mysql
【问题】 MySQL 中四种隔离级别分别是什么?
【参考答案】 MySQL 数据库中定义的四种事务隔离级别(Transaction Isolation Levels)用于解决并发事务带来的问题:
- 读未提交 (READ UNCOMMITTED):
- 特点:事务可以读取到其他事务未提交的数据修改。
- 问题:存在 脏读 (Dirty Read),即读取到了最终可能回滚的无效数据。
- 读已提交 (READ COMMITTED):
- 特点:事务只能读取到其他事务已经提交的数据。
- 问题:解决了脏读,但存在 不可重复读 (Non-Repeatable Read),即在同一个事务内多次读取同一条记录,结果可能不一致。
- 可重复读 (REPEATABLE READ):
- 特点:保证在同一个事务内,多次读取同一条记录的结果是一致的。
- 地位:MySQL InnoDB 存储引擎的 默认隔离级别。
- 可串行化 (SERIALIZABLE):
- 特点:最高的隔离级别。通过强制事务排序,使之不可能相互冲突。
- 代价:在每个读数据行上加上共享锁,性能最低。
【延伸考点讲解】
- 并发问题总结:脏读(读取未提交数据)、不可重复读(读取已提交的更新数据)、幻读(读取已提交的新插入数据)。
- 幻读 (Phantom Read) 与 MVCC:InnoDB 在“可重复读”级别下,通过 MVCC (多版本并发控制) 和 Next-Key Locks (间隙锁) 已经在很大程度上解决了幻读问题,这是它与标准 SQL 定义的区别。
- 隔离级别与性能的权衡:隔离级别越高,数据一致性越好,但系统的并发性能越差。在实际开发中,通常根据业务场景选择
READ COMMITTED(大多数数据库默认)或REPEATABLE READ(MySQL 默认)。
【问题】 SQL 之连接查询(左连接和右连接的区别)?
【参考答案】 连接查询是 SQL 中将多张表的数据结合在一起的基础操作。常见的连接方式如下:
- 左连接 (LEFT JOIN):
- 逻辑:以左表为基准,返回左表的所有记录。
- 结果:如果右表中有匹配项,则显示对应数据;如果没有匹配项,右表的字段显示为
NULL。
- 右连接 (RIGHT JOIN):
- 逻辑:以右表为基准,返回右表的所有记录。
- 结果:如果左表中有匹配项,则显示对应数据;如果没有匹配项,左表的字段显示为
NULL。
- 内连接 (INNER JOIN):
- 逻辑:只返回两张表中完全匹配(满足连接条件)的行。
- 全连接 (FULL JOIN):
- 逻辑:返回左右两表中的所有记录。匹配的行合并显示,不匹配的行显示
NULL。 【延伸考点讲解】
- 逻辑:返回左右两表中的所有记录。匹配的行合并显示,不匹配的行显示
- 性能与习惯:在实际开发中,左连接 的使用频率远高于右连接。绝大多数右连接都可以通过交换表顺序改为左连接,这样代码逻辑更符合从左到右的阅读习惯。
- MySQL 对全连接的支持:MySQL 原生并不支持
FULL JOIN关键字。如果需要实现全连接,通常使用LEFT JOIN和RIGHT JOIN配合UNION关键字来实现。 - 驱动表与被驱动表:连接查询时,基准表被称为“驱动表”,另一张表称为“被驱动表”。合理选择驱动表并结合索引,是 SQL 调优的关键。
【问题】 left join on 后面加条件与 where 后面加条件与 group by having 后加条件的区别?
【参考答案】 这三者在 SQL 执行流程中的阶段不同,导致了过滤效果的差异:
- ON 条件:
- 阶段:在生成连接中间表(Join)时执行。
- 效果:如果是
LEFT JOIN,即使ON中的条件为假,左表的记录也 一定会 返回,只是对应的右表字段为NULL。
- WHERE 条件:
- 阶段:在临时表生成之后执行的过滤。
- 效果:它对连接后的结果集进行筛选。如果
WHERE条件不满足,整行记录(包括左表数据)都会被剔除,此时LEFT JOIN的“保留左表”特性会失效。
- HAVING 条件:
- 阶段:在
GROUP BY分组计算之后执行。 - 效果:专门用于过滤分组后的聚合结果(如
COUNT(*) > 1),不能直接用于过滤原始行。 【延伸考点讲解】
- 阶段:在
- 执行顺序:
FROM->ON->JOIN->WHERE->GROUP BY->HAVING->SELECT->ORDER BY。 - 性能优化:尽量将过滤条件放在
ON或WHERE中,而不是HAVING,因为早期的过滤可以减少后续处理的数据量。 - 逻辑陷阱:在使用
LEFT JOIN时,如果误将右表的筛选条件放在WHERE中,可能会导致查询结果退化为INNER JOIN的效果。
【问题】 数据库三范式是什么?
【参考答案】 数据库范式(Normal Form)是设计关系型数据库时需要遵循的规范,旨在减少数据冗余和改善数据完整性:
- 第一范式 (1NF):
- 核心:原子性。要求表中的每个字段都是不可再分的最小数据单位。
- 第二范式 (2NF):
- 核心:完全函数依赖。在满足 1NF 的基础上,要求表中的非主键列必须完全依赖于主键,而不能只依赖于主键的一部分(针对复合主键而言)。
- 第三范式 (3NF):
- 核心:消除传递依赖。在满足 2NF 的基础上,要求表中的非主键列必须直接依赖于主键,不能存在传递依赖(即非主键列 A 依赖于非主键列 B,而 B 依赖于主键)。
【延伸考点讲解】
- 设计目标:范式化的主要目的是消除数据冗余,从而减少数据插入、更新和删除时的异常。
- 反范式化 (Denormalization):在实际的高性能数据库设计中,有时为了提高查询效率(减少多表关联 Join 操作),会刻意违反范式,增加一定的冗余字段。
- 范式级别:除了前三范式,还有 BCNF(鲍依斯-科德范式)、第四范式、第五范式等,但在绝大多数商业应用设计中,达到第三范式即被认为是合理的。
【问题】 SQL 语句的关键词执行顺序是怎样的?
【参考答案】 理解 SQL 的逻辑执行顺序对于编写高效的查询至关重要。其标准执行顺序如下:
- FROM:从指定的数据源(表或视图)加载数据。
- ON:执行连接条件过滤。
- JOIN:进行表连接操作。
- WHERE:对原始行数据进行初步筛选。
- GROUP BY:将结果集划分为多个分组。
- 聚合函数:执行
COUNT,SUM,AVG等计算。 - HAVING:对分组后的结果进行二次筛选。
- SELECT:选择要显示的列,执行计算表达式。
- DISTINCT:对结果集进行去重。
- ORDER BY:对最终结果进行排序。
- LIMIT / OFFSET:进行分页截断。
简记: FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT。
【延伸考点讲解】
- 别名的使用限制:为什么
WHERE中不能直接使用SELECT中定义的别名?因为在执行WHERE时,SELECT尚未执行,别名还未定义。而ORDER BY却可以使用别名。 - 性能优化:由于
WHERE在GROUP BY之前执行,而HAVING在其之后,因此应尽可能将过滤条件写在WHERE中,以减少参与分组和聚合的数据量。 - 执行引擎差异:虽然逻辑执行顺序是标准的,但数据库查询优化器(Optimizer)在实际执行时可能会根据索引和统计信息调整物理执行路径。
函数
【问题】 SQL 中聚合函数有哪些?
【参考答案】
聚合函数(Aggregate Functions)是对一组值进行计算并返回单个汇总值的函数。它们通常与 GROUP BY 子句配合使用。常用的聚合函数包括:
- AVG():返回数值列的平均值。空值(NULL)会被忽略。
- COUNT():返回匹配条件的行数。
COUNT(*)统计总行数,COUNT(column)统计非空值的行数。 - MAX():返回指定列中的最大值。
- MIN():返回指定列中的最小值。
- SUM():返回数值列的总和。空值会被忽略。
【延伸考点讲解】
- NULL 值的处理:除了
COUNT(*)之外,大多数聚合函数都会自动忽略NULL值。在计算平均值时,NULL不会计入分母。 - DISTINCT 的使用:聚合函数可以配合
DISTINCT关键字使用,例如COUNT(DISTINCT city)将统计不重复的城市数量。 - WHERE 与 HAVING 的配合:
WHERE用于在聚合前过滤行,而HAVING用于在聚合后过滤组。例如:SELECT department, AVG(salary) FROM employees WHERE age > 30 GROUP BY department HAVING AVG(salary) > 5000;
【问题】 在 MySQL 中,怎么存储 IP 地址?
【参考答案】 在 MySQL 中存储 IP 地址,应优先考虑性能和存储空间的平衡:
- IPv4 存储:
- 推荐方案:使用 32位无符号整数 (UNSIGNED INT)。
- 理由:仅占用 4 字节,比字符串存储(需 15 字节以上)节省空间,且索引查询速度更快。
- 转换函数:
INET_ATON()(字符串转数字)和INET_NTOA()(数字转字符串)。
- IPv6 存储:
- 推荐方案:使用 VARBINARY(16)。
- 理由:IPv6 地址为 128 位,占用 16 字节。
- 转换函数:
INET6_ATON()和INET6_NTOA()。
【延伸考点讲解】
- 为什么不用 VARCHAR?:虽然
VARCHAR(15)更直观,但它需要额外的 1 字节存储长度,实际占用可达 16 字节,且在进行范围查询(如 CIDR 匹配)时性能远低于整数。 - 转换示例:
SELECT INET_ATON('192.168.1.1');-> 返回3232235777SELECT INET_NTOA(3232235777);-> 返回'192.168.1.1'
- 架构建议:在高性能场景下,不仅是 IP 地址,对于具有固定长度或可数值化的标识符,都应优先考虑使用定长数值类型存储。
存储引擎
【问题】 MyISAM 存储引擎了解吗?
【参考答案】 MyISAM 是 MySQL 5.5 之前的默认存储引擎。它的设计目标是快速读取,但在并发写入和数据安全性方面较弱。
- 锁机制:仅支持 表级锁 (Table-level Locking)。读操作加共享锁,写操作加排他锁。高并发写入时容易产生严重的性能瓶颈。
- 事务支持:不支持事务,也不支持崩溃后的安全恢复。
- 存储结构:每张表在磁盘上存储为三个文件:
.frm(表结构)、.MYD(数据)、.MYI(索引)。 - 索引特性:支持 全文索引 (FULLTEXT)(MySQL 5.6 之前唯一支持全文索引的引擎)。索引采用 B-Tree 结构,且是非聚集索引(数据与索引分离)。
- 统计信息:内置计数器存储了表的总行数,因此
count(*)操作极快。
【延伸考点讲解】
- 聚集索引 vs 非聚集索引:MyISAM 是非聚集索引,索引文件(.MYI)存储的是指向数据文件(.MYD)中物理地址的指针。
- 适用场景:适用于读多写极少、对事务无要求、追求极致查询速度或需要全文搜索的场景(如日志表、报表分析、只读内容系统)。
- 数据完整性:由于不支持事务和外键,数据的完整性必须由应用程序逻辑来保证。
【问题】 InnoDB 存储引擎了解吗?
【参考答案】 InnoDB 是 MySQL 5.5 之后默认的存储引擎,是目前应用最广泛的事务型引擎:
- 事务支持:完全支持 ACID 事务,支持提交、回滚和崩溃恢复能力。
- 锁机制:支持 行级锁 (Row-level Locking),大大提高了多用户并发性能。
- 并发控制:通过 MVCC (多版本并发控制) 实现了非锁定读,减少了锁冲突。
- 数据存储:采用 聚集索引 (Clustered Index) 组织表,数据文件与主键索引绑定在一起,通过主键查询效率极高。
- 数据完整性:支持 外键 (Foreign Key) 约束。
【延伸考点讲解】
- 聚集索引 vs 辅助索引:InnoDB 的数据实际上存储在主键索引的叶子节点上。辅助索引(二级索引)的叶子节点存储的是主键值,因此通过辅助索引查询通常需要“回表”。
- Buffer Pool:InnoDB 拥有独立的缓冲池,不仅缓存索引,也缓存真实数据,这是它性能优于 MyISAM 的关键之一。
- 幻读解决:通过 Next-Key Locks(行锁 + 间隙锁)算法,InnoDB 在“可重复读”隔离级别下成功解决了幻读问题。
- 统计信息:与 MyISAM 不同,InnoDB 不存储表的总行数,执行
count(*)需要扫描索引或全表。
优化
【问题】 MySQL 怎样优化分页查询?
【参考答案】
当数据量巨大时,传统的 LIMIT offset, rows 分页方式会随着 offset 的增大而变得极其缓慢,因为数据库需要扫描并丢弃前面的所有行。优化方案包括:
- 基于主键的范围查询:
- 逻辑:如果主键是自增且连续的,记录上一次查询的最大 ID,下次查询时直接定位。
- 示例:
SELECT * FROM table WHERE id > 10000 LIMIT 10; - 优点:直接定位,性能极佳。
- 子查询优化(延迟关联):
- 逻辑:先通过子查询利用覆盖索引找到目标主键,再回表获取完整记录。
- 示例:
SELECT * FROM table t1 JOIN (SELECT id FROM table ORDER BY id LIMIT 10000, 10) t2 ON t1.id = t2.id; - 优点:减少了回表次数和数据扫描量。
- 覆盖索引:
- 逻辑:如果查询的字段全部包含在索引中,则无需回表,直接从索引中返回结果。
【延伸考点讲解】
- 深度分页瓶颈:深分页(如
LIMIT 1000000, 10)的本质问题是 MySQL 需要读取 1,000,010 条记录,然后丢弃前 1,000,000 条,造成巨大的磁盘 I/O 和内存浪费。 - 业务层面规避:对于极深的分页,可以考虑限制用户的翻页深度(如只允许翻前 100 页),或者采用“下一页”模式(类似微博、抖音的无限滚动,记录上一个游标值)。
- 搜索引擎辅助:对于海量数据的复杂分页查询,通常建议将其同步到 Elasticsearch 等全文检索引擎中处理。
【问题】 SQL 之 SQL 注入是什么?
【参考答案】 SQL 注入(SQL Injection)是一种常见的网络安全漏洞。攻击者通过在 Web 表单输入、URL 参数或 HTTP 请求中插入恶意的 SQL 代码,欺骗数据库服务器执行非预期的指令。
- 核心原理:由于应用程序没有对用户输入进行严格的校验和过滤,直接将输入拼接到 SQL 语句中执行。
- 典型危害:绕过身份验证、窃取敏感数据(如用户密码)、非法篡改或删除数据库记录,甚至通过数据库权限获取服务器控制权。
- 示例:查询语句原本为
SELECT * FROM user WHERE username = '+ 用户输入 +'。若攻击者输入' OR '1'='1,SQL 将变为SELECT * FROM user WHERE username = '' OR '1'='1',导致WHERE条件恒成立,从而绕过登录。
【延伸考点讲解】
- 注入类型:包括报错注入、布尔盲注、时间盲注(基于延迟)、联合查询注入(UNION)等。
- 防御关键:永远不要相信用户的输入。必须对用户输入进行严格的合法性校验、特殊字符转义,或者最根本地使用 预编译语句 (Prepared Statements)。
- 辅助工具:开发者常用的自动化漏洞检测工具有 sqlmap。
【问题】 防止 SQL 注入的方式?
【参考答案】 预防 SQL 注入的核心原则是“数据与指令分离”。主要方式包括:
- 使用预编译语句 (Prepared Statements):
- 原理:SQL 模板先发送到数据库编译,之后传入的参数仅被视为纯数据,不会被解析为 SQL 指令。
- 示例:JDBC 中的
PreparedStatement。
- 使用 ORM 框架的安全特性:
- MyBatis:优先使用
#{}占位符(底层即预编译),避免使用${}(直接拼接)。 - Hibernate/JPA:使用命名参数查询。
- MyBatis:优先使用
- 严格的输入校验与转义:
- 对用户输入进行类型检查(如 ID 必须是数字)、长度限制及特殊字符转义(如单引号、分号等)。
- 最小权限原则:
- 数据库账号仅赋予执行业务所需的最小权限,禁止 Web 应用使用
root或db_owner权限连接数据库。
- 数据库账号仅赋予执行业务所需的最小权限,禁止 Web 应用使用
【延伸考点讲解】
- #{} vs ${}:在 MyBatis 中,
#{}会将参数部分替换为?,而${}是直接进行字符串替换,后者极易引发 SQL 注入。但在某些动态场景(如动态表名、排序字段ORDER BY)中不得不使用${}时,必须手动进行白名单过滤。 - 存储过程安全:虽然存储过程也是预编译的,但如果在存储过程内部使用了动态 SQL 拼接,依然可能存在注入风险。
- WAF (Web Application Firewall):在网络层部署 Web 应用防火墙,可以拦截大部分常见的注入攻击。
【问题】 MySQL 性能优化有哪些?
【参考答案】 MySQL 性能优化可以从多个维度入手,包括 SQL 语句优化、索引优化、数据库架构设计等:
- SQL 语句优化:
- 精准查询:避免使用
SELECT *,仅返回必要的字段,减少网络带宽消耗 and 内存占用。 - 限制返回量:如果已知只查询一行,使用
LIMIT 1,引擎在找到后会立即停止扫描。 - 避免全表扫描:避免在
WHERE子句中对字段进行NULL值判断、函数操作或开头模糊查询(如LIKE '%abc'),这些都会导致索引失效。 - 子查询优化:优先使用
EXISTS或JOIN代替IN/NOT IN,因为前者更能有效利用索引。
- 精准查询:避免使用
- 索引优化:
- 覆盖索引:尽量使查询条件和返回字段都在索引中,避免“回表”。
- 合理建立索引:为高频搜索、排序、分组的字段建立索引,但避免过度索引。
- 架构与配置优化:
- 选择合适的引擎:事务型应用首选
InnoDB(行锁、事务支持);读密集且无事务要求可考虑MyISAM。 - 字段类型优化:使用最精确的类型,如存储 IP 使用
INT而非VARCHAR。
- 选择合适的引擎:事务型应用首选
【延伸考点讲解】
- 执行计划 (EXPLAIN):这是性能优化的神器。通过
EXPLAIN查看 SQL 的执行路径,关注type(连接类型,ref/range优于ALL)和key(是否命中索引)。 - 慢查询日志 (Slow Query Log):开启慢查询日志记录执行时间超过阈值的 SQL,是定位系统性能瓶颈的首要步骤。
- 读写分离与分库分表:当单机性能达到上限时,可以通过主从复制实现读写分离,或者通过垂直/水平拆分(分库分表)来分散存储压力。
【问题】 有哪些数据库优化方面的经验?
【参考答案】 在实际项目开发中,数据库优化通常遵循“由易到难、由局部到整体”的原则:
- 语句级别:优先使用
PreparedStatement。它不仅能防止 SQL 注入,且数据库会对预编译语句进行缓存,在重复执行时性能更高。 - 设计级别:
- 慎用外键:外键约束会显著降低插入和删除的性能。在高性能互联网应用中,通常去掉数据库层面的外键,由程序逻辑保证数据完整性。
- 适当冗余:为了减少高频的
JOIN查询,可以适当违反范式,在表中增加冗余字段(如“回复数”、“最后更新时间”)。
- 操作选择:使用
UNION ALL代替UNION。如果业务能保证数据不重复且无需排序,UNION ALL不会进行去重和排序操作,执行效率远高于UNION。 - 事务控制:尽量缩短事务的生命周期,避免在事务中进行远程网络调用或耗时较长的业务逻辑,以减少行锁锁定时间。
【延伸考点讲解】
- 反范式化权衡:冗余字段虽然提高了查询速度,但增加了数据维护的复杂度(更新时需要同步更新多处)。
- 索引维护:索引并非越多越好。插入、删除、更新操作都需要维护索引。应定期清理长期未被使用的无效索引。
- 批量操作:在大量插入数据时,应使用批量插入(Batch Insert)而非循环单条插入,以减少与数据库的交互次数。
【问题】 一张表,里面有 ID 自增主键,当 insert 了 17 条记录之后,删除了第 15, 16, 17 条记录,再把 MySQL 重启,再 insert 一条记录,这条记录的 ID 是 18 还是 15 ?
【参考答案】 这个问题的答案取决于使用的 存储引擎 以及 MySQL 的版本:
- MyISAM 引擎:
- 结果:ID 是 18。
- 原理:MyISAM 会将自增主键的最大 ID 记录在数据文件(.MYI)中,重启后依然能从磁盘读取到该值。
- InnoDB 引擎:
- MySQL 5.7 及以前版本:ID 是 15。
- 原理:自增计数器(Auto-increment Counter)仅存储在内存中。重启后,InnoDB 会执行类似
SELECT MAX(id) FROM table FOR UPDATE的语句来重新初始化计数器。由于 15, 16, 17 已被删除,表中最大 ID 为 14,因此新插入的 ID 为 15。 - MySQL 8.0 及以后版本:ID 是 18。
- 原理:8.0 版本将自增计数器的变化记录在了重做日志(Redo Log)中,实现了持久化,重启后不会丢失。
【延伸考点讲解】
- 自增空洞:在任何版本中,如果事务回滚(Rollback)或者插入失败,已经消耗掉的自增 ID 都不会被回收,这会导致 ID 序列中出现“空洞”。
- AUTO_INCREMENT 初始化:可以通过
ALTER TABLE table_name AUTO_INCREMENT = N;手动设置下一个自增 ID 的起始值。 - 并发性能:InnoDB 使用专门的“自增锁”(AUTO-INC Locking)来保证并发插入时 ID 的唯一性,在大规模并发写入时,这可能成为一个微小的性能瓶颈。
【问题】 在 MySQL 中 ENUM 的用法是什么?
【参考答案】
ENUM 是 MySQL 中的一种字符串对象,允许在创建表时定义一组预定义的允许值。
- 基本语法:
col_name ENUM('value1', 'value2', 'value3') - 存储机制:内部使用整数(1, 2, 3…)来存储,每个值对应一个索引。这使得它比直接存储字符串更节省空间。
- 约束作用:插入的值必须是定义好的枚举成员之一(如果不符合,在非严格模式下存入空字符串,严格模式下报错)。
【延伸考点讲解】
- 性能优势:由于内部存储为整数,处理速度快且占用空间小(1 到 255 个成员占 1 字节,256 到 65535 个占 2 字节)。
- 主要缺点:
- 修改成本高:增加或删除枚举成员通常需要
ALTER TABLE,在海量数据表上非常耗时。 - 排序陷阱:默认按索引号(定义的顺序)排序,而不是按字母顺序。
- 修改成本高:增加或删除枚举成员通常需要
- 最佳实践:对于值极少变动且范围固定的字段(如性别
'male', 'female'),可以使用ENUM;对于变动频繁的业务维度,建议使用关联表或在应用层控制。
【问题】 CHAR 和 VARCHAR 的区别?
【参考答案】
CHAR 和 VARCHAR 是 MySQL 中最常用的两种字符串类型,它们的主要区别在于存储方式、长度限制和性能:
- 存储方式:
- CHAR:定长字符串。存储时,如果内容不足定义长度,会用空格填充。检索时,会自动删除尾部空格。
- VARCHAR:变长字符串。仅存储实际内容长度(外加 1-2 字节用于记录长度),不会填充空格。
- 长度限制:
- CHAR:最大长度为 255 字符。
- VARCHAR:最大长度理论上为 65535 字节(受行最大大小限制)。
- 性能表现:
- CHAR:由于是定长的,数据库引擎处理速度更快,不存在碎片问题。
- VARCHAR:由于是变长的,在更新时如果内容变长,可能导致行拆分(Row Split),产生碎片,性能略低。
【延伸考点讲解】
- 适用场景:
- CHAR:适用于长度非常固定的字段,如 MD5 摘要、身份证号、手机号、性别等。
- VARCHAR:适用于长度波动较大的字段,如评论、地址、个人简介等。
- 存储空间计算:
VARCHAR(N)在存储时,如果 $N \le 255$,需要额外 1 字节记录长度;如果 $N > 255$,需要 2 字节。 - 尾部空格处理:这是一个经典陷阱。
CHAR在检索时会丢弃尾部空格,而VARCHAR(在 MySQL 5.0.3 之后)会保留尾部空格。
【问题】 如果一个表有一列定义为 TIMESTAMP,将发生什么?
【参考答案】
TIMESTAMP 列具有自动初始化和自动更新的特性,具体行为取决于创建表时的定义:
- 自动更新:默认情况下,如果未显式指定值,第一个
TIMESTAMP列会在行被插入时设置为当前时间,并且在行数据发生更改时,自动更新为当前时间(ON UPDATE CURRENT_TIMESTAMP)。 - 存储范围:其范围是
'1970-01-01 00:00:01' UTC到'2038-01-19 03:14:07' UTC。 - 时区相关:存储时会从当前时区转换为 UTC,检索时再转换回当前时区。
【延伸考点讲解】
- 与 DATETIME 的区别:
DATETIME占用 8 字节(5.6 后 5 字节),范围更广(1000-9999年),且与时区无关;TIMESTAMP仅占 4 字节,空间效率更高,但受“2038年问题”限制。 - 显式控制:可以通过定义
DEFAULT CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP来精确控制初始化和更新行为。 - 2038年问题:由于
TIMESTAMP使用 32 位整数存储秒数,将在 2038 年溢出。对于需要存储远期时间的场景,建议使用DATETIME。
【问题】 列设置为 AUTO INCREMENT 时,如果在表中达到最大值,会发生什么情况?
【参考答案】
当自增列达到该数据类型所允许的最大值时,AUTO_INCREMENT 将无法继续递增。
- 后果:随后的插入操作将会失败,MySQL 会报错(通常是
Duplicate entry 'xxx' for key 'PRIMARY'),因为尝试插入的值已经存在。 - 解决方式:需要根据业务需求更改字段类型(例如从
INT改为BIGINT),或者清理旧数据并重置计数器。
【延伸考点讲解】
- 数据类型限制:
TINYINT UNSIGNED:最大 255INT UNSIGNED:最大 4,294,967,295(约 42 亿)BIGINT UNSIGNED:最大 $2^{64}-1$(几乎不可能达到溢出)
- 监控报警:在生产环境中,建议对核心表的自增主键使用率进行监控,当使用率达到 80% 时即触发报警。
- 主键设计:对于预期数据量巨大的表,建议在设计之初就直接使用
BIGINT作为主键,以规避未来可能出现的溢出风险和高昂的改表成本。
【问题】 怎样才能找出最后一次插入时分配了哪个自动增量?
【参考答案】
可以使用 MySQL 内置函数 LAST_INSERT_ID() 来获取最后一次插入操作生成的自增 ID。
- 基本用法:执行
SELECT LAST_INSERT_ID();即可返回最近一条INSERT语句产生的AUTO_INCREMENT值。 - 特点:该函数是 基于会话(Session) 的。这意味着它返回的是当前连接中最后一次产生的 ID,而不会受到其他并发连接插入操作的影响,因此是线程安全的。
【延伸考点讲解】
- 多行插入:如果在一条
INSERT语句中插入了多行数据,LAST_INSERT_ID()只会返回 第一行 产生的 ID。 - 应用场景:常用于父子表关联插入。先插入父表,获取产生的 ID,再将该 ID 作为外键插入子表。
- 与 MAX(id) 的区别:千万不要使用
SELECT MAX(id) FROM table来获取最新 ID。在高并发环境下,MAX(id)可能会获取到其他事务刚刚插入的 ID,导致逻辑错误。
【问题】 BLOB 和 TEXT 有什么区别?
【参考答案】
BLOB(Binary Large Object)和 TEXT 都是用于存储大量数据的类型,它们的主要区别在于对字符集和排序规则的处理:
- 数据性质:
- BLOB:存储二进制数据(如图片、视频、音频、可执行文件等)。它没有字符集的概念。
- TEXT:存储大文本数据(如文章内容、评论等)。它关联有字符集(如 utf8mb4)。
- 大小写敏感性:
- BLOB:在排序和比较时是 区分大小写 的(因为它被视为字节字符串)。
- TEXT:在排序和比较时通常是 不区分大小写 的(取决于所选字符集的 Collation)。
- 大小限制:两者都有四个变体(TINY, REGULAR, MEDIUM, LONG),最大存储容量相同(LONG 类型可达 4GB)。
【延伸考点讲解】
- 性能影响:由于
BLOB和TEXT数据通常非常大,MySQL 会将其存储在行之外(Off-page Storage)。在查询时,如果不需要这些字段,务必避免使用SELECT *,否则会产生大量的 I/O 开销。 - 索引限制:不能直接对完整的
BLOB或TEXT列建立索引,必须指定索引前缀长度(Prefix Indexing)。 - 临时表风险:包含
BLOB或TEXT的查询在排序时可能无法使用内存临时表,而被迫使用磁盘临时表,这会严重降低查询效率。
【问题】 MySQL 当记录不存在时 insert,当记录存在时 update,语句怎么写?
【参考答案】 在 MySQL 中,通常有两种主流方式来实现这种“存在即更新,不存在即插入”(Upsert)的逻辑:
- ON DUPLICATE KEY UPDATE(推荐):
- 语法:
INSERT INTO table (a, b, c) VALUES (1, 2, 3) ON DUPLICATE KEY UPDATE c = c + 1; - 原理:如果插入导致唯一索引(UNIQUE)或主键(PRIMARY KEY)冲突,则执行后面的
UPDATE逻辑。
- 语法:
- REPLACE INTO:
- 语法:
REPLACE INTO table (a, b, c) VALUES (1, 2, 3); - 原理:如果发现冲突,MySQL 会先 删除 旧记录,然后再 插入 新记录。
- 语法:
【延伸考点讲解】
- 两者的区别:
ON DUPLICATE KEY UPDATE是原地更新,保留原有记录的其他字段和自增 ID。REPLACE INTO是“删后插”,会导致自增 ID 发生变化,且如果表中存在外键约束或触发器,可能会引发非预期的问题。
- 性能对比:在高并发场景下,
ON DUPLICATE KEY UPDATE的性能通常优于REPLACE INTO,因为后者涉及两次操作(DELETE + INSERT)。 - INSERT IGNORE:如果只想在不存在时插入,存在时直接忽略(不报错也不更新),可以使用
INSERT IGNORE INTO ...。
锁机制
【问题】 MySQL 中有哪几种锁?
【参考答案】 MySQL 的锁机制主要可以从两个维度进行划分:存储引擎支持程度和锁定粒度。
- 按粒度划分:
- 表级锁 (Table Lock):锁定整张表。开销小,加锁快,不会出现死锁;但锁定粒度大,冲突概率最高,并发度最低(MyISAM 默认)。
- 行级锁 (Row Lock):锁定特定的数据行。开销大,加锁慢,会出现死锁;但锁定粒度最小,冲突概率低,并发度最高(InnoDB 默认)。
- 页级锁 (Page Lock):锁定数据页,粒度介于表锁和行锁之间(BDB 引擎支持)。
- 按类型划分(行锁/表锁内):
- 共享锁 (S 锁):允许事务读取一行数据,阻止其他事务获得相同数据集的排他锁。
- 排他锁 (X 锁):允许事务删除或更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。
- 意向锁 (IS/IX):表级锁,用于表示事务准备在行级别加锁。
【生动例子与内部逻辑】 为了理解这些锁的配合,我们可以使用 “图书馆办公楼” 的例子:
- 场景:假设图书馆有一栋办公楼(数据库),楼里有很多层(数据页),每层有很多房间(数据行)。
- 行锁与排他锁:某位老师想在 201 房间(行)闭关写书,他进去后反锁了门(加排他锁 X)。此时其他老师既不能进去看书,也不能进去写书。
- 意向锁 (IS/IX):这位老师在反锁 201 房间的同时,必须在二楼的电梯口立一个牌子:“本层有房间正在使用”(加意向排他锁 IX)。
- 表锁的冲突检查:此时,楼层管理员(系统事务)想要关闭整层楼进行电路检修(申请表级排他锁 X)。如果没有电梯口的牌子(意向锁),管理员必须推开二楼每一个房间的门去检查是否有人;有了牌子,管理员一眼就能看到本层有房间被锁定,从而直接等待,效率大幅提升。
【延伸考点讲解】
- 意向锁的逻辑核心:意向锁(IS/IX)是表级锁,它们存在的唯一目的就是为了在之后加表锁时能够快速判断表中的记录是否被行锁锁定,从而避免全表扫描。
- 锁的兼容性:
- 意向锁之间是互相兼容的(多个事务可以同时在不同行加锁)。
- 意向锁与表级 S/X 锁可能冲突(如 IX 锁与表级 S 锁冲突)。
- 行锁的实现原理:InnoDB 的行锁是通过给 索引上的索引项 加锁来实现的,而不是给真实的记录加锁。这意味着如果查询没有走索引,InnoDB 将会使用表锁(通过隐藏的聚集索引锁定所有行)。
- 死锁检测:InnoDB 会自动监测死锁,并通过回滚持有最少行级排他锁的事务来解除死锁。
【问题】 数据库怎样保证并发更新不出错?
【参考答案】 并发更新的核心挑战在于 “丢失更新(Lost Update)” 问题。解决该问题的常用方案包括:
- 悲观锁 (Pessimistic Locking):
- 逻辑:假设冲突一定会发生。在更新前先对行加锁(如
FOR UPDATE),直到事务提交。 - 效果:其他尝试更新该行的事务会被阻塞,直到当前事务释放锁。
- 逻辑:假设冲突一定会发生。在更新前先对行加锁(如
- 乐观锁 (Optimistic Locking):
- 逻辑:假设冲突很少发生。不使用数据库锁,而是在更新时检查数据版本(通常通过
version字段)。 - 实现:
UPDATE table SET balance = new_val, version = version + 1 WHERE id = ? AND version = {读取时的版本号}。
- 逻辑:假设冲突很少发生。不使用数据库锁,而是在更新时检查数据版本(通常通过
【生动例子与运行逻辑】 假设账户余额为 100,用户 A 和 B 同时发起扣款操作:
- 悲观锁模式:
- A 开启事务并执行
SELECT balance FROM account WHERE id=1 FOR UPDATE,锁定了该行。 - B 此时尝试执行同样的语句,会被数据库挂起等待。
- A 扣除 50 余额变为 50,提交事务。
- B 被唤醒,读取到最新的余额 50,再扣除 30 变为 20,提交事务。最终余额 20,数据正确。
- A 开启事务并执行
- 乐观锁模式:
- A 和 B 同时读取到余额 100 和版本号 1。
- A 先执行更新,
WHERE version = 1匹配成功,余额变 50,版本号变 2。 - B 尝试执行更新,
WHERE version = 1匹配失败(此时已是 2),受影响行数为 0。 - B 需要根据业务逻辑进行重试(重新读取最新余额 50,版本 2,再尝试更新)。
【延伸考点讲解】
- 适用场景:
- 悲观锁:适用于写操作极度频繁、冲突概率高的场景,避免了大量乐观锁重试带来的性能开销。
- 乐观锁:适用于读多写少、冲突概率低的场景,因不加锁而具有更高的吞吐量。
- CAS 的 ABA 问题:在乐观锁中,如果版本号仅基于业务值,可能出现值先变 A 再变 B 再变回 A 的情况。引入单调递增的
version字段可完美规避此问题。 - 死锁风险:悲观锁在高并发多表操作下可能导致死锁;乐观锁本质上是无锁方案,不存在死锁风险。
【问题】 对比一下悲观锁和乐观锁?
【参考答案】 悲观锁和乐观锁是并发控制中两种截然不同的策略,它们并非真实的数据库锁,而是设计思想:
- 悲观锁 (Pessimistic Locking):
- 核心思想:假定数据每次读取都会被他人修改。
- 实现方式:依靠数据库提供的锁机制(如
FOR UPDATE)。 - 适用场景:写操作密集、冲突频繁、追求数据绝对安全的场景。
- 乐观锁 (Optimistic Locking):
- 核心思想:假定数据在读取到更新期间通常不会被修改。
- 实现方式:在应用层通过版本号(Version)或 CAS 机制实现。
- 适用场景:读多写少、并发量大、对响应时间要求高的场景。
【生动例子与内部逻辑】 我们可以用 “图书馆借书” 的场景来类比:
- 悲观锁模式(老式闭架借阅):
读者想看某本书,必须先去前台申请,管理员将书从书架取出并登记该书“已被借走”。此时其他任何人都无法看到或借阅这本书,直到该读者归还。
- 逻辑:加锁 -> 操作 -> 释放锁。这种方式虽然安全,但如果读者看书太慢,书架的利用率就很低。
- 乐观锁模式(现代开架借阅):
书架上的书谁都可以拿去翻看。每个读者的借书证上记录了该书的版本(如第 3 版)。当读者去前台办理借阅时,管理员会检查:该书在书架上的版本是否依然是第 3 版?
- 逻辑:如果是,说明期间没人修改过,借阅成功,版本更新为 4。如果书架上已经是第 4 版了(说明被别人先借走并还回来了),管理员会告知你借阅失败,请重新拿新版。
【延伸考点讲解】
- 性能权衡:
- 悲观锁:由于需要排队,会产生大量的锁等待和上下文切换开销。
- 乐观锁:省去了锁的申请和释放过程,但在高冲突环境下,频繁的重试(自旋)会消耗大量 CPU 资源。
- 死锁风险:悲观锁可能导致事务互相等待产生死锁;乐观锁由于不加锁,不存在死锁。
- ABA 问题:在乐观锁中,如果版本号定义不当,可能出现数据被修改后又改回原值的情况。引入单调递增的数字
version是解决 ABA 问题的标准做法。
事务
【问题】 什么是 MySQL 的 redo log 和 binlog?
【参考答案】 MySQL 包含两类核心日志,分别由 Server 层和存储引擎层维护:
- binlog(归档日志):
- 所属层:Server 层,所有引擎通用。
- 性质:逻辑日志,记录 SQL 语句的原始逻辑(如“给 ID=2 的行 c 字段加 1”)。
- 写入方式:追加写,不会覆盖旧日志。
- 作用:主从复制、数据恢复。
- redo log(重做日志):
- 所属层:InnoDB 引擎层特有。
- 性质:物理日志,记录物理页的变更(如“在某个数据页的某个偏移量处做了什么修改”)。
- 写入方式:循环写,空间固定,写满后会覆盖开头。
- 作用:崩溃恢复(Crash-safe),保证事务的持久性。
【生动例子与内部逻辑】 我们可以用 “掌柜记账” 的例子来理解:
- 场景:古代酒店掌柜有一个账本(磁盘数据文件),还有一个粉板(redo log)。
- redo log 的逻辑(WAL 机制):当客人来赊账时,如果直接翻开厚重的账本查找到该客人再修改,效率极低(随机 I/O)。掌柜会先在粉板上记下这笔账(顺序 I/O),等打烊后再同步到账本。即使酒店突然停电(数据库宕机),掌柜只要看一眼粉板,就能恢复账本中还没记上的账。这就是 WAL (Write-Ahead Logging)。
- binlog 的逻辑:binlog 就像是酒店的流水单据。即使粉板擦了、账本丢了,只要流水单据还在,就能从头开始算出现在的账目(数据恢复)。
- 两阶段提交 (2PC):为了保证“粉板”和“流水单”一致,掌柜在记账时分为两步:
- 先在粉板记下账目,标记为“准备好了”(Prepare)。
- 写流水单据(binlog 写入)。
- 在粉板上把状态改为“已完成”(Commit)。
【深度技术解析】
- redo log 的循环结构:
- redo log 由固定大小的文件组成(如 4 个 1GB 文件)。
- write pos 是当前记录的位置,一边写一边后移。
- checkpoint 是当前要擦除的位置(即已同步到磁盘的位置)。
- 如果
write pos追上了checkpoint,说明 redo log 已满,MySQL 会停止所有更新操作,先推动checkpoint刷盘。
- binlog 的三种格式:
- STATEMENT:记录原始 SQL。优点是日志量小,缺点是在使用
UUID()、NOW()等函数时可能导致主从数据不一致。 - ROW(推荐):记录行的实际变更。优点是数据绝对安全,缺点是日志量巨大(如一条
UPDATE影响万行,会记录万条变更)。 - MIXED:混合模式。普通 SQL 用 STATEMENT,可能导致不一致的 SQL 自动转为 ROW。
- STATEMENT:记录原始 SQL。优点是日志量小,缺点是在使用
- 2PC 崩溃恢复细节:
- 如果在 Prepare 之后、Commit 之前发生宕机:
- 扫描 redo log。如果发现事务处于
Prepare状态,则去查看 binlog 中是否存在对应的XID。 - binlog 存在且完整:提交事务。因为 binlog 已写入,不提交会导致主从不一致。
- binlog 不存在:回滚事务。因为该事务尚未真正完成。
- 扫描 redo log。如果发现事务处于
- 如果在 Prepare 之后、Commit 之前发生宕机:
【高阶面试深度补充】
- 组提交 (Group Commit):
- 问题:每次事务提交都要刷盘(fsync),会导致磁盘 I/O 成为瓶颈。
- 优化:MySQL 会将多个并发事务的日志写入操作合并为一次 fsync,从而极大提高 TPS。
- 双写缓冲 (Doublewrite Buffer):
- 问题:如果数据库宕机时,InnoDB 正在写一个 16KB 的数据页,只写了 4KB 停电了(页断裂/Partial Page Write),此时 redo log 无法修复(因为它记录的是物理修改而非完整页)。
- 解决:在写数据页之前,先将页副本顺序写入系统表空间的双写缓冲区。宕机恢复时,如果数据页损坏,先从双写缓冲区还原页,再应用 redo log。
- Change Buffer 与 redo log 的关系:
- 当更新非聚集索引且数据页不在内存时,InnoDB 会将修改记录在
Change Buffer中,并同步记入redo log。 - 这样即使不随机读磁盘(将数据页读入内存),也能保证修改的持久化。
- 当更新非聚集索引且数据页不在内存时,InnoDB 会将修改记录在
- 日志刷盘的具体性能损耗:
- 磁盘 I/O 是数据库最慢的部分。
sync_binlog=1和innodb_flush_log_at_trx_commit=1的组合被称为 “双 1 配置”,是保证数据绝对不丢失的最高安全级别,但会对性能产生 20%~50% 的损耗。
- 磁盘 I/O 是数据库最慢的部分。
【延伸考点讲解】
- sync_binlog 参数:控制 binlog 刷盘频率。设置为 1 表示每次事务提交都刷盘,最安全。
- innodb_flush_log_at_trx_commit 参数:控制 redo log 刷盘策略。设置为 1 表示每次提交都持久化到磁盘。
- 为什么不能只用 binlog 恢复?:binlog 是逻辑日志,它不具备“脏页检查”的能力。当数据库宕机时,binlog 无法知道哪些数据已经写入磁盘,哪些还在内存。而 redo log 记录了物理修改,且通过
checkpoint明确知道哪些修改还没落盘,因此只有 redo log 能实现 Crash-safe。
【问题】 MySQL 怎么保证原子性的?怎么保证事务的 ACID?
【参考答案】 InnoDB 引擎通过日志(redo/undo log)、锁机制以及 MVCC 共同保证了事务的 ACID 特性:
- 原子性 (Atomicity):由 undo log 保证。记录了每步操作的反向操作(如插入对应删除),当事务失败时利用 undo log 将数据回滚到初始状态。
- 一致性 (Consistency):是事务追求的终极目标。通过原子性、持久性和隔离性共同保障,确保数据库从一个合法的状态转变到另一个合法的状态。
- 隔离性 (Isolation):由 锁机制 和 MVCC(多版本并发控制)保证。确保并发执行的事务之间互不干扰。
- 持久性 (Durability):由 redo log 保证。修改操作先写入 redo log 并刷盘,即使数据库宕机,重启后也能根据 redo log 恢复未落盘的数据。
【生动例子与内部逻辑】 以 “银行转账” 为例(A 转账 100 元给 B):
- 原子性保证:如果在 A 扣钱成功、B 加钱失败时发生错误,MySQL 会查找 undo log。undo log 中记录了“给 A 账号加回 100 元”的操作,系统自动执行回滚,保证转账要么全成功,要么全失败。
- 持久性保证:A 扣钱的操作一旦提交,系统会立即将该变更记录在 redo log 并强制刷盘。就算此时银行机房突然停电,由于 redo log 已经在磁盘上,电力恢复后系统能自动根据日志把 A 扣钱的变更同步到账本文件中。
- 隔离性保证:在 A 转账期间,如果 C 想查询 A 的余额,MVCC 会让 C 看到转账前的“快照”版本,而不是转账中途的中间状态。
【延伸考点讲解】
- Force Log at Commit:为了保证持久性,InnoDB 要求在事务提交前,其产生的 redo log 必须已经落盘(fsync),这被称为“提交时强制日志刷新”。
- undo log 的清理:undo log 不会立即删除,它不仅用于回滚,还用于 MVCC 读快照。只有当系统中没有事务再需要该版本数据时,后台的
Purge线程才会将其清理。 - 一致性的双重含义:一致性不仅指数据库内部的物理一致性(如 B+ 树结构完整),更指业务逻辑上的一致性(如转账前后总金额不变)。
【问题】 什么是 undo log 和 MVCC?
【参考答案】
undo log(回滚日志)和 MVCC(多版本并发控制)是 InnoDB 引擎实现事务隔离级别(尤其是 RC 和 RR)的核心底层技术:
- undo log:物理上是存储在回滚段中的一系列日志,逻辑上记录了数据行的所有历史快照。每当数据发生修改,旧版本就会存入 undo log 并通过隐藏的
DATA_ROLL_PTR指针串联成一个 版本链。 - MVCC:一种非锁定读的实现方案。它通过读取版本链中符合可见性规则的版本,使读操作不被写操作阻塞。
- ReadView:决定“当前事务能看到版本链中的哪个版本”。它包含四个核心属性:
m_ids:生成 ReadView 时,当前系统中活跃且未提交的事务 ID 列表。min_trx_id:m_ids中的最小值。max_trx_id:系统即将分配给下一个事务的 ID(即当前最大事务 ID + 1)。creator_trx_id:创建该 ReadView 的事务 ID。
【生动例子与内部逻辑】 想象一个 “公文修改” 的场景:
- 版本链:公文(数据行)正在被修改。每次修改前,旧版都会存入存档柜(undo log),新公文注明“上个版本在柜子几号”。
- MVCC 判定规则:
- 规则 1:如果被访版本的
trx_id<min_trx_id:说明该版本在 ReadView 生成前已提交,可见。 - 规则 2:如果
trx_id>=max_trx_id:说明该版本在 ReadView 生成后才开启,属于未来的版本,不可见。 - 规则 3:如果
min_trx_id<=trx_id<max_trx_id:- 若
trx_id在m_ids列表中:说明该版本所属事务仍活跃,不可见。 - 若
trx_id不在m_ids列表中:说明事务已提交,可见。
- 若
- 规则 1:如果被访版本的
- 隔离级别的差异:
- RC(读已提交):事务中每次 SELECT 都会生成一个全新的 ReadView,因此能读到其他事务中途提交的数据。
- RR(可重复读):事务中仅在第一次 SELECT 时生成一个 ReadView,后续查询共用此视图,从而保证了可重复读。
【延伸考点讲解】
- 隐藏字段:每行记录包含
DATA_TRX_ID(最后修改事务 ID)和DATA_ROLL_PTR(指向 undo log)。 - 快照读 vs 当前读:
- 普通
SELECT是 快照读,不加锁,依靠 MVCC。 SELECT ... FOR UPDATE、UPDATE、DELETE等是 当前读,必须读取最新版本并加锁(行锁、间隙锁)。
- 普通
- undo log 的分类:
- insert undo log:仅用于事务回滚,事务提交后即可删除。
- update undo log:用于回滚和 MVCC,需等到没有 ReadView 再引用时,由 Purge 线程清理。
索引
【问题】 请简述MySQL常用的索引结构和索引类型有哪些种类?内部实现是怎样的?
【参考答案】 MySQL中索引是用于加速数据查询的数据结构,其核心作用类似于书籍的目录,能极大减少数据库需要扫描的数据量。MySQL支持多种索引结构,最常用的是B+树索引和哈希索引,此外还有全文索引、空间索引等。而索引类型则从逻辑角度划分,如主键索引、唯一索引、普通索引、全文索引、组合索引等。
一、常用的索引结构
- B+树索引
- 结构描述:B+树是一种平衡多路查找树,所有数据都存储在叶子节点,并且叶子节点之间通过双向链表连接,形成有序结构。非叶子节点只存储键值索引和指向子节点的指针。
- 内部实现:
- 每个节点对应一个磁盘页(默认16KB),通过页内二分查找快速定位。
- 插入和删除操作会触发节点的分裂或合并,以维持树的平衡。
- 叶子节点有序且链表相连,使得范围查询非常高效(只需遍历链表)。
- 适用场景:全值匹配、范围查询、排序、分组等。是InnoDB和MyISAM存储引擎的默认索引结构。
- 哈希索引
- 结构描述:基于哈希表实现,通过哈希函数将索引列的值映射到对应的槽位,快速定位数据行。
- 内部实现:
- 采用链地址法处理哈希冲突。
- 由于哈希表无序,无法用于范围查询和排序。
- 适用场景:仅支持等值查询(如
=、IN),且查询速度极快(O(1))。Memory引擎默认使用哈希索引,InnoDB支持自适应哈希索引(自动为热点页建立哈希索引,但不可人为干预)。
- 全文索引
- 结构描述:用于对文本内容进行关键词搜索,基于倒排索引实现。
- 内部实现:将文本分词后,记录每个词出现的位置和文档ID。
- 适用场景:
MATCH ... AGAINST语句,适合大文本字段的搜索,如文章内容。MyISAM和InnoDB(5.6+)均支持。
- 空间索引(R-Tree)
- 结构描述:用于地理空间数据类型,基于R树实现。
- 适用场景:GIS相关查询,如
ST_Distance等。MyISAM和InnoDB支持,但使用较少。
二、常用的索引类型(按逻辑划分)
- 主键索引(PRIMARY KEY):一种特殊的唯一索引,不允许空值。每个表只能有一个主键索引,InnoDB中主键即聚簇索引,直接存储行数据。
- 唯一索引(UNIQUE):索引列的值必须唯一,允许空值(但空值可重复,取决于数据库实现)。保证数据唯一性。
- 普通索引(INDEX):最基本的索引,没有任何限制,仅用于加速查询。
- 全文索引(FULLTEXT):用于全文搜索,如前所述。
- 组合索引(Composite Index):基于多个列的索引,遵循最左前缀原则。例如
(a,b,c)索引,可加速a、(a,b)、(a,b,c)的查询。
三、不同存储引擎的实现差异
- InnoDB:
- 索引即数据,聚簇索引(主键)的叶子节点存储整行数据,二级索引叶子节点存储主键值(因此回表需通过主键查找)。
- 支持自适应哈希索引(AHI),自动为频繁访问的索引页建立哈希索引以加速等值查询。
- 全文索引基于倒排表,支持中文分词(需插件)。
- MyISAM:
- 索引和数据分离,索引叶子节点存储数据行的物理地址(指针)。
- 不支持事务,但索引压缩特性在某些场景更省空间。
- Memory:
- 默认哈希索引,也可选择B+树索引,但数据易失。
【大白话解释于举例说明】
- B+树索引:就像图书馆的分类卡片柜,每个抽屉(节点)里放着卡片(键值),卡片上写着书名和书的位置。要找“Java编程思想”,先按首字母找抽屉,再按书名精确找卡片,最后按卡片指示去书架上拿书(数据)。要找“Java”开头的所有书,只需沿着卡片链一路找下去。
- 哈希索引:好比字典后面的偏旁部首表,直接告诉你某个字在第几页,非常快,但没法找“水”字旁的所有字(范围查询)。
- 全文索引:就像搜索引擎的倒排表,你搜“MySQL”,它告诉你哪些文档里有这个词。
【扩展知识点详解】
- B+树与B树的区别:B+树非叶子节点不存数据,能容纳更多键,树更矮,磁盘I/O更少;叶子节点链表便于范围扫描。
- 聚簇索引与二级索引:InnoDB中,数据行存储在聚簇索引中,二级索引需回表;覆盖索引可避免回表。
- 索引下推(ICP):将部分条件从Server层下推到存储引擎层,减少回表次数。
- 索引合并:多个索引同时使用,对结果集合并,但不如联合索引高效。
- 索引选择性:区分度高的列适合做索引,如唯一ID,而性别字段选择性差,索引效果不佳。
- 最左前缀原则:联合索引
(a,b,c)可匹配a、(a,b)、(a,b,c),但跳过中间列会导致部分失效。 - 索引优化建议:高频查询建索引、避免冗余索引、控制索引数量(影响写性能)、使用覆盖索引。
【问题】 MySQL建立索引的优势、影响与原则是什么?
【参考答案】 索引是数据库系统中用于加速数据查询的数据结构,合理使用索引能极大提升查询性能,但也存在一些负面影响。以下是索引的优势、影响和设计原则的详细说明。
一、索引的优势
- 加速数据检索:索引使数据库可以快速定位到满足条件的行,避免全表扫描,尤其对于大表效果显著。
- 保证数据的唯一性:通过唯一索引可以确保表中某列或多列的组合值唯一。
- 加速排序和分组:索引中数据已排序,能显著提高
ORDER BY和GROUP BY操作的效率。 - 使用覆盖索引避免回表:如果索引包含了查询所需的所有列,则无需回表读取完整行,减少I/O操作。
- 优化连接查询:在多表连接时,索引可以加速连接条件的匹配,提升
JOIN性能。 - 减少磁盘I/O:索引通常比数据行小,扫描索引比扫描全表需要的I/O更少。
- 支持唯一约束和主键:索引是实现主键和唯一约束的基础。
二、索引的影响(缺点)
- 占用额外存储空间:索引需要占用磁盘空间,如果索引过多,可能消耗大量存储。
- 降低写操作性能:当对表进行
INSERT、UPDATE、DELETE操作时,除了修改数据,还需要同步更新所有相关索引,导致写操作变慢。 - 增加维护成本:索引需要定期维护(如重建),且在数据量变化时可能产生碎片。
- 可能导致优化器选择错误:如果索引设计不合理,优化器可能选择低效的索引,反而降低性能。
- 创建索引本身耗时:在大表上创建索引可能需要较长时间,影响业务。
三、索引设计原则
- 选择性高的列优先:列中不同值的比例越高,索引效果越好。例如主键、唯一ID等。
- 频繁作为查询条件的列:在
WHERE、JOIN、ORDER BY、GROUP BY中经常出现的列应考虑建立索引。 - 使用联合索引时遵循最左前缀原则:联合索引
(a,b,c)可以支持a、(a,b)、(a,b,c)的查询,但跳过中间列会导致部分失效。 - 避免冗余索引:例如已有索引
(a,b),再建索引(a)就是冗余,因为前者可以覆盖后者。 - 控制索引数量:索引不是越多越好,一般单表建议不超过5-6个,平衡查询和写入性能。
- 小表可不建索引:对于记录很少的表,全表扫描可能比使用索引更快。
- 考虑前缀索引:对于很长的字符串列(如
VARCHAR(255)),可以使用前缀索引(如INDEX(name(10)))节省空间,但需权衡选择性。 - 利用覆盖索引:尽量让索引包含查询的所有列,避免回表。
- 索引列不宜参与计算:对索引列使用函数或表达式会导致索引失效,应避免。
- 主键尽量短小:InnoDB中主键是聚簇索引,过长的主键会使二级索引占用更多空间。
- 根据排序需求调整索引顺序:如果查询经常需要对某列排序,可将其放在联合索引的末尾(因为排序利用索引顺序)。
- 考虑数据分布:对于重复值很多的列(如性别),索引效果差,通常不建索引。
【大白话解释于举例说明】
- 优势:索引就像书的目录,让你直接翻到想看的那页,而不是一页页翻(全表扫描)。同时,目录也帮你按拼音排序,找同类词更快(排序和分组)。
- 影响:但目录本身也占书的页数(存储空间),每次书内容修改(增删改)都需要更新目录,所以写书变慢了。
- 原则:
- 给经常查找的词语建目录(频繁查询列)。
- 如果目录太长,只取前几个字建索引(前缀索引)。
- 一本书的目录不能太多(控制索引数量),否则找目录也费劲。
- 如果书很薄,干脆不要目录(小表不建索引)。
- 联合索引像多级目录:先按姓氏,再按名字,所以不能跳过姓氏直接查名字(最左前缀)。
【扩展知识点详解】
- 索引的底层实现:InnoDB使用B+树,叶子节点存储数据(聚簇索引)或主键值(二级索引)。理解B+树结构有助于优化索引设计。
- 索引选择性计算:选择性 = 列中不同值的数量 / 总行数。选择性越高,索引越有效。
- 三星索引概念:指索引满足三个条件:查询相关的列都在索引中(覆盖)、索引顺序与查询条件一致、索引排序与
ORDER BY一致,达到最优性能。 - 索引下推(ICP):将部分查询条件下推到存储引擎层,减少回表次数。
- 索引合并:MySQL在某些情况下会使用多个索引合并结果,但不如联合索引高效。
- MRR优化:Multi-Range Read,将随机回表改为顺序读,提升I/O效率。
- 索引碎片:频繁的增删改会导致索引碎片,可通过
OPTIMIZE TABLE或重建索引解决。 - 不可见索引:MySQL 8.0支持不可见索引,用于测试新索引效果而不影响实际查询。
- 函数索引:MySQL 8.0支持在表达式上建立索引,解决对列使用函数导致索引失效的问题。
- 索引监控:使用
SHOW INDEX FROM table查看索引信息,通过慢查询日志分析未使用索引的查询。
【问题】 MySQL中hash索引的底层数据结构是怎样的?它是怎么工作的?
【参考答案】 MySQL中的哈希索引主要基于哈希表(Hash Table)实现,是一种以键-值(key-value)方式存储的数据结构,通过哈希函数将索引列的值映射到特定的槽位(bucket)中,以实现快速等值查找。在MySQL中,哈希索引主要用于Memory存储引擎(显式创建)以及InnoDB存储引擎的自适应哈希索引(内部自动使用)。下面以Memory引擎的哈希索引为例详细说明。
一、底层数据结构 哈希索引的底层是一个数组,数组的每个元素称为一个哈希桶(bucket),每个桶指向一个链表的头部。当多个不同的键值经过哈希函数计算后得到相同的哈希码(即哈希冲突)时,这些键值会被存储在同一个桶对应的链表中。这种结构称为拉链法(或链地址法)解决冲突。
- 哈希函数:将输入的键(如索引列的值)转换为一个整数哈希码,然后通过取模运算(或其他映射)得到数组的索引位置。Memory引擎使用的哈希函数通常是对键值进行某种运算(如MySQL内置的哈希函数),力求分布均匀。
- 链表节点:每个节点存储了键值、指向实际数据行的指针(或主键值)以及指向下一个节点的指针。对于Memory引擎,由于数据本身存储在内存中,索引节点可以直接指向数据行的内存地址。
二、工作原理
- 插入操作
- 计算插入键的哈希值,通过哈希函数定位到对应的哈希桶。
- 检查该桶对应的链表中是否已存在相同键(避免重复,取决于索引是否唯一)。
- 将新的键值对(包含指向数据行的指针)插入到链表的头部或尾部(具体取决于实现,通常为头部以提高最近访问效率)。
- 如果链表过长,可能会影响查询性能,但哈希表通常通过调整数组大小(rehash)来保持负载因子在合理范围。Memory引擎的哈希索引在创建时固定了桶的数量(可通过
HASH_KEY_BUCKETS参数控制,但实际可能动态调整?Memory引擎的表在创建时指定MAX_ROWS等会影响桶数,但一般是静态的)。
- 查询操作(等值查询)
- 计算查询键的哈希值,定位哈希桶。
- 遍历该桶对应的链表,逐个比较键值,直到找到匹配的键或链表结束。
- 如果找到,则通过节点中存储的指针获取实际数据行;如果未找到,返回空。
- 时间复杂度理想情况下为O(1),最坏情况下(所有键映射到同一桶)退化为O(n)。
- 删除操作
- 定位哈希桶,在链表中找到对应节点,将其删除并调整链表指针。
三、哈希索引的特点
- 仅支持等值查询:包括
=、IN、<=>(安全等于),不支持范围查询(如<、>、BETWEEN)。 - 查询速度极快:理想情况下一次哈希计算即可定位,不需要像B+树那样进行多次I/O。
- 无法用于排序:因为哈希表中的数据不是按顺序存储的,所以无法用于
ORDER BY操作。 - 无法利用部分索引列:对于联合索引,哈希索引会使用所有索引列计算哈希值,不能只使用前缀列。例如,联合索引
(a,b),查询仅涉及a时无法使用哈希索引。 - 存储结构紧凑:哈希索引通常比B+树索引占用更少空间,但取决于哈希函数和负载因子。
四、哈希索引与B+树索引的对比
| 特性 | 哈希索引 | B+树索引 |
|---|---|---|
| 查询类型 | 等值查询 | 等值、范围、排序、分组 |
| 查询速度 | O(1) 理想 | O(log n) 稳定 |
| 索引列使用 | 必须所有列等值 | 支持最左前缀 |
| 排序支持 | 不支持 | 支持 |
| 冲突处理 | 链表或开放地址 | 树结构调整 |
| 适用引擎 | Memory(显式)、InnoDB(自适应) | InnoDB、MyISAM等 |
五、InnoDB的自适应哈希索引(AHI)
InnoDB存储引擎内部维护了一个自适应哈希索引,它不是由用户创建的,而是InnoDB根据数据访问模式自动为频繁访问的索引页建立的哈希索引。目的是加速等值查询,减少B+树查找的路径。AHI使用索引键的前缀(如(space_id, page_no))构建哈希表,只针对热点页生效,对用户透明。
六、哈希索引的适用场景
- 适用于等值查询非常频繁且数据量可预估的场景,如缓存表、字典表。
- 在Memory引擎中,适合存储临时结果、中间数据。
- 不适合需要范围查询、排序或模糊匹配的业务。
【大白话解释于举例说明】 哈希索引就像一本新华字典的“拼音音节索引”,但只告诉你某个音节对应的字在哪一页。比如你想查“红”字,先按拼音“hong”找到对应的页码,然后直接翻到那一页(O(1))。但如果你想找所有拼音以“h”开头的字,哈希索引就无能为力了,因为那些字可能散落在各个页码,没有顺序。而B+树索引就像按笔画排序的目录,可以快速定位某个字,也可以找所有相同笔画的字(范围查询)。
在MySQL的Memory引擎里,哈希索引就像一张巨大的电话簿,每个姓名(键)通过算法计算出一个号码,然后放在对应编号的抽屉里。如果两个人算出的号码相同(冲突),就在同一个抽屉里用小纸条(链表)串起来。要找一个人,只需要计算号码,打开抽屉,顺着小纸条找。
【扩展知识点详解】
- Memory引擎的哈希索引参数:在创建表时可以指定
USING HASH来显式使用哈希索引,如CREATE TABLE ... INDEX idx USING HASH (col)。但Memory引擎也支持B+树索引(USING BTREE),默认是哈希索引。 - 哈希冲突的影响:当链表过长时,查询会退化为线性查找,可通过调整哈希函数或增加桶数量(rehash)来优化。Memory引擎在表创建时通过
MAX_ROWS估算桶数量,但不支持动态rehash,因此需合理预估数据量。 - 自适应哈希索引的监控:可通过
SHOW ENGINE INNODB STATUS查看AHI的使用情况,包括命中率等。 - 哈希索引的限制:在MySQL中,除了Memory引擎,NDB Cluster引擎也支持哈希索引。但InnoDB的哈希索引仅限内部自适应,用户无法直接创建。
- 哈希索引与唯一约束:唯一哈希索引可以保证键的唯一性,但冲突检查仍需遍历链表。
- 性能考量:哈希索引的查询性能与哈希函数均匀性、负载因子、链表长度相关。设计良好的哈希索引在等值查询上优于B+树,但写操作(插入/删除)可能因哈希冲突而变慢(需维护链表)。
- 与其他数据库的对比:例如PostgreSQL的哈希索引经过优化,支持WAL日志和崩溃恢复,而MySQL Memory引擎的哈希索引是非持久化的,数据易失。
- 使用建议:在需要高速缓存、会话级临时表等场景,可使用Memory引擎和哈希索引。对于持久化数据,应优先考虑InnoDB的B+树索引。
【问题】 讲一下你对MySQL中B 树 / B+ 树索引的了解,底层数据结构是怎样的?工作原理是什么?有什么优势?适用场景是什么?
【参考答案】 MySQL中的索引主要基于B+树(B-Tree的变种)实现,尤其是InnoDB存储引擎。B+树是一种平衡多路查找树,专为磁盘存储优化,能够高效支持等值查询、范围查询、排序和分组等操作。以下从底层数据结构、工作原理、优势及适用场景等方面详细阐述。
一、底层数据结构 B+树是一种多级索引结构,由根节点、内部节点(非叶子节点)和叶子节点组成。其核心特点如下:
- 节点:每个节点对应一个磁盘页(InnoDB默认16KB),节点内部包含多个键值(key)和指针(pointer)。
- 内部节点:仅存储键值和指向子节点的指针,不存储实际数据。这些键值用于引导搜索路径。
- 叶子节点:存储实际的数据行(对于聚簇索引)或主键值(对于二级索引)。所有叶子节点通过双向链表连接,形成有序结构,便于范围扫描。
- 平衡性:树始终保持平衡,所有叶子节点在同一层,从根到叶子的路径长度相同。
在InnoDB中,聚簇索引(主键索引)的叶子节点直接存储整行数据;二级索引的叶子节点存储索引列的值和对应的主键值,回表需通过主键查询聚簇索引。
二、工作原理
- 查找过程:从根节点开始,通过二分查找定位到键值所在的指针范围,逐层向下,直到到达叶子节点。在叶子节点中,进一步查找具体的键值,如果找到则获取对应的数据或主键。
- 范围查询:由于叶子节点通过链表有序连接,当需要查找某个范围内的数据时,先找到范围起始点,然后沿着链表顺序遍历直到结束,无需回溯树结构。
- 插入与删除:插入新键时,会先定位到对应的叶子节点,如果节点未满则直接插入;否则进行节点分裂,将中间键提升到父节点,并可能递归分裂。删除操作类似,可能导致节点合并。
- 维护平衡:通过分裂、合并等操作确保树的高度始终稳定(通常为2-4层),从而保证查询性能的稳定性。
三、B+树的优势
- 磁盘I/O优化:每个节点大小与磁盘页对齐,一次I/O可读取整个节点。树的高度较低(通常2-4层),意味着查找数据只需少量I/O操作,远少于全表扫描。
- 支持高效范围查询:叶子节点的链表结构使得范围扫描只需顺序读取,无需多次遍历树。
- 数据有序存储:索引天然有序,能够加速
ORDER BY和GROUP BY操作,避免文件排序。 - 高扇出性:内部节点不存储数据,仅存键和指针,因此每个节点能容纳更多键,降低树的高度。
- 稳定性能:所有查询(包括等值和范围)的时间复杂度均为O(log n),不会因数据分布不均而波动。
- 支持覆盖索引:如果查询的列全部在索引中(二级索引),则无需回表,进一步提升性能。
四、适用场景 B+树索引适用于以下场景:
- 全值匹配查询:如
WHERE id = 123。 - 范围查询:如
WHERE age BETWEEN 20 AND 30、WHERE name LIKE 'abc%'。 - 排序和分组:
ORDER BY、GROUP BY可以利用索引的顺序。 - 连接查询:在多表
JOIN时,连接列上的索引能加速匹配。 - 覆盖索引:查询字段全部包含在索引中时,直接使用索引返回结果。
- 唯一性约束:主键索引和唯一索引保证数据唯一性。
【大白话解释于举例说明】
- 底层数据结构:想象一本新华字典的“部首检字表”。根节点就像字典的“部首目录”,告诉你某个部首在哪一页;内部节点就像每一页上的小索引,指引你进一步查找;叶子节点就像最终的词条页,上面写着字的解释(数据)。所有词条页按拼音顺序排列,并相互链接,方便你查找相邻的字(范围查询)。
- 工作原理:你想查“张”字,先看“部首目录”找到“弓”字部在第几页,然后翻到那一页,在“弓”部列表中找到“张”对应的页码,最后翻到该页看到“张”的解释。每一步都像在树中向下走一层。
- 优势:因为目录(内部节点)只存部首和页码,很薄,所以翻得快;而词条页(叶子节点)按顺序排,要找“张”到“章”之间的字,只需顺着页边找,不用来回翻。
- 适用场景:适合精确查找(比如查某个字),也适合找所有同部首的字(范围查询),还能按拼音排序(比如给字表排序)。
【扩展知识点详解】
- B树与B+树的区别:
- B树的每个节点都存储数据,导致内部节点空间占用大,扇出低,树更高。
- B+树只有叶子节点存数据,内部节点仅存键,扇出高,树更矮;且叶子节点链表便于范围扫描。
- InnoDB中索引的实现:
- 聚簇索引:主键索引即聚簇索引,叶子节点存整行数据,表数据按主键顺序物理存储。
- 二级索引:非主键索引,叶子节点存索引列和主键值,查询时需回表(除非覆盖索引)。
- 自适应哈希索引:InnoDB会为频繁访问的索引页建立哈希索引,加速等值查询。
- B+树的层高计算:假设一行数据1KB,一个16KB页可存约15行,每个键值对占用几十字节,内部节点可存几百个键。对于2千万行的表,树高通常为3层,查询只需3次I/O。
- 索引维护开销:插入、删除可能导致页分裂或合并,产生写放大,但B+树通过缓冲池和后台操作减轻影响。
- B+树在磁盘上的组织:InnoDB通过表空间管理页,每个页有唯一编号,指针存储为页号+偏移量。
- 与LSM树对比:LSM树(如LevelDB、RocksDB)适用于写多读少场景,而B+树更适合读多写少。
- 优化技巧:利用最左前缀原则设计联合索引;避免对索引列使用函数;合理选择索引列顺序等。
【问题】 什么是MySQL的覆盖索引?
【参考答案】
覆盖索引(Covering Index)是指一个索引包含了查询所需的所有列(即查询的字段都在索引中),使得查询只需要扫描索引而无需回表(访问数据行)就能得到结果。在MySQL中,可以通过EXPLAIN命令的输出中,如果Extra列显示Using index,则表示该查询使用了覆盖索引。覆盖索引能显著提升查询性能,因为索引通常比数据行小,且顺序存储,可以减少I/O操作。需要注意的是,只有B-Tree索引(包括InnoDB的聚簇索引和二级索引)能实现覆盖索引,而哈希索引、空间索引、全文索引等由于不存储完整的列值,无法用作覆盖索引。
【大白话解释于举例说明】 可以把索引想象成一本书的目录,数据行是书的内容。普通查询就像按目录找到页码后,还要翻到对应的页去读内容(回表)。而覆盖索引就像目录里直接写了你想要的所有信息,比如目录里除了标题还有作者和出版年份,你只需要查目录就能得到答案,根本不用翻到正文。
例如,假设有一张用户表user:
CREATE TABLE user (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
address VARCHAR(100),
INDEX idx_name_age (name, age)
);
执行查询:
SELECT name, age FROM user WHERE name = '张三';
因为name和age都在联合索引idx_name_age中,MySQL可以直接从索引中获取这两列的值,无需读取整行数据。使用EXPLAIN查看,Extra列会显示Using index,说明用到了覆盖索引。
如果换成SELECT * FROM user WHERE name = '张三',索引中不包含address,就需要回表取数据,就无法使用覆盖索引。
【扩展知识点详解】
-
判断覆盖索引的方法
通过EXPLAIN分析查询,如果Extra列出现Using index,则表明使用了覆盖索引。注意Using index与Using where的区别:Using index表示直接通过索引获取数据,而Using where表示在索引层过滤后还需要回表检查条件。 -
覆盖索引的工作原理
MySQL在B+Tree索引中,叶子节点存储了索引列的值以及指向数据行的指针(对于二级索引,叶子节点包含索引列和主键值)。如果查询的所有列都包含在索引列中,优化器会选择仅扫描索引,避免回表产生的随机I/O,大幅提升查询速度。 - 覆盖索引的优缺点
- 优点:减少I/O操作(索引通常比数据行小,且按顺序存储);避免聚簇索引的回表开销;对于InnoDB,如果覆盖索引包含了主键,甚至可以避免二次查找(因为二级索引叶子节点存储主键值)。
- 缺点:索引本身占用更多存储空间;维护成本增加(写操作需更新索引);并非所有查询都能设计覆盖索引。
- 适用场景
- 高频查询且返回字段较少时,可创建覆盖索引优化。
- 统计类查询(如
COUNT(*))若能用覆盖索引也会更快。 - 需要排序的查询,若索引包含排序字段,也可能避免文件排序。
-
与聚簇索引的关系
在InnoDB中,聚簇索引(主键索引)的叶子节点直接存储整行数据,因此任何SELECT只要通过主键查询,天然就是“覆盖”的,因为索引本身包含了所有列。但二级索引需要回表,只有二级索引包含所有查询列时才能实现覆盖。 - 注意事项
- 覆盖索引要求查询列必须全部在索引中,因此
SELECT *通常无法使用覆盖索引,除非索引包含了所有字段(例如创建了包含所有列的联合索引,但这样索引体积过大,不推荐)。 - 在MySQL中,只有B-Tree索引(包括InnoDB和MyISAM)支持覆盖索引;哈希索引、空间索引、全文索引等无法实现覆盖索引,因为它们不存储原始列值。
- 使用
EXPLAIN时,如果Extra显示Using index condition,则代表使用了索引条件下推(ICP),与覆盖索引不同,后者是直接在索引层完成所有数据获取。
- 覆盖索引要求查询列必须全部在索引中,因此
- 设计覆盖索引的原则
- 将查询中经常出现的字段(尤其是
WHERE、SELECT、ORDER BY、GROUP BY涉及的字段)纳入联合索引。 - 注意索引字段的顺序,尽量满足最左前缀原则。
- 平衡查询性能与索引维护成本,避免创建过宽的索引。
- 将查询中经常出现的字段(尤其是
【问题】 造成索引失效的场景有哪些?
【参考答案】 MySQL中索引失效(即查询无法使用索引或优化器放弃使用索引)的常见场景包括:
- 违反最左前缀原则:对于联合索引,查询条件未从索引的最左列开始,或跳过中间列,导致部分索引无法使用。
- 对索引列使用函数或计算:在
WHERE子句中对索引列进行函数操作(如DATE()、LENGTH())或表达式计算(如col+1),会使索引失效。 - 隐式类型转换:当索引列的类型与查询条件的类型不一致时,MySQL会进行隐式转换,导致索引失效(例如字符串列与数字比较)。
- 模糊查询以通配符开头:使用
LIKE '%abc'或LIKE '_abc'时,无法使用索引(但LIKE 'abc%'可以使用索引)。 - 使用
OR连接条件:如果OR两边的条件中,有一边的列没有索引,或虽然都有索引但MySQL优化器认为扫描全表更优,则可能放弃索引。 - 使用
!=或<>操作符:不等于比较通常会让索引失效,除非查询的数据分布非常特殊(例如主键范围扫描)。 IS NULL或IS NOT NULL:对于某些存储引擎(如InnoDB),IS NULL可能使用索引,但IS NOT NULL通常导致索引失效,尤其是当NULL值占比很小时。- 全表扫描比索引更快:当优化器估算发现使用索引需要访问大量数据(例如超过表的30%左右),可能会放弃索引而选择全表扫描(如范围查询数据量过大时)。
ORDER BY与索引顺序不匹配:如果ORDER BY的字段顺序与索引顺序不一致,或同时包含ASC和DESC混用,可能无法利用索引排序。SELECT *且无覆盖索引:当查询所有列且索引不包含全部列时,需要回表,如果回表代价高,优化器可能放弃索引。- 使用
NOT IN、NOT EXISTS:这些操作通常导致索引失效,转为全表扫描。 - 对索引列进行参数化查询但参数类型不匹配:例如PreparedStatement中设置参数类型与字段类型不一致,导致隐式转换。
【大白话解释于举例说明】 可以把索引想象成书的目录,索引失效就是明明有目录却无法用,只能一页页翻书。
- 最左前缀原则:比如联合索引是
(a, b, c),就像目录先按a排,再按b,再按c。你只查b和c,目录就帮不上忙;或者查a和c,跳过b,那么a能用,c用不了(因为中间跳过了b)。WHERE b = 2; -- 索引失效 WHERE a = 1 AND c = 3; -- 只有a能用,c不能(需要先按b定位) - 函数计算:比如你在目录里找作者,但条件写的是
LENGTH(name)=5,这就相当于把名字改成了长度,目录就没办法直接定位。WHERE LENGTH(name)=5; -- 索引失效 - 类型转换:比如手机号字段是
varchar,但你用数字查WHERE phone = 13800138000,MySQL会先把所有phone转成数字再比,索引就废了。WHERE phone = 13800138000; -- 隐式转换,索引失效 - LIKE以%开头:你要找名字里带“三”的人,写
LIKE '%三%',就像在目录里找第二个字是“三”的,没法直接定位,只能翻遍整本书。WHERE name LIKE '%三%'; -- 索引失效 - OR条件:比如
WHERE age=20 OR name='张三',如果age有索引但name没有,那只能用全表扫,因为部分数据还是要查表。WHERE age=20 OR name='张三'; -- 如果name无索引,全表扫描 - 不等于:
WHERE age != 20,就像要找所有不是20岁的人,如果年龄分布很广,数据库觉得还不如全表扫一遍。WHERE age <> 20; -- 通常索引失效 - IS NULL/IS NOT NULL:
WHERE name IS NULL,对于大多数情况,NULL值很少,用索引找很快;但IS NOT NULL要排除NULL,如果大部分都不是NULL,还不如全表扫。WHERE name IS NOT NULL; -- 可能索引失效 - 优化器估算:比如你要查价格大于100的商品,如果超过30%的商品都大于100,那用索引还不如直接全表扫,因为索引加回表更慢。
WHERE price > 100; -- 如果数据量大,可能走全表扫描 - ORDER BY顺序不匹配:索引是
(a, b),但ORDER BY b, a,就像目录先按a排,你要按b排,就没法直接利用。ORDER BY b, a; -- 索引失效(需filesort) - SELECT * 无覆盖索引:
SELECT * FROM user WHERE age=20,如果索引只有age,那找到age=20的记录后还要回表取其他字段,如果回表太多,不如全表扫描。
【扩展知识点详解】
-
最左前缀原则的细节:联合索引的匹配遵循从左到右的顺序,一旦跳过某一列,后面的列无法使用索引。此外,范围查询(
>、<、BETWEEN)也会导致后续列索引失效(但范围列本身仍能用)。例如WHERE a>1 AND b=2,a能用到索引,b不能(因为a是范围),这是索引使用而非失效。 -
函数索引与虚拟列:MySQL 5.7+支持虚拟列,可以在虚拟列上建立索引以解决对列使用函数的问题。8.0+支持函数索引(直接对表达式建立索引),从而避免索引失效。
-
隐式类型转换规则:当字符串和数字比较时,MySQL会将字符串转换为数字(而非数字转字符串)。例如
phone='13800138000'(字符串)用索引,而phone=13800138000(数字)会导致全表扫描。日期类型与字符串比较也可能发生转换。 -
OR条件的优化:如果OR所有条件列都有索引,MySQL可能使用索引合并(Index Merge)来优化,但效率不一定高。尽量改为
UNION或IN(如果可能)。 -
优化器成本估算:MySQL通过抽样统计信息估算行数,当估算读取行数超过全表一定比例(通常10%-30%),就会放弃索引。这可以通过
FORCE INDEX强制使用,但不推荐生产环境使用。 -
排序与索引:如果
ORDER BY字段和WHERE条件字段可以组成联合索引,可能避免文件排序。例如WHERE a=1 ORDER BY b,索引(a,b)可以完美支持。但如果ORDER BY和GROUP BY混合使用,也可能导致索引失效。 -
覆盖索引与回表:当使用覆盖索引时,即使查询条件不符合最左前缀(只要索引包含了所有字段),也可能使用索引(Extra显示
Using index)。但覆盖索引不能完全避免索引失效,例如WHERE b=2在索引(a,b)上,虽然b不是最左,但若查询字段只有b,仍可能使用索引扫描(但效率低,因为需要扫描整个索引)。这算不算索引失效?严格来说索引被使用了,但不是高效的访问方式,优化器可能放弃。 -
统计信息过时:如果表的统计信息不准确,优化器可能错误地选择全表扫描。可通过
ANALYZE TABLE更新统计信息。 -
分区表:分区表的索引失效可能涉及分区裁剪失败,需注意分区键的使用。
-
锁与并发:某些锁操作(如
LOCK TABLES)可能导致索引使用受限,但一般不常见。 -
索引不可见:MySQL 8.0支持不可见索引,优化器不会使用,相当于人为使索引失效。
优化建议:
- 定期使用
EXPLAIN分析查询,关注type、key、Extra列。 - 为高频查询设计合适的联合索引,考虑字段顺序。
- 避免在索引列上做计算、函数、类型转换,必要时使用冗余字段或函数索引。
- 使用
LIKE时,尽量将通配符放在右侧。 - 对于
OR,考虑拆分为UNION或使用IN(如果集合较小)。 - 监控慢查询日志,针对性的优化。
注意:以上场景并非绝对,MySQL优化器会根据实际情况(数据分布、统计信息、索引成本)做出判断,因此“索引失效”是一个动态结果。
【问题】 联合索引的匹配规则有哪些?
【参考答案】 联合索引(也称为复合索引)的匹配规则主要遵循最左前缀原则,并结合查询条件的使用方式决定索引是否能被有效利用。具体规则如下: 全值匹配我最爱,最左前缀要遵守; 带头大哥不能死,中间兄弟不能断; 索引列上少计算,范围之后全失效; like百分写最右,覆盖索引不写星; 不等空值还有or,索引失效要少用; var引号不能丢,索引规则也不难;
- 全值匹配:查询条件中的字段与联合索引的所有列完全匹配(即等值比较),且顺序与索引定义一致时,索引效率最高。
- 最左前缀原则:查询必须从联合索引的最左侧列开始,并且不能跳过中间的列。只有满足最左前缀的查询部分才能使用索引。
- 如果查询条件中缺失最左侧列,则无法使用该索引。
- 如果跳过中间列,那么只能使用索引中从最左侧到跳过列之前的部分,后续列无法利用索引。
- 范围查询导致后续列失效:当查询条件中出现范围查询(
>、<、BETWEEN、LIKE等)时,该列可以使用索引,但其后的列无法继续使用索引(即索引只能用于范围列本身及其前面的列)。 - 对索引列使用函数或计算会使索引失效:如果在索引列上进行函数操作或表达式计算(如
LENGTH(col)、col+1),则该列无法使用索引,进而可能导致整个索引无法使用(除非满足最左前缀的其他列仍可用)。 - LIKE查询以通配符开头会导致索引失效:
LIKE '%abc'或LIKE '_abc'无法使用索引,但LIKE 'abc%'可以使用索引(属于范围查询的一种)。 - 索引列的类型转换会导致索引失效:如果查询条件中的数据类型与索引列的数据类型不一致(例如字符串列与数字比较),MySQL会进行隐式类型转换,导致该列索引无法使用。
- 使用
OR连接条件可能导致索引失效:如果OR两边的条件中,有一边不是索引列或MySQL认为全表扫描更优,则可能放弃使用索引。 - 使用
!=、<>、NOT IN等否定操作符通常使索引失效,除非优化器判断使用索引成本更低(如查询大部分数据时)。 IS NULL和IS NOT NULL:对于IS NULL,如果NULL值较少,可能使用索引;IS NOT NULL通常导致索引失效(当非NULL值占多数时)。- 排序(
ORDER BY)与索引匹配:如果ORDER BY的字段顺序与联合索引一致,且排序方向相同,则可以利用索引避免文件排序。但若顺序不一致或存在混合排序方向,则无法使用索引排序。 - 覆盖索引可以绕过部分限制:如果查询的字段全部包含在联合索引中(即覆盖索引),即使某些条件不满足最左前缀,也可能通过扫描整个索引来获取数据(但效率可能低于全值匹配)。
【大白话解释于举例说明】
假设有一张学生表,创建了联合索引(name, age, class)。下面用通俗语言解释规则:
- 全值匹配:就像你按姓名、年龄、班级三个条件精确找人,索引一步到位。
SELECT * FROM student WHERE name='张三' AND age=18 AND class='一班'; -- 完美使用索引 - 最左前缀:索引像电话簿先按姓氏、再按名字排序。你只知道名字不知道姓氏,就找不到;或者你知道姓氏和班级,但跳过年龄,那么班级条件用不上(因为年龄没确定,无法在年龄范围内精确找班级)。
WHERE age=18 AND class='一班'; -- 没从name开始,索引失效(全表扫描) WHERE name='张三' AND class='一班'; -- name能用,class不能用(跳过了age) - 范围后失效:比如你找姓“张”且年龄大于18的,
name的等值条件可以用索引,age的范围条件也能用,但age后面的class条件就只能在筛选出的数据中再过滤,无法利用索引快速定位了。WHERE name='张三' AND age>18 AND class='一班'; -- name和age用索引,class不能 -
函数/计算:如果条件写成
WHERE LEFT(name,1)='张',相当于把名字改了,索引就没法用了。 -
LIKE通配符:
WHERE name LIKE '张%'能用索引(相当于范围),但%张不行。 -
类型转换:如果
name是字符串,你用数字查WHERE name=123,MySQL会把所有name转成数字再比,索引失效。 -
OR:
WHERE name='张三' OR age=18,如果age没索引,那即使name有索引,也可能全表扫描。 -
不等于:
WHERE age != 18,要找所有不是18岁的,数据库觉得全表扫更快。 -
IS NULL:
WHERE name IS NULL如果确实有NULL值,可能用索引(但效率一般);IS NOT NULL通常不用索引。 -
排序:
ORDER BY name, age, class可以用索引排序;但ORDER BY age, name顺序不对,需要文件排序。 - 覆盖索引:如果只查
name,age(都在索引里),即使条件只有age=18(不符合最左),也可能扫描整个索引得到结果(Extra显示Using index),但比全表扫描快。
【扩展知识点详解】
-
联合索引在B+树中的存储结构
联合索引的B+树按照索引定义的列顺序依次排序。例如索引(a,b,c),先按a排序,a相同的按b排序,b相同的按c排序。因此,只有遵循最左前缀的查询才能高效地定位数据。 -
最左前缀原则的数学原理
因为索引树的排序规则,如果查询条件中不包含最左列,就无法确定在树中搜索的起始范围,只能全索引扫描。例如,查找所有b=2的记录,由于a未知,必须遍历整个索引树,相当于全表扫描(但扫描索引比扫描表稍快)。 -
范围查询后列失效的原因
当使用范围查询时(如a>1),满足条件的a值有很多,对于每个不同的a,b和c的排序规则只在a确定的子树内有效。因此,范围查询后的列无法继续用于精确查找,只能对结果集进行过滤。MySQL 8.0引入了索引下推(ICP),可以将部分条件推送到存储引擎层过滤,但依然无法避免扫描。 -
索引下推(Index Condition Pushdown)
MySQL 5.6+支持ICP,允许在存储引擎层过滤不符合后续索引列条件的数据,减少回表次数。例如WHERE name='张三' AND age>18 AND class='一班',在ICP下,class条件会在读取索引时判断,只有满足class='一班'的才回表,但class本身并未用于索引定位。 -
索引选择性与优化器成本估算
优化器会根据统计信息估算不同执行计划的成本(包括IO和CPU)。即使存在可用索引,如果优化器认为全表扫描成本更低(如返回数据量占比较大),也会放弃索引。这是索引“失效”的另一层含义,并非索引本身不能用,而是优化器选择了更优方案。 -
排序与索引的关系
如果ORDER BY的字段顺序与索引完全一致,且排序方向相同,则MySQL可以直接利用索引的有序性避免文件排序(filesort)。如果查询中同时包含WHERE和ORDER BY,索引设计应尽量同时满足两者(例如将WHERE的等值列放在前面,ORDER BY列放在后面)。 - 索引设计原则
- 选择区分度高的列作为索引前列。
- 将经常用于
WHERE条件、JOIN连接、ORDER BY、GROUP BY的列纳入联合索引。 - 考虑查询频率和更新开销,避免过多索引。
- 对于范围查询频繁的场景,可将范围列放在索引最后,以避免影响后续列。
- 特殊情况处理
- IN查询:
IN在MySQL中通常当作多个等值比较,如果IN列表值不多,可以使用索引,且不会导致后续列失效(但IN之后的范围列依然可能失效)。 - OR条件的优化:若
OR两边列都有独立索引,MySQL可能使用索引合并(Index Merge),但效率通常不如联合索引。 - 函数索引:MySQL 8.0支持在表达式上创建索引,可以解决对列使用函数导致的失效问题。
- 隐式转换规则:当字符串与数字比较时,MySQL将字符串转为数字(例如
'123'转123),若字符串列有索引,转换后索引失效。
- IN查询:
-
验证方法
使用EXPLAIN分析查询,关注key(实际使用的索引)、key_len(使用的索引长度)、ref(哪些列或常量用于查找)、Extra(Using where、Using index、Using index condition等)。例如key_len可以推断出使用了联合索引中的哪些列。 - 常见误区
- 误区:只要查询涉及索引列,就会使用索引。实际上,必须遵循最左前缀。
- 误区:范围查询一定导致后续列失效。注意,如果范围条件是等值
=,则后续列可以继续使用;范围(>、<)才会阻断。 - 误区:
LIKE '%abc'一定不用索引。在少数情况下,如果查询只返回索引列(覆盖索引),且优化器认为索引扫描成本低于全表扫描,仍可能使用索引(但效率较低)。
理解联合索引的匹配规则是SQL优化的基础,实际应用中需结合具体查询和数据分布,通过EXPLAIN分析调整索引设计。
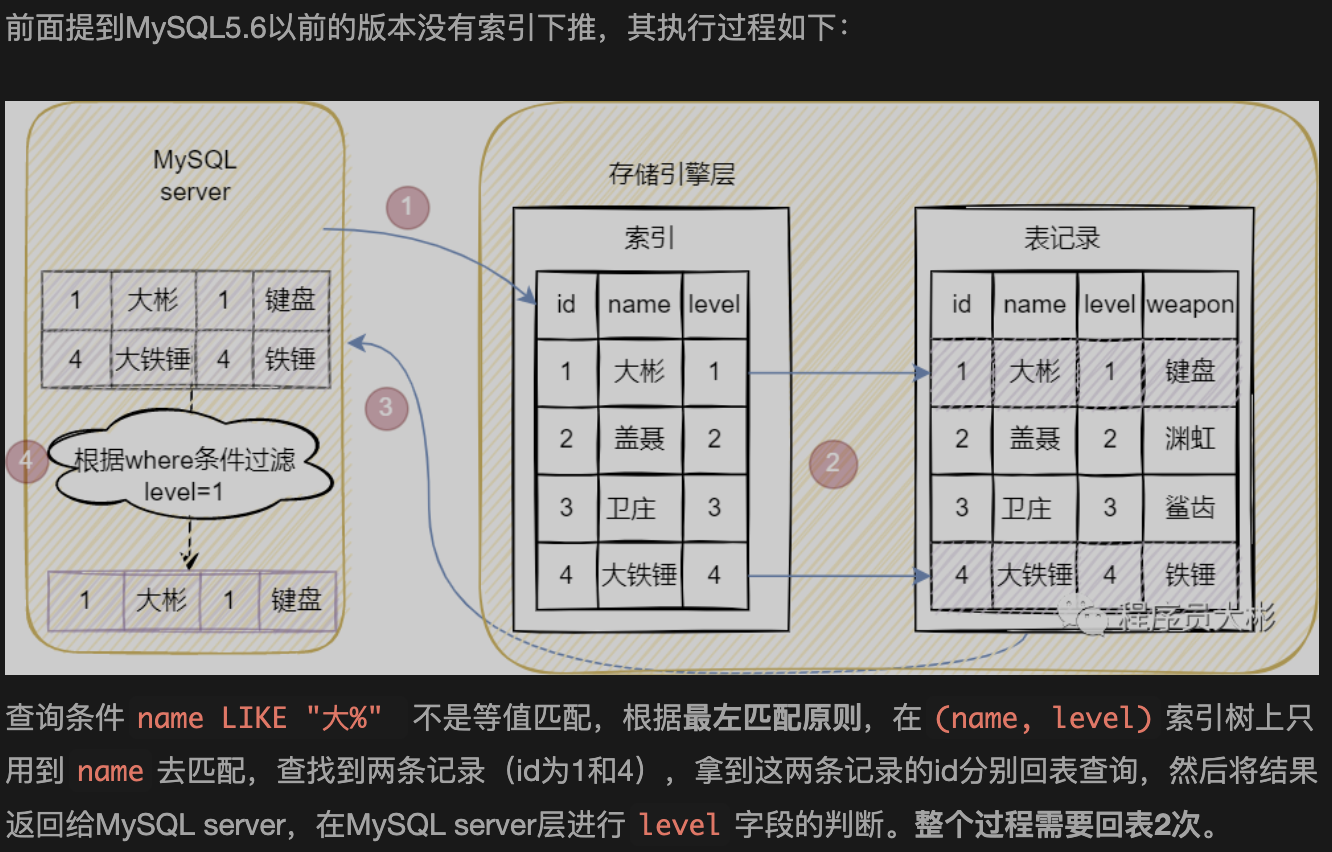
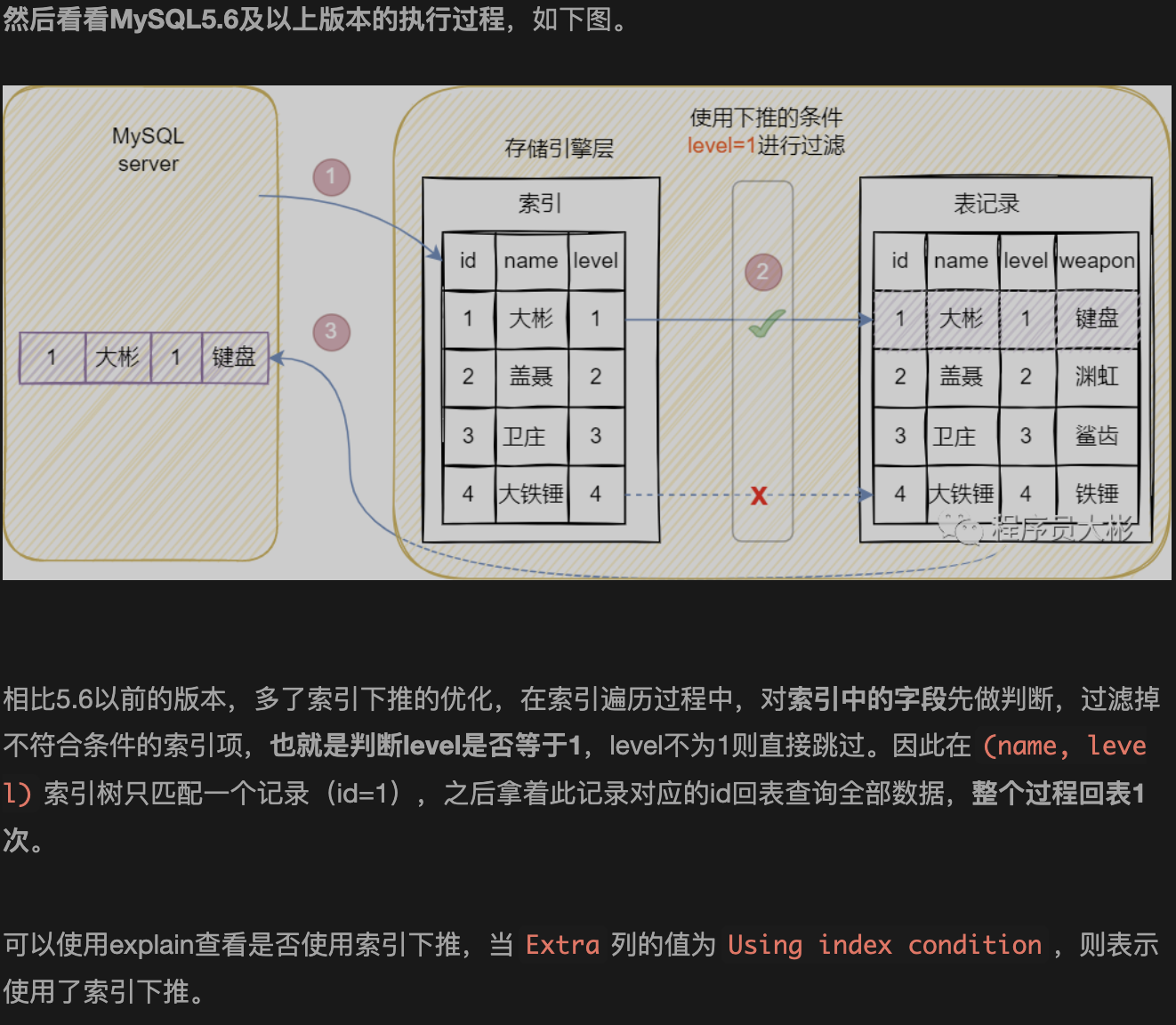
【问题】 MySQL的索引下推是什么?
【参考答案】 索引下推(Index Condition Pushdown,简称ICP)是MySQL 5.6版本引入的一种查询优化技术,旨在减少使用二级索引查询时的回表次数,提升查询性能。其核心思想是将部分查询条件下推到存储引擎层,在存储引擎层利用索引列进行数据过滤,只将满足条件的索引记录返回给Server层,从而避免对不满足条件的记录进行回表操作。
在ICP引入之前,MySQL使用二级索引查询的流程为:存储引擎通过索引找到记录(先读取索引记录,再根据主键回表读取完整行数据),然后将完整行数据返回给Server层,Server层再对记录进行WHERE条件的过滤。这种模式下,即使索引记录最终不满足WHERE条件,也会发生回表,造成不必要的I/O开销。
引入ICP后,如果查询条件中包含索引列的条件,Server层会将这部分条件下推到存储引擎,存储引擎在读取索引记录时,直接根据下推的条件进行判断,只有满足条件的索引记录才进行回表操作,否则跳过。这样就减少了回表次数,提高了查询效率。
ICP默认开启,可通过optimizer_switch系统变量控制,并使用EXPLAIN查看执行计划时,若Extra列显示Using index condition,则表示使用了索引下推。
【大白话解释于举例说明】 可以把索引比作图书馆的图书目录卡片,数据行比作书架上的实体书。传统查询就像:根据目录卡片找到一本书的编号,然后去书架取回整本书,再翻开看内容是否符合条件(比如作者或年份)。如果不符合,这本书就白取了,还得放回去,浪费体力。
索引下推就像:在查目录卡片时,卡片上已经记录了部分信息(比如作者),你可以先根据卡片上的信息筛选掉明显不符合的书,只把符合条件的书编号记下来,再去书架上取书。这样你只需要取回真正需要的书,避免了无效的搬书劳动。
具体例子:
假设有一张用户表user,有联合索引(age, name),查询语句:
SELECT * FROM user WHERE age > 20 AND name LIKE '%三%';
在没有ICP时,存储引擎会根据age > 20找到所有符合条件的索引记录(包含主键),然后逐个回表读取完整行,Server层再对name进行LIKE匹配。即使很多行name不满足条件,也会发生回表。
有了ICP后,Server层将name LIKE '%三%'下推到存储引擎,存储引擎在扫描索引时,对每个索引记录先判断name是否匹配(因为索引中包含了name列),只有匹配的才回表。这样大大减少了回表次数。
【扩展知识点详解】
- ICP的工作原理
- 当使用二级索引进行范围扫描或等值扫描时,如果查询条件中除了索引列还有额外的索引列条件,MySQL会将这部分条件(即可以使用索引列进行判断的条件)传递给存储引擎。
- 存储引擎遍历索引时,对每个索引条目先检查下推的条件,如果满足则根据索引中的主键进行回表;如果不满足则直接跳过,无需回表。
- ICP主要适用于二级索引,因为聚簇索引本身包含了整行数据,无需回表。
- ICP的适用条件
- 只能用于二级索引,不能用于聚簇索引(主键索引)。
- 需要访问完整行记录(即查询需要回表),如果查询已通过覆盖索引完成(
Extra显示Using index),则ICP不生效。 - 下推的条件必须是索引列的条件,且不能包含子查询、非索引列、函数(但某些情况如
LIKE前缀匹配也可能下推)。 - 适用于InnoDB和MyISAM存储引擎。
- 需要优化器评估使用ICP的成本低于不使用ICP。
- 如何查看是否使用了ICP
- 使用
EXPLAIN分析查询,如果Extra列显示Using index condition,则说明使用了索引下推。 - 也可以通过
optimizer_switch变量查看ICP状态:SHOW VARIABLES LIKE 'optimizer_switch';,其中index_condition_pushdown=on表示开启。
- 使用
- ICP与覆盖索引的区别
- 覆盖索引(
Using index)是指查询所需的所有列都在索引中,无需回表。 - ICP(
Using index condition)则仍需回表,但减少了回表的次数。两者可同时出现?实际上Extra中不会同时出现Using index和Using index condition,因为如果覆盖索引生效,就无需回表,ICP就没有意义了。但可能存在Using index condition和Using where同时出现的情况,表示ICP过滤了一部分,Server层再过滤剩下的。
- 覆盖索引(
- ICP的优化效果
- 减少回表次数,降低随机I/O开销。
- 尤其适用于索引列选择性较差、需要回表大量记录但实际满足条件的记录较少的情况。
- 对于
LIKE模糊查询(只要通配符不在最左)、范围查询等场景效果明显。
- ICP的局限性
- 只能下推索引列的条件,对于非索引列的条件无法下推,仍需Server层过滤。
- 如果查询中使用了函数或表达式在索引列上,导致索引列无法直接用于判断,则无法下推(除非MySQL 8.0支持函数索引后,对函数索引列的条件可能下推)。
- 在某些情况下,优化器可能认为使用ICP成本更高(例如索引扫描本身需要大量读取),而选择不使用。
- ICP与索引条件下推的历史
- MySQL 5.6首次引入ICP。
- MySQL 5.7、8.0持续优化,对更多类型的查询支持ICP,包括分区表的ICP等。
- 相关参数
optimizer_switch中的index_condition_pushdown可以动态开启或关闭ICP:SET optimizer_switch = 'index_condition_pushdown=off';
- 示例分析
假设表结构:CREATE TABLE t1 (a INT, b INT, c INT, KEY idx_a_b (a, b));查询:
SELECT * FROM t1 WHERE a > 10 AND b = 5;- 无ICP:存储引擎通过索引找到所有
a>10的记录(索引项包含a,b和主键),回表获取完整行,Server层再过滤b=5。 - 有ICP:存储引擎在扫描索引时,对于每个
a>10的记录,先检查b=5(因为b也在索引中),只有b=5的才回表。
- 无ICP:存储引擎通过索引找到所有
- 与其他优化的配合
- ICP可以与MRR(Multi-Range Read)配合使用,进一步优化回表的磁盘读取顺序,将随机I/O转为顺序I/O。
- 在MySQL 8.0中,ICP还支持对派生表(Derived Table)的下推等。
总之,索引下推是MySQL重要的性能优化特性,理解其原理有助于编写高效SQL和设计索引,并在分析执行计划时准确判断查询是否充分利用了索引。
【问题】 什么是MySQL的回表?
【参考答案】 回表(Return to Table)是指在使用二级索引(非聚簇索引)进行查询时,由于二级索引的叶子节点只存储了索引列的值和对应的主键值,而没有存储完整的行数据,因此当查询需要获取索引列以外的其他列时,需要根据二级索引中获取的主键值,再到聚簇索引(主键索引)中查找完整的行记录,这个过程称为回表。回表操作会增加额外的I/O开销,因为需要两次索引扫描:先扫描二级索引找到主键,再扫描聚簇索引获取行数据。如果查询需要回表的行数较多,性能会显著下降。在某些情况下,MySQL优化器可能认为回表代价过高而选择直接进行全表扫描(即只使用聚簇索引扫描整个表)。
在InnoDB存储引擎中,聚簇索引的叶子节点直接存储整行数据,因此通过聚簇索引查询可以直接获取所有列,无需回表。而每个二级索引的叶子节点存储的是索引列的值和主键值(对于InnoDB)或行指针(对于MyISAM,但MyISAM没有聚簇索引的概念)。所以,回表特指InnoDB中二级索引查询后需要再次访问聚簇索引的行为。
【大白话解释于举例说明】 想象你有一个巨大的图书馆,里面有成千上万本书。图书馆有两种卡片目录:
- 一种是按书名排序的目录(相当于二级索引),卡片上写着书名和书的唯一编号(主键),以及书所在的书架位置信息(实际上在InnoDB中,卡片上只有编号,位置需要通过编号再查)。
- 另一种是按编号排序的目录(相当于聚簇索引),卡片上详细记录了书的完整信息,包括作者、出版社、内容简介等,并且编号就是书在书架上的实际位置(聚簇索引的叶子节点就是书本身)。
现在你想找一本名字叫《Java编程思想》的书,并且想知道它的作者和出版社。你首先去书名目录(二级索引)找到“Java编程思想”这张卡片,卡片上只有书名和书的编号(比如#12345)。然后你拿着这个编号#12345去编号目录(聚簇索引)查找,找到编号#12345的卡片,上面详细记录了作者、出版社等信息。这个拿着编号再去查详细信息的步骤,就是“回表”。
如果你只需要书名(即索引本身包含的列),那么你在书名目录上就能直接得到答案,无需再去查编号目录。这就是“覆盖索引”的场景。
再举一个SQL例子:
表user有字段id(主键)、name、age,并在name上建立了普通索引。
查询SELECT name, age FROM user WHERE name = '张三';
执行过程:
- 通过
name索引找到所有name='张三'的索引项,每个索引项包含name和对应的id。 - 对于每个索引项,根据
id到聚簇索引(主键索引)中查找完整的行数据,从中取出age字段。 - 返回结果。
这里
age不在name索引中,所以需要回表。如果查询改为SELECT name FROM user WHERE name = '张三';,因为name索引已经包含了name列,就不需要回表,这是覆盖索引。
【扩展知识点详解】
-
回表产生的根本原因
InnoDB采用聚簇索引组织数据,数据行存储在聚簇索引的叶子节点上。二级索引只存储索引列和主键值,不存储其他列。因此,当查询需要的数据列超出了二级索引的范围时,就必须通过主键回表获取缺失的数据。 - 回表对性能的影响
- 回表意味着额外的I/O操作,尤其是当需要回表的行数很多时,会产生大量随机I/O,因为二级索引和聚簇索引的数据页可能分散在不同的磁盘位置。
- 如果回表次数过多,MySQL优化器可能认为全表扫描(即直接扫描聚簇索引)更高效,从而放弃使用二级索引。
- 回表次数取决于索引选择性和查询条件。例如,范围查询可能导致大量回表。
- 如何避免或减少回表
- 使用覆盖索引:设计索引时,尽量将查询中需要返回的列都包含在索引中,这样查询可以直接从索引获取所有数据,无需回表。例如,对于高频查询
SELECT name, age FROM user WHERE name = ?,可以创建联合索引(name, age)。 - 使用索引下推(ICP):虽然不能完全避免回表,但ICP可以在回表前通过索引列条件过滤掉部分记录,减少回表次数。
- 合理设计索引:避免创建过多的索引,但针对关键查询建立合适的联合索引。
- 限制返回行数:通过
LIMIT减少回表次数。 - 使用主键查询:直接通过主键查询无需回表。
- 使用覆盖索引:设计索引时,尽量将查询中需要返回的列都包含在索引中,这样查询可以直接从索引获取所有数据,无需回表。例如,对于高频查询
-
回表与索引选择
MySQL优化器在选择索引时,会评估使用索引的成本,包括回表的代价。如果优化器估计需要回表的行数占全表比例较高(通常超过20%-30%),可能会选择全表扫描。因此,了解回表成本对于分析查询性能至关重要。 - 回表在不同存储引擎中的表现
- InnoDB:聚簇索引+二级索引,回表必须。
- MyISAM:索引和数据分离,索引叶子节点存储行数据的物理地址(指针),因此使用任何索引都需要根据地址直接读取数据行,这本质上也是一种“回表”,但由于MyISAM没有聚簇索引的概念,其所有索引都是非聚簇的,且索引中直接包含行地址,所以通常不特别称为“回表”,但同样有随机I/O问题。
- Memory引擎:默认使用哈希索引,数据按行存储,索引指向数据位置,类似MyISAM。
- 如何判断查询是否发生了回表
使用EXPLAIN分析查询:- 如果
key列使用了二级索引,且Extra列没有Using index,则说明发生了回表(因为需要回表获取未包含在索引中的列)。 - 如果
Extra列显示Using index,表示使用了覆盖索引,无需回表。 - 如果
Extra列显示Using index condition,表示使用了索引下推,但仍然需要回表(但回表前过滤了一部分)。 - 如果
type列为ALL,表示全表扫描,没有使用索引。
- 如果
-
回表与主键长度
二级索引的叶子节点存储主键值,因此主键的长度会影响二级索引的大小。使用较短的整数主键(如自增int)比使用长字符串主键(如UUID)更节省空间,从而减少I/O。 -
回表与多版本并发控制(MVCC)
在可重复读隔离级别下,回表读取数据时可能需要根据undo log构建旧版本,增加额外开销,但这是另一层面的问题。 - 实际案例分析
假设有表t,联合索引(a, b),查询SELECT a, b, c FROM t WHERE a = 1。- 如果
c不在索引中,则需要回表获取c,EXPLAIN会显示key为(a,b),Extra可能为空或Using where(取决于是否有其他条件)。 - 如果将索引改为
(a, b, c),则查询SELECT a, b, c成为覆盖索引,Extra显示Using index,无需回表。
- 如果
- 回表与JOIN查询
在多表连接中,驱动表使用索引查找后,对每行结果可能需要回表获取完整数据再与被驱动表连接,同样需要考虑回表成本。
总结:回表是InnoDB索引机制下的必然现象,理解回表有助于设计高效的索引和编写高性能SQL。通过覆盖索引、索引下推、合理查询等手段可以有效减少回表带来的性能损耗。
缓冲池
【问题】 什么是MySQL缓冲池?
【参考答案】 MySQL的缓冲池(Buffer Pool)是InnoDB存储引擎中一块重要的内存区域,主要用于缓存磁盘上的数据页和索引页,以减少磁盘I/O,提升数据库的读写性能。缓冲池是InnoDB缓存机制的核心,其作用和工作原理如下:
- 核心作用:
- 缓存数据页:当读取数据时,首先从缓冲池中查找,若命中则直接返回,否则从磁盘加载到缓冲池。
- 缓存索引页:加速索引查找,减少磁盘访问。
- 管理脏页:对数据的修改先在缓冲池中的页上进行(标记为脏页),然后由后台线程异步刷新到磁盘,实现写优化。
- 通过LRU(最近最少使用)算法管理缓存页的淘汰,确保热数据常驻内存。
- 内部结构:
InnoDB通过三个关键链表管理缓冲池中的内存页:
- Free List(空闲链表):记录当前空闲的缓存页,用于存放从磁盘新加载的数据页。
- LRU List(LRU链表):管理已被使用的缓存页,按最近最少使用的顺序排序。InnoDB对LRU进行了优化,将链表分为年轻代(young sublist)和老年代(old sublist),避免全表扫描污染热数据。
- Flush List(脏页链表):记录所有被修改但未刷入磁盘的脏页,按最早修改时间排序,便于后台线程刷盘。
- 工作流程:
- 读操作:根据表空间ID和页号通过哈希表查找页是否在缓冲池中。若在,则直接使用并根据LRU策略调整位置;若不在,从Free List获取空闲页(若Free List为空,则淘汰LRU List尾部的一个页,若该页为脏页则先加入Flush List或刷盘),然后从磁盘加载数据页放入LRU List的老年代头部。
- 写操作:直接在缓冲池的页上修改,标记为脏页并加入Flush List(如果不在其中)。同时,该页被移动到LRU List的年轻代头部。
- 刷盘:后台线程(Page Cleaner)定期将Flush List中的脏页刷新到磁盘,并清理LRU List中符合条件的页以维持空闲页。
缓冲池的大小通过参数innodb_buffer_pool_size配置,是影响MySQL性能的关键因素。合理设置缓冲池大小可显著提升数据库并发处理能力和响应速度。
【大白话解释于举例说明】 可以把缓冲池想象成你办公桌上的常用文件抽屉。所有工作文件都存放在远处的文件柜里(磁盘),每次取文件都要走过去,很费时间。为了提高效率,你在办公桌上放一个抽屉(缓冲池),把经常用的文件放在里面。
- Free List:抽屉里空白的文件夹,准备放新文件。
- LRU List:抽屉里文件的摆放顺序。最常用的放在最上面(年轻代),不常用的压在下面(老年代)。当抽屉满了需要放新文件时,就会把最下面最不常用的文件扔掉(淘汰),腾出空间。
- Flush List:记录你修改过的文件清单。你在文件上做了笔记(修改),还没放回文件柜,需要记下来等有空时统一放回(刷盘)。
例如,执行SELECT * FROM user WHERE id=1时,MySQL先在缓冲池中找id=1的数据页。如果找到直接返回;如果没找到,从磁盘加载该页到缓冲池,放入LRU链表的老年代头部,然后返回数据。执行UPDATE user SET name='张三' WHERE id=1时,直接在缓冲池中修改该页,标记为脏页并加入Flush List,同时该页被移动到LRU链表的年轻代头部。之后,后台线程会在适当时机将脏页写回磁盘。
【扩展知识点详解】
- 缓冲池的组成结构
- 数据页(Page):缓冲池以页为单位管理,默认16KB。每个页对应磁盘上的一个数据页。
- 控制块(Control Block):每个缓存页有一个控制块,记录元数据(如表空间ID、页号、LRU指针、脏页标志等),控制块本身也占用内存。
- 哈希表:根据(space_id, page_no)快速定位页是否在缓冲池中。
- 链表:Free List、LRU List、Flush List均为双向链表,通过控制块中的指针连接。
- LRU算法的优化(Midpoint Insertion Strategy)
- 传统LRU可能因全表扫描导致热数据被淘汰。InnoDB将LRU List分为两部分:
- Young sublist(年轻代):占5/8,存放频繁访问的热数据。
- Old sublist(老年代):占3/8,存放新加载或偶尔访问的数据。
- 新读取的页总是插入到Old sublist的头部,只有再次被访问时才会被移动到Young sublist头部。参数
innodb_old_blocks_time可设置页在Old区域停留的最短时间,防止短时热点被误移。
- 传统LRU可能因全表扫描导致热数据被淘汰。InnoDB将LRU List分为两部分:
- 关键参数
innodb_buffer_pool_size:缓冲池总大小,建议设为物理内存的50%-70%。innodb_buffer_pool_instances:将缓冲池划分为多个实例,减少锁竞争。innodb_old_blocks_pct:Old区域占比,默认37(即3/8)。innodb_old_blocks_time:页在Old区域的最短停留时间(毫秒),默认1000。innodb_max_dirty_pages_pct:脏页比例上限,默认75%,超过则强制刷盘。innodb_io_capacity:后台刷盘的最大I/O能力。
- 缓冲池对性能的影响
- 读性能:热数据常驻内存,避免磁盘I/O。
- 写性能:写操作先修改内存,异步刷盘,减少写延迟。
- 磁盘负载:合并多次写操作,减少随机I/O。
- 内存占用:过大会导致操作系统内存换页,过小则频繁缺页。
- 监控与分析
SHOW ENGINE INNODB STATUS:查看缓冲池命中率、链表长度、脏页数量等。INNODB_BUFFER_POOL_STATS表:提供详细的统计信息(如读请求次数、磁盘读取次数)。- 命中率计算公式:
(innodb_buffer_pool_read_requests - innodb_buffer_pool_reads) / innodb_buffer_pool_read_requests。
-
预读机制
InnoDB根据访问模式提前将相邻页加载到缓冲池,包括线性预读和随机预读,由参数innodb_read_ahead_threshold控制。 -
Checkpoint与刷盘
Checkpoint机制推进重做日志的复用,并触发脏页刷盘。缓冲池中的Flush List是Checkpoint刷盘的主要依据。后台线程根据LSN(日志序列号)顺序刷新脏页。 -
与双写缓冲区的关系
双写缓冲区(Doublewrite Buffer)是InnoDB为保证数据页写入原子性而引入的机制,位于共享表空间,与缓冲池协同工作但独立于缓冲池。 -
缓冲池预热
重启后可通过innodb_buffer_pool_load_at_startup自动加载先前保存的缓冲池内容,或手动执行SELECT ...进行预热。 - 常见问题
- 缓冲池污染:全表扫描可能将热数据挤出,通过LRU冷热分离和
innodb_old_blocks_time避免。 - 内存碎片:频繁分配释放可能导致碎片,可通过调整实例数量和页大小优化。
- 并发竞争:多实例可缓解锁竞争,但需均衡配置。
- 缓冲池污染:全表扫描可能将热数据挤出,通过LRU冷热分离和
掌握缓冲池原理是MySQL性能调优的基础,合理配置和监控能显著提升数据库的整体性能。
执行计划
【问题】 讲一下执行计划EXPLAIN?
【参考答案】 EXPLAIN是MySQL提供的一条用于分析查询语句执行计划的命令。通过在SELECT、DELETE、INSERT、REPLACE、UPDATE等语句前加上EXPLAIN关键字,MySQL会返回关于查询执行步骤的详细信息,包括表的读取顺序、索引使用情况、连接类型、扫描行数等,帮助开发者理解查询的性能瓶颈并进行优化。
EXPLAIN的输出结果包含多个字段,每个字段都有特定的含义:
- id:查询中每个SELECT子句的标识符,id越大越先执行,相同id则从上到下执行。
- select_type:查询的类型,如SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)、DERIVED(派生表)、UNION(联合查询)等。
- table:当前行所访问的表。
- partitions:匹配的分区(如果表分区)。
- type:访问类型,反映查询的效率,从好到坏依次为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。实际常见的重要类型有:
- system:表只有一行(系统表),是const的特例。
- const:通过主键或唯一索引等值查询,最多返回一行。
- eq_ref:连接查询中,被驱动表通过主键或唯一索引等值访问,常用于连接条件。
- ref:使用非唯一索引或唯一索引的前缀进行等值查询,可能返回多行。
- range:索引范围扫描,如
BETWEEN、>、<、IN()等。 - index:全索引扫描,即遍历整个索引树(比全表扫描快,因为索引通常较小)。
- ALL:全表扫描,性能最差。
- possible_keys:可能用到的索引(一个或多个)。
- key:实际使用的索引,若为NULL则表示未使用索引。
- key_len:实际使用的索引的最大字节长度,可推断查询使用了联合索引中的哪些列。
- ref:显示哪些列或常量与key一起用于从表中选择行,常见值有
const(常量)、列名(如db.table.col)等。 - rows:MySQL估计需要扫描的行数(不是精确值)。
- filtered:表示返回结果的行数占扫描行数的百分比(估计值),最大100。
- Extra:包含额外的执行信息,常见重要值有:
- Using index:使用了覆盖索引,无需回表。
- Using where:使用了WHERE条件过滤,但可能是在存储引擎层或Server层。
- Using index condition:使用了索引下推(ICP)。
- Using temporary:使用了临时表(通常由于GROUP BY或ORDER BY)。
- Using filesort:使用了文件排序(无法利用索引排序)。
- Impossible WHERE:WHERE条件永远为假。
- Select tables optimized away:优化器确定无需访问表(如聚合函数查询)。
通过分析EXPLAIN的输出,可以识别全表扫描、索引未命中、排序效率低等问题,从而针对性地创建或调整索引、优化SQL语句。
【大白话解释于举例说明】 可以把EXPLAIN想象成一个导航软件的“路线预览”。当你输入一个目的地(查询),导航会告诉你:先走哪条路(表的读取顺序),是否走高速(索引),路上有几个红绿灯(扫描行数),以及最终到达的方式(type)。例如:
- type=ALL:就像导航说“没有高速,只能走普通道路,全程50公里”,意味着全表扫描,速度慢。
- type=ref:导航说“走高速,但高速出口有好几个”,相当于用了非唯一索引,可能匹配多行。
- type=const:导航说“直达,只有一个出口”,表示通过唯一索引精确定位。
- Extra=Using index:导航说“全程高速直达,无需下高速”,表示覆盖索引,直接在索引中就拿到了所有数据。
- Extra=Using filesort:导航说“需要重新规划路线,因为下高速后要掉头”,意味着无法利用索引排序,需要额外排序。
假设我们有表user,主键id,普通索引name,执行:
EXPLAIN SELECT * FROM user WHERE name = '张三';
输出可能显示type=ref,key=name,rows=1,Extra=Using index condition(如果还有别的条件)或Using where。这告诉我们:查询用了name索引,但需要回表获取其他字段,并且通过索引下推可能过滤了一部分数据。
【扩展知识点详解】
- type字段详解(按性能从高到低)
- system:表只有一行记录,是const的特例,一般不会出现。
- const:最多匹配一行,如主键或唯一索引等值查询。
- eq_ref:出现在多表连接时,被驱动表使用主键或唯一索引连接,且驱动表每行只匹配被驱动表一行。
- ref:非唯一索引等值查询,或唯一索引的前缀匹配。
- fulltext:使用全文索引。
- ref_or_null:类似ref,但额外搜索包含NULL值的行。
- index_merge:使用索引合并优化(多个索引合并使用)。
- unique_subquery:子查询中使用唯一索引。
- index_subquery:子查询中使用普通索引。
- range:索引范围扫描,如
>、<、BETWEEN、IN等。 - index:全索引扫描,遍历整个索引树,但通常比全表扫描快。
- ALL:全表扫描。
- key_len的计算
key_len表示索引使用的字节数,可用于判断联合索引实际使用了多少列。计算方法:- 字符集:utf8mb4每个字符占4字节,utf8占3字节,gbk占2字节。
- 变长字段(如varchar)需要额外2字节存储长度。
- 允许NULL的字段需要额外1字节标记NULL。
例如,varchar(10) NOT NULL在utf8mb4下,最大长度为10*4 + 2 = 42字节。若查询使用了该列,key_len为42。
- rows与filtered的用途
- rows:优化器估算需要读取的行数,反映了索引选择性。
- filtered:表示经过WHERE条件过滤后剩余行数的百分比。例如rows=100,filtered=10,则预计返回10行。结合rows*filtered可估算最终结果集大小。
- EXPLAIN的扩展形式
- EXPLAIN FORMAT=JSON:以JSON格式输出更详细的信息,包括成本估算、索引条件等。
- EXPLAIN EXTENDED(MySQL 5.6前)和 EXPLAIN PARTITIONS(5.1前)已被整合进标准EXPLAIN。
- SHOW WARNINGS 可显示优化器重写后的查询。
- EXPLAIN的局限性
- 执行计划是基于当前统计信息的估算,实际执行可能因缓存、并发等不同。
- 不显示触发器、存储过程的影响。
- 对于复杂的存储过程或函数,EXPLAIN可能无法深入内部。
- 如何利用EXPLAIN优化查询
- 关注type是否为ALL或index,如果是,考虑添加或调整索引。
- 检查key是否为NULL,possible_keys是否有可用索引未被使用。
- 查看key_len是否充分利用了联合索引。
- 检查Extra中是否有Using filesort或Using temporary,考虑优化排序或分组字段的索引。
- 对比rows与实际返回行数,若差距过大,可能统计信息过旧(需ANALYZE TABLE)。
- 对于连接查询,确保被驱动表的连接列有索引,且type为eq_ref或ref。
- 实战案例
假设有联合索引(a, b, c),查询SELECT * FROM t WHERE a=1 AND c=2,EXPLAIN可能显示key_len只包含a的长度(如4字节),说明只用了a列,c列未用索引,Extra可能显示Using where。此时若想进一步优化,可考虑将索引改为(a, c, b)或(a, b, c)并利用索引下推,或创建覆盖索引(a, c)。
掌握EXPLAIN是SQL调优的基础,结合慢查询日志和性能监控,可以系统地提升MySQL查询效率。
主从复制
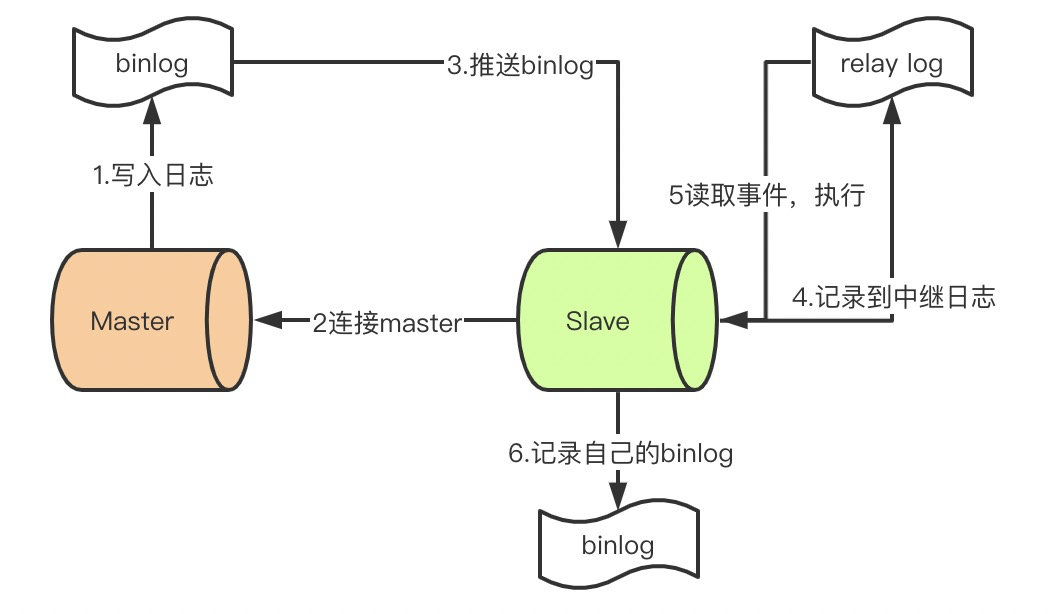
【问题】 MySQL主从复制的流程是什么?
【参考答案】 MySQL主从复制是一种基于二进制日志(binlog)的数据同步机制,其核心流程可概括为三个步骤:主库记录变更、从库拉取日志、从库重放日志。具体流程如下:
- 主库记录二进制日志
- 当主库上的事务提交(或准备提交)时,会将数据变更写入二进制日志(binlog)文件。
- 在写入binlog前,主库会生成一个dump线程,用于后续向从库发送binlog事件。
- binlog的写入与事务的提交顺序一致,确保了复制的一致性。
- 从库I/O线程拉取日志
- 从库启动一个I/O线程,连接到主库,请求从指定的binlog文件名和位置开始同步。
- 主库的dump线程负责读取binlog事件,并发送给从库的I/O线程。
- 从库I/O线程将接收到的binlog事件写入本地的中继日志(relay log)文件。
- 从库SQL线程重放日志
- 从库启动一个SQL线程(或多个SQL线程,若启用并行复制),持续读取中继日志中的事件并顺序执行。
- SQL线程将事件在从库上重放,更新从库数据,使其与主库保持一致。
- 执行完成后,从库可以选择记录自己的二进制日志(若
log_slave_updates开启),以便作为其他从库的主库。
整个过程是异步的,即主库提交事务后不会等待从库确认,但可以通过配置半同步复制来保证至少一个从库收到日志。此外,从库也可以开启并行复制(MySQL 5.7+)以提高重放效率。
【大白话解释于举例说明】 可以把主从复制想象成一个“课堂笔记”的传递过程:
- 主库是老师,在课堂上讲课并写在黑板上(binlog记录变更)。
- 从库是学生,需要记笔记来复习。
- 学生派了一个人(I/O线程)专门去抄老师的板书:这个人站在讲台边,老师每写一条(binlog事件),他就抄下来(写入自己的笔记本,即relay log)。这个过程中,老师不会等学生抄完才继续讲课(异步)。
- 学生还有另一个人(SQL线程)负责朗读笔记本上的内容并理解(执行SQL),从而记住知识点(更新数据)。如果学生想当小老师(作为其他从库的主库),他还可以在自己的笔记本上再整理一份笔记(记录自己的binlog)。
再举个例子:一个电商网站的主库处理订单,从库用于报表查询。当用户下单时,主库插入一条订单记录,并写入binlog。从库I/O线程立即拉取这条binlog,写入relay log,SQL线程随后执行插入,这样从库就有了新订单数据,报表查询就能看到最新数据(尽管可能有轻微延迟)。
【扩展知识点详解】
- 主从复制的目的
- 读写分离:主库处理写操作,从库处理读操作,提升并发能力。
- 数据备份:从库可作为热备份,防止主库故障。
- 高可用:配合故障转移工具(如MHA、Orchestrator)实现主从切换。
- 数据分析:从库可承担复杂查询,避免影响主库性能。
- 二进制日志(binlog)格式
- STATEMENT:记录原始SQL语句,优点是日志量小,缺点是不确定性函数(如UUID())可能导致数据不一致。
- ROW:记录每行数据的变更,优点是最精确,缺点是日志量大。
- MIXED:混合模式,默认使用STATEMENT,对于不确定语句自动转为ROW。
- 复制类型
- 异步复制:默认方式,主库提交事务后立即返回,不等待从库确认。
- 半同步复制:主库等待至少一个从库收到binlog(写入relay log)后才提交事务,需安装插件
rpl_semi_sync_master和rpl_semi_sync_slave。 - 同步复制:主库等待所有从库执行完毕才提交,性能差,MySQL未实现(可用Group Replication或Galera Cluster)。
- GTID复制
- GTID(全局事务标识符)为每个事务分配唯一ID,简化复制管理和故障转移。基于GTID的复制无需指定binlog文件名和位置,自动定位。
- 并行复制
- MySQL 5.6引入基于库级别的并行复制(不同库的事务可并行)。
- MySQL 5.7引入基于逻辑时钟的并行复制(同一库内事务可并行,但需满足提交顺序)。
- MySQL 8.0进一步优化,支持基于WRITESET的并行复制,提高并发度。
- 复制拓扑
- 一主一从:基础架构。
- 一主多从:常见读写分离。
- 主主复制:互为主从,需避免冲突(一般用于特殊场景)。
- 级联复制:从库再作为其他从库的主库,减轻主库压力。
- 常见问题与优化
- 复制延迟:主库写压力大、从库SQL线程慢、大事务等导致。解决方案:并行复制、优化SQL、拆分大事务。
- 数据一致性:异步复制可能丢数据,半同步复制可缓解。
- 主从切换:需确保数据一致,使用GTID或
master_pos_wait等工具。 - 从库binlog:若从库开启
log_slave_updates,则会记录从库执行的变更,用于链式复制。
- 监控复制状态
SHOW SLAVE STATUS\G:查看从库复制状态,关键字段:Slave_IO_Running、Slave_SQL_Running、Seconds_Behind_Master(延迟秒数)。SHOW MASTER STATUS:查看主库binlog信息。- 通过
performance_schema表(如replication_applier_status)获取更详细统计。
- 复制过滤
- 可在从库配置
replicate-do-db、replicate-ignore-table等规则,过滤不需要复制的数据库或表。
- 可在从库配置
- 安全性考虑
- 主从复制需使用具有
REPLICATION SLAVE权限的用户。 - 建议开启SSL加密复制流量。
- 从库应避免直接写入,防止数据不一致。
- 主从复制需使用具有
理解主从复制流程是MySQL高可用架构的基础,合理配置可提升系统稳定性和扩展性。
分库分表
【问题】 做过MySQL分库分表吗?多大数据量需要分表?分表方案是什么?有遇到过数据倾斜吗?
【参考答案】 分库分表是应对数据库单库单表数据量过大导致性能下降的常见解决方案。关于何时需要分表,业界常用阿里巴巴《Java开发手册》中提到的“单表行数超过500万行或单表容量超过2GB”作为参考,但实际阈值取决于硬件配置、索引大小、InnoDB缓冲池(innodb_buffer_pool_size)等因素。核心判断标准是:当索引无法完全加载到内存,导致频繁磁盘I/O,或表锁/行锁竞争激烈,或备份维护时间过长时,就需要考虑分库分表。
分库分表的方案主要分为垂直拆分和水平拆分,其中水平拆分是应对大数据量的核心手段。常见的水平分片策略包括:
- 范围分片(Range):按数据范围(如时间、ID区间)划分到不同库表。优点是实现简单,扩容方便(只需新增节点)。缺点是容易产生热点数据(如近期数据访问频繁),且数据分布可能不均。
- 哈希分片(Hash):对分片键(如用户ID)进行哈希计算,取模后路由到具体库表。优点是数据分布均匀,避免热点。缺点是扩容困难,通常需要翻倍扩容并迁移数据。
- 一致性哈希(Consistent Hashing):在哈希基础上引入虚拟节点,使得扩容时只需迁移少量数据。适合需要动态扩容的场景。
- 二次分片法:先计算总分片数(库数×表数),取模得到逻辑分片号,再通过分片号除以表数得到库索引,取模得到表索引。这种方案将库和表解耦,便于后期扩容(但翻倍扩容仍会导致数据迁移)。
- 基因法:利用分片键的某些二进制位(基因)决定分片位置,保证同一用户的数据落在同一分片,同时支持跨分片查询的基因嵌入。
- 关系表冗余法:维护一张路由表,记录分片键到具体库表的映射。优点是灵活,支持任意分片规则。缺点是路由表可能成为性能瓶颈,且需要额外维护。
- 剔除公因数法:类似二次分片,但通过数学优化减少数据迁移量。
数据倾斜是指分片后各节点数据量或访问负载差异过大,导致部分节点成为瓶颈。常见原因有:分片键选择不当(如按地区分片但部分地区数据量极大)、哈希算法不均匀、数据特征变化(如某用户数据暴增)。解决数据倾斜的方法包括:重新选择分片键、使用一致性哈希、对超大Key进行二次拆分(如分桶)、动态调整分片规则、定期分析数据分布并手动迁移等。通常用偏斜率(最大数据量-最小数据量)/最小数据量来衡量倾斜程度,一般要求控制在5%以内。
【大白话解释于举例说明】
- 为什么需要分库分表:就像图书馆的书架,如果书太多,一个书架放不下,找书会变慢(索引加载不到内存,要频繁翻硬盘)。或者大家抢同一本书(锁竞争),那就需要把书分散到多个书架(分表)甚至多个房间(分库)。
- 什么时候分:阿里巴巴说的500万行或2GB是个参考,但关键看你的书架(内存)有多大。如果书架足够大,能放下所有书的索引,再多书也能快速找;如果书架小,书一多就得频繁去仓库(磁盘)搬书,速度就慢了。
- 分表方案举例:
- 范围分片:按年份分订单表,2023年的放一张表,2024年的放另一张。优点是每年一张,清晰明了,缺点是今年是热点,大家都查今年的表,这张表压力大。
- 哈希分片:对用户ID取模,比如模8,分成8个表。优点是每个表数据差不多均匀,缺点是如果以后要增加到16个表,数据得重新分布(麻烦)。
- 二次分片:比如我们计划有4个库,每个库8张表,总分片数32。计算
hash(userId) % 32得到逻辑分片号0-31,再通过逻辑分片号 / 8得到库号,逻辑分片号 % 8得到表号。这样每个逻辑分片对应唯一库和表,方便管理。 - 基因法:比如用户ID的后几位作为基因,决定分片。这样同一个用户的订单都会落到同一个分片,便于查询用户的所有订单。
- 数据倾斜:就像分水果时,有的筐装了100个苹果,有的只装了10个,装100个的筐都快压坏了。原因可能是分片键没选好(比如按省份分,广东省的订单特别多)。解决办法可以是换分片键,或者把广东的订单再细分成多个小筐。
【扩展知识点详解】
- 分库分表的触发条件
- 数据量达到千万级以上,且增长迅速。
- 磁盘I/O压力大,缓存命中率下降。
- 数据库连接数不足,或长事务导致锁等待严重。
- 单表备份、DDL操作时间过长。
- 业务需求(如多租户隔离)。
实际评估需结合QPS、TPS、数据增长预测等。
- 垂直拆分与水平拆分
- 垂直拆分:按业务模块将表拆分到不同库(如用户库、订单库),或按列将大表拆分为频繁访问列和扩展列(字段拆分)。
- 水平拆分:将同一张表的数据按规则分散到多个结构相同的表或库中。
- 常见分片策略详解
- 范围分片:
优点:扩容简单(只需新增节点,无需迁移历史数据,除非数据跨范围);适合按时间维度的数据归档。
缺点:热点问题;数据分布可能不均;需要预先规划范围段。
应用场景:日志表、订单表按时间分表。 - 哈希分片:
优点:数据分布均匀;路由算法简单。
缺点:扩容困难(通常需要2倍扩容,数据迁移量大);不支持范围查询(除非使用基因法)。
改进:一致性哈希,通过虚拟节点减少数据迁移量,但实现复杂。 - 一致性哈希:
原理:将哈希值空间组织成环,节点分布在环上,数据落在顺时针最近的节点。引入虚拟节点解决节点不均。
优点:动态扩缩容时只需迁移部分数据。
缺点:实现复杂;仍可能存在数据倾斜,需结合虚拟节点优化。 - 二次分片法:
公式:slot = hash(key) % (dbCount * tableCount);dbIndex = slot / tableCount;tableIndex = slot % tableCount。
优点:库和表解耦,便于管理;可通过调整表数量扩容,但通常也是翻倍。
缺点:翻倍扩容时,原分片数据需要重新分布(所有数据迁移),成本高。 - 基因法:
核心思想:将分片键的某些位(如后几位)作为分片基因,同一实体的相关数据(如用户订单)都落在同一分片。例如用户ID取模1024,订单表也使用用户ID的分片基因,这样用户的所有订单都在同一分片,方便JOIN查询。
优点:支持关联查询;数据局部性好。
缺点:分片键必须包含基因;扩容时基因位数变化可能导致数据迁移。 - 关系表路由:
使用独立的路由表存储分片键到目标库表的映射。
优点:规则灵活,支持任意分片算法,易于动态调整。
缺点:每次查询需额外访问路由表,可能引入性能瓶颈和单点风险;需保证路由表的高可用。
改进:使用缓存(如Redis)缓存路由信息。 - 剔除公因数法:
一种数学优化方法,通过选择互质的分片数量来减少数据迁移,但实际应用较少。
- 范围分片:
- 数据倾斜的成因与处理
- 成因:
- 分片键选择不当(如按省份分片,人口大省数据多)。
- 数据本身分布不均(如某些用户订单量巨大)。
- 哈希算法问题(如取模的模数不是质数,导致某些余数概率高)。
- 范围分片中某些范围数据量过大。
- 监控与衡量:通过统计各分片的数据量、QPS、响应时间,计算偏斜率。偏斜率公式:(最大值-最小值)/最小值。
- 解决方案:
- 重新选择分片键,或使用组合分片键。
- 对超大Key进行二次拆分(如分桶),将单个逻辑键的数据分散到多个物理分片,路由时按子键访问。
- 使用一致性哈希并增加虚拟节点。
- 动态迁移数据,手动调整分片边界。
- 对于范围分片,可以引入更细粒度的分段。
- 使用中间件(如ShardingSphere)提供的自动平衡功能。
- 成因:
- 分库分表带来的挑战
- 跨分片查询:需要聚合多个分片的数据,如分页、排序、分组,通常通过中间件或应用层归并。
- 分布式事务:跨库事务难以保证ACID,需采用柔性事务(如TCC、最终一致性)。
- 主键全局唯一:可使用雪花算法、UUID、数据库自增步长等方式生成。
- 扩容与数据迁移:设计时应考虑平滑扩容方案,如使用一致性哈希、双写迁移、工具迁移(如ShardingSphere-Scaling)。
- SQL支持限制:分库分表中间件对某些复杂SQL的支持有限。
- 业界实践
- MyCAT:基于Cobar的分布式数据库中间件,支持多种分片算法。
- ShardingSphere:Apache顶级项目,提供JDBC、Proxy两种模式,功能强大。
- TiDB:分布式数据库,自动分片,对应用透明。
- Vitess:YouTube开源,用于MySQL水平扩展。
- 何时不推荐分库分表
- 数据量不大,可通过优化索引、升级硬件解决。
- 业务查询极其复杂,跨分片操作多,分库分表后反而性能下降。
- 团队缺乏运维分布式数据库的能力。
此时可考虑使用云数据库的自动读写分离、只读实例等方案。
- 分库分表的设计原则
- 选择合适的分片键,尽量让80%的查询带分片键。
- 避免跨分片事务,尽量设计成单分片内操作。
- 预留扩容空间,如初始分片数设置成2的幂次,便于翻倍扩容。
- 考虑数据生命周期,冷热数据分离。
总之,分库分表是一项系统工程,需要综合评估业务、数据、成本等因素,并选择合适的方案和中间件。数据倾斜是常见问题,需持续监控和调优。
【问题】 分库分表后,id主键怎么处理?
【参考答案】 分库分表后,传统的单库自增主键无法满足全局唯一性要求,因此需要引入分布式ID生成方案。一个优秀的分布式ID生成器应具备全局唯一、趋势递增、高性能、高可用等特点。常见的解决方案包括:
-
数据库号段模式
在专用数据库中维护一个ID生成表,每次批量获取一个号段(如1000个ID)加载到应用内存,用完后再去数据库获取新号段。这种方式解决了单点瓶颈,保证了ID递增,但依赖数据库。 -
Redis生成
利用Redis的原子自增命令INCR/INCRBY生成ID。优点是性能高、有序;缺点是Redis宕机后可能丢失最新ID,且需考虑持久化机制。 -
UUID/GUID
在应用本地生成全球唯一ID,性能极高。但UUID无序、占用空间大(36字符),作为主键会导致B+树索引频繁分裂,性能下降。适合用作业务唯一标识,但不推荐作为数据库主键。 -
雪花算法(Snowflake)
Twitter开源,生成64位长整型ID,由时间戳、机器ID、序列号组成。特点是趋势递增、高性能、不依赖第三方。缺点是强依赖机器时钟,时钟回拨会导致ID重复或服务不可用。 -
其他方案
- 美团的Leaf:基于号段模式和雪花算法,提供高效稳定的ID生成服务。
- 滴滴的Tinyid:基于号段模式,支持HTTP和Java客户端。
- 百度的UidGenerator:基于雪花算法,通过自定义时钟回拨处理。
- Zookeeper:通过znode版本号生成,但性能较低,不常用。
选择方案需结合业务场景:对有序性要求高(如分页排序)可选号段模式或雪花算法;对唯一性要求高且可接受无序可选UUID;对性能要求极高且可接受微小重复概率可选Redis。
【大白话解释于举例说明】
- 数据库号段模式:就像你去粮店买米,如果每次只买一粒,粮店忙不过来(高并发瓶颈)。现在改成一次领一袋(号段),你把这一袋米扛回家慢慢吃(内存中分配),吃完了再去领下一袋。这样粮店的负担就小了。
- Redis生成ID:就像班级里有一个计数器,每次有人要号,老师喊下一个数字(INCR)。优点是快,但万一老师忘了记到哪了(Redis宕机),就乱了。
- UUID:相当于给每个人发一个全球唯一的身份证号,但号码又长又没规律,按这个号去图书馆找书(B+树索引),新书来了只能随便插空,导致书架混乱(页分裂)。
- 雪花算法:像电话号码,前几位是区号(时间戳),中间是分局号(机器ID),最后是用户号(序列号)。在同一时刻,同一分局不会给两个人同一个用户号。这样生成的号码既有顺序,又不会重复。
【扩展知识点详解】
- 分布式ID的核心要求
- 全局唯一:必须保证ID在全局唯一,不能冲突。
- 趋势递增:尽量保持递增,有利于数据库索引性能(B+树页分裂少)。
- 高性能:生成速度要快,延迟低,满足高并发。
- 高可用:服务不能成为单点,需支持集群部署。
- 安全性:不易被猜测,但通常主键不需要。
- 数据库号段模式详解
- 创建ID生成表:
CREATE TABLE id_sequence (biz_type VARCHAR(32), max_id BIGINT, step INT, version INT)。 - 应用通过事务更新
max_id并获取新号段:UPDATE id_sequence SET max_id = max_id + step, version = version + 1 WHERE biz_type = 'order' AND version = old_version。 - 号段加载到内存后,应用内部分配,用完再取。
- 优点:ID有序、可控,无单点瓶颈(可多库轮询)。
- 缺点:需要维护数据库高可用,号段用完时会有数据库访问。
- 创建ID生成表:
- Redis生成ID的注意事项
- 使用
INCR命令,但需考虑Redis持久化(RDB/AOF)可能丢失最近增量。 - 可结合
INCRBY设置步长,配合多节点部署(如每个节点设置不同起始值和步长)。 - Redis宕机恢复后,可通过持久化文件或数据库记录补偿,避免重复。
- 适合流量不大或允许微小间隙的场景。
- 使用
- UUID的改进版本
- UUID有多个版本,常用版本4是随机生成,版本1基于时间戳和MAC地址(有序性稍好,但会暴露MAC地址)。
- 可转化为二进制存储(16字节),减少空间。
- 使用有序UUID(如基于时间戳排序)可缓解索引问题,但仍不如自增ID。
- 雪花算法深度解析
- 标准64位分配:
- 1位符号位:固定0,表示正数。
- 41位时间戳:毫秒级,可用69年(从某个纪元开始)。
- 10位机器ID:可支持1024台机器。
- 12位序列号:同一毫秒内可生成4096个ID。
- 时钟回拨问题处理:
- 若回拨时间短,可等待时间追上再服务。
- 若回拨时间长,需记录最后生成时间,拒绝生成或使用备用方案(如暂停服务、使用ZooKeeper协调)。
- 变体:如使用更多位机器ID、缩短时间戳位数、支持自定义纪元。
- 实现示例:美团的Leaf-snowflake引入Zookeeper管理机器ID,并通过检查时钟回拨解决冲突。
- 标准64位分配:
-
号段模式与雪花算法的对比
方案 优点 缺点 适用场景 号段模式 简单,ID有序,可控 需要维护数据库,号段用完有延迟 中低并发,对顺序要求高 雪花算法 高性能,无网络依赖 依赖时钟,机器ID需管理 高并发,分布式环境 - 业界成熟方案
- 美团Leaf:支持号段模式(Leaf-segment)和雪花算法(Leaf-snowflake),通过HTTP或RPC服务提供。
- 滴滴Tinyid:基于号段模式,提供REST API和Java客户端,支持多数据库冗余。
- 百度UidGenerator:基于雪花算法,使用RingBuffer缓存ID,解决时钟回拨。
- 小米的chronos:基于数据库号段,提供高可用集群。
- 分库分表后主键设计注意事项
- 如果业务不需要全局有序,可接受无序ID(如UUID),但需考虑索引性能。
- 如果业务需要按ID排序,尽量选择趋势递增的方案(如雪花算法)。
- 若分片键本身就是主键,且使用雪花算法,需确保不同分片的ID不会落在同一范围(通常自然满足)。
- 对于复合分片,可能需要联合主键(如分片键+序列ID)。
- 实战中的权衡
- 中小型系统:使用数据库号段模式或雪花算法(自己实现或引入开源工具)。
- 大型系统:部署独立的ID生成服务(如Leaf集群),保证高可用和低延迟。
- 微服务架构:每个服务可使用不同的ID生成策略,但需避免跨服务ID冲突。
- 未来趋势
- 随着云原生发展,分布式ID生成趋向于基础设施化,如提供Sidecar模式的ID生成器。
- 数据库自身演进,如TiDB的全局自增ID、PostgreSQL的序列,可减少应用层负担。
总之,选择主键生成方案需结合业务规模、一致性要求、开发成本等因素综合评估。在实际应用中,最常用的还是雪花算法及其变体,以及号段模式。
redis
内存-单线程
【问题】 Redis是单线程还是多线程?为什么单线程还这么快?Redis有哪些优势?Redis的线程模型是什么?Redis是怎么做数据持久化的?AOF和RDB的原理分别是什么?RDB做快照时会阻塞线程吗?RDB做快照的时候数据能修改吗?Redis是怎么解决在bgsave做快照的时候允许数据修改呢?什么是写前日志与写后日志?
【参考答案】
一、Redis是单线程还是多线程?
- Redis的核心处理(命令执行)是单线程的:从Redis 6.0之前,Redis的主要操作(如读写键值对、执行Lua脚本等)都由主线程串行处理,保证了原子性和数据一致性。在 4.0 之前虽然我们说 Redis 是单线程,也只是说它的网络 I/O 线程以及 Set 和 Get 操作是由一个线程完成的。但是 Redis 的持久化、集群同步还是使用其他线程来完成。
- Redis 6.0引入了多线程I/O:虽然命令执行仍是单线程,但网络I/O读写(如接受请求、发送响应)可以启用多线程,提升并发处理能力,特别是处理大尺寸数据的性能。但核心数据操作依然是单线程。
- 后台任务使用多线程/多进程:例如持久化(RDB的bgsave会fork子进程)、AOF重写、异步删除等操作由子进程或后台线程处理,不阻塞主线程。
二、为什么单线程还这么快?
- 基于内存存储:所有数据存储在内存中,读写速度极快(微秒级),避免了磁盘I/O的瓶颈。
- 非阻塞I/O多路复用:使用epoll(Linux)/kqueue(BSD)等机制,单线程可以高效处理大量并发连接,复用同一个线程处理多个Socket事件。
- 避免上下文切换和锁竞争:单线程模型避免了多线程的线程切换开销和锁竞争,没有死锁风险。
- 数据结构优化:内部数据结构经过精心设计,如哈希表、跳表等,操作高效。
- 纯内存操作加上高效的网络模型,使得Redis能够达到极高的吞吐量(通常可达10万+ QPS)。
三、Redis有哪些优势?
- 极高的性能:基于内存,读写速度快,支持高并发。
- 丰富的数据类型:支持String、Hash、List、Set、Sorted Set、Bitmap、HyperLogLog、地理空间等。
- 原子操作:所有命令都是原子性的,支持事务和Lua脚本。
- 持久化:支持RDB(快照)和AOF(日志)两种持久化方式,保证数据安全。
- 高可用与分布式:支持主从复制、哨兵模式(Sentinel)和集群模式(Cluster),易于扩展。
- 功能丰富:支持过期时间、发布订阅、Lua脚本、Pipeline、事务等。
- 客户端众多:几乎所有语言都有成熟的客户端库。
- 运维友好:配置简单,支持监控命令(如INFO、SLOWLOG等)。
四、Redis的线程模型是什么? Redis的线程模型基于文件事件处理器(File Event Handler),属于单线程Reactor模式。其核心组件:
- 多个Socket连接:客户端连接产生网络事件。
- I/O多路复用程序:使用操作系统提供的多路复用接口(select/epoll/kqueue)监听多个Socket,将就绪的事件放入队列。
- 事件分发器:单线程循环从队列中取出事件,根据事件类型(如可读、可写)调用对应的处理器。
- 事件处理器:包括连接应答处理器、命令请求处理器、命令回复处理器等,实际执行Redis命令逻辑。
这种模型使得Redis能够以单线程高效处理大量并发请求。
五、Redis是怎么做数据持久化的?AOF和RDB的原理分别是什么? Redis提供了两种持久化方式:RDB(Redis Database) 和 AOF(Append Only File)。
- RDB持久化
- 原理:在指定的时间间隔内生成当前数据集的内存快照(snapshot),保存为一个压缩的二进制文件(默认
dump.rdb)。可以通过SAVE(同步阻塞)或BGSAVE(异步后台)命令触发。 - 工作方式:
BGSAVE时,Redis主进程会fork出一个子进程,子进程将内存数据写入临时RDB文件,完成后替换旧文件。主进程继续处理命令,不受影响(通过写时复制技术)。 - 优点:文件紧凑,适合备份、灾难恢复、数据传输;恢复速度快。
- 缺点:可能丢失最后一次快照后的数据;fork子进程可能耗时。
- 原理:在指定的时间间隔内生成当前数据集的内存快照(snapshot),保存为一个压缩的二进制文件(默认
- AOF持久化
- 原理:将每一条写命令以追加的方式写入AOF文件(默认
appendonly.aof)。恢复时通过重新执行文件中的命令来重建数据。 - 工作方式:写命令先写入缓冲区(aof_buf),根据配置的
appendfsync策略同步到磁盘(always/everysec/no)。AOF文件过大时会触发重写(BGREWRITEAOF),通过读取当前内存数据生成最小命令集,替换旧文件。 - 优点:数据更安全(可配置每秒同步),最多丢失1秒数据;文件可读,便于误操作修复。
- 缺点:文件体积通常比RDB大;恢复速度较慢。
- 原理:将每一条写命令以追加的方式写入AOF文件(默认
两者结合
Redis 4.0+支持混合持久化(开启aof-use-rdb-preamble),AOF重写时生成的子文件中,前半部分是RDB格式的快照,后半部分是增量的AOF命令,兼顾了RDB的快速恢复和AOF的数据安全。
六、RDB做快照时会阻塞线程吗?
- SAVE命令:会阻塞主线程,直到快照完成,期间无法处理其他命令,生产环境禁用。
- BGSAVE命令:主线程fork出子进程后,不会阻塞主线程,主线程可以继续处理命令。但fork瞬间会短暂阻塞(复制页表等操作,耗时取决于内存大小)。
- 自动RDB(根据配置文件触发)本质上是执行
BGSAVE,因此也不会长期阻塞主线程。
七、RDB做快照的时候数据能修改吗?
- 对于
BGSAVE,数据可以修改。因为子进程进行快照时,主线程继续执行写命令,修改内存数据。这是通过操作系统的写时复制(Copy-On-Write, COW)技术实现的。 - 对于
SAVE,由于主线程被阻塞,无法修改数据。
八、Redis是怎么解决在bgsave做快照的时候允许数据修改呢?
- 写时复制(COW):当
BGSAVE执行时,主进程fork出一个子进程。fork之后,父子进程共享相同的内存页。如果主进程要修改某个内存页(执行写命令),操作系统会将该页复制一份(分配新物理页),主进程修改副本,子进程仍然使用原来的旧页。这样,子进程看到的是fork时刻的数据快照,而主进程可以继续修改数据。 - 因此,
BGSAVE期间的数据修改不会影响子进程生成的快照一致性,子进程得到的是fork时刻的完整数据视图。
九、什么是写前日志与写后日志? 这是数据库持久化中的两种策略,在Redis中分别对应AOF和RDB的写入时机。
- 写前日志(Write-Ahead Logging, WAL):在修改数据之前先记录日志,这样即使系统崩溃,重启后可以通过日志恢复。在Redis中,AOF可以视为一种写前日志(每次写命令先追加到AOF文件,再执行操作,取决于配置策略)。但严格来说,Redis的AOF是在命令执行后才追加,所以是“写后日志”,但与数据库WAL思想相似:日志持久化先行,保证数据可恢复。
- 写后日志:先修改数据,再记录日志。RDB是写后快照:数据先存在内存,然后周期性生成快照保存到磁盘;AOF在默认配置下也是先执行命令再写入日志(但如果配置
always,则会在命令返回前同步日志,可视为写前)。通常,RDB属于写后,因为它保存的是某个时刻的数据状态,不是操作日志。 - 在Redis中,AOF的写策略:如果使用
appendfsync always,则每次命令执行后会同步日志,相当于写后但立即持久化;如果使用everysec,则是每秒同步一次,可能丢失1秒数据。实际上,AOF日志记录了已经执行的命令,所以是“写后日志”,但它的作用是为了重放命令,与WAL的“写前”有所不同。 - Redis 在写入日志之前,不对命令进行语法检查,所以只记录执行成功的命令,避免出现记录错误命令的情况,而且在命令执行后再写日志不会阻塞当前的写操作。
- 后写日志主要有两个风险可能会发生:数据可能会丢失:如果 Redis 刚执行完命令,此时发生故障宕机,会导致这条命令存在丢失的风险;可能阻塞其他操作:AOF 日志其实也是在主线程中执行,所以当 Redis 把日志文件写入磁盘的时候,还是会阻塞后续的操作无法执行。
【大白话解释于举例说明】
- 单线程:就像只有一个收银员的超市,虽然只有一个收银员,但收银台前的通道(I/O多路复用)能同时关注多个排队顾客,哪个顾客准备好了(有事件),收银员就过去服务。因为收银员动作很快(内存操作),而且顾客付款动作很简单(数据结构简单),所以即便只有一个收银员,也能服务很多顾客。
- 持久化:RDB就像给整个超市拍张照片(快照),拍的时候如果顾客想拿货(修改数据),就给顾客一个复制品(写时复制),照片还是原来的样子。AOF就像超市的收银小票(操作日志),每次交易都记录下来,万一系统崩溃,可以重新按照小票再交易一遍恢复数据。
- 写前/写后日志:写前日志好比先写备忘录再做事,写后日志就是先做事再记备忘录。Redis的AOF是先做事(执行命令)再记(写入日志),但为了安全,可以在做事后立即记(always),类似写后即时。
【扩展知识点详解】
- Redis 6.0多线程I/O:多线程仅用于网络I/O读写(解析命令、发送响应),命令执行依然是单线程,避免了多线程复杂性和锁竞争,同时提高大流量下的吞吐量。
- RDB与AOF的混合模式:从Redis 4.0开始,AOF重写时生成RDB格式的头部,快速加载,再追加后续AOF命令,兼顾两者优点。
- fork子进程的优化:Redis在fork时使用“写时复制”技术,但内存越大fork越耗时,需监控并调整系统参数(如vm.overcommit_memory)。
- AOF的刷盘策略:
appendfsync always安全性高但性能低,everysec是折衷(最多丢1秒数据),no由操作系统决定刷盘,性能最高但风险大。 - 持久化配置建议:通常同时开启RDB和AOF,RDB用于快速恢复和备份,AOF用于减少数据丢失。也可以只开AOF,但需要定期重写。
- Redis的线程模型演化:从单线程到多线程I/O,再到后台任务多线程(如异步删除),体现对现代硬件的利用。
- 数据恢复优先级:当同时有RDB和AOF时,Redis优先使用AOF恢复,因为AOF数据更完整。
- 写时复制的细节:子进程在生成RDB时,如果主进程修改了大量数据,会导致大量内存页复制,可能增加内存开销和CPU压力,需监控内存使用。
- RDB快照的适用场景:适合数据备份、全量复制(主从初次同步)、容灾恢复。
- AOF重写:通过子进程遍历当前内存数据生成新的最小命令集,期间写操作继续追加到旧AOF,同时缓存到新AOF的重写缓冲区,最后合并替换,保证了数据不丢失。
【问题】 为什么要使用redis缓存?
【参考答案】 使用Redis作为缓存,主要是为了提升系统性能和减轻数据库压力。具体原因包括:
- 高速读写:Redis基于内存,读写速度极快(微秒级),远高于磁盘数据库,能够显著降低响应延迟。
- 高并发支撑:单机Redis可以支撑数万到十万级的QPS,有效应对高并发场景,避免数据库成为瓶颈。
- 丰富的数据结构:支持String、Hash、List、Set、Sorted Set等,可以灵活实现各种缓存需求(如计数器、排行榜、会话存储等)。
- 持久化支持:提供RDB和AOF两种持久化方式,保证缓存数据在重启后恢复,兼顾速度与数据安全。
- 分布式与高可用:支持主从复制、哨兵、集群模式,可构建高可用的缓存架构。
- 原子操作:内置原子性操作(如INCR、HSET),适合秒杀、计数器等场景,避免并发问题。
- 淘汰策略:支持多种内存淘汰策略(LRU、LFU、TTL等),自动清理不常用数据,合理利用内存。
【大白话解释于举例说明】 想象你的数据库是一个大仓库,每次取货都要走到仓库深处,很慢。而Redis就像前台的一个小货架,把最常用的商品(热点数据)摆在上面,伸手就能拿到,大大加快了取货速度。同时,这个小货架还能自动整理,把不常用的商品放回仓库(淘汰策略),腾出空间放新的热门商品。
【扩展知识点详解】
- 缓存适用场景:读多写少、数据一致性要求不高的数据(如用户会话、商品详情、配置信息)。
- 缓存常见问题:缓存穿透、缓存击穿、缓存雪崩,以及相应的解决方案(布隆过滤器、互斥锁、过期时间随机化等)。
- Redis与其他缓存产品的对比:后续问题详述。
【问题】 为什么要用 redis 而不用 map/guava 做缓存?
【参考答案】
本地缓存(如ConcurrentHashMap、Guava Cache)和应用内缓存(如Caffeine)与Redis的主要区别在于存储位置、共享性、持久化、分布式支持等方面。选择Redis而非本地缓存的原因如下:
- 多实例共享:Redis是独立服务,可以被多个应用实例共享,实现分布式缓存。而本地缓存每个应用实例有独立的一份,数据不一致,无法全局共享。
- 持久化能力:Redis支持持久化,重启后数据不丢失;本地缓存随应用生命周期消失,重启后需重新加载。
- 集中管理:Redis提供统一的监控、管理、过期策略和淘汰机制,便于运维;本地缓存分散在每台机器,难以统一管理。
- 内存容量:本地缓存受限于单个JVM堆内存,容易导致GC压力;Redis独立部署,可利用更大内存,且支持集群扩展。
- 数据一致性:多实例本地缓存难以保证数据一致性,而Redis作为集中式缓存,能保证所有实例看到相同的数据。
- 丰富功能:Redis支持复杂数据结构、事务、Lua脚本、发布订阅等功能,远超本地缓存。
当然,本地缓存也有优势:无网络开销,访问速度更快;适合单机应用或对一致性要求不高的场景。但分布式系统中,Redis是更合适的选择。
【大白话解释于举例说明】 本地缓存就像每个员工自己口袋里的小本本,记下自己常用的信息,但员工之间不知道彼此记了什么,信息不通。而Redis就像公司前台的一个公用白板,所有员工都能看和写,信息一致且共享。如果员工离职(应用重启),小本本就丢了,但白板还在。
【扩展知识点详解】
- Guava Cache vs Caffeine:Caffeine是高性能的本地缓存库,常用于单机缓存,但仍是本地缓存。
- 多级缓存架构:可同时使用本地缓存(如Caffeine)和Redis,本地缓存命中更快,Redis做二级共享缓存。
- 本地缓存的风险:数据漂移、内存泄漏、GC压力。
【问题】 redis 和 memcached 的区别是什么?
【参考答案】 Redis和Memcached都是流行的内存缓存系统,但Redis功能更强大,主要区别如下:
| 维度 | Redis | Memcached |
|---|---|---|
| 数据结构 | 支持String、Hash、List、Set、Sorted Set、Bitmap、HyperLogLog、地理空间等丰富类型 | 仅支持简单的Key-Value,Value为字符串或二进制数据 |
| 持久化 | 支持RDB和AOF两种持久化方式,可将数据保存到磁盘 | 不支持持久化,重启后数据丢失 |
| 内存管理 | 内存淘汰策略灵活(如LRU、LFU、TTL),可配置最大内存 | 基于Slab分配器,有固定内存块,可能产生内存碎片 |
| 集群模式 | 原生支持Cluster模式,自动分片和高可用 | 不支持集群,需客户端实现一致性哈希或使用第三方代理(如Twemproxy) |
| 复制 | 支持主从复制,可实现读写分离和故障转移 | 不支持复制,无法做高可用 |
| 事务/Lua | 支持事务(MULTI/EXEC)和Lua脚本,保证原子性 | 不支持事务,仅有基本的incr/decr原子操作 |
| 线程模型 | 核心命令处理单线程,但支持多线程I/O(6.0+) | 多线程架构,每个核一个线程,但锁竞争可能影响性能 |
| 适用场景 | 复杂数据结构、需要持久化、分布式缓存、排行榜等 | 简单缓存、纯K-V场景、对性能要求极高且可容忍数据丢失 |
| 性能 | 单机QPS可达10万+,复杂操作稍低 | 纯K-V操作,多线程,吞吐量可能略高(但Redis 6.0多线程I/O后接近) |
总体来说,Redis是功能全面的数据存储(缓存+数据库),Memcached是纯粹的缓存。现代应用首选Redis。
【大白话解释于举例说明】 可以把Redis想象成瑞士军刀,功能多样,能切水果、开瓶、锯木头(丰富数据结构);Memcached就像一把普通水果刀,只能切水果(简单K-V)。Redis会记账(持久化),丢了东西还能找回;Memcached用完就忘,不存档。Redis可以组队(集群)分工合作,Memcached只能单打独斗。
【扩展知识点详解】
- 选型建议:如果需要缓存复杂结构、持久化、高可用,选Redis;如果仅需要简单K-V缓存且追求极致性能,Memcached仍可考虑,但Redis已足够优秀。
- Redis 6.0的多线程I/O使其在大包场景下性能提升,缩小了与Memcached的差距。
- 实际生产环境,Redis生态更完善(客户端、工具、社区),是主流选择。
【问题】 一次redis命令的完整请求通讯过程是怎样的?
【参考答案】 Redis命令的完整请求通讯过程涉及客户端与服务器之间的网络交互、服务器内部的事件处理以及命令的执行与响应。其核心是基于文件事件处理器的单线程Reactor模型(Redis 6.0之前命令执行是单线程,但I/O读写可启用多线程)。整个过程可以分为以下几个步骤:
-
客户端发起连接
客户端通过TCP协议与Redis服务器建立连接(通常使用6379端口)。连接建立后,服务器将该客户端Socket注册到I/O多路复用程序(如epoll)中,等待事件就绪。 -
客户端发送命令
客户端将命令按照RESP(Redis Serialization Protocol)协议进行序列化,然后通过Socket发送到服务器。例如,命令SET key value被编码为*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n。 -
服务器事件循环
Redis服务器的主线程循环调用I/O多路复用函数(如epoll_wait),等待Socket上的可读或可写事件。当客户端的Socket变为可读时,事件被触发。 - 读取命令并解析
- 对于Redis 6.0之前的单线程模型:主线程直接读取Socket中的数据,将数据解析为命令和参数。
- 对于Redis 6.0及以后启用了多线程I/O:主线程将可读的Socket分配给I/O线程子线程,由子线程完成读取和解析,然后将解析好的命令放入队列,主线程再从队列中取出命令执行。这实现了I/O读写的并行化,但命令执行仍然是单线程。
-
执行命令
主线程根据解析出的命令名称,在命令表中查找对应的命令处理函数,然后调用该函数执行。执行过程中直接操作内存数据结构(如哈希表、跳表等),因此速度极快。如果命令需要持久化(如写命令),会根据配置决定是否写入AOF缓冲区或触发RDB。 -
生成响应
命令执行后,生成RESP格式的响应结果(如+OK\r\n或$5\r\nvalue\r\n)。然后将响应数据写入客户端的输出缓冲区。 -
返回响应给客户端
当客户端的Socket变为可写时,Redis通过I/O多路复用触发写事件,将输出缓冲区的数据发送回客户端。同样,多线程I/O模式下可能由I/O线程完成发送。 - 客户端接收响应
客户端接收到响应后,进行解析并返回给上层应用。
整个过程是异步非阻塞的,单个Redis实例可以高效处理成千上万的并发连接。
【大白话解释于举例说明】 可以把Redis处理请求的过程比作一个高效的餐厅服务流程:
- 客户端连接:顾客来到餐厅,找到座位(建立TCP连接)。
- 点餐(发送命令):顾客按照菜单格式(RESP协议)对服务员说:“来一份炒饭”(SET key value)。服务员记下后送到厨房窗口(Socket发送)。
- 厨房事件循环:大厨(主线程)站在窗口前,用眼扫视(epoll)哪个窗口有订单进来。
- 读取菜单:大厨看到窗口有订单,拿起来看(读取数据),如果是多线程I/O模式,会有帮厨(I/O线程)帮忙看菜单,然后把订单递给大厨。
- 炒菜(执行命令):大厨根据菜单炒菜(执行命令),操作食材(内存数据)。
- 装盘(生成响应):炒好后把菜装盘,放在窗口(输出缓冲区)。
- 上菜(返回响应):服务员看到窗口有菜,端给顾客(写事件)。
- 顾客用餐:顾客拿到菜,满意而归。
整个过程只有一个大厨(单线程执行),但通过多个窗口和快速扫视,能同时服务很多顾客。
【扩展知识点详解】
- RESP协议:Redis客户端与服务器通信的序列化协议,支持简单字符串、错误、整数、批量字符串、数组等类型,具有可读性好、解析简单的特点。
- I/O多路复用:Redis利用操作系统提供的多路复用机制(epoll、kqueue、select等)实现单线程处理多个连接,避免了多线程上下文切换和锁竞争。这是Redis高并发的基础。
- Redis 6.0多线程I/O:为了解决大尺寸数据读写时网络I/O可能成为瓶颈的问题,Redis 6.0引入了多线程I/O,将网络读写操作分配给多个线程并行处理,但命令执行依然是单线程,保持了核心数据结构的无锁访问。
- 命令执行原子性:由于单线程执行,每个命令都是原子性的,不存在并发干扰。但多个命令组合需要事务或Lua脚本来保证原子性。
- AOF与复制:写命令执行后,如果需要持久化,会同步或异步写入AOF缓冲区;同时如果开启了主从复制,会将该命令传播给从节点(异步)。
- 输出缓冲区:Redis为每个客户端维护输出缓冲区,如果缓冲区过大可能触发客户端关闭或限制,防止慢客户端影响整体性能。
- 管道(Pipeline):客户端可以将多个命令一次性发送,减少网络往返,服务器会依次执行并返回多个响应,提高批量操作效率。
- 事务与Lua脚本:虽然命令是单线程执行,但事务(MULTI/EXEC)和Lua脚本可以保证多个命令的原子性执行,期间不会被其他命令插入。
- 阻塞命令:如
BLPOP等阻塞命令会挂起当前连接,但不会阻塞其他连接,Redis内部通过特殊机制处理。 - 性能指标:了解此过程有助于分析Redis性能瓶颈,例如网络延迟、命令复杂度、内存操作耗时等。可以通过
INFO命令查看命令统计、慢查询日志等。
数据结构
【问题】 Redis 常见数据结构有哪些?它们分别适用使用场景有哪些?具体怎么用性能最好?
【参考答案】 Redis提供了丰富的数据结构,每种结构都有其独特的内部实现和适用场景。合理选择和使用数据结构可以最大化性能,并节省内存。
一、常见数据结构及其使用场景
- String(字符串)
- 特点:最简单的类型,value可以是字符串、整数或浮点数,最大512MB。
- 常用命令:set,get,decr,incr,mget 等。
- 使用场景:
- 缓存单个值(如JSON序列化的对象、HTML片段)。
- 计数器(INCR、DECR),如文章阅读数、点赞数。
- 分布式锁(SETNX)。
- 存储Session或Token。
- 性能最佳实践:
- 避免存储大字符串(超过10KB),否则会增大内存和网络开销。
- 利用整数自增原子操作实现高性能计数。
- 使用批量操作(MSET/MGET)减少网络往返。
- Hash(哈希)
- 特点:类似Java的HashMap,适合存储对象(多个字段)。内部编码可以是ziplist(小对象)或hashtable。当哈希表的元素个数小于某个阈值时,Redis 会使用一个压缩列表(ziplist)来节省内存。
- 常用命令:hget,hset,hgetall 等。
- 使用场景:
- 存储用户信息、商品详情等结构化数据,可部分更新(HGETALL、HSET)。
- 实现购物车(用户ID为key,商品ID为field,数量为value)。
- 性能最佳实践:
- 控制Hash中字段数量(建议小于1000),避免使用大Hash导致内存和操作开销。
- 使用HMSET/HGETALL批量操作,但注意HGETALL可能返回大量数据,需评估网络开销。
- 对于经常需要获取所有字段的场景,Hash比String序列化更高效。
- List(列表)
- 特点:双向链表,支持左右两端插入弹出。内部编码可以是quicklist(Redis 3.2后)。Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。另外可以通过 lrange 命令,就是从某个元素开始读取多少个元素,可以基于 list 实现高性能分页,可以做类似微博那种下拉不断分页的东西(一页一页的往下走),性能高。
- 常用命令:lpush,rpush,lpop,rpop,lrange 等
- 使用场景:
- 消息队列(LPUSH + BRPOP实现阻塞队列)。
- 最新动态/排行榜(LPUSH + LTRIM保留最新N条)。
- 栈(LPUSH/LPOP)或队列(LPUSH/RPOP)。
- 微博的关注列表,粉丝列表,消息列表等。
- 性能最佳实践:
- 避免对大列表进行索引访问(如LINDEX),时间复杂度O(N)。
- 使用LRANGE分页时,注意范围不要太大。
- 对于消息队列,使用阻塞命令(BRPOP)减少轮询开销。
- Set(集合)
- 特点:无序唯一集合,支持交集、并集、差集操作。内部编码可以是intset(整数集合)或hashtable。集合中的元素没有先后顺序。可以基于 set 轻易实现交集、并集、差集的操作。
- 常用命令:sadd,spop,smembers,sunion 等
- 使用场景:
- 标签系统(如用户兴趣标签)。
- 共同好友/关注(SINTER)。
- 抽奖(SRANDMEMBER、SPOP)。
- 在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。
- 性能最佳实践:
- 小整数集合使用intset节省内存。
- 交集、并集计算时,尽量在小集合上操作,可将大集合暂存为临时Set。
- 避免存储大Set,可能导致阻塞(交集运算复杂度高)。
- Sorted Set(有序集合)
- 特点:每个元素关联一个分数(score),按分数排序。内部编码是ziplist或skiplist。sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,底层实现使用跳表(skip list)和哈希表。
- 常用命令:zadd,zrange,zrem,zcard 等
- 使用场景:
- 排行榜(ZADD + ZRANGE/ZREVRANGE)。在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
- 延迟队列(将任务作为元素,时间戳作为分数,通过ZRANGEBYSCORE获取到期任务)。
- 范围查找(如根据权重筛选数据)。
- 性能最佳实践:
- 控制元素数量,skiplist操作复杂度O(logN),适合大数据量。
- 使用ZINCRBY更新分数,原子操作。
- 分页查询时使用ZRANGE带WITHSCORES获取分数。
- Bitmap(位图)
- 特点:基于String类型的位操作,每个bit代表一个状态。
- 使用场景:
- 用户签到(每天一个bit)。
- 活跃用户统计(SETBIT/BITCOUNT)。
- 布隆过滤器(配合SETBIT)。
- 性能最佳实践:
- 适合海量数据的布尔型统计,内存占用极小。
- 使用BITOP进行位运算(与、或、非)。
- 注意offset不要过大,否则可能导致内存浪费。
- HyperLogLog(基数统计)
- 特点:概率算法,用于统计唯一值(如UV),误差约0.81%。
- 使用场景:
- 统计独立IP数、页面UV。
- 近似去重计数。
- 性能最佳实践:
- 每个HyperLogLog占用12KB内存,适合大基数统计。
- 使用PFADD/PFCOUNT/PFMERGE命令。
- Geo(地理空间)
- 特点:基于Sorted Set实现,存储经纬度信息,支持距离计算、范围查询。
- 使用场景:
- 附近的人/地点(GEORADIUS)。
- 地理位置存储与检索。
- 性能最佳实践:
- 内部使用Sorted Set,所以性能与Zset相当。
- 注意单位转换,使用合适的精度。
- Stream(流)
- 特点:类似消息日志,支持持久化、消费者组、ACK机制,是Redis 5.0引入的专门消息队列结构。
- 使用场景:
- 消息队列(取代List/PubSub)。
- 事件溯源、日志存储。
- 性能最佳实践:
- 合理设置消息最大长度(XADD MAXLEN)。
- 使用消费者组实现负载均衡和消费确认。
二、通用性能最佳实践
- 选择合适的编码:Redis会根据数据大小和数量自动选择内部编码(如ziplist、hashtable、skiplist),也可以配置阈值优化内存。
- 避免大Key:大Key会导致阻塞、内存不均、网络开销大。可将大Hash拆分为多个小Hash,或将大String分块。
- 合理设置过期时间:为缓存数据设置TTL,避免内存无限增长。
- 使用批量操作:如MSET/HMSET、PIPELINE、Lua脚本减少网络RTT。
- 监控与优化:使用
MEMORY USAGE命令分析key内存占用,使用SLOWLOG定位慢命令。 - 数据结构选择原则:能用Hash不用String(存储对象),能用Set不用List(去重),能用Zset不用List(排序)。
- 使用连接池:客户端复用连接,减少连接开销。
【大白话解释于举例说明】
- String:就像一个个小卡片,可以写数字、文字,适合存简单值。比如文章的阅读量,用INCR就自动加1,超快。
- Hash:像一份档案袋,里面有姓名、年龄、地址等多个字段。要改其中一项,不用整个换档案袋,直接改那一项就行。比如用户资料。
- List:像一条双向传送带,左边放进去,右边取出来。适合做消息队列,或者保存最新评论列表。
- Set:像一个标签盒,里面的标签都是唯一的,可以快速知道两个盒子的共同标签。比如用户兴趣交集。
- Sorted Set:像排行榜,每个人有分数,按分数高低排队。比如游戏积分榜,更新分数自动排序。
- Bitmap:像一长串二进制灯,每个灯亮(1)或灭(0)。适合记录用户是否签到,1亿用户只需12MB内存。
- HyperLogLog:像估算人数的大概计数器,告诉你今天大约有多少人访问过,误差很小但很省内存。
- Geo:像地图坐标,能计算两点的距离,找出附近的人。
- Stream:像流水账本,每条记录有顺序,可以分组消费,就像Kafka简化版。
【扩展知识点详解】
- 内部编码优化:
- ziplist:紧凑存储,适用于小数据量,节省内存。例如Hash字段少于512个且每个值小于64字节时使用ziplist。
- skiplist:跳表,用于有序集合,支持快速范围查询。
- intset:整数集合,当Set全是整数且数量不多时使用。
可通过object encoding key查看编码。
-
内存淘汰策略:当内存满时,Redis支持多种淘汰策略(volatile-lru, allkeys-lru等),需根据业务选择。
-
Pipeline(管道):将多个命令打包发送,减少网络延迟,性能提升明显。但注意管道中命令无原子性。
-
Lua脚本:将多个命令封装成原子操作,减少网络开销,适合复杂业务逻辑。
-
事务(MULTI/EXEC):保证一批命令原子执行,但不支持回滚。
- 大Key危害与处理:
- 扫描大key:使用
redis-cli --bigkeys。 - 删除大key:使用
UNLINK(异步删除)避免阻塞。
- 扫描大key:使用
-
数据结构的选用基准测试:建议结合业务实际数据量进行压测,选择最优数据结构。
- Redis模块:如RedisBloom(布隆过滤器)、RedisTimeSeries等,扩展更多数据结构。
【问题】 说说Redis哈希槽的概念?为什么这么设计?优势是什么?能解决什么问题?
【参考答案】
Redis集群(Cluster)采用哈希槽(Hash Slot)机制来实现数据分片。整个集群共有16384个哈希槽,每个键通过CRC16(key) % 16384计算出所属的槽,然后将这些槽分配给集群中的多个主节点(每个节点负责一部分槽)。这种设计使得数据分布与节点解耦,极大简化了集群的扩展和故障转移。
一、为什么这么设计? 传统的分布式缓存系统常采用一致性哈希(如Memcached客户端实现),虽然也能实现数据分布,但在节点增删时,数据迁移的范围较大,且需要客户端维护复杂的路由算法。Redis选择哈希槽的主要考虑:
- 简化数据迁移:当增加或删除节点时,只需将一部分槽从旧节点迁移到新节点,而不是重新计算所有键的映射。迁移的粒度是“槽”,而不是单个键,大大降低了数据重分布的复杂度。
- 解耦数据和节点:通过引入“槽”这一中间层,键与节点的关系变成“键→槽→节点”,使得节点可以动态变化而不影响键的哈希计算。
- 易于实现集群管理:集群控制节点(如
redis-cli --cluster)可以轻松地执行reshard操作,将槽从高负载节点移出,实现负载均衡。 - 客户端路由简单:客户端只需要知道槽与节点的对应关系(可从任意节点获取),就能直接计算出目标节点,无需复杂的哈希环查找。
二、优势是什么?
- 数据分布均匀:CRC16算法将键均匀映射到16384个槽,且槽的分配可以人为控制,避免一致性哈希可能出现的分布不均。
- 动态扩容/缩容方便:只需重新分配槽的归属,而无需改变键的哈希方式。迁移过程中,集群仍可对外提供服务,对业务影响小。
- 细粒度的负载均衡:槽的数量远大于节点数,可以通过移动少量槽来调整各节点的负载,实现平滑的负载均衡。
- 高效的故障转移:当主节点故障时,其从节点接管整个槽集合,而不是部分数据,简化了数据一致性处理。
- 支持多键操作限制:Redis集群要求多键操作(如交集、并集)必须位于同一个槽内,哈希槽设计通过
hash tags机制允许将相关键强制映射到同一槽,从而支持跨键事务。
三、能解决什么问题?
- 数据分片问题:解决单机内存容量有限的问题,将数据分散到多个节点,实现水平扩展。
- 节点动态变化时的数据重分布问题:在增加或删除节点时,只需迁移槽,避免全量数据重新哈希,减少迁移成本和系统中断时间。
- 集群状态一致性问题:通过槽分配信息(在集群节点间通过Gossip协议同步),确保所有节点和客户端都能快速获取最新的槽映射表。
- 客户端路由复杂性问题:客户端可以缓存槽映射表,直接定位节点,无需代理层,降低请求延迟。
【大白话解释于举例说明】 可以把Redis集群想象成一个大型图书馆,有多个书库(节点)。书如何分配到哪个书库呢?不是直接按书名分配,而是先把所有可能的书名编号(比如0到16383个编号),每个编号就是一个“哈希槽”。每本书(键)通过一个公式(CRC16)计算得到一个编号,然后就知道它该去哪个编号的书架。每个书库负责管理一批编号的书架。
- 为什么这么设计? 如果直接按书名首字母分,新增一个书库时,好多书都得重新搬(一致性哈希也会搬一部分)。但用编号书架,新增书库时,只需要把某些编号的书架整个搬到新书库,不需要每本书单独计算。搬书架时,其他书架还能正常借阅。
- 优势:搬书架容易,负载均衡灵活(比如1号书库太满,可以挪几个书架到2号),读者(客户端)只需要记住“哪个编号在哪个书库”的清单,就能直接找到书。
- 能解决什么问题:解决了书库扩容时大规模搬书的麻烦,也解决了读者找书时需要知道所有书库位置的问题。
【扩展知识点详解】
- 哈希槽的数量为什么是16384?
- CRC16算法产生16位输出,即0-65535,但Redis选择了16384(2^14)。原因:
- 节点间通过心跳包传递槽信息,每个槽用一个bit表示(0/1表示是否由本节点负责),16384个槽需要2KB(16384/8=2048字节)的空间,而65535个槽需要8KB,心跳包过大。
- 通常集群节点数不会超过1000,16384个槽足够均匀分布。
- 减少位图大小,提高网络传输效率。
- CRC16算法产生16位输出,即0-65535,但Redis选择了16384(2^14)。原因:
- 哈希标签(Hash Tag)
- 如果希望某些键(如
user:1001:name和user:1001:age)落入同一槽以便执行多键操作,可以使用哈希标签:键中包含{...},Redis只计算括号内内容的哈希值。例如user:{1001}:name和user:{1001}:age都会根据1001计算槽,保证它们在同一个槽。
- 如果希望某些键(如
- 槽迁移过程
- 迁移由集群管理工具(如
redis-cli --cluster reshard)发起,源节点将槽中的键逐步发送给目标节点,期间客户端访问该槽时,可能收到ASK重定向,需先向目标节点询问。 - 迁移过程中,键仍可读写,只是部分键可能已被迁移,需要特殊处理(
ASKING命令)。
- 迁移由集群管理工具(如
- 客户端如何定位键?
- 客户端从集群节点获取槽映射表(通过
CLUSTER SLOTS或CLUSTER NODES),缓存到本地。计算键的哈希槽后,直接与对应节点通信。如果节点变更(如故障转移),客户端会收到MOVED重定向,并更新缓存。
- 客户端从集群节点获取槽映射表(通过
-
哈希槽与一致性哈希的对比
维度 Redis哈希槽 一致性哈希 数据分布粒度 槽(预定义固定数量) 节点(虚拟节点) 增删节点影响 只需迁移槽,影响范围可控 部分键重新映射,范围与虚拟节点数有关 实现复杂度 集群内建支持,客户端简单 依赖客户端实现,需维护哈希环 负载均衡 可手动迁移槽调整 自动但可能不均 多键操作支持 通过哈希标签 难以保证 -
槽分配与集群规模
槽总数固定,节点数可以远少于槽数。每个节点可以负责多个槽,最小分配单位是一个槽。因此集群最大节点数为16384(理论),但实际受网络和性能限制,建议不超过1000。 -
槽迁移对性能的影响
迁移过程中,源节点需要遍历槽内的所有键,逐个发送,可能占用CPU和网络。但迁移可控制速度(通过redis-cli --cluster的--cluster-replace和--cluster-timeout等选项),尽量减少对业务的影响。 - 槽信息的同步
集群节点通过Gossip协议定期交换状态,包括槽分配信息。每个节点都保存完整的槽映射表,确保任何节点都能正确重定向客户端。
【问题】 怎么用Redis实现消息队列?如何实现延时队列?用Java举例。
【参考答案】
一、使用Redis实现消息队列 Redis提供了多种方式实现消息队列,常见的有List、Pub/Sub和Stream,各有优缺点。
- 基于List实现消息队列 利用List的LPUSH(左推)和RPOP(右弹)或阻塞版本BRPOP,可以构建一个简单的点对点队列。
- 生产者:使用
LPUSH将消息插入队列头部。 - 消费者:使用
BRPOP从队列尾部阻塞弹出,实现实时消费。 - 优点:简单易用,支持阻塞读取,适合轻量级场景。
- 缺点:消息无持久化,消费者宕机可能导致消息丢失;不支持多消费组(多个消费者竞争消费,每条消息只被一个消费者获取)。
- 基于Pub/Sub实现消息队列 利用Redis的发布订阅模式,生产者向频道发布消息,所有订阅该频道的消费者都能收到。
- 生产者:
PUBLISH channel message - 消费者:
SUBSCRIBE channel - 优点:支持广播,一对多通信。
- 缺点:消息不持久化,消费者离线期间的消息会丢失;可靠性差,没有ACK机制。
- 基于Stream实现消息队列(推荐) Redis 5.0引入的Stream数据类型,专为消息队列设计,支持持久化、消费者组、ACK确认等。
- 生产者:使用
XADD向Stream添加消息,每个消息有唯一ID。 - 消费者:使用
XREAD或XREADGROUP读取消息,支持阻塞读取。消费者组可实现负载均衡,消息可ACK确认。 - 优点:持久化(可配置),支持多消费组,消息可追溯,类似Kafka的消费模型。
- 缺点:相对复杂,需要理解消费者组概念。
二、如何实现延时队列 延时队列指消息不是立即被消费,而是在指定时间后才可消费。Redis可以通过Sorted Set实现延时队列。
实现原理:
- 将消息内容作为Sorted Set的成员(member),将期望的执行时间戳(如未来时间)作为分值(score)。
- 消费者定时(或轮询)执行
ZRANGEBYSCORE命令,获取当前时间戳之前的所有成员(即到期的消息),然后处理这些消息,并从Sorted Set中移除(使用ZREM)。 - 为防止多消费者竞争,可以使用Lua脚本保证原子性,或采用单消费者轮询后分发。
步骤:
- 生产者:
ZADD delay-queue <future_timestamp> <message_json> - 消费者:循环执行:
- 获取当前时间戳
now - 执行
ZRANGEBYSCORE delay-queue 0 now WITHSCORES LIMIT 0 10获取最多10条到期消息。 - 遍历每条消息,处理业务逻辑。
- 处理成功后,使用
ZREM delay-queue <message>移除消息。 - 如果处理失败,可根据业务决定是否重试(可重新添加并更新score为下次重试时间)。
- 获取当前时间戳
三、Java代码示例
- 基于List的简单队列 ```java import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool;
public class ListQueueExample { private static final String QUEUE_KEY = “myqueue”;
// 生产者
public static void produce(String message) {
try (Jedis jedis = new Jedis("localhost", 6379)) {
jedis.lpush(QUEUE_KEY, message);
}
}
// 消费者(阻塞方式)
public static void consume() {
try (Jedis jedis = new Jedis("localhost", 6379)) {
while (true) {
// 阻塞直到有消息,超时0表示一直阻塞
List<String> messages = jedis.brpop(0, QUEUE_KEY);
// messages结构:[QUEUE_KEY, message]
System.out.println("Received: " + messages.get(1));
// 处理业务逻辑...
}
}
}
public static void main(String[] args) {
// 启动生产者线程
new Thread(() -> produce("Hello")).start();
// 启动消费者
consume();
} } ```
- 基于Stream的消息队列(使用Jedis) ```java import redis.clients.jedis.*; import java.util.Map; import java.util.HashMap;
public class StreamQueueExample { private static final String STREAM_KEY = “mystream”; private static final String GROUP_NAME = “mygroup”; private static final String CONSUMER_NAME = “consumer1”;
public static void produce(String message) {
try (Jedis jedis = new Jedis("localhost", 6379)) {
Map<String, String> map = new HashMap<>();
map.put("data", message);
// 添加消息,*表示自动生成ID
String id = jedis.xadd(STREAM_KEY, null, map);
System.out.println("Produced: " + id);
}
}
public static void consume() {
try (Jedis jedis = new Jedis("localhost", 6379)) {
// 创建消费组(如果不存在)
try {
jedis.xgroupCreate(STREAM_KEY, GROUP_NAME, "0-0", true);
} catch (Exception e) {
// 组可能已存在
}
while (true) {
// 读取消息,每次最多1条,阻塞5000毫秒
Map.Entry<String, List<StreamEntry>> entry = jedis.xreadGroup(
GROUP_NAME, CONSUMER_NAME, 1, 5000, true,
new StreamEntryID(), new StreamEntryID()
);
if (entry != null) {
List<StreamEntry> entries = entry.getValue();
for (StreamEntry se : entries) {
System.out.println("Received: " + se.getFields());
// 处理业务逻辑...
// 确认消息
jedis.xack(STREAM_KEY, GROUP_NAME, se.getID());
}
}
}
}
}
public static void main(String[] args) {
// 启动生产者
new Thread(() -> produce("Hello Stream")).start();
// 启动消费者
consume();
} } ```
- 基于Sorted Set的延时队列 ```java import redis.clients.jedis.Jedis; import redis.clients.jedis.Tuple; import java.util.Set;
public class DelayQueueExample { private static final String DELAY_KEY = “delayqueue”;
// 生产者:添加延时消息,delaySeconds为延时秒数
public static void produce(String message, int delaySeconds) {
try (Jedis jedis = new Jedis("localhost", 6379)) {
long score = System.currentTimeMillis() + delaySeconds * 1000L;
jedis.zadd(DELAY_KEY, score, message);
}
}
// 消费者:轮询到期消息
public static void consume() {
try (Jedis jedis = new Jedis("localhost", 6379)) {
while (true) {
long now = System.currentTimeMillis();
// 获取当前时间之前的所有消息,最多10条
Set<Tuple> messages = jedis.zrangeByScoreWithScores(DELAY_KEY, 0, now, 0, 10);
for (Tuple tuple : messages) {
String message = tuple.getElement();
// 尝试移除(原子操作,防止多消费者重复消费)
long removed = jedis.zrem(DELAY_KEY, message);
if (removed > 0) { // 成功移除,代表获得了该消息
System.out.println("Processing: " + message);
// 处理业务...
} else {
// 可能已被其他消费者取走,忽略
}
}
// 暂停一小段时间再轮询,避免空转
try {
Thread.sleep(100);
} catch (InterruptedException e) {
break;
}
}
}
}
public static void main(String[] args) {
// 添加一个延时5秒的消息
produce("Delayed Hello", 5);
// 启动消费者
consume();
} } ```
改进:为防止轮询压力过大,可以使用ZRANGEBYSCORE和ZREMRANGEBYSCORE结合Lua脚本实现原子操作,或者使用定时任务(如ScheduledExecutorService)代替无限循环。
【大白话解释】
- 消息队列:就像快递柜,生产者往柜子里放包裹(消息),消费者从柜子里取包裹。List就是简单的单格柜子(一条消息只能被一个人取走),Pub/Sub是广播喇叭(所有人都能听到),Stream是带编号的包裹流水线,可以分组取货。
- 延时队列:就像预约寄件,你约定明天下午3点来取件。快递员(消费者)每隔一段时间查看预约记录(Sorted Set),把时间到的包裹拿出来处理。
【扩展知识点】
- List实现队列的注意事项:
- 使用
BRPOP可以避免频繁轮询,但客户端需处理阻塞中断。 - 消息可能丢失(消费者处理前宕机),可配合备份List或ACK机制(如先处理完再
RPOPLPUSH备份到另一个List)。
- 使用
- Stream的详细特性:
- 消息ID由时间戳和序列号组成,支持范围查询。
- 消费者组内负载均衡,每个消息只分配给组内一个消费者。
XPENDING和XCLAIM可处理未ACK的消息(死信队列)。
- 延时队列的可靠性:
- 多消费者竞争时,需保证原子性(可用Lua脚本:
ZRANGEBYSCORE+ZREM一起执行)。 - 若处理失败,可将消息重新加回延时队列并设置新的重试时间。
- 考虑使用
Redisson等封装好的框架,它提供了RDelayedQueue基于Redis的延时队列实现。
- 多消费者竞争时,需保证原子性(可用Lua脚本:
- 性能考量:
- 延时队列轮询频率应权衡延迟和CPU,可使用
ZRANGEBYSCORE配合LIMIT限制获取条数。 - 对于高吞吐场景,Stream比List更可靠。
- 延时队列轮询频率应权衡延迟和CPU,可使用
- 客户端选择:
- Jedis:同步阻塞客户端,简单易用。
- Lettuce:支持异步和响应式,连接池管理更优。
- Redisson:封装了分布式对象和服务,包括队列、延迟队列等,简化开发。
内存淘汰
【问题】 Redis 过期键的删除策略有哪几种?什么情况下用哪种最优?怎么设置删除策略?
【参考答案】 Redis 对于过期键的删除主要有三种策略:定时删除、惰性删除、定期删除。但 Redis 实际采用的是惰性删除与定期删除相结合的策略。
一、三种删除策略详解
- 定时删除
- 原理:在设置键的过期时间的同时,创建一个定时器,当过期时间到达时,立即执行删除操作。
- 优点:对内存最友好,过期键能第一时间被清理,释放内存。
- 缺点:对 CPU 不友好。如果大量键同时过期,会占用大量 CPU 时间处理删除任务,可能影响 Redis 的正常响应。此外,维护大量定时器本身也有开销。
- Redis 未采用此策略,因为其 CPU 开销不可控。
- 惰性删除
- 原理:当客户端访问一个键时,先检查该键是否已过期,若过期则删除该键,然后返回空;若未过期则正常返回。
- 优点:对 CPU 友好,只在访问时进行删除,不会额外占用 CPU。
- 缺点:对内存不友好。如果一个键过期后从未被访问,它将一直占用内存,可能导致内存泄漏。
- Redis 采用此策略作为基础,确保过期键在被访问时得到清理。
- 定期删除
- 原理:每隔一段时间(如每秒 10 次),程序随机抽取一部分设置了过期时间的键,检查是否过期,若过期则删除。
- 优点:是前两种策略的折中。通过限制删除操作的时长和频率,既减少了对 CPU 的影响,又能主动清理过期键,避免内存大量堆积。
- 缺点:难以确定最佳执行频率。频率太高则 CPU 压力大,太低则惰性删除无法覆盖的过期键可能积累。
- Redis 采用此策略,通过后台任务定期执行,与惰性删除配合。
二、Redis 实际采用的策略:惰性删除 + 定期删除
- 惰性删除保证了每次访问时过期键的及时清理。
- 定期删除作为补充,周期性地扫描并删除那些长期未被访问的过期键,防止内存无限增长。
- 两者结合,使得 Redis 在 CPU 和内存之间取得了良好的平衡。
三、什么情况下用哪种最优?
- 组合策略是 Redis 的默认选择,适用于绝大多数场景。
- 对内存要求极高,希望过期键尽快释放内存:可以适当调高定期删除的执行频率(增大
hz参数),但会消耗更多 CPU。 - 对 CPU 要求极高,且内存相对充足:可以降低
hz参数,减少定期删除的频率,让惰性删除作为主要手段,但需注意内存堆积风险。 - 极端场景如大量短生命周期键(如会话数据):可调高
hz并配合内存淘汰策略(如volatile-lru)使用。
通常默认配置(hz=10)已经足够,无需修改。
四、怎么设置删除策略? Redis 没有直接提供开关来选择只用某一种策略,但可以通过以下方式调整删除行为:
-
调整定期删除频率
通过修改redis.conf中的hz参数(或运行时使用CONFIG SET hz)来改变后台任务的执行频率。hz默认值为 10,取值范围 1~500。数值越大,定期删除执行越频繁,过期键被清理得越及时,但 CPU 开销也越大。 -
设置内存淘汰策略
当内存达到maxmemory限制时,Redis 会触发内存淘汰,这虽然不是专门的过期键删除策略,但可以影响过期键的清理。例如maxmemory-policy设置为volatile-lru会优先淘汰已设置过期时间的键(包括已过期和未过期)。可以通过maxmemory设置内存上限,通过maxmemory-policy选择淘汰算法。 -
手动删除
可以使用DEL或UNLINK命令显式删除已知的过期键,但一般不作为自动策略。 -
监控与调优
通过INFO stats中的expired_keys指标观察过期键删除数量,结合 CPU 和内存使用情况调整hz或淘汰策略。
【大白话解释于举例说明】
- 定时删除:好比每个垃圾袋上装了个闹钟,时间一到就自动爆炸(删除),虽然干净但闹钟多了太吵(CPU 忙)。
- 惰性删除:好比只有当你走到垃圾袋旁边时,才顺手把它扔掉。如果永远没人路过,垃圾就永远堆着。
- 定期删除:好比清洁工每隔一段时间来巡视一次,随机捡起一些垃圾扔掉,既不会太累,也能保持基本整洁。
- Redis 的做法:既有人路过时顺手扔(惰性),又有清洁工定时来扔(定期),屋子既不会太脏,也不会累着清洁工。
【扩展知识点详解】
- 定期删除的实现细节:
- 由
serverCron调用activeExpireCycle函数,每次执行会遍历所有数据库,随机抽取 20 个设置了过期时间的键,删除其中过期的,并统计过期比例。若过期比例超过 25%,则继续循环抽取删除,直到比例低于 25% 或总耗时超过 25ms。这样既保证了清理效率,又防止长时间阻塞主线程。
- 由
hz的作用范围:- 除了过期键删除,
hz还影响关闭超时客户端、更新统计信息、执行 lazy free 等后台任务。因此调整hz需综合考虑。
- 除了过期键删除,
- 内存淘汰策略与过期键的关系:
- 当 Redis 内存达到
maxmemory且设置了淘汰策略时,可能会主动删除过期键(如果策略针对 volatile 类型)。但过期键删除是由定时任务和惰性删除触发,淘汰是在内存紧张时触发,两者不同。
- 当 Redis 内存达到
- 主从复制下的过期键处理:
- 从库不会主动删除过期键,而是依赖主库在键过期时发送
DEL命令。如果从库被提升为主库,会重新计算过期时间并执行正常删除。
- 从库不会主动删除过期键,而是依赖主库在键过期时发送
- 持久化中的过期键:
- RDB 文件生成时不会包含已过期键;AOF 文件中,键过期时会追加一条
DEL命令,AOF 重写时会忽略过期键。
- RDB 文件生成时不会包含已过期键;AOF 文件中,键过期时会追加一条
- 如何查看当前
hz值:- 使用
CONFIG GET hz命令。
- 使用
- 优化建议:
- 如果业务中有大量键在同一时刻过期(如缓存同时失效),可能导致瞬间 CPU 飙升。可考虑在设置过期时间时增加随机偏移量,避免集中过期。
- 对于需要严格定时清理的场景,可结合 Redis 的键空间通知(keyspace notifications)或外部调度器实现精确控制。
通过合理配置和监控,可以确保 Redis 过期键的删除既高效又稳定。
【问题】 Redis 内存回收算法有哪些?底层分别是怎么实现的?怎么选择并设置合适的回收算法?
【参考答案】
Redis 的内存回收算法实际上指的是内存淘汰策略,即当 Redis 使用的内存达到 maxmemory 上限时,如何选择要删除的键以释放内存。Redis 提供了多种淘汰策略,分别基于 LRU、LFU、随机、TTL 等算法。
一、Redis 内存淘汰策略
Redis 8 种淘汰策略(通过 maxmemory-policy 配置):
- noeviction:默认策略。不淘汰任何键,当内存不足时,写操作返回错误(如
OOM command not allowed),读操作正常。 - volatile-lru:在设置了过期时间的键中,使用近似 LRU 算法淘汰最近最少使用的键。
- allkeys-lru:在所有键中(包括未设置过期时间的),使用近似 LRU 算法淘汰最近最少使用的键。
- volatile-lfu:在设置了过期时间的键中,使用 LFU 算法淘汰访问频率最低的键(Redis 4.0 引入)。
- allkeys-lfu:在所有键中,使用 LFU 算法淘汰访问频率最低的键。
- volatile-random:在设置了过期时间的键中,随机淘汰键。
- allkeys-random:在所有键中,随机淘汰键。
- volatile-ttl:在设置了过期时间的键中,淘汰剩余存活时间(TTL)最短的键(越早过期的越先被淘汰)。
二、底层实现原理
- 近似 LRU 算法(LRU: Least Recently Used)
- 不是精确的 LRU:Redis 没有维护全局的按访问时间排序的链表,而是采用近似 LRU,通过随机采样和淘汰池来模拟。
- 实现:
- 每个键对象内部维护一个 24 位的
lru字段,记录该键最后一次被访问的时间戳(秒级精度)。 - 当需要淘汰时,执行以下步骤:
- 每个键对象内部维护一个 24 位的
- 从待淘汰的键集合中(根据策略是 volatile 还是 allkeys)随机抽取
maxmemory-samples个键(默认 5 个),放入候选池。 - 从候选池中选择
lru时间最早的键(即最近最少使用)进行淘汰。 - 如果本次淘汰后内存仍不足,继续采样并比较。 - Redis 3.0 之后引入了淘汰池(pool)优化:每次淘汰时,将采样的键放入一个大小固定的池中,池中保持按 lru 时间排序,淘汰时取池中时间最早的,同时将新采样的键与池中键比较,保留更优的。这样可以提高淘汰的精确度,近似真正的 LRU。
- LFU 算法(LFU: Least Frequently Used)
- Redis 4.0 引入,基于访问频次淘汰。
- 每个键对象的
lru字段在 LFU 模式下被拆分为两部分:高 16 位存储上次衰减时间(分钟级),低 8 位存储访问频次(counter)。 - 频次更新:每次访问键时,counter 增加(不是简单 +1,而是基于概率对数增长,使高频和低频区分度合理)。
- 频次衰减:counter 会随时间衰减,衰减因子可配置(
lfu-decay-time),避免长期不访问的键因历史高频而一直保留。 - 淘汰时:随机采样,选择 counter 最小的键淘汰(近似 LFU)。
-
随机淘汰 直接随机选择键淘汰,实现简单,开销小,但无法保证淘汰的是冷数据。
- TTL 淘汰
- 对设置了过期时间的键,根据过期时间排序,优先淘汰剩余时间最短的键。
- Redis 内部维护了过期时间字典,但淘汰时也是通过随机采样比较 TTL。
三、如何选择并设置合适的回收算法? 选择淘汰策略需结合业务特点:
| 业务场景 | 推荐策略 | 理由 |
|---|---|---|
| 所有数据都有过期时间,希望淘汰冷数据 | volatile-lru / volatile-lfu | 只淘汰过期键,保护永久键 |
| 希望所有键(包括永久键)都能被淘汰 | allkeys-lru / allkeys-lfu | 内存不足时,优先淘汰最不常用的数据 |
| 对数据访问频率有严格要求,希望保留高频键 | allkeys-lfu / volatile-lfu | LFU 更能反映长期访问热度 |
| 希望淘汰随机,简单均匀 | allkeys-random | 适合数据分布均匀,无热点场景 |
| 数据有明确的过期时间,希望尽量保留快到期的数据(比如缓存雪崩预防) | volatile-ttl | 淘汰即将过期的数据,避免缓存雪崩 |
| 不允许任何数据丢失,写请求需要严格保证 | noeviction | 内存满时写报错,需业务降级或扩容 |
配置方式:
- 在
redis.conf中设置:maxmemory 2gb # 设置最大内存 maxmemory-policy allkeys-lru # 设置淘汰策略 maxmemory-samples 10 # 设置采样数量(越大越精确,但性能稍降) - 动态修改(运行时):
CONFIG SET maxmemory 2gb CONFIG SET maxmemory-policy allkeys-lru CONFIG SET maxmemory-samples 10
采样数量 maxmemory-samples 默认 5,范围 1-10。增大采样数会使淘汰更精确,但会增加 CPU 开销。
【大白话解释于举例说明】
- LRU:好比整理书架,你经常看的书放在顺手的地方,不常看的书塞角落。内存不足时,把最角落的扔掉。Redis 不精确,因为不可能翻遍所有书,而是随机抽几本,扔掉其中看起来最旧的。
- LFU:好比记录每本书被翻的次数,经常翻的书留着,极少翻的扔掉。即使最近没看,但以前经常看,也保留。Redis 用计数器近似,并随时间衰减。
- 随机:闭着眼扔一本,简单粗暴。
- TTL:在每本书上标了到期时间,优先扔掉马上到期的。
例如:一个新闻网站,热门新闻(热点数据)应该保留,冷门新闻淘汰,用 allkeys-lru 或 allkeys-lfu 都行。如果每个新闻都设置了过期时间(比如 1 天),可以用 volatile-lru,但万一某个新闻没设过期时间,它就永远不会被淘汰,可能导致内存吃紧,所以 allkeys-lru 更稳妥。
【扩展知识点详解】
- LRU 与 LFU 对比:
- LRU 关注“最近”访问,适合访问模式变化快的场景(如突发热点)。
- LFU 关注“频率”,适合访问模式长期稳定的场景(如基础数据)。
- 但 LFU 可能让历史高频但当前无用的键长期占据内存(可通过衰减缓解)。
-
Redis 的近似 LRU 与真实 LRU 比较:
Redis 官方测试显示,采样 5 时,近似 LRU 与真实 LRU 非常接近,采样 10 时几乎相同。因此大多数场景默认 5 足够。 - 淘汰策略对性能的影响:
- 随机淘汰开销最小。
- LRU/LFU 需要采样和比较,开销稍大,但采样数小,影响可忽略。
- TTL 淘汰需要比较剩余时间,与 LRU 类似。
- 持久化与淘汰的关系:
- 执行
SAVE或BGSAVE生成的 RDB 文件中不包含已淘汰的键。 - AOF 重写时也会忽略已淘汰的键。
- 执行
- 主从复制中的淘汰:
- 淘汰只在主库触发。主库淘汰键后,会发送
DEL命令给从库,从库删除相应键。 - 如果从库开启了
slave-read-only,但淘汰由主库控制,不影响。
- 淘汰只在主库触发。主库淘汰键后,会发送
- 如何监控淘汰情况:
- 通过
INFO stats查看evicted_keys指标,了解淘汰键数量,辅助调整内存策略。 - 如果
evicted_keys持续增长,说明内存不足或策略不合理,需扩容或优化数据。
- 通过
- 淘汰与过期键删除的区别:
- 淘汰(eviction)是内存达到上限时触发的主动删除。
- 过期键删除(expiration)是键过期后的清理,由惰性删除和定期删除完成,与内存上限无关。
- 特殊注意事项:
- 使用
allkeys-lru时,即使键设置了过期时间,也可能因淘汰而被提前删除。 - 如果业务有重要数据不能丢失,不应开启淘汰或使用
noeviction,但需配合内存监控。
- 使用
通过合理设置淘汰策略,可以充分利用 Redis 的内存,同时保证系统稳定性。
【问题】 Redis怎样设置key的过期时间?有几种方式?哪些是原子性的?
【参考答案】 在Redis中,设置key的过期时间主要有以下几种方式,所有单个命令都是原子性的:
一、设置过期时间的命令
-
EXPIRE key seconds
将key的过期时间设置为指定的秒数。例如:EXPIRE user:123 3600表示该key在1小时后过期。 -
PEXPIRE key milliseconds
将key的过期时间设置为指定的毫秒数。 -
EXPIREAT key timestamp
将key的过期时间设置为指定的UNIX时间戳(秒级)。例如:EXPIREAT user:123 1672531200表示在2023-01-01 00:00:00过期。 -
PEXPIREAT key milliseconds-timestamp
将key的过期时间设置为指定的毫秒级时间戳。 -
SET key value EX seconds
在设置字符串类型key的同时,指定过期时间(秒)。这是SET命令的扩展选项,原子性地完成赋值和过期设置。 -
SET key value PX milliseconds
在设置字符串key的同时,指定过期时间(毫秒)。 -
SETEX key seconds value
这是一个专门用于设置带过期时间的字符串key的命令,功能等同于SET key value EX seconds,但已不太推荐(可用SET替代)。 -
PSETEX key milliseconds value
类似SETEX,但过期时间为毫秒。
此外,对于其他数据结构(如Hash、List等),可以通过上述EXPIRE等命令单独设置过期时间。
二、原子性说明
- 每个单独的Redis命令都是原子性的。因为Redis使用单线程处理命令,每个命令在执行过程中不会被其他命令打断,所以上述所有单个命令(包括带EX/PX选项的SET)都是原子操作。
- 注意:如果通过多个命令组合来实现(例如先
SET再EXPIRE),这两个命令之间可能会被其他命令插入,因此整体不是原子性的。若要保证原子性,可以使用事务(MULTI/EXEC)或Lua脚本将多个操作封装。
三、相关操作
- PERSIST key:移除key的过期时间,使其变为永久有效。
- TTL key / PTTL key:查看key剩余的生存时间(秒/毫秒)。
【大白话解释】 好比给冰箱里的食物贴保质期标签:
- 你可以单独说“这盒牛奶3天后过期”(EXPIRE),或者“这盒牛奶必须在周一前喝完”(EXPIREAT)。
- 你也可以在放进冰箱的同时就贴上“保质期3天”的标签(SET … EX)。
- 这些操作都是由一个人(Redis单线程)一次性完成的,不会有人中途干扰,所以是原子的。但如果先放进冰箱,回头再贴标签,中间可能被别人碰过,就不是原子操作了。
【扩展知识点详解】
- 对于已设置过期时间的key,如果使用
SET命令(不带EX/PX选项)覆盖其值,则过期时间会被清除。 - 在Redis主从复制中,过期时间的设置会通过命令传播,从库不主动删除过期键,而是由主库在键过期时发送
DEL命令。 - 过期键的实际删除由惰性删除和定期删除策略负责,与过期时间设置命令无关。
- 使用
EXPIRE等命令时,如果key不存在,则返回0;如果设置成功,返回1。
【问题】 MySQL 单表里有 2000万数据,Redis 中只存20w的数据,如何保证 Redis 中的数据都是热点数据?
【参考答案】 要确保 Redis 中只存储 20 万热点数据,需要结合 Redis 自身的淘汰机制、缓存加载策略以及业务层面的数据热度统计。以下是一套完整的方案:
一、利用 Redis 内存淘汰策略自动保留热点数据
-
设置合理的最大内存
根据 20 万数据的预估内存占用,在 redis.conf 中配置maxmemory,例如maxmemory 2gb(具体大小需根据每条数据平均大小估算,可留一定余量)。确保 Redis 内存刚好能容纳约 20 万条数据。 - 选择 LRU 或 LFU 淘汰策略
- 若希望保留最近访问的数据,使用
allkeys-lru(所有键中淘汰最近最少使用)或volatile-lru(仅针对设置了过期时间的键)。LRU 能有效反映近期热点。 - 若希望保留访问频率高的数据(如某些长期热门商品),可选用
allkeys-lfu或volatile-lfu(Redis 4.0+),LFU 更能体现长期访问热度。
设置示例:maxmemory-policy allkeys-lru
- 若希望保留最近访问的数据,使用
- 调整采样数
通过maxmemory-samples提高淘汰精确度,默认 5,可适当调大至 10,使淘汰更接近真实 LRU/LFU。
这样,当 Redis 内存达到上限时,会自动淘汰非热点数据,保留访问最频繁的 20 万数据。
二、缓存加载策略:只缓存被访问的数据
- 读时缓存(Cache-Aside)
应用在读取数据时,先查 Redis:- 若命中,直接返回;
- 若未命中,则查询 MySQL,将结果写入 Redis,并设置合理的过期时间(如 1 小时)。
这样,只有被实际访问过的数据才会进入 Redis,且随着时间推移,访问频率低的数据会被 LRU 淘汰,而高频数据得以保留。
- 设置合适的过期时间
为每个缓存键设置 TTL,避免数据长期不更新。过期时间可根据业务特点动态调整(例如热门商品 TTL 短一些,冷门商品长一些但会被淘汰)。过期后,下次访问会重新从 MySQL 加载,再次进入 Redis。
三、主动预热热点数据 如果业务可以预判热点(如每日热门商品、热搜词),可以通过离线或定时任务统计热度(如从数据库的访问日志、订单量等),将 Top 20 万数据提前加载到 Redis 中。例如:
- 每日凌晨计算前一天的热门商品 ID 列表。
- 将这些商品信息批量写入 Redis,并设置过期时间。
- 同时保留 LRU 淘汰机制,使缓存动态适应当日热点变化。
四、监控与调优
- 通过
INFO stats监控evicted_keys(淘汰键数量)和缓存命中率。如果命中率低,说明淘汰策略可能不合适或热点数据量不足 20 万,可考虑增大内存或调整策略。 - 使用
redis-cli --bigkeys分析大键,避免个别大键占用过多内存影响淘汰效果。 - 结合业务访问模式,定期调整淘汰策略或 TTL。
五、保证数据一致性 当 MySQL 数据更新时,需要及时更新或删除 Redis 中的对应缓存,避免脏数据。常见做法:
- 更新时双写:先更新数据库,再删除 Redis 中的缓存(推荐),下次读取时重新加载。
- 订阅 binlog:使用 Canal 等中间件监听 MySQL 变更,异步刷新 Redis。
通过以上组合策略,可以确保 Redis 中的 20 万数据始终是业务真正的热点数据,最大化缓存价值。
【大白话解释于举例说明】 想象 Redis 是一个能放 20 万件商品的“热门货架”,MySQL 是背后有 2000 万商品的“大仓库”。我们怎么保证货架上始终是最热门的商品?
- 货架自动淘汰:给货架设定最大容量,并制定规则(LRU):哪个商品最近没人买,就把它扔回仓库,腾出地方放新来的热门商品。
- 只卖被点过的商品:顾客来买商品时,如果货架上没有,就去仓库取出来放在货架上,并贴上保质期(过期时间)。这样只有被顾客点过的商品才会出现在货架上。
- 提前预测热门:根据历史销售数据,提前把预测的热门商品摆上货架。
- 定期检查:看看货架上的商品卖得快不快(命中率),如果总是有人来问但货架上没有(缓存穿透),就调整规则。
这样,货架上留下的自然就是最热门的商品了。
【扩展知识点详解】
- LRU 与 LFU 的选择:LRU 适合访问模式变化快的场景(如新闻热点),LFU 适合访问模式稳定的场景(如基础数据)。若无法确定,可先用 LRU,通过监控调整。
- 过期时间与淘汰策略的关系:设置过期时间可以主动让数据失效,但淘汰是在内存满时触发。两者互补,过期时间可避免数据长期不更新,淘汰保证内存可控。
- 缓存击穿、穿透、雪崩:需考虑相应防护措施,如布隆过滤器、互斥锁、随机过期时间等。
- 内存估算:20 万数据的内存占用取决于数据结构。例如,String 类型每条数据平均 50 字节,则 20 万约 10MB;若包含复杂结构,可能更大。需实际估算并配置
maxmemory。 - 淘汰策略对性能的影响:采样数越大越精确,但会略微增加 CPU 开销,一般 5-10 足够。
- Redis 的 LFU 实现:通过 24 位 lru 字段拆分为 16 位时间(分钟级)和 8 位计数器,访问时计数器对数增长,并随时间衰减,避免历史高频数据永久占据内存。
用java的基本数据结构实现一个时间复杂度是O1的LRU算法
使用双向链表+哈希表实现
使用双向链表来维护缓存的顺序,使用哈希表来快速查找缓存中的元素
双向链表:用于存储缓存的键值对,能够快速地移动节点到链表的头部(表示最近使用)或尾部(表示最少使用)。
哈希表:用于快速访问链表中的节点,键为缓存的键,值为链表中的节点
import java.util.HashMap;
class LRUCache {
private class Node {
int key;
int value;
Node prev;
Node next;
Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private final int capacity;
private final HashMap<Integer, Node> map;
private final Node head;
private final Node tail;
public LRUCache(int capacity) {
this.capacity = capacity;
this.map = new HashMap<>();
this.head = new Node(0, 0); // Dummy head
this.tail = new Node(0, 0); // Dummy tail
head.next = tail;
tail.prev = head;
}
private void removeNode(Node node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addToHead(Node node) {
node.next = head.next;
node.prev = head;
head.next.prev = node;
head.next = node;
}
public int get(int key) {
if (!map.containsKey(key)) {
return -1; // Not found
}
Node node = map.get(key);
removeNode(node);
addToHead(node);
return node.value;
}
public void put(int key, int value) {
if (map.containsKey(key)) {
Node node = map.get(key);
node.value = value;
removeNode(node);
addToHead(node);
} else {
if (map.size() >= capacity) {
Node lru = tail.prev;
removeNode(lru);
map.remove(lru.key);
}
Node newNode = new Node(key, value);
addToHead(newNode);
map.put(key, newNode);
}
}
}
===============================================
封装好的数据结构就是LinkedHashMap
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache<K, V> {
// 缓存的最大容量
private final int capacity;
private final LinkedHashMap<K, V> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
// 这true意味着当访问元素时,它们会被移动到链表的末尾
this.cache = new LinkedHashMap<K, V>(capacity, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当缓存的大小超过容量时,移除最旧的元素
return size() > capacity;
}
};
}
public V get(K key) {
// 从缓存中获取元素,如果元素不存在,则返回
return cache.getOrDefault(key, null);
}
public void put(K key, V value) {
//将元素放入缓存中。如果缓存已满,则会自动移除最旧的元素
cache.put(key, value);
}
public void displayCache() {
System.out.println(cache);
}
public static void main(String[] args) {
LRUCache<Integer, String> lruCache = new LRUCache<>(3);
lruCache.put(1, "One");
lruCache.put(2, "Two");
lruCache.put(3, "Three");
lruCache.displayCache(); // {1=One, 2=Two, 3=Three}
lruCache.get(1); // Access key 1
lruCache.put(4, "Four"); // This should evict key 2
lruCache.displayCache(); // {3=Three, 1=One, 4=Four}
lruCache.put(5, "Five"); // This should evict key 3
lruCache.displayCache(); // {1=One, 4=Four, 5=Five}
}
}
持久化
【问题】 Redis的同步机制讲一下?
【参考答案】 Redis的同步机制主要是指主从复制,它允许一个Redis主节点(Master)的数据被复制到一个或多个从节点(Slave)。从节点也可以作为其他从节点的主节点,形成链式复制(即从从复制)。同步机制保证了数据的冗余备份和读写分离,是Redis高可用的基础。
一、同步机制的核心流程
Redis主从复制分为全量复制和增量复制(部分复制)两种模式,通过PSYNC命令实现。
- 连接建立与身份验证
- 从节点通过
SLAVEOF命令指定主节点IP和端口,或通过配置文件设置slaveof。 - 连接建立后,从节点向主节点发送
PING检查连通性,若主节点设置了密码,需通过AUTH认证。
- 从节点通过
- 数据同步阶段
- 从节点向主节点发送
PSYNC <runid> <offset>,携带主节点的运行ID和自己已复制的偏移量。 - 主节点根据情况返回:
- 全量复制:若从节点是第一次连接或断连太久导致偏移量不在复制积压缓冲区中,主节点返回
+FULLRESYNC <runid> <offset>,开始全量复制。 - 部分复制:若偏移量仍在缓冲区中,主节点返回
+CONTINUE,接着发送从该偏移量开始的增量数据。
- 全量复制:若从节点是第一次连接或断连太久导致偏移量不在复制积压缓冲区中,主节点返回
- 从节点向主节点发送
二、全量复制详解
- 触发条件:
- 从节点第一次连接主节点。
- 从节点断线时间过长,主节点的复制积压缓冲区已覆盖不到缺失的数据。
- 从节点请求的
runid与当前主节点不一致(如主节点重启或故障切换后)。
- 执行步骤:
- 生成RDB:主节点执行
BGSAVE生成RDB快照文件。若已有BGSAVE在执行,则复用该RDB。 - 记录增量:主节点在生成RDB期间,将所有写命令缓存在复制缓冲区中,防止数据丢失。
- 传输RDB:主节点将生成的RDB文件发送给从节点。从节点接收后,先清空自身数据,然后加载RDB到内存。
- 发送增量:从节点加载RDB完成后,主节点将复制缓冲区中的写命令发送给从节点。
- 后续增量:之后主节点将实时的写命令以命令流的形式持续发送给从节点,保持同步。
- 生成RDB:主节点执行
- 优化选项:
- 无盘复制:设置
repl-diskless-sync yes,主节点不经过磁盘直接通过网络发送RDB,减少磁盘I/O。 - 从节点并行加载:从节点加载RDB时会阻塞,期间无法服务。
- 无盘复制:设置
三、增量复制(部分复制)详解
- 核心机制:
- 主节点维护一个复制积压缓冲区(
repl_backlog),它是一个固定大小的环形队列,默认1MB,可配置repl-backlog-size。 - 每个写命令都会写入缓冲区,并分配一个递增的复制偏移量(offset)。
- 从节点会定期向主节点发送
REPLCONF ACK <offset>,报告自己已复制的偏移量。
- 主节点维护一个复制积压缓冲区(
- 执行步骤:
- 从节点重连后,发送
PSYNC携带上次同步的runid和offset。 - 主节点检查该
offset是否还在自己的复制积压缓冲区内。如果在,则返回+CONTINUE,并从该offset开始发送缓冲区中的后续命令。 - 从节点接收并执行这些增量命令,实现快速同步,避免全量复制的开销。
- 从节点重连后,发送
四、从从复制
- 从节点也可以作为其他从节点的主节点,形成主-从-从的链式结构。
- 配置方式:在从节点上执行
SLAVEOF <上游节点IP> <端口>,使其成为另一个从节点的从节点。 - 优点:减轻主节点的推送压力,适用于从节点数量较多的场景。
- 缺点:增加复制延迟,上游从节点的性能会影响下游。
五、复制偏移量与心跳
- 主节点和从节点各自维护一个复制偏移量,通过
INFO replication可以查看。 - 从节点每秒发送一次
REPLCONF ACK给主节点,报告自己的偏移量,主节点据此监控从节点进度和延迟。 - 主节点定期向从节点发送
PING,维持心跳并检测从节点存活。
六、复制的异步性与数据一致性
- Redis默认采用异步复制:主节点执行完写命令后直接返回客户端,不等待从节点确认。因此主从之间可能存在短暂的不一致(最终一致性)。
- 可以通过配置
min-slaves-to-write和min-slaves-max-lag来保证至少有N个从节点延迟在阈值内,否则主节点拒绝写,提升一致性等级。 - 从节点通常设置为只读(
slave-read-only yes),避免意外写入导致数据不一致。
七、复制ID(Replication ID)
- 每个Redis实例有一个唯一的复制ID(
runid),标识数据集的演进历史。 - 当主节点故障切换后,新主节点会生成新的复制ID,但会保留旧ID(
replid2)和对应的偏移量,以便从节点使用PSYNC时能基于旧ID进行部分复制。
八、复制的注意事项与性能影响
- 全量复制开销大:fork子进程生成RDB可能短暂阻塞主进程,内存越大阻塞时间越长。网络传输RDB也会占用带宽。
- 复制缓冲区大小:应根据业务写量和允许的断线时间合理设置
repl-backlog-size,避免频繁全量复制。 - 无盘复制:适用于磁盘较慢但网络带宽充足的场景,但会直接占用网络I/O。
- 主从版本兼容:尽量保持主从版本一致,避免兼容性问题。
九、复制与高可用的关系
- 主从复制本身不提供自动故障转移,需配合哨兵(Sentinel)或集群(Cluster)实现。
- 哨兵监控主从状态,在主节点故障时自动将从节点提升为新主,并通知客户端。
- 集群模式内置了分片和复制,每个主节点有多个从节点,支持自动故障转移。
【大白话解释】 Redis的同步就像老师和学生抄笔记:
- 第一次:学生要把老师之前写的全部内容抄下来(全量复制)。老师把完整笔记(RDB)复印一份给学生,学生拿到后誊写,同时老师把复印后新写的内容记在小黑板上(复制缓冲区),等学生誊写完再补上。
- 断线重连:学生只是漏掉了最近几行,如果老师还记得(还在缓冲区里),老师只把漏掉的部分告诉学生(部分复制),不用重新抄全部。
- 学生太多:可以让一个学生当小老师,其他学生找他抄(从从复制),减轻老师负担。
- 老师写新内容:老师每次写新内容,会口头告诉所有学生(命令传播),学生们各自记下。
【扩展知识点详解】
- PSYNC 的演进:Redis 2.8之前使用
SYNC(总是全量复制);2.8引入PSYNC支持部分复制;4.0引入PSYNC2,优化了故障切换后的部分复制。 - 复制积压缓冲区的配置:
repl-backlog-size建议设置为(断线重连时间 * 每秒平均写命令大小),例如若允许断线10秒,每秒写1MB,则设为10MB。 - 无盘复制的配置:
repl-diskless-sync yes,并可通过repl-diskless-sync-delay延迟复制开始时间,让多个从节点同时同步减少RDB生成次数。 - 复制延迟监控:通过
INFO replication查看master_last_io_seconds_ago(主从上次通信间隔)和slave_lag(从节点延迟秒数)。 - 主从认证:通过
masterauth配置密码,确保复制安全。 - 复制与持久化的配合:若从节点开启持久化,建议先开启再复制,避免重启后全量复制。
- 复制与哨兵:哨兵通过
info命令获取复制信息,并利用PSYNC进行故障转移后的增量同步。
【问题】 Redis 持久化数据和缓存怎么做扩容?
【参考答案】 Redis的扩容方案取决于其使用场景:是作为缓存(允许数据丢失)还是作为持久化存储(要求数据可靠)。两种场景下的扩容策略有所不同,但最终都可以通过Redis Cluster实现平滑扩容。
一、当Redis作为缓存使用时 缓存场景下,数据允许丢失(可从后端数据库重建),因此扩容相对简单,主要目标是动态调整节点数量以均衡负载。常用方案是基于一致性哈希的客户端分片或代理分片。
- 客户端分片(一致性哈希)
- 在客户端实现分片逻辑,通过一致性哈希算法(如Ketama)将key映射到具体的Redis节点。
- 当增加或减少节点时,只有少量key需要重新映射(因为一致性哈希只影响环上相邻节点的数据),其余key仍能正确路由。
- 缺点:客户端需要维护分片规则,且数据迁移需自行处理(可配合双写或渐进式迁移)。
- 代理中间件
- 使用Twemproxy、Codis等代理层,对客户端屏蔽后端节点变化。代理层内部维护分片规则(如一致性哈希或预分片),并支持动态扩缩容。
- 扩容时,代理层调整分片配置,将部分数据迁移到新节点(通常需手动触发)。
- 优点:客户端无感知;缺点:引入代理增加一跳延迟。
- Redis Cluster
- Redis官方集群方案,内置数据分片(16384个槽)和节点间通信。
- 可作为缓存或持久化存储的统一解决方案,通过槽迁移实现平滑扩容。
二、当Redis作为持久化存储使用时 持久化场景下,数据不能丢失,扩容时必须保证数据的完整迁移。因此,必须使用支持在线数据再平衡的系统。
- Redis Cluster(推荐)
- Redis Cluster通过哈希槽机制将数据分片,每个节点负责一部分槽。
- 扩容时,将新节点加入集群,然后从现有节点迁移部分槽到新节点。迁移过程以槽为单位,逐键迁移,期间服务不中断。
- 迁移由集群管理工具(如
redis-cli --cluster reshard)触发,数据会逐步移动,最终完成平衡。 - 优点:原生支持,自动化程度高,数据可靠。
- 客户端固定分片
- 如果使用客户端固定分片(如取模分片),节点数一旦确定就不能轻易改变,否则映射关系变化会导致大量数据失效(缓存场景可容忍,持久化不可接受)。
- 若要扩容,需停机或双写迁移,复杂度高,不推荐。
三、通用扩容步骤(以Redis Cluster为例)
- 准备新节点:启动新的Redis实例,配置为集群模式。
- 加入集群:使用
CLUSTER MEET命令将新节点加入现有集群。 - 分配槽:执行reshard操作,从现有节点迁移部分槽到新节点。迁移过程中,源节点将槽内的键逐步发送给目标节点,客户端访问时可能收到
ASK重定向,但最终会更新路由表。 - 调整副本:如果需要,可以为新主节点添加从节点以增加高可用性。
- 验证与监控:使用
CLUSTER INFO和CLUSTER NODES检查集群状态,确保所有槽已分配,节点负载均衡。
四、总结
- 缓存场景:可使用一致性哈希客户端分片或代理,扩容灵活但需处理数据重建。
- 持久化存储:必须使用Redis Cluster,其槽迁移机制保证数据不丢失且服务在线。
- 无论何种场景,Redis Cluster都是最通用、最推荐的扩容方案,既支持缓存也支持持久化,且内置高可用和自动故障转移。
【大白话解释于举例说明】
- 缓存场景:好比商场的临时储物柜,丢了可以再补,所以扩容就像多放几个柜子,用一致性哈希算法决定哪个顾客去哪个柜子,新加柜子只影响附近几个顾客的存放位置,少量顾客需要重新放一下东西。
- 持久化存储:好比银行金库,钱不能丢。扩容就像金库不够用了,需要增加一个新金库,并且要把部分钱从旧金库搬到新金库。这个过程必须小心翼翼,钱不能少,且搬的时候银行还要正常营业(在线)。Redis Cluster就是那个有组织的搬家公司,它把金库分成16384个格子(槽),一格一格地搬,搬的时候客户还能存取款(通过重定向机制)。
【扩展知识点详解】
- 一致性哈希原理
- 将节点和数据key映射到同一个环上(0~2^32-1),数据落在顺时针方向最近的节点上。
- 节点增减时,只影响环上相邻节点的数据,其他节点不受影响,大大减少了重新映射的范围。
- 实际应用中引入虚拟节点解决节点不均问题。
- Redis Cluster的哈希槽
- 共16384个槽,每个key通过
CRC16(key) & 16383计算槽位。 - 槽的分配信息在集群中传播,客户端可缓存槽映射表。
- 迁移时,源节点将槽内的键逐个发送给目标节点,期间键仍可读写(需特殊处理
ASK重定向)。
- 共16384个槽,每个key通过
- 扩容中的数据迁移
- 迁移过程:
- 目标节点准备导入槽。
- 源节点将槽标记为
migrating,目标节点标记为importing。 - 客户端访问该槽时,若键还在源节点,正常处理;若已迁移,返回
ASK重定向,客户端先向目标节点发ASKING再执行命令。 - 源节点遍历槽内的所有键,使用
MIGRATE命令批量迁移到目标节点。
- 迁移完成后,广播槽的新归属,客户端更新缓存。
- 迁移过程:
- 扩容前的规划
- 估算数据量,确定新节点数量。
- 在测试环境演练迁移过程,验证数据一致性。
- 监控集群性能,避免迁移期间负载过高。
- 客户端兼容性
- 使用Redis Cluster时,客户端需支持集群协议(如Jedis Cluster、Lettuce),能处理
MOVED和ASK重定向,并缓存槽信息。 - 若使用普通客户端,可搭配代理(如Predixy、Redis Sentinel)但会损失部分功能。
- 使用Redis Cluster时,客户端需支持集群协议(如Jedis Cluster、Lettuce),能处理
- 扩缩容的常见问题
- 数据倾斜:迁移后需检查各节点槽数量是否均衡,可通过
CLUSTER REBALANCE自动调整(需在集群模式下)。 - 性能影响:迁移过程中,大量
MIGRATE命令可能占用网络带宽和CPU,建议在低峰期执行,或限制迁移速度(通过redis-cli --cluster的--cluster-timeout等选项)。 - 故障处理:若迁移中节点故障,需确保数据一致性,Redis Cluster会自动处理(如从节点接管)。
- 数据倾斜:迁移后需检查各节点槽数量是否均衡,可通过
- 持久化与扩容的配合
- 扩容前确保所有节点已开启持久化(RDB/AOF),防止迁移过程中数据丢失。
- 新节点加入后,会自动从主节点同步数据(如果作为从节点),但作为主节点则需要迁移槽。
- 云服务商的托管Redis
- 使用云服务(如阿里云、AWS ElastiCache)时,扩容通常由控制台一键操作,底层自动完成数据迁移,对用户透明。
事务
【问题】 Redis事务机制是怎样实现的?
【参考答案】
Redis通过MULTI、EXEC、WATCH等命令实现事务功能,允许将多个命令打包成一个步骤执行,并保证原子性和隔离性。其核心机制是:命令入队和延迟执行,结合WATCH实现乐观锁。
一、事务的基本流程
- 事务开始:客户端发送
MULTI命令,服务器将该客户端标记为事务状态。 - 命令入队:在事务状态下,后续发送的命令不会立即执行,而是被放入一个命令队列中(排队)。服务器返回
QUEUED表示命令已入队。 - 事务执行:客户端发送
EXEC命令,服务器原子性地依次执行队列中的所有命令,并将结果一次性返回给客户端。 - 事务取消:客户端发送
DISCARD命令,清空命令队列并退出事务状态。
二、事务的错误处理 Redis事务中的错误分为两类,处理方式不同:
- 入队时错误:如果命令在入队时发现语法错误(如命令名拼写错误、参数数量不对),Redis会立即返回错误,并拒绝执行该命令,但事务仍可继续添加其他命令。当执行
EXEC时,如果队列中存在入队错误的命令,则整个事务所有命令都不会执行(即事务失败)。 - 执行时错误:如果命令在执行时发生错误(如对字符串进行
LPUSH操作),Redis不会中断事务,而是继续执行后续命令。错误命令的结果返回错误信息,但其他命令正常执行,没有回滚。
三、WATCH命令与乐观锁
WATCH用于实现乐观锁,保证事务执行期间数据未被其他客户端修改。用法:
- 在
MULTI之前,使用WATCH监视一个或多个键。 - 如果在执行
EXEC之前,被监视的键被其他客户端修改了,则当前事务会被打断,EXEC返回nil(表示事务执行失败)。 - 之后可以重试事务或执行其他操作。
WATCH的实现原理:服务器记录被监视的键,并在键被修改时递增一个计数器。EXEC时检查计数器是否变化,若变化则拒绝执行事务。
四、Redis事务的ACID特性
- 原子性(Atomicity):事务中的所有命令要么全部执行(遇到执行时错误也继续执行),要么全部不执行(入队错误或
WATCH触发)。但注意Redis事务不支持回滚,因此并非传统意义上的原子性。 - 一致性(Consistency):事务执行前后,数据保持逻辑一致性(取决于命令本身,Redis不保证业务一致性)。
- 隔离性(Isolation):由于Redis单线程执行命令,事务中的所有命令在
EXEC时连续执行,中间不会被其他命令插入,因此具备严格的隔离性。 - 持久性(Durability):只有当Redis开启AOF且
appendfsync为always时,事务才具有持久性。默认情况下,持久性不保证。
五、为什么Redis不支持回滚?
- 设计理念:Redis命令失败通常是由于编程错误(如对错误类型操作),这种情况在开发阶段就应该发现。Redis追求简单高效,回滚会增加复杂性。
- 性能考虑:回滚需要记录状态,影响性能。
【大白话解释于举例说明】 想象Redis事务是一个“点餐流程”:
- MULTI:你说“我要开始点餐了”,服务员拿出小本本准备记。
- 命令入队:你一个个说“来份宫保鸡丁”、“来碗米饭”、“再来瓶可乐”,服务员只记下来,不实际下单。
- WATCH:就像你提前和朋友说“别动我桌上的水杯”,如果有人动了,你这次点餐就取消。
- EXEC:你说“下单”,服务员才把小本本上的菜一次性传给厨房。厨房按顺序做,如果做可乐时发现没可乐了(执行错误),宫保鸡丁和米饭还是会做,不会因为可乐没了就把菜倒掉(没有回滚)。如果点菜单上写了“鱼香肉丝”但字迹看不清(入队语法错),服务员直接说这单不做了,所有菜都不上。
【扩展知识点详解】
- 事务与管道(Pipeline)的区别:管道只是将多个命令打包发送,减少网络开销,但服务器依然逐个执行,不保证原子性;事务则保证原子性(但不回滚)和隔离性。
- WATCH的实现细节:Redis使用一个
watched_keys字典,每个键关联一个客户端列表。当键被修改时,对应客户端的REDIS_DIRTY_CAS标志被设置,EXEC时检测该标志。 - 事务中的命令错误:命令入队错误主要是语法错误,如
SET key(缺少参数);执行时错误如对列表用GET。注意:事务中的命令错误不会导致整个事务回滚,但可以借助DISCARD手动放弃。 - Redis脚本(Lua)与事务:Lua脚本也可以实现原子性操作,且支持更复杂的逻辑。相比事务,Lua脚本更灵活,且不会因为中间错误而停止执行(脚本中遇到错误会停止)。通常推荐使用Lua脚本替代事务实现复杂原子操作。
- 事务性能:
EXEC时一次性执行所有命令,减少网络往返,但命令仍然串行执行。如果事务中包含大量命令,可能阻塞其他客户端,应避免过大的事务。 - 主从复制下的事务:事务中的命令会以单个
MULTI...EXEC块的形式传播给从节点,从节点也会原子地执行整个块。 - 持久化与事务:如果启用AOF,每个写命令都会写入AOF文件,事务中的命令在AOF中也是以
MULTI...EXEC块存储,保证了重放时的原子性。 - 分布式事务:Redis事务仅针对单实例,跨节点事务需使用其他方案(如Redlock或Lua脚本在集群模式中有限支持)。
通过以上机制,Redis事务在保证隔离性的同时提供了简洁的原子操作,适用于需要批量执行且不要求回滚的场景。

雪崩和击穿
【问题】 什么是Redis缓存雪崩?怎样处理?什么是缓存穿透?怎么解决?
【参考答案】
一、缓存雪崩 定义:缓存雪崩是指缓存中大量数据在同一时间(或短时间内)集中过期失效,导致所有请求直接穿透到后端数据库,数据库因瞬时压力过大而崩溃。此外,Redis节点故障导致整个缓存不可用,也会引发雪崩。
原因:
- 大量key设置了相同的过期时间,导致同时失效。
- Redis服务宕机或网络中断。
- 缓存服务重启后,缓存为空,大量请求涌入数据库。
处理方法:
- 设置随机过期时间:为key的过期时间增加一个随机值(如1~5分钟),避免集中过期。
- 使用互斥锁:缓存失效时,只允许一个线程去加载数据,其他线程等待(例如利用
SETNX实现分布式锁)。 - 永不过期策略:对热点数据不设置过期时间,由后台线程异步更新缓存。
- 多级缓存:引入本地缓存(如Caffeine)作为Redis的二级缓存,分担压力。
- 提前预热:在业务高峰期前,预先将热点数据加载到缓存中。
- 高可用部署:采用Redis主从+哨兵或Cluster模式,避免单点故障。
- 限流降级:在数据库层配置限流,当缓存失效时对请求进行降级处理(如返回默认值)。
二、缓存穿透 定义:缓存穿透是指查询一个不存在的数据(缓存和数据库中都没有),导致每次请求都绕过缓存直接查询数据库。若攻击者利用大量此类请求,可能导致数据库压力过大甚至崩溃。一般 MySQL 默认的最大连接数在 150 左右,这个可以通过 show variables like ‘%max_connections%’;命令来查看。一般 3000 个并发请求就能打死大部分数据库了。
原因:
- 恶意攻击或爬虫频繁请求不存在的key。
- 业务逻辑缺陷,查询了不存在的记录。
解决方法:
- 缓存空对象:当从数据库查询不到结果时,将空值(如
null)也存入缓存,并设置较短的过期时间(如5分钟)。后续请求命中空缓存直接返回,避免穿透数据库。- 优点:实现简单。
- 缺点:占用缓存空间,可能存在短暂数据不一致(真实数据写入后,空缓存需等待过期)。
- 布隆过滤器:在缓存前增加布隆过滤器,将数据库中所有可能存在的数据key哈希到位数组中。请求到来时先检查key是否在布隆过滤器中,如果不存在则直接拒绝请求,避免查询数据库。
- 优点:内存占用极小,性能极高。
- 缺点:存在误判率(可能将存在误判为不存在,但不存在绝不会误判为存在),且需要同步维护过滤器与数据库数据的一致性。
- 接口参数校验:对请求参数进行合法性校验,如ID必须为正整数、符合特定格式,非法请求直接拦截。
- 限流与黑名单:针对恶意IP或高频请求进行限流,并加入黑名单。
- 增强数据完整性:确保数据库记录不为空,但实际很难做到所有查询都有结果。
【大白话解释】
- 缓存雪崩:好比商场所有优惠券同时过期,顾客瞬间涌向柜台(数据库),柜台被挤爆。解决方案:让优惠券错开过期时间(随机值),或者只允许一个人去柜台咨询(互斥锁),其他人排队等待。
- 缓存穿透:好比有人反复问“有没有哈利波特的魔法杖”,店里根本没有(数据库不存在),但每次都要去仓库翻找(查询数据库),店员累垮。解决方案:在门口贴个清单(布隆过滤器),不在清单上的直接说“没有”,或者第一次问过后就记下“没有这件商品”(空缓存),下次就不用翻仓库了。
【扩展知识点详解】
- 缓存击穿(区别于雪崩):指某个热点key过期失效,同时有大量请求并发访问该key,导致瞬间压力全部打到数据库。解决方式与雪崩类似,可使用互斥锁或永不过期策略。
- 布隆过滤器实现:可用Google Guava的BloomFilter类,或Redis的布隆过滤器模块(RedisBloom)实现。
- 空对象缓存的注意点:为避免内存浪费,可设置较短的过期时间;同时,当数据库写入真实数据时,需主动删除或更新该空缓存。
- 高并发下的互斥锁:使用Redis的
SET key value NX PX命令实现分布式锁,确保只有一个线程加载数据。 - 缓存预热:可通过离线任务扫描热点数据,提前写入缓存。
- 监控与告警:监控缓存命中率、数据库QPS,及时发现异常并调整策略。
分布式锁
如何解决 Redis 的并发竞争 Key 问题?
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
基于 zookeeper 临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在 zookeeper 上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
在实践中,当然是从以可靠性为主。所以首推 Zookeeper。
怎样用Redis实现分布式锁?怎样用zookeeper实现分布式锁?怎样用数据库实现分布式锁?
分布式的CAP理论告诉我们任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。一般情况下,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证最终一致性,只要这个最终时间是在用户可以接受的范围内即可。在很多时候,为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。
一个可靠的、高可用的分布式锁需要满足以下几点
互斥性:任意时刻只能有一个客户端拥有锁,不能被多个客户端获取
安全性:锁只能被持有该锁的客户端删除,不能被其它客户端删除
死锁避免:获取锁的客户端因为某些原因而宕机,而未能释放锁,其它客户端也就无法获取该锁,需要有机制来避免该类问题的发生
高可用:当部分节点宕机,客户端仍能获取锁或者释放锁
基于数据库实现的乐观锁
乐观锁的通常是基于数据版本号来实现的。比如,有个商品表t_goods,有一个字段left_count用来记录商品的库存个数。在并发的情况下,为了保证不出现超卖现象,即left_count不为负数。乐观锁的实现方式为给商品表增加一个版本号字段version,默认为0,每修改一次数据,将版本号加1。
无版本号并发超卖示例:
线程1查询,当前left_count为1,则有记录
select * from t_goods where id = 10001 and left_count > 0
线程2查询,当前left_count为1,也有记录
select * from t_goods where id = 10001 and left_count > 0
线程1下单成功库存减一,修改left_count为0,
update t_goods set left_count = left_count - 1 where id = 10001
线程2下单成功库存减一,修改left_count为-1,产生脏数据
update t_goods set left_count = left_count - 1 where id = 10001
有版本号的乐观锁示例:
线程1查询,当前left_count为1,则有记录,当前版本号为999
select left_count, version from t_goods where id = 10001 and left_count > 0;
线程2查询,当前left_count为1,也有记录,当前版本号为999
select left_count, version from t_goods where id = 10001 and left_count > 0;
线程1,更新完成后当前的version为1000,update状态为1,更新成功
update t_goods set version = 1000, left_count = left_count-1 where id = 10001 and version = 999;
线程2,更新由于当前的version为1000,udpate状态为0,更新失败,再针对相关业务做异常处理
update t_goods set version = 1000, left_count = left_count-1 where id = 10001 and version = 999;
可以发现,这种和CAS的乐观锁机制是类似的,所不同的是CAS的硬件来保证原子性,而这里是通过数据库来保证单条SQL语句的原子性。顺带一提CAS的ABA问题一般也是通过版本号来解决。
基于数据库实现的排他锁
基于数据库的排他锁需要通过数据库的唯一性约束UNIQUE KEY来保证数据的唯一性,从而为锁的独占性提供基础。
CREATE TABLE `distribute_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`unique_mutex` varchar(64) NOT NULL COMMENT '需要锁住的资源或者方法',
-- `state` tinyint NOT NULL DEFAULT 1 COMMENT '1:未分配;2:已分配
PRIMARY KEY (`id`),
UNIQUE KEY `unique_mutex`
);
其中,unique_mutex就是我们需要加锁的对象,需要用UNIQUE KEY来保证此对象唯一
加锁时增加一条记录
insert into distribute_lock(unique_mutex) values('mutex_demo');
如果当前SQL执行成功代表加锁成功,如果抛出唯一索引异常(DuplicatedKeyException)则代表加锁失败,当前锁已经被其他竞争者获取。
解锁锁时删除该记录
delete from distribute_lock(unique_mutex) values('muetx_demo');
除了增删记录,也可以通过更新state字段来标识是否获取到锁
update distribute_lock set state = 2 where `unique_mutex` = 'muetx_demo' and state=1;
更新之前需要SELECT确认锁在数据库中存在,没有则创建之。如果创建或更新失败,则说明这个资源已经被别的线程占用了。
数据库排他锁可能出现的问题及解决思路:
没有失效时间, 一旦解锁失败,会导致锁记录一直在数据库中,其他线程无法再获得锁。可通过定时任务清除超时数据来解决
是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。可通过增加字段记录当前主机信息和当线程信息
这个锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的在线程并不会进入阻塞队列,需要不停自旋直到获得锁,相对耗资源。
基于数据库的分布式锁,能够满足一些简单的需求,好处是能够少引入依赖,实现较为简单,缺点是性能较低,且难以满足复杂场景下的高并发需求。
基于redis的实现
一个简单的分布式锁机制是使用setnx、expire 、del 三个命令的组合来实现的。setnx命令的含义为:当且仅当key不存在时,value设置成功,返回1;否则返回0。
加锁,设置锁的唯一标识key,返回1说明加锁成功,返回0加锁失败
setnx key value
设置锁超时时间为30s,防止死锁
expire key 30
解锁, 删除锁
del key
这种思路存在的问题:
1:setnx和expire的非原子性:如果加锁之后,服务器宕机,导致expire和del均执行不了,会导致死锁。
将加锁和设置锁过期时间做成一个原子性操作;在Redis 2.6.12版本之后,set命令增加了NX可选参数,可替代setnx命令;增加了EX可选参数,可以设置key的同时指定过期时间;或者将两个操作封装在lua脚本中,发送给Redis执行,从而实现操作的原子性。
2:del导致误删:A线程超时之后未执行完, 锁过期释放;B线程获得锁,此时A线程执行完,执行del将B线程的锁删除。
将key的value设置为线程相关信息,del释放锁之前先判断一下锁是不是自己的。(释放和判断不是原子性的,需要封装在lua脚本中或者用Redis自身事务)
3:锁过期后引起的并发:A线程超时之后未执行完, 锁过期释放;B线程获得锁,此时A、B线程并发执行会导致线程安全问题。启动一个守护线程,在后台自动给自己的锁''续期“,执行完成,显式关掉守护进程;redis集群环境下,我们自己写的也不OK, 直接上RedLock之Redisson落地实现
redis分布式锁的缺点
在大型的应用中,一般redis服务都是集群形式部署的,由于Slave同步Master是异步的,所以会出现客户端A在Master上加锁,此时Master宕机,Slave没有完成锁的同步,Slave变为Master,客户端B此时可以完成加锁操作。为了解决这一问题,官方给出了redlock算法,即使这样在一些较复杂的场景下也不能100%保证没有问题。
基于zookeeper的实现
zookeeper 是一个开源的分布式协调服务框架,主要用来解决分布式集群中的一致性问题和数据管理问题。zookeeper本质上是一个分布式文件系统,由一群树状节点组成,每个节点可以存放少量数据,且具有唯一性
zookeeper有四种类型的节点:
持久节点(PERSISTENT)默认节点类型,断开连接仍然存在
持久顺序节点(PERSISTENT_SEQUENTIAL)在持久节点的基础上,增加了顺序性。指定创建同名节点,会根据创建顺序在指定的节点名称后面带上顺序编号,以保证节点具有唯一性和顺序性
临时节点(EPHEMERAL)断开连接后,节点会被删除
临时顺序节点(EPHEMERAL_SEQUENTIAL)在临时节点的基础上,增加了顺序性。
基于zookeeper实现的分布式锁主要利用了zookeeper临时顺序节点的特性和事件监听机制。主要思路如下:
1:创建节点实现加锁,通过节点的唯一性,来实现锁的互斥;如果使用临时节点,节点创建成功表示获取到锁;如果使用临时顺序节点,客户端创建的节点为顺序最小节点,表示获取到锁
2:删除节点实现解锁
3:通过临时节点的断开连接自动删除的特性来避免持有锁的服务器宕机而导致的死锁
4:通过节点的顺序性和事件监听机制,大节点监听小节点,形成节点监听链,来实现等待队列(公平锁)
不使用监听机制,未获取到锁的线程自旋重试或者失败退出(根据业务决定),可实现非阻塞的乐观锁。
不使用临时顺序节点,而使用临时节点,所有客户端都去监听该临时节点,可实现非公平锁。但是会产生"羊群效应",单个事件,引发多个服务器响应,占用服务器资源和网络带宽,需要根据业务场景选用。
zookeeper分布式锁的缺点:
1:zookeeper分布式锁是性能可能没有redis分布式锁高,因为每次在创建锁和释放锁的过程中,都要动态创建、销毁临时节点来实现锁功能。
2:使用zookeeper也有可能带来并发问题,只是并不常见而已。比如,由于网络抖动,客户端与zk集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点。
总结
从实现的复杂性角度(从高到低)zookeeper >= redis> 数据库
数据库实现的分布式锁易于理解和实现,且不会给项目引入其他依赖。zookeeper和redis需要考虑的情况更多,实现相对较为复杂,但是都有现成的分布式锁框架curator和redision,用起来代码反而可能会更简洁。
从性能角度(从高到低)redis>zookeeper > 数据库
redis数据存在内存,速度很快;zookeeper虽然数据也存在内存中,但是本身维护节点的一致性。需要耗费一些性能;数据库则只有索引在内存中,数据存于磁盘,性能较差。
从可靠性角度(从高到低)zookeeper > redis > 数据库
zookeeper天生设计定位就是分布式协调,强一致性,可靠性较高;redis分布式锁需要较多额外手段去保证可靠性;数据库则较难满足复杂场景的需求。
数据一致性
【问题】 如何保证Redis缓存与数据库双写时的数据一致性?为了保证缓存和数据库一致性,说说只读缓存的方案?
【参考答案】 在分布式系统中,缓存与数据库双写时可能出现数据不一致,主要因为并发操作导致缓存和数据库中的数据不同步。保证一致性需要根据业务对一致性的要求(强一致性或最终一致性)选择合适的策略。以下介绍常见的解决方案,并重点阐述只读缓存(Cache Aside)模式。
一、常见的双写一致性方案
- 先更新数据库,再更新缓存(不推荐)
- 步骤:先写数据库,成功后更新缓存。
- 问题:并发下可能导致数据不一致。例如,两个写线程同时操作,A写库后B写库,B先更新缓存,A后更新缓存,导致缓存中是旧值。
- 适用场景:极少使用,除非对一致性要求不高且更新操作极少。
- 先更新缓存,再更新数据库(不推荐)
- 步骤:先更新缓存,再写数据库。
- 问题:如果缓存更新成功而数据库更新失败,数据不一致;且并发下同样可能错乱。
- 先删除缓存,再更新数据库(Cache Aside变种)
- 步骤:写操作先删除缓存,再更新数据库。读操作先读缓存,未命中则读数据库,然后写回缓存。
- 问题:并发下可能造成脏数据。例如:线程A删除缓存后,准备更新数据库;此时线程B读缓存未命中,读数据库得到旧值并写回缓存;然后线程A更新数据库为新值,导致缓存中一直是旧值。
- 解决方案:延时双删策略:在更新数据库后,延迟一段时间再次删除缓存,确保读线程可能写入的旧缓存被清除。但延迟时间难以确定,且仍可能短暂不一致。
- 先更新数据库,再删除缓存(推荐,Cache Aside经典模式)
- 步骤:写操作先更新数据库,成功后删除缓存。读操作先读缓存,未命中则读数据库,然后写回缓存。
- 优势:这是Facebook等公司采用的模式,在大多数场景下能保证最终一致性。因为读操作写缓存是在数据库更新之后,只要缓存删除成功,下次读就会加载最新数据。并发问题主要出现在:线程A更新数据库后删除缓存前,线程B读缓存未命中,读数据库得到旧值并写回缓存。但这种情况概率较低,且可以通过延迟双删(第一次删除后,短暂延时再次删除)进一步降低不一致窗口。
- 缺点:如果删除缓存失败,会导致脏数据。可通过重试机制(如消息队列异步重试)保证最终删除成功。
- 基于消息队列的异步同步
- 步骤:写操作只更新数据库,然后发送一条消息到MQ,消费端异步删除或更新缓存。利用MQ的重试和至少一次送达保证最终一致性。
- 优点:解耦,可靠性高。
- 缺点:引入消息中间件,增加复杂性。
- 读写锁(强一致性方案)
- 步骤:对某个key的读写操作加分布式锁,确保同一时刻只有一个线程操作。写操作加写锁,读操作加读锁,实现强一致性。
- 优点:可保证强一致性。
- 缺点:并发性能大幅下降,适用于对一致性要求极高的场景(如金融交易)。
二、只读缓存(Cache Aside)方案详解 只读缓存方案是实际应用中最常见的模式,其核心思想是:写操作只更新数据库,并让缓存失效;读操作先读缓存,未命中则读数据库,再写回缓存。这样保证了缓存中的数据总是从数据库加载的,只要数据库是最新的,缓存最终也会是最新的。
工作流程
- 读请求:
- 先查询Redis,若命中则直接返回。
- 若未命中,查询MySQL,获取数据。
- 将数据写入Redis,并设置过期时间(可选)。
- 返回数据。
- 写请求:
- 更新MySQL数据库。
- 删除Redis中对应的缓存(或者将缓存置为失效)。
为什么删除缓存而不是更新缓存?
- 更新缓存需要知道新数据,且可能涉及复杂计算;而删除缓存更简单,且能保证下次读时加载最新数据。
- 删除操作是幂等的,多次删除不影响结果。
如何保证删除成功?
- 若删除失败,缓存中仍是旧数据。可以通过以下方式保证:
- 重试机制:将删除操作放入消息队列,由消费者异步重试直到成功。
- 设置缓存过期时间:即使删除失败,缓存也会在过期后自动失效,最终从数据库加载新数据(实现最终一致性)。
- 结合数据库事务和本地消息表:在数据库事务中插入一条待删除记录,由后台任务扫描并执行删除。
并发下的一致性分析 考虑一个典型并发场景:
- 线程A执行写操作:更新数据库 → 删除缓存(假设成功)。
- 线程B执行读操作:在A删除缓存后、更新数据库前?不,A先更新数据库,所以数据已新。主要风险在于A更新数据库后、删除缓存前,线程B读缓存未命中,读数据库得到旧数据(因为A还未提交?但数据库通常读已提交,若A已提交,则B读到新数据;若A未提交,则B读到旧数据,但A还未提交,此时数据库状态还是旧,理论上读到的旧数据是正确的,因为A的事务可能回滚。所以真正的不一致窗口在A提交后、删除缓存前,如果此时有读请求,会读数据库得到新值(因为A已提交),然后写回缓存,这恰好是正确的。唯一可能导致脏数据的是:A提交后,B读数据库得到新值并写缓存,然后A删除缓存,这样缓存被删掉,下次读会重新加载,没问题。所以经典模式基本安全。
但有一个经典并发问题:线程A更新数据库,删除缓存之前,线程B读缓存未命中,读数据库(此时可能读到A未提交的数据,取决于隔离级别),然后写回缓存(此时缓存中是旧值,如果A提交后删缓存成功,则旧值被删;但如果B写缓存发生在A删除缓存之后?实际上由于网络延迟,可能B写缓存在A删除之后,导致缓存中永远是旧值?分析:假设顺序为:A更新数据库(提交)→ B读数据库(此时得到新值)→ B写缓存(新值)→ A删除缓存(此时缓存被删)。没问题。如果顺序是:A更新数据库(提交)→ A删除缓存 → B读数据库(新值)→ B写缓存(新值),也没问题。问题出现在:A更新数据库(提交)后,B读数据库得到旧值?不可能,因为A已提交,数据库是新的。除非A未提交,但此时数据库还是旧值,B读到的旧值对应数据库旧状态,而A可能回滚,所以B读到的旧值是合理的。因此经典模式在大多数场景下能保证最终一致性。
只读缓存的优缺点
- 优点:实现简单,与业务解耦,能有效降低数据库压力。
- 缺点:存在短暂不一致窗口(从数据库更新到缓存删除成功之间),但通常可接受;需要处理缓存删除失败问题。
【大白话解释】
- 只读缓存:好比图书馆有电脑查询系统(缓存)和实体书架(数据库)。读者查书:
- 先看电脑,如果有直接取书号(读缓存命中)。
- 如果电脑没有,就去书架找书,找到后在电脑上登记一下(写回缓存),方便下次别人查。
- 管理员还书(写操作):
- 先把书放回书架(更新数据库),然后删掉电脑上的记录(删除缓存)。这样下次有人查这本书,电脑上没有,就会去书架找最新的,并重新登记。
- 万一删记录时网络故障,电脑上还有旧记录,但书已经更新了,读者查电脑会得到错误信息。解决方法是:给电脑记录设个有效期(过期时间),过期后自动消失,最终还是会从书架找;或者管理员反复尝试删除直到成功。
【扩展知识点】
- 缓存更新策略对比:
- Cache Aside:写时删除缓存,读时加载。最常用。
- Read Through:读时若未命中,由缓存服务自动加载(类似Cache Aside,但加载逻辑在缓存层)。
- Write Through:写时先更新缓存,缓存同步更新数据库(强一致但性能低)。
- Write Behind:写时只更新缓存,异步批量更新数据库(高吞吐但可能丢数据)。
-
最终一致性保证:通过设置缓存过期时间,即使删除失败,也能在过期后恢复一致。
-
分布式锁与强一致性:对于严格一致性的场景(如库存扣减),可采用分布式锁或使用Redis的原子操作(如DECR)结合Lua脚本实现。
-
缓存粒度问题:更新数据库时,是删除整个对象缓存还是部分字段?通常删除整个key即可。
-
重试机制的设计:可结合本地消息表、MQ或Redis的list作为重试队列,确保删除操作最终成功。
- 监控与补偿:定期扫描缓存与数据库的差异,进行补偿修复(如通过业务日志或定时任务)。
总之,对于大多数业务,采用先更新数据库再删除缓存的只读缓存方案,配合过期时间和重试机制,即可满足最终一致性要求。若需要强一致性,需引入锁或分布式事务。
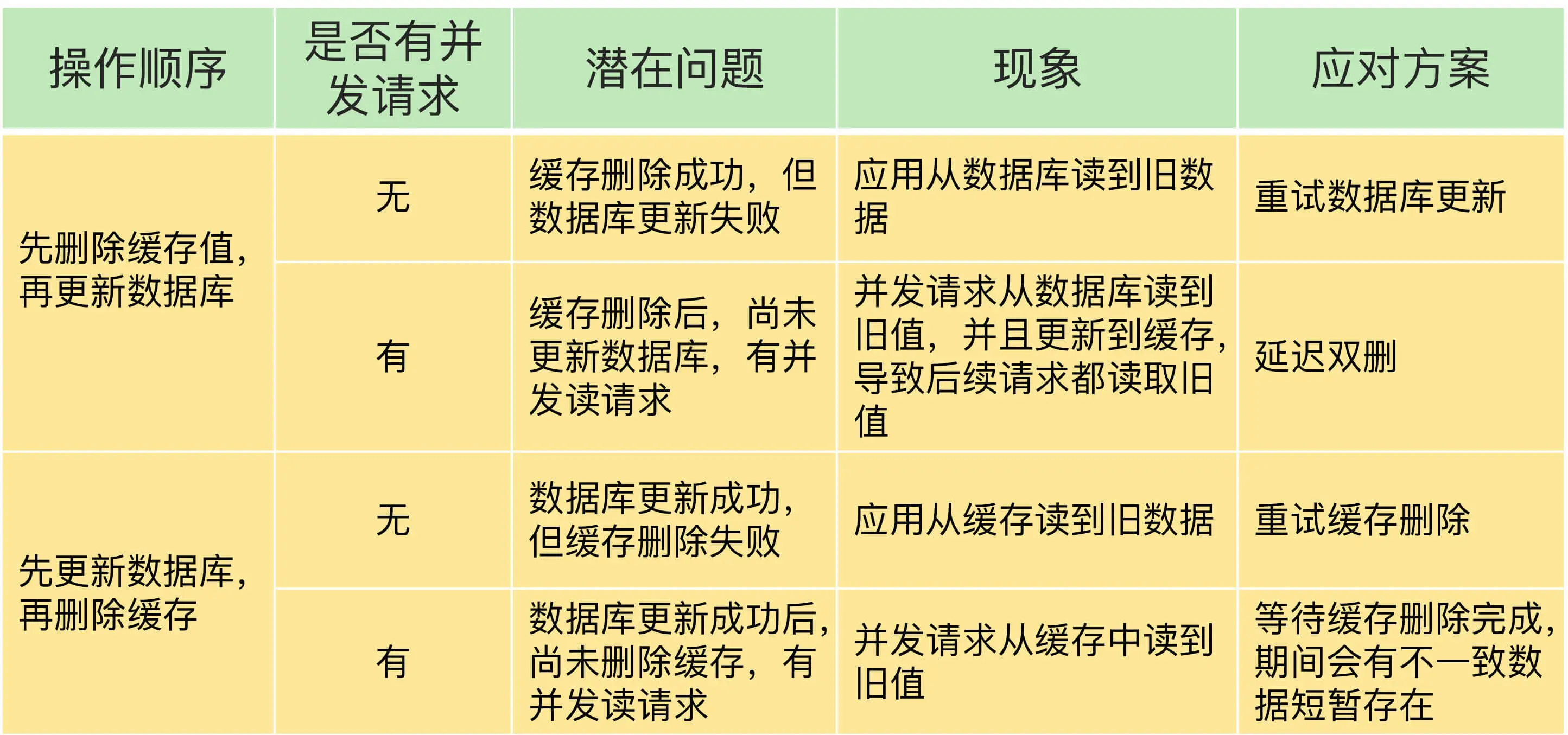
高可用与性能
【问题】 Redis 如何实现高可用?高可用方案有几种?最优方案是什么?Redis集群在宕机后怎么最快恢复数据?恢复数据的流程是什么?
【参考答案】
一、Redis如何实现高可用? Redis的高可用(High Availability,HA)是指当部分节点故障时,系统仍能持续提供服务的能力。主要通过以下机制实现:
- 主从复制(Replication):一个主节点(Master)可以有多个从节点(Slave),从节点实时同步主节点的数据,实现读写分离和数据冗余。
- 故障检测与自动转移:通过哨兵(Sentinel)或集群(Cluster)的监控和选举机制,在主节点故障时自动将从节点提升为新的主节点,并通知客户端更新连接。
- 持久化:通过RDB和AOF将数据持久化到磁盘,在节点重启或故障后能够恢复数据。
- 分片与多副本:在集群模式下,数据分片存储在不同节点,每个分片有多个副本(主从),部分节点故障不影响整体服务。
二、Redis高可用方案有几种? 主要有三种高可用方案:
- 主从复制(Master-Slave Replication)
- 架构:一主多从,主节点负责写,从节点负责读(可选)。主节点故障时需要手动将从节点提升为主,或借助第三方工具(如keepalived)实现自动切换,但严格来说不是原生高可用。
- 优点:简单,读写分离提升读性能。
- 缺点:主节点故障时切换需要人工干预或额外脚本,可能造成服务中断。
- 哨兵模式(Sentinel)
- 架构:在主从复制基础上,增加哨兵集群(至少3个哨兵节点)监控所有节点,自动完成故障检测、选举和故障转移,并通知客户端。
- 优点:实现自动故障转移,保证服务的高可用;监控和通知机制完善。
- 缺点:仍存在单点写瓶颈(只有一个主节点),数据量受单机内存限制。
- Redis集群模式(Cluster)
- 架构:数据自动分片到多个主节点,每个主节点有多个从节点作为副本。集群内节点相互通信(Gossip协议),自动进行故障转移和重分片。
- 优点:支持水平扩展,无中心化架构,高可用和分布式一体;单个节点故障不影响全局。
- 缺点:配置相对复杂,客户端需支持集群协议;跨分片操作(如多键事务)受限。
此外,云服务商提供的托管Redis(如阿里云、AWS ElastiCache)也集成了高可用特性,但属于商业方案。
三、最优方案是什么? “最优”取决于业务需求、数据规模和运维能力:
- 对于数据量不大(可单机承载)、需要高可用和自动故障转移的场景,哨兵模式是最佳选择,配置简单,满足大多数中小型应用。
- 对于数据量巨大、需要水平扩展和高并发写操作的场景,Redis集群模式是最优方案,能够线性扩展性能和存储容量,并原生支持高可用。
- 如果预算充足且希望减少运维,云服务商的托管Redis是省心的选择。
一般来说,生产环境优先推荐Redis集群模式,因为它不仅实现了高可用,还解决了单机容量和性能瓶颈,是未来扩展的基础。
四、Redis集群在宕机后怎么最快恢复数据? Redis集群的“宕机”可能涉及以下几种情况,恢复策略不同:
- 单个从节点宕机:不影响集群服务,只需重启从节点,它会自动从主节点同步数据恢复。
- 单个主节点宕机:如果该主节点有健康的从节点,集群会自动触发故障转移,将其中一个从节点提升为新的主节点,服务快速恢复(秒级),数据由从节点继承,基本不丢失。
- 多个主节点同时宕机:可能造成部分槽位不可用,集群进入fail状态,需要人工介入。恢复最快的方式是:
- 优先使用从节点恢复:如果宕机的主节点还有从节点存活,可手动执行
CLUSTER FAILOVER或等待自动转移(如果配置允许)。 - 使用持久化文件恢复:如果所有副本都故障,需要重启宕机节点并从持久化文件(RDB/AOF)恢复数据。确保最近一次持久化文件可用。
- 结合备份和AOF:如果有定期备份(RDB文件),可以复制到节点目录,启动后自动加载;同时开启AOF可减少数据丢失。
- 优先使用从节点恢复:如果宕机的主节点还有从节点存活,可手动执行
最快恢复的要点:
- 确保持久化开启(最好同时RDB和AOF),并定期备份。
- 保证每个主节点至少有一个健康的从节点,这样自动故障转移最快。
- 使用哨兵或集群的自动故障转移,减少人工干预时间。
- 对于极端情况,提前准备备份文件和恢复脚本。
五、恢复数据的流程是什么? 以下以Redis集群模式为例,描述主节点故障后的恢复流程(自动和手动):
- 自动故障转移(主节点有从节点)
- 检测故障:集群中其他主节点通过Gossip协议发现某个主节点不可达(PFAIL状态),经过多数主节点确认后标记为FAIL。
- 选举从节点:故障主节点的从节点中,通过Raft风格的选举选出优先级最高、数据最完整的一个从节点。
- 提升为主:被选中的从节点执行
SLAVEOF NO ONE,停止复制,将自己变为主节点,并接管原主节点的所有槽位。 - 更新集群状态:新主节点广播消息,其他节点更新路由信息。客户端感知到变化(通过MOVED或ASK重定向)。
- 恢复完成:整个流程通常在几秒到十几秒内完成,数据不丢失(因为从节点已同步原主节点数据)。
- 手动恢复(无从节点或自动转移失败)
- 步骤1:确认故障范围
使用CLUSTER NODES查看集群状态,确定宕机节点和受影响槽位。
- 步骤1:确认故障范围
- 步骤2:准备数据
- 如果节点还有持久化文件(RDB/AOF),直接使用。
- 如果没有最新文件,尝试从备份中恢复最近的RDB文件,并将其复制到节点数据目录。
-
步骤3:启动节点
修改配置文件,确保cluster-enabled yes,然后启动Redis进程。节点会加载持久化数据。 -
步骤4:加入集群
使用CLUSTER MEET <ip> <port>将节点重新加入集群(如果节点已在集群配置中,可能自动加入)。节点会尝试从其他主节点同步槽位数据,但若为旧主节点,需手动分配槽位或将其设为从节点。 - 步骤5:数据同步
- 如果节点作为新主节点,需要手动将槽位分配给它,或让它作为从节点复制其他主节点(若原主节点已恢复)。
- 使用
CLUSTER REPLICATE <node-id>将节点设为从节点,开始全量同步。
- 步骤6:恢复服务
集群重新达到稳定状态,所有槽位有主节点负责。客户端路由表更新后即可正常访问。
- 数据恢复的优化建议
- 启用AOF(
appendonly yes)并设置appendfsync everysec,最多丢失1秒数据。 - 定期执行
BGSAVE生成RDB快照,并异地备份。 - 对于集群模式,确保每个主节点至少有一个从节点,以提高容错性。
- 使用
redis-check-rdb和redis-check-aof工具修复损坏的持久化文件。
- 启用AOF(
【大白话解释于举例说明】
- 高可用:就像超市有好几个收银台(主节点),每个收银台有助手(从节点),如果某个收银员生病了,助手立刻顶上(故障转移),顾客(客户端)几乎感觉不到。
- 方案对比:主从复制像只有一个正式收银员和几个备用收银员,但生病时需要经理(人工)来安排;哨兵模式就像安排了专门的管理员(哨兵)时刻盯着,一旦发现自动安排;集群模式则像多个收银台各自独立,每个收银台也有助手,同时还能分担顾客(数据分片)。
- 恢复数据:如果某个收银台和助手都倒了(数据丢失),最快的方法是拿出昨天的销售记录(RDB备份)和今天的收银小票(AOF日志),重新录入系统,然后再开业。
【扩展知识点详解】
- 哨兵模式的架构细节:哨兵节点监控主从节点,通过主观下线(SDOWN)和客观下线(ODOWN)判断故障,通过Raft算法选举领导者执行故障转移。
- 集群的故障转移参数:
cluster-node-timeout控制节点超时时间,影响故障检测速度;cluster-slave-validity-factor控制从节点有效性。 - 数据丢失场景:异步复制可能导致少量数据丢失(主节点未同步给从节点就宕机),可通过配置
min-slaves-to-write和min-slaves-max-lag减少风险。 - 备份策略:结合RDB和AOF,同时开启混合持久化(Redis 4.0+),提高恢复效率。
- 无盘复制:在从节点全量同步时,主节点可以直接通过网络发送RDB数据,避免磁盘I/O。
- 故障转移后的数据一致性:新主节点可能丢失部分未同步的写操作,需要业务层面容忍或使用WAIT命令增强一致性。
- 集群维护:使用
redis-cli --cluster工具进行节点添加、删除、重新分片等操作。 - 监控与告警:结合Prometheus、Grafana等监控Redis指标(如
cluster_state、connected_slaves),及时发现异常。
通过合理选择和配置高可用方案,并制定完善的备份与恢复流程,Redis可以满足绝大多数生产环境的高可用要求。
【问题】 Redis 常见性能问题和解决方案有哪些?
【参考答案】 Redis 作为高性能内存数据库,在生产环境中可能遇到各种性能问题。以下是常见问题及其解决方案,按类别归纳:
一、持久化相关性能问题
- 问题:主节点执行 RDB 快照导致阻塞
- 现象:
SAVE命令直接阻塞主线程,BGSAVE虽然 fork 子进程,但 fork 操作本身会阻塞主线程(内存越大阻塞时间越长)。快照生成期间,主线程无法处理请求,导致服务间歇性暂停。 - 解决方案:
- 禁止在主节点执行
SAVE,尽量使用BGSAVE。 - 如果数据量巨大,可考虑关闭主节点 RDB,仅在从节点开启 RDB,或使用无盘复制(
repl-diskless-sync yes)。 - 调整
save配置,避免频繁自动触发 RDB。 - 监控 fork 耗时,优化系统内存分配(如设置
vm.overcommit_memory=1)。
- 禁止在主节点执行
- 现象:
- 问题:AOF 重写或同步导致性能抖动
- 现象:AOF 重写时 fork 子进程,同样有 fork 阻塞。同时,如果
appendfsync always,每次写命令都会同步磁盘,严重影响性能。 - 解决方案:
- 设置合理的
appendfsync策略,如everysec(每秒同步)兼顾性能与安全。 - 将 AOF 重写放在从节点执行,或调整自动重写阈值(
auto-aof-rewrite-percentage、auto-aof-rewrite-min-size)。 - 使用 SSD 磁盘提升 I/O 性能。
- 设置合理的
- 现象:AOF 重写时 fork 子进程,同样有 fork 阻塞。同时,如果
二、主从复制相关性能问题
- 问题:主从复制延迟或断连
- 现象:从节点复制滞后,或频繁断线重连,导致全量复制开销大。
- 解决方案:
- 主从节点尽量部署在同一局域网,保证网络低延迟和高带宽。
- 合理设置
repl-backlog-size,增大复制积压缓冲区,避免因网络抖动触发全量复制。 - 避免在主节点压力大时增加从节点,可先低峰期添加。
- 使用链式复制(主-从-从)减轻主节点推送压力。
- 问题:主从复制拓扑结构不合理
- 现象:使用图状结构(如多个从节点互相复制),导致数据混乱和复制风暴。
- 解决方案:采用单向链表结构(
Master -> Slave1 -> Slave2 -> ...),便于故障转移和维护。避免循环复制。
三、内存相关问题
- 问题:内存不足导致频繁淘汰或 OOM
- 现象:
maxmemory设置不合理,导致evicted_keys激增,命中率下降,甚至写失败。 - 解决方案:
- 根据数据量预估合理设置
maxmemory,并留有一定余量。 - 选择合适的淘汰策略(如
allkeys-lru)。 - 监控内存使用,及时扩容或清理无用数据。
- 根据数据量预估合理设置
- 现象:
- 问题:大 key 问题
- 现象:单个 key 存储过大(如大 Hash、大 List),操作时阻塞主线程(如
HGETALL、LRANGE),或导致网络传输慢。 - 解决方案:
- 拆分大 key 为多个小 key(如 Hash 分桶)。
- 使用
SCAN类命令替代直接获取所有元素。 - 删除大 key 时使用
UNLINK(异步删除)避免阻塞。
- 现象:单个 key 存储过大(如大 Hash、大 List),操作时阻塞主线程(如
四、命令与使用不当问题
- 问题:慢查询
- 现象:执行复杂命令(如
SORT、KEYS、SMEMBERS)或 O(N) 命令处理大量数据,阻塞主线程。 - 解决方案:
- 使用
SLOWLOG定位慢查询,优化命令或数据模型。 - 避免使用
KEYS,改用SCAN。 - 对集合操作使用
SSCAN、HSCAN等游标命令。 - 控制一次操作的数据量,如
LRANGE限制范围。
- 使用
- 现象:执行复杂命令(如
- 问题:频繁创建/关闭连接
- 现象:客户端短连接导致 TCP 开销大。
- 解决方案:使用连接池(如 JedisPool、Lettuce),复用连接。
五、网络与系统层面问题
- 问题:网络带宽瓶颈
- 现象:大量数据传输(如 RDB 同步、大 key 响应)占满带宽。
- 解决方案:
- 启用压缩(如
set时压缩大文本)。 - 限制单个响应大小,或使用 Pipeline 合并请求。
- 升级网络设备。
- 启用压缩(如
- 问题:系统参数配置不当
- 现象:如
overcommit_memory未设置导致 fork 失败,transparent_hugepage开启导致内存延迟。 - 解决方案:
- 设置
vm.overcommit_memory = 1。 - 关闭透明大页(
echo never > /sys/kernel/mm/transparent_hugepage/enabled)。 - 调整
somaxconn和tcp_backlog提高连接队列长度。
- 设置
- 现象:如
六、其他常见问题
- 问题:缓存穿透、击穿、雪崩
- 详见之前的解答。
- 问题:Lua 脚本长时间执行
- 现象:Lua 脚本执行时间过长阻塞其他命令。
- 解决方案:控制脚本执行时间,使用
SCRIPT KILL终止,或优化脚本逻辑。
【大白话解释于举例说明】
- 持久化阻塞:好比你在记账(主线程),突然有人让你去复印一整本账本(RDB 快照),你只能停下手中的笔去复印,顾客就得等着。解决办法是让别人(从节点)去复印,或者复印时用复写纸(无盘复制)减少等待。
- 复制延迟:老师讲课(主节点),学生(从节点)记笔记,如果教室太大(网络远)或者老师讲得太快(压力大),学生就记不过来。可以让几个学生当助教(链式复制)分担记录任务。
- 大 key:一个篮子里装太多鸡蛋,拿的时候容易打碎(阻塞)。不如分装到多个小篮子,每次只拿一小篮。
【扩展知识点详解】
- 持久化优化:
save配置:save 900 1表示 900 秒内有 1 次修改就触发 BGSAVE。rdbcompression可开启压缩,减少 RDB 体积但消耗 CPU。- AOF 重写期间,主线程继续服务,子进程写临时文件,重写完成后替换原文件。
- 主从复制优化:
repl-diskless-sync:无盘复制,主节点直接通过网络发送 RDB,适合磁盘慢网络快的场景。repl-timeout:设置复制超时时间,避免误判。- 从节点可设置
slave-read-only=yes防止写。
- 内存优化:
- 使用
MEMORY USAGE key分析 key 内存占用。 - 调整编码阈值,如
hash-max-ziplist-entries控制小对象编码。 - 开启
activedefrag自动碎片整理。
- 使用
- 监控工具:
INFO命令查看各项指标。redis-cli --stat实时统计。redis-benchmark压测性能。- 结合 Prometheus + Grafana 可视化监控。
- 系统配置建议:
- 设置
maxclients限制最大连接数。 - 调整
tcp-keepalive检测死连接。 - 使用非 root 用户运行 Redis 提升安全。
- 设置
通过以上措施,可以显著提升 Redis 的生产稳定性与性能。
【问题】 Redis中Pipeline有什么好处,为什么要用pipeline?
【参考答案】 Pipeline(管道)是Redis提供的一种批量执行命令的机制,它允许客户端将多个命令一次性发送到服务器,而不需要等待每个命令的响应。服务器在处理完所有命令后,再将所有响应一次性返回给客户端。Pipeline的核心好处是显著减少网络往返时间(RTT,Round-Trip Time),从而大幅提升批量操作的性能。
一、Pipeline的主要好处
-
减少网络延迟
在普通模式下,执行n个命令需要n次网络往返(请求→响应)。而使用Pipeline,只需要一次网络往返(发送n个命令,接收n个响应)。对于远程部署的Redis,网络延迟可能是几毫秒到几十毫秒,Pipeline能将延迟降低到原来的1/n,极大提升吞吐量。 -
提升吞吐量
由于减少了等待响应的空闲时间,客户端可以在同一时间内发送更多命令,服务器也能更高效地处理。尤其适合需要批量写入或读取的场景(如批量插入、数据初始化)。 -
节省带宽
将多个命令打包发送,减少了TCP包的数量和协议头开销,更有效地利用网络带宽。 -
降低服务器端连接压力
减少了客户端与服务器之间的交互次数,降低了服务器处理网络事件的开销,间接提高服务器并发能力。 -
实现简单,无需修改业务逻辑
Pipeline通过客户端库提供,只需将多个命令放入管道,然后一次性提交,对业务代码侵入小。
二、为什么要用Pipeline?
- 应对高延迟网络:如果客户端和Redis服务器不在同一机房(如跨机房部署),网络延迟较大,Pipeline的优势尤为明显。
- 批量操作场景:例如初始化大量数据、缓存预热、批量删除或更新等。这些场景下,使用Pipeline可以节省大量时间。
- 减少客户端CPU/内存开销:非Pipeline模式需要为每个请求创建和解析响应,Pipeline统一处理,减少了重复工作。
- 避免阻塞其他操作:Pipeline中的命令在服务器端仍是串行执行,但客户端无需等待每个响应,可以继续其他任务(如果是异步Pipeline)。
三、Pipeline的注意事项
- 非原子性:Pipeline只是将多个命令打包发送,但服务器执行时依然是顺序执行,且不会保证这些命令作为一个整体被原子执行。如果中间某个命令失败,后续命令仍会执行(类似事务但不支持回滚)。若需要原子性,应使用事务(MULTI/EXEC)或Lua脚本。
- 内存占用:客户端在Pipeline发送前需缓存所有命令,服务器也需要缓存所有响应,因此命令数量不宜过多(建议分批,如每1000条一批),否则可能导致客户端或服务器内存压力。
- 依赖客户端支持:并非所有Redis客户端都支持Pipeline,但主流客户端(如Jedis、Lettuce、Redisson)均有实现。
- 与事务的区别:Pipeline关注性能,事务关注原子性。两者可结合使用(Pipeline中包含MULTI/EXEC),但需注意事务命令本身也需要网络往返。
【大白话解释】 想象你去超市购物(发送命令),普通模式是:你买一瓶水,付钱(等待),再买一包薯片,付钱(等待),如此反复,每次都要排队(网络往返)。而Pipeline就像你推个购物车,把所有想买的商品一次性装进去,然后到收银台一次性结账,大大节省了时间。
但Pipeline有个缺点:它不能保证这些商品是作为一个整体被处理(原子性),比如收银台刷了10件商品,第5件条码扫不出来,其他9件照样结账。如果要求要么全买要么全不买,就得用事务(MULTI/EXEC)——相当于提前和收银员说“这一车要么全买,要么不买”。
【扩展知识点】
-
Pipeline与批量命令的区别
Redis本身有些命令支持批量操作,如MSET、MGET、HMGET、LPUSH等,它们能在一次请求中处理多个key,效率比Pipeline更高(因为服务器内部优化)。但Pipeline可以组合不同类型的命令,灵活性更强。 -
Pipeline与事务结合
可以在Pipeline中包含MULTI和EXEC,使一批命令以事务方式执行,既享受Pipeline的低延迟,又获得原子性保证。 -
Pipeline与异步I/O
在异步客户端(如Lettuce)中,Pipeline通常基于异步编程模型实现,无需阻塞等待,进一步提升性能。 - 性能对比示例
假设网络延迟为1ms,执行1000条命令:- 普通模式:耗时约1000 * 1ms = 1秒(忽略执行时间)。
- Pipeline模式:耗时约1ms(一次往返) + 1000条命令执行时间(假设每条0.1ms)= 约1.1ms + 0.1ms * 1000 = 101.1ms,性能提升近10倍。
- 注意事项总结
- 控制单次Pipeline的命令数量,避免内存溢出。
- 若命令间有依赖(如后一个命令需要前一个的结果),Pipeline无法处理,因为结果尚未返回。此时需使用事务或Lua脚本。
- 在高并发场景,合理使用Pipeline可有效降低Redis负载。
总之,Pipeline是Redis性能优化的重要手段,尤其在批量操作和高延迟网络环境中,能带来数量级的性能提升。
【问题】 Jedis与Redisson对比有什么优缺点?
【参考答案】 Jedis和Redisson都是Java语言中常用的Redis客户端,但它们在设计理念、功能特性和使用场景上有显著区别。以下是详细对比:
一、Jedis 定位:轻量级、底层的Redis客户端,直接暴露Redis API,命令与Redis原生命令一一对应。
优点:
- 简单易用:API直观,与Redis命令几乎一致,学习成本低。
- 性能高:基于同步阻塞I/O,在低并发场景下性能优秀。
- 轻量级:依赖少,代码体积小,适合对依赖敏感的项目。
- 广泛使用:社区成熟,文档丰富,问题易排查。
缺点:
- 线程不安全:多个线程不能共享同一个Jedis实例,需使用连接池(如JedisPool)来管理,每个线程从池中获取连接。
- 功能单一:仅支持基本的Redis命令,未封装高级分布式对象(如分布式锁、计数器、队列等)。
- 不支持异步/响应式:所有操作都是同步阻塞的,无法充分利用系统资源进行非阻塞调用。
- 连接管理:需要手动管理连接池,配置不当可能影响性能。
二、Redisson
定位:基于Redis的分布式Java对象和服务框架,提供了丰富的分布式数据结构(如RMap、RSet、RLock等)和高级功能。
优点:
- 功能丰富:内置分布式锁(
RLock)、分布式集合、限流器、延迟队列、布隆过滤器等,开箱即用。 - 线程安全:所有对象和服务都是线程安全的,可共享同一个Redisson实例。
- 支持异步和响应式:基于Netty,提供异步API(
RFuture)和响应式API(RxJava3/Reactor),支持高并发非阻塞编程。 - 连接管理自动优化:自动管理连接池,支持主从、哨兵、集群模式,配置简单。
- 抽象层次高:开发者可以像使用本地Java集合一样操作分布式数据结构,减少重复代码。
缺点:
- 学习曲线较陡:需要理解其提供的分布式对象概念,API不如Jedis直接。
- 相对重量级:依赖较多(如Netty),项目体积增大,可能不适合小型项目。
- 性能略低:由于封装层次较多,在极端性能敏感场景下,可能不如直接使用Jedis高效(但通常差异可接受)。
- 版本兼容性:部分高级功能需要Redis 3.0+支持,且需注意Redisson版本与Redis版本的匹配。
三、选型建议
- 简单场景:仅需执行基本Redis命令(如缓存读写),对性能要求高,使用Jedis。
- 复杂分布式场景:需要使用分布式锁、队列、布隆过滤器等高级功能,或需要异步/响应式编程,选择Redisson。
- 混合使用:也可以同时引入两者,用Jedis处理简单命令,用Redisson处理复杂分布式协调,但需注意依赖冲突。
【大白话解释】
- Jedis:好比一把锤子,简单直接,上手就会用,能快速钉钉子。但如果你要修汽车(复杂分布式场景),光有锤子不够。
- Redisson:好比一个多功能工具箱,里面有扳手、螺丝刀、电钻等,几乎能应对所有维修需求。但你需要先学习这些工具怎么用,工具箱本身也比较重。
选哪个?如果是临时修个椅子(简单缓存),用锤子就行;如果是开修车铺(微服务架构),就得上工具箱。
【扩展知识点详解】
- 连接池配置:
- Jedis需要手动配置
JedisPool,合理设置maxTotal、maxIdle、minIdle等参数。 - Redisson自动管理连接,只需配置节点地址和线程池大小,内部使用
MasterSlaveConnectionManager等。
- Jedis需要手动配置
- 分布式锁实现:
- Redisson的
RLock实现了可重入锁,基于Lua脚本保证原子性,并支持自动续期(看门狗机制),防止死锁。 - Jedis需要自己用
SETNX+EXPIRE实现简单锁,但需处理超时、可重入等问题,容易出错。
- Redisson的
- 异步支持:
- Redisson的异步API(
RFuture)允许非阻塞调用,结合CompletionStage或回调,提升吞吐量。 - Jedis可通过多线程或连接池模拟异步,但本质上仍是同步阻塞。
- Redisson的异步API(
- 数据序列化:
- Jedis默认传输字节数组,需自行处理序列化(如JSON、Protobuf)。
- Redisson内置多种编解码器(Jackson、Kryo、Avro等),自动完成对象序列化。
- 集群与哨兵支持:
- Jedis通过
JedisCluster和JedisSentinelPool支持集群和哨兵,但配置相对复杂。 - Redisson通过
Config轻松配置集群、哨兵、主从模式,自动处理拓扑变化。
- Jedis通过
- 性能对比:
- 在纯命令执行上,Jedis可能略快(因为封装少)。但在高级功能上,Redisson的Lua优化可能更优。
- Redisson的异步模型在高并发下能获得更高吞吐量。
-
依赖冲突:
同时引入两者时,需注意Netty版本冲突,可通过exclusion解决。 - Spring Boot集成:
- Jedis可通过
Spring Data Redis集成,提供RedisTemplate。 - Redisson有官方
redisson-spring-boot-starter,可自动配置并注入RedissonClient。
- Jedis可通过
综上,选择哪个客户端取决于项目需求:追求简单直接选Jedis,需要分布式服务选Redisson。
【问题】 为什么要做Redis 分区?有哪些Redis分区实现方案?Redis 分区有什么缺点?
【参考答案】 一、为什么要做Redis分区? Redis分区(Partitioning)是将数据分布到多个Redis实例上的过程,主要目的包括:
- 扩展内存容量:单个Redis实例受限于物理内存,分区可以使用多台机器的内存,理论上支持无限扩展。
- 提升计算能力:通过增加节点,可以将计算负载分散到多台机器,从而成倍提升整体处理能力(如QPS)。
- 增加网络带宽:多台机器可以提供聚合的网络带宽,避免单节点成为网络瓶颈。
- 实现高可用和容错:结合主从复制和故障转移,分区可提高系统整体可用性。
二、Redis分区实现方案 主要有三种实现方式:客户端分区、代理分区、查询路由。
- 客户端分区
- 原理:客户端直接决定数据存储到哪个Redis节点,通常采用一致性哈希或取模算法。例如,客户端计算key的哈希值,根据节点数量取模得到目标节点,然后直接连接该节点执行命令。
- 代表实现:Jedis Sharding、ShardedJedis等。
- 优点:简单高效,无需额外组件,性能高。
- 缺点:客户端需要维护分片规则,节点变更时需重新分配数据(通常配合一致性哈希减少影响)。
- 代理分区
- 原理:客户端请求发送到代理层(如Twemproxy、Codis),代理根据分区规则将请求转发到后端Redis节点,并将结果返回给客户端。客户端无需感知后端节点变化。
- 代表实现:Twemproxy(Twitter开源的Redis/Memcached代理)、Codis(豌豆荚开发的Redis集群方案)。
- 优点:对客户端透明,易于管理和扩展。
- 缺点:引入代理增加一跳延迟,代理可能成为性能瓶颈。
- 查询路由
- 原理:客户端随机请求任意一个Redis节点,如果该节点不包含所请求的key,则返回重定向指令,客户端再根据重定向连接到正确的节点。Redis Cluster正是采用这种方案,每个节点都保存了槽与节点的映射关系,客户端可以缓存该映射。
- 代表实现:Redis Cluster(官方集群方案)。
- 优点:去中心化,节点间通过Gossip协议通信,支持自动故障转移和在线扩缩容。
- 缺点:客户端需支持集群协议(处理MOVED、ASK重定向),实现相对复杂。
三、Redis分区的缺点
- 多key操作受限:涉及多个key的操作(如交集、并集、事务)通常不被支持,因为这些key可能分布在不同的节点上。虽然可以通过哈希标签(hash tag)将相关key强制放到同一节点,但灵活性降低。
- 事务支持受限:跨节点的事务无法实现,Redis事务仅支持单节点。
- 数据处理复杂:备份、恢复、扩容等运维操作变得复杂。例如,需要从多个节点收集RDB/AOF文件,或进行数据迁移。
- 扩容/缩容困难:动态增加或删除节点时,数据重分布可能非常复杂,需要迁移大量数据。Redis Cluster提供了在线重分片,但其他方案(如客户端分区)需要停机或使用预分片技术。
- 无法使用某些高级功能:如排序、Lua脚本涉及多个key时可能受限。
【大白话解释于举例说明】
- 为什么分区:好比一个仓库(单实例)装不下所有货物,我们租多个仓库(多个实例),把不同货物分类存放,这样总容量大了,搬运工(CPU)也多了,进出货速度更快。
- 三种分区方式:
- 客户端分区:你(客户端)自己记着“手机在1号仓,电脑在2号仓”,直接去对应仓库取货。
- 代理分区:你告诉总台(代理)“我要手机”,总台根据记录告诉你该去1号仓,或者总台帮你取来。
- 查询路由:你随便走进一个仓库,如果走错了,仓库管理员告诉你“手机在1号仓,请去那边”,你再去1号仓。Redis Cluster就是这种方式。
- 缺点:如果你要同时取手机和电脑(多key操作),它们可能不在同一个仓库,就没办法一次性拿,得分两次。仓库扩容时,需要把一些货物搬到新仓库,过程麻烦。
【扩展知识点详解】
- 预分片(Pre-sharding):在系统初期就创建足够多的虚拟节点(如16384个槽),即使实际物理节点少,也能预留未来扩展。当新增节点时,只需将部分槽迁移过去,无需重新哈希。
- 一致性哈希:常用于客户端分区,通过引入虚拟节点解决节点不均问题。节点增减只影响相邻节点,减少数据迁移量。
- Redis Cluster的哈希槽:固定16384个槽,每个key通过CRC16(key) % 16384确定槽,槽在节点间分配。迁移时以槽为单位,逐键迁移,客户端通过MOVED和ASK重定向感知。
- 分区的数据迁移:在扩容时,需将部分数据从旧节点迁移到新节点。Redis Cluster的
redis-cli --cluster reshard可实现在线迁移,但期间可能影响性能。 - 分区与复制结合:每个分片可配置主从节点,提高高可用性。例如,Redis Cluster中每个主节点可以有多个从节点,主节点故障时从节点自动晋升。
- 备份与恢复:在分区环境中,需要定期从所有主节点收集RDB或AOF文件,分别恢复后合并数据。也可使用支持跨节点快照的备份工具。
- 应用场景:
- 大数据量(如几十GB以上)且需水平扩展时,应使用Redis Cluster。
- 对延迟敏感且数据量可控,可考虑客户端分区(如ShardedJedis)。
- 需要简化客户端逻辑时,代理分区如Codis是好选择。
通过合理选择分区方案,可以充分发挥Redis的分布式能力,同时规避其缺点。
【问题】 Redis单点吞吐量是多少?什么是QPS?什么是TPS?
【参考答案】
Redis单点的吞吐量受多种因素影响(如硬件性能、命令复杂度、数据大小、网络延迟等)。在理想条件下(使用简单命令如SET/GET处理小数据,千兆网络,高性能CPU),Redis单节点可以达到10万+ QPS(每秒查询数)。对于涉及多个命令的事务或Lua脚本,吞吐量会相应降低,但通常也能达到数万TPS(每秒事务数)。实际上,官方基准测试显示,Redis单实例在普通硬件上可处理约8~10万QPS。
QPS(Queries Per Second):每秒查询数,指服务器每秒能够处理的请求数量。它衡量的是服务器处理请求的能力,通常用于描述读操作为主的场景。在Redis中,每个命令(如GET、SET)都可以视为一个查询。
TPS(Transactions Per Second):每秒事务数,指服务器每秒能够处理的事务数量。事务通常指一组操作的集合,这些操作要么全部成功,要么全部失败。在Redis中,事务由MULTI/EXEC包裹的一组命令构成。TPS更适合衡量包含多个操作的事务处理能力。
区别与联系:
- QPS侧重于单次请求/命令的吞吐量,而TPS侧重于完整事务的吞吐量。
- 一个事务可能包含多个命令,因此TPS通常小于或等于QPS(例如,一个事务包含3个命令,那么QPS可能是TPS的3倍左右)。
- 对于大多数Redis应用,主要关注QPS,因为常用的是单个命令操作。但在使用事务或Lua脚本的场景下,TPS更有参考价值。
【大白话解释于举例说明】
- QPS:好比超市收银台每秒能结账多少个顾客(每个顾客只买一件商品)。如果收银员动作快,每秒能结10个顾客,QPS就是10。
- TPS:好比顾客买的东西多,需要扫描多件商品(多个命令)才算一个完整购物流程(事务)。如果收银员每秒能完成2个这样的复杂结账流程,TPS就是2,而每个流程扫描5件商品,那么QPS就是10。
在Redis中,如果只是简单存取值,就像单个商品结账,用QPS衡量;如果用事务批量处理,就像多件商品结账,用TPS更合适。
【扩展知识点详解】
- 影响Redis吞吐量的因素:
- 硬件:CPU主频、内存速度、网络带宽和延迟。
- 命令复杂度:简单命令(如
GET)比复杂命令(如SORT、聚合操作)快得多。 - 数据大小:操作大key(如大的String、Hash)会占用更多CPU和网络资源。
- 持久化配置:开启AOF或RDB可能会轻微影响性能(尤其是AOF的
always策略)。 - 客户端连接数:连接过多可能导致上下文切换开销,使用连接池可优化。
- 慢查询:需要监控并优化。
- 如何提高Redis吞吐量:
- 使用Pipeline批量发送命令,减少网络往返。
- 启用Redis 6.0+的多线程I/O(
io-threads)处理网络读写。 - 使用Redis Cluster进行水平扩展。
- 优化数据结构,避免大key。
- 合理配置内存淘汰策略和过期时间。
- QPS与TPS在分布式系统中的意义:
- 在微服务架构中,QPS常用于衡量API接口的负载能力。
- TPS常用于衡量数据库或事务处理系统的能力,如金融交易系统。
- Redis作为缓存,通常关注QPS;作为消息队列或分布式锁,可能关注TPS。
- 基准测试工具:
redis-benchmark是官方自带的压测工具,可以测试不同命令的QPS。- 例如:
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000模拟50个客户端发送1万次请求,测试QPS。
- 实际生产中的经验值:
- 一般业务场景下,单个Redis节点QPS可稳定在5~10万。
- 若使用Pipeline或集群,可轻松突破百万QPS。
- 注意事项:
- QPS和TPS都是瞬时峰值,需结合平均响应时间(RT)综合评估系统性能。
- 高QPS下需关注CPU、内存、网络带宽瓶颈,及时扩容或优化。
【问题】 Redis性能排查步骤?
【参考答案】 当Redis出现性能问题时,可以按照以下步骤进行系统性排查与优化:
-
检查基线性能
使用redis-cli --intrinsic-latency <测试秒数>命令测试Redis实例在当前环境下的固有延迟,了解硬件和操作系统层面的最大延迟。如果基线延迟本身就高,需要排查硬件或系统配置。 -
排查慢查询命令
通过SLOWLOG GET查看慢查询日志,分析是否存在复杂度高的命令(如KEYS、SORT、HGETALL对大集合的操作)。解决方案:用SCAN代替KEYS,聚合计算移到客户端,或优化数据模型。 -
检查过期键设置
如果大量key设置了相同的过期时间,可能导致集中过期,造成延迟抖动。解决方案:在过期时间上增加随机偏移量,避免同时删除。 - 检查bigkey
大key(如包含大量元素的Hash、List、Set)会导致操作阻塞、网络传输慢。解决方案:- 使用
redis-cli --bigkeys扫描大key。 - 对bigkey进行拆分。
- 删除bigkey时,Redis 4.0+使用
UNLINK异步删除;低版本用SCAN分批删除。 - 查询时避免全量获取,如用
HSCAN、SSCAN、LRANGE限制范围。
- 使用
- 检查AOF配置
如果开启了AOF持久化,appendfsync策略为always会大幅降低性能;everysec是折中方案。同时,AOF重写期间与主线程竞争磁盘I/O可能导致延迟。解决方案:- 根据业务可靠性要求调整
appendfsync策略。 - 设置
no-appendfsync-on-rewrite yes,避免重写期间fsync。 - 使用高性能磁盘(如SSD)存放AOF文件。
- 根据业务可靠性要求调整
- 检查内存使用与swap
如果Redis内存使用接近maxmemory,触发淘汰策略可能影响性能;如果发生内存交换(swap),性能急剧下降。解决方案:- 监控
used_memory和maxmemory,及时扩容或清理数据。 - 使用
INFO memory查看是否有swap(mem_fragmentation_ratio异常)。 - 避免与其他内存密集型应用混布。
- 考虑使用Redis集群分摊内存压力。
- 监控
-
检查透明大页(THP)
透明大页机制(Transparent Huge Pages)会导致内存分配延迟增加,尤其在fork子进程时。解决方案:关闭透明大页(echo never > /sys/kernel/mm/transparent_hugepage/enabled)。 -
检查主从复制配置
如果主节点数据量过大,从节点加载RDB时可能阻塞,且全量复制消耗带宽。解决方案:控制主节点数据量在2~4GB以内,避免大实例;使用无盘复制(repl-diskless-sync yes)减少磁盘I/O。 - 检查CPU和NUMA架构
多核CPU上,Redis单线程可能被调度到不同核心,导致缓存失效;NUMA架构下跨Socket访问内存会增加延迟。解决方案:- 使用
taskset将Redis进程绑定到固定CPU核心。 - 在NUMA机器上,确保Redis和网络中断处理程序运行在同一个CPU Socket(如使用
numactl)。
- 使用
- 其他常规检查
- 检查客户端连接数是否过多(
INFO clients),合理配置连接池。 - 检查网络带宽和延迟,避免跨机房部署。
- 升级Redis版本到最新稳定版,利用多线程I/O等优化。
- 检查客户端连接数是否过多(
【大白话解释于举例说明】
- 基线性能:好比运动员先测一下自己平常的百米速度,如果本身就跑得慢,可能是场地或身体问题,不是今天状态差。
- 慢查询:就像查账时用笨方法翻遍所有账本(KEYS),自然慢;改用索引(SCAN)就快。
- 过期键:假设所有优惠券都同一时间过期,顾客蜂拥而至(数据库压力大);让过期时间分散,就平稳了。
- bigkey:一个大箱子装太多东西,搬起来费劲;拆成小箱子,每次只搬一小箱。
- AOF配置:每次记账都立刻写硬盘(always)肯定慢;每秒记一次(everysec)平衡安全与速度。
- swap:内存不够用硬盘当内存,就像用U盘当内存条,速度暴跌。
- 透明大页:内存分页太大,就像用大卡车运小包裹,反而效率低。
- 主从复制:主库太大,从库复制时就像下载几十G文件,又慢又占带宽。
- CPU绑定:让工人固定在一个工作台,不用来回跑,效率更高。
【扩展知识点详解】
- intrinsic-latency:该命令测试Redis内部循环的延迟,排除网络和客户端影响,反映硬件和系统调用延迟。一般应低于几十微秒。
- 慢查询配置:
slowlog-log-slower-than设置慢查询阈值(微秒),slowlog-max-len设置日志长度。 - bigkey影响:除阻塞外,bigkey还导致内存碎片、网络拥塞。可用
MEMORY USAGE key查看具体内存占用。 - AOF重写与fork:fork子进程时需复制页表,内存越大fork越慢,期间主线程阻塞。可通过
latency-monitor监控fork事件。 - 透明大页与写时复制:THP在fork时可能导致更多内存复制,增加延迟。生产环境建议关闭。
- NUMA优化:使用
numactl --cpubind=0 --membind=0将Redis绑定到指定Socket,避免跨节点内存访问。 - CPU绑定:
taskset -c 0,1 redis-server,注意不要绑定到超线程虚拟核,避免竞争。 - 监控工具:
redis-cli --stat实时查看QPS、内存;INFO commandstats分析命令耗时;MEMORY DOCTOR诊断内存问题。 - 性能调优参数:
tcp-backlog、maxclients、timeout等需根据场景调整。 - 持续优化:性能排查是动态过程,需结合监控、压测和业务变化定期进行。
mybatis
【问题】 什么是Mybatis?为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?mybatis的优点有哪些?缺点有哪些?
【答案】 一、什么是 MyBatis? MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 封装了 JDBC 的重复代码,通过简单的 XML 或注解配置,将 Java 对象与数据库中的记录进行映射,使得开发者可以专注于 SQL 本身和业务逻辑,而无需处理 JDBC 的繁琐细节(如注册驱动、获取连接、处理结果集等)。
二、为什么说 MyBatis 是半自动 ORM 映射工具? ORM(Object-Relational Mapping,对象关系映射)是指将 Java 对象与数据库表记录自动映射的技术。MyBatis 被称为半自动 ORM,因为它只完成了结果集到对象的映射(即自动封装结果集),以及对象参数到 SQL 参数的映射,但需要开发者手动编写 SQL 语句。与之相对,全自动 ORM(如 Hibernate)不仅负责映射,还会根据对象操作自动生成 SQL,开发者几乎不需要编写 SQL。
三、MyBatis 与全自动 ORM(如 Hibernate)的区别
| 对比维度 | MyBatis(半自动) | Hibernate(全自动) |
|---|---|---|
| SQL 生成 | 开发者手动编写 SQL | 框架根据对象状态自动生成 SQL(HQL 或 SQL) |
| 控制权 | 开发者完全控制 SQL,便于优化和定制 | 框架控制 SQL,优化空间有限 |
| 学习曲线 | 较低,只需熟悉 SQL 和映射配置 | 较高,需理解 HQL、缓存、懒加载等复杂概念 |
| 移植性 | 差,SQL 可能依赖特定数据库方言 | 好,可通过配置切换数据库(Hibernate 适配多种方言) |
| 开发效率 | 较高,但需要编写 SQL | 极高,无需编写 SQL,纯对象操作 |
| 性能调优 | 灵活,可直接优化 SQL | 复杂,需通过缓存、抓取策略等手段 |
四、MyBatis 的优点
- 灵活可控:开发者手写 SQL,可以针对复杂查询和特定数据库优化,性能达到最优。
- 易于学习:相比 Hibernate,MyBatis 概念简单,只需要掌握 SQL 和基本配置即可上手。
- 动态 SQL:提供强大的动态 SQL 标签(如
<if>、<foreach>),方便拼接复杂查询条件。 - 与 JDBC 相比:消除了大量重复代码,简化了数据访问层开发。
- 轻量级:无侵入性,不会强制继承或实现特定接口(只需配置映射即可)。
- 良好的集成:可与 Spring、Spring Boot 无缝集成,支持缓存(一级、二级缓存)。
五、MyBatis 的缺点
- 工作量大:需要手动编写 SQL 和映射配置,尤其在表字段多、关联复杂时,工作量较大。
- 数据库移植性差:SQL 语句可能包含特定数据库的语法,切换数据库时需修改 SQL。
- 配置文件较多:早期版本需要配置 XML 文件,虽然现在支持注解,但复杂 SQL 仍需 XML。
- 缺乏全自动 ORM 的高级特性:如懒加载、缓存策略等需要额外配置,不如 Hibernate 开箱即用。
- SQL 注入风险:如果使用
${}拼接参数,可能导致 SQL 注入(需使用#{}预编译)。
【大白话解释】
- MyBatis 是什么:就像你去餐厅吃饭,不用自己洗菜、切菜(JDBC 的重复工作),但需要亲自点菜(写 SQL)。厨房(MyBatis)会按你的菜单做好菜,并把菜端到你面前(结果映射)。
- 为什么叫半自动:好比“半自动洗衣机”,你需要自己把衣服放进去、倒洗衣液(写 SQL),然后它帮你洗好甩干(映射结果)。而“全自动洗衣机”(Hibernate)你只需把衣服扔进去,它会自动加洗衣液、选模式、洗完烘干(自动生成 SQL 和映射)。
- 优点:自己写 SQL,就像自己炒菜,味道可控,可以加辣加麻(优化性能);容易学会,会 SQL 就能用。
- 缺点:每次都要自己写菜单,如果菜品复杂,点菜也累(工作量大);换了个餐厅(换数据库),菜单可能不适用(移植性差)。
【扩展知识点详解】
- MyBatis 核心组件:
- SqlSessionFactoryBuilder:根据配置构建 SqlSessionFactory。
- SqlSessionFactory:生产 SqlSession 的工厂,通常是单例的。
- SqlSession:代表一次数据库会话,提供执行 SQL、获取映射器的方法。
- Mapper:接口,通过动态代理绑定 SQL 语句,是推荐的使用方式。
- 工作原理:
- 读取配置文件(mybatis-config.xml)和映射文件(或注解)。
- 构建 SqlSessionFactory。
- 通过 SqlSessionFactory 打开 SqlSession。
- 通过 SqlSession 获取 Mapper 接口代理,或直接调用 API 执行 SQL。
- 执行 SQL 并映射结果返回。
- 动态 SQL:
<if>:条件判断<choose> (<when> <otherwise>):多分支选择<where>、<set>:动态处理 WHERE 和 SET 子句<foreach>:遍历集合<trim>:自定义前缀后缀
- 与 Hibernate 的详细对比:
- 开发速度:Hibernate 在简单 CRUD 上更快,MyBatis 在复杂查询上更灵活。
- 性能:MyBatis 由于手写 SQL,通常性能更高,但 Hibernate 通过缓存优化也能达到相近水平。
- 适用场景:MyBatis 适合需要精细控制 SQL、遗留数据库、或 SQL 较复杂的项目;Hibernate 适合业务逻辑简单、快速开发、对数据库移植性要求高的项目。
- 缓存机制:
- 一级缓存:SqlSession 级别,默认开启。
- 二级缓存:Mapper 级别,需配置,可跨 SqlSession 共享。
- 最佳实践:
- 使用 Mapper 接口,避免直接调用 SqlSession API。
- 参数尽量用
#{}防止 SQL 注入。 - 对于复杂查询,结合动态 SQL 和分页插件(如 PageHelper)。
- 与 Spring 集成时,使用
@MapperScan或MapperFactoryBean。
【问题】 在MyBatis中,#{}和${}的区别是什么?
【答案】
在MyBatis中,#{} 和 ${} 都是用于参数替换的占位符,但它们在处理方式和安全性上有本质区别:
- 预编译与直接拼接:
#{}:会被解析为 JDBC 的预编译语句(PreparedStatement)中的占位符?,并在执行时通过参数安全地设置值。MyBatis 会将其替换为?,然后使用PreparedStatement的setXxx()方法赋值。这可以有效防止 SQL 注入。${}:是简单的字符串替换,MyBatis 在解析 SQL 时,会直接将${}中的内容替换为参数的实际值,然后拼接成最终的 SQL 语句。这可能导致 SQL 注入风险,因为参数值可能包含恶意的 SQL 片段。
- 使用场景:
#{}:用于绝大多数参数传递,如字段值、条件值等。因为它安全可靠,且能自动处理数据类型和引号(例如字符串类型会自动加单引号)。${}:通常用于动态传入数据库对象,如表名、列名、排序字段等。因为这些对象不能使用占位符,只能通过字符串拼接。使用时需确保传入的值是可信的,避免注入风险。
- 类型处理:
#{}:会根据参数类型自动进行类型转换和加引号处理。例如,传入字符串会自动加单引号,传入数字则不加。${}:不会做任何类型处理,直接替换为字符串,因此需要手动处理引号。例如,如果传入字符串值,需要在 SQL 中显式加单引号,如'${name}'。
- 执行效率:
#{}:由于使用了预编译,数据库可以缓存执行计划,对于重复执行相同 SQL 的场景效率更高。${}:每次都会生成新的 SQL 语句,数据库无法缓存,可能影响性能。
【大白话解释】
#{}就像去餐厅点菜,你告诉服务员你要的菜名,服务员记下来,然后后厨按标准流程做菜。无论谁点同样的菜,流程都一样,安全可靠(预编译)。${}就像你直接冲进后厨,告诉厨师“给我炒个菜,再加点特殊调料”,厨师直接按你的要求做,但你可能会不小心把厨房弄乱(SQL 注入风险)。
例如:
-- 使用 #{}
SELECT * FROM user WHERE name = #{name}
-- 实际执行:SELECT * FROM user WHERE name = ?
-- 参数 '张三' 会安全设置
-- 使用 ${}
SELECT * FROM user WHERE name = '${name}'
-- 如果传入 "张三' OR '1'='1",拼接后变成:
-- SELECT * FROM user WHERE name = '张三' OR '1'='1'
-- 这就是 SQL 注入攻击。
【扩展知识点详解】
- SQL 注入原理:
${}直接拼接参数,攻击者可构造恶意参数改变 SQL 语义,导致数据泄露或破坏。例如,传入' OR 1=1; --可能使查询返回所有数据。 - 使用 ${} 的安全措施:如果必须使用
${}(如动态表名),应对参数进行严格校验,例如使用白名单,只允许预定义的几个表名,或通过代码逻辑控制。 - MyBatis 的解析顺序:MyBatis 首先解析
${}进行字符串替换,然后再处理#{}生成占位符。这意味着如果${}替换的内容中包含#{},#{}仍会被处理。 - 与 JDBC 的对应:
#{}对应PreparedStatement的setObject或setString等,参数独立传递;${}对应Statement的字符串拼接,参数直接嵌入 SQL。 - OGNL 表达式:在
${}中可以使用 OGNL 表达式进行复杂运算(如${1+1}),但#{}不支持,#{}只能直接引用参数。 - 动态 SQL 中的使用:在
<if test="...">等标签中,使用的是 OGNL 表达式,与参数传递的占位符不同。注意区分 test 表达式中的参数引用(直接写 param)和 SQL 语句中的占位符。 - 最佳实践:
- 优先使用
#{},除非必须动态传入表名、列名等。 - 对于排序字段,建议使用
#{}结合OrderBy的列名白名单,或者通过 Java 代码控制拼接。 - 对用户输入的任何内容都不要直接使用
${},如果必须,则进行严格过滤。
- 优先使用
- 常见误区:误认为
${}可以解决#{}无法处理的情况,如模糊查询。实际上,模糊查询可以用#{}配合数据库函数实现,如WHERE name LIKE '%' || #{name} || '%'(Oracle)或WHERE name LIKE CONCAT('%', #{name}, '%')(MySQL)。
【问题】 在MyBatis中,当实体类中的属性名和表中的字段名不一样时有几种处理方法?
【答案】 当实体类中的属性名与数据库表中的字段名不一致时,MyBatis 提供了多种映射方式来解决这一问题,确保查询结果能正确封装到实体对象中。主要有以下四种处理方法:
- 使用 SQL 别名
在编写 SQL 语句时,为查询字段指定与实体类属性名一致的别名。这是最简单直接的方法,适用于简单的字段不一致场景。
示例:SELECT user_id AS userId, user_name AS userName FROM user WHERE id = #{id} - 使用 resultMap 结果映射
通过<resultMap>标签显式定义字段与属性的映射关系,这是 MyBatis 最强大、最灵活的配置方式。可以处理复杂的映射,如关联对象、嵌套集合等。
示例:<resultMap id="userMap" type="com.example.User"> <id property="userId" column="user_id"/> <result property="userName" column="user_name"/> </resultMap> <select id="selectUser" resultMap="userMap"> SELECT * FROM user WHERE id = #{id} </select> - 开启驼峰命名自动映射
在 MyBatis 全局配置中开启驼峰命名转换,将数据库字段的 下划线命名 自动映射为实体类的 驼峰命名。例如,数据库字段user_name会自动映射到实体类属性userName。
配置方式(在 mybatis-config.xml 中):<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings>或者在 Spring Boot 的 application.yml 中:
mybatis: configuration: map-underscore-to-camel-case: true - 使用注解 @Results 和 @Result
在 Mapper 接口的方法上使用注解直接定义映射关系,适用于简单映射且不想写 XML 的场景。
示例:@Select("SELECT * FROM user WHERE id = #{id}") @Results({ @Result(property = "userId", column = "user_id"), @Result(property = "userName", column = "user_name") }) User selectUser(int id);
【大白话解释】
- SQL 别名:就像你给数据库字段起个小名,让 MyBatis 能认出它对应实体类的哪个属性。比如数据库字段叫
user_name,你查出来时把它改名叫userName,实体类就能接住。 - resultMap:好比画一张“对照表”,告诉 MyBatis 数据库的哪一列对应实体类的哪个属性。即使名字完全不同,也能按表里的一一对应关系映射。
- 驼峰命名自动映射:如果数据库习惯用下划线(如
user_name),而实体类习惯用小驼峰(如userName),MyBatis 可以自动识别这种模式,省去手动配置的麻烦。就像开启了一个“自动翻译器”。 - 注解映射:把对照关系直接写在代码里,适合简单情况,不用去翻 XML 文件。
【扩展知识点详解】
- 优先级:如果同时使用多种方式,MyBatis 的优先级规则大致为:
resultMap> SQL 别名 > 全局驼峰配置。即显式定义的 resultMap 会覆盖其他设置。 - resultMap 的复杂用法:可以配置继承(
extends)、关联(association,用于一对一)、集合(collection,用于一对多)等高级映射。 - 自动映射级别:MyBatis 提供了
autoMappingBehavior设置(NONE、PARTIAL、FULL),控制自动映射的程度。驼峰转换与自动映射配合使用。 - 注解的局限性:注解方式不适合复杂映射(如多表关联),且当 SQL 较长时,代码可读性较差,建议使用 XML。
- 混合使用:可以在 resultMap 中部分字段自动映射,部分手动指定。例如设置
autoMapping="true"后,未显式配置的字段会自动根据列名和属性名匹配(考虑驼峰)。 - MyBatis-Plus 增强:如果使用 MyBatis-Plus,其默认开启驼峰映射,并提供
@TableId、@TableField等注解,可以更便捷地指定映射关系。例如@TableField("user_name")。 - 注意事项:
- 使用别名时,要注意 SQL 关键字冲突,可能需要加引号。
- 开启驼峰映射后,只对下划线转驼峰有效,其他命名风格(如大小写混用)需手动处理。
- 在关联查询中,如果多个表有同名字段,建议使用别名或 resultMap 明确指定。
【问题】 在MyBatis中,模糊查询有几种实现方式?
【答案】 在 MyBatis 中,实现模糊查询主要有以下四种常见方式,每种方式在参数处理和 SQL 拼接上有所区别:
- 使用
${}直接拼接
在 SQL 语句中直接用${}将参数值拼接到 LIKE 子句中。这种方式简单直观,但存在 SQL 注入风险,且需要手动添加百分号。
示例:<select id="selectByName" resultType="User"> SELECT * FROM user WHERE name LIKE '%${name}%' </select> - 使用
#{}结合数据库函数
在 SQL 中使用#{}作为占位符,并通过数据库的字符串连接函数(如CONCAT)将百分号与参数拼接。这种方式安全,可防止 SQL 注入。
示例:<select id="selectByName" resultType="User"> SELECT * FROM user WHERE name LIKE CONCAT('%', #{name}, '%') </select> - 使用 MyBatis 的
<bind>标签
在映射文件中使用<bind>标签定义一个变量,将参数与百分号拼接,然后在 SQL 中使用该变量。这种方式既安全又灵活,尤其适用于多数据库兼容的场景。
示例:<select id="selectByName" resultType="User"> <bind name="pattern" value="'%' + name + '%'"/> SELECT * FROM user WHERE name LIKE #{pattern} </select> - 在 Java 代码中拼接
在调用 Mapper 之前,由业务层将参数拼接好(如name = "%"+name+"%"),然后直接传入 Mapper。这种方式也能防止注入,但将拼接逻辑混入业务层。
示例:String name = "%" + userName + "%"; List<User> users = userMapper.selectByName(name);对应的 Mapper:
<select id="selectByName" resultType="User"> SELECT * FROM user WHERE name LIKE #{name} </select>
推荐做法:优先使用 方式2(CONCAT) 或 **方式3(
【大白话解释】
- 方式1(${}):直接把用户输入的内容塞进 SQL 语句里,就像把陌生人带进你家厨房,万一他包里藏了危险品(恶意 SQL 代码),就可能搞破坏(SQL 注入)。不推荐。
- 方式2(CONCAT):用数据库的函数把百分号和参数粘在一起,然后通过安全的
#{}传进去。就像你让服务员把配料加好,再端上桌,安全省心。 - **方式3(
)**:在 SQL 映射文件里,用 MyBatis 自带的 ` ` 标签把参数和百分号拼好,再放进去。相当于你自己在厨房门口把配料组合好,再交给厨师,既安全又灵活。 - 方式4(Java拼接):在 Java 代码里先把参数加工好,再传给 Mapper。就像你在外面把菜洗好切好,然后直接给厨师下锅,同样安全,但可能让代码不够整洁。
【扩展知识点详解】
-
SQL 注入风险:使用
${}时,如果参数直接来源于用户输入,攻击者可构造' OR '1'='1等字符串,导致 SQL 语义改变,查询所有数据。因此,除非参数完全可信(如程序内部生成),否则禁止使用${}进行模糊查询。 - 数据库兼容性:
CONCAT('%', #{name}, '%')在 MySQL、PostgreSQL 中可用,但在 SQL Server 中应使用'%' + #{name} + '%'。<bind>标签与数据库无关,MyBatis 负责拼接,因此具有更好的移植性。
-
性能考虑:使用
LIKE '%...%'会导致全表扫描(索引失效),因为前导通配符%使得数据库无法使用 B+ 树索引。如果数据量大,应考虑使用全文搜索引擎(如 Elasticsearch)或优化查询条件(如仅后通配...%)。 -
特殊字符转义:当参数本身包含百分号(
%)或下划线(_)时,需要转义。例如,用户想查询包含%的内容,此时需要在 SQL 中使用ESCAPE子句。使用<bind>标签可以更方便地处理转义。 - 动态 SQL 组合:模糊查询常与
<if>标签结合,实现可选条件。例如:<select id="selectByCondition" resultType="User"> SELECT * FROM user <where> <if test="name != null and name != ''"> AND name LIKE CONCAT('%', #{name}, '%') </if> </where> </select> - MyBatis-Plus 扩展:如果使用 MyBatis-Plus,可以直接使用
like方法,如queryWrapper.like("name", name),底层封装了安全的拼接,极大简化代码。
【问题】 什么是MyBatis的接口绑定?有哪些实现方式?Mapper接口的工作原理是什么?Mapper接口里的方法,参数不同时,方法能重载吗?使用MyBatis的mapper接口调用时有哪些要求?
【答案】 一、什么是MyBatis的接口绑定? MyBatis的接口绑定是指通过定义一个Java接口,将接口中的方法与映射文件(XML)中的SQL语句或注解中的SQL关联起来,从而可以通过调用接口方法的方式来执行对应的SQL操作。这种方式消除了传统DAO层手动实现类的繁琐,由MyBatis动态生成接口的代理对象,开发者只需定义接口即可。
二、接口绑定的实现方式
- 基于XML配置
在XML映射文件中,通过namespace属性指定接口的全限定名,并将接口中的方法与XML中的<select>、<insert>等标签通过方法名对应起来。例如:<mapper namespace="com.example.UserMapper"> <select id="selectUser" resultType="User"> SELECT * FROM user WHERE id = #{id} </select> </mapper> - 基于注解
直接在接口方法上使用@Select、@Insert等注解编写SQL语句。例如:public interface UserMapper { @Select("SELECT * FROM user WHERE id = #{id}") User selectUser(int id); }
三、Mapper接口的工作原理 MyBatis启动时,会扫描映射文件或注解,为每个Mapper接口创建代理对象(通过JDK动态代理)。当调用接口方法时,代理对象根据方法名和参数找到对应的SQL语句,执行并返回结果。具体流程:
- 注册映射:MyBatis解析配置文件,将每个
namespace与接口关联,并将SQL语句以方法名为键存入配置中。 - 获取代理:通过
SqlSession.getMapper(Class)方法,MyBatis使用MapperProxyFactory创建接口的动态代理对象。 - 执行调用:代理对象拦截方法调用,根据方法名从配置中查找对应的SQL语句,然后通过
SqlSession执行SQL,并将结果映射返回。
四、Mapper接口里的方法,参数不同时,方法能重载吗? 不能重载。MyBatis通过方法名(在namespace下)唯一确定要执行的SQL语句,不区分参数类型或个数。即使参数不同,只要方法名相同,MyBatis会认为它们是同一个映射,导致冲突。因此,在同一个Mapper接口中,不能定义同名方法,无论参数是否相同。
五、使用MyBatis的mapper接口调用时有哪些要求?
- 接口名与映射文件namespace一致:XML中的
namespace必须等于接口的全限定名。 - 方法名与SQL id一致:接口中的方法名必须等于XML中
<select>等标签的id,或注解中定义的SQL对应。 - 返回值类型匹配:方法返回值类型必须与映射文件中定义的
resultType或resultMap兼容。 - 参数类型匹配:方法参数需与SQL语句中占位符的参数类型一致,可通过
@Param注解指定参数名(多参数时必用)。 - 接口不能有重载方法:如前述。
- 接口中方法不能使用修饰符:必须是
public的(默认),但无需显式写。 - 需要注册接口:在Spring中,需通过
@MapperScan或@Mapper注解将接口纳入IoC容器。
【大白话解释】
- 接口绑定:就像你给餐厅打电话订餐,你不需要亲自去厨房(不用写实现类),只要报上菜名(方法名),餐厅就会按菜单(SQL映射)做好送过来。MyBatis就是那个帮你拨电话、传话的接线员(代理对象)。
- 实现方式:可以写一张纸菜单(XML),或者直接在电话里说菜名(注解),两种方式都能让接线员明白你的需求。
- 工作原理:MyBatis启动时,会给每个菜单(接口)配一个机器人(代理对象)。你点菜(调用方法),机器人就去后厨找对应的厨师(SQL),做好后端给你(返回结果)。
- 不能重载:就像菜单上不能有两道菜都叫“鱼香肉丝”,即使配料不同,也会让厨师混乱。所以方法名必须唯一。
- 调用要求:就像点菜时,菜名必须准确(方法名一致),你说“我要一份鱼香肉丝”时,服务员知道该记在哪个菜单(namespace匹配),而且你指定的口味(参数类型)也要对得上。
【扩展知识点详解】
- 命名空间的作用:
namespace不仅用于绑定接口,还用于区分不同Mapper接口中相同的方法名,避免冲突。 - 参数处理:
- 单参数:可以直接使用参数名(如
#{id})。 - 多参数:必须使用
@Param注解指定参数名,如List<User> selectByNameAndAge(@Param("name") String name, @Param("age") int age);,否则MyBatis会以param1、param2等形式引用。
- 单参数:可以直接使用参数名(如
- 返回类型:
- 查询单条记录:返回实体对象或
Map。 - 查询多条记录:返回
List或Set。 - 插入/更新:返回
int表示影响行数。
- 查询单条记录:返回实体对象或
- 动态代理的实现:MyBatis使用JDK动态代理,代理对象实现了Mapper接口,所有方法调用都会被
MapperProxy的invoke方法拦截,最终调用SqlSession的相应方法。 - Spring集成:在Spring中,通过
MapperFactoryBean或@MapperScan将Mapper接口注册为Bean,Spring在启动时会自动创建代理对象并注入。 - 接口方法与SQL映射的对应关系:MyBatis通过
方法签名(包括方法名和参数类型)查找SQL,但只使用方法名。因此,如果两个方法名相同但参数不同,会抛出异常,提示重复的statement。 - 泛型支持:接口方法返回值可以是泛型,如
List<T>,但需要在XML中配置resultType为具体类型,或使用resultMap。 - 批量操作:接口方法可以使用
List参数实现批量插入,通过<foreach>标签遍历。 - 注意事项:
- 接口方法不能重载,但可以通过默认方法(Java 8+)提供默认实现,但默认方法不会被代理,需注意。
- 如果使用注解和XML同时配置相同的方法,XML会覆盖注解(通常以XML为准)。
- 确保
mybatis.mapper-locations(Spring Boot)或mapperLocations(Spring)配置正确,以便MyBatis扫描到XML文件。
分页和插件
【问题】 Mybatis是如何进行分页的?分页插件的原理是什么?简述Mybatis的插件运行原理以及如何编写一个插件?
【答案】 一、Mybatis 如何进行分页? Mybatis 提供以下几种分页方式:
-
内存分页(RowBounds)
使用RowBounds对象在 SQL 查询时传入偏移量和限制条数。Mybatis 会执行 SQL 获取所有数据,然后在内存中进行截取。这种方式适用于小数据量,大数据量时性能极差(消耗内存和网络)。
示例:List<User> list = sqlSession.selectList("getUserList", null, new RowBounds(0, 10)); -
物理分页(手动编写 SQL)
在 Mapper 的 SQL 语句中直接编写数据库特定的分页语法,如 MySQL 的LIMIT #{offset}, #{pageSize}。这种方式性能好,但需要为不同数据库编写不同 SQL,且每个查询都要手动处理。
示例:SELECT * FROM user LIMIT #{offset}, #{pageSize} -
使用分页插件
最常见的方式,通过插件(如 PageHelper)自动拦截 SQL,在运行时动态拼接分页语句,并自动执行 count 查询获取总记录数。对业务代码无侵入,只需在调用前设置分页参数。
示例:PageHelper.startPage(pageNum, pageSize); List<User> list = userMapper.selectAll();
二、分页插件的原理是什么? 分页插件基于 Mybatis 的插件(Interceptor)机制,核心原理如下:
- 分页插件实现了
Interceptor接口,通过@Intercepts注解拦截 Executor 的query方法(或StatementHandler的prepare方法)。 - 在拦截方法中,插件判断当前操作是否需要分页(通常通过线程上下文中的分页参数)。
- 如果需要分页,插件会:
- 拦截原始的 SQL 语句。
- 根据数据库方言(如 MySQL、Oracle)将 SQL 包装成分页查询语句(例如在原 SQL 后添加
LIMIT)。 - 同时,自动生成一个 count 查询(将原 SQL 包装为
SELECT COUNT(*) FROM (原SQL) temp),并执行以获取总记录数。 - 将分页参数设置到 SQL 中,执行分页查询。
- 最后将分页结果封装为
PageInfo等分页对象返回。
以 PageHelper 为例,它在 Executor 的 query 方法前拦截,通过 Dialect 接口适配不同数据库,完成动态 SQL 改写。
三、Mybatis 的插件运行原理以及如何编写一个插件?
- 插件运行原理
Mybatis 允许在四大核心对象的方法执行过程中进行拦截:
- Executor(执行器):负责增删改查操作。
- StatementHandler(语句处理器):负责处理 SQL 语句的预编译、参数设置和结果集处理。
- ParameterHandler(参数处理器):负责设置预编译语句的参数。
- ResultSetHandler(结果集处理器):负责将结果集映射为 Java 对象。
Mybatis 通过 JDK 动态代理为这些核心对象创建代理对象。当调用它们的方法时,会经过插件链,每个插件都有机会执行增强逻辑。插件需要实现 Interceptor 接口,并使用 @Intercepts 注解声明要拦截的方法签名。
- 如何编写一个插件? 编写一个自定义插件通常包含以下步骤:
步骤 1:实现 Interceptor 接口
public class MyPlugin implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 在目标方法执行前可以加入增强逻辑
System.out.println("Before method: " + invocation.getMethod());
// 执行目标方法(即被拦截的原方法)
Object result = invocation.proceed();
// 在目标方法执行后可以加入增强逻辑
System.out.println("After method");
return result;
}
@Override
public Object plugin(Object target) {
// 使用 Mybatis 提供的 Plugin 工具生成代理对象
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
// 可以获取配置文件中传入的参数
}
}
步骤 2:使用 @Intercepts 和 @Signature 指定拦截的目标
@Intercepts({
@Signature(
type = Executor.class, // 拦截的对象类型
method = "query", // 要拦截的方法名
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class} // 方法参数类型
)
})
public class MyPlugin implements Interceptor {
// ...
}
步骤 3:在 Mybatis 配置文件中注册插件
<plugins>
<plugin interceptor="com.example.MyPlugin">
<property name="someProperty" value="someValue"/>
</plugin>
</plugins>
或者在 Spring Boot 中通过 @Configuration 注册 Interceptor 到 SqlSessionFactory。
插件执行流程:当 Mybatis 创建核心对象(如 Executor)时,会遍历所有已注册的插件,调用每个插件的 plugin 方法生成代理对象,最终形成一个代理链。当调用目标方法时,会依次执行插件的 intercept 方法,直到最后一个代理才执行真正的方法。
【大白话解释】
- 分页方式:Mybatis 分页有三种方法:第一种是“假分页”,把所有数据查出来再在内存里切分(RowBounds),就像去图书馆把所有书搬回家,再挑几本看,书少还行,书多了累死。第二种是“手动分页”,写 SQL 时自己加 LIMIT,就像告诉图书管理员只要第1-10本书,但每次都要自己说。第三种是“插件分页”,用一个智能助手(PageHelper),你只要说“我要第2页,每页10本”,助手会自动帮你改 SQL,还帮你数总共有多少本书,省心省力。
- 分页插件原理:插件就像给 Mybatis 装了个“监听器”,在执行 SQL 前偷看你的指令,如果发现有分页要求,就悄悄把 SQL 改成分页形式,再执行。
- 插件原理:Mybatis 把核心对象都包了一层代理,就像给每个核心员工配了个“监督员”。你可以在监督员那里设规则(插件),当员工做某些事(方法调用)时,监督员就会插一脚,先干点别的,再让员工继续干。
- 编写插件:就像自己设计一个监督员,需要告诉他:你要监督谁(Executor 等)、他做什么事时你要干预(方法名和参数)、干预时做什么(intercept 方法)。写好后注册到 Mybatis 的“监督员名单”里。
【扩展知识点详解】
- 插件拦截的四大对象和方法:
Executor:update、query、commit、rollback等。StatementHandler:prepare、parameterize、batch、update、query等。ParameterHandler:getParameterObject、setParameters。ResultSetHandler:handleResultSets、handleOutputParameters等。
-
多个插件的执行顺序:按照配置文件中
plugin标签的先后顺序组成责任链,先配置的先执行其intercept方法中的前置逻辑,后配置的后执行前置逻辑;执行proceed()时会进入下一个插件,最后才执行真实方法;后置逻辑的执行顺序与前置相反。 - PageHelper 分页插件的内部实现:
- 使用
ThreadLocal存储分页参数,确保线程隔离。 - 在拦截器中判断是否有分页参数,有则调用
Dialect的getCountSql和getPageSql方法生成 count 查询和分页查询。 - 执行 count 查询后,将结果封装到
Page对象中,并继续执行分页查询,最后将分页数据放入PageInfo。
- 使用
- 编写插件的注意事项:
- 必须正确声明
@Signature的args,必须与原方法参数类型完全一致,否则无法拦截。 plugin方法通常直接使用Plugin.wrap(target, this),它会自动创建代理对象。- 在
intercept方法中,一定要调用invocation.proceed()以执行原方法,否则会阻断调用链。 - 插件可能影响性能,应谨慎使用,避免在频繁调用的方法中做耗时操作。
- 必须正确声明
- 常见插件用途:
- 分页插件(如 PageHelper)
- 性能监控插件(打印 SQL 执行时间)
- 数据权限插件(动态拼接权限条件)
- 逻辑删除插件(自动追加未删除条件)
- Mybatis 的插件限制:只能拦截上述四大对象,不能拦截自定义对象。如果需要更灵活的控制,可以考虑使用 Mybatis-Plus 的扩展功能。
标签
【问题】 Mybatis 映射文件中,如果A 标签通过include 引用了B 标签的内容,请问,B 标签能否定义在A 标签的后面,还是说必须定义在A 标签的前面?
【答案】
在 MyBatis 的映射文件(XML)中,通过 <include> 标签引用的 SQL 片段(<sql> 标签)可以定义在被引用的位置之后,即 B 标签可以定义在 A 标签的后面,不需要强制放在前面。
这是因为 MyBatis 在解析 XML 映射文件时,会先读取整个文档,建立所有 <sql> 片段的 ID 与内容的映射关系,然后再处理其他标签中的 <include> 引用。因此,无论 <sql> 片段定义在文件中的哪个位置(前后均可),只要其 ID 唯一且在同一个文件中,<include> 都能正确找到并引用。
需要注意的是:如果通过 refid 引用其他文件中的 <sql> 片段(如 namespace.sqlId),则必须确保被引用的 namespace 对应的映射文件已被加载,且该文件的 <sql> 片段定义在引用之前或之后并无影响,因为所有映射文件在加载后都会合并到全局配置中。
【大白话解释】
MyBatis 读取 XML 文件就像老师批改试卷:老师会先把整张卷子(整个 XML 文件)浏览一遍,把所有填空题(<sql> 标签)的答案先记在心里,然后再去看其他题目(<include>)里引用这些答案的地方。所以,即使某道题的答案写在卷子的最后一页,也不影响前面题目引用它。
【扩展知识点详解】
-
MyBatis 解析 XML 的顺序:MyBatis 使用 XML 解析器(如 XPath)加载整个文档到 DOM 树,然后递归处理各个节点。在解析过程中,会先收集所有的
<sql>节点存入 Configuration 对象中,之后当遇到<include>时,直接从 Configuration 中根据refid获取对应的 SQL 片段,因此不依赖物理顺序。 -
<include>的refid属性:可以引用本文件内的 SQL 片段(直接写 ID),也可以引用其他文件中的 SQL 片段(格式为namespace.sqlId)。跨文件引用时,被引用的 namespace 必须在 MyBatis 配置中已经注册,且该 SQL 片段的 ID 在对应 namespace 中唯一。 <include>支持属性传递:可以通过<property>子标签向被引用的 SQL 片段传递参数,例如:<sql id="userColumns">${alias}.id, ${alias}.name</sql> <select id="selectUser"> SELECT <include refid="userColumns"><property name="alias" value="u"/></include> FROM user u </select>在解析时,
${alias}会被替换为u。- 注意事项:
<sql>片段的 ID 在同一个映射文件中必须唯一。- 如果
<include>引用的 SQL 片段不存在,MyBatis 会在启动时抛出异常,提示找不到对应的 SQL 片段。 - 在使用
<include>时,可以结合动态 SQL 标签(如<if>),但要注意被包含的 SQL 片段本身可能也包含动态标签,解析时会递归处理。
- 实践建议:虽然顺序不重要,但从代码可读性和维护性角度,通常将公共的
<sql>片段放在文件顶部,以便快速查找和管理。但这仅仅是编码风格问题,不影响功能。
【问题】 如何用MyBatis优化批量插入?
【答案】 MyBatis 中优化批量插入主要从减少SQL执行次数、合理使用批处理和控制事务粒度三个方面入手。以下是几种常用的优化方案:
- 使用 foreach 标签拼接多行插入(适用于 MySQL、PostgreSQL 等)
利用 MyBatis 的动态 SQL 功能,在一个
insert语句中拼接多个values,一次请求插入多条记录。这种方式能显著减少网络往返次数和数据库解析 SQL 的开销。
示例:
<insert id="batchInsert" parameterType="list">
INSERT INTO user (name, age) VALUES
<foreach collection="list" item="item" separator=",">
(#{item.name}, #{item.age})
</foreach>
</insert>
注意:
- 拼接的 SQL 长度受数据库
max_allowed_packet限制,需控制单次插入的记录数(如每次 500-1000 条)。 - 适用于 MySQL,Oracle 等数据库需要改用其他语法(如 Oracle 的
INSERT ALL)。
- 使用 MyBatis 的 BatchExecutor
MyBatis 支持三种执行器类型:
SIMPLE、REUSE、BATCH。通过开启BATCH执行器,可以将多次 insert 语句的预编译和参数设置合并为一次网络往返,大幅提升性能。
实现方式:
- 在 Spring 中配置
SqlSessionTemplate的executorType为BATCH。 - 或者手动获取
SqlSession:sqlSessionFactory.openSession(ExecutorType.BATCH)。
示例:
try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH, false)) {
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
for (User user : userList) {
mapper.insert(user);
}
sqlSession.commit(); // 批量提交
}
- 设置 JDBC 批处理参数
对于 MySQL,可以在 JDBC URL 中添加
rewriteBatchedStatements=true,驱动会将executeBatch()中的多条 insert 语句重写为一条多值 insert 语句,进一步提升效率。jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true -
分批次提交 无论使用哪种方式,都不应一次性插入海量数据(如几十万条),否则可能占用过多内存或导致事务锁过长。建议采用分片提交,每批次插入一定数量(如 1000 条)后提交事务,并清空缓存。
-
使用 MyBatis-Plus 的批量插入 如果使用 MyBatis-Plus,可以直接调用
saveBatch()方法,其内部封装了分批 + 批处理的逻辑,非常便捷。 - 异步或并行插入 对于极端性能要求,可采用多线程并行插入不同批次,但需注意事务隔离和数据库连接池大小。
【大白话解释】
- foreach 拼接:就像写一封信,把多条记录合并成一条长清单寄出去,而不是每一条单独寄一封信。省去了反复拆信、读信的麻烦。
- BatchExecutor:好比让邮递员(MyBatis)把一堆信先攒起来,等攒够一捆再一起送去邮局(数据库)。邮局可以一次性处理这捆信,效率大大提高。
- rewriteBatchedStatements:相当于邮局的工作人员(JDBC驱动)看到一捆信,主动帮你在信封上合并地址,变成一封包含多个收件人的大信(多行 insert),进一步减少了处理步骤。
- 分批次提交:就像搬家,不能一次把所有家具都搬过去,否则车装不下、人也累。分几次搬,每次搬适量,既轻松又安全。
【扩展知识点详解】
- ExecutorType 的区别:
SIMPLE:每次执行 SQL 都创建一个新的预处理语句(PreparedStatement),执行完立即关闭。REUSE:复用预处理语句,避免重复创建,但仍是单条执行。BATCH:将多条 SQL 的预处理语句缓存起来,调用commit()或flushStatements()时一次性发送到数据库执行,减少网络往返。
-
批处理原理:JDBC 的
PreparedStatement支持addBatch()和executeBatch()。当开启BATCH执行器后,MyBatis 会调用addBatch()累积参数,最终由驱动批量发送。如果驱动不支持(如旧版本 MySQL),则可能回退为逐条执行。 - 数据库限制:
- MySQL:
max_allowed_packet限制单次 SQL 包大小。若 foreach 拼接的 SQL 过大,需减小批次大小。 - Oracle:使用
INSERT ALL或批处理,但 Oracle 的批处理需要手动控制事务大小。 - SQL Server:支持
VALUES多行插入,但同样有大小限制。
- MySQL:
-
事务与缓存:批处理时,通常需要手动控制提交频率,避免长事务占用锁和连接。同时,一级缓存(SqlSession 级别)会在批处理中累积对象,需定期清理或分批次创建新的 SqlSession。
- 性能对比:
- 逐条插入:最慢,网络开销大。
- foreach 拼接多行:快,但 SQL 可能过长。
- BATCH 执行器 + 分片:通常是最佳平衡,兼具速度和可控性。
- BATCH + rewriteBatchedStatements:对于 MySQL,接近极限性能。
- 注意事项:
- 使用 BATCH 执行器时,返回的受影响行数可能不准确(驱动合并执行后返回的可能是总和)。
- 批处理中若某条数据失败,默认行为是抛异常,且可能无法回滚已成功的部分(取决于驱动和事务)。建议在业务允许的情况下分批+事务。
- 在 Spring 中,若使用
@Transactional且事务传播行为导致多个 SqlSession 共享同一事务,需确保使用相同的ExecutorType。
- 代码示例(Spring + MyBatis): ```java @Autowired private SqlSessionTemplate sqlSessionTemplate;
public void batchInsert(List
---
【问题】
在MyBatis中如何获取自动生成的主键值?
【答案】
在 MyBatis 中获取自动生成的主键值主要有三种方式:基于 XML 配置、基于注解配置以及使用 `<selectKey>` 标签。具体如下:
1. 基于 XML 配置(推荐)
在 `<insert>` 标签中使用 `useGeneratedKeys="true"` 和 `keyProperty` 属性。执行插入后,MyBatis 会将数据库自动生成的主键值设置到传入实体对象的指定属性中。
**示例**:
```xml
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(name, age) VALUES(#{name}, #{age})
</insert>
调用后,user.getId() 即可获取生成的主键值。
如果需要指定数据库中的列名,可额外添加 keyColumn 属性(例如当主键列名与属性名不一致时)。
- 基于注解配置
在 Mapper 接口的方法上使用
@Options注解,同样设置useGeneratedKeys = true和keyProperty。
示例:
@Insert("INSERT INTO user(name, age) VALUES(#{name}, #{age})")
@Options(useGeneratedKeys = true, keyProperty = "id")
int insertUser(User user);
- 使用
<selectKey>标签(适用于非自增主键或特殊需求) 对于不支持自动生成主键的数据库(如 Oracle 的序列),或需要自定义主键生成逻辑的场景,可以使用<selectKey>标签在插入前(或后)执行查询获取主键值。
示例(Oracle 序列):
<insert id="insertUser">
<selectKey keyProperty="id" resultType="long" order="BEFORE">
SELECT SEQ_USER.NEXTVAL FROM DUAL
</selectKey>
INSERT INTO user(id, name, age) VALUES(#{id}, #{name}, #{age})
</insert>
order="BEFORE" 表示先查询序列值并设置到实体中,再执行插入;order="AFTER" 则先插入再查询(适用于 MySQL 自增主键,但通常不如 useGeneratedKeys 高效)。
- 批量插入获取主键
对于批量插入,需要数据库驱动支持返回批量生成的主键(如 MySQL)。配置方式与单条类似,但需注意:
- XML 中设置
useGeneratedKeys="true"和keyProperty,且keyProperty需指定为实体类中接收主键的属性(如list.id)。 - JDBC URL 中应添加
rewriteBatchedStatements=true以启用批量重写。
- XML 中设置
示例:
<insert id="batchInsert" useGeneratedKeys="true" keyProperty="id">
INSERT INTO user(name, age) VALUES
<foreach collection="list" item="item" separator=",">
(#{item.name}, #{item.age})
</foreach>
</insert>
插入后,list 中每个元素的 id 属性都会被自动填充。
【大白话解释】 MyBatis 获取自动生成的主键,就像你在超市购物结账时,收银员扫描完商品后,系统自动生成一个小票号。你希望收银员把这个小票号也写在你手上的购物清单(实体对象)上,这样你就不用再回去查了。
- useGeneratedKeys:告诉 MyBatis “帮我取回数据库自动生成的 ID”。
- keyProperty:指定要把 ID 塞到实体对象的哪个属性里(比如
id字段)。 - **
**:对于像 Oracle 这样不自增的数据库,你得先去“取号机”拿个号(查询序列),然后把号贴在商品上再结账。
【扩展知识点详解】
- 底层原理:
useGeneratedKeys依赖于 JDBC 的Statement.getGeneratedKeys()方法,数据库驱动需支持返回生成的主键(MySQL、PostgreSQL 等支持,Oracle 不自增故不支持)。 - keyColumn 的作用:当数据库主键列名与实体属性名不同时,可通过
keyColumn指定列名,确保正确映射。例如keyColumn="user_id"。 - 批量插入主键的限制:并非所有数据库驱动都支持批量返回主键。MySQL 需要驱动版本 5.1.7+ 并设置
rewriteBatchedStatements=true;Oracle 不支持批量返回,需用其他方式。 - selectKey 的适用场景:
- order=”BEFORE”:适用于序列、UUID 等需要在插入前生成主键的场景。
- order=”AFTER”:适用于自增主键(如 MySQL),但通常
useGeneratedKeys更简洁高效。
- 不同数据库的配置差异:
- MySQL:
useGeneratedKeys直接支持自增主键。 - PostgreSQL:支持
useGeneratedKeys,但需指定keyColumn为返回的列名(如id)。 - Oracle:使用序列 +
<selectKey>。 - SQL Server:支持
useGeneratedKeys,但需在 insert 语句中包含OUTPUT子句(或使用selectKey)。
- MySQL:
- MyBatis-Plus 的增强:MyBatis-Plus 通过
@TableId注解的type属性可配置主键生成策略(如IdType.AUTO、IdType.INPUT、IdType.SEQUENCE),底层自动处理主键获取,无需手动配置。 - 注意事项:
useGeneratedKeys仅对<insert>语句有效,对<update>、<delete>无效。- 如果实体对象中对应属性已有值,可能会被生成的主键覆盖。
- 对于批量插入,驱动返回的主键顺序可能与参数列表顺序不一致,需谨慎处理。
【问题】 Mybatis的xml中有哪些常用标签?一对一和一对多映射分别是如何实现的?如何用标签实现动态sql?
【答案】 一、Mybatis XML 中的常用标签 Mybatis 的映射文件中提供了丰富的标签,用于定义 SQL 语句、结果映射、动态 SQL 等。主要分为以下几类:
- 基础 CRUD 标签:
<select>:定义查询语句。<insert>:定义插入语句。<update>:定义更新语句。<delete>:定义删除语句。<sql>:定义可重用的 SQL 片段,可通过<include>引用。<include>:引用<sql>定义的片段。
- 结果映射标签:
<resultMap>:定义结果集与 Java 对象的映射规则。<id>:标记主键字段的映射。<result>:标记普通字段的映射。<association>:用于一对一关联的映射。<collection>:用于一对多关联的映射。<discriminator>:根据结果值决定使用不同的映射。
- 动态 SQL 标签:
<if>:条件判断。<choose>、<when>、<otherwise>:多条件分支。<where>:自动处理 WHERE 子句中的 AND/OR 前缀。<set>:自动处理 UPDATE 语句中的 SET 子句逗号。<foreach>:遍历集合,用于 IN 查询或批量操作。<trim>:自定义前缀、后缀以及要覆盖的字符串。<bind>:创建一个变量并绑定到上下文,用于模糊查询等。
二、一对一和一对多映射的实现方式
MyBatis 通过 <resultMap> 中的 <association> 和 <collection> 标签实现关联查询的映射。
- 一对一映射(使用
<association>) 场景:一个用户对应一个身份证(假设User类中有IdCard属性)。- 嵌套结果:通过连接查询一次性查出所有字段,然后通过
<association>指定如何将结果集中的列映射到关联对象的属性。 ```xml
- 嵌套结果:通过连接查询一次性查出所有字段,然后通过
- **嵌套查询**:执行多条 SQL,先查用户,再根据用户 id 查身份证。通过 `<association>` 的 `select` 属性指定另一个查询的 id,并传入参数。
```xml
<resultMap id="userMap" type="User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<association property="idCard" column="id" select="selectIdCardByUserId"/>
</resultMap>
<select id="selectIdCardByUserId" resultType="IdCard">
SELECT * FROM id_card WHERE user_id = #{userId}
</select>
- 一对多映射(使用
<collection>) 场景:一个用户有多条订单(User类中有List<Order>属性)。- 嵌套结果:连接查询,结果集中可能有多行(一个用户对应多个订单),MyBatis 会自动去重并填充集合。 ```xml
- **嵌套查询**:先查用户,再根据用户 id 查询订单列表。
```xml
<resultMap id="userMap" type="User">
<id property="id" column="id"/>
<result property="name" column="name"/>
<collection property="orders" column="id" select="selectOrdersByUserId"/>
</resultMap>
<select id="selectOrdersByUserId" resultType="Order">
SELECT * FROM orders WHERE user_id = #{userId}
</select>
三、如何用标签实现动态 SQL? 动态 SQL 通过组合标签在运行时根据条件生成不同的 SQL 语句。
<if>:用于条件判断,满足条件则拼接内部 SQL。<select id="findByCondition" resultType="User"> SELECT * FROM user WHERE 1=1 <if test="name != null and name != ''"> AND name LIKE CONCAT('%', #{name}, '%') </if> <if test="age != null"> AND age = #{age} </if> </select><where>:自动处理 WHERE 关键字,并去掉多余的 AND/OR。<select id="findByCondition" resultType="User"> SELECT * FROM user <where> <if test="name != null"> AND name = #{name} </if> <if test="age != null"> AND age = #{age} </if> </where> </select><choose>、<when>、<otherwise>:类似 Java 的 switch-case。<select id="findByCondition" resultType="User"> SELECT * FROM user <where> <choose> <when test="name != null"> AND name = #{name} </when> <when test="age != null"> AND age = #{age} </when> <otherwise> AND status = 'active' </otherwise> </choose> </where> </select><set>:用于 update 语句,自动处理 SET 子句中的逗号。<update id="updateUser"> UPDATE user <set> <if test="name != null">name = #{name},</if> <if test="age != null">age = #{age},</if> </set> WHERE id = #{id} </update><foreach>:遍历集合,常用于 IN 查询或批量插入。<select id="findByIds" resultType="User"> SELECT * FROM user WHERE id IN <foreach collection="list" item="id" open="(" separator="," close=")"> #{id} </foreach> </select><trim>:可以自定义前缀、后缀,以及要覆盖的字符串(如AND、OR、逗号),是<where>和<set>的基础。<trim prefix="WHERE" prefixOverrides="AND |OR "> <if test="name != null">AND name = #{name}</if> <if test="age != null">AND age = #{age}</if> </trim><bind>:在 XML 中定义一个变量,常用于模糊查询。<select id="findByName" resultType="User"> <bind name="pattern" value="'%' + name + '%'"/> SELECT * FROM user WHERE name LIKE #{pattern} </select>
【大白话解释】
- 常用标签:就像乐高积木,每种标签都有特定形状和用途。
<select>是“查询积木”,<if>是“条件积木”,<where>是“自动修正 WHERE 的积木”,把它们拼起来就能搭出复杂的 SQL 语句。 - 一对一映射:好比一个人(User)随身带着一张身份证(IdCard),你要把这两个对象组装起来。MyBatis 提供两种方式:
- 嵌套结果:一次 SQL 把人和身份证的信息都查出来,然后按字段分装到两个对象里。就像你一次性拿到人的资料和身份证复印件,然后手动把身份证复印件塞到人的档案袋里。
- 嵌套查询:先查人,拿到人后再根据人的 id 去查身份证,然后塞进去。就像先找到人的档案,再根据档案里的身份证号去另一个柜子找身份证原件。
- 一对多映射:好比一个人有多个订单,你要把订单列表塞到人的对象里。同样有两种方式:
- 嵌套结果:一次 SQL 查出人和他的所有订单(可能多条),MyBatis 会自动识别哪些列是人的信息(根据主键去重),哪些是订单信息,然后组装成列表。
- 嵌套查询:先查人,然后根据人的 id 执行另一条 SQL 查出所有订单,再把订单列表塞给人。
- 动态 SQL:就像根据不同情况自动调整 SQL 语句。比如用户搜索时,可能填了姓名,也可能填了年龄,用
<if>判断哪个条件有值,就拼接到 SQL 里。<where>会自动处理多余的 AND,<foreach>可以生成IN (1,2,3)这样的语句。
【扩展知识点详解】
- **
和 的常用属性**: property:关联的属性名。javaType/ofType:关联对象的类型(ofType用于集合,指定泛型类型)。column:传递给嵌套查询的字段(可多个,用{key1=col1, key2=col2}形式)。select:指定嵌套查询的 statement id。fetchType:设置懒加载(lazy或eager),可覆盖全局配置。
-
懒加载:通过配置
lazyLoadingEnabled=true和aggressiveLazyLoading=false,可以实现关联对象的按需加载,提高性能。 -
动态 SQL 的底层原理:MyBatis 使用 OGNL 表达式解析参数,通过 XML 解析器将标签组合成 SQL 源,在运行时动态生成最终的 SQL 语句。
- **
的详细用法**: prefix:添加的前缀。suffix:添加的后缀。prefixOverrides:忽略的前缀(如AND、OR)。suffixOverrides:忽略的后缀(如逗号)。
-
**
的 collection 取值**:可以是 `List`、`Array`、`Map` 等。当参数为 `List` 时,默认使用 `list` 作为 key;数组默认使用 `array`;`@Param` 注解可指定名称。 -
**
的作用域**:定义的变量仅在当前 SQL 语句中有效,可以用于拼接模糊查询、动态表名等。 -
映射继承:
<resultMap>支持通过extends属性继承另一个 resultMap,减少重复配置。 -
**鉴别器
**:根据某列的值,选择不同的 resultMap,实现多态映射(例如,根据用户类型映射不同子类)。 -
SQL 片段的复用:使用
<sql id="baseColumns">定义常用列,然后用<include refid="baseColumns"/>引用,避免重复编写。 - 最佳实践:
- 对于关联查询,优先考虑嵌套结果(一条 SQL)以减少数据库交互。
- 如果数据量较大,可使用嵌套查询并开启懒加载。
- 动态 SQL 中注意判断 null 和空字符串,避免生成无效条件。
- 使用
<bind>处理模糊查询可以避免不同数据库的兼容性问题。
懒加载和缓存
【问题】 Mybatis的一级、二级缓存分别是如何实现的?Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
【答案】 一、Mybatis 一级缓存的实现 一级缓存是 Mybatis 默认开启且无法关闭的缓存,其作用域是 SqlSession 级别(也称为会话级缓存)。
- 存储结构:每个 SqlSession 对应一个
Executor执行器对象,在执行器BaseExecutor中维护了一个PerpetualCache实例,而PerpetualCache内部核心就是一个简单的HashMap。 - 缓存 Key 的生成:缓存的 Key 由以下要素共同决定,用于唯一标识一次查询:
- Mapper 的 statementId(命名空间 + SQL id)。
- 查询条件中的参数对象。
- 分页所需的 RowBounds 对象。
- 具体的 SQL 语句字符串。
- 生命周期与失效:
- 在同一个 SqlSession 中执行两次完全相同的查询,第二次会直接从缓存中获取结果。
- 如果在 SqlSession 中执行了 insert、update、delete 等 DML 操作,无论是否提交,都会清空该 SqlSession 的一级缓存,以保证数据一致性。
- 当 SqlSession 执行
close()或clearCache()方法时,缓存也会被清空或释放。
二、Mybatis 二级缓存的实现 二级缓存是 mapper 级别(namespace 级别) 的缓存,可被多个 SqlSession 共享,默认关闭,需要手动开启。
- 开启方式:
- 全局开关:在 Mybatis 核心配置文件中设置
<setting name="cacheEnabled" value="true"/>(默认为 true)。 - 局部开关:在具体的 Mapper XML 文件中添加
<cache/>标签,并可配置缓存策略(如 LRU、FIFO)、刷新间隔、大小和只读属性等。
- 全局开关:在 Mybatis 核心配置文件中设置
- 实现机制:
- 当二级缓存开启后,Mybatis 会使用
CachingExecutor装饰器模式对原有的Executor进行包装。 CachingExecutor在真正执行查询前,会先根据缓存 Key 在二级缓存中查找。- 二级缓存的 Key 生成规则与一级缓存相同,但其缓存对象存储在全局的
Configuration对象中,供所有 SqlSession 共享。
- 当二级缓存开启后,Mybatis 会使用
- 查询顺序:当二级缓存开启后,数据的查询流程为 二级缓存 -> 一级缓存 -> 数据库。
- 失效机制:执行 DML 操作时,不仅会清空一级缓存,也会清空对应的二级缓存。
三、Mybatis 延迟加载的支持与实现原理 Mybatis 支持延迟加载(Lazy Loading),也称为懒加载。
-
什么是延迟加载: 在进行对象关联查询(如一对一、一对多)时,并不立即执行关联对象的 SQL,而是先返回一个代理对象。只有当真正调用关联对象的属性或方法时,才会触发 SQL 去数据库加载数据。
- 配置方式:
- 全局配置:在 Mybatis 主配置文件中设置
<setting name="lazyLoadingEnabled" value="true"/>。 - 局部配置:在
<association>或<collection>标签中设置fetchType="lazy"(优先级高于全局配置)。
- 全局配置:在 Mybatis 主配置文件中设置
- 实现原理(动态代理):
- 当 Mybatis 解析到关联映射配置了延迟加载后,它并不会直接创建目标对象,而是使用 Javassist 或 CGLIB 动态代理技术为目标属性创建一个代理对象。
- 该代理对象持有执行查询所需的信息(如 statementId、参数、SqlSession 等)。
- 当应用程序首次访问该代理对象的任何方法(如
getXxx())时,代理对象会拦截这次调用,检查数据是否已加载。 - 若未加载,代理对象会通过持有的信息发起一次数据库查询,将结果填充到代理对象中,并最终返回真实数据。后续对同一属性的访问将直接返回已加载的数据。
【大白话解释】
- 一级缓存:就像你(SqlSession)办公桌上放着一个个人笔记本。每次查数据都先看看笔记本里有没有记过,有就直接用,没有才去大档案室(数据库)翻,并把结果记下来。如果此时你在桌上改了任何数据(DML操作),为了避免出错,你会立刻把这个笔记本全部撕掉,保证下次查的是最新的。
- 二级缓存:就像是整个部门(同一个 namespace)公用的一个公共文件柜。你桌子上的笔记本(一级缓存)找不到数据时,会先去公共柜子里找找有没有其他同事留下的记录。如果公共柜子开启了(需要手动配置),大家都可以共享。
- 延迟加载:就像你点了一份“豪华套餐”,里面包含一个主餐和一个甜品。服务员(Mybatis)先只把主餐端上来,甜品没上。当你吃完主餐,喊了一声“该上甜品了”(第一次调用关联属性的
get方法),服务员才去后厨把甜品端过来给你。这就避免了如果你没喊甜品,后厨就白做的资源浪费。
【扩展知识点详解】
- 一级缓存的特殊配置:虽然一级缓存无法关闭,但可以通过配置
localCacheScope为STATEMENT,使得每次查询结束后都清空缓存,相当于在 Statement 级别禁用缓存效果。 - Spring 整合的影响:在 Spring 环境中,如果没有开启事务,每次 Mapper 方法调用都会创建一个新的 SqlSession,此时一级缓存将失效。只有在开启了事务的同一个方法内,多个查询才会共享一级缓存。
- 分布式系统下的缓存:Mybatis 的一、二级缓存均为本地缓存。在分布式部署中,如果一个节点更新了数据库,其他节点的缓存无法感知,会导致数据一致性问题。因此,在分布式环境下通常建议禁用二级缓存,并将一级缓存设置为
STATEMENT级别,或使用 Redis 等分布式缓存方案自定义 Cache 实现。 - 自定义二级缓存:Mybatis 允许通过实现
org.apache.ibatis.cache.Cache接口来集成第三方缓存框架,如 Redis 或 Ehcache,以实现更强大的分布式缓存能力。 - 延迟加载的触发条件:除了直接调用关联对象的
getter方法外,配置项aggressiveLazyLoading默认为 false,当为 true 时,对主对象的任何属性调用都会触发所有关联对象的加载。