空指针和异常
-
对象空指针
-
//理解什么是空指针 public class WhatIsNpe { public static class User { private String name; private String[] address; public void print() { System.out.println("This is User Class!"); } public String readBook() { System.out.println("User Read Imooc Escape!"); return null; } } //自定义一个运行时异常 public static class CustomException extends RuntimeException {} public static void main(String[] args) { // 第一种情况: 调用了空对象的实例方法 // User user = null; // user.print(); // 第二种情况: 访问了空对象的属性 // User user = null; // System.out.println(user.name); // 第三种情况: 当数组是一个空对象的时候, 取它的长度 // User user = new User(); // System.out.println(user.address.length); // 第四种情况: null 当做 Throwable 的值 // CustomException exception = null; // throw exception; // 第五种情况: 方法的返回值是 null, 调用方直接去使用 User user = new User(); System.out.println(user.readBook().contains("MySQL")); } }
赋值自动拆箱
-
变量赋值自动拆箱出现的空指针
-
方法传参时自动拆箱出现的空指针
-
基本数据类型优于包装器类型,优先考虑使用基本类型
-
对于不确定的包装器类型,一定要校验是否是null
-
对于值为null的包装器类型,赋值为0
-
//自动拆箱引发的空指针问题 @SuppressWarnings("all") public class UnboxingNpe { private static int add(int x, int y) { return x + y; } private static boolean compare(long x, long y) { return x >= y; } public static void main(String[] args) { // 1. 变量赋值自动拆箱出现的空指针 // javac UnboxingNpe.java // javap -c UnboxingNpe.class Long count = null; long count_ = count; // 2. 方法传参时自动拆箱引发的空指针 // Integer left = null; // Integer right = null; // System.out.println(add(left, right)); // 3. 用于大小比较的场景 // Long left = 10L; // Long right = null; // System.out.println(compare(left, right)); } }
字符串,数组,集合
-
字符串使用equals时出现空指针
-
对象数组虽然new出来了,但是如果没有初始化,一样会出现空指针
-
list对象add null不报错,但是addAll不能添加null,否则NPE
-
//字符串、数组、集合在使用时出现空指针 @SuppressWarnings("all") public class BasicUsageNpe { private static boolean stringEquals(String x, String y) { return x.equals(y); } public static class User { private String name; } public static void main(String[] args) { // 1. 字符串使用 equals 可能会报空指针错误 // System.out.println(stringEquals("xyz", null)); // System.out.println(stringEquals(null, "xyz")); // 2. 对象数组 new 出来, 但是元素没有初始化 // User[] users = new User[10]; // for (int i = 0; i != 10; ++i) { // users[i] = new User(); // users[i].name = "imooc-" + i; // } // 3. List 对象 addAll 传递 null 会抛出空指针 List<User> users = new ArrayList<User>(); User user = null; List<User> users_ = null; users.add(user); users.addAll(users_); } }
optional规避空指针
-
代表存在与不存在
-
可以看做至多包含一个元素的集合
-
不能作为类的字段使用,没有实现序列化接口
-
在领域模型中小心使用
-
//学会 Optional, 规避空指针异常 @SuppressWarnings("all") public class OptionalUsage { private static void badUsageOptional() { Optional<User> optional = Optional.ofNullable(null); User user = optional.orElse(null); // good user = optional.isPresent() ? optional.get() : null; // bad } public static class User { private String name; public String getName() { return name; } } private static void isUserEqualNull() { User user = null; if (user != null) { System.out.println("User is not null"); } else { System.out.println("User is null"); } Optional<User> optional = Optional.empty(); if (optional.isPresent()) { System.out.println("User is not null"); } else { System.out.println("User is null"); } } private static User anoymos() { return new User(); } public static void main(String[] args) { // 没有意义的使用方法 isUserEqualNull(); User user = null; Optional<User> optionalUser = Optional.ofNullable(user); // 存在即返回, 空则提供默认值 optionalUser.orElse(new User()); // 存在即返回, 空则由函数去产生 optionalUser.orElseGet(() -> anoymos()); // 存在即返回, 否则抛出异常 optionalUser.orElseThrow(RuntimeException::new); // 存在才去做相应的处理 optionalUser.ifPresent(u -> System.out.println(u.getName())); // map 可以对 Optional 中的对象执行某种操作, 且会返回一个 Optional 对象 optionalUser.map(u -> u.getName()).orElse("anymos"); // map 是可以无限级联操作的 optionalUser.map(u -> u.getName()).map(name -> name.length()).orElse(0); } }
异常
- Java异常处理实践原则
- 使用异常,而不是状态码,因为异常更加详细
- 主动捕获检查性异常,并对异常信息进行记录
- 保持代码整洁,一个方法中不要有多个try catch或者嵌套
- 捕获更加具体的异常,而不是通用的exception
- 合理的设计自定义异常类
- 案例
- 可迭代对象在遍历的同时做修改,会报并发修改异常
- 类型转换不符合Java继承关系,报类型转换异常
- 枚举查找时,若枚举不存在,不会返回null,而是直接抛出异常
-
//Java 异常处理 @SuppressWarnings("all") public class ExceptionProcess { private static class User {} //Java 异常本质 -- 抛出异常 private void throwException() { User user = null; // .... if (null == user) { throw new NullPointerException(); } } //不能捕获空指针异常 private void canNotCatchNpeException() { try { throwException(); } catch (ClassCastException cce) { System.out.println(cce.getMessage()); System.out.println(cce.getClass().getName()); } } //能够捕获空指针异常 private void canCatchNpeException() { try { throwException(); } catch (ClassCastException cce) { System.out.println(cce.getMessage()); System.out.println(cce.getClass().getName()); } catch (NullPointerException npe) { System.out.println(npe.getMessage()); System.out.println(npe.getClass().getName()); } } public static void main(String[] args) { ExceptionProcess process = new ExceptionProcess(); process.canCatchNpeException(); process.canNotCatchNpeException(); } } -
//编码中的常见的异常 @SuppressWarnings("all") public class GeneralException { public static class User { private String name; public User() {} public User(String name) { this.name = name; } public String getName() { return name; } } public static class Manager extends User {} public static class Worker extends User {} private static final Map<String, StaffType> typeIndex = new HashMap<>( StaffType.values().length ); static { for (StaffType value : StaffType.values()) { typeIndex.put(value.name(), value); } } private static void concurrentModificationException(ArrayList<User> users) { // 直接使用 for 循环会触发并发修改异常 // for (User user : users) { // if (user.getName().equals("imooc")) { // users.remove(user); // } // } // 使用迭代器则没有问题 Iterator<User> iter = users.iterator(); while (iter.hasNext()) { User user = iter.next(); if (user.getName().equals("imooc")) { iter.remove(); } } } private static StaffType enumFind(String type) { // return StaffType.valueOf(type); // 1. 最普通、最简单的实现 // try { // return StaffType.valueOf(type); // } catch (IllegalArgumentException ex) { // return null; // } // 2. 改进的实现, 但是效率不高 // for (StaffType value : StaffType.values()) { // if (value.name().equals(type)) { // return value; // } // } // return null; // 3. 静态 Map 索引, 只有一次循环枚举的过程 // return typeIndex.get(type); // 4. 使用 Google Guava Enums, 需要相关的依赖 return Enums.getIfPresent(StaffType.class, type).orNull(); } public static void main(String[] args) { // 1. 并发修改异常 // ArrayList<User> users = new ArrayList<User>( // Arrays.asList(new User("qinyi"), new User("imooc")) // ); // concurrentModificationException(users); // 2. 类型转换异常 // User user1 = new Manager(); // User user2 = new Worker(); // Manager m1 = (Manager) user1; // Manager m2 = (Manager) user2; // System.out.println(user2.getClass().getName()); // System.out.println(user2 instanceof Manager); // 3. 枚举查找异常 System.out.println(enumFind("RD")); System.out.println(enumFind("abc")); } } //员工类型枚举类 public enum StaffType { RD, QA, PM, OP; }
资源泄露
-
try finally问题和改进
- 对单个资源的操作基本不会有问题
- 当同时操作多个资源时,代码冗长,且存在资源泄露风险
- try-with-resource 不仅比 try-finally方便,而且不容易出错
-
//解决使用 try finally 的资源泄露隐患 public class Main { //传统的方式实现对资源的关闭 private String traditionalTryCatch() throws IOException { // 1. 单一资源的关闭 // String line = null; // BufferedReader br = new BufferedReader(new FileReader("")); // try { // line = br.readLine(); // } finally { // br.close(); // } // return line; // 2. 多个资源的关闭 // 第一个资源 InputStream in = new FileInputStream(""); try { // 第二个资源 OutputStream out = new FileOutputStream(""); try { byte[] buf = new byte[100]; int n; while ((n = in.read(buf)) >= 0) out.write(buf, 0, n); } finally { out.close(); } } finally { in.close(); } return null; } //java7 引入的 try with resources 实现自动的资源关闭 private String newTryWithResources() throws IOException { // 1. 单个资源的使用与关闭 // try (BufferedReader br = new BufferedReader(new FileReader(""))) { // return br.readLine(); // } // 2. 多个资源的使用与关闭 try (FileInputStream in = new FileInputStream(""); FileOutputStream out = new FileOutputStream("") ) { byte[] buffer = new byte[100]; int n = 0; while ((n = in.read(buffer)) != -1) { out.write(buffer, 0, n); } } return null; } public static void main(String[] args) throws MyException { // AutoClose autoClose = new AutoClose(); // try { // autoClose.work(); // } finally { // autoClose.close(); // } try (AutoClose autoClose = new AutoClose()) { autoClose.work(); } } } public class AutoClose implements AutoCloseable { @Override public void close() { System.out.println(">>> close()"); throw new RuntimeException("Exception in close()"); } public void work() throws MyException { System.out.println(">>> work()"); throw new MyException("Exception in work()"); } } public class MyException extends Exception { public MyException() { super(); } public MyException(String message) { super(message); } }
计算,集合,接口
数字和日期
import java.math.BigDecimal;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/*<h1>数值计算和时间计算</h1>*/
@SuppressWarnings("all")
public class NumberAndTime {
/*<h2>scale 需要与小数位匹配</h2>*/
private static void scaleProblem() {
BigDecimal decimal = new BigDecimal("12.222");
// BigDecimal result = decimal.setScale(12);
// System.out.println(result);
BigDecimal result = decimal.setScale(2, BigDecimal.ROUND_HALF_UP);
System.out.println(result);
}
/*<h2>BigDecimal 做除法时出现除不尽的情况</h2>*/
private static void divideProblem() {
// System.out.println(new BigDecimal(30).divide(new BigDecimal(7)));
System.out.println(
new BigDecimal(30).divide(new BigDecimal(7), 2,
BigDecimal.ROUND_HALF_UP)
);
}
/*<h2>精度问题导致比较结果和预期的不一致</h2>*/
private static void equalProblem() {
BigDecimal bd1 = new BigDecimal("0");
BigDecimal bd2 = new BigDecimal("0.0");
System.out.println(bd1.equals(bd2));
System.out.println(bd1.compareTo(bd2) == 0);
}
//<h2>SimpleDateFormat 可以解析大于/等于它定义的时间精度</h2>
private static void formatPrecision() throws Exception {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String time_x = "2020-03-01 10:00:00";
String time = "2020-03";
System.out.println(sdf.parse(time_x));
System.out.println(sdf.parse(time));
}
//SimplleDateFormat 存在线程安全问题</h2>
private static void threadSafety() {
SimpleDateFormat sdf = new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss");
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(
10, 100, 1, TimeUnit.MINUTES,
new LinkedBlockingDeque<>(1000)
);
while (true) {
threadPoolExecutor.execute(() -> {
String dateString = "2020-03-01 10:00:00";
try {
Date parseDate = sdf.parse(dateString);
String dateString2 = sdf.format(parseDate);
System.out.println(dateString.equals(dateString2));
} catch (ParseException ex) {
ex.printStackTrace();
}
});
}
}
public static void main(String[] args) throws Exception {
// scaleProblem();
// divideProblem();
// equalProblem();
// formatPrecision();
threadSafety();
}
}
for循环
-
传统的for循环是怎样的
- 如果是数组,通过数组长度,建立索引
- 如果是集合,迭代器
-
传统for循环的弊端
- 需要的是可迭代对象中的元素,并不需要元素的索引
- 在嵌套环境下,需要小心迭代器对象的正确性
-
for-each 优于for
- 只专注于迭代对象自身,而不考虑多余的索引
- 任何实现iterable接口的对象,都可以使用for-each循环处理
- Java8 iterable.forEach在一些场景下会更方便
-
/*<h1>小小 for 循环, 沾上集合出大问题</h1>*/ @SuppressWarnings("all") public class ForeachOptimize { private static Collection<Integer> left = Arrays.asList(1, 2, 3, 4, 5, 6, 7); private static Collection<Integer> right = Arrays.asList(1, 2, 3, 4, 5); /*<h2>集合迭代经常犯的错误</h2>*/ private static void wrongIterator() { // // 传统方式 - 使用索引 // int[] xyz = new int[]{1, 2, 3, 4, 5}; // for (int i = 0; i != xyz.length; ++i) { // System.out.println(xyz[i]); // } // // // 传统方式 - 迭代器 // for (Iterator<Integer> i = left.iterator(); i.hasNext(); ) { // System.out.println(i.next()); // } // 嵌套迭代容易出现问题 // for (Iterator<Integer> l = left.iterator(); l.hasNext(); ) { // for (Iterator<Integer> r = right.iterator(); r.hasNext(); ) { // System.out.println(l.next() * r.next()); // } // } // 正确的用法, 嵌套迭代 // for (Iterator<Integer> l = left.iterator(); l.hasNext(); ) { // Integer tmp = l.next(); // for (Iterator<Integer> r = right.iterator(); r.hasNext(); ) { // System.out.println(tmp * r.next()); // } // } for (Integer l : left) { for (Integer r : right) { System.out.println(l * r); } } } private static void square(int value) { System.out.println(value * value); } public static void main(String[] args) { wrongIterator(); // Java8 Iterable.forEach vs for-each for (Integer l : left) { square(l); } left.forEach(l -> square(l)); left.forEach(ForeachOptimize::square); } }
满地坑的List列表
Arrays.asList
- 我们初始化三个数字的 int[]数组,然后使用 Arrays.asList 把数组转换为List
int[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
log.info("list:{} size:{} class:{}", list, list.size(), list.get(0).getClass());
/*这个List 包含的其实是一个 int 数组,整个 List 的元素个数是 1,元素类型是整数数组。
其原因是,只能是把 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。我们知
道,Arrays.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为了一个
对象成为了泛型类型 T
*/
- 直接遍历这样的 List 必然会出现 Bug,修复方式有两种,如果使用 Java8 以上版本可以使 用 Arrays.stream 方法来转换,否则可以把 int 数组声明为包装类型 Integer 数组
int[] arr1 = {1, 2, 3};
List list1 = Arrays.stream(arr1).boxed().collect(Collectors.toList());
log.info("list:{} size:{} class:{}", list1, list1.size(), list1.get(0).getClass());
Integer[] arr2 = {1, 2, 3};
List list2 = Arrays.asList(arr2);
log.info("list:{} size:{} class:{}", list2, list2.size(), list2.get(0).getClass());
- 第一个坑,不能直接使用 Arrays.asList 来转换基本类型数组
- 第二个坑,Arrays.asList 返回的 List 不支持增删操作
String[] arr = {"1", "2", "3"};
List list = Arrays.asList(arr);
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);
/*
日志里有一个 UnsupportedOperationException,为 List 新增字符串 5 的操
作失败了,而且把原始数组的第二个元素从 2 修改为 4 后,asList 获得的 List 中的第二个
元素也被修改为 4 了
*/
- Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。ArrayList 内部类继承自AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException。
- 第三个坑,对原始数组的修改会影响到我们获得的那个 List。
- ArrayList 其实是直接使用了原始的数组。Arrays.asList 获得的 List 交给其他方法处理,很容易因为共享了数组,相互修改产生Bug。
- 修复方式比较简单,重新 new 一个 ArrayList 初始化 Arrays.asList 返回的 List 即可
String[] arr = {"1", "2", "3"};
List list = new ArrayList(Arrays.asList(arr));
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);
- 修改后的代码实现了原始数组和 List 的“解耦”,不再相互影响。同时,因为操作的是真正的 ArrayList,add 也不再出错
使用 List.subList会OOM
- List.subList 返回的子List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响。如果不注意,很可能会因此产生 OOM 问题。
- 定义一个名为 data 的静态 List 来存放 Integer 的 List,也就是说 data 的成员本身是包含了多个数字的 List。循环 1000 次,每次都从一个具有 10 万个 Integer 的List 中,使用 subList 方法获得一个只包含一个数字的子 List,并把这个子 List 加入 data变量
private static List<List<Integer>> data = new ArrayList<>();
private static void oom() {
for (int i = 0; i < 1000; i++) {
List<Integer> rawList = IntStream.rangeClosed(1, 100000).boxed().collect(Collectors.toList());
data.add(rawList.subList(0, 1));
}
}
/*
你可能会觉得,这个 data 变量里面最终保存的只是 1000 个具有 1 个元素的 List,不会占
用很大空间,但程序运行不久就出现了 OOM
*/
- 出现 OOM 的原因是,循环中的 1000 个具有 10 万个元素的 List 始终得不到回收,因为它始终被 subList 方法返回的 List 强引用。
- 首先初始化一个包含数字 1 到 10 的 ArrayList,然后通过调用 subList 方法取出 2、3、4;随后删除这个 SubList 中的元素数字 3,并打印原始的 ArrayList;最后为原始的ArrayList 增加一个元素数字 0,遍历 SubList 输出所有元素
List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toList());
List<Integer> subList = list.subList(1, 4);
System.out.println(subList);
subList.remove(1);
System.out.println(list);
list.add(0);
try {
subList.forEach(System.out::println);
} catch (Exception ex) {
ex.printStackTrace();
}
/*
[2, 3, 4]
[1, 2, 4, 5, 6, 7, 8, 9, 10]
java.util.ConcurrentModificationException
at java.util.ArrayList$SubList.checkForComodification(ArrayList.java:1239)
at java.util.ArrayList$SubList.listIterator(ArrayList.java:1099)
at java.util.AbstractList.listIterator(AbstractList.java:299)
at java.util.ArrayList$SubList.iterator(ArrayList.java:1095)
at java.lang.Iterable.forEach(Iterable.java:74)
原始 List 中数字 3 被删除了,说明删除子 List 中的元素影响到了原始 List;
尝试为原始 List 增加数字 0 之后再遍历子 List,会出现ConcurrentModificationException。
*/
- 第一,ArrayList 维护了一个叫作 modCount 的字段,表示集合结构性修改的次数。所谓 结构性修改,指的是影响 List 大小的修改,所以 add 操作必然会改变 modCount 的值。
- 第二,获得的 List 其实是内部类 SubList,并不是普通的 ArrayList,在初始化的时候传入了 this。
- 第三,这个 SubList 中的 parent 字段就是原始的List。SubList 初始化的时候,并没有把原始 List 中的元素复制到独立的变量中保存。我们可以认为 SubList 是原始 List 的视图,并不是独立的 List。双方对元素的修改会相互影响,而且 SubList 强引用了原始的 List,所以大量保存这样的 SubList 会导致 OOM。
- 第四,遍历 SubList 的时候会先获得迭代器,比较原始ArrayList modCount 的值和 SubList 当前 modCount 的值。获得了 SubList 后,我们为原始 List 新增了一个元素修改了其 modCount,所以判等失败抛出 ConcurrentModificationException 异常。
- 既然 SubList 相当于原始 List 的视图,那么避免相互影响的修复方式有两种:
- 一种是,不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList;
- 另一种是,对于 Java 8 使用 Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数,同样可以达到 SubList 切片的目的。
//方式一
List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toList());
List<Integer> subList = new ArrayList<>(list.subList(1, 4));
System.out.println(subList);
subList.remove(1);
System.out.println(list);
list.add(0);
subList.forEach(System.out::println);
//方式2
List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toList());
List<Integer> subList = list.stream().skip(1).limit(3).collect(Collectors.toList());
System.out.println(subList);
subList.remove(1);
System.out.println(list);
list.add(0);
subList.forEach(System.out::println);
选用合适的数据结构
ListVSMap
- 第一个误区是,使用数据结构不考虑平衡时间和空间。
- 首先,定义一个只有一个 int 类型订单号字段的 Order 类
@Data
@NoArgsConstructor
@AllArgsConstructor
static class Order {
private int orderId;
}
- 定义一个包含 elementCount 和 loopCount 两个参数的 listSearch 方法,初始化一个具有 elementCount 个订单对象的 ArrayList,循环 loopCount 次搜索这个ArrayList,每次随机搜索一个订单号
private static Object listSearch(int elementCount, int loopCount) {
List<Order> list = IntStream.rangeClosed(1, elementCount).mapToObj(i -> new Order(i)).collect(Collectors.toList());
IntStream.rangeClosed(1, loopCount).forEach(i -> {
int search = ThreadLocalRandom.current().nextInt(elementCount);
Order result = list.stream().filter(order -> order.getOrderId() == search).findFirst().orElse(null);
Assert.assertTrue(result != null && result.getOrderId() == search);
});
return list;
}
- 定义另一个 mapSearch 方法,从一个具有 elementCount 个元素的 Map 中循环loopCount 次查找随机订单号。Map 的 Key 是订单号,Value 是订单对象
private static Object mapSearch(int elementCount, int loopCount) {
Map<Integer, Order> map = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toMap(Function.identity(), i -> new Order(i)));
IntStream.rangeClosed(1, loopCount).forEach(i -> {
int search = ThreadLocalRandom.current().nextInt(elementCount);
Order result = map.get(search);
Assert.assertTrue(result != null && result.getOrderId() == search);
});
return map;
}
- 对 100 万个元素的 ArrayList 和 HashMap,分别调用 listSearch 和mapSearch 方法进行 1000 次搜索
int elementCount = 1000000;
int loopCount = 1000;
StopWatch stopWatch = new StopWatch();
stopWatch.start("listSearch");
Object list = listSearch(elementCount, loopCount);
System.out.println(ObjectSizeCalculator.getObjectSize(list));
stopWatch.stop();
stopWatch.start("mapSearch");
Object map = mapSearch(elementCount, loopCount);
stopWatch.stop();
System.out.println(ObjectSizeCalculator.getObjectSize(map));
System.out.println(stopWatch.prettyPrint());
TimeUnit.HOURS.sleep(1);
/*
可以看到,仅仅是 1000 次搜索,listSearch 方法耗时 3.3 秒,而 mapSearch 耗时仅仅108 毫秒。
*/
- 搜索 ArrayList 的时间复杂度是 O(n),而 HashMap 的 get 操作的时间复杂度是 O(1)。所以,要对大 List 进行单值搜索的话,可以考虑使用 HashMap,其中 Key 是要搜索的值,Value 是原始对象,会比使用 ArrayList 有非常明显的性能优势。
- 即使我们要搜索的不是单值而是条件区间,也可以尝试使用 HashMap 来进行“搜索性能优化”。如果你的条件区间是固定的话,可以提前把 HashMap 按照条件区间进行分组,Key 就是不同的区间。
- 类似,如果要对大 ArrayList 进行去重操作,也不建议使用 contains 方法,而是可以考虑使用HashSet 进行去重。使用 HashMap 是否会牺牲空间呢?分析堆可以再次证明,ArrayList 在内存占用上性价比很高。所以,在应用内存吃紧的情况下,我们需要考虑是否值得使用更多的内存消耗来换取更高的性能。
ArrayVSLinked
- 第二个误区是,过于迷信教科书的大 O 时间复杂度。
- 对于数组,随机元素访问的时间复杂度是 O(1),元素插入操作是 O(n);
- 对于链表,随机元素访问的时间复杂度是 O(n),元素插入操作是 O(1)。
- 定义四个参数一致的方法,分别对元素个数为 elementCount 的 LinkedList 和 ArrayList,循环 loopCount 次,进行随机访问和增加元素到随机位置的操作
//LinkedList访问
private static void linkedListGet(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(LinkedList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.get(ThreadLocalRandom.current().nextInt(elementCount)));
}
//ArrayList访问
private static void arrayListGet(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(ArrayList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.get(ThreadLocalRandom.current().nextInt(elementCount)));
}
//LinkedList插入
private static void linkedListAdd(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(LinkedList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.add(ThreadLocalRandom.current().nextInt(elementCount), 1));
}
//ArrayList插入
private static void arrayListAdd(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(ArrayList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.add(ThreadLocalRandom.current().nextInt(elementCount), 1));
}
- 测试
int elementCount = 100000;
int loopCount = 100000;
StopWatch stopWatch = new StopWatch();
stopWatch.start("linkedListGet");
linkedListGet(elementCount, loopCount);
stopWatch.stop();
stopWatch.start("arrayListGet");
arrayListGet(elementCount, loopCount);
stopWatch.stop();
System.out.println(stopWatch.prettyPrint());
StopWatch stopWatch2 = new StopWatch();
stopWatch2.start("linkedListAdd");
linkedListAdd(elementCount, loopCount);
stopWatch2.stop();
stopWatch2.start("arrayListAdd");
arrayListAdd(elementCount, loopCount);
stopWatch2.stop();
System.out.println(stopWatch2.prettyPrint());
/*
在随机访问方面,我们看到了 ArrayList 的绝对优势
但,随机插入操作居然也是 LinkedList 落败
---------------------------------------------
ns % Task name
---------------------------------------------
6604199591 100% linkedListGet
011494583 000% arrayListGet
StopWatch '': running time = 10729378832 ns
---------------------------------------------
ns % Task name
---------------------------------------------
9253355484 086% linkedListAdd
1476023348 014% arrayListAdd
*/
- 翻看 LinkedList 源码发现,插入操作的时间复杂度是 O(1) 的前提是,你已经有了那个要 插入节点的指针。但,在实现的时候,我们需要先通过循环获取到那个节点的 Node,然后 再执行插入操作。前者也是有开销的,不可能只考虑插入操作本身的代价
- 对于插入操作,LinkedList 的时间复杂度其实也是 O(n)。
关于remove方法
- 调用类型是 Integer 的 ArrayList 的 remove 方法删除元素,传入一个 Integer 包装类 的数字和传入一个 int 基本类型的数字,结果一样吗?
//删除指定坐标元素
private static void removeByIndex(int index) {
List<Integer> list =
IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toCollection(ArrayList::new));
System.out.println(list.remove(index));
System.out.println(list);
}
//删除对应元素
private static void removeByValue(Integer index) {
List<Integer> list =
IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toCollection(ArrayList::new));
System.out.println(list.remove(index));
System.out.println(list);
}
- 循环遍历 List,调用 remove 方法删除元素,往往会遇到 ConcurrentModificationException 异常,原因是什么,修复方式又是什么呢?
private static void forEachRemoveWrong() {
List<String> list =
IntStream.rangeClosed(1, 10).mapToObj(String::valueOf).collect(Collectors.toCollection(ArrayList::new));
for (String i : list) {
if ("2".equals(i)) {
list.remove(i);
}
}
System.out.println(list);
}
private static void forEachRemoveRight() {
List<String> list =
IntStream.rangeClosed(1, 10).mapToObj(String::valueOf).collect(Collectors.toCollection(ArrayList::new));
for (Iterator<String> iterator = list.iterator(); iterator.hasNext(); ) {
String next = iterator.next();
if ("2".equals(next)) {
iterator.remove();
}
}
System.out.println(list);
}
private static void forEachRemoveRight2() {
List<String> list =
IntStream.rangeClosed(1, 10).mapToObj(String::valueOf).collect(Collectors.toCollection(ArrayList::new));
list.removeIf(item -> item.equals("2"));
System.out.println(list);
}
线程
synchronized

atomic
spring
- bean名称生成策略
- 定义一个bean(使用@Component,@Service),spring生成的bean名称是把第一个字母变成小写,其他不变
- 若第一个,第二个字母都是大写,则直接返回
- spring自动装配规则
- 属性对象虽然注入了,但是当前类没有标记为bean,导致获取属性NPE
- 当前类标记为来bean,且属性对象也注入了,但是却用new创建了当前对象,获取对象中的属性也会NPE
- 使用bean的整个过程,都应该被spring容器所管理
- spring默认的包扫描机制是当前包以及子包下的所有目录,在这些目录以外的类不会被扫描进入spring管理
- 可以使用@ComponentScan注解
- value,includeFilters,excludeFilters,lazyInit
- spring容器
- 不常用的容器实现:BeanFactory:提供基本的DI功能
- 应用上下文:ApplicationContext:解析配置文件,注册管理bean
- 生成应用上下文的四种方式
- 实现ApplicationContextInitializer接口
- 实现ApplicationListener接口,观察者模式
- 实现ApplicationContextAware接口
- 注解和异常
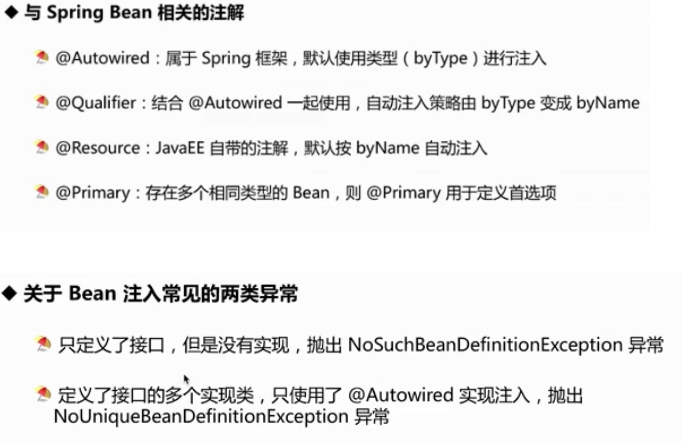
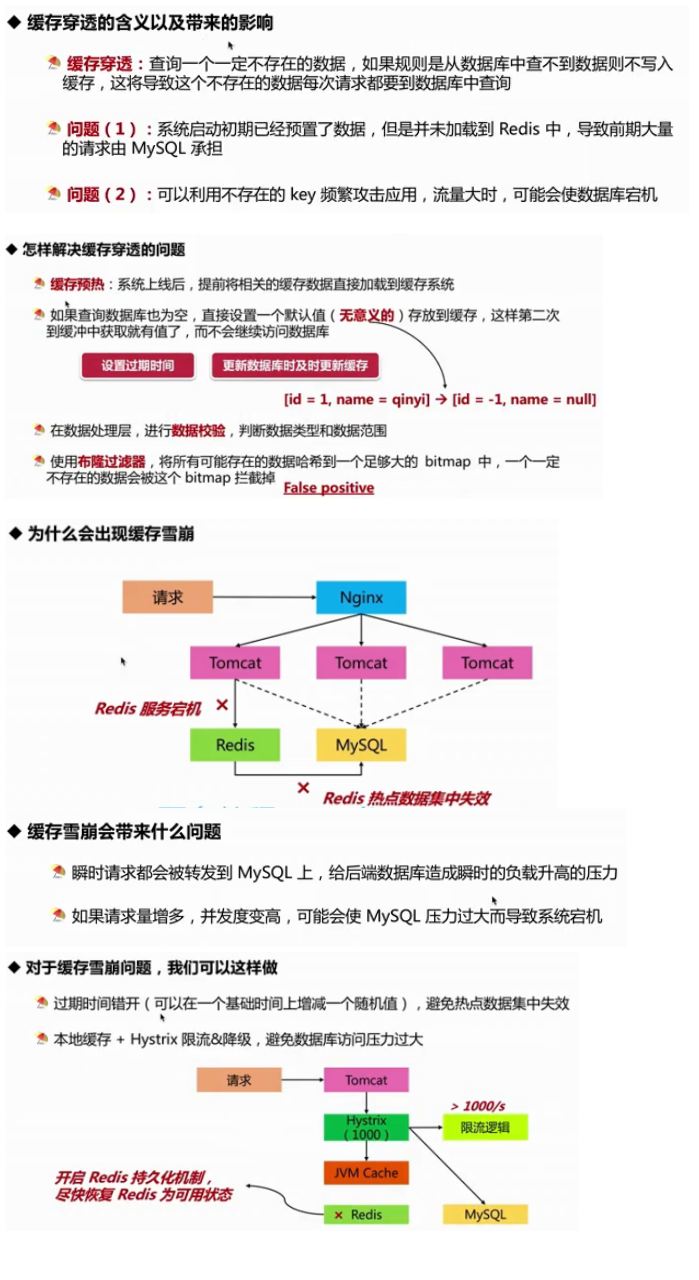
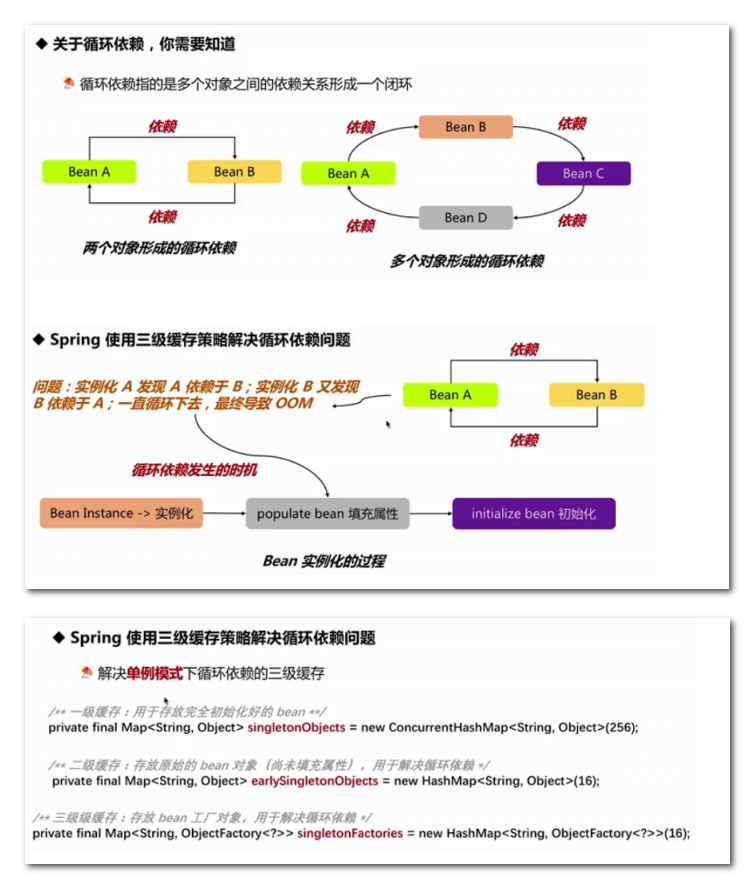
- 循环依赖
- bean处理器

- 事务处理
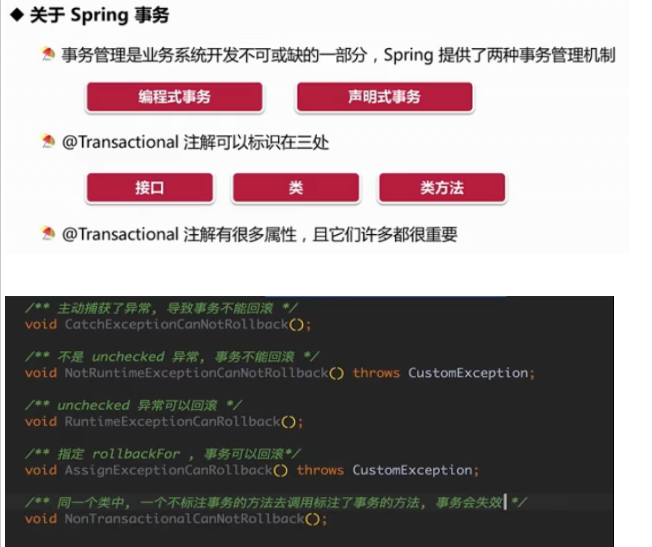
工具类中无法注入mapper
- 因为一般情况下工具类是不归spring容器管理的,这时候使用@Autowired注解去注入mapper是不管用的
- 使用@PostConstruct注解声明一个初始化方法
- 声明一个本工具类的静态变量
- 在初始化方法中初始化mapper
public class MysqlDateUtils {
@Autowired
private SysUserMapper sysUserMapper;
private static MysqlDateUtils mysqlDateUtils;
@PostConstruct
public void init() {
mysqlDateUtils = this;
mysqlDateUtils.sysUserMapper = this.sysUserMapper;
}
/**
* 获取数据库当前的年月日(yyyy-MM-dd HH:mm:ss)
* @return Date
*/
public static String getMysqlNowDate() {
return parseMysqlDateToStr("yyyy-MM-dd",mysqlDateUtils.sysUserMapper.getMysqlNowDate());
}
/**
* 获取数据库当前的年月日时分秒(yyyy-MM-dd HH:mm:ss)
* @return DateTime
*/
public static String getMysqlNowDateTime() {
return parseMysqlDateToStr("yyyy-MM-dd HH:mm:ss",mysqlDateUtils.sysUserMapper.getMysqlNowDate());
}
public static final String parseMysqlDateToStr(final String format, final Date date)
{
return new SimpleDateFormat(format).format(date);
}
springMVC
状态码
- 使用ResponseEntity类:标识整个HTTP响应(状态码,头部信息,响应体)
- 异常类或controller方法上标识@ResponseStatus注解
- 使用@ControllerAdvice(@RestControllerAdvice)和@ExceptionHandler注解
日期序列化
- 前台到后台的时间格式转换
- 使用@JsonFormat注解,但是格式单一
-
实现自定义格式转换器@JsonDeserialize
-
converter
-
@Slf4j public class DateJacksonConverter extends JsonDeserializer<Date> { private static final String[] pattern = new String[] { "yyyy-MM-dd HH:mm:ss", "yyyy/MM/dd" }; @Override public Date deserialize(JsonParser jsonParser, DeserializationContext context) throws IOException, JsonProcessingException { Date targetDate = null; String originDate = jsonParser.getText(); if (StringUtils.isNotEmpty(originDate)) { try { long longDate = Long.parseLong(originDate.trim()); targetDate = new Date(longDate); } catch (NumberFormatException pe) { try { targetDate = DateUtils.parseDate( originDate, DateJacksonConverter.pattern ); } catch (ParseException ex) { log.error("parse error: {}", ex.getMessage()); throw new IOException("parse error"); } } } return targetDate; } @Override public Class<?> handledType() { return Date.class; } } -
config
-
@Configuration public class DateConverterConfig { @Bean public DateJacksonConverter dateJacksonConverter() { return new DateJacksonConverter(); } @Bean public Jackson2ObjectMapperFactoryBean jackson2ObjectMapperFactoryBean( @Autowired DateJacksonConverter dateJacksonConverter ) { Jackson2ObjectMapperFactoryBean jackson2ObjectMapperFactoryBean = new Jackson2ObjectMapperFactoryBean(); jackson2ObjectMapperFactoryBean.setDeserializers(dateJacksonConverter); return jackson2ObjectMapperFactoryBean; } }
过滤器和拦截器
-
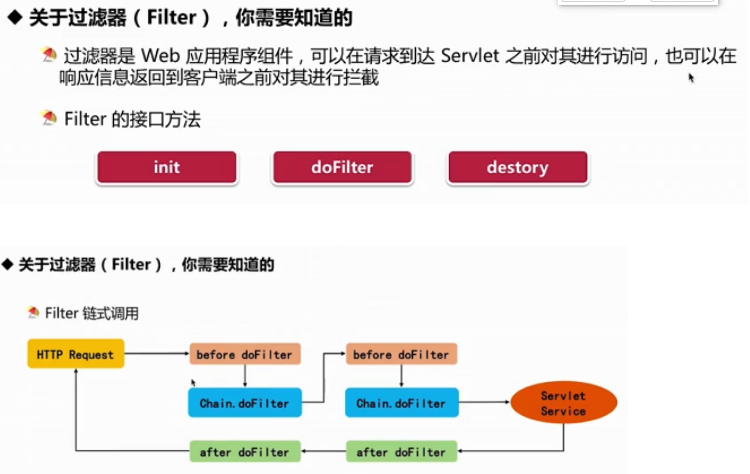
-

-
LogFilter
-
@Slf4j @WebFilter(urlPatterns = "/*", filterName = "LogFilter") public class LogFilter implements Filter { @Override public void init(FilterConfig filterConfig) throws ServletException { } @Override public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { long start = System.currentTimeMillis(); chain.doFilter(request, response); log.info("LogFilter Print Log: {} -> {}", ((HttpServletRequest) request).getRequestURI(), System.currentTimeMillis() - start); } @Override public void destroy() { } } -
LogInterceptor
-
@Slf4j @Component public class LogInterceptor implements HandlerInterceptor { long start = System.currentTimeMillis(); @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { start = System.currentTimeMillis(); HandlerMethod handlerMethod = (HandlerMethod) handler; log.info("LogInterceptor: {}", ((HandlerMethod) handler).getBean() .getClass().getName()); log.info("LogInterceptor: {}", handlerMethod.getMethod().getName()); return true; } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { log.info("LogInterceptor Print Log: {} -> {}", request.getRequestURI(), System.currentTimeMillis() - start); } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { } } -
UpdateLogInterceptor
-
@Slf4j @Component public class UpdateLogInterceptor implements HandlerInterceptor { @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { request.setAttribute("startTime", System.currentTimeMillis()); return true; } @Override public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { log.info("UpdateLogInterceptor Print Log: {} -> {}", request.getRequestURI(), System.currentTimeMillis() - (long) request.getAttribute("startTime")); } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { } } -
WebInterceptorAdapter
-
@Component @Configuration public class WebInterceptorAdapter implements WebMvcConfigurer { @Override public void addInterceptors(InterceptorRegistry registry) { registry.addInterceptor(new LogInterceptor()).addPathPatterns("/星星").order(0); registry.addInterceptor(new UpdateLogInterceptor()) .addPathPatterns("/星星").order(1); registry.addInterceptor(new UserIdInterceptor()).addPathPatterns("/星星") .order(3); } }
输入输出流
- 一个流可以理解为一个数据的序列
- 输入流标识从一个源读取数据,输出流标识向一个目标写数据
- 在过滤器,拦截器中对HTTP请求中的数据做校验,如果是json数据,我们就需要读取输入流
- request的getInputStream()和getReader()都只能使用一次
- Request的getInputStream() getReader() getParameter()方法互斥,也就是使用了其中一个,再使用另外的两个是获取不到数据的
- Response也是一样
- 使用HttpServletRequestWrapper+Filter解决输入流不能重复读取问题
springBoot
配置文件
- 使用一个全局的配置文件,且配置文件名是固定的,配置文件的作用是来修改springboot自动配置的默认值
- 可以使用application.properties格式,也可以使用application.yml格式
- 由于yaml格式可读性高,推荐使用
-
如果两种配置文件同时存在的时候,默认优先使用.properties配置文件
- 配置文件优先级加载顺序

多环境配置
- 多环境使用spring.profile.active可以指定配置文件
- 使用占位符${spring.profiles.active},在启动命令中指定配置文件
定时任务

Jackson

- 消除json字符串中的循环引用
//com.alibaba.fastjson.JSONObject # toJSONString 消除循环引用
JSONObject.toJSONString(object, SerializerFeature.DisableCircularReferenceDetect)
跨域
跨域问题:
-
添加响应头,配置当次请求允许跨域
-
- Access-Control-Allow-Origin:支持哪些来源的请求跨域
- Access-Control-Allow-Methods:支持哪些方法跨域
- Access-Control-Allow-Credentials:跨域请求默认不包含cookie,设置为true可以包含cookie
- Access-Control-Expose-Headers:跨域请求暴露的字段CORS请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到6个基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。
- Access-Control-Max-Age:表明该响应的有效时间为多少秒。在有效时间内,浏览器无 须为同一请求再次发起预检请求。请注意,浏览器自身维护了一个最大有效时间,如果 该首部字段的值超过了最大有效时间,将不会生效。
- 添加跨域配置
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.cors.CorsConfiguration;
import org.springframework.web.cors.reactive.CorsWebFilter;
import org.springframework.web.cors.reactive.UrlBasedCorsConfigurationSource;
@Configuration
public class PassJavaCorsConfiguration {
@Bean
public CorsWebFilter corsWebFilter() {
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
CorsConfiguration corsConfiguration = new CorsConfiguration();
// 配置跨域
corsConfiguration.addAllowedHeader("*"); // 允许所有请求头跨域
corsConfiguration.addAllowedMethod("*"); // 允许所有请求方法跨域
corsConfiguration.addAllowedOrigin("*"); // 允许所有请求来源跨域
corsConfiguration.setAllowCredentials(true); //允许携带cookie跨域,否则跨域请求会丢失cookie信息
source.registerCorsConfiguration("/**", corsConfiguration);
return new CorsWebFilter(source);
}
}
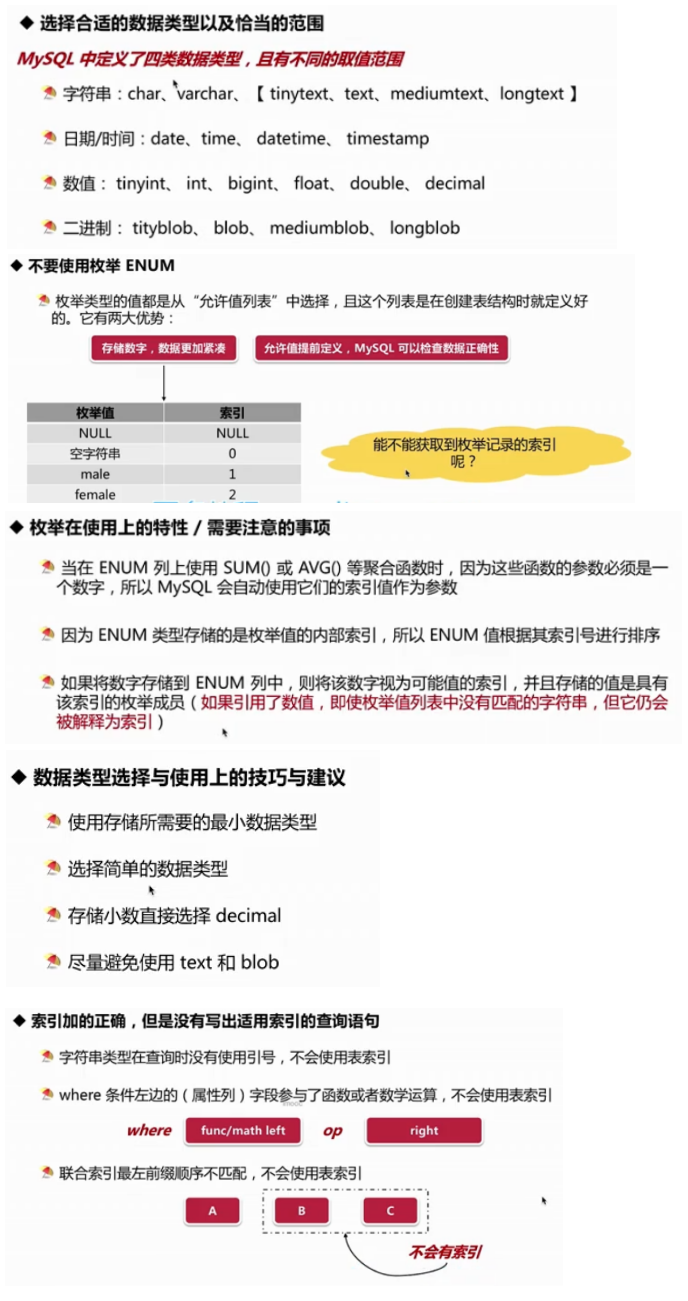
MySQL
- null是默认行为,如果你不指定列字段是not null的,那么,他就是null的
- 一个很严重的误区,null不占用存储空间(是一种优化行为)
- null属性非常方便,sql语句或者代码不需要额外的填充或判断
- MySQL难以优化引用可空列查询,他会使索引,索引统计和值更加复杂。可空列需要更多的存储空间,还需要MySQL内部进行特殊处理。可空列被索引后,每条记录都需要一个额外的字节,还能导致myisam中固定大小的索引变成可变大小的索引
- null的长度并不是0
- 可以使用特殊值取填充null,例如空字符串,或数字0
- 对于已经存在数据的表,填充特殊值到null列,再去修改表结构
- 虽然MySQL允许创建表时不指定主键,但是一定要指定一个主键,如果没有指定主键,判断是否存在非空整形唯一索引,有则成为主键,否则INNODB会自动添加隐式主键
- 主键不具有任何业务含义,只是一个唯一的自增整数值
-

- MySQL连接参数

- MySQL慢查询

- MySQL分库分表

MySQL中的null坑
- 首先定义一个只有 id 和 score 两个字段的实体
@Entity
@Data
public class User {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private Long score;
}
- 程序启动的时候,往实体初始化一条数据,其 id 是自增列自动设置的 1,score 是NULL
@Autowired
private UserRepository userRepository;
@PostConstruct
public void init() {
userRepository.save(new User());
}
-
测试下面三个用例,来看看结合数据库中的 null 值可能会出现的坑:
通过 sum 函数统计一个只有 NULL 值的列的总和,比如 SUM(score)
select 记录数量,count 使用一个允许 NULL 的字段,比如 COUNT(score)
使用 =NULL 条件查询字段值为 NULL 的记录,比如 score=null 条件
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@Query(nativeQuery=true,value = "SELECT SUM(score) FROM `user`")
Long wrong1();
@Query(nativeQuery = true, value = "SELECT COUNT(score) FROM `user`")
Long wrong2();
@Query(nativeQuery = true, value = "SELECT * FROM `user` WHERE score=null")
List<User> wrong3();
}
/*
得到的结果,分别是 null、0 和空 List
虽然记录的 score 都是 NULL,但 sum 的结果应该是 0 才对;
虽然这条记录的 score 是 NULL,但记录总数应该是 1 才对;
使用 =NULL 并没有查询到 id=1 的记录,查询条件失效。
*/
- MySQL 中 sum 函数没统计到任何记录时,会返回 null 而不是 0,可以使用 IFNULL 函数把 null 转换为 0
- MySQL 中 count 字段不统计 null 值,COUNT(*) 才是统计所有记录数量的正确方式。
- MySQL 中 =NULL 并不是判断条件而是赋值,对 NULL 进行判断只能使用 IS NULL 或者 IS NOT NULL。
- 在MySQL的使用中,对于索引列,建议都设置为not null,因为如果有null的话,MySQL需要单独专门处理null值,会额外耗费性能。
@Query(nativeQuery = true, value = "SELECT IFNULL(SUM(score),0) FROM `user`")
Long right1();
@Query(nativeQuery = true, value = "SELECT COUNT(*) FROM `user`")
Long right2();
@Query(nativeQuery = true, value = "SELECT * FROM `user` WHERE score IS NULL")
List<User> right3();
/*
可以得到三个正确结果,分别为 0、1、[User(id=1, score=null)] :
*/
Redis
- 常用的数据类型和适用场景
- string:字符串类型,应用广泛,常用于计数器,session等键值独立的数据
- hash:存储结构化的数据,KV共同构建一个对象的信息
- list:队列,栈,有界队列
- set:去重,无序的数据集合,在类似于社交的业务功能上应用广泛
- sortedSet:带有权重的集合,在类似于排行榜业务上有广泛应用,可以实现范围查找