简介
- 基于Apache Lucene构建的开源搜索引擎
- 采用Java编写,提供简单易用的RESTful API
- 轻松的横向扩展,可支持PB级的结构化和非结构化数据处理
应用场景
- 海量数据分析引擎
- 站内搜索引擎
- 数据仓库
- 英国卫报-实时分析公众对文章的回应
- 维基百科、GitHub-站内实时搜索
- 百度-实时日志监控平台
- 阿里巴巴、谷歌、京东、腾讯、小米等等
用途
收集日志或交易数据,并且要分析和挖掘此数据以查找趋势,统计信息,摘要或异常。在这种情况下,您可以使用 Logstash(Elasticsearch / Logstash / Kibana堆栈的一部分)来收集,聚合和解析数据,然后让 Logstash 将这些数据提供给 Elasticsearch。数据放入 Elasticsearch 后,您可以运行搜索和聚合以挖掘您感兴趣的任何信息。
工作原理
Elasticsearch 的原始数据从哪里来?
原始数据从多个来源 ( 包括日志、系统指标和网络应用程序 ) 输入到 Elasticsearch 中。
Elasticsearch 的数据是怎么采集的?
数据采集指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。这里用到了 Logstash
怎么可视化查看想要检索的数据?
这里就要用到 Kibana 了,用户可以基于自己的数据进行搜索、查看数据视图等。
ELK
Logstash 就是 ELK 中的 L。
Logstash 是 Elastic Stack 的核心产品之一,可用来对数据进行聚合和处理,并将数据发送到 Elasticsearch。Logstash 是一个开源的服务器端数据处理管道,允许您在将数据索引到 Elasticsearch 之前同时从多个来源采集数据,并对数据进行充实和转换。
Kibana 是一款适用于 Elasticsearch 的数据可视化和管理工具,可以提供实时的直方图、线性图等。
软件安装
- 单机安装
单机安装ElasticSearch
安装前,请确保已经安装JDK1.8
安装前,请确保已经安装nodejs6.0以上
官网:https://www.elastic.co/products/elasticsearch
下载安装包:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.0.tar.gz
解压安装包:tar -vxf elasticsearch-5.6.0.tar.gz
cd elasticsearch-5.6.0.tar.gz
启动前,检查JDK环境
java -v
请确保已经安装JDK1.8
启动elasticsearch
sh ./bin/elasticsearch
当日志输出started时,表示启动成功
验证服务
127.0.0.1:9200
elasticsearch服务默认监听9200端口
访问:http://127.0.0.1:9200
如果出现版本信息,则安装成功
- 插件安装
实用插件Head安装
打开github:https://github.com/mobz/elasticsearch-head
下载插件包:https://codeload.github.com/mobz/elasticsearch-head/zip/master
unzip elasticsearch-head-master.zip
cd elasticsearch-head-master
检查Node环境
node -v
请确保已经安装nodejs6.0以上
安装插件
npm install
启动插件
npm run start
输出日志表示启动成功
Started connect web server on http://localhost:9100
访问
http://localhost:9100
ElasticSearch整合elasticsearch-head插件
cd elasticsearch-5.6.0
vim config/elasticsearch.yml
在配置文件的最后面加上
允许head插件跨域访问rest接口
http.cors.allowed: true
http.cors.allow-origin: "*"
:wq
后台启动
./bin/elasticsearch -d
再次重新启动elasticsearch-head插件
cd elasticsearch-head-master
启动插件
npm run start
访问
http://localhost:9100
- 集群安装
集群安装
1个master、2个slave
master节点配置
配置当前节点为主节点
cd elasticsearch-5.6.0
修改配置
vim config/elasticsearch.yml
在配置文件的最后面加上
# 指定集群的名字
cluster.name: myes
# 指定当前节点的名字
node.name: master
# 指定当前节点为master
node.master: true
# 指定绑定的IP
network.host: 127.0.0.1
# 使用默认端口:9200
:wq
ps -ef | grep 'pwd'
kill pid
重新启动
./bin/elasticsearch -d
检查服务是否正常启动
http://localhost:9200
slave节点配置
mkdir es_slave
cp elasticsearch-5.6.0.tar.gz es_slave/
cd es_slave
tar -vxf elasticsearch-5.6.0.tar.gz
cp -r elasticsearch-5.6.0 es_slave1
cp -r elasticsearch-5.6.0 es_slave2
修改es_slave1配置
cd es_slave1
vim config/elasticsearch.yml
在配置文件的最后面加上
# 指定集群的名字:需要和master节点一致
cluster.name: myes
# 指定当前节点的名字
node.name: slave1
# 指定绑定的IP
network.host: 127.0.0.1
# 指定当前节点绑定端口号8200
http.port: 8200
# 该配置主要是为了找到master节点
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
:wq
启动服务
./bin/elasticsearch -d
检查服务是否正常启动
http://localhost:9100
安装之前的步骤配置slave2
cd es_slave2
vim config/elasticsearch.yml
在配置文件的最后面加上
# 指定集群的名字:需要和master节点一致
cluster.name: myes
# 指定当前节点的名字
node.name: slave2
# 指定绑定的IP
network.host: 127.0.0.1
# 指定当前节点绑定端口号8000
http.port: 8000
# 该配置主要是为了找到master节点
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
:wq
启动服务
./bin/elasticsearch -d
检查服务是否正常启动
http://localhost:9100
基础概念
- 集群和节点
一个 ES Index 在集群模式下,有多个 Node (节点)组成。每个节点就是 ES 的Instance (实例)。
每个节点上会有多个 shard (分片), P1 P2 是主分片, R1 R2 是副本分片
每个分片上对应着就是一个 Lucene Index(底层索引文件)
Lucene Index 是一个统称
由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档
commit point记录了所有 segments 的信息
一个集群是由一个或多个ES组成的集合
每一个集群都有一个唯一的名字
每一个节点都是通过集群的名字来加入集群的
每一个节点都有自己的名字
节点能够存储数据,参与集群索引数据以及搜索数据的独立服务
- 基础概念
索引:含有相同属性的文档集合;Elasticsearch 会以 JSON 文档的形式存储数据。每个文档都会在一组键 ( 字段或属性的名称 ) 和它们对应的值 ( 字符串、数字、布尔值、日期、数值组、地理位置或其他类型的数据 ) 之间建立联系。
Elasticsearch 使用的是一种名为倒排索引的数据结构,这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。
在索引过程中,Elasticsearch 会存储文档并构建倒排索引,这样用户便可以近实时地对文档数据进行搜索。索引过程是在索引 API 中启动的,通过此 API 您既可向特定索引中添加 JSON 文档,也可更改特定索引中的 JSON 文档。
类型:索引可以定义一个或多个类型,文档必须属于一个类型
(通常会定义有相同字段的文档作为一个类型)
文档:文档是可以被索引的基本数据单位
索引相当于SQL里的DataBase,也就是数据库
类型相当于SQL里的Table,也就是表
文档相当于SQL里的一行记录,也就是一行数据
假设有一个信息查询系统,使用ES做存储。那么里面的数据就可以分为各种各样的索引,比如:汽车索引、图书索引、家具索引等等。图书索引又可以细分为各种类型,比如:科普类、小说类、技术类等等。具体到每一本书籍,就是文档,就是整个图书里面最小的存储单位。
- 索引高级概念
分片:每个索引都有多个分片,每个分片是一个Lucene索引
备份:拷贝一份分片就完成了分片的备份
ES默认在创建索引时,会创建5个分片、1个备份
分片的数量只能在创建索引时设置,而不能在后期进行修改
备份是可以动态修改的
倒排索引
假如数据库有如下电影记录:
1-大话西游
2-大话西游外传
3-解析大话西游
4-西游降魔外传
5-梦幻西游独家解析
分词:将整句分拆为单词
| 序号 | 保存到 ES 的词 | 对应的电影记录序号 |
|---|---|---|
| A | 西游 | 1,2, 3,4, 5 |
| B | 大话 | 1,2, 3 |
| C | 外传 | 2,4, 5 |
| D | 解析 | 3,5 |
| E | 降魔 | 4 |
| F | 梦幻 | 5 |
| G | 独家 | 5 |
检索:独家大话西游
将 独家大话西游 解析拆分成 独家、大话、西游
ES 中 A、B、G 记录 都有这三个词的其中一种, 所以 1,2, 3,4, 5 号记录都有相关的词被命中。
1 号记录命中 2 次, A、B 中都有 ( 命中 2 次 ) ,而且 1 号记录有 2 个词,相关性得分:2 次/2 个词=1
2 号记录命中 2 个词 A、B 中的都有 ( 命中 2 次 ) ,而且 2 号记录有 2 个词,相关性得分:2 次/3 个词= 0.67
3 号记录命中 2 个词 A、B 中的都有 ( 命中 2 次 ) ,而且 3 号记录有 2 个词,相关性得分:2 次/3 个词= 0.67
4 号记录命中 2 个词 A 中有 ( 命中 1 次 ) ,而且 4 号记录有 3 个词,相关性得分:1 次/3 个词= 0.33
5 号记录命中 2 个词 A 中有 ( 命中 2 次 ) ,而且 4 号记录有 4 个词,相关性得分:2 次/4 个词= 0.5
所以检索出来的记录顺序如下:
1-大话西游 ( 想关性得分:1 )
2-大话西游外传 ( 想关性得分:0.67 )
3-解析大话西游 ( 想关性得分:0.67 )
5-梦幻西游独家解析 ( 想关性得分:0.5 )
4-西游降魔 ( 想关性得分:0.33 )
Lucene索引结构
索引结构中的文件
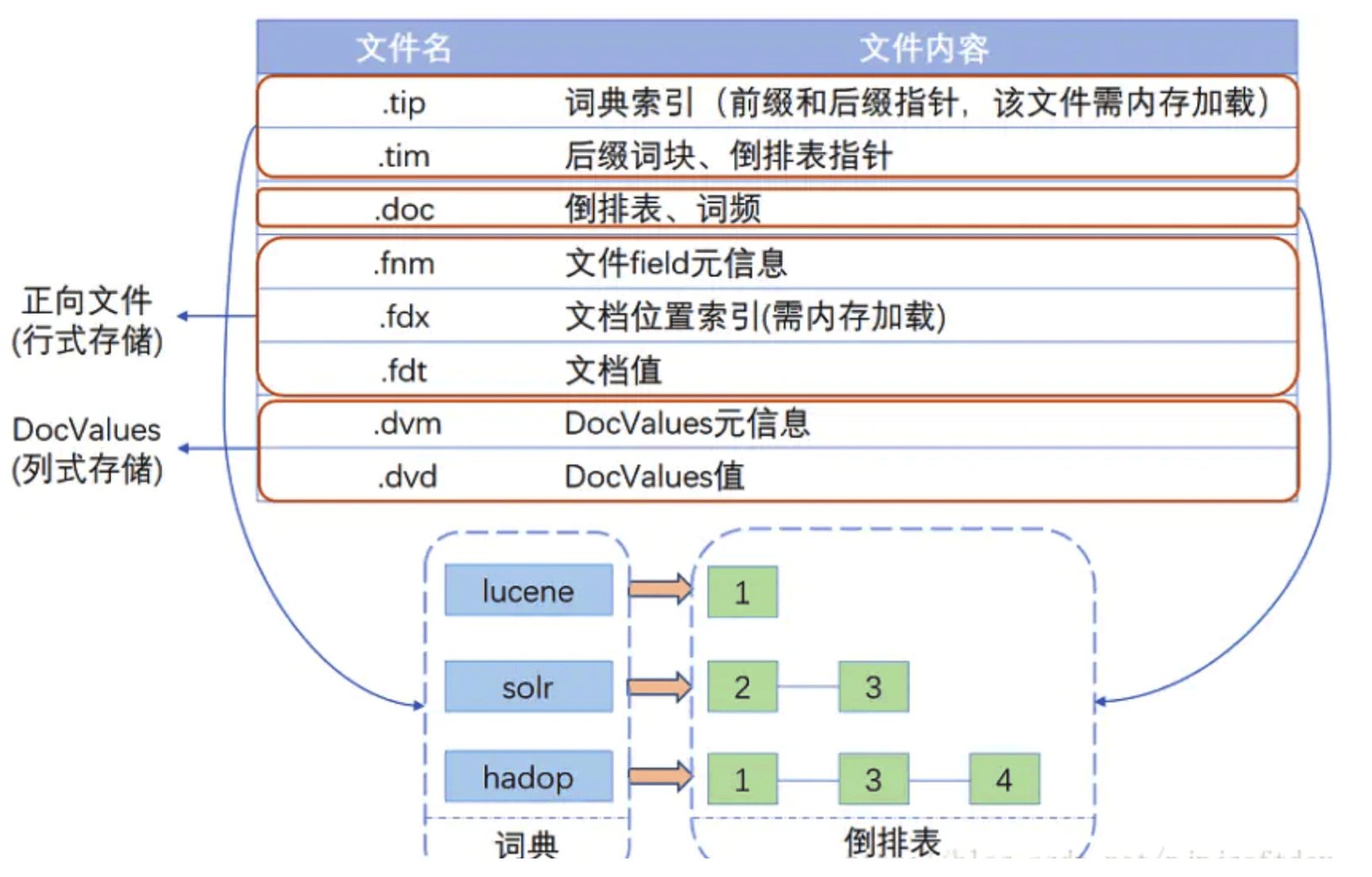
文件之间的关系如下图
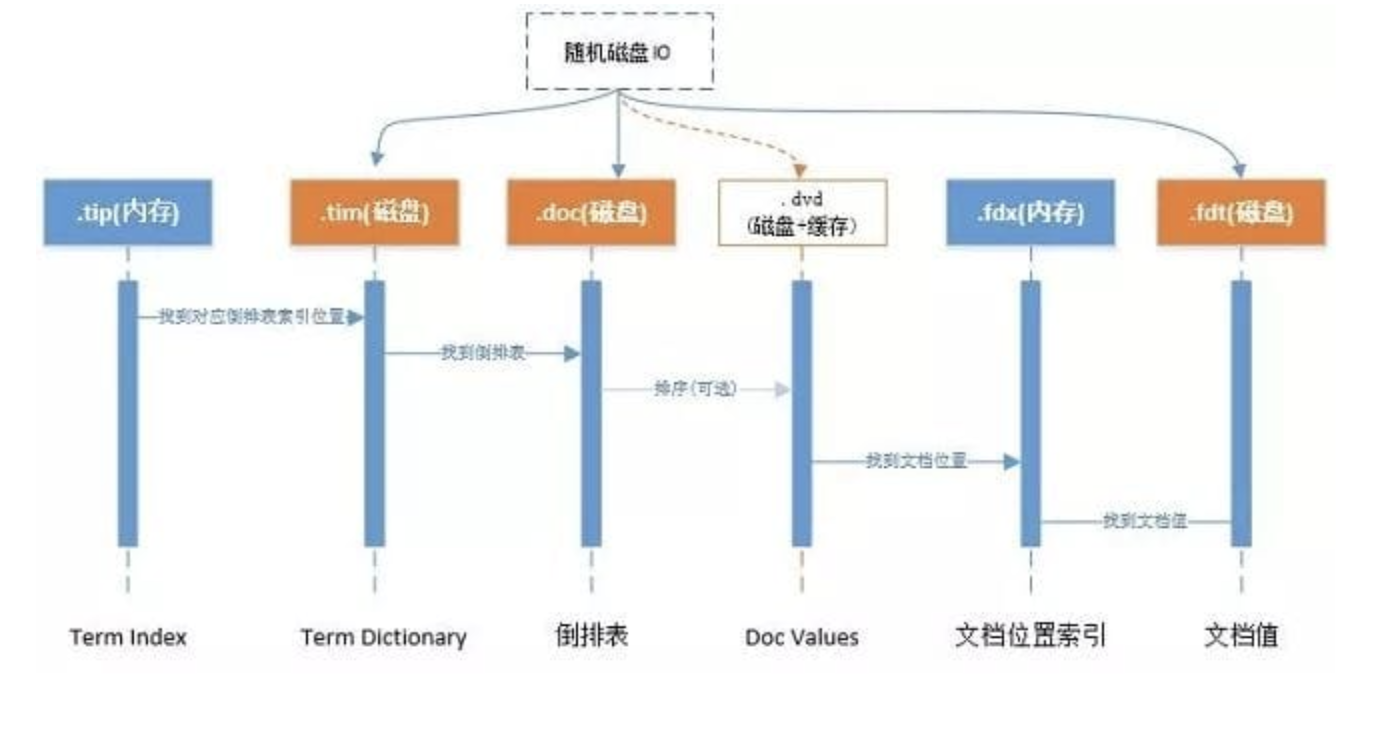
Lucene处理流程
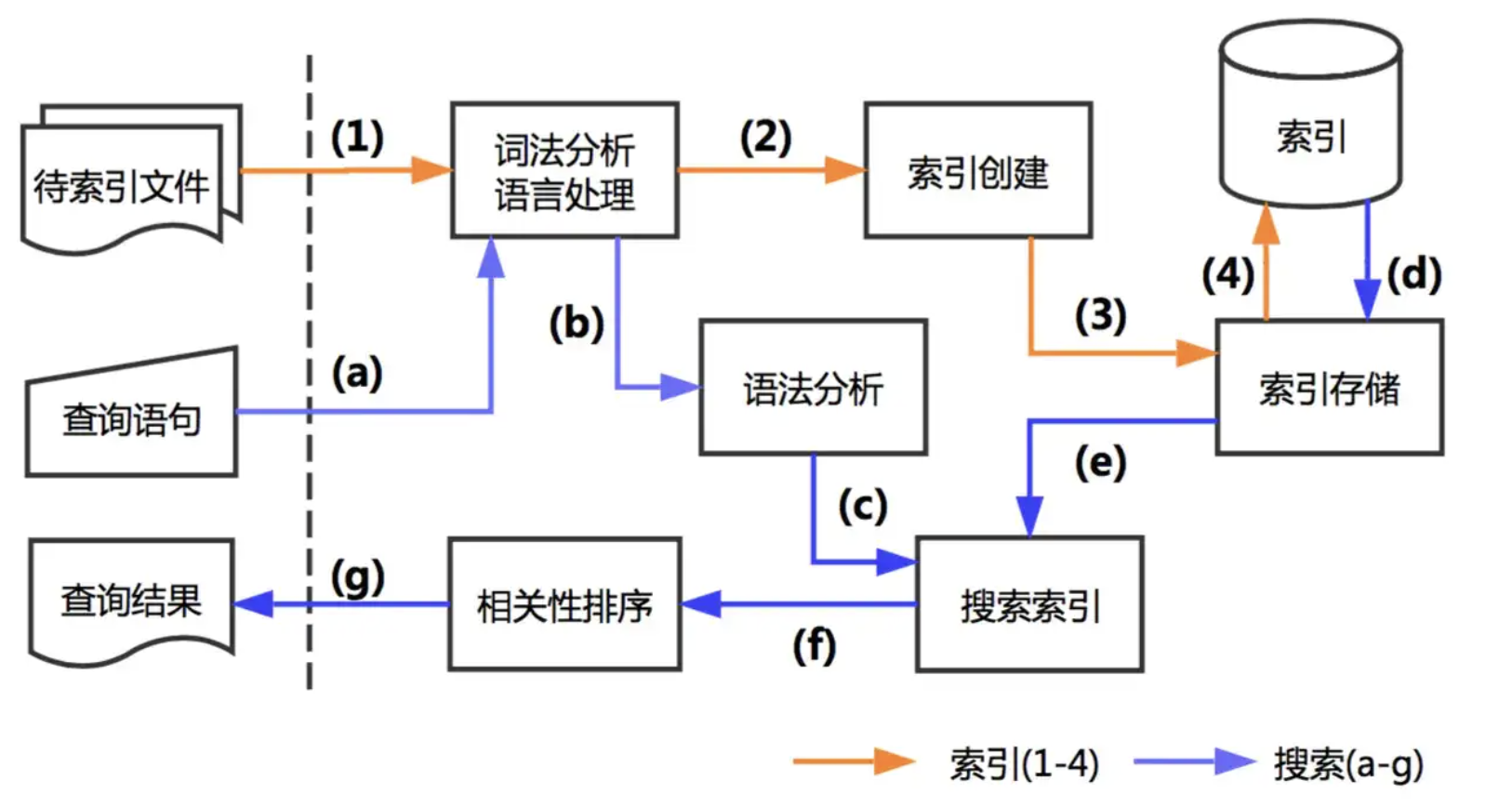
创建索引的过程:
准备待索引的原文档,数据来源可能是文件、数据库或网络
对文档的内容进行分词组件处理,形成一系列的Term
索引组件对文档和Term处理,形成字典和倒排表
搜索索引的过程:
对查询语句进行分词处理,形成一系列Term
根据倒排索引表查找出包含Term的文档,并进行合并形成符合结果的文档集
比对查询语句与各个文档相关性得分,并按照得分高低返回
ES分析器
分析的过程包括:
首先,将一块文本分成适合于倒排索引的独立的 词条
之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器 实际上是将三个功能封装到了一个包里:
字符过滤器 首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML,或者将 & 转化成 and。
分词器 其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条
Token 过滤器 最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化 Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump 和 leap 这种同义词)。
标准分析器:
标准分析器是Elasticsearch默认使用的分析器。它是分析各种语言文本最常用的选择。它根据 Unicode 联盟 定义的 单词边界 划分文本。删除绝大部分标点。最后,将词条小写。
"Set the shape to semi-transparent by calling set_trans(5)"
分析后
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
简单分析器
简单分析器在任何不是字母的地方分隔文本,将词条小写
set, the, shape, to, semi, transparent, by, calling, set, trans
空格分析器
空格分析器在空格的地方划分文本。
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
语言分析器
特定语言分析器可用于 很多语言。它们可以考虑指定语言的特点。例如, 英语 分析器附带了一组英语无用词(常用单词,例如 and 或者 the ,它们对相关性没有多少影响),它们会被删除
索引文档流程
新建单个文档所需要的步骤顺序:
客户端向 Node 1 发送新建、索引或者删除请求。
节点使用文档的 _id 确定文档属于分片 0 。发现分片0分配在Node3上,请求会被转发到 Node 3。
Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功
新建多个文档所需要的步骤顺序:
客户端向 Node 1 发送 bulk 请求。
Node 1 为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主机。
主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端
索引流程:
协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片
shard = hash(document_id) % (num_of_primary_shards)
当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh
在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush
在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。 flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时
数据持久化过程
数据持久化过程:write -> refresh -> flush -> merge
write 过程
一个新文档过来,会存储在 in-memory buffer 内存缓存区中,顺便会记录 Translog(Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录);这时候数据还没到 segment ,是搜不到这个新文档的。数据只有被 refresh 后,才可以被搜索到
refresh 过程
refresh 默认 1 秒钟。ES 是支持修改这个值的,通过 index.refresh_interval 设置 refresh (冲刷)间隔时间。
in-memory buffer 中的文档写入到新的 segment 中,但 segment 是存储在文件系统的缓存中。此时文档可以被搜索到
最后清空 in-memory buffer。注意: Translog 没有被清空,为了将 segment 数据写到磁盘
文档经过 refresh 后, segment 暂时写到文件系统缓存,这样避免了性能 IO 操作,又可以使文档搜索到。refresh 默认 1 秒执行一次,性能损耗太大。一般建议稍微延长这个 refresh 时间间隔,比如 5 s。因此,ES 其实就是准实时,达不到真正的实时
flush 过程
每隔一段时间—例如 translog 变得越来越大—索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行
上个过程中 segment 在文件系统缓存中,会有意外故障文档丢失。那么,为了保证文档不会丢失,需要将文档写入磁盘。
文档从文件缓存写入磁盘的过程就是 flush。写入磁盘后,清空 translog。
1:所有在内存缓冲区的文档都被写入一个新的段
2:缓冲区被清空
3:一个Commit Point被写入硬盘
4:文件系统缓存通过 fsync 被刷新(flush)
5:老的 translog 被删除
merge 过程
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢
Elasticsearch通过在后台进行Merge Segment来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段
当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索
一旦合并结束,老的段被删除
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行
1:新的段被刷新(flush)到了磁盘。 写入一个包含新段且排除旧的和较小的段的新提交点
2:新的段被打开用来搜索
3:老的段被删除
索引结构mapping
如果我们需要对这个建立索引的过程做更多的控制:比如想要确保这个索引有数量适中的主分片,并且在我们索引任何数据之前,分析器和映射已经被建立好。那么就会引入两点:第一个禁止自动创建索引,第二个是手动创建索引。
可以通过在 config/elasticsearch.yml 的每个节点下添加下面的配置
action.auto_create_index: false
索引格式
使用put请求创建一个索引
PUT /my_index
{
"settings": { ... any settings ... },
"mappings": {
"properties": { ... any properties ... }
}
}
settings: 用来设置分片,副本等配置信息
mappings: 字段映射,类型等
properties: 属性
对user对象创建一个索引test-index-users,并指定一些参数
创建索引
PUT /test-index-users
{
"settings": {
"number_of_shards": 1, //分片数为1个
"number_of_replicas": 1 //副本数为1个
},
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"remarks": {
"type": "text"
}
}
}
}
返回结果:
{
"acknowledged":true,
"shards_acknowledged":true,
"index":"test-index-users"
}
查看索引结构
GET /test-index-users/_mapping
返回结果:
{
"test-index-users": {
"mappings": {
"properties": {
"age": {
"type": "long"
},
"name": {
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
},
"type": "text"
},
"remarks": {
"type": "text"
}
}
}
}
}
查看索引设置
GET /test-index-users/_settings
返回结果:
{
"test-index-users": {
"settings": {
"index": {
"apack": {
"metadata": {
"app_id": "prod-es-4fs",
"index_max_storage": "60.0",
"shard_max_storage": "20.0"
}
},
"blocks": {
"read_only_allow_delete": "false"
},
"creation_date": "1740131244421",
"indexing": {
"slowlog": {
"source": "1000",
"threshold": {
"index": {
"debug": "50ms",
"info": "100ms",
"trace": "20ms",
"warn": "200ms"
}
}
}
},
"mapping": {
"field_name_length": {
"limit": "100"
},
"nested_objects": {
"limit": "100"
}
},
"max_prefix_length": "50",
"max_refresh_listeners": "20",
"max_regex_length": "50",
"max_terms_count": "1024",
"max_wildcard_length": "50",
"number_of_replicas": "1",
"number_of_shards": "3",
"provided_name": "test-index-users",
"refresh_interval": "1s",
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"search": {
"slowlog": {
"threshold": {
"fetch": {
"debug": "80ms",
"info": "100ms",
"trace": "50ms",
"warn": "200ms"
},
"query": {
"debug": "100ms",
"info": "200ms",
"trace": "50ms",
"warn": "500ms"
}
}
}
},
"unassigned": {
"node_left": {
"delayed_timeout": "5m"
}
},
"uuid": "a2vXgFIFR1Ouwi5hP-XdAA",
"version": {
"created": "7100099"
}
}
}
}
}
插入一组测试数据
POST /test-index-users/_doc
{
"name":"myname",
"age":18,
"remarks":"hello world"
}
返回结果:
{
"_index": "test-index-users",
"_type": "_doc",
"_id": "B3noJ5UBCmMdHuxJFhcB",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查看数据
GET /test-index-users/_search
{
"query":{
"match_all":{}
}
}
返回结果
{
"_shards": {
"failed": 0,
"skipped": 0,
"successful": 3,
"total": 3
},
"hits": {
"hits": [
{
"_id": "B3noJ5UBCmMdHuxJFhcB",
"_index": "test-index-users",
"_score": 1,
"_source": {
"age": 18,
"name": "myname",
"remarks": "hello world"
},
"_type": "_doc"
}
],
"max_score": 1,
"total": {
"relation": "eq",
"value": 1
}
},
"timed_out": false,
"took": 4
}
修改索引配置
PUT /test-index-users/_settings
{
"settings": {
"number_of_replicas": 0
}
}
关闭索引,一旦索引被关闭,那么这个索引只能显示元数据信息,不能够进行读写操作
POST /test-index-users/_close
打开索引
POST /test-index-users/_open
删除索引
DELETE /test-index-users
索引模板
索引模板是一种告诉Elasticsearch在创建索引时如何配置索引的方法
在创建索引之前可以先配置模板,这样在创建索引(手动创建索引或通过对文档建立索引)时,模板设置将用作创建索引的基础
模板有两种类型:索引模板和组件模板
组件模板是可重用的构建块,用于配置映射,设置和别名;它们不会直接应用于一组索引
索引模板可以包含组件模板的集合,也可以直接指定设置,映射和别名
索引模板的优先级:
可组合模板优先于旧模板。如果没有可组合模板匹配给定索引,则旧版模板可能仍匹配并被应用。
如果使用显式设置创建索引并且该索引也与索引模板匹配,则创建索引请求中的设置将优先于索引模板及其组件模板中指定的设置
如果新数据流或索引与多个索引模板匹配,则使用优先级最高的索引模板
基本用法
bool布尔查询
通过布尔逻辑将较小的查询组合成较大的查询
Bool查询语法有以下特点
- 子查询可以任意顺序出现
- 可以嵌套多个查询,包括bool查询
- 如果bool查询中没有must条件,should中必须至少满足一条才会返回结果。
bool查询包含四种操作符,分别是must,should,must_not,filter。他们均是一种数组,数组里面是对应的判断条件。
must: 必须匹配。贡献算分must_not:过滤子句,必须不能匹配,但不贡献算分should: 选择性匹配,至少满足一条。贡献算分filter: 过滤子句,必须匹配,但不贡献算分
实例1
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
在filter元素下指定的查询对评分没有影响 , 评分返回为0。分数仅受已指定查询的影响
实例2
GET _search
{
"query": {
"bool": {
"filter": {
"term": {
"status": "active"
}
}
}
}
}
查询为所有文档分配0分,因为没有指定评分查询
实例3
GET _search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"status": "active"
}
}
}
}
}
此bool查询具有match_all查询,该查询为所有文档指定1.0分
实例4
GET /_search
{
"query": {
"bool": {
"should": [
{ "match": { "name.first": { "query": "shay", "_name": "first" } } },
{ "match": { "name.last": { "query": "banon", "_name": "last" } } }
],
"filter": {
"terms": {
"name.last": [ "banon", "kimchy" ],
"_name": "test"
}
}
}
}
}
每个query条件都可以有一个_name属性,用来追踪搜索出的数据到底match了哪个条件
boosting提高查询
不同于bool查询,bool查询中只要一个子查询条件不匹配那么搜索的数据就不会出现。而boosting query则是降低显示的权重/优先级(即score)。
比如搜索逻辑是 name = ‘apple’ and type =’fruit’,对于只满足部分条件的数据,不是不显示,而是降低显示的优先级(即score)
实例
创建数据
POST /test-dsl-boosting/_bulk
{ "index": { "_id": 1 }}
{ "content":"Apple Mac" }
{ "index": { "_id": 2 }}
{ "content":"Apple Fruit" }
{ "index": { "_id": 3 }}
{ "content":"Apple employee like Apple Pie and Apple Juice" }
查询数据
GET /test-dsl-boosting/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"content": "apple"
}
},
"negative": {
"term": {
"content": "pie"
}
},
"negative_boost": 0.5
}
}
}
查询结果对匹配pie的做降级显示处理
constant_score固定分数查询
查询某个条件时,固定的返回指定的score;显然当不需要计算score时,只需要filter条件即可,因为filter context忽略score。
实例
创建数据
POST /test-dsl-constant/_bulk
{ "index": { "_id": 1 }}
{ "content":"Apple Mac" }
{ "index": { "_id": 2 }}
{ "content":"Apple Fruit" }
查询数据
GET /test-dsl-constant/_search
{
"query": {
"constant_score": {
"filter": {
"term": { "content": "apple" }
},
"boost": 1.2
}
}
}
查询到的每条数据的score都是1.2
dis_max最佳匹配查询
分离最大化查询(Disjunction Max Query)指的是: 将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回
实例
创建数据
POST /test-dsl-dis-max/_bulk
{ "index": { "_id": 1 }}
{"title": "Quick brown rabbits","body": "Brown rabbits are commonly seen."}
{ "index": { "_id": 2 }}
{"title": "Keeping pets healthy","body": "My quick brown fox eats rabbits on a regular basis."}
用户输入词组 “Brown fox” 然后点击搜索按钮。事先,我们并不知道用户的搜索项是会在 title 还是在 body 字段中被找到,但是,用户很有可能是想搜索相关的词组。用肉眼判断,文档 2 的匹配度更高,因为它同时包括要查找的两个词
GET /test-dsl-dis-max/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
根据分数计算,查询结果中文档1在前,文档2在后
使用 dis_max 即分离 最大化查询(Disjunction Max Query) 。分离(Disjunction)的意思是 或(or) ,这与可以把结合(conjunction)理解成 与(and) 相对应。分离最大化查询(Disjunction Max Query)指的是: 将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回
GET /test-dsl-dis-max/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
],
"tie_breaker": 0
}
}
}
分数 = 第一个匹配条件分数 + tie_breaker * 第二个匹配的条件的分数
这样你就能理解通过dis_max将doc 2 置前了, 当然这里如果缺省tie_breaker字段的话默认就是0,你还可以设置它的比例(在0到1之间)来控制排名。(显然值为1时和should查询是一致的)
function_score函数查询
script_score 使用自定义的脚本来完全控制分值计算逻辑。如果你需要以上预定义函数之外的功能,可以根据需要通过脚本进行实现
weight 对每份文档适用一个简单的提升,且该提升不会被归约:当weight为2时,结果为2 * _score
random_score 使用一致性随机分值计算来对每个用户采用不同的结果排序方式,对相同用户仍然使用相同的排序方式
field_value_factor 使用文档中某个字段的值来改变_score,比如将受欢迎程度或者投票数量考虑在内
实例
GET /_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"functions": [
{
"filter": { "match": { "test": "bar" } },
"random_score": {},
"weight": 23
},
{
"filter": { "match": { "test": "cat" } },
"weight": 42
}
],
"max_boost": 42,
"score_mode": "max",
"boost_mode": "multiply",
"min_score": 42
}
}
}
GET /_search
{
"query": {
"function_score": {
"query": {
"match": { "message": "elasticsearch" }
},
"script_score": {
"script": {
"source": "Math.log(2 + doc['my-int'].value)"
}
}
}
}
}
match全文索引
指定字段查询
POST /test-dsl-match/_bulk
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" }
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps over the quick dog" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox brown dog" }
GET /test-dsl-match/_search
{
"query": {
"match": {
"title": "QUICK!"
}
}
}
执行上面这个 match 查询的步骤是:
检查字段类型:标题 title 字段是一个 string 类型( analyzed )已分析的全文字段,这意味着查询字符串本身也应该被分析。
分析查询字符串:将查询的字符串 QUICK! 传入标准分析器中,输出的结果是单个项 quick 。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询。
查找匹配文档:用 term 查询在倒排索引中查找 quick 然后获取一组包含该项的文档,本例的结果是文档:1、2 和 3 。
为每个文档评分:用 term 查询计算每个文档相关度评分 _score ,这是种将词频(term frequency,即词 quick 在相关文档的 title 字段中出现的频率)和反向文档频率(inverse document frequency,即词 quick 在所有文档的 title 字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式。
match多个词
GET /test-dsl-match/_search
{
"query": {
"match": {
"title": "BROWN DOG"
}
}
}
因为 match 查询必须查找两个词( ["brown","dog"] ),它在内部实际上先执行两次 term 查询,然后将两次查询的结果合并作为最终结果输出。为了做到这点,它将两个 term 查询包入一个 bool 查询中
所以上述查询的结果,和如下语句查询结果是等同的
GET /test-dsl-match/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": "brown"
}
},
{
"term": {
"title": "dog"
}
}
]
}
}
}
上面等同于should(任意一个满足),是因为 match还有一个operator参数,默认是or, 所以对应的是should。
所以上述查询也等同于
GET /test-dsl-match/_search
{
"query": {
"match": {
"title": {
"query": "BROWN DOG",
"operator": "or"
}
}
}
}
如果是需要and操作呢,即同时满足
GET /test-dsl-match/_search
{
"query": {
"match": {
"title": {
"query": "BROWN DOG",
"operator": "and"
}
}
}
}
他就等同于bool的must
GET /test-dsl-match/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": "brown"
}
},
{
"term": {
"title": "dog"
}
}
]
}
}
}
如果用户给定 3 个查询词,想查找至少包含其中 2 个的文档,该如何处理?将 operator 操作符参数设置成 and 或者 or 都是不合适的。
match 查询支持 minimum_should_match 最小匹配参数,这让我们可以指定必须匹配的词项数用来表示一个文档是否相关。我们可以将其设置为某个具体数字,更常用的做法是将其设置为一个百分数,因为我们无法控制用户搜索时输入的单词数量
GET /test-dsl-match/_search
{
"query": {
"match": {
"title": {
"query":"quick brown dog",
"minimum_should_match": "75%"
}
}
}
}
以上查询也等同于
GET /test-dsl-match/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "quick" }},
{ "match": { "title": "brown" }},
{ "match": { "title": "dog" }}
],
"minimum_should_match": 2
}
}
}
当给定百分比的时候, minimum_should_match 会做合适的事情:在之前三词项的示例中, 75% 会自动被截断成 66.6% ,即三个里面两个词。无论这个值设置成什么,至少包含一个词项的文档才会被认为是匹配的
match_pharse查询
match本质上是对term组合,match_phrase本质是连续的term的查询
GET /test-dsl-match/_search
{
"query": {
"match_phrase": {
"title": {
"query": "quick brown f"
}
}
}
}
f并不是一个分词,不满足term查询,所以最终查不出任何内容了
match_pharse_prefix:可以查最后一个词项是前缀的方法
GET /test-dsl-match/_search
{
"query": {
"match_phrase_prefix": {
"title": {
"query": "quick brown f"
}
}
}
}
这个查询就有结果了
prefix的意思不是整个text的开始匹配,而是最后一个词项满足term的prefix查询而已
match_bool_prefix:查询中的分词是无序的
GET /test-dsl-match/_search
{
"query": {
"match_bool_prefix": {
"title": {
"query": "quick brown f"
}
}
}
}
结果是3,2,4
本质上可以转换为
GET /test-dsl-match/_search
{
"query": {
"bool" : {
"should": [
{ "term": { "title": "quick" }},
{ "term": { "title": "brown" }},
{ "prefix": { "title": "f"}}
]
}
}
}
multi_match:一次对多字段查询
{
"query": {
"multi_match" : {
"query": "Will Smith",
"fields": [ "title", "*_name" ]
}
}
}
同时查询title字段和以_name结尾的字段
query_string自定义组合查询
此查询使用语法根据运算符(例如AND或)来解析和拆分提供的查询字符串NOT。然后查询在返回匹配的文档之前独立分析每个拆分的文本。可以使用该query_string查询创建一个复杂的搜索,其中包括通配符,跨多个字段的搜索等等。尽管用途广泛,但查询是严格的,如果查询字符串包含任何无效语法,则返回错误。
GET /test-dsl-match/_search
{
"query": {
"query_string": {
"query": "(lazy dog) OR (brown dog)",
"default_field": "title"
}
}
}
本质上查询这四个分词(term)or的结果而已,查询结果是4,3,1
simple_query_string:查询不会针对无效语法返回错误。而是,它将忽略查询字符串的任何无效部分。
GET /test-dsl-match/_search
{
"query": {
"simple_query_string" : {
"query": "\"over the\" + (lazy | quick) + dog",
"fields": ["title"],
"default_operator": "and"
}
}
}
结果是2,3
Intervals规则顺序匹配
Intervals是时间间隔的意思,本质上将多个规则按照顺序匹配
GET /test-dsl-match/_search
{
"query": {
"intervals" : {
"title" : {
"all_of" : {
"ordered" : true,
"intervals" : [
{
"match" : {
"query" : "quick",
"max_gaps" : 0,
"ordered" : true
}
},
{
"any_of" : {
"intervals" : [
{ "match" : { "query" : "jump over" } },
{ "match" : { "query" : "quick dog" } }
]
}
}
]
}
}
}
}
}
term词项查询
准备测试数据
PUT /test-dsl-term-level
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"programming_languages": {
"type": "keyword"
},
"required_matches": {
"type": "long"
}
}
}
}
POST /test-dsl-term-level/_bulk
{ "index": { "_id": 1 }}
{"name": "Jane Smith", "programming_languages": [ "c++", "java" ], "required_matches": 2}
{ "index": { "_id": 2 }}
{"name": "Jason Response", "programming_languages": [ "java", "php" ], "required_matches": 2}
{ "index": { "_id": 3 }}
{"name": "Dave Pdai", "programming_languages": [ "java", "c++", "php" ], "required_matches": 3, "remarks": "hello world"}
最常见的根据分词查询
GET /test-dsl-term-level/_search
{
"query": {
"term": {
"programming_languages": "php"
}
}
}
查询结果是2,3
terms:根据多个分词匹配,它们是or的关系
GET /test-dsl-term-level/_search
{
"query": {
"terms": {
"programming_languages": ["php","c++"]
}
}
}
查询结果是1,2,3
Term_set:根据某个数字字段分词匹配,初衷是用文档中的数字字段动态匹配查询满足term的个数
GET /test-dsl-term-level/_search
{
"query": {
"terms_set": {
"programming_languages": {
"terms": [ "java", "php" ],
"minimum_should_match_field": "required_matches"
}
}
}
}
查询结果是2
exists字段是否存在
由于多种原因,文档字段的索引值可能不存在:
源JSON中的字段是null或[]
该字段已”index” : false在映射中设置
字段值的长度超出ignore_above了映射中的设置
字段值格式错误,并且ignore_malformed已在映射中定义
GET /test-dsl-term-level/_search
{
"query": {
"exists": {
"field": "remarks"
}
}
}
//查询存在remarks字段的文档,结果是3
ids根据id查询
ids 即对id查找
GET /test-dsl-term-level/_search
{
"query": {
"ids": {
"values": [3, 1]
}
}
}
查询结果是1,3;查询和id顺序无关
prefix前缀查询
通过前缀查找某个字段
GET /test-dsl-term-level/_search
{
"query": {
"prefix": {
"name": {
"value": "Jan"
}
}
}
}
查询结果是1
wildcard通配符
支持各种通配符查询
GET /test-dsl-term-level/_search
{
"query": {
"wildcard": {
"name": {
"value": "D*ai",
"boost": 1.0,
"rewrite": "constant_score"
}
}
}
}
查询结果为3,name="Dave Pdai"
range范围查询
指定范围,常常被用在数字或者日期范围的查询
GET /test-dsl-term-level/_search
{
"query": {
"range": {
"required_matches": {
"gte": 3,
"lte": 4
}
}
}
}
查询结果为文档3
regexp正则查询
通过正则表达式查询
GET /test-dsl-term-level/_search
{
"query": {
"regexp": {
"name": {
"value": "Ja.*",
"case_insensitive": true
}
}
}
}
查询结果为文档1,2
fuzzy模糊匹配
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
更改字符(box→ fox)
删除字符(black→ lack)
插入字符(sic→ sick)
转置两个相邻字符(act→ cat)
GET /test-dsl-term-level/_search
{
"query": {
"fuzzy": {
"remarks": {
"value": "hell"
}
}
}
}
查询结果为文档3
聚合查询
ElasticSearch提供了三种聚合方式: 桶聚合(Bucket Aggregation),指标聚合(Metric Aggregation) 和 **管道聚合(Pipline Aggregation)
新建测试数据
关于汽车交易的信息:车型、颜色、制造商、售价、何时被出售等。
POST /test-agg-cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
bucket桶聚合
ElasticSearch中桶在概念上类似于 SQL 的分组(GROUP BY),而指标则类似于 COUNT() 、 SUM() 、 MAX() 等统计方法。
桶(Buckets) 满足特定条件的文档的集合
哪个颜色的汽车销量最好,用聚合可以轻易得到结果,用 terms 桶操作
GET /test-agg-cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color.keyword"
}
}
}
}
聚合操作被置于顶层参数 aggs 之下(如果你愿意,完整形式 aggregations 同样有效)。
可以为聚合指定一个我们想要名称,本例中是: popular_colors 。
定义单个桶的类型 terms 。
因为我们设置了 size 参数,所以不会有 hits 搜索结果返回。
popular_colors 聚合是作为 aggregations 字段的一部分被返回的。
每个桶的 key 都与 color 字段里找到的唯一词对应。它总会包含 doc_count 字段,告诉我们包含该词项的文档数量。
每个桶的数量代表该颜色的文档数量。
多个聚合
同时计算两种桶的结果:对color和对make。
GET /test-agg-cars/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color.keyword"
}
},
"make_by" : {
"terms" : {
"field" : "make.keyword"
}
}
}
}
聚合嵌套
新的聚合层让我们可以将 avg 度量嵌套置于 terms 桶内。实际上,这就为每个颜色生成了平均价格
GET /test-agg-cars/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color.keyword"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
我们需要给度量起一个名字( avg_price )这样可以稍后根据名字获取它的值。最后,我们指定度量本身( avg )以及我们想要计算平均值的字段( price )
动态脚本的聚合
ElasticSearch还支持一些基于脚本(生成运行时的字段)的复杂的动态聚合
GET /test-agg-cars/_search
{
"runtime_mappings": {
"make.length": {
"type": "long",
"script": "emit(doc['make.keyword'].value.length())"
}
},
"size" : 0,
"aggs": {
"make_length": {
"histogram": {
"interval": 1,
"field": "make.length"
}
}
}
}
Fileter前置条件过滤
在当前文档集上下文中定义与指定过滤器(Filter)匹配的所有文档的单个存储桶。通常,这将用于将当前聚合上下文缩小到一组特定的文档。
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"make_by": {
"filter": { "term": { "type": "honda" } },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}
查询制造商为honda的均价
filters对filter进行分组聚合
设计一个新的例子, 日志系统中,每条日志都是在文本中,包含warning/info等信息。
PUT /test-agg-logs/_bulk
{ "index" : { "_id" : 1 } }
{ "body" : "warning: page could not be rendered" }
{ "index" : { "_id" : 2 } }
{ "body" : "authentication error" }
{ "index" : { "_id" : 3 } }
{ "body" : "warning: connection timed out" }
{ "index" : { "_id" : 4 } }
{ "body" : "info: hello pdai" }
对包含不同日志类型的日志进行分组,这就需要filters:
GET /test-agg-logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket_key": "other_messages",
"filters" : {
"infos" : { "match" : { "body" : "info" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
对number类型聚合:range
基于多桶值源的聚合,使用户能够定义一组范围-每个范围代表一个桶。在聚合过程中,将从每个存储区范围中检查从每个文档中提取的值,并“存储”相关/匹配的文档。请注意,此聚合包括from值,但不包括to每个范围的值。
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 20000 },
{ "from": 20000, "to": 40000 },
{ "from": 40000 }
]
}
}
}
}
对IP类型聚合:ip_range
GET /ip_addresses/_search
{
"size": 10,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "to": "10.0.0.5" },
{ "from": "10.0.0.5" }
]
}
}
}
}
返回结果
{
...
"aggregations": {
"ip_ranges": {
"buckets": [
{
"key": "*-10.0.0.5",
"to": "10.0.0.5",
"doc_count": 10
},
{
"key": "10.0.0.5-*",
"from": "10.0.0.5",
"doc_count": 260
}
]
}
}
}
此外还可以用CIDR Mask分组
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "mask": "10.0.0.0/25" },
{ "mask": "10.0.0.127/25" }
]
}
}
}
}
返回结果
{
...
"aggregations": {
"ip_ranges": {
"buckets": [
{
"key": "10.0.0.0/25",
"from": "10.0.0.0",
"to": "10.0.0.128",
"doc_count": 128
},
{
"key": "10.0.0.127/25",
"from": "10.0.0.0",
"to": "10.0.0.128",
"doc_count": 128
}
]
}
}
}
增加key显示
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "to": "10.0.0.5" },
{ "from": "10.0.0.5" }
],
"keyed": true // here
}
}
}
}
返回结果
{
...
"aggregations": {
"ip_ranges": {
"buckets": {
"*-10.0.0.5": {
"to": "10.0.0.5",
"doc_count": 10
},
"10.0.0.5-*": {
"from": "10.0.0.5",
"doc_count": 260
}
}
}
}
}
自定义key显示
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "key": "infinity", "to": "10.0.0.5" },
{ "key": "and-beyond", "from": "10.0.0.5" }
],
"keyed": true
}
}
}
}
返回结果
{
...
"aggregations": {
"ip_ranges": {
"buckets": {
"infinity": {
"to": "10.0.0.5",
"doc_count": 10
},
"and-beyond": {
"from": "10.0.0.5",
"doc_count": 260
}
}
}
}
}
对日期类型聚合:date_range
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"range": {
"date_range": {
"field": "sold",
"format": "yyyy-MM",
"ranges": [
{ "from": "2014-01-01" },
{ "to": "2014-12-31" }
]
}
}
}
}
对柱状图功能:Histrogram
指标聚合
单值分析,标准stat类型
avg平均值
计算班级的平均分
POST /exams/_search?size=0
{
"aggs": {
"avg_grade": { "avg": { "field": "grade" } }
}
}
返回
{
...
"aggregations": {
"avg_grade": {
"value": 75.0
}
}
}
max最大值
计算销售最高价
POST /sales/_search?size=0
{
"aggs": {
"max_price": { "max": { "field": "price" } }
}
}
返回
{
...
"aggregations": {
"max_price": {
"value": 200.0
}
}
}
min最小值
计算销售最低价
POST /sales/_search?size=0
{
"aggs": {
"min_price": { "min": { "field": "price" } }
}
}
返回
{
...
"aggregations": {
"min_price": {
"value": 10.0
}
}
}
sum计算和
计算销售总价
POST /sales/_search?size=0
{
"query": {
"constant_score": {
"filter": {
"match": { "type": "hat" }
}
}
},
"aggs": {
"hat_prices": { "sum": { "field": "price" } }
}
}
返回
{
...
"aggregations": {
"hat_prices": {
"value": 450.0
}
}
}
value_count统计数量
销售数量统计
POST /sales/_search?size=0
{
"aggs" : {
"types_count" : { "value_count" : { "field" : "type" } }
}
}
返回
{
...
"aggregations": {
"types_count": {
"value": 7
}
}
}
单值分析:其他类型
weighted_avg带权重的avg
POST /exams/_search
{
"size": 0,
"aggs": {
"weighted_grade": {
"weighted_avg": {
"value": {
"field": "grade"
},
"weight": {
"field": "weight"
}
}
}
}
}
返回
{
...
"aggregations": {
"weighted_grade": {
"value": 70.0
}
}
}
cardinality 基数(distinct去重)
POST /sales/_search?size=0
{
"aggs": {
"type_count": {
"cardinality": {
"field": "type"
}
}
}
}
返回
{
...
"aggregations": {
"type_count": {
"value": 3
}
}
}
median_absolute_deviation:中位值
GET reviews/_search
{
"size": 0,
"aggs": {
"review_average": {
"avg": {
"field": "rating"
}
},
"review_variability": {
"median_absolute_deviation": {
"field": "rating"
}
}
}
}
返回
{
...
"aggregations": {
"review_average": {
"value": 3.0
},
"review_variability": {
"value": 2.0
}
}
}
非单值分析:stats类型
stats包含avg,max,min,sum和count
POST /exams/_search?size=0
{
"aggs": {
"grades_stats": { "stats": { "field": "grade" } }
}
}
返回
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}
matrix_stats 针对矩阵模型
使用矩阵统计量来描述收入与贫困之间的关系。
GET /_search
{
"aggs": {
"statistics": {
"matrix_stats": {
"fields": [ "poverty", "income" ]
}
}
}
}
返回
{
...
"aggregations": {
"statistics": {
"doc_count": 50,
"fields": [ {
"name": "income",
"count": 50,
"mean": 51985.1,
"variance": 7.383377037755103E7,
"skewness": 0.5595114003506483,
"kurtosis": 2.5692365287787124,
"covariance": {
"income": 7.383377037755103E7,
"poverty": -21093.65836734694
},
"correlation": {
"income": 1.0,
"poverty": -0.8352655256272504
}
}, {
"name": "poverty",
"count": 50,
"mean": 12.732000000000001,
"variance": 8.637730612244896,
"skewness": 0.4516049811903419,
"kurtosis": 2.8615929677997767,
"covariance": {
"income": -21093.65836734694,
"poverty": 8.637730612244896
},
"correlation": {
"income": -0.8352655256272504,
"poverty": 1.0
}
} ]
}
}
}
extended_stats根据从汇总文档中提取的数值计算统计信息
GET /exams/_search
{
"size": 0,
"aggs": {
"grades_stats": { "extended_stats": { "field": "grade" } }
}
}
返回
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0,
"sum_of_squares": 12500.0,
"variance": 625.0,
"variance_population": 625.0,
"variance_sampling": 1250.0,
"std_deviation": 25.0,
"std_deviation_population": 25.0,
"std_deviation_sampling": 35.35533905932738,
"std_deviation_bounds": {
"upper": 125.0,
"lower": 25.0,
"upper_population": 125.0,
"lower_population": 25.0,
"upper_sampling": 145.71067811865476,
"lower_sampling": 4.289321881345245
}
}
}
}
string_stats 针对字符串
用于计算从聚合文档中提取的字符串值的统计信息。
POST /my-index-000001/_search?size=0
{
"aggs": {
"message_stats": { "string_stats": { "field": "message.keyword" } }
}
}
返回
{
...
"aggregations": {
"message_stats": {
"count": 5,
"min_length": 24,
"max_length": 30,
"avg_length": 28.8,
"entropy": 3.94617750050791
}
}
}
非单值分析:百分数型
percentiles 百分数范围
针对从聚合文档中提取的数值计算一个或多个百分位数。
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time"
}
}
}
}
返回
{
...
"aggregations": {
"load_time_outlier": {
"values": {
"1.0": 5.0,
"5.0": 25.0,
"25.0": 165.0,
"50.0": 445.0,
"75.0": 725.0,
"95.0": 945.0,
"99.0": 985.0
}
}
}
}
percentile_ranks 百分数排行
根据从汇总文档中提取的数值计算一个或多个百分位等级。
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_ranks": {
"percentile_ranks": {
"field": "load_time",
"values": [ 500, 600 ]
}
}
}
}
返回
{
...
"aggregations": {
"load_time_ranks": {
"values": {
"500.0": 90.01,
"600.0": 100.0
}
}
}
}
非单值分析:地理位置型
geo_bounds
汇总展示了如何针对具有商店业务类型的所有文档计算位置字段的边界框
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "52.374081,4.912350", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "52.369219,4.901618", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "52.371667,4.914722", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "51.222900,4.405200", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "48.861111,2.336389", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "48.860000,2.327000", "name": "Musée d'Orsay"}
POST /museums/_search?size=0
{
"query": {
"match": { "name": "musée" }
},
"aggs": {
"viewport": {
"geo_bounds": {
"field": "location",
"wrap_longitude": true
}
}
}
}
返回
{
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": {
"lat": 48.86111099738628,
"lon": 2.3269999679178
},
"bottom_right": {
"lat": 48.85999997612089,
"lon": 2.3363889567553997
}
}
}
}
}
================
geo_centroid
================
geo_line
================
非单值分析:Top型
top_hits 分桶后的top hits
POST /sales/_search?size=0
{
"aggs": {
"top_tags": {
"terms": {
"field": "type",
"size": 3
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"sort": [
{
"date": {
"order": "desc"
}
}
],
"_source": {
"includes": [ "date", "price" ]
},
"size": 1
}
}
}
}
}
}
返回
{
...
"aggregations": {
"top_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "hat",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmauCQpcRyxw6ChK",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 200
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "t-shirt",
"doc_count": 3,
"top_sales_hits": {
"hits": {
"total" : {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmauCQpcRyxw6ChL",
"_source": {
"date": "2015/03/01 00:00:00",
"price": 175
},
"sort": [
1425168000000
],
"_score": null
}
]
}
}
},
{
"key": "bag",
"doc_count": 1,
"top_sales_hits": {
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "sales",
"_type": "_doc",
"_id": "AVnNBmatCQpcRyxw6ChH",
"_source": {
"date": "2015/01/01 00:00:00",
"price": 150
},
"sort": [
1420070400000
],
"_score": null
}
]
}
}
}
]
}
}
}
=================
top_metrics
POST /test/_bulk?refresh
{"index": {}}
{"s": 1, "m": 3.1415}
{"index": {}}
{"s": 2, "m": 1.0}
{"index": {}}
{"s": 3, "m": 2.71828}
POST /test/_search?filter_path=aggregations
{
"aggs": {
"tm": {
"top_metrics": {
"metrics": {"field": "m"},
"sort": {"s": "desc"}
}
}
}
}
返回
{
"aggregations": {
"tm": {
"top": [ {"sort": [3], "metrics": {"m": 2.718280076980591 } } ]
}
}
}
管道聚合
让上一步的聚合结果成为下一个聚合的输入,这就是管道。
管道机制在设计模式上属于责任链模式
Bucket聚合 -> Metric聚合: bucket聚合的结果,成为下一步metric聚合的输入
Average bucket
Min bucket
Max bucket
Sum bucket
Stats bucket
Extended stats bucket
性能优化
主要从硬件配置优化、索引优化设置、查询方面优化、数据结构优化、集群架构优化
硬件配置优化
在系统层面能够影响应用性能的一般包括三个因素:CPU、内存和 IO,可以从这三方面进行 ES 的性能优化工作
大多数 Elasticsearch 部署往往对 CPU 要求不高。
如果有一种资源是最先被耗尽的,它可能是内存。排序和聚合都很耗内存,所以有足够的堆空间来应付它们是很重要的。
由于 ES 构建基于 lucene,而 lucene 设计强大之处在于 lucene 能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene 的索引文件 segements 是存储在单文件中的,并且不可变,对于 OS 来说,能够很友好地将索引文件保持在 cache 中,以便快速访问;因此,我们很有必要将一半的物理内存留给 lucene;另一半的物理内存留给 ES(JVM heap)
当机器内存小于 64G 时,遵循通用的原则,50% 给 ES,50% 留给 lucene
当机器内存大于 64G 时,遵循以下原则
如果主要的使用场景是全文检索,那么建议给 ES Heap 分配 4~32G 的内存即可;其它内存留给操作系统,供 lucene 使用(segments cache),以提供更快的查询性能
如果主要的使用场景是聚合或排序,并且大多数是 numerics,dates,geo_points 以及 not_analyzed 的字符类型,建议分配给 ES Heap 分配 4~32G 的内存即可,其它内存留给操作系统,供 lucene 使用,提供快速的基于文档的聚类、排序性能。
如果使用场景是聚合或排序,并且都是基于 analyzed 字符数据,这时需要更多的 heap size,建议机器上运行多 ES 实例,每个实例保持不超过 50% 的 ES heap 设置(但不超过 32 G,堆内存设置 32 G 以下时,JVM 使用对象指标压缩技巧节省空间),50% 以上留给 lucene
禁止 swap,一旦允许内存与磁盘的交换,会引起致命的性能问题。可以通过在 elasticsearch.yml 中 bootstrap.memory_lock: true,以保持 JVM 锁定内存,保证 ES 的性能
推荐你使用G1 GC; 因为我们目前的项目使用的就是G1 GC,运行效果良好,对Heap大对象优化尤为明显。修改jvm.options文件
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
更改为
-XX:+UseG1GC
-XX:MaxGCPauseMillis=50
其中 -XX:MaxGCPauseMillis是控制预期的最高GC时长,默认值为200ms,如果线上业务特性对于GC停顿非常敏感,可以适当设置低一些。但是 这个值如果设置过小,可能会带来比较高的cpu消耗。
G1对于集群正常运作的情况下减轻G1停顿对服务时延的影响还是很有效的,但是如果是你描述的GC导致集群卡死,那么很有可能换G1也无法根本上解决问题。 通常都是集群的数据模型或者Query需要优化
索引优化
索引优化主要是在 Elasticsearch 的插入层面优化,Elasticsearch 本身索引速度其实还是蛮快的
批量提交
当有大量数据提交的时候,建议采用批量提交(Bulk 操作);此外使用 bulk 请求时,每个请求不超过几十M,因为太大会导致内存使用过大。
比如在做 ELK 过程中,Logstash indexer 提交数据到 Elasticsearch 中,batch size 就可以作为一个优化功能点。但是优化 size 大小需要根据文档大小和服务器性能而定。
像 Logstash 中提交文档大小超过 20MB,Logstash 会将一个批量请求切分为多个批量请求
如果在提交过程中,遇到 EsRejectedExecutionException 异常的话,则说明集群的索引性能已经达到极限了。这种情况,要么提高服务器集群的资源,要么根据业务规则,减少数据收集速度,比如只收集 Warn、Error 级别以上的日志
优化Refresh
为了提高索引性能,Elasticsearch 在写入数据的时候,采用延迟写入的策略,即数据先写到内存中,当超过默认1秒(index.refresh_interval)会进行一次写入操作,就是将内存中 segment 数据刷新到磁盘中,此时我们才能将数据搜索出来,所以这就是为什么 Elasticsearch 提供的是近实时搜索功能,而不是实时搜索功能
如果我们的系统对数据延迟要求不高的话,我们可以通过延长 refresh 时间间隔,可以有效地减少 segment 合并压力,提高索引速度。比如在做全链路跟踪的过程中,我们就将 index.refresh_interval 设置为30s,减少 refresh 次数。再如,在进行全量索引时,可以将 refresh 次数临时关闭,即 index.refresh_interval 设置为-1,数据导入成功后再打开到正常模式,比如30s。
在加载大量数据时候可以暂时不用 refresh 和 repliccas,index.refresh_interval 设置为-1,index.number_of_replicas 设置为0。
查询优化
路由优化
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?它其实是通过下面这个公式来计算出来的:shard = hash(routing) % number_of_primary_shards
routing 默认值是文档的 id,也可以采用自定义值,比如用户 ID。
不带routing在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为2个步骤:
分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
聚合:协调节点搜集到每个分片上查询结果,再将查询的结果进行排序,之后给用户返回结果
带routing查询的时候,可以直接根据 routing 信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序。
filter和query
尽可能使用过滤器上下文(Filter)替代查询上下文(Query)
Query:此文档与此查询子句的匹配程度如何
Filter:此文档和查询子句匹配
Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一样计算相关性分数,同时Filter结果可以缓存
深度翻页
在使用 Elasticsearch 过程中,应尽量避免大翻页的出现。
正常翻页查询都是从 from 开始 size 条数据,这样就需要在每个分片中查询打分排名在前面的 from+size 条数据。协同节点收集每个分配的前 from+size 条数据。协同节点一共会受到 N*(from+size) 条数据,然后进行排序,再将其中 from 到 from+size 条数据返回出去。如果 from 或者 size 很大的话,导致参加排序的数量会同步扩大很多,最终会导致 CPU 资源消耗增大。
可以通过使用 Elasticsearch scroll 和 scroll-scan 高效滚动的方式来解决这样的问题。
也可以结合实际业务特点,文档 id 大小如果和文档创建时间是一致有序的,可以以文档 id 作为分页的偏移量,并将其作为分页查询的一个条件
整合springboot
- pom
<properties>
<elasticsearch.version>5.5.2</elasticsearch.version>
</properties>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
- 编写ES配置类
@Configuration
public class EsConfig {
@Bean
public TransportClient client() throws UnknownHostException{
//新建一个服务地址
InetSocketTransportAddress node = new InetSocketTransportAddress(InetAddress.getByName("localhost"),9300);
Settings settings = Settings.builder()
// es集群名称
.put("cluster.name", "myes")
.build();
TransportClient client = new PreBuiltTransportClient(settings);
client.addTransportAddress(node);
return client;
}
}
- 编写图书接口类
/**
* @title 图书REST接口类
* @describe 调ES接口
*/
@RestController
public class BookRest {
@Autowired
private TransportClient client;
@GetMapping("/")
public String index(){
return "index";
}
/**
* @describe 查询接口
* @author zc
* @version 1.0 2017-09-15
*/
@GetMapping("/get/book/novel")
public ResponseEntity<?> get(@RequestParam(name="id",defaultValue="")String id){
if(id.isEmpty()){
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
GetResponse result = this.client.prepareGet("book","novel",id).get();
if(!result.isExists()){
return new ResponseEntity<>(HttpStatus.NOT_FOUND);
}
return new ResponseEntity<>(result.getSource(), HttpStatus.OK);
}
/**
* @describe 增加接口
* @author zc
* @version 1.0 2017-09-15
*/
@PostMapping("/add/book/novel")
public ResponseEntity<?> add(
@RequestParam(name="title")String title,
@RequestParam(name="author")String author,
@RequestParam(name="word_count")int wordCount,
@RequestParam(name="publish_date") @DateTimeFormat(pattern="yyyy-MM-dd HH:mm:ss") Date publishDate){
try {
//构建一个json
XContentBuilder content = XContentFactory.jsonBuilder()
.startObject()
.field("title",title)
.field("author", author)
.field("word_count", wordCount)
.field("publish_date", publishDate.getTime())
.endObject();
//获取返回结果
IndexResponse result = this.client.prepareIndex("book","novel").setSource(content).get();
return new ResponseEntity<>(result.getId(),HttpStatus.OK);
} catch (IOException e) {
e.printStackTrace();
return new ResponseEntity<>(HttpStatus.INTERNAL_SERVER_ERROR);
}
}
/**
* @describe 删除接口
* @author zc
* @version 1.0 2017-09-15
*/
@DeleteMapping("/delete/book/novel")
public ResponseEntity<?> delete(@RequestParam(name="id",defaultValue="")String id){
DeleteResponse result = this.client.prepareDelete("book", "novel", id).get();
return new ResponseEntity<>(result.toString(),HttpStatus.OK);
}
/**
* @describe 修改接口
* @author zc
* @version 1.0 2017-09-15
*/
@DeleteMapping("/update/book/novel")
public ResponseEntity<?> update(
@RequestParam(name="id",defaultValue="")String id,
@RequestParam(name="title",required=false)String title,
@RequestParam(name="author",required=false)String author){
UpdateRequest update = new UpdateRequest("book","novel",id);
try {
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject();
if(!StringUtils.isEmpty(title)){
builder.field("title",title);
}
if(!StringUtils.isEmpty(author)){
builder.field("author", author);
}
builder.endObject();
update.doc(builder);
UpdateResponse result = this.client.update(update).get();
return new ResponseEntity<>(result.toString(),HttpStatus.OK);
} catch (Exception e) {
e.printStackTrace();
return new ResponseEntity<>(HttpStatus.INTERNAL_SERVER_ERROR);
}
}
/**
* @describe 复合查询
* @author zc
* @version 1.0 2017-09-15
*/
@DeleteMapping("/query/book/novel")
public ResponseEntity<?> query(
@RequestParam(name="author",required=false)String author,
@RequestParam(name="title",required=false)String title,
@RequestParam(name="gt_word_count",defaultValue="0") int gtWordCount,
@RequestParam(name="lt_word_count",required=false) Integer ltWordCount){
// 构建布尔查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
if(!StringUtils.isEmpty(author)){
boolQuery.must(QueryBuilders.matchQuery("author", author));
}
if(!StringUtils.isEmpty(title)){
boolQuery.must(QueryBuilders.matchQuery("title", title));
}
// 构建范围查询
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("word_count")
.from(gtWordCount);
if(ltWordCount != null && ltWordCount > 0){
rangeQuery.to(ltWordCount);
}
// 使用filter构建
boolQuery.filter(rangeQuery);
SearchRequestBuilder builder = this.client.prepareSearch("book")
.setTypes("novel")
.setSearchType(SearchType.DFS_QUERY_THEN_FETCH)
.setQuery(boolQuery)
.setFrom(0)
.setSize(10);
System.out.println("[ES查询请求参数]:"+builder);
SearchResponse response = builder.get();
List<Map<String,Object>> result = new ArrayList<Map<String,Object>>();
for(SearchHit hit:response.getHits()){
result.add(hit.getSource());
}
return new ResponseEntity<>(result,HttpStatus.OK);
}
}