注释
以 # 开头,# 右边的所有东西都被当做说明文字,而不是真正要执行的程序,只起到辅助说明作用
要在 Python 程序中使用多行注释,可以用 一对 连续的 三个 引号(单引号和双引号都可以)
基本数据类型
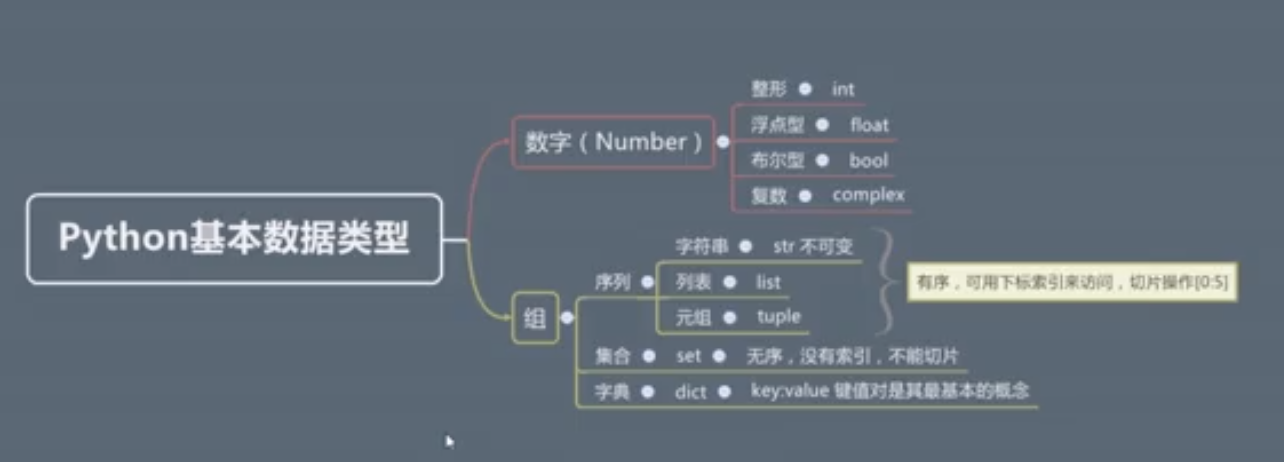
Number数字
整数int(不可变,值类型)
浮点数float
一个斜杠是除;两个斜杠是整除,只保留整数位
>>> type(1)
<class 'int'>
>>> type(-1)
<class 'int'>
>>> type(1.1)
<class 'float'>
>>> type(1.12)
<class 'float'>
>>> 1+0.1
1.1
>>> type(1+0.1)
<class 'float'>
>>> type(1+1)
<class 'int'>
>>> type(1+1.0)
<class 'float'>
>>> type(1*2)
<class 'int'>
>>> type(1*1.0)
<class 'float'>
>>> type(2/2)
<class 'float'>
>>> type(2//2)
<class 'int'>
bool布尔类型,表示真假
>>> True
True
>>> False
False
>>> type(True)
<class 'bool'>
>>> type(False)
<class 'bool'>
>>> int(True)
1
>>> int(False)
0
>>> bool(1)
True
>>> bool(0)
False
complex表示复数
>>> 36j
36j
进制表示和转换
二进制
用0b表示,0b10表示二进制10
八进制
用0o表示,0o10表示八进制10
十进制
123
十六进制
用0x表示,0x10表示十六进制10
其他进制转换为二进制用bin()命令,例如bin(10),bin(0o7),bin(0x1F)
其他进制转换为八进制用oct()命令,例如oct(0b111)
其他进制转换为十进制用int()命令,例如int(0b111)
其他进制转换为十六进制用hex()命令,例如hex(0b1111)
>>> 0b10
2
>>> 0o10
8
>>> 0x10
16
>>> bin(10)
'0b1010'
>>> oct(0b111)
'0o7'
>>> int(0b111)
7
>>> hex(0b11111)
'0x1f'
字符串
str表示字符串,可以用单引号,或者双引号表示,(不可变,值类型)
>>> 'hello world'
'hello world'
>>> "hello world"
'hello world'
>>> type('hello')
<class 'str'>
>>> type("hello")
<class 'str'>
>>> type('1')
<class 'str'>
>>> "let's go"
"let's go"
>>> 'let"s go'
'let"s go'
>>> 'let\' go'
"let' go"
三个引号可以表示多行字符串,\n转义字符表示换行,\r表示回车,\t表示tab
>>> '''
... hello
... world
... '''
'\nhello\nworld\n'
>>> print('hello world\nhaha')
hello world
haha
原始字符串,在字符串前加r,就会原样输出
>>> print(r'c:\ntwork\py')
c:\ntwork\py
字符串运算
>>> 'hello'+' world'
'hello world'
>>> 'hello'+1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
>>> 'hello'*2
'hellohello'
>>> 'hello'[0]
'h'
>>> 'hello'[-1]
'o'
>>> 'hello'[0:3]
'hel'
>>> 'hello'[0:-1]
'hell'
>>> 'hello world'[6:]
'world'
查看字符对应的ASCII值
>>> ord('a')
97
str与byte转换
a = 'hello xiaomu'
print(a, type(a)) # str
b = b'hello xiaomu'
print(b, type(b)) # bytes
'''
用法
string. encode(encoding='utf-8,errors='strict)
bytes. decode(encoding='utf-8', errors='strict')
参数:
encoding: 转换成的编码格式,如ascii,gbk,默认 utf-8
errors: 出错时的处理方法,默认strict直接抛错误,也可以选择 ignore忽略错误
返回值 :
返回一个比特 ( bytes )类型
'''
str_data = 'my name is dewei'
byte_data = str_data.encode('utf-8')
print(byte_data) # b'my name is dewei'
byte_data = b'my name is dewei'
str_data = byte_data.decode('utf-8')
print(str_data) # 'my name is dewei'
常用方法
# capitalize 首字母大写,其他字母小写
s = 'student'
s = s.capitalize()
print(s)
# lower casefold 字符串字母全部小写
s = 'STUDENT HELLO'
print(s)
s1 = s.lower()
print(s1)
s2 = s.casefold()
print(s2)
# upper 字符串字母全部大写
s = 'student hello'
print(s)
s1 = s.upper()
print(s1)
# swapcase 字符串字母大小写翻转
s = 'student HELLO'
print(s)
s1 = s.swapcase()
print(s1)
# zfill 为字符串定义长度,入不满足,缺少的部分在前面用0填补
s = 'love'
print(s)
s1 = s.zfill(8)
print(s1) #0000love
# count 统计字符串中字符的数量
s = 'loveloove'
print(s)
s1 = s.count('o')
print(s1) # 3
# startswith,endswith 判断字符串是否以某个字符或字符串开头或结尾,返回布尔值
s = 'we are love'
print(s)
s1 = s.startswith('we')
print(s1) # True
s2 = s.endswith('ve')
print(s2) # True
# find查询字符串中元素的位置下标,查询不到返回-1;index 查询字符串中元素的位置下标,查询不到报错
s = 'we are love'
print(s)
s1 = s.find('are')
print(s1) # 3
s2 = s.index('ve')
print(s2) # 9
# strip 去除字符串中的空格或元素
s = ' we are love '
print(s)
s1 = s.strip()
print(s1)
s2 = s.strip('ve ')
print(s2)
# replace 把字符串中的某个元素替换为另一个元素,可以指定替换的数量
s = 'python is a good python code'
print(s)
s1 = s.replace('python', 'java',1)
print(s1)
s2 = s.replace('python', 'java',2)
print(s2)
# isspace 判断字符串是否是由空格组成
print(' '.isspace()) # True
print('hello world'.isspace()) # False
# istitle 判断字符串是不是一个标题类型,此函数只适用于英文
print('Hello World'.istitle()) # True
print('hello world'.istitle()) # False
# isupper islower 判断字符串是否全是大写或者小写
print('HELLO'.isupper()) # True
print('hello'.islower()) # True
# join 字符串拼接
# split 字符串切割
字符串与数字类型转换
# 整形转字符串
new_str = str(123)
# 浮点型转字符串
new_str = str(3.14)
# 字符串转整形
new_int = int('123')
# 字符串转浮点型
new_float = float('3.14')
字符串与列表的转换
'''
split用法
string.split(sep=None, maxsplit=-1)
参数:
sep: 切割的规则符号,不填写,默认空格,如字符串无空格则不分割生成列表
maxsplit : 根据切割符号切割的次数,默认-1无限制
返回值 :返回一个列表
'''
info = 'my name is dewei'
info_list = info.split()
print(info_list) #['my','name','is', 'dewei']
'''
join用法
'sep'join(iterable)
参数:
sep: 生成字符串用来分割列表每个元素的符号
iterable : 非数字类型的列表或元组或集合
返回值 :
返回一个字符串
'''
test = ['a', 'b', 'c']
new_str ='.'.join(test)
print(new_str) # 'a.b.c'
# sorted内置函数
sort_str_new = 'abdfipqc'
print(sort_str_new)
res = sorted(sort_str new)
print(''.join(res)) # abcdfipq
列表与元组
列表list,或者称为数组,(可变,引用类型)
>>> type([1,2,3])
<class 'list'>
>>> type(["hello",2,True])
<class 'list'>
>>> [[1,2,3],["hello","world"],[True,False]]
[[1, 2, 3], ['hello', 'world'], [True, False]]
>>> [1,2,3][0]
1
>>> [1,2,3][-1]
3
>>> [1,2,3][0:2]
[1, 2]
>>> [1,2,3]+[4,5]
[1, 2, 3, 4, 5]
>>> [1,2,3]*2
[1, 2, 3, 1, 2, 3]
>>> 3 in [1,2,3]
True
>>> 3 not in [1,2,3]
False
>>> len("hello world")
11
>>> max([1,2,3])
3
>>> min([1,2,3])
1
len函数可以计算出除了数字类型以外,其他所有数据类型的长度
与列表比较相似的还有一个元组(不可变,值类型)
>>> type((1,2,3))
<class 'tuple'>
>>> type((1))
<class 'int'>
>>> type(('hello'))
<class 'str'>
>>> type(())
<class 'tuple'>
>>> type((1,))
<class 'tuple'>
常用函数
# append 把一个元素添加到列表中,被添加的元素只会添加到末尾,是在原有列表的基础上添加的,不会产生新变量
books = []
print(id(books))
books.append('python入门课程')
print(books)
print(id(books))
# insert 把一个元素添加到列表的指定位置,若位置不存在则添加到末尾
xiyouji = '西游记'
books.insert(0,xiyouji)
print(books)
print(id(books))
# count 返回当前列表中某个元素的个数
fruits =['苹果','西瓜','水蜜桃','西瓜','雪梨']
count=fruits.count('西瓜')
print(count)
# remove 删除列表中的某一个元素,如果删除的元素不存在会报错,如果删除的元素有多个,只会删除第一个
drinks=['雪碧','可乐','矿泉水']
drinks.remove('矿泉水')
print(drinks) # ['雪碧','可乐']
# del 把变量从内存中彻底删除
drinks=['雪碧','可乐','矿泉水']
del drinks
print(drinks) # name'drinks is not defined
# reverse 对当前列表顺序进行反转
drinks=['雪碧','可乐','矿泉水']
drinks.reverse()
print(drinks) # ['矿泉水','可乐','雪碧']
# sort 对当前列表按照一定规律进行排序,列表中的元素类型必须一致,否则会报错
'''
用法:
list.sort(cmp=None, key=None, reverse=False)
参数:
cmp--可选参数,制定排序方案的函数
key-参数比较
reverse--排序规则,reverse=True降序,reverse=False升序(默认)
'''
books = ['python', 'django', 'web', 'flask','tornado']
books.sort()
print(books) # ['django', 'flask', 'python', 'tornado','web']
# clear 将当前列表中的数据清空
target=[1,2,3,4,5,6]
target.clear()
# copy 将当前的列表复制一份相同的列表,新列表与旧列表内容相同,但内存空间不同
'''
通俗的说,我们有一个列表a,列表
里的元素还是列表,当我们拷贝出新列
表b后,无论是a还是b的内部的列表中
的数据发生了变化后,相互之间都会受
到影响,-浅拷贝(copy)
不仅对第一层数据进行了
copy,对深层的数据也进行
copy,原始变量和新变量完
完全全不共享数据-深拷贝(deepcopy)
'''
old_list=['a','b','c']
new_list=old_list.copy()
print(new_list) # ['a','b','c']
# extend 将其他列表或元组中的元素导入到当前列表中
students=['dewei','xiaomu','xiaogang']
new_students=('xiaowang','xiaohong')
students.extend(new_students)
students
['dewei', 'xiaomu', 'xiaogang', 'xiaowang', 'xiaohong']
# pop 通过索引删除并获取列表的元素
names =['dewei','xiaomu']
pop_item=names.pop(0)
print('pop item:',pop_item,'names:' , names) # pop item: dewei names:['xiaomu']
# set 列表转集合
new_set = set([1,2,3,4,5])
# tuple 列表转元组
new_tuple = tuple([1,2,3,4,5])
# list 元组转列表
new_list = list((1,2,3,4,5))
索引与切片
# coding:utf-8
numbers=[1,2,3,4,5,6,7,8,9,10]
print(len(numbers) - 1)
print(numbers[9])
print('获取列表完整数据:',numbers[:])
print('另一种获取完整列表的方法:',numbers[0:])
print('第三种获取列表的方法:',numbers[0:-1]) #1-9
print('列表的反序:',numbers[::-1])
print('列表的反项获取',numbers[-3:-1])
print('步长2获取切片:',numbers[0:8:2])
print('切片生成空列表',numbers[0:0])
new_numbers=numbers[:4]
print(new_numbers)
集合set
用大括号表示,特征:无序,不重复,(可变,引用类型);无法通过索引获取元素;无获取元素的方法,只能打印集合;集合只是用来处理列表或元组的一种临时类型,他不适合存储与传输
>>> type({1,2,3})
<class 'set'>
>>> 1 in {1,2,3}
True
>>> 1 not in {1,2,3}
False
>>> {1,2,3,4,5} - {3,4}
{1, 2, 5}
>>> {1,2,3,4,5} & {3,4}
{3, 4}
>>> {1,2,3} | {4,5}
{1, 2, 3, 4, 5}
>>> type({})
<class 'dict'>
>>> type(set())
<class 'set'>
>>> len(set())
0
常用函数
# add 用于集合中添加一个元素,如果集合中已存在该元素则该函数不执行
a_set=set()
a_set.add('dewei')
print(a_set) # {'dewei'}
# update 加入一个新的集合(或列表,元组,字符串),如新集合内的元素在原集合中存在则无视
a_set=set()
a_set.update([3,4,5])
print(a_set) # {3,4,5}
# remove 将集合中的某个元素删除,如元素不存在将会报错
a_set={1,2,3}
a_set.remove(3)
print(a_set) # {1,2}
# clear 清空当前集合中的所有元素
a_set={1,2,3}
a_set.clear()
# del 删除集合
a_set={1,2,2,3}
del a_set
print(a_set) #报错
# difference 返回集合的差集,即返回的集合元素包含在第一个集合中,但不包含在第二个集合(方法的参数)中
a_set={'name','xiaomu','xiaoming'}
b_set={'xiaoming','xiaogang','xiaohong'}
a_diff=a_set.difference(b_set)
print(a_diff) # {'name','xiaomu'}
# intersection 返回两个或更多集合中都包含的元素,即交集
a_set={'name','xiaomu','xiaoming'}
b_set={'xiaoming','xiaogang','xiaohong'}
a_inter=a_set.intersection(b_set)
print(a_inter) # {'xiaoming'}
# union 返回多个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次
a_set={'name','xiaomu','xiaoming'}
b_set={'xiaoming', 'xiaogang', 'xiaohong'}
un=a_set.union(b_set)
print(un) # {'name', 'xiaogang', 'xiaohong', 'xiaoming', 'xiaaomu'}
# isdisjoint 判断两个集合是否包含相同的元素,如果没有返回True,否则返回False
a_set={'name','xiaomu','xiaoming'}
b_set={'xiaoming','xiaogang','xiaohong'}
result=a_set.isdisjoint(b_set)
print(result) # False
字典dict
字典dict是可变的,引用类型
key必须是不可变类型,比如int,str
>>> {1:1,2:2}
{1: 1, 2: 2}
>>> {1:1,2:2}[1]
1
常用方法
# keys 获取所有的key
my_dict={'name': 'dewei','age': 33}
key_list=list(my_dict.keys())
key_list
['name','age']
# 根据key获取value
my_dict={'name': 'dewei', 'age': 33}
name=my_dict['name']
print(name) # dewei
In[21]:name=my_dict.get('name')
print(name) # dewei
# clear 清空当前字典中的所有数据
my_dict={'name':'dewei','age': 33}
my_dict.clear()
print(my_dict) # {}
# pop 删除字典中指定的key,并将其结果返回,如果key不存在则报错
my_dict={'name':'dewei','age':33}
pop_value=my_dict.pop('age')
print('pop value:',pop_value,'my_dict:',my_dict) # pop value: 33 my_dict:{'name': 'dewei'}
# popitem 删除当前字典里末尾一组键值对并将其返回
my_dict={'name': 'dewei','age': 33}
my_dict.popitem() # ('age', 33)
# del 删除字典中的元素或删除字典
my_dict= {'name': 'dewei', 'age': 33}
del my_dict['name']
print(my_dict) # {'age':33}
# copy 复制一个新字典
old_dict={'name': 'dewei','age': 33}
new_dict=old_dict.copy()
id(new_dict)!=id(old_dict) # True
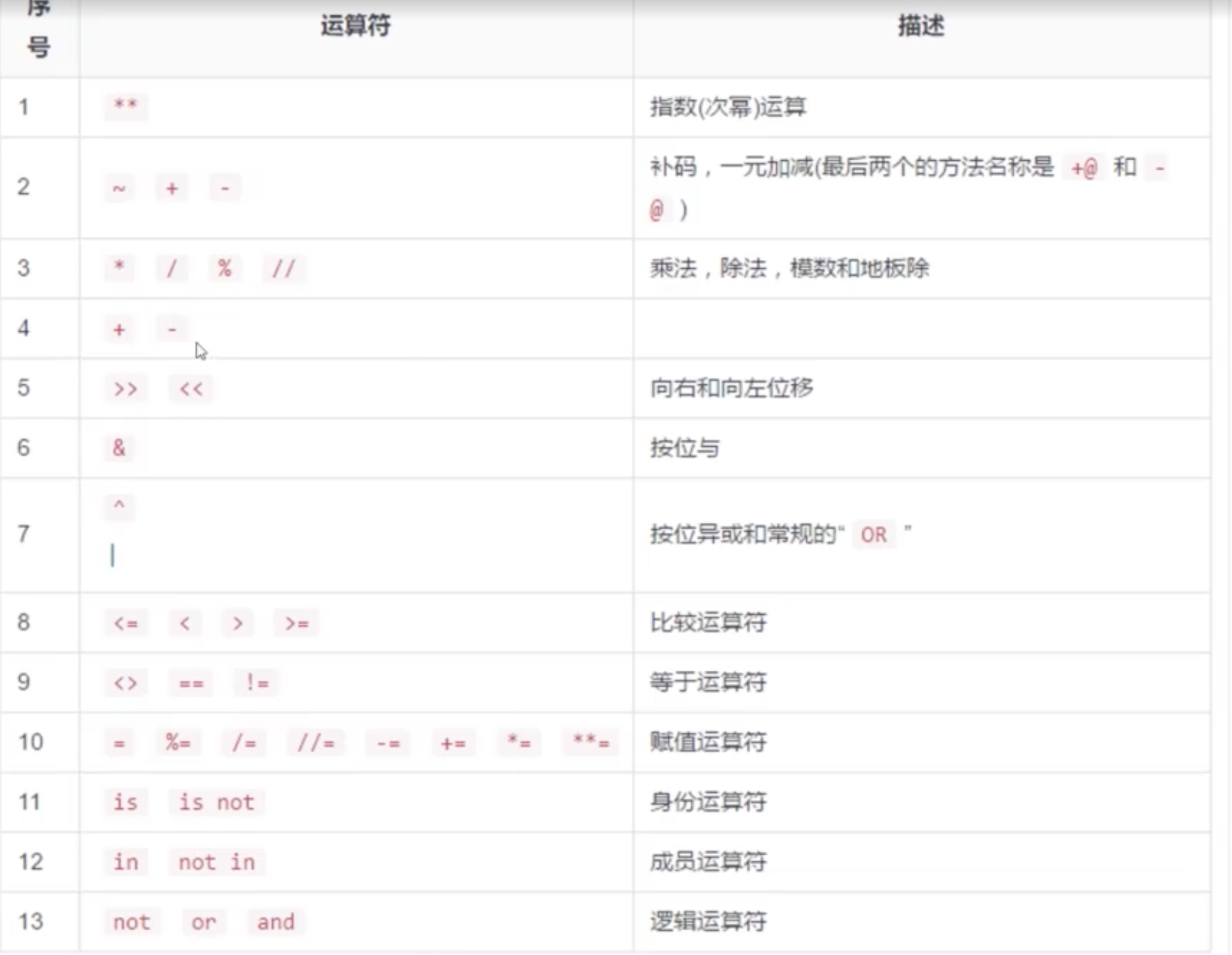
运算符
海象运算符
p = 'python'
if (b:=len(p)) > 5:
print("str len is "+str(b))
#用f关键字拼接字符串
print(f'str len is {b}')
流程控制
包括条件控制,循环控制
'''
条件判断语句
'''
MOOD = True
if MOOD:
print("this is a true")
else:
print("this is a false")
# 比对用户账号,常量一般用全大写字母表示
USER_NAME = 'admin'
USER_PASS = '123'
print('please input user name')
input_name = input()
print('please input user pass')
input_pass = input()
if USER_NAME == input_name and USER_PASS == input_pass:
print('success')
else:
print('fail')
# 计算成绩
SCORE = 90
if SCORE == 90:
print('A')
elif SCORE == 80:
print('B')
else:
print('C')
#循环,可以使用break和continue
li = [1,2,3,4,5]
for item in li:
print(li)
#等差数列,打印2,4,6,8
for i in range(0,10,2):
print(i,end=',')
#列表步长,打印1,3,5,7
a = [1,2,3,4,5,6,7,8]
b = a[0:len(a):2]
print(b)
# while
CONDITION = 10
while CONDITION < 10:
print('this is a while')
迭代器
# coding:utf-8
iter_obj = iter((1, 2, 3))
def _next(iter_obj):
try:
return next(iter_obj)
except StopIteration:
return None
# print(_next(iter_obj))
# print(_next(iter_obj))
# print(_next(iter_obj))
# print(_next(iter_obj))
def make_iter():
for i in range(10):
yield i
iter_obj = make_iter()
for i in iter_obj:
print(i)
print('----')
for i in iter_obj:
print(i)
iter_obj = (i for i in range(10))
for i in iter_obj:
print(i)
print('=====')
for i in iter_obj:
print(i)
模块导入
# 第一种导入方式
import module.module1
print(module.module1.a)
# 第二种导入方式
import module.module1 as m
print(m.a)
# 第三种导入方式
from module.module1 import a
print(a)
批量导入使用__init__.py文件,注意是双下划线;
假如在module1文件夹下创建了此文件
import sys
import datatime
import io
在module2文件夹下的demo文件下想引用sys库中的变量
import module1
print(module1.sys.path)
模块内置变量
print('package: '+ __package__)
print('name: '+__name__)
print('doc: '+__doc__)
print('file: '+__file__)
系统库
datetime库
from datetime import datetime
from datetime import timedelta
now = datetime.now( )
print(now, type(now))
three_days = timedelta(days=3)
after_three_day = now + three_days
print(after_three_day)
before_three_day = now - three_days
print(before_three_day)
one_hour = timedelta(hours=1)
before_one_hour = now - one_hour
print(before_one_hour)
# 日期转字符串
date = datetime.now( )
str_date = date.strftime('%Y-%m-%d %H:%M:%S')
print(str_date) # '2020-03-17 15:19:27'
# 字符串转日期
str_date ='2021-10-10 13:13:13'
date_obj = datetime.strptime(str_date,"%Y-%m-%d %H:%M:%S')
print(date_obj) #datetime.datetime(2021-10-10 13:13:13)
time库
import time
# 获取时间戳,秒级别
now = time.time()
print(now, type(now))
# 时间戳转时间对象
time_obj = time.localtime(now)
print(time_obj, type(time_obj))
current_time_obj = time.locatime()
print(current_time_obj)
# 时间暂停1秒
time.sleep(1)
# 时间转字符串
str_time = time.strftime('%Y-%m-%d %H:M:%s', time.localtime())
print(str_time) # 2020-03-17 15:34:59
os库
import os
# 获取当前绝对路径
current_path = os.getcwd()
print(current_path)
# 判断是否为绝对路径
print(os.path.isabs(current_path))
# 在当前目录下创建test1文件夹
new_path = '%s/testl' % current_path
if os.path.exists(new_path):
os.makedirs(new_path)
# 列出当前路径下的文件夹
data = os.listdir(current_path)
print(data)
# 删除相对路径下的文件夹test2和子文件夹
new_path2 = os.path.join(current_path, 'test2' , 'abc') # 路径拼接
os.removedirs('test2/abc')
# 根据绝对路径删除单个文件夹
os.rmdir('%s/test3_new' % current_path)
# 重命名
os.rename('test3','test3_new')
os.rename('pip_image.py','pip3_image.py')
current_path = current_path + '/package os.py'
print(os.path.isfile(current_path))
print(os.path.split(current_path))
print(os.path.isdir(os.path.split(current_path)[0]))
sys库
import sys
# 获取系统所有模块
modules = sys.modules
print(modules)
# 获取路径
path = sys.path
print(path)
# 获取系统编码
code = sys.getdefaultencoding()
print(code)
# 获取操作系统类型
print(sys.platform)
# 获取Python版本
print(sys.version)
# 获取命令行启动参数
command = sys.argv[1]
print(command)
巩固
# coding: utf-8
'''
小慕早上8点起床,起床之后就开始洗漱
洗漱完成之后,是8点30分,于是开始吃早饭,早饭有面包,牛奶,还有麦片
吃完早饭, 上午9点整, 小慕同学开始学习, 他走向自己的书柜, 书柜里有很多书:
高等数学, 历史,python入门
小慕拿了python入门的书,开始学习, 一直到12点。
在12点时候,小慕叫了外卖, 但是到了12点半, 外卖依然没有来。
于是 小慕给外卖小哥打了电话,电话号码是:
123456789
小哥说他有些繁忙,可能要在12点55的时候送达,并请小慕原谅, 他会尽快送到
到了12点55的时候,外卖小哥准时送达了。
小慕的午餐是: 西红柿炒鸡蛋盖饭, 价格是 12.5 ,小慕支付了费用后,开始吃饭
吃过午饭,已经是下午1点25分了,小慕决定不学习了,而是去超市购物。
于是,小慕来到一家超市,超市里有不同的柜台,放置着不同的内容:
零食的柜台:
薯片, 锅巴, 饼干
生活的柜台:
洗发水, 香皂, 沐浴乳, 其中洗发水有三款, abc, 价格分别是5,10,15
水果的柜台:
苹果,香蕉, 哈密瓜, 橘子, 西瓜
蔬菜的柜台:
西红柿, 黄瓜, 韭菜, 大白菜
饮料的柜台:
雪碧, 可乐, 矿泉水
小慕买了 1瓶可乐, 1袋薯片, 两个苹果, 1颗大白菜, 他们的价格分别是:
2.5, 4, 1.2, 0.9
小慕还选了 一个洗发水, 并且选择了最贵的一款,放到自己的购物车中
小慕来到收银台, 收银员计算一下总价 ?
小慕将这些东西带回家, 然后就去健身了, 在健身之前, 他量了一下体重, 是44.78公斤,
经过2.5 个小时的锻炼之后, 再来一称, 是 44.76, 小慕很开心, 看来锻炼身体对减肥
是有帮助的。
回到家, 已经是下午5点了, 小慕洗了个澡, 拿起可乐 和 一个苹果, 看起了电视,
一直到很晚...
'''
username = '小慕'
get_up_time = '8:00'
bf_time = '8:30' # 早餐时间
bf_contents = ['牛奶', '面包', '麦片']
study_time = '9:00'
books = ('高等数学', '历史', 'python入门')
study_book = 'python入门'
ready_lunch_time = '12:00'
brother_phone = 123456789
real_lunch_time = '12:55'
lunch_pay = 12.5
lunch_name = '西红柿鸡蛋盖饭'
shopping_time = '1:25'
shop = {
'snacks': ['薯片', '锅巴', '饼干'],
'live': ['洗发水', '香皂', '沐浴乳'],
'fruits': [
'苹果', '香蕉',
'哈密瓜', '橘子',
'西瓜'
],
'vegetables': ['西红柿', '黄瓜', '韭菜', '大白菜'],
'drinks': ['雪碧', '可乐', '矿泉水']
}
a, b, c = 5, 10, 15
cola_pay = 2.5
potato = 4
apple_two = 1.2
cabbage = 0.9
tot = cola_pay + potato + apple_two + cabbage + c
sport_time = 2.5
before_weight = 44.78
after_weight = 44.76
go_backhome_time = '5:00'
if __name__ == '__main__':
print('我们的主人公是:', username)
print('他是', get_up_time, '起床')
print(bf_time, '吃早餐')
print('早餐都有:', bf_contents)
print(study_time, '开始学习')
print('书架上都有:', books)
print(username, '看的书是', study_book)
print(username, '准备', ready_lunch_time, '吃午饭')
print('外卖小哥的电话是:', brother_phone)
print(username, '在', real_lunch_time, '开始吃饭')
print('他吃的是', lunch_name, '并且价格是', lunch_pay)
print('购物的时间是', shopping_time)
print('超市的柜台里有:', shop)
print(username, '共花费', tot, '元')
print('去健身了')
print('健身之前,体重是', before_weight)
print('经过了', sport_time, '时间的锻炼')
print('体重变成了', after_weight)
print(username, '在', go_backhome_time, '回家了')
变量
-
在 Python 中,每个变量 在使用前都必须赋值,变量 赋值以后 该变量 才会被创建
-
等号(=)用来给变量赋值
-
=左边是一个变量名
-
=右边是存储在变量中的值
变量的命名
-
标示符可以由 字母、下划线 和 数字 组成
-
不能以数字开头
- 不能与关键字重名
Python中的 标识符 是 区分大小写的- 在
Python中,如果 变量名 需要由 二个 或 多个单词 组成时,可以按照以下方式命名
-
- 每个单词都使用小写字母
- 单词与单词之间使用
_下划线连接;first_name、last_name
- 还可以使用驼峰命名法
demo
# 定义 qq 号码变量
qq_number = "1234567"
# 定义 qq 密码变量
qq_password = "123"
# 在程序中,如果要输出变量的内容,需要使用 print 函数
print(qq_number)
print(qq_password)
变量的类型
- 在
Python中定义变量是 不需要指定类型(在其他很多高级语言中都需要) - 数据类型可以分为 数字型 和 非数字型
- 数字型
-
- 整型 (
int)
- 整型 (
-
- 浮点型(
float)
- 浮点型(
-
- 布尔型(
bool)
- 布尔型(
-
-
- 真
True非 0 数—— 非零即真
- 真
-
-
-
- 假
False0
- 假
-
-
- 复数型 (
complex)
- 复数型 (
-
-
- 主要用于科学计算,例如:平面场问题、波动问题、电感电容等问题
-
- 非数字型
-
- 字符串
-
- 列表
-
- 元组
-
- 字典
- 使用
type函数可以查看一个变量的类型
变量的格式化输出
-
在 Python 中可以使用
print函数将信息输出到控制台 -
如果希望输出文字信息的同时,一起输出 数据,就需要使用到 格式化操作符
-
%被称为 格式化操作符,专门用于处理字符串中的格式 -
- 包含
%的字符串,被称为 格式化字符串
- 包含
-
%和不同的 字符 连用,不同类型的数据 需要使用 不同的格式化字符
| 格式化字符 | 含义 |
|---|---|
| %s | 字符串 |
| %d | 有符号十进制整数,%06d 表示输出的整数显示位数,不足的地方使用 0 补全 |
| %f | 浮点数,%.2f 表示小数点后只显示两位 |
| %% | 输出 % |
代码演示
print("我的名字叫 %s,请多多关照!" % name)
print("我的学号是 %06d" % student_no)
print("苹果单价 %.02f 元/斤,购买 %.02f 斤,需要支付 %.02f 元" % (price, weight, money))
print("数据比例是 %.02f%%" % (scale * 100))
"""
在控制台依次提示用户输入:姓名、公司、职位、电话、电子邮箱
"""
name = input("请输入姓名:")
company = input("请输入公司:")
title = input("请输入职位:")
phone = input("请输入电话:")
email = input("请输入邮箱:")
print("*" * 50)
print(company)
print()
print("%s (%s)" % (name, title))
print()
print("电话:%s" % phone)
print("邮箱:%s" % email)
print("*" * 50)
- 在
Python中,所有 非数字型变量 都支持以下特点:
-
- 都是一个 序列
sequence,也可以理解为 容器 - 取值
[] - 遍历
for in - 计算长度、最大/最小值、比较、删除
- 链接
+和 重复* - 切片
- 都是一个 序列
文件操作
创建与写入
# coding:utf-8
import os
def create_package(path):
if os.path.exists(path):
raise Exception('%s 已经存在不可创建' % path)
os.makedirs(path)
init_path = os.path.join(path, '__init__.py')
f = open(init_path, 'w')
f.write('# coding:utf-8\n')
f.close()
class Open(object):
def __init__(self, path, mode='w', is_return=True):
self.path = path
self.mode = mode
self.is_return = is_return
def write(self, message):
f = open(self.path, mode=self.mode)
if self.is_return:
message = '%s\n' % message
f.write(message)
f.close()
def read(self, is_strip=True):
result = []
with open(self.path, mode=self.mode) as f:
data = f.readlines()
for line in data:
if is_strip == True:
temp = line.strip()
if temp != "":
result.append(temp)
else:
if line != '':
result.append(line)
return result
if __name__ == '__main__':
current_path = os.getcwd()
# path = os.path.join(current_path, 'test1')
# create_package(path)
# open_path = os.path.join(current_path, 'b.txt')
o = Open('package_datetime.py', mode='r')
# o.write('你好 小慕')
data = o.read(is_strip=False)
print(data)
加密模块
# coding:utf-8
import hashlib
import time
base_sign = 'muke'
def custom():
a_timestamp = int(time.time())
_token = '%s%s' % (base_sign, a_timestamp)
# sha1 不可逆加密
hashobj = hashlib.sha1(_token.encode('utf-8'))
a_token = hashobj.hexdigest()
return a_token, a_timestamp
def b_service_check(token, timestamp):
_token = '%s%s' % (base_sign, timestamp)
b_token = hashlib.sha1(_token.encode('utf-8')).hexdigest()
if token == b_token:
return True
else:
return False
if __name__ == '__main__':
need_help_token, timestamp = custom()
time.sleep(1)
result = b_service_check(need_help_token, int(time.time()))
if result == True:
print('a合法,b服务可以进行帮助')
else:
print('a不合法,b不可进行帮助')
base64
# coding;utf-8
import base64
replace_one = '%'
replace_two = '$'
def encode(data):
if isinstance(data, str):
data = data.encode('utf-8')
elif isinstance(data, bytes):
data = data
else:
raise TypeError('data need bytes or str')
_data = base64.encodebytes(data).decode('utf-8')
# 二次加密
_data = _data.replace('a',replace_one).replace('2',replace_two)
return _data
def decode(data):
if not isinstance(data, bytes):
raise TypeError('data need bytes' )
replace_one_b = replace_one.encode('utf-8')
replace_two_b = replace_two.encode('utf-8')
data = data.replace(replace_one_b, b'a').replace(replace_two_b, b'2')
return base64.decodebytes(data).decode('utf-8')
if __name__ == '__main__':
result = encode('hello xiaomu')
print(result)
new_result = decode(result,encode('utf-8'))
print(new_result)
日志
# coding:utf-8
import logging
import os
def init_log(path):
if os.path.exists(path):
mode = 'a'
else:
mode = 'w'
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(filename)s %(lineno)d %(levelname)s %(message)s',
filename=path,
filemode=mode
)
return logging
current_path = os.getcwd()
path = os.path.join(current_path, 'back.log')
log = init_log(path)
log.info('这是第一个记录的日志信息')
log.warning('这是一个警告')
log.error('这是一个重大的错误信息')
log.debug('这是一个debug')
函数
函数定义
def 是英文 define 的缩写
函数名称 应该能够表达 函数封装代码 的功能,方便后续的调用
函数名称 的命名应该 符合 标识符的命名规则
-
- 可以由 字母、下划线 和 数字 组成
-
- 不能以数字开头
-
- 不能与关键字重名
能否将 函数调用 放在 函数定义 的上方?
-
- 不能!
-
- 因为在 使用函数名 调用函数之前,必须要保证
Python已经知道函数的存在
- 因为在 使用函数名 调用函数之前,必须要保证
-
- 否则控制台会提示
NameError: name 'say_hello' is not defined(名称错误:say_hello 这个名字没有被定义)
- 否则控制台会提示
可以在一个Python文件中定义变量或函数,在另一个文件中import导入这个模块,然后使用模块名.变量的方式来调用
演示
# 定义一个两数相加的函数
def add(x,y):
result = x + y
return result
# 定义一个打印函数
def print_code(code):
print(code)
# 调用函数
a = add(1,2)
a1 = add(y=3,x=2)
b = print_code('python')
print(a,a1,b)
# 函数多返回值
def damage(skill_one,skill_two):
damage1 = skill_one * 2
damage2 = skill_two * 3
return damage1,damage2
res1,res2 = damage(222,333)
print(res1,res2)
# 默认参数,默认参数必须放到所有非默认参数之后
def print_user_info(name,age=18,gender = '男'):
print('name: '+name)
print('gender: '+gender)
print('age: '+str(age))
print_user_info('七七',24,'女')
print_user_info('七七',gender='女')
print_user_info('放放',25)
#可变参数
def moreparam(*param):
print(param)
print(type(param))
moreparam(1,2,3,4)
a = (1,2,3,4)
moreparam(*a)
# 关键词可变参数
def print_city(**city):
for key,value in city.items():
print(key,':',value)
print_city(bj='32c',sh='36c')
a = {'bj':'22c','sh':'33c'}
print_city(**a)
# 用global把局部变量变为全局变量
def demo():
global c
c = 2
demo()
print(c)
一些常用函数
# coding:utf-8
# 键盘输入函数
food = input('你想吃什么呢:')
print(food)
# 帮助命令函数
# help(input)
class Test(object):
a = 1
b = 2
def __init__(self):
self.a = self.a
self.b = self.b
test = Test()
print(test.a)
# 返回实例化的字典信息
result = vars(test)
print(result)
# 判断对象中是否有某个属性
print(hasattr(test, 'a'))
print(hasattr(list, 'appends'))
# 为实例化对象添加属性和值
setattr(test, 'c', 3)
print(test.c)
print(vars(test))
# setattr(list, 'c', 1)
if hasattr(list, 'appends'):
print(getattr(list, 'appends'))
else:
print('不能存在')
a = ['', None, True, 0]
print(any(a))
# all - > and
# any - > or
随机数函数
# coding:utf-8
import random
# 随机返回0~1的浮点数
print(random.random()) # 0.5699696526701014
# 产生一个a、b区间的随机浮点数
print(random.uniform(1,10)) # 3.803371151513113
# 产生一个a、b区间的随机整数
print(random.randint(10)) # 3
# 返回对象中的一个随机元素
random.choice(['a','b','c']) # b
random.choice('abc') # c
# 随机返回对象中指定的元素
random.sample(['a','b','c'],2) #['a','c']
random.sample('abc',2) # ['b','c']
# 获取区间内的一个随机数
random.randrange(0,100,1) # 51
random.choice(range(0,100,1)) # 45
# 模拟抽奖
gifts = ['iphone', 'ipad', 'car', 'tv']
def chioce_gifts():
gift = random.choice(gifts)
print('你得到了%s' % gift)
def chioce_gift_new():
count = random.randrange(0, 100, 1)
if 0 <= count <= 50:
print('你中了一个iphone')
elif 50 < count <= 70:
print('你中了一个ipad')
elif 70 < count < 90:
print('你中了一个tv电视')
elif count >= 90:
print('恭喜你中了一辆小汽车')
if __name__ == '__main__':
chioce_gift_new()
高级函数
内置高级函数
提示 __方法名__ 格式的方法是 Python 提供的 内置方法 / 属性,稍后会给大家介绍一些常用的 内置方法 / 属性
| 序号 | 方法名 | 类型 | 作用 |
|---|---|---|---|
| 01 | __new__ |
方法 | 创建对象时,会被 自动 调用 |
| 02 | __init__ |
方法 | 对象被初始化时,会被 自动 调用 |
| 03 | __del__ |
方法 | 对象被从内存中销毁前,会被 自动 调用 |
| 04 | __str__ |
方法 | 返回对象的描述信息,print 函数输出使用 |
具体
'''
__str__函数
如果定义了此函数,当print当前实例化对象的时候,会返回该函数的return信息
'''
class Test(object):
def __str__(self):
return '这是关于这个类的描述'
test = Test()
print(test)
'''
__getattr__函数
当调用的属性或方法不存在时,会返回该方法定义的信息
'''
class Test(object):
def __getattr__(self, key):
return'这个key: {} 不存在'.format(key)
test = Test()
test.a
'''
__setattr__函数
拦截当前类中不存在的值和属性
'''
class Test(object):
def __setattr__(self, key, value):
if key not in self.dict:
self.__dict__[key] = value
t = Test()
t.name = 'dewei
print(t.name) # dewei
'''
__call__函数
把一个类变为一个函数
'''
class Test(object):
def __call__(self,**kwargs):
print('args is {}'.format(kwargs))
t = Test()
t(name='dewei') # args is {'name':'dewei'}
高级
# coding:utf-8
from functools import reduce
frunts = ['apple', 'banana', 'orange']
result = filter(lambda x: 'e' in x, frunts)
print(list(result))
print(frunts)
def filter_func(item):
if 'e' in item:
return True
print('-------')
filter_result = filter(filter_func, frunts)
print(list(filter_result))
map_result = map(filter_func, frunts) # > all
print(list(map_result))
reduce_result = reduce(lambda x, y: x * y, [1, 1, 2, 4, 4])
print(reduce_result)
reduce_result_str = reduce(lambda x, y: x * y, frunts)
print(reduce_result_str)
多值参数
-
有时可能需要 一个函数 能够处理的参数 个数 是不确定的,这个时候,就可以使用 多值参数
-
python中有 两种 多值参数: -
- 参数名前增加 一个
*可以接收 元组
- 参数名前增加 一个
-
- 参数名前增加 两个
*可以接收 字典
- 参数名前增加 两个
-
一般在给多值参数命名时,习惯使用以下两个名字
-
*args—— 存放 元组 参数,前面有一个*
-
**kwargs—— 存放 字典 参数,前面有两个*
-
args是arguments的缩写,有变量的含义 kw是keyword的缩写,kwargs可以记忆 键值对参数
举例
def demo(num, *args, **kwargs):
print(num)
print(args)
print(kwargs)
demo(1, 2, 3, 4, 5, name="小明", age=18, gender=True)
拆包
-
在调用带有多值参数的函数时,如果希望:
-
- 将一个 元组变量,直接传递给
args
- 将一个 元组变量,直接传递给
-
- 将一个 字典变量,直接传递给
kwargs
- 将一个 字典变量,直接传递给
-
就可以使用 拆包,简化参数的传递,拆包 的方式是:
-
- 在 元组变量前,增加 一个
*
- 在 元组变量前,增加 一个
-
- 在 字典变量前,增加 两个
*
- 在 字典变量前,增加 两个
举例
def demo(*args, **kwargs):
print(args)
print(kwargs)
# 需要将一个元组变量/字典变量传递给函数对应的参数
gl_nums = (1, 2, 3)
gl_xiaoming = {"name": "小明", "age": 18}
# 会把 num_tuple 和 xiaoming 作为元组传递个 args
# demo(gl_nums, gl_xiaoming)
demo(*gl_nums, **gl_xiaoming)
类和对象
类的定义
类名的命名规则要符合大驼峰命名法
class Student():
# 类变量
name = ''
age = 18
count = 0
# 构造函数,默认返回None
def __init__(self,name,age):
self.name = name
self.age = age
# 实例变量
self.score = 0
# 私有变量,以双下划线开头
self.__idcard = 12345
def print_info(self):
print('name: '+ self.name)
print('age: ' + str(self.age))
# 私有方法,以双下划线开头
def __marking(self):
print('成绩为: '+ str(self.score))
# 定义类方法,参数固定cls
@classmethod
def print_count(cls):
cls.count +=1
print(cls.count)
# 定义静态方法,参数随意
@staticmethod
def smethod(x,y):
pass
student = Student('qq',18)
student.print_info()
Student.print_count()
# 尽量不要在外面调用私有函数和私有变量
student._Student__marking()
print(student._Student__idcard)
-
在类封装的方法内部,
self就表示 当前调用方法的对象自己 -
调用方法时,程序员不需要传递
self参数 -
在方法内部
-
可以通过
self.访问对象的属性 -
也可以通过
self.调用其他的对象方法
汇总
class Person:
"""人类"""
def __init__(self, name, weight):
self.name = name
self.weight = weight
def __str__(self):
return "我的名字叫 %s 体重 %.2f 公斤" % (self.name, self.weight)
def run(self):
"""跑步"""
print("%s 爱跑步,跑步锻炼身体" % self.name)
self.weight -= 0.5
def eat(self):
"""吃东西"""
print("%s 是吃货,吃完这顿再减肥" % self.name)
self.weight += 1
xiaoming = Person("小明", 75)
xiaoming.run()
xiaoming.eat()
xiaoming.eat()
print(xiaoming)
生命周期
1:实例化__init__对象生命开始(在内存中分配一个内存块)
2:__del__对象生命结束(从内存中释放这个内存块)
在 Python 中
当使用 类名() 创建对象时,为对象 分配完空间后,自动 调用 __init__ 方法
当一个 对象被从内存中销毁 前,会 自动 调用 __del__ 方法
应用场景
__init__ 改造初始化方法,可以让创建对象更加灵活
__del__ 如果希望在对象被销毁前,再做一些事情,可以考虑一下 __del__ 方法
生命周期
一个对象从调用 类名() 创建,生命周期开始
一个对象的 __del__ 方法一旦被调用,生命周期结束
在对象的生命周期内,可以访问对象属性,或者让对象调用方法
继承关系
定义子类时,将父类传入子类参数内
子类实例化可以调用自己与父类的函数与变量
父类无法调用子类的函数和变量
父类
class Parent(object):
def _init__(self, name, sex):
self.name = name
self.sex = sex
def talk(self):
return f'{self.name} are walking'
def is_sex(self):
if self.sex == 'boy':
return f'{self.name} is a boy'
else:
return f'{self.name} is a girl'
子类
class Child(Parent):
def __init__(self,school,name,sex):
self.school = school
#Parent.__init__(self,name,sex)
# 调用父类构造方法
super(Child,self).__init__(name,sex)
def play_football(self):
return f'[self.name] are playing football'
多重继承
class Tool(object):
def work(self):
return 'tool work'
def car(self):
return 'car will work'
class Food(object):
def work(self):
return 'food work'
def cake(self):
return 'i like cake'
# 最左侧的类会先被继承
class Person(Tool,Food):
pass
if __name__ == '__main__':
p = Person()
p_car = p.car()
p_cake = p.cake()
p_work = p.work() # tool woek
判空
a = None
# a = ''
# a = []
# a = False
if a:
print()
if not a:
print()
异常
介绍
'''
try:
<代码块1> # 被try关键字检查并保护的业务代码
except<异常的类型>:
<代码块2> # 代码块1出现错误后执行的代码块
当except代码块有多个的时候,当捕获到第一个后不会继续往下捕获
'''
try:
1/0
except (ZeroDivisionError, Exception) as e:
print('0不能被1整除')
print('程序继续执行')
print(e)
finally:
return 'finally'
异常类型集合
Exception:通用异常类型( 基类 )
ZeroDivisionError:不能整除0
AttributeError:对象没有这个属性
IOError:输入输出操作失败
IndexError:没有当前的索引
KeyError:没有这个键值 (key)
NameError:没有这个变量 (未初始化对象)
SyntaxError:Python语法错误
SystemError:解释器的系统错误
ValueError:传入的参数错误
主动抛出自定义异常
def test(number):
if number == 100:
# 主动抛出异常
raise ValueError('number 不可以是100')
return number
# 自定义异常要继承Exception
class NameLimitError(Exception):
def __init__(self, message):
self.message = message
断言
assert len(kwargs) == 4,"参数必须是4个
进程与线程
包
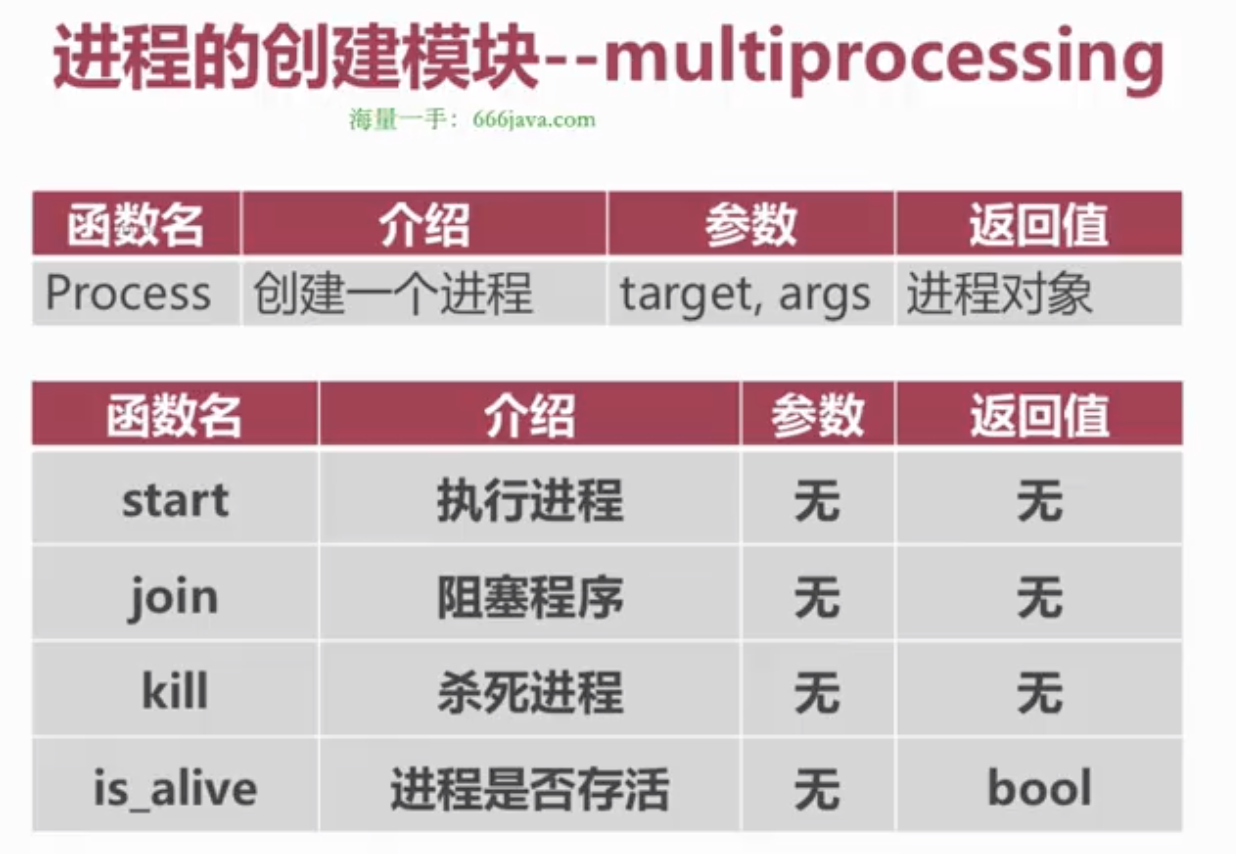
交替打印
# coding:utf-8
import time
import os
import multiprocessing
def work_a():
for i in range(10):
print(i, 'a', os.getpid())
time.sleep(1)
def work_b():
for i in range(10):
print(i, 'b', os.getpid())
time.sleep(1)
if __name__ == '__main__':
start = time.time() # 主进程1
a_p = multiprocessing.Process(target=work_a) # 子进程1
# a_p.start() # 子进程1执行
# a_p.join()
b_p = multiprocessing.Process(target=work_b) # 子进程2
# b_p.start() # 子进程2执行
for p in (a_p, b_p):
p.start()
for p in (a_p, b_p):
p.join()
for p in (a_p, b_p):
print(p.is_alive())
print('时间消耗是:', time.time() - start) # 主进程代码2
print('parent pid is %s' % os.getpid()) # 主进程代码3行
多进程存在的问题:
通过进程模块执行的函数无法获取返回值
多个进程修改文件可能出现问题
进程太多可能导致资源不足的情况
进程池

进程池和进程锁
# coding:utf-8
import os
import time
import multiprocessing
def work(count, lock):
lock.acquire()
print(count, os.getpid())
time.sleep(5)
lock.release()
return 'result is %s, pid is %s' % (count, os.getpid())
if __name__ == '__main__':
# 进程池
pool = multiprocessing.Pool(5)
manger = multiprocessing.Manager()
# 进程锁
lock = manger.Lock()
results = []
for i in range(20):
result = pool.apply_async(func=work, args=(i, lock))
# results.append(result)
# for res in results:
# print(res.get())
pool.close()
pool.join()
正则表达式
概括字符集
#概括字符集
# \d \D
# \w 单词字符 \W
# \s 空白字符 \S
# . 匹配除换行符\n之外的其他所有字符
用到百度
JSON
数据类型对比
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number | int |
| number | float |
| true | True |
| false | False |
| null | None |
序列化和反序列化
import json
# 序列化
student = [{'name':'qq','age':18,'flag':False}]
json_str = json.dumps(student)
print(type(json_str))
print(json_str)
# 反序列化
j_str = '[{"name":"ww","age":12,"flag":true}]'
student1 = json.loads(j_str)
print(type(student1))
print(student1)
结合文件写入读取
# coding;utf-8
import json
def read(path):
with open(path, 'r') as f:
data = f.read( )
return json.loads(data)
def write(path, data):
with open(path, 'w') as f:
if isinstance(data, dict):
_data = json.dumps(data)
f.write(_data)
else:
raise TypeError('data is dict')
return True
data = {'name':'小暴' ,'age': 18,'top': 176}
if __name__ == '__main__':
write('test.json', data)
result = read('test.json')
result['sex'] = 'boy'
write('test.json', result)
枚举
创建一个枚举
from enum import Enum
class VIP(Enum):
YELLO = 1
GREEN = 2
BLACK = 3
RED = 4
print(VIP.YELLO.name())
print(VIP.YELLO.value())
print(VIP(2))
函数式编程
闭包=函数+环境变量
origin = 0
def factory(pos):
def go(step):
nonlocal pos
new_pos = pos + step
pos = new_pos
return new_pos
return go
tourlist = factory(origin)
print(tourlist(2))
print(tourlist(3))
print(tourlist(5))
匿名函数
普通函数和匿名函数
from functools import reduce
def add(x,y):
return x + y
# 匿名函数
f = lambda x,y: x+y
print(add(2,3))
print(f(2,3))
lis = [1,2,3,4,5]
l = map(lambda x: x*x,lis)
print(list(l))
# 连续计算
r = reduce(lambda x,y:x+y,lis)
print(r)
# 过滤器
fl = [1,0,1,1,0]
f = filter(lambda x:True if x==1 else False,fl)
print(list(f))
三元表达式
x = 2
y = 3
res = x if x > 2 else y
print(res)
装饰器
import time
def decorator(func):
def wrapper():
print(time.time())
func()
return wrapper
def f():
print('this is a function')
fu = decorator(f)
fu()
简便写法
import time
def decorator(func):
def wrapper(*args,**kw):
print(time.time())
func(*args,**kw)
return wrapper
@decorator
def f(func_name):
print('this is a function'+func_name)
@decorator
def f2(func_name1,func_name2):
print('this is a function1'+func_name1)
print('this is a function2'+func_name2)
@decorator
def f3(func_name1,func_name2,**kw):
print('this is a function1'+func_name1)
print('this is a function2'+func_name2)
print('this is a kw'+kw)
f('func1')
f2('func1','func2')
f3('func1','func2',a=1,b=2,c=3)
构造函数装饰器
from dataclasses import dataclass
@dataclass
class Student():
name:str
age:int
st = Student('ss',18)
类方法装饰器
'''
classmethod
将类函数可以不经过实例化而直接被调用
用法:
@classmethod
def func(cls, ...):
do
参数介绍:
cls 替代普通类函数中的self变为cls,代表当前操作的是类
'''
class Test(object):
@classmethod
def add(cls, a, b):
return a + b
Test.add(1,2)
'''
staticmethod
将类函数可以不经过实例化而直接被调用,被该装饰器调用的函数不许传递self或cls参数,且无法再该函数内调用其它类函数或类变量
用法:
@staticmethod
def func(...):
参数介绍:
函数题内无cls或self参数
'''
class Test(object):
@staticmethod
def add(a, b):
return a + b
Test,add(1,2)
'''
property
将类函数的执行免去括弧,类似于调用属性(变量)
用法:
@property
def func(self):
do
'''
class Test(object):
def _init__(self, name):
self,name = name
@property
def call name(self):
return 'hello {}'.format(self.name)
test = Test('小慕')
result = tes.call_name
print(result) # hello 小慕
列表推导式
a = [1,2,3,4,5]
b = [i*i for i in a]
print(b)
# 字典推导式
student = {
"xixi":1
"haha":2
}
# 翻转
s = {value:key for key,value in student}
爬虫demo
爬取虎牙LOL直播列表主播名称和热度
'''
爬虫爬取虎牙游戏主播热度排行
技术 BeautifulSoup
爬虫框架 Scrapy
'''
from urllib import request
import ssl
import re
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
class Spider():
'''
this is a class
'''
# 获取LOL直播列表HTML页面
url = 'https://www.huya.com/g/lol'
# 包含主播名字和热度的代码块
root_parrten = '<span class="txt">[\s\S]*?</span></span>'
# 包含主播名字的代码块
name = '<i class="nick" title="([\s\S]*?)">'
# 包含主播热度的代码块
num = '<i class="js-num">([\s\S]*?)</i>'
# 处理直播列表
def __fetch_content(self):
r = request.urlopen(Spider.url)
htmls = r.read()
htmls = str(htmls,encoding='utf-8')
return htmls
# 处理名字和热度
def __analysis(self,htmls):
root_htmls = re.findall(Spider.root_parrten,htmls)
li = []
for html in root_htmls:
name = re.findall(Spider.name,html)
num = re.findall(Spider.num,html)
ma = {'name':name,'num':num}
li.append(ma)
return li
# 最终封装数据
def __fin(self,li):
l = lambda x:{
'name':x['name'][0].strip(),
'num':x['num'][0]
}
s = map(l,li)
s = sorted(s,key=self.__sorted,reverse=True)
return s
# 按照热度排序
def __sorted(self,li):
r = re.findall('[1-9\d*\.?\d*]',li['num'])
num = float(r[0])
if '万' in li['num']:
num *= 10000
return num
# 主入口
def go(self):
htmls = self.__fetch_content()
li = self.__analysis(htmls)
ma = list(self.__fin(li))
print(ma)
spider = Spider()
spider.go()