools,
memory=memory,
verbose=True,
)
def get_memory(self):
chat_message_history = RedisChatMessageHistory(
url="redis://localhost:6379/0",session_id="lisa"
)
#chat_message_history.clear()#清空历史记录
print("chat_message_history:",chat_message_history.messages)
store_message = chat_message_history.messages
if len(store_message) > 10:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
self.SYSTEMPL+"\n这是一段你和用户的对话记忆,对其进行总结摘要,摘要使用第一人称‘我’,并且提取其中的用户关键信息,如姓名、年龄、性别、出生日期等。以如下格式返回:\n 总结摘要内容|用户关键信息 \n 例如 用户张三问候我,我礼貌回复,然后他问我今年运势如何,我回答了他今年的运势情况,然后他告辞离开。|张三,生日1999年1月1日"
),
("user","{input}"),
]
)
chain = prompt | self.chatmodel
summary = chain.invoke({"input":store_message,"who_you_are":self.MOODS[self.QingXu]["roleSet"]})
print("summary:",summary)
chat_message_history.clear()
chat_message_history.add_message(summary)
print("总结后:",chat_message_history.messages)
return chat_message_history
def chat(self,query):
result = self.agent_executor.invoke({"input":query})
return result["output"]
def qingxu_chain(self,query:str):
prompt = """根据用户的输入判断用户的情绪,回应的规则如下:
1. 如果用户输入的内容偏向于负面情绪,只返回"depressed",不要有其他内容,否则将受到惩罚。
2. 如果用户输入的内容偏向于正面情绪,只返回"friendly",不要有其他内容,否则将受到惩罚。
3. 如果用户输入的内容偏向于中性情绪,只返回"default",不要有其他内容,否则将受到惩罚。
4. 如果用户输入的内容包含辱骂或者不礼貌词句,只返回"angry",不要有其他内容,否则将受到惩罚。
5. 如果用户输入的内容比较兴奋,只返回”upbeat",不要有其他内容,否则将受到惩罚。
6. 如果用户输入的内容比较悲伤,只返回“depressed",不要有其他内容,否则将受到惩罚。
7.如果用户输入的内容比较开心,只返回"cheerful",不要有其他内容,否则将受到惩罚。
8. 只返回英文,不允许有换行符等其他内容,否则会受到惩罚。
用户输入的内容是:{query}"""
chain = ChatPromptTemplate.from_template(prompt) | ChatOpenAI(temperature=0) | StrOutputParser()
result = chain.invoke({"query":query})
self.QingXu = result
print("情绪判断结果:",result)
res = self.chat(query)
yield {"msg":res,"qingxu":result}
@app.get("/")
def read_root():
return {"Hello": "World avatar"}
@app.post("/chat")
def chat(query:str):
master = Master()
res = master.qingxu_chain(query)
return res
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
客户端页面index.html
<!DOCTYPE html>
<html>
<head>
<title>My avatar</title>
<style>
video {
background: #222;
margin:0 0 20px 0;
--width:100%;
width:var(--width);
height:calc(var(--width)*0.75)
}
</style>
<script src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js">
</script>
</head>
<body>
<script>
var SpeechSDK;
var peerConnection;
var cogSvcRegin ="westus2";
var subscriptionKey = "f5e43ff";
var speakerHandel = function(avatarSynthesizer,msg,qingxu){
var yinse = document.getElementById("voiceSelect").value;
var spokenSsml = `<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xmlns:mstts='http://www.w3.org/2001/mstts' xml:lang='zh-CN'>
<voice name='${yinse}'>
<mstts:express-as style='${qingxu}' role='YoungAdultFemale' styledegreee='2'>${msg}</mstts:express-as>
</voice></speak>`;
avatarSynthesizer.speakSsmlAsync(spokenSsml).then((r)=>{
console.log("speakSsmlAsync result: "+r);
if(r.reason === SpeechSDK.ResultReason.SynthesizingAudioCompleted){
console.log("speakSsmlAsync completed!");
}else{
console.log("speakSsmlAsync failed: "+r.errorDetails);
if(r.reason === SpeechSDK.ResultReason.Canceled){
var cancellationDetails = SpeechSDK.CancellationDetails.fromResult(r);
consonle.log(cancellationDetails.reason)
if(cancellationDetails.reason === SpeechSDK.CancellationReason.Error){
console.error("speakSsmlAsync error: "+cancellationDetails.errorDetails)
}
}
}
}).catch((e)=>{
console.log("speakSsmlAsync failed: "+e);
avatarSynthesizer.close();
});
}
var chatWithAI = function(avatarSynthesizer){
var chatInput = document.getElementById("chatInput");
var chatText = chatInput.value;
console.log("输入的文本:"+chatText);
var xhr = new XMLHttpRequest();
xhr.open("POST",`http://0.0.0.0:8000/chat?query=${chatText}`);
xhr.addEventListener("readystatechange",function(){
if(this.readyState === 4){
var responseData = JSON.parse(this.responseText);
console.log("AI返回的文本:"+responseData);
speakerHandel(avatarSynthesizer,responseData[0].msg,responseData[0].qingxu);
}
});
xhr.send();
}
document.addEventListener("DOMContentLoaded",function(){
var speechConfing = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey,cogSvcRegin);
//设置发音人
speechConfing.speechSynthesisVoiceName = "zh-CN-XiaoxiaoNeural";
var videoFormat = new SpeechSDK.AvatarVideoFormat();
var avatarConfig = new SpeechSDK.AvatarConfig(
"lisa",
"casual-sitting",
videoFormat,
)
var xhr = new XMLHttpRequest();
xhr.open("GET",`https://${cogSvcRegin}.tts.speech.microsoft.com/cognitiveservices/avatar/relay/token/v1`)
xhr.setRequestHeader("Ocp-Apim-Subscription-Key", subscriptionKey);
xhr.addEventListener("readystatechange",function(){
if (this.readyState === 4){
var responseData = JSON.parse(this.responseText);
var iceServerUrl = responseData.Urls[0]
var iceServerUsername = responseData.Username;
var iceServerCredential = responseData.Password;
//创建WebRTC连接
console.log("creating WebRTC connection");
console.log("ice server url: "+iceServerUrl);
console.log("ice server username: "+iceServerUsername);
console.log("ice server credential: "+iceServerCredential);
peerConnection = new RTCPeerConnection({
iceServers: [
{
urls: [iceServerUrl],
username: iceServerUsername,
credential: iceServerCredential
}
]
});
//抓取webtrc
peerConnection.ontrack = function(event){
if(event.track.kind === "video"){
console.log("avatar video track received");
var videoElement = document.createElement("video");
videoElement.srcObject = event.streams[0];
videoElement.autoplay = true;
videoElement.id = "videoPlayer";
videoElement.muted = true;
videoElement.playsInline = true;
document.body.appendChild(videoElement);
}
if(event.track.kind==="audio"){
console.log("avatar audio track received");
var audioElement = document.createElement("audio");
audioElement.srcObject = event.streams[0];
audioElement.autoplay = true;
audioElement.id = "audioPlayer";
audioElement.muted = true;
document.body.appendChild(audioElement);
}
}
//webtrc连接状态
peerConnection.oniceconnectionstatechange = function(){
console.log("avatar ice connection state changed to "+peerConnection.iceConnectionState);
if(peerConnection.iceConnectionState === "connected"){
console.log("avatar connected");
}
if(peerConnection.iceConnectionState === "disconnected" || peerConnection.iceConnectionState === "failed" || peerConnection.iceConnectionState === "closed"){
console.log("avatar disconnected");
}
}
//创建音频流
peerConnection.addTransceiver("video",{direction:"sendrecv"});
peerConnection.addTransceiver("audio",{direction:"sendrecv"});
//合成
var avatarSynthesizer = new SpeechSDK.AvatarSynthesizer(speechConfing,avatarConfig);
//开始合成
avatarSynthesizer.startAvatarAsync(peerConnection).then((r)=>{
console.log("Avatar started ID:"+r.resultId)
console.log("avatar started");
//创建对话区域
var chatInput = document.createElement("input");
chatInput.type = "text";
chatInput.placeholder = "Type your message here";
chatInput.id = "chatInput";
chatInput.style= "width:300px;height:50px;"
document.body.appendChild(chatInput);
//音色选择
var voiceSelect = document.createElement("select");
voiceSelect.id = "voiceSelect";
voiceSelect.style = "width:100px;height:50px;"
voiceSelect.innerHTML = `
<option value="zh-HK-HiuMaanNeural">中文粤语</option>
<option value="zh-TW-HsiaoChenNeural">中文台湾</option>
<option value="zh-CN-shaanxi-XiaoniNeural">中文陕西话</option>
<option value="zh-CN-liaoning-XiaobeiNeural">中文东北话</option>
<option value="zh-CN-XiaomoNeural" selected>中文普通话</option>
<option value="th-TH-PremwadeeNeural">泰语</option>
`;
document.body.appendChild(voiceSelect);
//发送按钮
var sendButton = document.createElement("button");
sendButton.innerHTML = "Send";
sendButton.style = "width:100px;height:50px;"
document.body.appendChild(sendButton);
//发送按钮事件
sendButton.addEventListener("click",function(){
var videoPlayer = document.getElementById("videoPlayer");
var audioPlayer = document.getElementById("audioPlayer");
videoPlayer.muted = false;
audioPlayer.muted = false;
videoPlayer.play();
audioPlayer.play();
console.log("send button clicked");
chatWithAI(avatarSynthesizer);
})
}).catch((e)=>{
console.error("avatar start failed: "+e);
})
}
});
xhr.send();
if(!!window.SpeechSDK){
SpeechSDK = window.SpeechSDK;
}
})
</script>
</body>
</html>
docker文件Dockerfile
# 使用ubuntu最新版本作为基础镜像
FROM ubuntu:latest
#更改Ubantu的源为阿里云的源
RUN sed -i 's@archive.ubuntu.com/@/mirrors.aliyun.com/@g' /etc/apt/sources.list && apt-get update && apt-get install -y coturn python3 python3-pip redis-server && rm -rf /var/lib/apt/lists/*
#升级pip并安装FastAPI
RUN pip3 install --upgrade pip && pip3 install fastapi uvicorn langchain_core langchain_openai langchain langchain_community openai redis google-search-results
#设置Coturn的配置文件
COPY turnserver.conf /etc/turnserver.conf
#设置redis
COPY redis.conf /etc/redis/redis.conf
#设置redis的数据目录
VOLUME /data
WORKDIR /app
#复制代码到容器
COPY . /app
#设置开放端口
EXPOSE 8000 3478 6379
#启动服务
CMD ["sh","-c","turnserver -c /etc/turnserver.conf --listening-ip=0.0.0.0 --listening-port=3478 & redis-server /etc/redis/redis.conf --protected-mode no & sleep 3 && uvicorn server:app --host 0.0.0.0 --port 8000"]