初识redis
-
redis是什么:开源的基于键值对的存储服务系统。拥有多种数据结构,高性能,功能丰富
-
redis特性:
速度快,10w OPS 内存
持久化,将数据的更新异步的保存在磁盘上
多种数据结构,字符串、hash、列表、集合、有序集合 延伸到位图
支持多种编程语言。
功能丰富,–发布订阅 LUA脚本 事务 pipeline(并发效率)“ 瑞士军刀”
简单, –不依赖外部库 单线程模型
主从复制(重要)
高可用,分布式(重点)
v2.8开始支持Redis-Sentinel(哨兵)高可用
v3.0开始支持Redis-Cluster 分布式
-
redis典型应用场景:
缓存系统
计数器
消息队列系统
排行榜
社交系统

实时系统

安装
$ wget http://download.redis.io/releases/redis-5.0.2.tar.gz (3.0.7版本)
$ tar xzf redis-5.0.2.tar.gz
$
通常建立软连接 ln -s redis-3.0.7 redis
$ cd redis-5.0.2
$ make
$ make install
-
可执行文件说明:
- redis-server Redis服务器
- redis-cli Redis命令行客户端
- redis-benchmark Redis性能测试
- redis-check-aof AOF文件修复工具
- redis-check-dump RDB文件修复工具
- redis-sentinel Sentinel服务器(2.8以后)
-
三种启动方式:
- 最简单启动 redis-server
ps -ef|grep redis netstat -antpl|grep redis redis-cli -h ip -p port ping- 动态参数启动
redis-server --port 6380 (默认6379)- 配置文件启动
redis-server configPath- 比较
生产环境选择配置启动 单机多实例配置文件开源用端口号区分开 简单的客户端链接: redis-cli -h 10.10.79.150 -p 6384 ping set hello world get hello -
redis常用配置
- deamonize 是否是守护进程默认no建议yes
- 修改protected-mode yes 改为 protected-mode no
- 注释掉 #bin 127.0.0.1
- prot redis对外端口号
- logfile redis系统日志
- dir redis工作目录
--------------cat redis-6380.conf |grep -v "#"|grep -v "^$">redis-6382.conf -------------------查看配置属性清晰 [root@redis01 redis]# redis-server config/redis-6382.conf [root@redis01 redis]# more config/redis-6382.conf daemonize yes port 6382 dir "/opt/moudels/redis/data" ----需要自己建立文件夹 logfile "6382.log" [root@redis01 redis]# 日志位置: /opt/moudels/redis/data - redis6.0.8
- 官网地址:https://redis.io/
- 中文官网地址:http://www.redis.cn/
单线程与多线程
redis重要里程碑
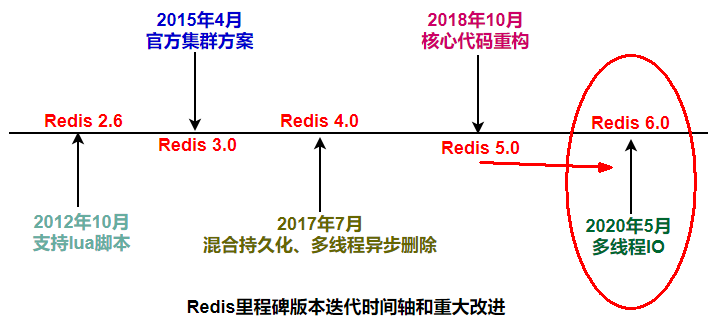
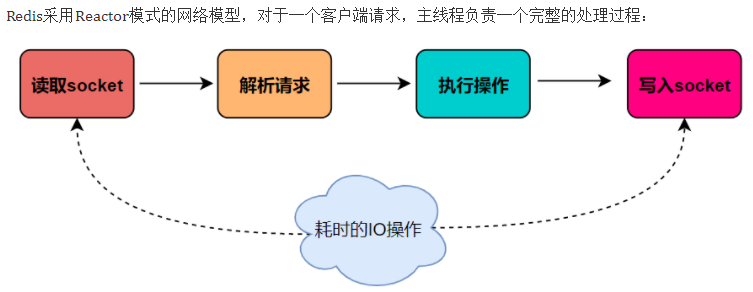
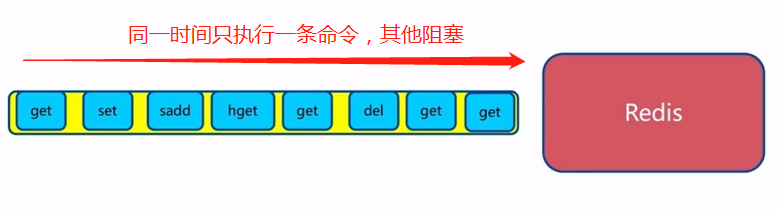
Redis是单线程主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。
但Redis的其他功能,比如持久化、异步删除、集群数据同步等等,其实是由额外的线程执行的。 Redis工作线程是单线程的,但是,整个Redis来说,是多线程的;
Redis3.x单线程时代但性能依旧很快的主要原因:
- 基于内存操作:Redis 的所有数据都存在内存中,因此所有的运算都是内存级别的,所以他的性能比较高;
- 数据结构简单:Redis 的数据结构是专门设计的,而这些简单的数据结构的查找和操作的时间大部分复杂度都是 O(1),因此性能比较高;
- 多路复用和非阻塞 I/O:Redis使用 I/O多路复用功能来监听多个 socket连接客户端,这样就可以使用一个线程连接来处理多个请求,减少线程切换带来的开销,同时也避免了 I/O 阻塞操作
- 避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的发生
简单来说,Redis 4.0 之前一直采用单线程的主要原因有以下三个:
1 使用单线程模型是 Redis 的开发和维护更简单,因为单线程模型方便开发和调试;
2 即使使用单线程模型也并发的处理多客户端的请求,主要使用的是多路复用和非阻塞 IO;
3 对于 Redis 系统来说,主要的性能瓶颈是内存或者网络带宽而并非 CPU。
单线程存在什么问题?
这就是redis3.x单线程时代最经典的故障,大key删除的头疼问题,由于redis是单线程的,正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如时包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿。
使用惰性删除可以有效的避免 Redis 卡顿的问题
在 Redis 4.0 中就新增了多线程的模块,当然此版本中的多线程主要是为了解决删除数据效率比较低的问题的。
unlink key
flushdb async
flushall async
把删除工作交给了后台(子线程)异步来删除数据了。
在Redis 4.0就引入了多个线程来实现数据的异步惰性删除等功能,但是其处理读写请求的仍然只有一个线程,所以仍然算是狭义上的单线程。
对于Redis主要的性能瓶颈是内存或者网络带宽而并非 CPU。
Unix网络编程中的五种IO模型:
Blocking IO - 阻塞IO
NoneBlocking IO - 非阻塞IO
IO multiplexing - IO多路复用

signal driven IO - 信号驱动IO
asynchronous IO - 异步IO
Redis工作线程是单线程的,但是,整个Redis来说,是多线程的;
I/O 的读和写本身是堵塞的,比如当 socket 中有数据时,Redis 会通过调用先将数据从内核态空间拷贝到用户态空间,再交给 Redis 调用,而这个拷贝的过程就是阻塞的,当数据量越大时拷贝所需要的时间就越多,而这些操作都是基于单线程完成的。
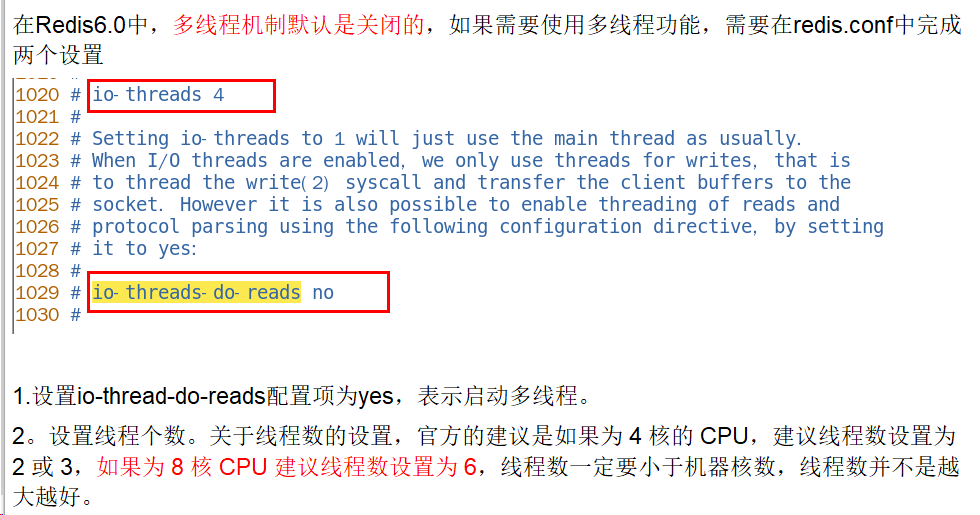
在 Redis 6.0 中新增了多线程的功能来提高 I/O 的读写性能,他的主要实现思路是将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket 的读写可以并行化了,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Socket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。
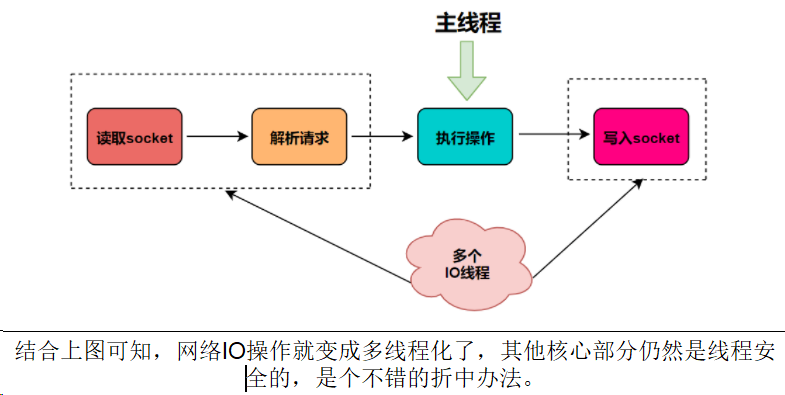
Redis 6.0 将网络数据读写、请求协议解析通过多个IO线程的来处理 ,对于真正的命令执行来说,仍然使用主线程操作,一举两得,便宜占尽!
Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis服务器可以处理8W到10W的QPS, 这也是Redis处理的极限了,对于80%的公司来说,单线程的Redis已经足够使用了。
Redis自身出道就是优秀,基于内存操作、数据结构简单、多路复用和非阻塞 I/O、避免了不必要的线程上下文切换等特性,在单线程的环境下依然很快;
但对于大数据的 key 删除还是卡顿厉害,因此在 Redis 4.0 引入了多线程unlink key/flushall async 等命令,主要用于 Redis 数据的异步删除;
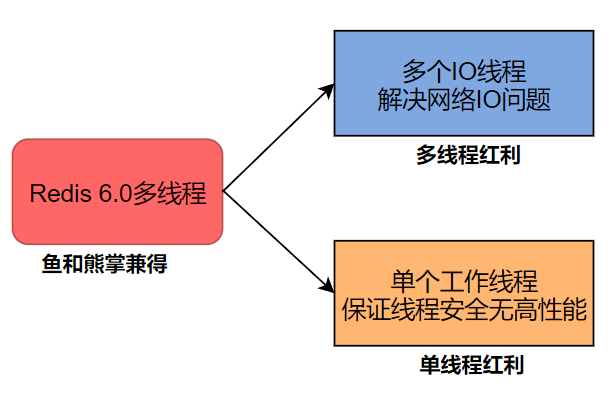
而在 Redis 6.0 中引入了 I/O 多线程的读写,这样就可以更加高效的处理更多的任务了,Redis 只是将 I/O 读写变成了多线程,而命令的执行依旧是由主线程串行执行的,因此在多线程下操作 Redis 不会出现线程安全的问题。
Redis 无论是当初的单线程设计,还是如今与当初设计相背的多线程,目的只有一个:让 Redis 变得越来越快。
redis API
- 官方命令大全:http://www.redis.cn/commands.html
- 论坛:http://doc.redisfans.com/
- 命令不区分大小写,而key是区分大小写的
- help @类型名词
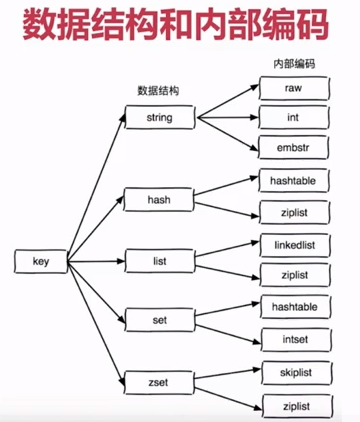
- 八大类型:
- 1.String(字符类型)
- 2.Hash(散列类型)
- 3.List(列表类型)
- 4.Set(集合类型)
- 5.SortedSet(有序集合类型,简称zset)
- 6.Bitmap(位图)
- 7.HyperLogLog(统计)
- 8.GEO(地理)
-
通用命令:
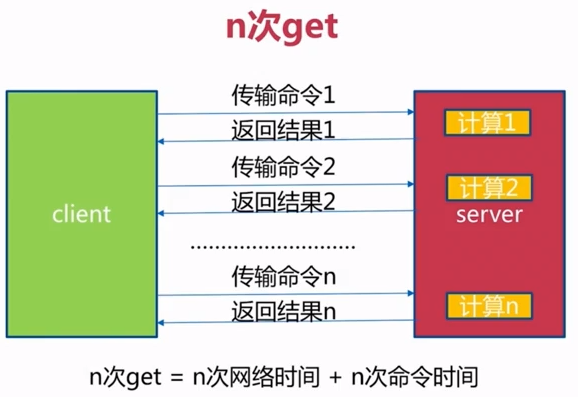
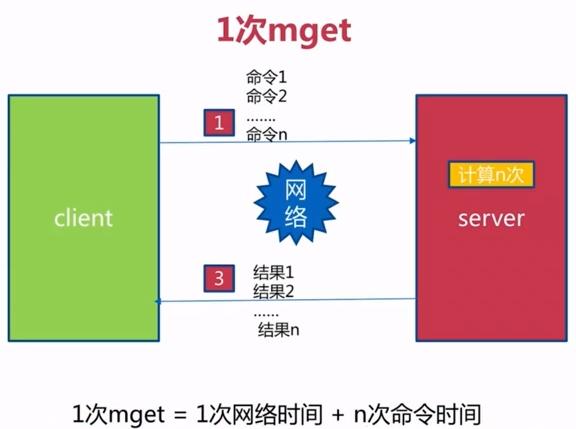
- mset /mget : 批量设置 减少了网络时间 一般而言=网络时间+命令时间
-
sadd myset a b c d e 将一个或多个成员元素加入到集合中
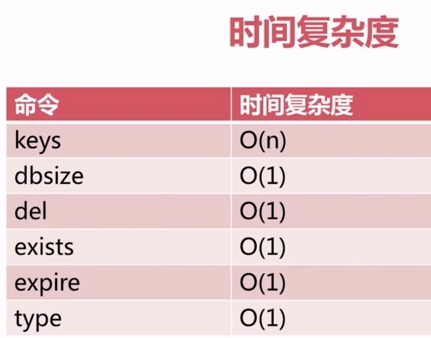
- keys *:获取所有的key(生产不适用 热备从节点 scan)


- dbsize:获取键的总数

- exists:判断key是否存在

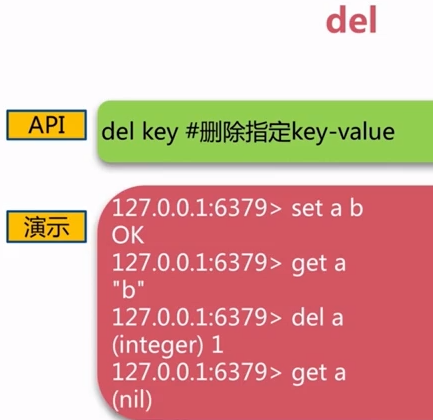
- del:删除键值对
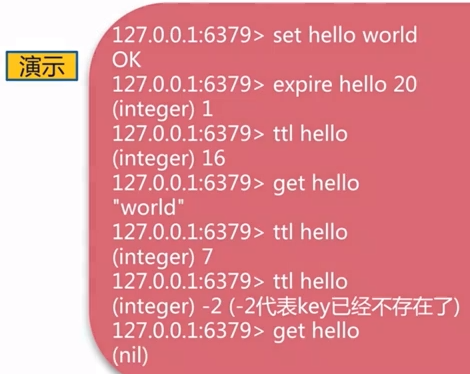
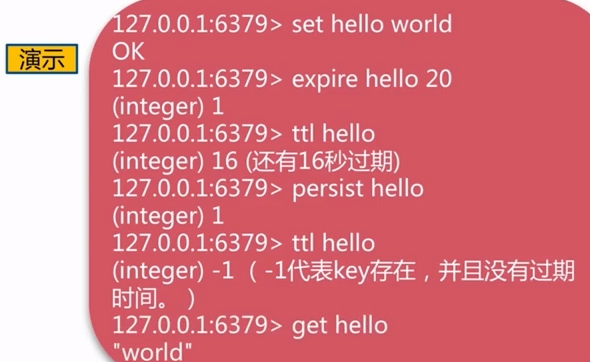
- expire,ttl,persist :过期相关

- type:获取键的类型

- 时间复杂度
- 数据结构和内部编码
- 单线程架构
- 单线程为什么这么快:纯内存存储,非阻塞IO,避免场景切换和静态消耗
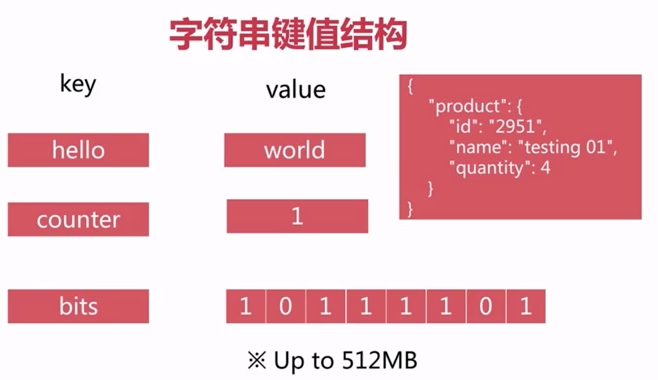
String 字符串
- 键值结构
- 场景:缓存、计数器、分布式锁等。
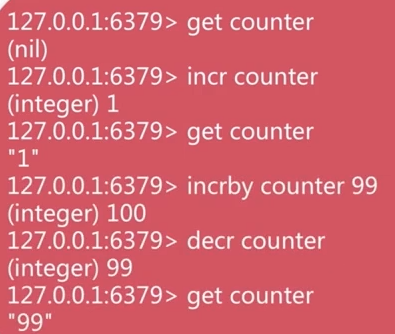
- 获取get,设置值set,删除del


- 自增incr,自减decr,增加一定数值incrby,减少一定数值decrby

- 实战应用:缓存视频的基本信息(数据源在MySQL中)

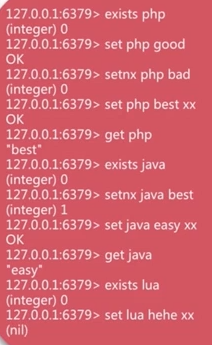
- set,setnx,setxx

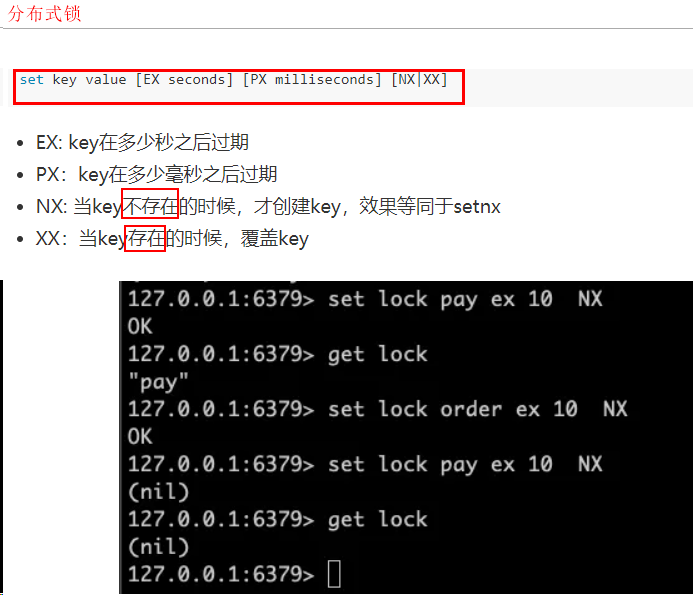
分布式锁
- 批量获取mget,批量设置值mset


- getset,append,strlen


- incrbyfloat,getrange,setrange


- 应用场景
- 商品编号,订单号采用INCR命令生成
- 点赞计数
Hash 哈希
-
Map<String,Map<Object,object>> -
键值结构

- hset,hget,hdel


- hexists,hlen


- hmget,hmset


- 实战:获取视频信息

- hgetall,hvals,hkeys


- hsetnx,hincrby,hincrbyfloat

- 应用场景

list 列表
-
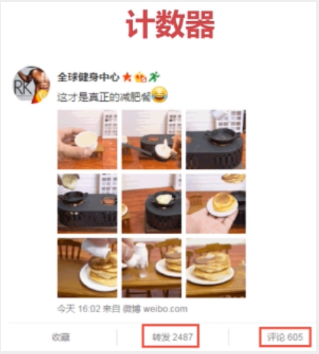
一个双端链表的结构,容量是2的32次方减1个元素,大概40多亿,主要功能有push/pop等,一般用在栈、队列、消息队列等场景。
-
数据结构


- rpush,lpush

- linsert,rinsert

- lpop,rpop

- lrem

- ltrim

- lrange

- lindex

- llen

- lset

- blpop,brpop

- TIPS
1:LPUSH + LPOP = Stack
2:LPUSH + RPOP = Queue
3:LPUSH + LTRIM = Capped Colection
4:LPUSH + BRPOP = Message Queue
- 应用场景

set无序列表
- 数据结构

- 特点:无序,无重复,集合间操作
- sadd,srem

- scard,sismember,srandmember(不会破坏集合),smember(无序),spop(从集合弹出)

- 实战

-
实战,抽奖系统,点赞
-
sdiff,sinter,sunion

- 应用场景
- 微信抽奖小程序
1、 用户ID,立即参与按钮:sadd key 用户ID
2、 显示已经有多少人参与了,上图23208人参加:SCARD key
3、 抽奖(从set中任意选取N个中奖人):
SRANDMEMBER key 2 随机抽奖2个人,元素不删除
SPOP key 3 随机抽奖3个人,元素会删除
- 朋友圈点赞
1、 新增点赞:sadd pub:msgID 点赞用户ID1 点赞用户ID2
2、 取消点赞:srem pub:msgID 点赞用户ID
3、 展现所有点赞过的用户:SMEMBERS pub:msgID
4、 点赞用户数统计,就是常见的点赞红色数字:scard pub:msgID
5、 判断某个朋友是否对楼主点赞过:SISMEMBER pub:msgID 用户ID
- 可能认识的人

- 共同关注的人,共同爱好:取交集
zset:有序集合
- 数据结构



- zadd

- zrem

- zscore

- zincrby

- zcard

- 综合演示

- zrange

- zrangebyscore

- zcount

- zremrangebyrank

- zremrangebyscore

- 综合演示

- zrevrank,zrevrange,zrevrangebyscore,zinterstore,zunionstore
- 热卖商品排行
定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
1、商品编号1001的销量是9,商品编号1002的销量是15
zadd goods:sellsort 9 1001 15 1002
2、有一个客户又买了2件商品1001,商品编号1001销量加2
zincrby goods:sellsort 2 1001
3、求商品销量前10名
ZRANGE goods:sellsort 0 10 withscores
- 热搜排行
新数据类型
需求痛点:亿量级数据的收集和统计
存的进,取得快,多统计
1:聚合统计:统计多个集合元素的聚合结果,就是交差并等集合统计,主要是交并差集和聚合函数的应用
2:排序统计:
以抖音vcr最新的留言评价为案例,所有评论需要两个功能,按照时间排序+分页显示
方案1:
每个商品评价对应一个List集合,这个List包含了对这个商品的所有评论,而且会按照评论时间保存这些评论, 每来一个新评论就用LPUSH命令把它插入List的队头。但是,如果在演示第二页前,又产生了一个新评论, 第2页的评论不一样了。
原因:List是通过元素在List中的位置来排序的,当有一个新元素插入时,原先的元素在List中的位置都后移了一位,原来在第1位的元素现在排在了第2位,当LRANGE读取时,就会读到旧元素。
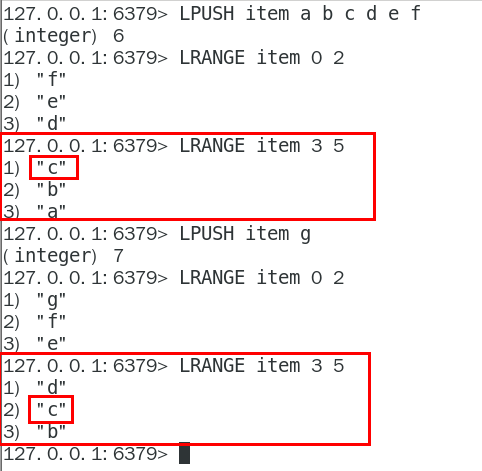
方案二:
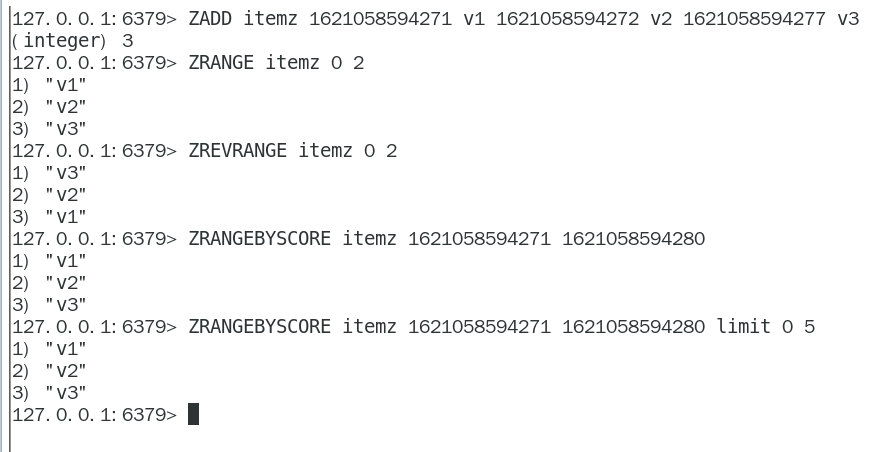
在⾯对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使⽤ZSet
3:二值统计:集合元素的取值就只有0和1两种。在钉钉上班签到打卡的场景中,我们只用记录有签到(1)或没签到(0),可以用bigmap实现
4:基数统计:指统计⼀个集合中不重复的元素个数,可以用hyperloglog实现
bitmap位图
用String类型作为底层数据结构实现的一种统计二值状态的数据类型;换句话说:由0和1状态表现的二进制位的bit数组
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们可以称之为一个索引或者位格)。Bitmap支持的最大位数是2^32位,它可以极大的节约存储空间,使用512M内存就可以存储多大42.9亿的字节信息(2^32 = 4294967296)

按年去存储一个用户的签到情况,365 天只需要 365 / 8 ≈ 46 Byte,1000W 用户量一年也只需要 44 MB 就足够了。
假如是亿级的系统, 每天使用1个1亿位的Bitmap约占12MB的内存(10^8/8/1024/1024),10天的Bitmap的内存开销约为120MB,内存压力不算太高。在实际使用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录以节省内存开销。
典型应用场景:
电影、广告是否被点击播放过
钉钉打卡上下班,签到统计
日活统计
最近一周的活跃用户
统计指定用户一年之中的登陆天数
某用户按照一年365天,哪几天登陆过?哪几天没有登陆?全年中登录的天数共计多少?
用户是否登陆过Y、N,比如京东每日签到送京豆;
签到日历仅展示当月签到数据
签到日历需展示最近连续签到天数
假设当前日期是20210618,且20210616未签到
若20210617已签到且0618未签到,则连续签到天数为1
若20210617已签到且0618已签到,则连续签到天数为2
连续签到天数越多,奖励越大
所有用户均可签到
截至2020年3月31日的12个月,京东年度活跃用户数3.87亿,同比增长24.8%,环比增长超2500万,此外,2020年3月移动端日均活跃用户数同比增长46%假设10%左右的用户参与签到,签到用户也高达3千万
MySQL解决方法:
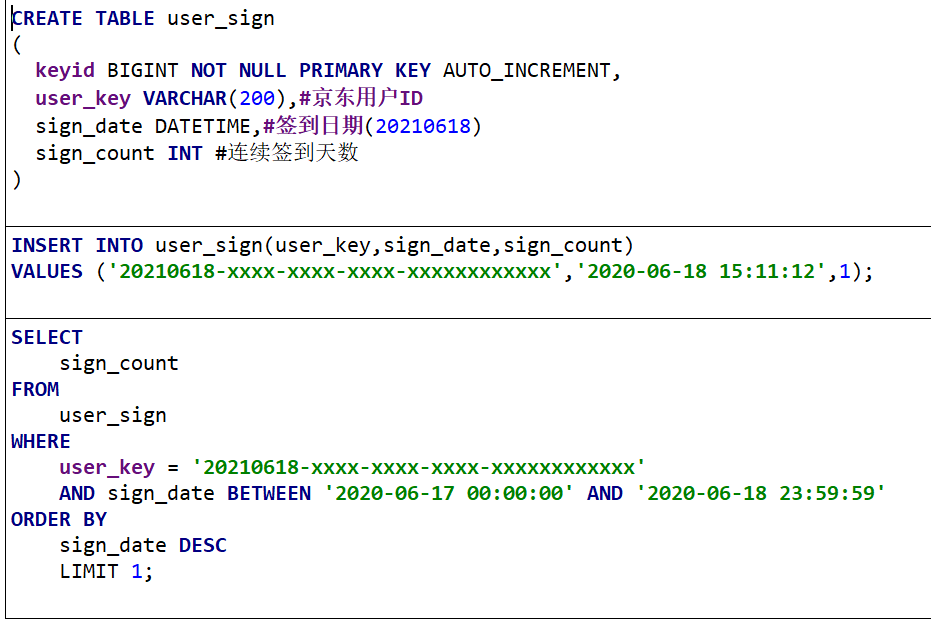
签到用户量较小时这么设计能行,但京东这个体量的用户(估算3000W签到用户,一天一条数据,一个月就是9亿数据)对于京东这样的体量,如果一条签到记录对应着当日用记录,那会很恐怖……
如何解决这个痛点?
1 一条签到记录对应一条记录,会占据越来越大的空间。 2 一个月最多31天,刚好我们的int类型是32位,那这样一个int类型就可以搞定一个月,32位大于31天,当天来了位是1没来就是0。 3 一条数据直接存储一个月的签到记录,不再是存储一天的签到记录。
在签到统计时,每个用户一天的签到用1个bit位就能表示, 一个月(假设是31天)的签到情况用31个bit位就可以,一年的签到也只需要用365个bit位,根本不用太复杂的集合类型
基本命令
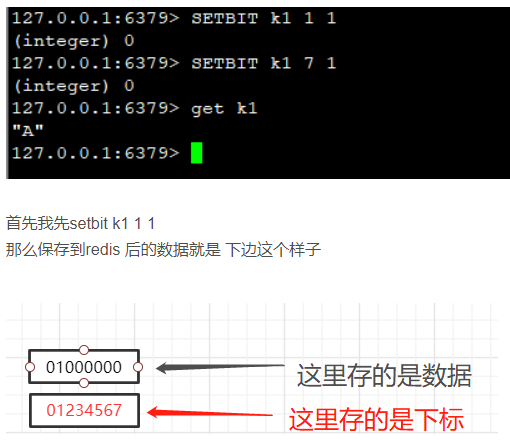
setbit key offset value
setbit 键 偏移位 只能0或者1
Bitmap的偏移量是从零开始算的
getbit key offset
getbit 键 偏移位
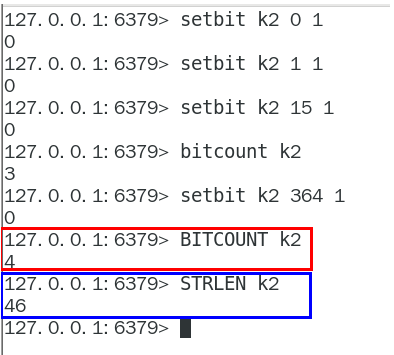
strlen key :统计字节数占用多少
不是字符串长度而是占据几个字节,超过8位后自己按照8位一组一byte再扩容

bitcount key:全部键里面含有1的有多少个
bitop
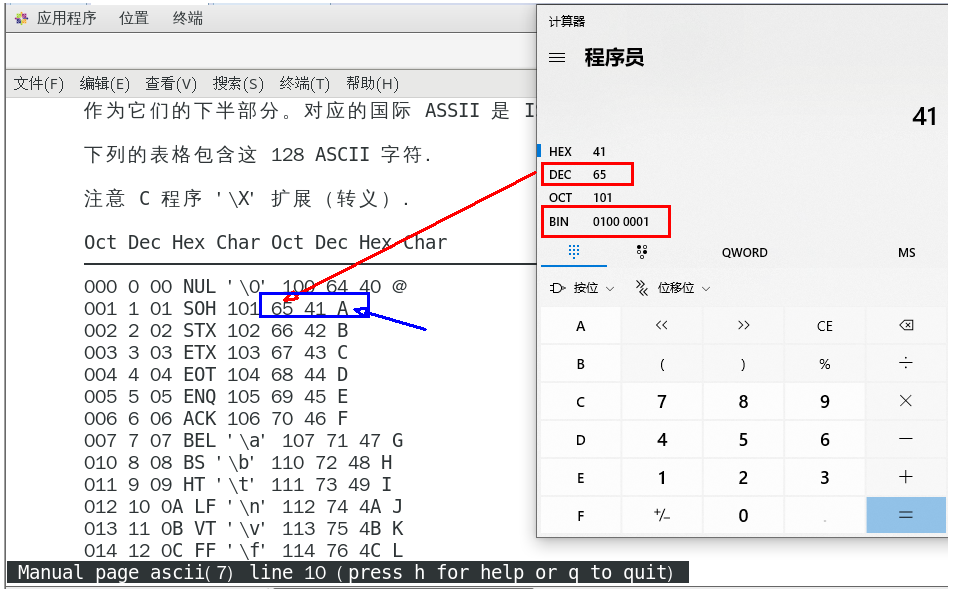
bitmap的底层编码说明,get命令操作如何
实质是二进制的ascii编码对应
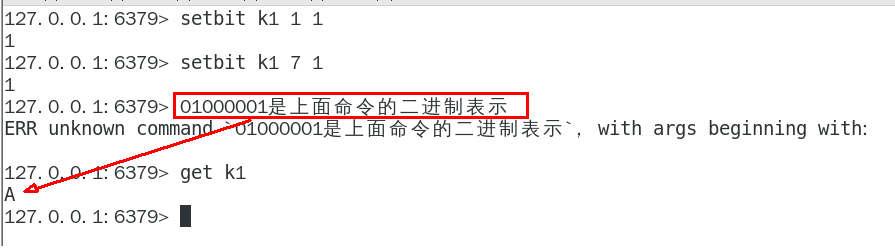
两个setbit命令对k1进行设置后,对应的二进制串就是0100 0001
二进制串就是0100 0001对应的10进制就是65,所以见下图:
hyperloglog去重统计


去重复统计功能的基数估计算法就是Hyperloglog
基数:是一种数据集,去重复后的真实个数

基数统计:用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
可不可以用bitmaps做数据较大的亿级统计?

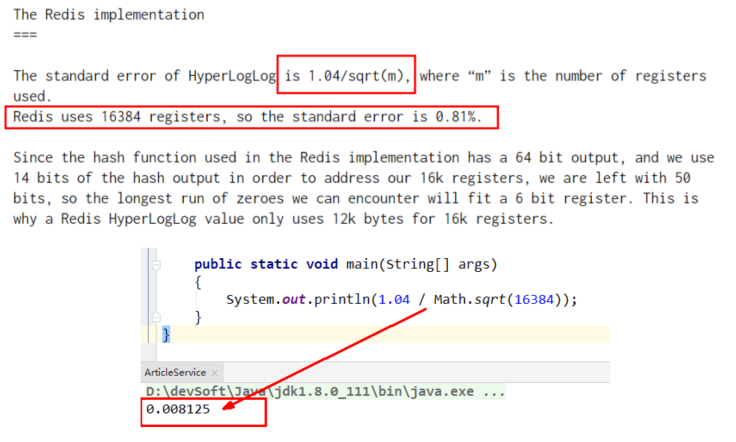
什么是概率算法:通过牺牲准确率来换取空间,误差仅仅只有0.81%左右,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,通过一定的概率统计方法预估数值,同时保证误差在一定范围内,故可以大大节约内存。
为什么Redis集群的最大槽数是16384个?

https://github.com/redis/redis/issues/2576

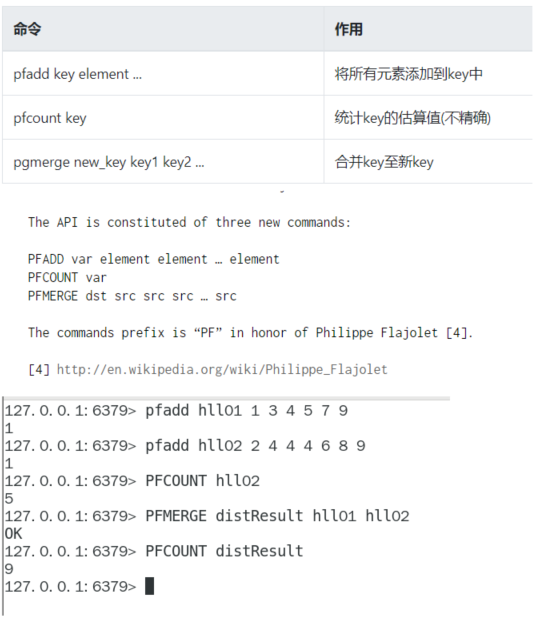
基本命令
UV:Unique Visitor,独立访客,可以理解为客户端IP
PV:Page View,页面浏览量
DAU:Daily Active User,日活跃用户量,登陆或者使用某个功能的用户数(去重登陆的用户)
MAU:Monthly Active User,月活跃用户数
代码实现
@Api(description = "案例实战总03:天猫亿级UV的Redis统计方案")
@RestController
@Slf4j
public class HyperLogLogController
{
@Resource
private RedisTemplate redisTemplate;
@ApiOperation("获得IP去重后的首页访问量")
@RequestMapping(value = "/uv",method = RequestMethod.GET)
public long uv()
{
//pfcount
return redisTemplate.opsForHyperLogLog().size("hll");
}
}
service
@Service
@Slf4j
public class HyperLogLogService
{
@Resource
private RedisTemplate redisTemplate;
/**
* 模拟后台有用户点击首页,每个用户来自不同ip地址
*/
@PostConstruct
public void init()
{
log.info("------模拟后台有用户点击首页,每个用户来自不同ip地址");
new Thread(() -> {
String ip = null;
for (int i = 1; i <=200; i++) {
Random r = new Random();
ip = r.nextInt(256) + "." + r.nextInt(256) + "." + r.nextInt(256) + "." + r.nextInt(256);
Long hll = redisTemplate.opsForHyperLogLog().add("hll", ip);
log.info("ip={},该ip地址访问首页的次数={}",ip,hll);
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
}
},"t1").start();
}
}
GEO地理坐标
Redis在3.2版本以后增加了地理位置的处理
地理位置是使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90, 90],只要我们确定一个点的经纬度就可以明确他在地球的位置。
例如滴滴打车,最直观的操作就是实时记录更新各个车的位置,当我们要找车时,在数据库中查找距离我们(坐标x0,y0)附近r公里范围内部的车辆
使用SQL表示
select taxi from position where x0-r < x < x0 + r and y0-r < y < y0+r
但是这样会有什么问题呢? 1.查询性能问题,如果并发高,数据量大这种查询是要搞垮数据库的 2.这个查询的是一个矩形访问,而不是以我为中心r公里为半径的圆形访问。 3.精准度的问题,我们知道地球不是平面坐标系,而是一个圆球,这种矩形计算在长距离计算时会有很大误差
GEO原理:将三维的地球转换为二维的坐标;将二维坐标转换为一维的点;将一维的点转换为二进制再通过base32编码
GEO Hash的核心原理:https://www.cnblogs.com/LBSer/p/3310455.html
查询经纬度:https://jingweidu.bmcx.com/
基本命令:
GEOADD:多个经度(longitude)、纬度(latitude)、位置名称(member)添加到指定的 key 中
GEOADD city 116.403963 39.915119 "天安门" 116.403414 39.924091 "故宫" 116.024067 40.362639 "长城"
3
type city
zset
解决中文乱码
redis-cli --raw
zrange city 0 -1
天安门
故宫
长城
GEOPOS 从键里面返回所有给定位置元素的位置(经度和纬度),不存在则返回nil。
geopos city 天安门
116.40396
39.9151197
GEODIST 返回两个给定位置之间的距离,后边参数是距离单位
geodist city 天安门 长城 km
59.3390
geodist city 天安门 长城 m
59338.9814
GEORADIUS 以给定的经纬度为中心, 返回与中心的距离不超过给定最大距离的所有位置元素
georadius city 116.418017 39.914402 10 km withdist withcoord count 10 withhash desc
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。
WITHCOORD: 将位置元素的经度和维度也一并返回。
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大
COUNT 限定返回的记录数。
GEORADIUSBYMEMBER 跟GEORADIUS类似:找出位于指定范围内的元素,中心点是由给定的位置元素决定
georadiusbymember city 天安门 10 km withdist withcoord count 10 withhash desc
GEOHASH返回一个或多个位置元素的 Geohash 表示
geohash city 天安门 故宫 长城
wx4g0f6f2v0
wx4g0gfqsj0
wx4t85y1kt0
实例场景
controller
@RestController
public class GeoController
{
public static final String CITY ="city";
@Autowired
private RedisTemplate redisTemplate;
@RequestMapping("/geoadd")
public String geoAdd()
{
Map<String, Point> map= new HashMap<>();
map.put("天安门",new Point(116.403963,39.915119));
map.put("故宫",new Point(116.403414 ,39.924091));
map.put("长城" ,new Point(116.024067,40.362639));
redisTemplate.opsForGeo().add(CITY,map);
return map.toString();
}
@GetMapping(value = "/geopos")
public Point position(String member) {
//获取经纬度坐标
List<Point> list= this.redisTemplate.opsForGeo().position(CITY,member);
return list.get(0);
}
@GetMapping(value = "/geohash")
public String hash(String member) {
//geohash算法生成的base32编码值
List<String> list= this.redisTemplate.opsForGeo().hash(CITY,member);
return list.get(0);
}
@GetMapping(value = "/geodist")
public Distance distance(String member1, String member2) {
Distance distance= this.redisTemplate.opsForGeo().distance(CITY,member1,member2, RedisGeoCommands.DistanceUnit.KILOMETERS);
return distance;
}
/**
* 通过经度,纬度查找附近的
* 北京王府井位置116.418017,39.914402
*/
@GetMapping(value = "/georadius")
public GeoResults radiusByxy() {
//这个坐标是北京王府井位置
Circle circle = new Circle(116.418017, 39.914402, Metrics.KILOMETERS.getMultiplier());
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults= this.redisTemplate.opsForGeo().radius(CITY,circle, args);
return geoResults;
}
/**
* 通过地方查找附近
*/
@GetMapping(value = "/georadiusByMember")
public GeoResults radiusByMember() {
String member="天安门";
//返回50条
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs.newGeoRadiusArgs().includeDistance().includeCoordinates().sortAscending().limit(50);
//半径10公里内
Distance distance=new Distance(10, Metrics.KILOMETERS);
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults= this.redisTemplate.opsForGeo().radius(CITY,member, distance,args);
return geoResults;
}
}
布隆过滤器
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。
它实际上是一个很长的二进制数组+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。
但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生

由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断某个数据是否存在
本质就是判断具体数据存不存在一个大的集合中
布隆过滤器是一种类似set的数据结构,只是统计结果不太准确
高效的插入和查询,占用空间少,返回的结果是不确定性的。
一个元素如果判断结果为存在的时候,元素不一定存在;但是判断结果为不存在的时候则一定不存在。
布隆过滤器可以添加元素,但是不能删除元素,因为删除元素会导致误判率增加。
误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判。
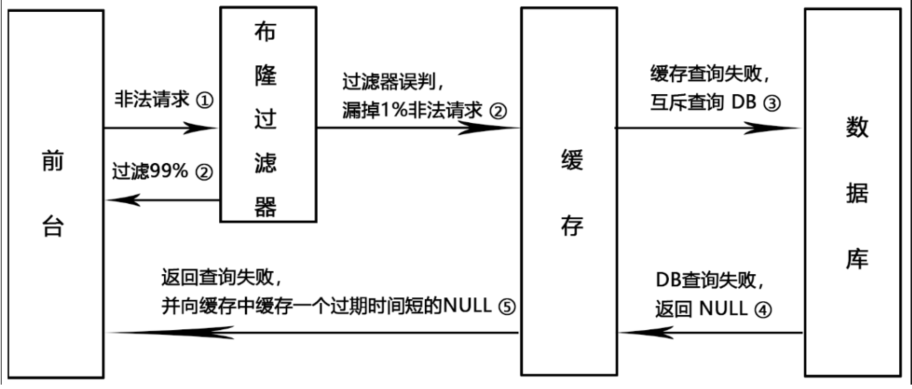
布隆过滤器可以解决缓存穿透的问题
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。
当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则穿透到Mysql数据库
黑名单校验
把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
原理
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值
如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”。
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
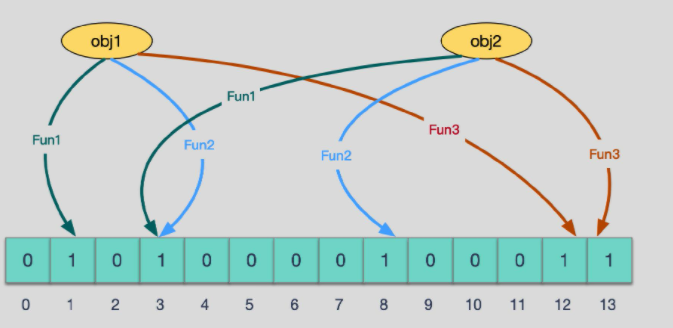
查询key时
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在;如果这几个位置全都是 1,那么说明极有可能存在;因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突
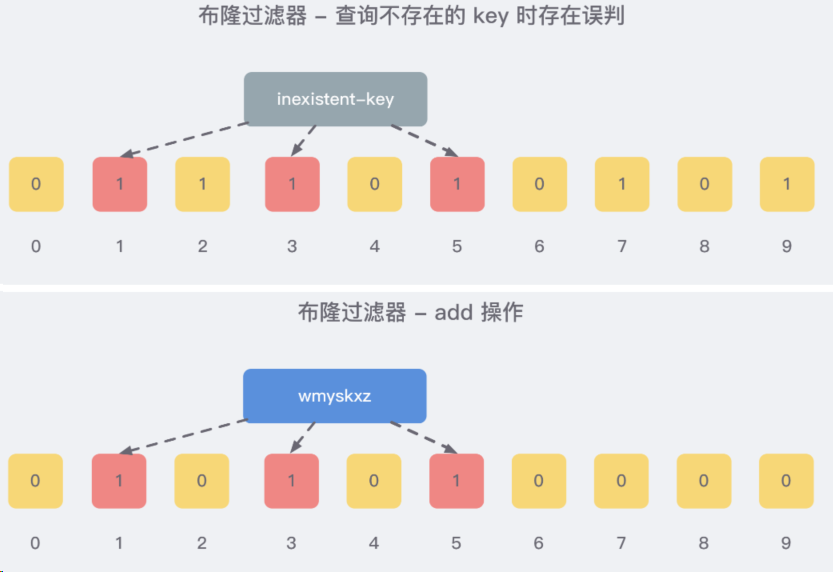
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的, 因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素
使用时最好不要让实际元素数量远大于初始化数量
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。
缓存雪崩
缓存中大量数据同时过期
redis缓存集群实现高可用,主从+哨兵
ehcache本地缓存+Hystrix或者sentinel限流降级
开启redis持久化机制aof和rdb,尽快恢复缓存集群
缓存穿透
数据既不在redis中,也不在MySQL中,查询一条不存在于两者的记录,请求最终都会打到数据库上,导致数据库崩溃,称为缓存穿透
解决方案1:空对象缓存或设置缺省值;当使用不同ID恶意攻击时,要设置缓存过期时间,否则无关紧要的key会越来越多
方案2:guava布隆过滤器解决缓存穿透
demo
public void bloomFilter()
{
// 创建布隆过滤器对象
BloomFilter filter = BloomFilter.create(Funnels.integerFunnel(), 100);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
}
取样本100W数据,查查不在100W范围内的其它10W数据是否存在
public class BloomfilterDemo
{
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)
public static double fpp = 0.03;
// 构建布隆过滤器
private static BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,fpp);
public static void main(String[] args)
{
//1 先往布隆过滤器里面插入100万的样本数据
for (int i = 0; i <= size; i++) {
bloomFilter.put(i);
}
//故意取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里
List list = new ArrayList(10 * _1W);
for (int i = size+1; i size + 100000; i++) {
if (bloomFilter.mightContain(i)) {
System.out.println(i+"\t"+"被误判了.");
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
说明
guava提供的布隆过滤器缺陷就是只能单机使用,不适用于分布式场景
方案三:Redis布隆过滤器解决缓存穿透:
白名单架构说明
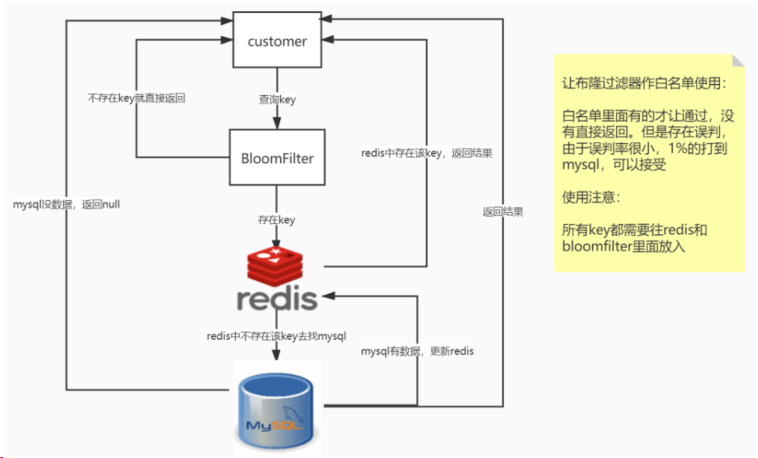
误判问题,但是概率小可以接受,不能从布隆过滤器删除
全部合法的key都需要放入过滤器+redis里面,不然数据就是返回null
public class RedissonBloomFilterDemo2 {
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少
public static double fpp = 0.03;
static RedissonClient redissonClient = null;
static RBloomFilter rBloomFilter = null;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.111.147:6379")
.setDatabase(0);
//构造redisson
redissonClient = Redisson.create(config);
//通过redisson构造rBloomFilter
rBloomFilter = redissonClient.getBloomFilter("phoneListBloomFilter",
new StringCodec());
rBloomFilter.tryInit(size, fpp);
// 1测试 布隆过滤器有+redis有
rBloomFilter.add("10086");
redissonClient.getBucket("10086", new StringCodec())
.set("chinamobile10086");
// 2测试 布隆过滤器有+redis无
//rBloomFilter.add("10087");
//3 测试 ,都没有
}
public static void main(String[] args) {
String phoneListById = getPhoneListById("10087");
System.out.println("------查询出来的结果: " + phoneListById);
//暂停几秒钟线程
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
redissonClient.shutdown();
}
private static String getPhoneListById(String IDNumber) {
String result = null;
if (IDNumber == null) {
return null;
}
//1 先去布隆过滤器里面查询
if (rBloomFilter.contains(IDNumber)) {
//2 布隆过滤器里有,再去redis里面查询
RBucket rBucket = redissonClient.getBucket(IDNumber,
new StringCodec());
result = rBucket.get();
if (result != null) {
return "i come from redis: " + result;
} else {
result = getPhoneListByMySQL(IDNumber);
if (result == null) {
return null;
}
// 重新将数据更新回redis
redissonClient.getBucket(IDNumber, new StringCodec()).set(result);
}
return "i come from mysql: " + result;
}
return result;
}
private static String getPhoneListByMySQL(String IDNumber) {
return "chinamobile" + IDNumber;
}
}
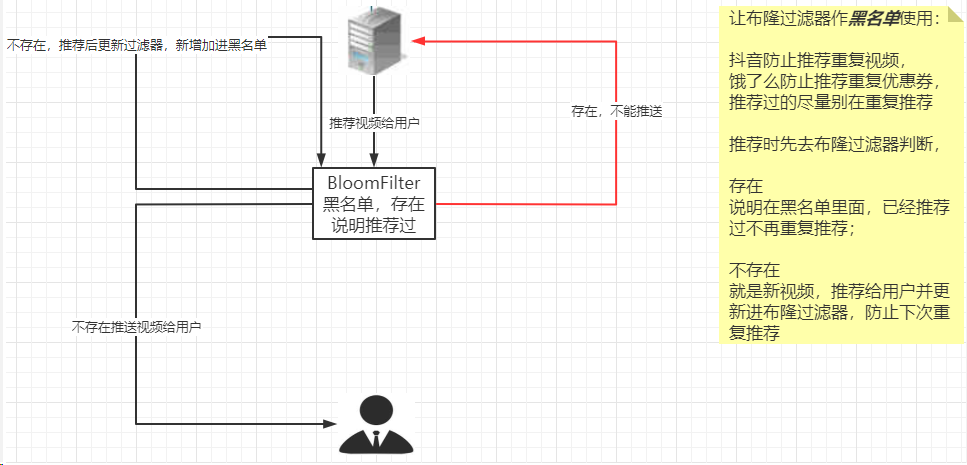
黑名单
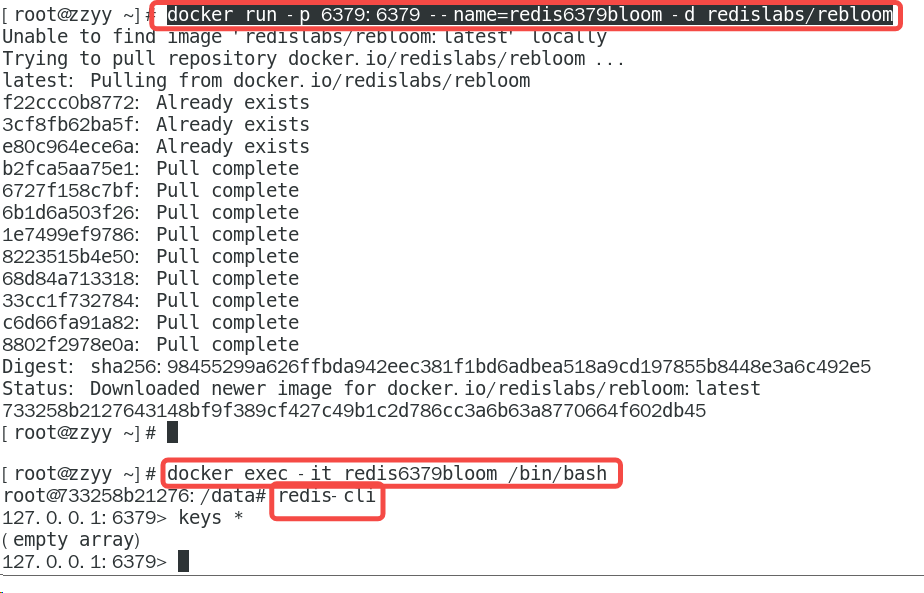
安装
Redis 在 4.0 之后有了插件功能(Module),可以使用外部的扩展功能,可以使用RedisBloom作为Redis布隆过滤器插件。
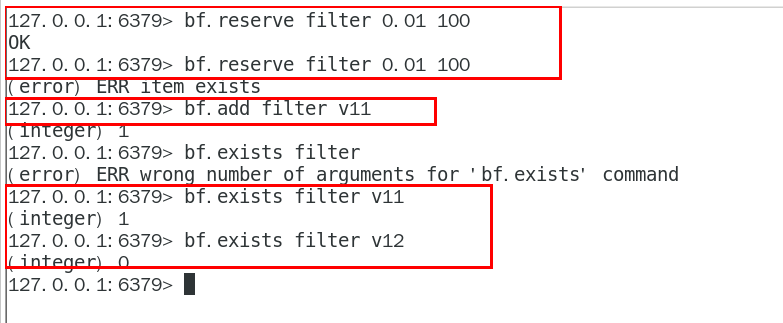
常用操作命令
缓存击穿
大量的请求同时访问一个key时,此时这个key正好失效,就会导致大量请求打到数据库上
方案一:互斥更新,随机退避,差异失效时间
方案二:对于访问频繁的热点key,可以考虑不设置过期时间
方案三:互斥独占锁防止击穿;多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
public String get(String key) {
String value = redis.get(key); //查询缓存
if (value != null) {
//直接返回
return value;
} else {
//缓存不存在则对方法加锁
//假设请求量很大,缓存过期
synchronized(TestFuture.class) {
value = redis.get(key); //再查询一次缓存
if (value != null) {
//直接返回
return value;
} else {
//缓存不存在,查询DB
value = dao.get(key);
redis.setnx(key, value, time);
return value;
}
}
}
}
淘宝聚划算功能实现分析
全天高并发,不能用DB做,只能用缓存,先把DB中参加活动的商品定时扫描到Redis中,支持分页
选用zset数据结构
redisConfig
@Configuration
public class RedisConfig
{
/**
* @param lettuceConnectionFactory
* @return
*
* redis序列化的工具配置类,下面这个请一定开启配置
* 127.0.0.1:6379> keys *
* 1) "ord:102" 序列化过
* 2) "\xac\xed\x00\x05t\x00\aord:102" 野生,没有序列化过
*/
@Bean
public RedisTemplate<String,Serializable> redisTemplate(LettuceConnectionFactory lettuceConnectionFactory)
{
RedisTemplate<String,Serializable> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(lettuceConnectionFactory);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
实体类
@Data
@ApiModel(value = "聚划算活动producet信息")
public class Product {
private Long id;
/**
* 产品名称
*/
private String name;
/**
* 产品价格
*/
private Integer price;
/**
* 产品详情
*/
private String detail;
public Product() {
}
public Product(Long id, String name, Integer price, String detail) {
this.id = id;
this.name = name;
this.price = price;
this.detail = detail;
}
}
public class Constants {
public static final String JHS_KEY="jhs";
public static final String JHS_KEY_A="jhs:a";
public static final String JHS_KEY_B="jhs:b";
}

定时器扫描
@Service
@Slf4j
public class JHSABTaskService
{
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
public void initJHSAB(){
log.info("启动AB定时器计划任务淘宝聚划算功能模拟.........."+DateUtil.now());
new Thread(() -> {
//模拟定时器,定时把数据库的特价商品,刷新到redis中
while (true){
//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
List<Product> list=this.products();
//先更新B缓存
this.redisTemplate.delete(Constants.JHS_KEY_B);
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_B,list);
this.redisTemplate.expire(Constants.JHS_KEY_B,20L,TimeUnit.DAYS);
//再更新A缓存
this.redisTemplate.delete(Constants.JHS_KEY_A);
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY_A,list);
this.redisTemplate.expire(Constants.JHS_KEY_A,15L,TimeUnit.DAYS);
//间隔一分钟 执行一遍
try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
log.info("runJhs定时刷新..............");
}
},"t1").start();
}
/**
* 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
*/
public List<Product> products() {
List<Product> list=new ArrayList<>();
for (int i = 1; i <=20; i++) {
Random rand = new Random();
int id= rand.nextInt(10000);
Product obj=new Product((long) id,"product"+i,i,"detail");
list.add(obj);
}
return list;
}
}
controller
@RestController
@Slf4j
@Api(description = "聚划算商品列表接口AB")
public class JHSABProductController
{
@Autowired
private RedisTemplate redisTemplate;
@RequestMapping(value = "/pruduct/findab",method = RequestMethod.GET)
@ApiOperation("按照分页和每页显示容量,点击查看AB")
public List<Product> findAB(int page, int size) {
List<Product> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis list数据结构的lrange命令实现分页查询
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY_A, start, end);
if (CollectionUtils.isEmpty(list)) {
log.info("=========A缓存已经失效了,记得人工修补,B缓存自动延续5天");
//用户先查询缓存A(上面的代码),如果缓存A查询不到(例如,更新缓存的时候删除了),再查询缓存B
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY_B, start, end);
}
log.info("查询结果:{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}
}