Java特性
【问题】谈谈你对 Java 平台的理解?
【参考答案】
Java 不仅仅是一门编程语言,更是一个由语言规范、虚拟机(JVM)和标准类库(JDK/JRE)构成的庞大生态系统。可以从以下四个核心层面深入理解:
- 核心理念:一次编译,到处运行(WORA)
- 字节码机制:Java 源码(
.java)经编译器编译成平台无关的字节码(.class)。 - JVM 的角色:不同操作系统(Windows, Linux, macOS)安装各自实现的 JVM。JVM 负责将同一份字节码翻译为特定平台的机器指令。这种“中间层”的设计屏蔽了底层硬件和 OS 的差异,是 Java 实现跨平台的基础。
- 字节码机制:Java 源码(
- 三大核心组件的层次关系
- JVM (Java Virtual Machine):执行字节码的核心引擎,负责类加载、内存管理(GC)、指令执行。
- JRE (Java Runtime Environment):包含 JVM 和运行 Java 程序所需的核心类库(如集合、并发、网络 IO 等)。它是运行 Java 程序的最小环境。
- JDK (Java Development Kit):在 JRE 的基础上,增加了编译器(
javac)、调试工具(jstack,jmap)、监控工具等开发组件。它是开发 Java 程序的完整工具箱。
- 现代执行模式:解释与编译的平衡
- 混合模式:JVM 最初是纯解释执行,现代 JVM(如 HotSpot)引入了 JIT(即时编译) 技术。它在运行时识别“热点代码”,将其直接编译为本地机器码并缓存,大幅提升性能。
- AOT(预编译):Java 9 之后引入,允许在程序运行前直接将字节码编译为机器码,以缩短冷启动时间,特别适用于云原生和 Serverless 场景。
- 生态与特性演进
- 内存管理:自动垃圾回收(GC)机制,将开发者从手动的内存申请与释放中解放出来,减少了内存泄漏风险。
- 强安全性:内置字节码校验、安全管理器(SecurityManager)及完善的类型安全系统。
- 持续进化:从 Java 8 的函数式编程(Lambda/Stream),到 Java 11/17 的语法简化,再到 Java 21 的虚拟线程(Project Loom),Java 始终在保持稳定性的同时追求高并发与开发效率。
【延伸考点】
- JVM 规范与具体实现:HotSpot(最主流)、OpenJ9、GraalVM(高性能多语言支持)。
- JIT 优化策略:内联(Inlining)、逃逸分析(Escape Analysis)、锁消除。
- Java 版本周期:每 6 个月一个小版本,每 2 年(或 3 年)一个 LTS 版本。
- 模块化系统 (Project Jigsaw):Java 9 引入的
module-info解决类路径混乱问题。
【问题】Java 的主要特性有哪些?Java 是“解释执行”的吗?
【参考答案】
Java 的核心竞争力源于其语言特性的平衡性以及高效的执行引擎。
1. Java 的核心特性
- 面向对象(OOP):封装、继承、多态。Java 是一门纯粹的面向对象语言(除了基本类型),支持接口、抽象类等高级特性,极大提高了代码的可维护性和复用性。
- 平台无关性(WORA):通过“一次编译,到处运行”的字节码机制实现,依赖不同平台的 JVM 进行翻译。
- 自动内存管理(GC):内置垃圾回收机制,开发者无需手动分配和释放内存,显著降低了内存泄漏和悬挂指针的风险。
- 强类型与安全性:严格的编译期类型检查、异常处理机制、字节码校验以及沙箱安全模型。
- 多线程支持:原生支持多线程编程,提供了丰富的并发工具包(JUC),现代版本中更引入了虚拟线程(Virtual Threads)以支持极高并发。
- 高性能:虽然是中间语言,但通过 JIT(即时编译)技术,其运行效率在许多场景下已接近 C++。
2. Java 的执行模式:是“解释执行”吗? 结论:Java 采用的是“编译 + 解释 + 即时编译(JIT)”的混合执行模式。
- 静态编译期:
.java源码通过javac编译成.class字节码。这一步是离线的,不涉及具体硬件平台。 - 动态运行期(JVM 内部):
- 解释执行:JVM 启动时,解释器(Interpreter)逐条读取字节码并将其翻译为机器码执行。这种方式启动快,但执行效率较低。
- 即时编译(JIT):当 JVM 发现某段代码运行频繁(“热点代码”),JIT 编译器(如 HotSpot 的 C1/C2 编译器)会将其直接编译为本地机器码并进行深度优化,随后直接执行机器码。
- 分层编译(Tiered Compilation):现代 JVM 会结合两者,初期使用解释执行保证快速启动,后期使用 JIT 保证极致性能。
因此,简单地将 Java 归类为“解释型”或“编译型”都是不准确的。它是编译成字节码后,由虚拟机通过解释与即时编译混合运行。
【延伸考点】
- JIT 编译器的分类:C1(Client 模式,启动快,优化少)与 C2(Server 模式,启动慢,极致优化)。
- 热点探测技术:基于计数器(方法调用计数器、回边计数器)的热点探测算法。
- Java 9+ 的 AOT 编译器:允许在运行前进行静态编译(如
jaotc工具),解决 JIT 的预热问题。 - GraalVM 的 Native Image:将 Java 代码编译为独立的可执行二进制文件,启动速度提升数倍。
【问题】什么是 Java 虚拟机(JVM)?为什么说 Java 是“平台无关”的?
【参考答案】
JVM 是 Java 跨平台的核心,它不仅是一个软件,更是一个严谨的规范。
1. JVM 的本质与定义 JVM(Java Virtual Machine)是一个虚构出来的计算机,它是通过在实际的计算机上仿真模拟各种计算机功能来实现时。它拥有一套完善的虚拟硬件架构,如处理器、堆栈、寄存器等,还有相应的指令系统。
- 作为规范:它定义了字节码文件的格式、类加载机制、内存布局以及指令执行逻辑。
- 作为实现:它是一个运行在特定操作系统上的进程。不同厂商(如 Oracle, IBM, Alibaba)根据 JVM 规范实现了不同的虚拟机(如 HotSpot, OpenJ9)。
2. 为什么 Java 是“平台无关”的? Java 的跨平台特性主要归功于“字节码”和“JVM”的解耦设计:
- 一次编译:Java 源码被编译成统一的
.class字节码文件,这些文件不包含任何特定平台的指令。 - 到处运行:每个操作系统都有对应的 JVM 实现。JVM 就像一个“翻译官”,它对上承接统一的字节码,对下将其翻译成当前操作系统和 CPU 能够理解的机器码。
- 解耦逻辑:开发者只需关注 Java 语言本身,而将“如何与不同系统底层交互”的任务交给了 JVM 厂商。这种“中间层”思想彻底实现了程序与硬件平台的解耦。
3. JVM 的核心组成部分
- 类加载子系统(Class Loader):负责从文件系统或网络中加载 Class 文件。
- 运行时数据区(Runtime Data Area):即 JVM 内存,包括堆、栈、方法区等。
- 执行引擎(Execution Engine):负责执行字节码,包含解释器、JIT 编译器和垃圾回收器(GC)。
- 本地接口(JNI):负责与本地方法库(C/C++ 实现)进行交互。
【延伸考点】
- JVM 内存区域划分:堆(共享)、栈(私有)、程序计数器、方法区。
- 类加载的双亲委派模型:如何保证核心类库不被篡改。
- JVM 调优的本质:平衡内存占用、吞吐量和停顿时间(STW)。
- GraalVM:一种能够运行多种语言(Java, JS, Python, Rust)的新型虚拟机。
【问题】JDK 和 JRE 的区别是什么?
【参考答案】
理解 JDK 与 JRE 的区别,是掌握 Java 环境配置与分发的基础。
1. JRE (Java Runtime Environment) —— Java 运行时环境 JRE 是运行 Java 程序所必需的最小环境。
- 核心组成:包含 JVM(Java 虚拟机)和 Java 标准类库(如集合、IO、网络等核心 API)。
- 适用人群:主要面向 Java 程序的“使用者”。如果你只需要运行现有的 Java 应用(如运行一个 JAR 包),安装 JRE 即可。
- 局限性:JRE 不包含任何开发工具,如编译器(
javac)、调试器或文档生成工具。
2. JDK (Java Development Kit) —— Java 开发工具包 JDK 是 Java 语言的软件开发工具包,它是 JRE 的超集。
- 核心组成:JDK = JRE + 开发工具。
- 开发工具:包含编译器(
javac)、打包工具(jar)、文档生成器(javadoc)、调试工具(jdb)以及丰富的诊断监控工具(jps,jstack,jmap,jstat等)。 - 适用人群:面向 Java “开发者”。它是编写、编译、测试和调试 Java 程序所必需的。
3. 现代演进:JDK 11 之后的变革
- 不再提供独立 JRE:从 JDK 11 开始,Oracle 不再发布独立的 JRE 安装包。
- 模块化分发:现代 Java 推荐使用
jlink工具。开发者可以根据应用的需求,仅提取必要的模块,定制出一个极其轻量的自定义运行时镜像(Custom Runtime Image),而不再依赖通用的、臃肿的 JRE。
4. 总结对比
- 包含关系:JDK ⊃ JRE ⊃ JVM。
- 职能划分:JVM 负责执行;JRE 提供运行所需的类库;JDK 提供开发、编译及诊断的全套装备。
【延伸考点】
- JDK 工具链:熟练掌握
jstack(排查死锁/高 CPU)、jmap(内存分析)等诊断命令。 - 模块化系统 (Jigsaw):JDK 9 引入的模块化如何改变了类路径(Classpath)的查找方式。
- LTS 版本选择:目前主流的生产环境版本(Java 8, 11, 17, 21)的选择依据与差异。
OOP面向对象
封装继承多态抽象
- OOP面向对象编程
【问题】谈谈你对面向对象编程(OOP)的理解?它有哪些优点?
【参考答案】
面向对象编程(Object-Oriented Programming, OOP)是一种核心的编程范式,它将现实世界中的事物抽象为“对象”,通过对象之间的交互来构建复杂的软件系统。
1. 面向对象的核心思想
- 以对象为中心:将数据(属性)和处理数据的方法(行为)封装在一起,形成一个独立的实体——对象。
- 模拟现实:通过类(模板)和对象(实例)的概念,使得代码结构更贴近人类对现实世界的认知逻辑。
2. 面向对象 vs 面向过程 (POP)
- 面向过程:以“步骤”为核心,将问题分解为一个个函数。优点是流程清晰,执行效率高;缺点是耦合度高,难以应对大规模复杂系统的维护。
- 面向对象:以“功能模块”为核心。虽然性能开销略大(因为需要实例化对象、动态绑定等),但在可维护性、扩展性和复用性上具有压倒性优势。
3. 面向对象软件开发的优点
- 模块化与封装:通过类和包将代码逻辑隔离,职责单一且边界清晰,便于团队协作开发。
- 代码复用:利用继承(子类复用父类)和组合(对象作为成员)机制,极大减少了重复代码的编写。
- 灵活性与扩展性:依托多态特性,通过接口和抽象类定义规范,使得系统在不修改原有代码的情况下,通过增加新类即可扩展功能(符合开闭原则)。
- 易于理解和沟通:代码逻辑与业务模型高度一致,降低了开发者与业务人员之间的理解成本。
4. 面向对象的四大支柱
- 封装:隐藏内部实现,暴露受控接口。
- 继承:实现代码复用和层级化建模。
- 多态:同一种行为具有多个不同表现形式(重载与重写)。
- 抽象:提取核心特征,忽略非核心细节。
【延伸考点】
- 设计原则 (SOLID):单一职责、开闭原则、里氏替换、接口隔离、依赖倒置。
- 组合优于继承:为什么在现代开发中更提倡通过组合来扩展功能,而非深层的继承树。
- Java 中的函数式编程:Java 8 之后如何通过 Lambda 和 Stream 弥补 OOP 在某些场景下过于繁琐的问题。
【问题】谈谈你对封装(Encapsulation)的理解?它有哪些具体好处?
【参考答案】
封装是面向对象编程的第一大特性,它的核心思想是“隐藏实现细节,暴露有限接口”。
1. 封装的本质 封装将对象的属性(数据)和行为(方法)结合在一起,并对外隐藏对象的内部状态。外部只能通过对象提供的公开方法(如 Getter/Setter 或业务方法)来访问或修改数据,而不能直接操作对象的私有字段。
2. 封装的具体好处
- 数据保护与安全性:通过将字段设置为
private,可以防止外部代码随意篡改对象内部的敏感数据。我们可以在 Setter 方法中加入逻辑校验(如年龄不能为负数),确保对象始终处于合法状态。 - 解耦与灵活性:外部调用者只依赖于公开的接口,而不关心内部是如何实现的。这意味着我们可以自由地修改内部算法、优化性能或重构代码,而不会影响到任何调用方的代码。
- 提高可维护性:由于内部实现被隐藏,代码的改动被限制在类内部。当 bug 出现时,我们可以快速定位到特定的类中,而不需要在整个系统中搜寻可能的篡改点。
- 隐藏复杂性:封装允许我们将复杂的逻辑包装在一个简单的接口背后。用户只需要知道“调用这个方法能做什么”,而不需要理解其内部成百上千行的实现细节。
3. 如何实现良好的封装
- 合理使用访问控制符(
private,protected,public)。 - 尽量减少 Setter 方法的暴露,优先通过构造函数或业务方法来初始化和变更状态。
- 设计不可变类(Immutable Class),通过封装彻底消除状态变更带来的并发风险。
【延伸考点】
- 访问权限修饰符的区别:
private(类内部)、default(同包)、protected(同包及子类)、public(全局)。 - Java Bean 规范:为什么标准 Java Bean 要求私有属性和公共 Getter/Setter。
- 贫血模型 vs 充血模型:在领域驱动设计(DDD)中,封装是如何通过充血模型体现业务逻辑的。
- Lombok 的利弊:使用
@Data注解自动生成 Getter/Setter 对封装性的潜在破坏。
【问题】抽象(Abstraction)和封装(Encapsulation)的区别是什么?
【参考答案】
虽然抽象和封装经常被一起提及,但它们在面向对象设计中关注的角度完全不同:
1. 核心定义与关注点
- 抽象(Abstraction):
- 核心理念:关注“做什么(What it does)”。它是对现实世界事物的简化建模,旨在提取出核心的特征和行为,而忽略那些非本质的细节。
- 目的:通过定义接口、抽象类等方式,建立起一套契约或规范,使得调用方只需要关心功能本身。
- 封装(Encapsulation):
- 核心理念:关注“怎么做(How it works)”。它是将数据(属性)和对数据的操作(方法)打包成一个独立的单元,并对外隐藏内部的实现逻辑。
- 目的:通过访问控制机制(如
private)保护数据安全,并实现内部实现的自由变更。
2. 实现形式的对比
- 抽象的体现:接口(Interface)、抽象类(Abstract Class)、方法签名。例如,定义一个
Shape接口,规定所有形状都必须有getArea()方法,但不关心具体是怎么算的。 - 封装的体现:类(Class)、访问修饰符(
public,private)、Getter/Setter。例如,在Circle类中通过Math.PI * r * r来实现getArea(),并保护半径r不被非法修改。
3. 二者的协作关系
- 抽象是封装的“门面”:抽象定义了对象对外表现出的行为规范(即接口)。
- 封装是抽象的“支撑”:封装通过隐藏复杂的内部逻辑,保证了抽象出的接口能够稳定、安全地被调用。
- 总结:抽象告诉我们对象能做什么,而封装确保这些功能在内部被安全且正确地实现。
【延伸考点】
- 面向接口编程:理解为什么“接口”是抽象的最高形式,以及它如何实现组件间的解耦。
- 开闭原则(OCP):封装和抽象是如何共同作用,实现“对扩展开放,对修改关闭”的。
- 设计模式中的体现:例如策略模式(Strategy Pattern)是如何利用抽象定义算法族,再通过封装隐藏各具体算法的。
- Java 8+ 接口默认方法:接口中引入
default方法后,抽象和实现的界限是否变得模糊。
【问题】new 一个对象和 clone 一个对象的过程有什么区别?
【参考答案】
虽然 new 和 clone() 都能在堆内存中产生新对象,但它们的实现机制和生命周期逻辑截然不同:
1. new 一个对象的过程 这是 Java 中创建对象最标准、最常用的方式,其底层逻辑遵循 JVM 的对象创建规范:
- 分配内存:JVM 首先在堆中分配一块足够的内存。
- 初始化默认值:将分配到的内存空间(不包括对象头)都初始化为零值(如 0, false, null)。
- 设置对象头:设置对象的哈希码、GC 分代年龄、锁状态标志以及指向类元数据的指针。
- 执行初始化逻辑:这是关键区别。JVM 会调用对象的构造方法(Constructor),按照继承链从上到下执行显式初始化、代码块初始化和构造器逻辑。
- 返回引用:最后将栈中的引用指向堆中的对象实例。
2. clone 一个对象的过程
clone() 是 Object 类的一个 native 方法,它跳过了构造器的执行过程:
- 分配内存:JVM 在堆中分配一块与原对象大小完全相同的内存。
- 内存二进制拷贝:这是核心机制。JVM 将原对象的所有内存数据(即所有字段的二进制位)直接复制到新内存空间。
- 不调用构造器:由于是直接内存拷贝,新对象的产生完全不经过构造方法。
- 前置条件:类必须实现
Cloneable接口(标识性接口),否则会抛出CloneNotSupportedException。
3. 核心差异总结
- 构造器调用:
new必须调用构造器;clone()绝对不调用构造器。 - 性能开销:
clone()在复制大对象或复杂对象时通常比new性能更好,因为它直接操作内存位。 - 拷贝深度:
new创建的是全新的对象;clone()默认执行的是浅拷贝(Shallow Copy),即基本类型复制值,而引用类型只复制引用地址,导致新旧对象共享内部的引用对象。
【延伸考点】
- 浅拷贝 vs 深拷贝:如何通过重写
clone()或利用序列化(Serializable)实现真正的深拷贝。 - Cloneable 接口的缺陷:为什么《Effective Java》建议优先使用“拷贝构造器”或“拷贝工厂”而非
clone()。 - JVM 指令集:
new对应new指令,而clone()对应invokevirtual(调用方法)。 - 对象头(Mark Word):理解
clone()之后,新对象的对象头信息是如何被重新设置的(例如哈希码不会被拷贝)。
【问题】为什么 Java 设计为“单继承,多实现”?
【参考答案】
这是 Java 在语言设计上对简洁性、安全性与灵活性权衡后的结果。
1. 为什么类只支持单继承?(安全性与简洁性)
- 规避“菱形继承”问题(Diamond Problem):如果类支持多继承,当一个类同时继承自两个拥有相同方法签名的父类时,子类在调用该方法时会产生歧义(不知道该执行哪一个父类的逻辑)。
- 结构清晰:单继承保证了类的继承树是严格的树状结构,而非复杂的网状结构。这降低了编译器实现的复杂度,也让开发者更容易追踪代码的调用链路。
- 状态冲突风险:类是可以拥有“成员变量(状态)”的。多继承会导致子类继承多套可能冲突的状态,增加了内存布局的复杂性和数据一致性的维护难度。
2. 为什么接口支持多实现?(灵活性与解耦)
- 行为的组合:接口代表的是一种“能力”或“协议”(Like-a 关系)。一个对象可以同时具备多种能力(如既能
Runnable也能Serializable),多实现极大地增强了系统的灵活性。 - 无状态性:在 Java 8 之前,接口不能定义成员变量,也没有方法实现,因此不存在菱形继承中的逻辑冲突。
- Java 8 后的演进(Default Method):虽然 Java 8 引入了接口默认方法,允许接口有实现,但 Java 规定:如果多个接口存在冲突的默认方法,实现类必须强制重写该方法以消除歧义。这在保持灵活性的同时,依然规避了二义性。
3. 总结:状态 vs 行为
- 类(Class):封装了状态和行为。单继承是为了保护状态的一致性。
- 接口(Interface):主要封装行为契约。多实现是为了支持行为的多样化组合。
【延伸考点】
- 组合优于继承(Favor Composition over Inheritance):理解为什么在复杂业务中应减少继承深度,转而使用组合。
- Java 8 接口冲突解决规则:类优先原则、子接口优先原则、显式覆盖原则。
- C++ 的虚继承:了解 C++ 是如何通过复杂的虚继承机制解决多继承问题的,对比 Java 的简洁性方案。
对象结构
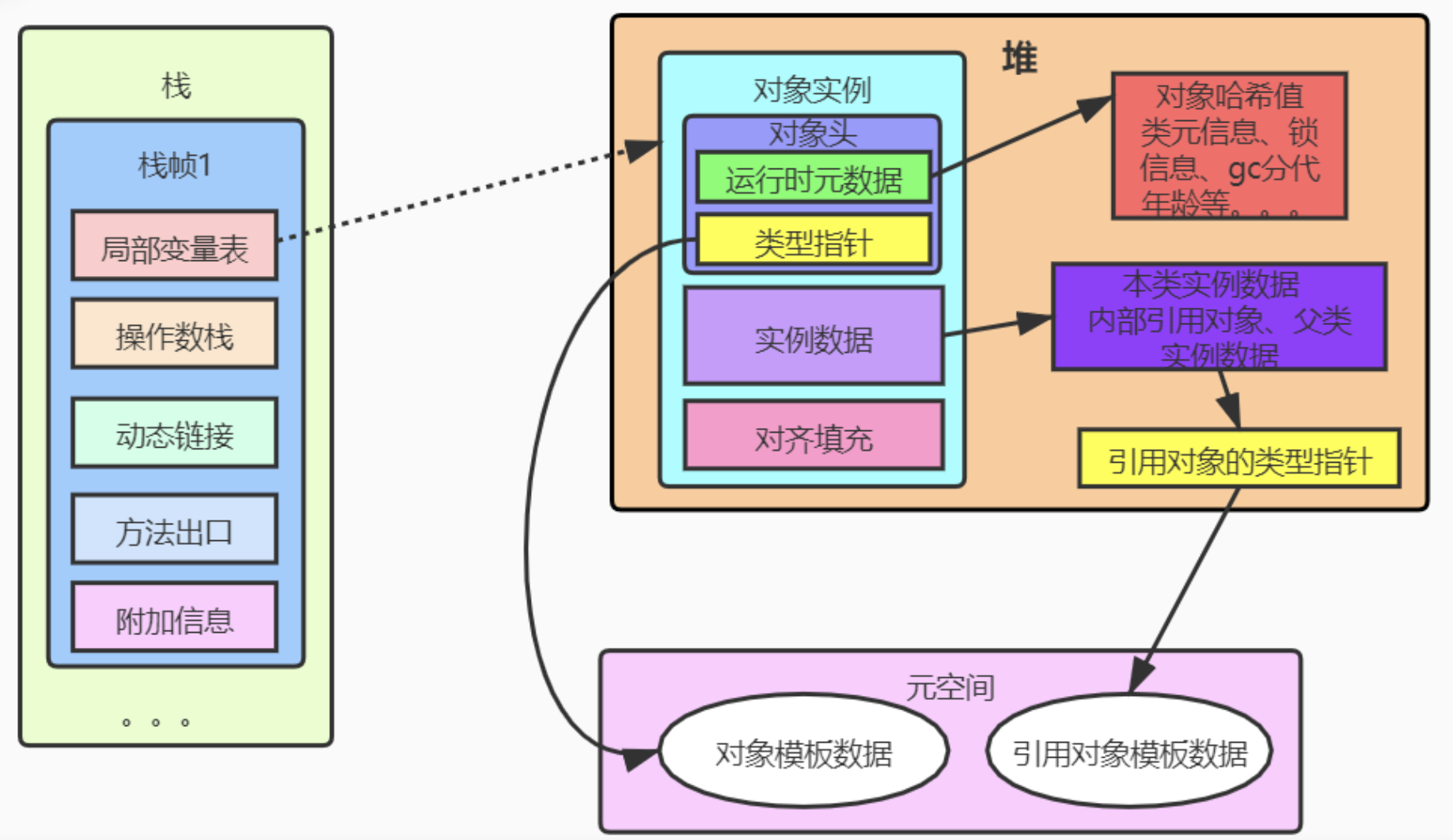
【问题】Java 对象的内存结构是怎样的?(以 HotSpot 为例)
【参考答案】
在 HotSpot JVM 中,一个普通 Java 对象在堆内存中的布局由以下三部分组成:
1. 对象头(Object Header) 对象头是对象内存布局中最重要的部分,包含两类信息:
- Mark Word(标记字段):存储对象自身的运行时数据。这是动态的,会根据锁状态改变内容。包含:哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID 等。
- Klass Pointer(类型指针):对象指向它的类元数据的指针,JVM 通过这个指针来确定该对象是哪个类的实例。
- 数组长度(仅数组对象):如果是数组对象,对象头中还会多出一块记录数组长度的区域。
2. 实例数据(Instance Data) 这是对象真正存储的有效信息,包括程序代码中定义的各种类型的字段内容,以及从父类继承下来的字段。
- 字段重排:为了提高内存利用率和 CPU 访问效率,JVM 会对字段进行重排(Field Reordering)。通常的规则是:宽度大的字段(如
long,double)排在前面,宽度小的排在后面。
3. 对齐填充(Padding) 对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。
- 为什么需要对齐?:由于 HotSpot 虚拟机的内存管理系统要求对象起始地址必须是 8 字节的整数倍(即对象的大小必须是 8 字节的整数倍)。如果实例数据部分没有对齐,就需要通过对齐填充来补全。
- 性能考量:8 字节对齐有助于 CPU 高效读取内存(缓存行对齐),避免跨缓存行读取带来的性能损耗。
【延伸考点】
- 指针压缩(CompressedOops):理解
-XX:+UseCompressedOops如何通过将 64 位指针压缩为 32 位来节省堆空间。 - 锁升级过程:Mark Word 是如何随锁状态(无锁、偏向锁、轻量级锁、重量级锁)的变化而动态切换存储内容的。
- JOL (Java Object Layout):熟练使用 JOL 工具在代码中打印对象的具体字节分布。
- 空对象的占用:一个
new Object()在 64 位 JVM(开启压缩指针)下占用多少字节?(通常是 16 字节:12 字节对象头 + 4 字节填充)。
java问题
标识符
【问题】Java 中的标识符(Identifier)命名规则有哪些?如何判断是否合法?
【参考答案】
标识符是编程时用于给变量、类、方法等命名的符号。Java 对标识符有严格的语法强制规则和业界通用的命名规范。
1. 语法强制规则(如果不遵守,编译报错)
- 组成字符:只能由字母(包括 Unicode 字符,如中文)、数字、下划线
_和美元符号$组成。 - 开头限制:不能以数字开头。
- 关键字限制:不能使用 Java 的关键字(如
class,public,if等)或保留字(如goto,const)。 - 大小写敏感:Java 是区分大小写的,
Username和username是两个不同的标识符。 - 长度限制:理论上没有长度限制,但实际开发中应避免过长。
- 特殊约束(Java 9+):从 Java 9 开始,单下划线
_被保留为关键字,不能再作为独立的标识符使用。
2. 业界通用规范(如果不遵守,代码质量差,影响协作)
- 包名(Package):全部小写,通常采用反向域名格式,如
com.google.util。 - 类名与接口名(Class/Interface):大驼峰命名法(UpperCamelCase),如
UserService,AccountMapper。 - 方法名与变量名(Method/Variable):小驼峰命名法(lowerCamelCase),如
getUserById,orderCount。 - 常量名(Constant):全部大写,单词间用下划线分隔,如
MAX_PAGE_SIZE。
3. 避坑指南
- 尽量不使用
$:虽然语法允许,但$通常由编译器自动生成代码时使用(如内部类),手动编写时应避免使用,以防冲突或混淆。 - 见名知意:严禁使用
a,b,c或list1,list2这种无意义命名。 - 避免拼音混用:除非是特定的业务专有名词(如
fapiao),否则应统一使用准确的英文单词。
【延伸考点】
- Java 关键字 vs 保留字:了解
true,false,null虽然不是关键字,但作为字面量也不能作为标识符。 - Unicode 支持:虽然 Java 支持中文命名,但在实际工程中为什么被视为禁忌?
- JDK 版本变化:Java 9 之后为什么禁止使用单下划线作为变量名(为后续 Lambda 的参数忽略占位符做准备)。
- 阿里巴巴 Java 开发手册:熟练掌握手册中关于命名的强制性要求。
char 和 String
【问题】字符型常量和字符串常量的区别有哪些?请从语法、内存和设计角度分析。
【参考答案】
在 Java 中,字符型常量(char)和字符串常量(String)虽然都用于表示文本,但在底层实现和使用场景上有本质区别。
1. 语法与形式上的区别
- 形式:字符型常量必须用 单引号
' '括起来(如'A','中');字符串常量必须用 双引号" "括起来(如"A","Hello","")。 - 内容:字符常量只能包含 单个字符;字符串常量可以包含 0 个或多个字符。
- 本质:字符常量本质上是一个 基本数据类型(
char),其值是该字符在 Unicode 编码表中的数值;字符串常量是一个 引用类型对象(String)。
2. 内存占用与存储方式
- 内存大小:
char占用 固定 2 个字节(16 位),存储的是 UTF-16 编码的代码单元(Code Unit)。String的大小是 动态的。它由对象头、字段信息(如hash)以及底层的存储数组组成。
- 存储位置:
char局部变量通常存储在 栈(Stack) 中。String实例存储在 堆(Heap) 中,且字面量会进入 字符串常量池(String Pool) 以便复用,减少内存开销。
3. 底层实现优化(Java 9+ 变化)
- Java 8 及以前:
String内部使用char[]数组存储,每个字符固定占 2 字节。 - Java 9 及以后:引入了 紧凑字符串(Compact Strings)。内部改用
byte[]加上一个coder标志位。- 如果字符串仅包含 Latin-1 字符(如英文),则每个字符仅占 1 字节。
- 如果包含中文字符等,则回退到每个字符占 2 字节。这一优化大幅降低了堆内存占用。
4. 运算与操作能力
char可以直接进行 算术运算(如'a' + 1结果为98),因为它本质上是整数。String具有丰富的 API 方法(如substring(),indexOf(),toUpperCase()等),且具有 不可变性(Immutability),任何修改操作都会返回一个新的字符串对象。
【延伸考点】
- UTF-16 与 Unicode:为什么一个
char(2字节)有时无法表示一个 Emoji 表情?(涉及代理对 Surrogate Pair 和增补字符)。 - String Table (String Pool):字符串常量池在 JVM 内存模型中的位置演变(PermGen -> Heap)。
- intern() 方法:如何手动将一个运行期间生成的字符串放入常量池?
- 内存泄漏风险:在旧版本 JDK 中
substring可能导致的内存泄漏问题及其在后续版本的修复。 - 性能优化:在循环中使用
+拼接字符串与使用StringBuilder的性能差异。 - Java 9 Compact Strings:为什么要把
char[]改成byte[]?对 GC 压力有何影响?
【问题】是否可以继承 String 类?为什么这样设计?
【参考答案】
在 Java 中,String 类是被 final 修饰的,因此不能被继承。
这种设计并非偶然,而是出于安全、性能和逻辑一致性的深度考量:
1. 保证不可变性(Immutability)的核心基础
String类内部使用final修饰的数组(Java 8 为char[],Java 9+ 为byte[])来存储字符。- 如果
String可以被继承,子类可能会重写其方法(如substring()),通过违规操作修改父类的内部属性,从而破坏其不可变性。 - 不可变性的好处:
- 线程安全:多个线程可以同时安全地访问同一个字符串实例,无需加锁。
- 哈希缓存:
String的hashCode在创建时计算并缓存,非常适合作为HashMap或HashSet的 Key。 - 常量池复用:只有字符串不可变,JVM 才能实现字符串常量池(String Pool),多个引用指向同一个内存地址以节省空间。
2. 安全性保障
- Java 的许多核心功能(如类加载机制、文件路径、网络连接 URL、数据库连接用户名密码)都依赖
String。 - 如果
String可被继承并伪造,黑客可以编写一个看似合法但行为诡异的MyString类,在权限校验等关键环节替换原有的String对象,从而绕过安全检查。
3. 性能优化
- 由于
String是final的,JVM 在编译和运行时可以进行大量的内联(Inline)优化。 - 编译器知道
String的方法不会被重写,因此可以直接调用,减少了虚函数表(vtable)查找的开销。
4. 逻辑清晰性
String作为一个基础的、原子的数据表示形式,其行为应该是可预测且统一的。允许继承会引入不必要的复杂性,增加开发者的心智负担。
【延伸考点】
- final 关键字的多种用途:修饰类(不可继承)、修饰方法(不可重写)、修饰变量(不可二次赋值)。
- String 真的完全不可变吗?:探讨如何通过 反射(Reflection) 强行修改
String内部的value数组(尽管极不推荐)。 - 设计模式:
String的设计体现了“不变模式(Immutable Pattern)”的极致应用。 - 与 StringBuilder/StringBuffer 的对比:为什么它们不是
final的(实际上它们也是final的,但它们内部的字符数组是可变的)。 - 组合优于继承:如果确实需要扩展字符串功能,应该使用包装模式或工具类,而不是继承。
【问题】Java 中字符串拼接的底层原理是什么?
【参考答案】
在 Java 中,字符串拼接的实现方式会根据代码场景和** JDK 版本**发生显著变化。主要分为以下几种情况:
1. 编译期常量折叠(Constant Folding)
- 场景:如
String s = "a" + "b" + "c"; - 原理:对于纯字面量常量的拼接,Java 编译器(javac)会在编译阶段直接将其优化为结果值
"abc"。 - 收益:在字节码中,这只是一个简单的
LDC "abc"指令,运行时完全没有拼接开销。
2. 运行期变量拼接(JDK 8 及以前)
- 场景:涉及变量的拼接,如
String s = str1 + str2; - 原理:编译器会自动将其转换为
StringBuilder(或StringBuffer)的操作:- 创建一个
new StringBuilder()对象。 - 顺序调用
append()方法将各部分添加进去。 - 最后调用
toString()生成一个新的String对象。
- 创建一个
- 注意:在循环中使用
+拼接会导致性能灾难,因为每次循环都会创建一个新的StringBuilder对象,产生大量内存碎片并增加 GC 压力。
3. 运行期变量拼接(JDK 9 及以后)
- 原理:引入了
invokedynamic(Indy) 机制和StringConcatFactory。 - 改变:不再在编译期显式生成
StringBuilder字节码,而是通过invokedynamic调用引导方法(Bootstrap Method)。 - 优势:这种方式将具体的拼接逻辑(策略)从编译期延迟到了运行期。JVM 可以根据当前的硬件和环境,动态选择最优的拼接策略(如预先计算大小后直接操作内存,避免
StringBuilder的中间扩容和数组拷贝),性能更佳且更具灵活性。
4. StringBuilder 的扩容机制
- 初始容量:默认 16 个字符。
- 扩容触发:当
count + 待添加长度 > value.length时。 - 扩容规则:新容量通常为
(旧容量 << 1) + 2(即2n + 2)。如果新容量仍不足,则直接取所需的最小容量。 - 代价:涉及新数组分配和
System.arraycopy的内存拷贝。
【延伸考点】
- 循环拼接禁忌:为什么阿里巴巴开发手册强制要求在循环内使用
StringBuilder.append()? - StringBuilder vs StringBuffer:线程安全性的权衡与内部同步锁的开销。
- StringConcatFactory 策略:了解 JDK 9+ 的
BC_STRATEGY(字节码策略)和MH_STRATEGY(句柄策略)。 - 预分配容量:在已知拼接长度时,通过
new StringBuilder(capacity)减少扩容次数的性能收益。 - invokedynamic 的意义:除了字符串拼接,它在 Lambda 表达式和动态语言支持中扮演什么角色?
【问题】String、StringBuilder 和 StringBuffer 的区别是什么?默认容量是多少?
【参考答案】
这三者在 Java 中都用于处理字符串,但在可变性、线程安全和性能上有明显区别:
1. 核心区别对比
- 可变性:
String:不可变(Immutable)。内部使用final修饰的数组,任何修改操作都会创建新的对象。StringBuilder与StringBuffer:可变(Mutable)。继承自AbstractStringBuilder,可以在原有对象上进行字符序列的修改,避免了频繁创建对象的开销。
- 线程安全性:
String:由于不可变,天然是线程安全的。StringBuffer:线程安全。其内部大部分方法(如append,insert,delete)都使用了synchronized关键字进行加锁同步。StringBuilder:非线程安全。方法没有加锁,在多线程并发操作同一对象时可能出现数据不一致。
- 性能:
StringBuilder>StringBuffer>String。StringBuilder省去了加锁开销,性能最高;String在大量拼接时性能最差(频繁 GC 和内存分配)。
2. 默认容量与扩容机制
- 初始容量:
- 无参构造:默认容量为 16 个字符。
- 带 String 参数构造:初始容量为 str.length() + 16。
- 扩容规则:
- 当现有容量不足以容纳新字符时,会触发扩容。
- 新容量计算公式:
newCapacity = (oldCapacity << 1) + 2(即 2倍旧容量 + 2)。 - 如果按照此公式扩容后仍不足,则直接使用所需的最小容量。
- 扩容涉及 新数组分配 和 System.arraycopy 的内存拷贝,因此建议在已知长度时预设容量。
3. 适用场景建议
- String:适用于少量字符串操作、常量定义、作为 Map 的 Key 或多线程共享只读数据的场景。
- StringBuilder:适用于单线程环境下的中大量字符串拼接操作(如循环构造 SQL、动态拼装日志)。
- StringBuffer:适用于多线程环境下的字符串共享修改场景(虽然现代开发中更多倾向于使用线程封闭后的
StringBuilder)。
【延伸考点】
- 为什么扩容是 2n+2?:了解这个“+2”是为了处理初始容量为 0 的极端情况。
- AbstractStringBuilder:了解
StringBuilder和StringBuffer的共同父类及其内部实现。 - 锁消除(Lock Elimination):JVM 的 JIT 编译器是否会自动优化
StringBuffer的锁?(如果在局部作用域内使用,锁会被消除)。 - String.intern():如何手动将运行期生成的字符串放入常量池。
- 预分配容量:在代码审查中,为什么推荐
new StringBuilder(size)而不是new StringBuilder()?
【问题】Java 9 对 String 的底层实现做了哪些重大改动?为什么要这样做?
【参考答案】
从 Java 9 开始,String 的底层实现经历了自 Java 诞生以来最重大的变化之一,主要体现在 紧凑字符串(Compact Strings) 特性的引入。
1. 底层存储结构的变化
- Java 8 及以前:内部使用
char[]数组存储字符,每个char占用 2 个字节(16 位),采用 UTF-16 编码。 - Java 9 及以后:内部改用
byte[]数组存储,并增加了一个byte类型的coder标志位。
2. 核心原理:Compact Strings
- Latin-1 状态(coder = 0):如果字符串仅包含 Latin-1 字符(如英文、数字、常用标点,即字符值 < 256),则每个字符仅占用 1 个字节。
- UTF-16 状态(coder = 1):如果字符串包含中文字符或其他特殊 Unicode 字符,则每个字符仍占用 2 个字节,回退到原有的存储效率。
- 自动切换:这种切换对开发者是完全透明的,JVM 会在运行时根据字符串内容自动选择最节省空间的编码方式。
3. 为什么要进行这项改动?(设计动机)
- 节省内存占用:根据甲骨文(Oracle)对大量堆转储(Heap Dump)的分析发现,应用中大部分字符串其实只包含 Latin-1 字符。将
char[]改为byte[]可以让这部分字符串的内存占用降低 50%。 - 减少 GC 压力:由于字符串占用了堆内存的很大一部分,减少其内存占用能显著降低垃圾回收(GC)的频率和停顿时间,从而提升系统整体吞吐量。
- 性能平衡:虽然增加了一个
coder判断逻辑,但由于现代 CPU 对位运算和分支预测的强大支持,以及内存占用减少带来的缓存命中率提升,整体性能往往是不降反升的。
4. 级联影响
StringBuilder和StringBuffer的底层也同步改为了byte[]。- 所有的字符串操作方法(如
indexOf,substring)都增加了根据coder标志位选择不同算法逻辑的分支。
【延伸考点】
- 内存可见性:Java 9 的改动对序列化(Serializable)和外部存储是否有影响?(通常通过
readObject/writeObject保持兼容)。 - StringUTF16 与 StringLatin1:了解这两个 JVM 内部类是如何处理不同编码下的字符串运算的。
- -XX:-CompactStrings:在某些极端全是中文字符的应用场景下,关闭该特性是否有收益?
- 与 G1 GC 的配合:G1 的字符串去重(String Deduplication)特性与 Compact Strings 的协同作用。
- Intrinsics 优化:JVM 如何通过汇编级别的指令优化(如 SIMD)来加速
byte[]的字符串处理。
【问题】char 型变量中能不能存储一个中文汉字?为什么?
【参考答案】
在 Java 中,char 型变量可以存储一个中文汉字,但这个结论有一个重要的前提条件。
1. 核心原理:UTF-16 编码
- Java 中的
char类型占用 2 个字节(16 位)。 - Java 内部使用 Unicode 字符集,并采用 UTF-16 编码格式来表示字符。
- 基本多文种平面(BMP):Unicode 的前 65536 个字符(U+0000 到 U+FFFF)被称为 BMP。绝大多数常用的中文字符(包括常用汉字、标点符号等)都落在这个范围内。
- 由于 BMP 范围内的字符在 UTF-16 中刚好占用 2 个字节,因此它们可以完美地存储在一个
char变量中。- 例如:
char c = '中';是合法的,其对应的 Unicode 编码是U+4E2D。
- 例如:
2. 例外情况:增补字符(Supplementary Characters)
- 随着 Unicode 标准的扩展,字符数量早已超过了 65536 个。超出 BMP 范围的字符(如某些罕见古籍汉字、生僻字、Emoji 表情等)被称为 增补字符。
- 这些字符的码点超过了
U+FFFF,在 UTF-16 编码下需要占用 4 个字节。 - 代理对(Surrogate Pair):为了表示这 4 个字节,Java 需要使用 两个
char变量(一个高代理项和一个低代理项)组合而成。 - 因此,对于这些生僻汉字或 Emoji,单个
char变量是无法存储的,必须使用String或char[]。
3. 总结
- 可以存储:绝大多数常用汉字(属于 BMP 平面)。
- 不可存储:少数生僻汉字、古汉字或 Emoji(属于增补字符平面,需占用两个
char)。
【延伸考点】
- Unicode 与 UTF-8/UTF-16 的区别:理解字符集(码表)与编码方案(存储规则)的本质区别。
- String.length() 的陷阱:为什么包含 Emoji 的字符串,
length()返回的结果可能比你看到的字符数要多?(因为length()返回的是char的数量,而非 Unicode 码点的数量)。 - 码点(Code Point)与代码单元(Code Unit):在处理国际化文本时,如何使用
s.codePointCount()正确计算字符数。 - Character API:熟悉
Character.isSupplementaryCodePoint(int codePoint)等工具方法。
【问题】如何将 byte[] 转为 String?在此过程中需要注意什么?
【参考答案】
在 Java 中,将字节数组(byte[])转换为字符串(String)主要通过 String 类的构造方法实现。
1. 转换方式
- 推荐方式:显式指定字符集。
byte[] bytes = ...; // 使用 StandardCharsets 工具类(推荐,避免魔法值) String str = new String(bytes, StandardCharsets.UTF_8); // 或者使用字符集名称 String str = new String(bytes, "UTF-8"); - 普通方式:使用无参构造(不推荐)。
String str = new String(bytes); // 使用系统默认字符集
2. 核心注意事项(防坑指南)
- 字符集不一致导致的乱码:这是最常见的问题。字节数组本身只是二进制数据,必须知道它当初是用什么编码(如 UTF-8, GBK)生成的。如果转换时指定的字符集与生成时的不一致,就会出现乱码(如中文变成
�或??)。 - 平台默认字符集风险:无参构造
new String(bytes)会调用Charset.defaultCharset()。在 Windows 下默认可能是 GBK,而在 Linux/macOS 下通常是 UTF-8。这意味着同一段代码在不同环境下运行结果可能不同。因此,生产环境必须显式指定字符集。 - 受损数据处理:如果字节数组在传输过程中丢失了部分字节,转换出的字符串可能会包含不可见字符或损坏。
- 内存开销:
new String会创建一个全新的对象。如果字节数组非常大,需注意堆内存占用情况。
3. 反向操作:String 转 byte[]
- 同样需要显式指定字符集:
byte[] bytes = str.getBytes(StandardCharsets.UTF_8);。
【延伸考点】
- 常见字符集区别:
UTF-8(变长,支持全球字符)、GBK(中文字符集,双字节)、ISO-8859-1(单字节,常用于中间件内部传输)。 - StandardCharsets vs String 名称:使用
StandardCharsets可以避免处理UnsupportedEncodingException受检异常。 - 乱码排查思路:当发现乱码时,如何通过十六进制查看字节内容,并确定原始编码?
- 网络传输协议:在 HTTP 或 Socket 编程中,如何通过 Header(如
Content-Type)协商字符集? - NIO 中的 CharsetDecoder:对于超大文件或流式数据,如何使用解码器进行更精细的转换处理?
【问题】什么是字符串常量池(String Pool)?它的作用和演进过程是怎样的?
【参考答案】
字符串常量池(String Pool) 是 JVM 为了提升性能和减少内存开销,专门为字符串对象开辟的一块特殊内存区域。
1. 核心设计理念:享元模式(Flyweight)
- 由于
String在 Java 中是不可变的,JVM 可以通过常量池让多个引用共享同一个字符串实例。 - 作用:避免了相同内容的字符串被频繁创建,从而节省了大量堆内存,并减轻了垃圾回收(GC)的压力。
2. 创建对象的不同行为
- 字面量创建:
String s = "abc";- JVM 会先去字符串常量池中查找是否已存在内容为
"abc"的对象。 - 如果存在,直接返回池中对象的引用。
- 如果不存在,则在池中创建一个新对象并返回引用。
- JVM 会先去字符串常量池中查找是否已存在内容为
- 构造器创建:
String s = new String("abc");- 这种方式会创建 1 或 2 个对象。
- 首先确保常量池中有
"abc"(如果没有则创建)。 - 然后在普通堆内存中再创建一个全新的
String对象。因此,s指向的是堆中的引用,而不是池中的引用。
3. 常量池位置的演进(重要)
- JDK 6 及以前:位于 永久代(PermGen)。永久代空间有限,大量字符串常驻容易导致
OutOfMemoryError: PermGen space。 - JDK 7:将字符串常量池移动到了 Java 堆(Heap) 中。
- 动机:堆空间更大,且受垃圾回收器的直接管理。当字符串不再被引用时,可以更及时地被回收。
- JDK 8 及以后:永久代被 元空间(Metaspace) 取代,但字符串常量池 依然保留在 Java 堆中。
4. 内部实现原理
- 字符串常量池底层是一个固定大小的 StringTable(本质是一个
Hashtable)。 - 它不存储字符串内容本身,而是存储指向字符串对象的引用。
【延伸考点】
- intern() 方法:如何手动将一个运行期生成的字符串对象驻留在常量池中?
- JDK 7 intern() 的行为变化:在池中没有字符串时,是复制对象还是仅记录引用?
- -XX:StringTableSize:如何调优常量池的大小以减少哈希冲突并提升查找性能?
- G1 GC 的字符串去重:这与常量池有何区别?(常量池是开发层面的复用,G1 去重是 JVM 自动扫描堆中重复数组并合并)。
- 编译期优化:为什么
"a" + "b"会直接进入常量池,而s1 + s2不会?
【问题】你对 String 对象的 intern() 方法熟悉吗?它的底层原理是什么?
【参考答案】
intern() 是 String 类的一个本地(native)方法,其核心作用是:确保字符串在常量池中只有一份拷贝。
1. 核心行为逻辑
当调用 s.intern() 时:
- 如果字符串常量池中已经包含一个等于此
String对象的字符串(通过equals(Object)确定),则返回池中该字符串的引用。 - 如果池中没有,则将此
String对象添加到池中,并返回此String对象的引用。
2. JDK 版本间的重大差异(高频面试点)
- JDK 6 及以前:
- 常量池在 永久代。
- 如果池中没有,
intern()会把该对象复制一份到永久代中,并返回永久代中新对象的引用。此时,堆中的原对象和池中的新对象是两个不同的对象。
- JDK 7 及以后:
- 常量池移动到了 Java 堆。
- 如果池中没有,
intern()不再复制对象,而是直接在池中记录堆中该对象的引用。这样可以节省内存,避免重复创建。
3. 经典案例分析
String s1 = new StringBuilder("go").append("od").toString();
System.out.println(s1.intern() == s1);
// JDK 6: false (s1在堆,intern返回的是复制到永久代的引用)
// JDK 7+: true (intern直接记录了堆中s1的引用)
String s2 = new StringBuilder("ja").append("va").toString();
System.out.println(s2.intern() == s2);
// 结果:false (无论哪个版本)
// 原因:常量池中早已存在 "java" 字符串(由 JVM 启动时加载 sun.misc.Version 类产生),
// s2.intern() 返回的是系统预存的引用,而 s2 是新创建的堆对象。
4. 实际应用场景
- 内存优化:在处理大量重复字符串(如城市名、省份名、订单状态)时,使用
intern()可以极大地减少内存占用,让数百万个引用指向同一个池内实例。 - 快速比较:如果确定字符串都已 intern,可以使用
==替代equals()进行快速比较,提升性能。
【延伸考点】
- StringTable 的性能:常量池底层是
StringTable(哈希表)。如果 intern 的字符串过多,哈希冲突会导致查找性能下降。可以通过-XX:StringTableSize调优。 - G1 GC 的字符串去重:了解 G1 的
String Deduplication如何在不使用intern()的情况下也能实现类似的内存优化效果。 - 编译期优化与 intern():字面量拼接(如
"a"+"b")是由编译器自动完成 intern 的,而变量拼接(如s1+s2)则不会自动 intern。
【问题】面试题—-考自《深入理解Java虚拟机》
public class StringPool58Demo {
public static void main(String[] args) {
String str1 = new StringBuilder("58").append("tongcheng").toString();
System.out.println(str1);
System.out.println(str1.intern());
System.out.println(str1 == str1.intern());
System.out.println("------------");
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2);
System.out.println(str2.intern());
System.out.println(str2 == str2.intern());
}
}
第一个为true
第二个为false
为什么?按照代码结果,Java字符串答案为false必然是两个不同的Java,那另外一个Java字符串如何加载进来的?
有一个初始化的Java字符串(jdk自带的),在加载sun.misc.Version这个类的时候进入常量池
System.initializeSystemClass()--->sun.misc.Version.init()
类加载器和rt.jar,根加载器提前部署加载rt.jar
变量
【问题】成员变量与局部变量的区别有哪些?请从语法、内存和生命周期角度分析。
【参考答案】
在 Java 中,成员变量(Field)和局部变量(Local Variable)在定义位置、存储方式及使用规则上有本质区别:
1. 语法与定义位置的区别
- 成员变量:定义在 类体中、方法外。
- 可以使用访问修饰符(
public,private等)、static(静态变量)、final、transient、volatile等修饰。
- 可以使用访问修饰符(
- 局部变量:定义在 方法体、代码块或方法参数列表 中。
- 不能使用访问修饰符和
static。 - 唯一允许的修饰符是
final。
- 不能使用访问修饰符和
2. 存储位置与内存布局(重点)
- 成员变量:
- 如果是非静态的(实例变量),随着对象实例一起存储在 堆(Heap) 内存中。
- 如果是静态的(类变量),存储在 方法区(Method Area/元空间) 中。
- 局部变量:
- 存储在 虚拟机栈(Stack) 的局部变量表中。
- 逃逸分析优化:如果 JVM 发现局部变量不会逃逸出方法,可能会通过“栈上分配”或“标量替换”将其直接分配在寄存器或栈上,以提高性能。
3. 生命周期与作用域
- 成员变量:
- 实例变量:随对象的创建而产生,随对象的销毁(GC 回收)而消失。
- 静态变量:随类的加载而产生,随类的卸载而消失,生命周期最长。
- 局部变量:随方法的调用而入栈(创建),随方法的结束而出栈(销毁)。作用域仅限于定义它的方法或代码块。
4. 默认初始值
- 成员变量:有默认初始值。数值型为
0,布尔型为false,引用类型为null。 - 局部变量:没有默认初始值。在使用之前必须显式初始化,否则编译器会直接报错。
【延伸考点】
- 静态变量 vs 实例变量:理解“属于类”与“属于对象”的本质区别。
- 栈上分配与逃逸分析:现代 JVM 如何优化局部变量的内存开销?
- 局部变量表(Local Variable Table):在字节码层面,局部变量是如何被索引和访问的?
- 变量隐藏(Variable Hiding):当局部变量与成员变量重名时,Java 如何处理?(局部变量优先,需通过
this访问成员变量)。
【问题】阐述静态变量和实例变量的区别?
【参考答案】
静态变量(Static Variable)和实例变量(Instance Variable)是 Java 成员变量的两种存在形式,它们在内存分配、生命周期和使用方式上有显著区别:
1. 所属范畴与共享性
- 静态变量:属于 类。被
static修饰,在内存中 仅存一份,由该类的所有实例共享。 - 实例变量:属于 对象(实例)。每创建一个对象,JVM 都会为该对象分配一份独立的实例变量副本,各对象之间互不影响。
2. 存储位置
- 静态变量:存储在 方法区(Method Area)(在 HotSpot JVM 中具体表现为永久代或元空间)的静态变量区。
- 实例变量:随着对象一起存储在 堆(Heap) 内存中。
3. 生命周期与加载时机
- 静态变量:随 类的加载 而初始化,随类的卸载而销毁。它的生命周期贯穿于整个程序的运行阶段。
- 实例变量:随 对象的创建 而初始化(
new的时候),随对象的销毁(被 GC 回收)而消失。
4. 调用方式
- 静态变量:可以通过 类名 直接访问(推荐),也可以通过对象引用访问。
- 实例变量:必须通过 对象引用 访问。
5. 常用场景
- 静态变量:常用于定义全局共享的常量(配合
final)、计数器、单例对象、公共配置信息等。 - 实例变量:用于描述对象的特有属性或状态(如用户的姓名、年龄等)。
【延伸考点】
- 线程安全性:静态变量在多线程环境下是共享资源,必须考虑并发访问的同步问题。
- GC 回收机制:静态变量指向的对象通常被视为 GC Root,如果处理不当,容易引发内存泄漏。
- 静态代码块(static block):静态变量的初始化顺序与静态代码块的关系(按定义顺序执行)。
- 单例模式:利用静态变量的唯一性和类加载机制实现线程安全的单例。
引用
【问题】对象实体与对象引用有何不同?请结合 JVM 内存模型进行阐述。
【参考答案】
在 Java 编程中,理解“对象实体”与“对象引用”的区别是掌握内存管理和垃圾回收的基础。
1. 定义与本质区别
- 对象实体(Object Instance):
- 本质:是通过
new、clone、反射或反序列化等方式创建的真实数据。 - 内容:包含对象头(Mark Word, Klass Pointer)、实例字段(Data)和对齐填充(Padding)。
- 存储:通常存储在 堆(Heap) 内存中。
- 本质:是通过
- 对象引用(Object Reference):
- 本质:是一个变量,存储的是指向对象实体的“地址”或“句柄”。
- 存储:可以存储在 栈(Stack) 的局部变量表中,也可以作为其他对象的字段存储在堆中,或者作为静态变量存储在方法区中。
2. 关系对比( analogy:遥控器与电视机)
- 多对一关系:一个对象实体可以被多个引用同时指向(如
Object a = obj; Object b = obj;)。 - 一对零关系:一个引用可以不指向任何对象(即
null)。 - 独立性:修改引用的指向(如
ref = null)不会立即改变对象实体的内容,但会影响对象的 可达性。
3. JVM 访问定位方式 JVM 通过引用访问对象主要有两种主流方式:
- 直接指针(HotSpot 采用):引用中直接存储对象在堆中的地址。优点是访问速度快,节省了一次指针定位的时间开销。
- 句柄池:引用中存储句柄地址,句柄中包含对象实例数据和类型数据的各自地址。优点是对象在 GC 移动时,只需修改句柄中的地址,引用本身无需变动。
4. 垃圾回收(GC)的影响
- 垃圾回收器判断一个对象是否应该被回收,不是看它有没有被引用,而是通过 可达性分析(Reachability Analysis) 算法,看它是否能从 GC Roots 追踪到。
- 一旦一个对象实体没有任何有效引用指向它,它就变成了“不可达对象”,最终会被 GC 清理。
【延伸考点】
- GC Roots 的组成:哪些变量可以作为起点?(如栈中的局部变量、方法区中的静态变量、JNI 引用等)。
- 指针压缩(CompressedOops):在 64 位 JVM 中,引用(指针)默认占用多少字节?开启压缩后又是多少?
- 逃逸分析:如果对象实体没有逃逸出方法,它是否一定分配在堆上?(可能被优化为栈上分配)。
- 引用类型:强、软、弱、虚四种引用对对象实体生命周期的不同影响。
【问题】强引用、软引用、弱引用、虚引用有什么区别?具体使用场景是什么?
【参考答案】
在 Java 中,为了更灵活地管理对象的生命周期,java.lang.ref 包提供了四种引用类型。它们的主要区别在于 垃圾回收器(GC)回收它们的时机不同。
1. 强引用(Strong Reference)
- 特性:最常见的引用,如
Object obj = new Object()。只要强引用存在,垃圾回收器 永远不会 回收掉被引用的对象。 - 回收时机:即使内存不足,JVM 宁愿抛出
OutOfMemoryError错误,也不会回收强引用对象。只有当引用被显式置为null或超出作用域时,对象才会被回收。 - 场景:绝大多数业务场景。
2. 软引用(Soft Reference)
- 特性:描述一些还有用但并非必需的对象。
- 回收时机:在系统 内存充足 时,不会被回收;在系统 内存不足(即将发生 OOM)时,垃圾回收器会回收这些对象。如果回收后内存仍不足,才会抛出异常。
- 场景:实现 内存敏感型缓存(如图片缓存、网页缓存)。既能提升查询速度,又能保证在内存紧张时自动释放,防止崩溃。
3. 弱引用(Weak Reference)
- 特性:强度比软引用更弱,描述非必需对象。
- 回收时机:只要 垃圾回收器开始工作,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。
- 场景:
WeakHashMap:用于存储那些不需要长期驻留内存的映射关系。- 解决内存泄漏:例如在 ThreadLocal 中防止 Entry 的 Key 泄漏;或在 Android 中防止非静态内部类(如 Handler)持有 Activity 引用导致无法回收。
4. 虚引用(Phantom Reference)
- 特性:也称“幽灵引用”或“幻象引用”。它是最弱的一种引用,完全不会影响对象的生命周期。通过虚引用甚至无法获取到对象实例(
get()永远返回null)。 - 回收时机:对象被回收时,虚引用会被放入一个 引用队列(ReferenceQueue) 中。
- 场景:主要用于 监控对象被从内存中删除的通知,实现比
finalize机制更灵活、更可靠的资源清理(如堆外内存的回收、日志记录等)。
【延伸考点】
- 引用队列(ReferenceQueue):软引用、弱引用和虚引用都可以配合队列使用,用于在对象被回收时接收系统的通知。
- ThreadLocal 的内存泄漏:深入理解为什么 ThreadLocal 的 Key 使用弱引用,而 Value 使用强引用会导致泄漏?
- finalize() 的弊端:为什么 JDK 9 开始使用
java.lang.ref.Cleaner或PhantomReference来替代finalize()? - 内存回收优先级:强 > 软 > 弱 > 虚。
- 虚引用的 get() 为什么返回 null?:设计初衷就是为了不让程序再次访问到该对象,仅作为回收通知。
对象相等
【问题】对象的相等(equals)与指向它们的引用相等(==),两者有什么不同?
【参考答案】
在 Java 中,判断“相等”主要有两种方式:== 操作符和 equals() 方法。它们的核心区别在于:== 比较的是地址,而 equals() 倾向于比较内容。
1. 引用相等(== 操作符)
- 对于引用类型:比较的是两个变量是否指向 堆内存中的同一个对象实例。即它们的内存地址是否完全相同。
- 对于基本类型:比较的是它们的 数值 是否相等。
- 特性:这是 Java 语法层面的强制比较,无法被重写。
2. 对象相等(equals 方法)
- 本质:它是
java.lang.Object类的一个方法。 - 默认行为:在
Object类中,equals()的默认实现就是使用==。也就是说,如果你不重写它,它比较的依然是引用相等。 - 重写目的:许多类(如
String、Integer、List等)都重写了equals()方法,将其改为比较 对象的内容 是否逻辑相等。- 例如:两个不同的
String对象,只要字符序列相同,equals()就返回true,但==返回false。
- 例如:两个不同的
3. 核心契约:equals 与 hashCode
- 在重写
equals()时,必须同时重写hashCode()。 - 规范要求:
- 如果
x.equals(y)为true,那么x.hashCode()必须等于y.hashCode()。 - 如果
x.hashCode() == y.hashCode(),x.equals(y)不一定为true(这就是哈希冲突)。
- 如果
- 后果:如果违反此契约,对象在放入
HashMap或HashSet时会出现丢失或无法正确查找的问题。
4. 总结对比
| 特性 | == 操作符 | equals() 方法 |
| 作用对象 | 基本类型、引用类型 | 仅引用类型 |
| 比较内容 | 内存地址(或基本类型的值) | 逻辑上的内容(需重写) |
| 可重写性 | 不可重写 | 可以重写 |
【延伸考点】
- String 的特殊性:为什么
"a" == "a"为true?(涉及字符串常量池)。 - Objects.equals():JDK 7 引入的工具方法如何优雅地避免
NullPointerException? - 自反性、对称性、传递性:重写
equals()时必须遵循的 5 大 Java 语言规范。 - instanceof 检查:在
equals()实现中,为什么第一步通常是instanceof或getClass()检查?
【问题】使用 equals 方法时,如何有效避免空指针异常(NPE)?
【参考答案】
在 Java 开发中,NullPointerException 是最常见的运行时异常之一。在使用 equals 方法进行比较时,可以通过以下几种策略有效规避 NPE:
1. 常量在前,变量在后(”Literal”.equals(var))
- 做法:将确定的字面量(常量)放在
equals方法的左侧。 - 原理:字面量永远不会为
null,因此调用它的equals方法是安全的。如果变量为null,该方法会安全地返回false。 - 示例:
// 推荐 if ("success".equals(status)) { ... } // 不推荐(如果 status 为 null,则抛出 NPE) if (status.equals("success")) { ... }
2. 使用 java.util.Objects.equals()(推荐)
- 做法:使用 JDK 7 引入的工具类方法。
- 原理:
Objects.equals(a, b)内部封装了空值判断逻辑:public static boolean equals(Object a, Object b) { return (a == b) || (a != null && a.equals(b)); } - 优点:代码简洁,语义清晰,且能同时处理两个操作数都为
null的情况(此时返回true)。
3. 使用封装好的工具类(如 Apache Commons)
- 做法:使用
StringUtils.equals(str1, str2)。 - 场景:在处理字符串比较时,这些库提供了非常健壮的空值处理机制。
4. 在重写 equals 时进行安全性检查
- 做法:在自定义类的
equals方法中,第一步应使用==判断是否为同一引用,第二步应使用instanceof或null检查。 - 示例:
@Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null || getClass() != obj.getClass()) return false; // ... 后续逻辑 }
【延伸考点】
- == 与 null:为什么
var == null永远不会抛出 NPE? - Optional 容器:在 Java 8+ 中,如何利用
Optional优雅地处理可能为空的对象比较? - Lombok 的 @EqualsAndHashCode:使用插件生成的代码是如何处理空值的?
- 业务逻辑中的 null 含义:在数据库查询结果比较时,
null应该被视为“空字符串”还是“未知状态”?
【问题】两个对象值相同(x.equals(y) == true),但却可以有不同的 hashCode,这句话对不对?为什么?
【参考答案】
这句话是不对的。
在 Java 中,equals() 和 hashCode() 之间存在着严格的 API 契约(Contract),这是保证散列集合(如 HashMap, HashSet, Hashtable)正常工作的基石。
1. 核心契约规则 根据 Java 官方规范(Object 类的文档):
- 规则一:如果两个对象通过
equals(Object)方法比较是相等的,那么它们的hashCode()方法必须产生 相同的整数结果。 - 规则二:如果两个对象通过
equals(Object)方法比较是不相等的,它们的hashCode()不要求 必须产生不同的整数结果(即允许哈希冲突)。
2. 为什么要这样设计?(以 HashSet 为例)
当你向 HashSet 放入一个对象时,底层逻辑如下:
- 首先计算对象的
hashCode,找到对应的存储槽(Bucket)。 - 如果该槽位已有对象,则调用
equals()方法判断新旧对象是否真的相等。 - 如果
equals相等但hashCode不同:新对象会被分配到不同的槽位。这样,同一个“逻辑相等”的对象就会在集合中出现多次,完全破坏了Set的去重特性。
3. 总结
- 相等对象必有相等哈希码:这是强制要求。
- 相同哈希码不一定相等:这是由于哈希算法的局限性导致的“哈希冲突”。
【延伸考点】
- 重写规范:为什么阿里巴巴开发手册强制要求“只要重写 equals,就必须重写 hashCode”?
- 性能影响:如果
hashCode实现得不好(所有对象返回同一个值),散列表会退化成什么数据结构?(退化为链表,查找复杂度从 O(1) 变为 O(n))。 - 对象不可变性:为什么作为
Map的 Key,对象最好是不可变的?(如果对象的属性改变导致hashCode改变,将无法从 Map 中找回该对象)。 - 常用实现:
String和Integer是如何重写hashCode的?(String采用 31 迭代算法)。
基本数据类型
【问题】整型包装类型值如何比较?浮点类型数据如何比较?
【参考答案】
在 Java 中,数值的比较需要根据数据类型(基本类型 vs 包装类型)和数值特性(整数 vs 浮点数)采用不同的策略。
1. 整型包装类型的比较(Integer, Long 等)
- 现象:由于自动装箱机制,
Integer x = 100; Integer y = 100;此时x == y为true;但当值为128时,==结果为false。 - 原理:常量池缓存:
Integer内部维护了一个IntegerCache,默认缓存了 -128 到 127 之间的对象。在此范围内的赋值会直接复用池中对象,因此==比较地址是相等的。- 超出此范围会创建新对象,
==比较的是堆地址,结果为false。
- 正确做法:
- 推荐使用
equals()方法:它比较的是对象包装的实际数值。 - 或者显式拆箱后比较:
x.intValue() == y.intValue()。
- 推荐使用
2. 浮点类型数据的比较(float, double)
- 风险:由于计算机采用二进制表示浮点数(IEEE 754 标准),无法精确表示某些十进制小数(如 0.1),直接使用
==比较极易产生非预期结果。 - 正确做法:
- 指定误差范围(Epsilon):判断两个浮点数之差的绝对值是否小于一个极小的阈值。
float a = 1.0f - 0.9f; float b = 0.9f - 0.8f; if (Math.abs(a - b) < 0.000001) { ... } // 视为相等 - 使用
BigDecimal(高精度场景):- 必须使用字符串构造器:
new BigDecimal("0.1"),避免使用new BigDecimal(0.1)引入初始精度误差。 - 使用
compareTo()比较:a.compareTo(b) == 0表示数值相等。
- 必须使用字符串构造器:
- 指定误差范围(Epsilon):判断两个浮点数之差的绝对值是否小于一个极小的阈值。
3. BigDecimal 的 equals() 与 compareTo() 区别
equals():不仅比较数值,还要求 精度(Scale) 一致。如0.1和0.10使用equals比较为false。compareTo():只比较 数值大小。如0.1和0.10使用compareTo比较为0(相等)。
【延伸考点】
- IntegerCache 调优:如何通过
-XX:AutoBoxCacheMax=<size>扩大缓存范围?为什么Byte,Short,Long,Character也有缓存? - NaN 与 Infinity:如何比较特殊的浮点数值?(
Double.isNaN(),Double.isInfinite())。 - 三目运算符的空指针风险:在自动拆箱过程中,三目运算符可能导致的 NPE 问题。
- MySQL 中的精度处理:在数据库中存储金额时,为什么推荐使用
DECIMAL而非FLOAT/DOUBLE?
【问题】表达式 a = a + b 与 a += b 有什么区别吗?
【参考答案】
虽然这两者在大多数情况下结果相同,但在 Java 语法规范和编译底层,它们存在两个核心区别:隐式类型转换和求值次数。
1. 隐式类型转换(核心区别)
a = a + b:- 原理:在进行
+运算时,Java 会进行 二进制数值提升(Binary Numeric Promotion)。例如,如果a是byte类型,a + b的结果会被提升为int类型。 - 结果:将
int赋值给byte必须进行显式强制类型转换,否则编译器会报错。
- 原理:在进行
a += b:- 原理:这是 复合赋值运算符。根据《Java 语言规范》(JLS),
E1 op= E2等价于E1 = (T)((E1) op (E2)),其中T是E1的类型。 - 结果:编译器会自动插入隐式强制类型转换。
- 原理:这是 复合赋值运算符。根据《Java 语言规范》(JLS),
- 代码示例:
byte a = 10; // a = a + 5; // 编译错误:不兼容的类型,从 int 转换到 byte 可能会有损失 a += 5; // 编译通过,等价于 a = (byte)(a + 5)
2. 表达式求值次数
a = a + b:表达式a会被求值两次(第一次读取值,第二次执行赋值)。a += b:表达式a只会被求值一次。虽然在简单变量下没有区别,但如果a是一个复杂的表达式(如getArray()[getIndex()] += 1),性能和副作用会有所不同。
3. 总结
+=更加简洁,且由于自带隐式转换,减少了手动强转的代码量。- 但也需要注意,
+=隐藏的强转可能会掩盖 精度丢失 或 数值溢出 的风险。
【延伸考点】
- 二进制数值提升规则:如果操作数中有
double,则另一个转为double;否则有float转float;否则有long转long;否则全部转为int。 - 复合赋值运算符家族:除了
+=,还有-=,*=,/=,%=,&=,|=,^=,<<=,>>=,>>>=。 - 精度丢失风险:在
int += long的场景下,如果不注意范围,可能会导致截断。 - 字节码差异:通过
javap -c查看两者生成的字节码指令有何不同。
【问题】Java 支持的数据类型有哪些?什么是自动拆装箱?
【参考答案】
Java 是一种强类型语言,其数据类型分为 基本数据类型 和 引用数据类型 两大类。
1. Java 的 8 种基本数据类型 Java 规范规定了基本类型的位宽,且不随操作系统的变化而变化(跨平台性的体现):
- 整数型:
byte:8 位(1 字节),范围 -128 ~ 127。short:16 位(2 字节),范围 -32768 ~ 32767。int:32 位(4 字节),最常用。long:64 位(8 字节),赋值时需加L后缀。
- 浮点型:
float:32 位(4 字节),赋值时需加f后缀。double:64 位(8 字节),精度更高,默认浮点类型。
- 字符型:
char:16 位(2 字节),存储 Unicode 字符。
- 布尔型:
boolean:仅true或false(具体大小由 JVM 实现,通常 1 字节或 4 字节)。
2. 引用数据类型
- 包括 类(Class)、接口(Interface)、数组(Array)。引用类型存储的是对象在堆中的内存地址。
3. 什么是自动拆装箱?
这是 Java 5 引入的特性,旨在简化基本类型与对应包装类(如 Integer, Double)之间的转换:
- 自动装箱(Autoboxing):将基本类型自动转为包装类对象。
- 底层实现:调用包装类的
valueOf()方法。如Integer i = 10;实际上是Integer i = Integer.valueOf(10);。
- 底层实现:调用包装类的
- 自动拆箱(Unboxing):将包装类对象自动转为基本类型。
- 底层实现:调用包装类的
xxxValue()方法。如int n = i;实际上是int n = i.intValue();。
- 底层实现:调用包装类的
4. 为什么要引入拆装箱?
- 容器支持:Java 集合(如
ArrayList,HashMap)只能存储引用类型,不能存储基本类型。 - 代码简洁:减少了手动转换的模板代码。
【延伸考点】
- Integer 缓存池:为什么
Integer.valueOf(100) == Integer.valueOf(100)为true而128为false? - 空指针风险(NPE):自动拆箱时,如果包装类对象为
null,会抛出NullPointerException。这是极其隐蔽的 Bug 来源。 - 性能开销:在循环中频繁进行拆装箱会产生大量临时对象,增加 GC 压力。
- 三目运算符的坑:三目运算符中包含基本类型和包装类型时,会触发自动拆箱,可能导致 NPE。
- Java 泛型擦除:为什么泛型不支持基本类型?(因为泛型擦除后会变为
Object,无法承载基本类型数据)。
【问题】表达式 float f = 3.4; 是否正确?如果不正确,应该如何修改?
【参考答案】
这条语句是不正确的,会导致编译错误。
1. 错误原因:默认类型与精度丢失
- 字面量默认类型:在 Java 中,任何带小数点的数字字面量(如
3.4)默认都被视为double类型(64 位双精度)。 - 窄化转换限制:
float类型是 32 位单精度。将一个 64 位的double数值直接赋值给 32 位的float变量,属于 窄化转换(Narrowing Primitive Conversion)。 - 编译器行为:由于窄化转换可能导致精度丢失或溢出,Java 编译器要求必须进行显式处理,否则会报错:“不兼容的类型: 从 double 转换到 float 可能会有损失”。
2. 正确的修改方式 有两种常见的修改方案:
- 添加后缀(推荐):使用
f或F后缀,明确告诉编译器这是一个float字面量。float f = 3.4f; - 显式强制类型转换:将
double强转为float。float f = (float) 3.4;
3. 数值字面量的其他规则
- 整数默认类型:不带小数点的整数(如
100)默认为int。若要表示long,需加L后缀(如100L)。 - 进制表示:
- 十六进制:以
0x开头(如0x1A)。 - 二进制(Java 7+):以
0b开头(如0b1010)。
- 十六进制:以
- 下划线分隔符(Java 7+):可以在数字中插入下划线以提高可读性(如
1_000_000),编译器会自动忽略它们。
【延伸考点】
- 浮点数的表示原理:了解 IEEE 754 标准,为什么
0.1 + 0.2 != 0.3? - 类型提升顺序:
byte -> short/char -> int -> long -> float -> double。为什么long可以自动转为float?(虽然long64 位,float32 位,但float的表示范围远大于long)。 - 字面量后缀规范:为什么建议
long后缀使用大写L而非小写l?(为了避免与数字1混淆)。 - 科学计数法:如何在 Java 中使用
e表示大数(如1.23e5)。
【问题】switch 语句支持哪些数据类型?是否支持 byte, long, String?
【参考答案】
switch 语句的支持类型随 Java 版本的演进而不断扩大。以下是具体的支持情况及其底层原理:
1. 支持的数据类型
- 基本类型及其包装类:
byte,short,char,int:这些 32 位以内的整型及其对应的包装类(Byte,Short,Character,Integer)均支持。包装类会通过自动拆箱转为基本类型。
- 枚举(Enum):从 Java 5 开始支持。
- 字符串(String):从 Java 7 开始支持。
2. 为什么不支持 long, float, double?
long:switch的设计初衷是高效的跳转,JVM 的字节码指令(如tableswitch)是针对 32 位整型设计的。long是 64 位,无法在单条指令中高效处理。float,double:由于浮点数存在精度问题,两个看似相等的数在内存中可能不一致,不适合做离散值的精确匹配。
3. 底层实现原理(重点)
- String 的 switch:
- 编译器先调用
String.hashCode()将字符串转为int。 - 在
switch中匹配哈希值。 - 关键点:由于哈希冲突的存在,匹配到哈希值后,还会通过
equals()方法进行二次校验,确保逻辑正确。
- 编译器先调用
- Enum 的 switch:
- 底层调用枚举对象的
ordinal()方法,将其转为整数索引。
- 底层调用枚举对象的
- 字节码层面:JVM 使用
tableswitch(连续索引,性能极高 O(1))或lookupswitch(非连续索引,采用二分查找 O(log n))指令。
4. 现代 Java 的增强(Java 12+)
- Switch 表达式:支持
->语法,无需break,且可以有返回值。 - 模式匹配(Pattern Matching):支持对类型进行匹配(如
case Integer i -> ...)。
【延伸考点】
- tableswitch vs lookupswitch:编译器如何根据
case值的疏密程度选择指令? - 为什么 switch 匹配 String 时效率比 if-else 高?:哈希跳转 vs 逐个 equals 比较。
- Null 安全性:如果
switch(expr)中的expr为null,会发生什么?(抛出NullPointerException)。 - 枚举 switch 的最佳实践:为什么在 switch 枚举时不需要加
default?(配合 IDE 检查缺失的枚举项)。
【问题】用最有效率的方法计算 2 乘以 8?
【参考答案】
最有效率的方法是使用位运算:2 << 3。
1. 核心原理
- 位移运算:在二进制表示中,将一个数左移
n位,相当于将其乘以2^n。 - 计算过程:
2的二进制是0000 0010,左移 3 位后变为0001 0000,即十进制的16。 - 效率原因:位移运算直接对应 CPU 的底层指令(如 x86 的
SHL),其执行周期通常比乘法指令(如MUL)更短,且不需要经过复杂的乘法器逻辑。
2. 现代开发中的实际建议
- 编译器优化:在现代 JVM(如 HotSpot)的 JIT 编译阶段,对于常量的乘法(如
x * 8),编译器会自动将其优化为位移指令。 - 可读性优先:在业务逻辑中,建议直接书写
2 * 8或x * 8。这样代码意图更清晰,且不会损失性能,因为底层的优化由编译器代劳。 - 底层库开发:在编写高性能中间件、图形处理或算法库时,手动使用位运算可以确保在各种环境下都能获得极致性能。
【延伸考点】
- 左移 vs 右移:左移(
<<)补 0;右移(>>)保留符号位;无符号右移(>>>)高位补 0。 - 溢出问题:位移超过 31 位(对于
int)会发生什么?(实际上是n % 32次位移)。 - 乘法优化范围:位移只能优化
2^n的乘法,对于非 2 的幂(如x * 7),编译器会如何处理?(可能会转为(x << 3) - x)。 - 位运算的其他应用场景:如权限控制(Bitmask)、哈希算法中的扰动函数等。
【问题】Java 的八种基本数据类型,每个占多少个字节?
【参考答案】
Java 语言规范明确定义了 8 种基本数据类型(Primitive Types),其位数和字节数是固定的,不随硬件架构或操作系统的改变而改变(这是 Java “一次编写,到处运行” 的基石)。
1. 整数类型
- byte:8 bit (1 byte),取值范围 -128 到 127。
- short:16 bit (2 byte),取值范围 -32,768 到 32,767。
- int:32 bit (4 byte),最常用的整数类型。
- long:64 bit (8 byte),常用于表示时间戳或大数值。
2. 浮点类型
- float:32 bit (4 byte),符合 IEEE 754 标准。
- double:64 bit (8 byte),默认的浮点数类型,精度更高。
3. 字符类型
- char:16 bit (2 byte),采用 Unicode (UTF-16) 编码,可以存储一个汉字。
4. 布尔类型
- boolean:理论上占 1 bit,但 JVM 规范并未定义其具体存储大小。
- 作为变量:在 HotSpot JVM 中,通常会被编译为
int处理,占 4 字节(为了对齐 CPU 寄存器,提高存取速度)。 - 作为数组:
boolean[]数组在 HotSpot 中通常被编译为byte[],每个元素占 1 字节。
- 作为变量:在 HotSpot JVM 中,通常会被编译为
5. 内存对齐(Padding)
在实际的 JVM 内存布局中,对象字段会进行“内存对齐”。例如,一个只包含 byte 字段的对象,其实际占用的空间可能会因为 8 字节对齐的要求而被填充(Padding)到更大的单位。
【延伸考点】
- 平台无关性:对比 C/C++(
int在不同平台上可能是 2 字节或 4 字节),Java 的固定大小有何意义? - 包装类:每种基本类型对应的包装类(如
Integer,Double)占用多少内存?(通常 12 字节对象头 + 4 字节数据 + 对齐)。 - String 的内存:Java 9 之后
String内部存储从char[]改为byte[](Compact Strings),对内存优化有何贡献? - void:
void是否属于基本类型?(Java 规范中它不是数据类型,但java.lang.Void是其对应的包装类)。
【问题】short s1 = 1; s1 = s1 + 1; 有什么错?short s1 = 1; s1 += 1; 是否有错?
【参考答案】
这两行代码涉及到 Java 的 数值提升(Numerical Promotion) 和 复合赋值运算符(Compound Assignment Operators) 的底层机制。
1. s1 = s1 + 1; 会导致编译错误
- 原因:在 Java 中,进行算术运算时会发生“自动类型提升”。对于
byte,short,char类型的操作数,它们在运算前会被自动提升为int。 - 计算过程:
s1 + 1表达式中,s1是short,1是int字面量。运算结果是int类型。 - 赋值冲突:将一个
int结果赋值给short类型的变量s1时,由于可能发生高位截断,编译器要求必须进行显式强制转换。 - 修正:
s1 = (short) (s1 + 1);
2. s1 += 1; 可以正确编译
- 原因:根据《Java 语言规范》(JLS),复合赋值表达式
E1 op= E2(如+=,-=,*=)等价于E1 = (T) ((E1) op (E2)),其中T是E1的类型。 - 底层行为:
s1 += 1实际上被编译器解释为s1 = (short) (s1 + 1)。 - 结论:复合赋值运算符内部隐式包含了一个强制类型转换,因此不会报错。
3. 字节码视角
s1 = s1 + 1涉及iadd指令(处理int),结果留在操作数栈顶,赋值时需要i2s指令截断。s1 += 1在字节码层面通常直接使用iinc指令(如果是局部变量且增加值为常量),或者自动处理了类型转换逻辑。
【延伸考点】
- 数值提升规则:如果操作数中有
double,结果为double;否则有float则为float;否则有long则为long;否则一律转为int。 - 常量优化:为什么
short s = 1;不报错?(编译器会对常量字面量进行范围检查,若在 short 范围内则允许窄化转换)。 - 复合赋值的副作用:由于隐式强转的存在,可能会在不经意间导致溢出(例如
byte b = 127; b += 1;结果会变成-128而非报错)。
【问题】Math.round(11.5) 等于多少?Math.round(-11.5) 等于多少?
【参考答案】
结果分别为:Math.round(11.5) 等于 12;Math.round(-11.5) 等于 -11。
1. 核心原理
Math.round 的计算公式非常直观,其本质是将参数 加上 0.5 后向下取整(取不大于该结果的最大整数)。
- 公式:
Math.round(x) = (long) Math.floor(x + 0.5d) - 正数场景:
11.5 + 0.5 = 12.0,floor(12.0)结果为12。 - 负数场景:
-11.5 + 0.5 = -11.0,floor(-11.0)结果为-11。
2. 与常见舍入函数的对比
- Math.floor(x):向下取整,返回不大于
x的最大整数(往轴左侧靠)。floor(11.5)→11.0;floor(-11.5)→-12.0
- Math.ceil(x):向上取整,返回不小于
x的最小整数(往轴右侧靠)。ceil(11.5)→12.0;ceil(-11.5)→-11.0
- Math.rint(x):返回最接近的整数。如果两个整数同样接近,则返回其中的 偶数(也称“银行家舍入法”)。
rint(11.5)→12.0;rint(10.5)→10.0
3. 陷阱提醒
很多人误以为 Math.round 是纯粹的“四舍五入”。但在数学中,-11.5 的四舍五入通常被认为是 -12(远离零点方向)。而 Java 的 Math.round 是 向正无穷大方向舍入。
- 记忆技巧:在数轴上,
round总是先向右移动 0.5 个单位,然后找它左边最近的那个整数点。
【延伸考点】
- 精确舍入:在金融计算中,如果需要严格的四舍五入或银行家舍入,应使用
BigDecimal。 - BigDecimal 舍入模式:
RoundingMode.HALF_UP:真正的四舍五入(-11.5 → -12)。RoundingMode.HALF_EVEN:银行家舍入,常用于减少累积误差。
- 面试陷阱:面试官可能会问
Math.round(-11.6)是多少?(-11.6 + 0.5 = -11.1,floor后为-12)。
【问题】Java 当中使用什么类型表示价格比较好?
【参考答案】
在处理金额、价格等对精度要求极高的场景时,绝对不能使用 float 或 double。推荐方案如下:
1. 推荐方案:BigDecimal(最常用)
- 优点:支持任意精度的定点数,可以完全避免二进制浮点数带来的精度丢失问题。
- 关键点:必须使用
String构造方法 或BigDecimal.valueOf(double)。new BigDecimal(0.1)→ 实际存储的是0.10000000000000000555...(仍有误差)。new BigDecimal("0.1")→ 准确存储0.1。
- 配套使用:结合
RoundingMode明确指定舍入规则(如四舍五入、银行家舍入)。
2. 替代方案:long(性能导向)
- 做法:将金额单位从“元”转换为“分”或“厘”,使用
long类型存储。 - 优点:计算效率极高(纯整数运算),节省内存,且天然规避了小数点精度问题。
- 适用场景:高并发交易系统、海量数据存储(如电商订单流水)。
3. 为什么 double / float 不行?
- 原理:计算机底层采用二进制浮点数(IEEE 754 标准)存储。像
0.1这样的十进制小数在二进制中是无限循环的,无法被精确表示。 - 后果:多次运算后,误差会不断累积,导致
0.1 + 0.2 != 0.3这种在金融系统中致命的问题。
【延伸考点】
- 精度 vs 范围:
BigDecimal的precision()(有效数字个数)与scale()(小数点后位数)的区别。 - 不可变性:
BigDecimal是不可变对象(Immutable),每次算术运算都会产生新对象,需注意赋值。 - 数据库对应:在 MySQL 中,对应的字段类型应为
DECIMAL,而非FLOAT/DOUBLE。 - Java Money API (JSR 354):了解现代 Java 生态中专门处理货币的规范化 API。
【问题】可以将 int 强转为 byte 类型么?会产生什么问题?
【参考答案】
可以进行强制类型转换,但由于 数据溢出(Overflow) 和 位截断(Truncation),可能会导致结果与预期大相径庭。
1. 转换原理
- 位宽差异:Java 中
int占用 32 位(4 字节),而byte占用 8 位(1 字节)。 - 截断行为:强转时,JVM 会直接将
int的高 24 位全部丢弃,仅保留最低的 8 位。
2. 可能产生的问题
- 正数变负数:如果
int的第 8 位(从右往左数)是1,截断后该位会变成byte的符号位。 - 示例分析:
int i = 130; // i 的二进制(32位):00000000 00000000 00000000 10000010 byte b = (byte) i; // 截断后保留 8 位:10000010 // 在 byte 中,最高位 1 是符号位,表示负数。 // 根据补码规则:10000010 (补码) -> 10000001 (反码) -> 11111110 (原码) = -126 System.out.println(b); // 输出 -126
3. 总结
- 如果
int的值在byte的范围(-128 到 127)之内,转换是安全的。 - 如果超出范围,结果会发生“环绕”(Wrap-around),即从最大值跳回最小值重新计数。
【延伸考点】
- 二进制补码:Java 所有的整数类型都采用补码存储,这决定了符号位参与运算的逻辑。
- 窄化转换(Narrowing Conversion):除
int转byte外,long转int、double转float等也都属于此类,均存在精度丢失或溢出风险。 - 隐式强转:回顾
s1 += 1内部是如何处理这种强转的? - 位运算技巧:如何通过
& 0xFF将byte转回“无符号”的int?(int i = b & 0xFF;)。
【问题】数据类型之间的转换?
【参考答案】
Java 中的数据类型转换主要涉及 String、基本类型、包装类 三者之间的相互转换。
1. 字符串(String)与 基本类型/包装类 的转换
- String → 基本类型:使用包装类的
parseXxx(String)方法。int i = Integer.parseInt("123");double d = Double.parseDouble("3.14");
- String → 包装类:使用包装类的
valueOf(String)方法。Integer obj = Integer.valueOf("123");- 区别:
parseInt返回的是基本类型int;valueOf返回的是包装对象Integer(内部通常会利用缓存池)。
- 基本类型 → String:
- 推荐:
String.valueOf(123)或Integer.toString(123)。 - 不推荐:
123 + ""(底层会创建StringBuilder对象,性能开销较大)。
- 推荐:
2. 基本类型与包装类的转换(装箱/拆箱)
- 自动装箱:
Integer obj = 10;(编译器自动调用Integer.valueOf(10))。 - 自动拆箱:
int i = obj;(编译器自动调用obj.intValue())。 - 风险点:拆箱时如果包装类对象为
null,会抛出NullPointerException。
3. 基本类型之间的转换
- 自动类型提升(隐式):小容量转大容量。
byte -> short -> int -> long -> float -> double。 - 强制类型转换(显式):大容量转小容量。可能导致溢出或精度丢失(如
(int)3.14结果为3)。
4. 进阶转换:String ↔ byte 数组
- String → byte[]:
str.getBytes(StandardCharsets.UTF_8)。 - byte[] → String:
new String(bytes, StandardCharsets.UTF_8)。- 注意:转换时必须指定字符集(如 UTF-8),否则会使用系统默认字符集,导致乱码。
【延伸考点】
- NumberFormatException:解析非数字字符串(如
"abc")时的异常处理。 - Boolean 的特殊性:
Boolean.parseBoolean("True")只要字符串忽略大小写等于"true"即返回true,否则一律返回false(不会抛异常)。 - Base64 转换:在网络传输中,如何将二进制 byte 数组转为可打印的 String?(使用
java.util.Base64)。 - 高性能解析:在大规模数据处理中,如何避免频繁创建 String 对象导致的 GC 压力?
【问题】Java 序列化中如果有些字段不想进行序列化,怎么办?
【参考答案】
对于不希望被序列化的字段,主要有以下几种处理方式:
1. 使用 transient 关键字(最常用)
- 作用:
transient是 Java 语言的关键字,专门用于修饰 实例变量。 - 行为:
- 序列化时:JVM 会跳过该字段,其值不会被写入字节流。
- 反序列化时:该字段会被恢复为所属类型的 默认值(如对象为
null,int为0,boolean为false)。
- 限制:只能修饰变量,不能修饰类或方法。
2. 使用 static 关键字
- 原理:序列化是针对 对象(实例) 状态的持久化,而
static修饰的变量属于 类(Class) 级别。 - 行为:静态变量 不会被序列化。即使你没有加
transient,反序列化后得到的静态变量值也是当前 JVM 中该类变量的最新值,而不是序列化时的值。
3. 自定义序列化控制
- 实现
Externalizable接口:与Serializable不同,实现此接口要求手动重写writeExternal和readExternal方法。你可以完全自主决定哪些字段参与序列化。 - 重写
writeObject和readObject:在实现Serializable的类中私有化这两个方法,通过defaultWriteObject()序列化常规字段,手动处理特殊字段。
4. 实际应用场景
- 敏感信息:如用户的
password、token,防止泄露到外部存储或网络。 - 派生字段:可以通过其他字段计算得出的值(如
age可以由birthday计算得出),没必要重复存储。 - 非序列化对象引用:如果类中包含一个没有实现
Serializable接口的第三方库对象引用,必须标记为transient,否则序列化会抛出NotSerializableException。
【延伸考点】
- 单例模式的序列化破坏:如何防止反序列化生成新的单例对象?(使用
readResolve方法)。 - ArrayList 的优化:为什么
ArrayList内部存储元素的elementData数组被标记为transient?(为了根据size仅序列化实际存在的元素,减少空间浪费)。 - 安全性:
transient仅仅是逻辑上的忽略,如果需要真正的安全,应对字段进行加密处理。
【问题】什么是 Java 序列化,如何实现 Java 序列化?
【参考答案】
1. 核心定义
- 序列化(Serialization):将 Java 对象的状态转换为 字节流 的过程。这样对象就可以被保存到磁盘文件,或者通过网络发送到另一个 JVM 中。
- 反序列化(Deserialization):将字节流恢复为 Java 对象的过程。
2. 如何实现
- 实现接口:类必须实现
java.io.Serializable接口。这是一个 标记接口(Marker Interface),内部没有任何方法,仅用于告知 JVM 该类可以被序列化。 - 示例代码:
public class User implements Serializable { // 建议手动声明,防止版本不一致导致失败 private static final long serialVersionUID = 1L; private String name; private transient String password; // 不参与序列化 } - 使用流对象:通过
ObjectOutputStream.writeObject()进行序列化,通过ObjectInputStream.readObject()进行反序列化。
3. serialVersionUID 的作用
- 它是序列化版本号。如果没有显式声明,编译器会根据类结构自动生成一个哈希值。
- 风险:如果类结构发生微调(如增加字段),自动生成的 UID 会改变。此时反序列化旧数据会抛出
InvalidClassException。 - 最佳实践:始终手动声明一个固定的
serialVersionUID,以确保类版本升级后的兼容性。
4. 现代替代方案 由于 JDK 原生序列化存在 安全性差(反序列化漏洞)、性能低、跨语言支持差 等缺陷,在实际生产中通常采用以下替代方案:
- 文本类:JSON(Jackson, Fastjson, Gson)、XML。
- 二进制类:Protobuf(高性能、多语言)、Kryo(Java 专用,极快)、Hessian。
【延伸考点】
- 父类与子类的序列化:如果父类没实现
Serializable但子类实现了,会发生什么?(反序列化时父类的无参构造器会被调用)。 - NotSerializableException:如果对象中包含一个未实现序列化接口的非 transient 引用字段,会报错。
- 单例破坏:如何通过
readResolve()保护单例不被反序列化破坏? - 深度克隆:如何利用序列化实现对象的深度拷贝(Deep Clone)?
静态
【问题】“static” 关键字是什么意思?Java 中是否可以覆盖(override)一个 static 方法?
【参考答案】
1. static 的核心含义
static 表示“静态的”或“全局的”。它修饰的成员不再属于某个具体的 对象(Instance),而是属于 类(Class) 共有。
- 修饰字段(静态变量):内存中只有一个副本,存在于 JVM 的 方法区(Method Area / Metaspace) 中。所有实例共享该变量。
- 修饰方法(静态方法):可以直接通过
类名.方法名()调用。静态方法内部不能使用this或super关键字。 - 修饰代码块(静态块):在类加载(Class Loading)时执行,且仅执行一次。常用于初始化静态资源。
- 修饰内部类(静态内部类):不持有外部类实例的引用,可以独立于外部类实例被创建。
2. static 方法能否被覆盖(Override)? 答案是:不可以。
- 现象:虽然子类可以定义一个与父类完全相同的
static方法,但这在 Java 中被称为 隐藏(Hiding),而不是重写(Override)。 - 底层原理:
- 重写(Override) 是 运行时多态。它依赖于 JVM 的 动态绑定(Dynamic Binding) 机制,根据对象的实际类型(Actual Type)在运行时决定调用哪个方法。
- 静态方法 是 编译期绑定(Static Binding)。编译器在编译阶段就根据引用的 声明类型(Declared Type) 确定了要调用的方法。
- 示例分析:
Parent p = new Child(); p.staticMethod(); // 即使实际对象是 Child,调用的依然是 Parent 的静态方法
3. 为什么设计上不支持 static 重写?
因为 static 的本意就是与类绑定。如果允许重写,就会引入实例相关的动态寻址逻辑,违背了 static “类级别共享”的初衷。
【延伸考点】
- 内存布局:JDK 7 之后,静态变量从永久代(PermGen)移到了堆(Heap)中,但逻辑上仍属于方法区。
- 类加载顺序:父类静态块 -> 子类静态块 -> 父类构造块 -> 父类构造器 -> 子类构造块 -> 子类构造器。
- 工具类设计:为什么工具类(如
Math,Arrays)的方法全是static?(无需状态,节省内存,调用方便)。 - 接口中的 static 方法:Java 8 之后接口可以定义
static方法,且不能被实现类继承。
【问题】是否可以在 static 环境中访问非 static 变量?
【参考答案】
结论:不能直接访问,但可以间接访问。
1. 为什么不能“直接”访问?
- 实例化时机不同:
static变量和方法在 类加载(Class Loading) 阶段就已经存在于方法区中,此时可能还没有任何对象被创建。而非static变量(实例变量)必须在 对象实例化(new) 之后才存在于堆内存中。 - 缺少
this引用:非static变量是属于某个具体对象的。在static方法中,JVM 并没有传入this指针,因此它无法知道该访问哪一个对象的变量。
2. 如何“间接”访问? 如果在静态方法中一定要访问非静态变量,必须先 手动创建对象实例,然后通过对象引用来访问。
public class MyClass {
int instanceVar = 10; // 非 static 变量
public static void staticMethod() {
// 错误:System.out.println(instanceVar);
// 正确:间接访问
MyClass obj = new MyClass();
System.out.println(obj.instanceVar);
}
}
3. 总结
- 静态访问非静态:必须通过对象引用。
- 非静态访问静态:可以直接访问(因为类成员对所有对象可见)。
【延伸考点】
- main 方法的限制:为什么
main方法必须是static?(JVM 无需实例化类即可运行程序)。如果在main中直接调用同类下的非静态方法会怎样?(编译报错)。 - 单例模式:单例模式中,静态的
getInstance()方法是如何访问私有的非静态构造器的? - 内存屏障:虽然
static保证了类级别的唯一性,但在多线程环境下,访问静态变量是否需要同步?(需要,static不保证线程安全)。
【问题】抽象方法是否可以同时是 static?是否可同时是本地方法(native)?是否可同时被 synchronized 修饰?
【参考答案】
结论:这三种组合在 Java 中都是非法的,编译会报错。
1. abstract 与 static 冲突
- 语义矛盾:
abstract方法的初衷是让子类通过 重写(Override) 来提供具体实现,这是一种 运行时动态绑定 行为。而static方法是属于类的,在 编译期静态绑定,不支持重写。 - 调用冲突:
static方法可以通过类名直接调用。如果允许abstract static,那么调用一个没有实现体的方法会导致系统崩溃。
2. abstract 与 native 冲突
- 语义冲突:
native表示该方法有实现,只不过是用 C/C++ 等本地语言编写的,由 JVM 通过 JNI 调用。而abstract明确表示该方法 没有实现,要求子类用 Java 编写实现。两者在“是否有实现”这一点上完全对立。
3. abstract 与 synchronized 冲突
- 锁机制冲突:
synchronized关键字的作用是为方法体内的逻辑加锁。由于abstract方法没有方法体,加锁对象(Monitor)无处挂载,也就没有意义。 - 设计逻辑:同步锁应该是具体实现细节,而不是接口/抽象层定义的契约。
4. 总结:非法组合清单
abstract+static:静态绑定 vs 动态绑定冲突。abstract+native:本地实现 vs 无实现冲突。abstract+synchronized:实现细节锁 vs 无实现冲突。abstract+final:必须被重写 vs 禁止重写冲突。abstract+private:对子类可见要求 vs 对子类隐藏冲突。
【延伸考点】
- 接口的演进:Java 8 之后,接口中可以定义
static方法和default方法(带实现的非抽象方法),这打破了传统“接口中全是抽象方法”的认知。 - 模板方法模式:在设计模式中,经常利用抽象方法定义算法骨架,由子类实现具体步骤。
- Strictfp:
abstract是否可以和strictfp组合?(不可以,因为strictfp也是一种实现层面的精度限制)。
【问题】Java 中的方法覆盖(Overriding)和方法重载(Overloading)是什么意思?
【参考答案】
方法重载和方法覆盖是 Java 多态性的两种不同表现形式。
1. 方法重载(Overloading)
- 定义:发生在 同一个类 中,方法名相同,但 参数列表不同(参数个数、类型或顺序不同)。
- 规则:
- 与返回值类型无关(不能仅靠返回值不同来重载)。
- 与访问修饰符无关。
- 本质:它是 编译期多态(也称静态绑定)。编译器在编译阶段根据传递的实参类型和数量,就能确定调用哪个方法。
2. 方法覆盖(Overriding)
- 定义:发生在 父子类 之间,子类重新定义了父类中已有的方法。
- 规则(两同两小一大):
- 两同:方法名相同、参数列表必须完全相同。
- 两小:
- 子类方法的返回值类型应比父类更小或相等(支持 协变返回类型)。
- 子类方法声明抛出的异常应比父类更小或相等。
- 一大:子类方法的访问权限必须大于或等于父类(如
protected可以改为public)。
- 限制:
static方法、final方法、private方法不能被覆盖。 - 本质:它是 运行时多态(也称动态绑定)。JVM 在运行期间根据 对象的实际类型 来决定执行哪个方法。
3. 核心区别对比
| 特性 | 方法重载 (Overloading) | 方法覆盖 (Overriding) |
|---|---|---|
| 范围 | 同一个类中 | 父子类之间 |
| 方法名 | 必须相同 | 必须相同 |
| 参数列表 | 必须不同 | 必须相同 |
| 多态性 | 编译期多态 | 运行时多态 |
| 绑定机制 | 静态绑定 | 动态绑定 |
【延伸考点】
@Override注解:强烈建议在覆盖方法上加上此注解,它可以让编译器帮你检查方法签名是否正确,防止因手误导致覆盖失败。- 构造器:构造器可以被重载,但不能被覆盖。
- 静态方法:子类定义与父类相同的静态方法不叫覆盖,叫 隐藏(Hiding)。
- invokevirtual vs invokestatic:从字节码指令层面理解重写(动态分派)与重载(静态分派)的区别。
【问题】什么是构造函数?什么是构造函数重载?什么是复制构造函数?
【参考答案】
1. 构造函数(Constructor)
- 定义:一种特殊的方法,用于在创建对象(
new)时初始化对象。 - 特点:
- 名称一致:必须与类名完全相同。
- 无返回值:不需要定义返回类型,连
void都不能有。 - 隐式生成:如果类中没有显式定义任何构造函数,编译器会自动生成一个 无参、空实现 的默认构造函数。
- 失效逻辑:一旦程序员定义了任何一个构造函数,默认的无参构造函数就会失效(如果仍需无参构造,必须手动写出)。
2. 构造函数重载(Constructor Overloading)
- 定义:在一个类中定义多个构造函数,它们的 参数列表不同(参数数量、类型或顺序不同)。
- 作用:提供多种初始化对象的方式。
- 内部调用:可以使用
this(...)在一个构造函数中调用另一个构造函数,但必须放在 第一行。
3. 复制构造函数(Copy Constructor)
- 定义:接收一个同类型的对象作为参数,并根据该对象创建一个新对象。
- Java 现状:Java 语言本身不像 C++ 那样内置复制构造函数,但开发者经常手动实现。
- 示例:
public class User { String name; int age; // 复制构造函数 public User(User other) { this.name = other.name; this.age = other.age; } } - 优势:相比于
Object.clone(),复制构造函数更安全(不依赖于Cloneable接口)、易于扩展且支持final字段的初始化。
【延伸考点】
- 构造器调用顺序:父类构造器总是先于子类构造器执行(通过隐式的
super())。 - 构造器私有化:在单例模式或静态工具类中,为什么要把构造函数设为
private? - 深拷贝 vs 浅拷贝:复制构造函数在处理引用类型成员时,默认是浅拷贝,如何实现深拷贝?
- 构造器与多态:在构造器中调用可能被子类重写的实例方法是非常危险的行为,为什么?(父类初始化时子类字段尚未初始化)。
【问题】数组有没有 length() 方法?String 有没有 length() 方法?
【参考答案】
这是一个关于 Java 基础语法的经典辨析题。结论是:数组没有 length() 方法,而 String 有 length() 方法。
1. 数组的 length 属性
- 形式:
int len = arr.length; - 本质:在 Java 中,数组是一种特殊的 对象。
length是数组对象内置的一个 final 实例属性。 - 原因:数组在创建时空间大小就已经固定,JVM 将其长度作为属性存储,以实现最高效的访问。
2. String 的 length() 方法
- 形式:
int len = str.length(); - 本质:
String是一个类,length()是它定义的一个 实例方法。 - 实现原理:在 JDK 8 之前,
String内部由char[] value存储,length()返回的是数组的长度。在 JDK 9 引入 Compact Strings 后,内部改为byte[] value,length()会根据编码方式计算字符个数。
3. 常用长度/大小获取方式总结
| 数据结构 | 获取方式 | 备注 |
|---|---|---|
| 数组 (Array) | arr.length |
唯一的属性访问 |
| 字符串 (String) | str.length() |
方法调用 |
| 集合 (List/Set/Map) | size() |
接口定义的统一方法 |
| 文件 (File) | file.length() |
返回字节数 (long) |
【延伸考点】
- 数组对象的特殊性:既然数组是对象,它的类名是什么?(如
int[]的类名是[I)。 - JavaScript 对比:在 JS 中,数组和字符串获取长度的方式都是
.length属性。 - 性能差异:属性访问(数组)通常比方法调用(String)略快,但在现代 JVM 优化下几乎可以忽略不计。
- 空指针风险:无论是调用
length属性还是length()方法,如果对象为null,都会抛出NullPointerException。
【问题】在 Java 中,如何跳出当前的多重嵌套循环?
【参考答案】
在 Java 中,跳出多重嵌套循环主要有以下三种方式:
1. 使用带标签(Label)的 break(官方推荐方式)
在最外层循环前定义一个标签(Label),然后在内层循环中使用 break 标签名; 即可直接跳出该标签所标识的循环体。
public class LabelBreak {
public static void main(String[] args) {
outer: // 定义标签
for (int i = 0; i < 5; i++) {
for (int j = 0; j < 5; j++) {
if (i == 2 && j == 2) {
break outer; // 跳出整个 outer 循环
}
System.out.println("i=" + i + ", j=" + j);
}
}
}
}
2. 使用标志位(Boolean Flag) 定义一个布尔变量作为控制条件,在内层循环修改标志位,外层循环根据该标志位决定是否退出。
boolean found = false;
for (int i = 0; i < 5 && !found; i++) {
for (int j = 0; j < 5; j++) {
if (condition) {
found = true;
break; // 跳出内层
}
}
}
3. 使用 return 直接结束方法
如果循环逻辑在一个独立的方法中,可以直接使用 return 语句终止整个方法的执行,从而达到跳出所有循环的效果。
4. 最佳实践建议
- 优先重构:多重嵌套循环通常意味着代码逻辑过于复杂。最好的做法是将内层循环提取为一个独立的方法,然后使用
return结束逻辑。这样不仅能优雅地跳出循环,还能显著提高代码的可读性和可测试性。 - 慎用标签:虽然带标签的
break很强大,但它在某种程度上破坏了程序的结构化控制流(类似goto),过多的标签会使代码难以维护。
【延伸考点】
- 带标签的 continue:与
break类似,continue 标签名;会跳过当前循环的剩余部分,直接开始下一次 外层循环 的迭代。 - Java 关键字限制:标签名可以是任何合法的标识符,但不能是 Java 关键字。
- 性能影响:这几种方式在执行效率上几乎没有区别,选择时应以 可读性 为第一准则。
【问题】Java 在静态方法中可以调用哪些方法?
【参考答案】
1. 核心调用规则
- 静态方法调用:可以直接调用本类或其他类的静态方法(Static Methods)。由于静态方法属于类级别(Class Level),在类加载后即可通过类名直接访问,无需创建对象实例。
- 实例方法调用:不能直接调用实例方法。静态方法在对象创建之前就已存在,而实例方法必须依赖具体的对象引用(
this)才能执行。若需调用,必须在静态方法内部先显式实例化对象,再通过对象引用调用。
2. 关键限制:为什么不能使用 this/super?
- 内存模型:静态方法存放在 JVM 的方法区(JDK 8+ 为元空间 Metaspace),而实例对象存放在堆(Heap)中。静态方法的执行不持有当前对象的隐式参数
this。 - 生命周期:静态方法随类加载而加载,生命周期长于任何单个对象。在静态方法执行时,可能根本没有任何对象被创建。
3. 代码示例
public class StaticTest {
public void instanceMethod() {}
public static void staticMethod() {}
public static void main(String[] args) {
staticMethod(); // OK: 直接调用静态方法
// instanceMethod(); // Error: 无法直接调用实例方法
StaticTest test = new StaticTest();
test.instanceMethod(); // OK: 通过对象引用调用
}
}
【延伸考点】
- 静态绑定与动态绑定:静态方法在编译期进行绑定(Static Binding),而实例方法(多态)在运行期根据实际类型进行动态绑定(Dynamic Binding)。
- 工具类设计:为什么
Math、Arrays等工具类全是静态方法?(无状态性、全局访问便利、节省内存)。 - 静态代码块:静态方法常配合
static {}块用于初始化类级别的配置或常量。
接口与抽象类
【问题】Java 支持多继承吗?Java 8 之后有什么变化?
【参考答案】
1. 类的单继承限制
- 核心规则:Java 的类(Class)不支持多继承。一个类只能有一个直接父类。这主要是为了避免“菱形继承问题”(Diamond Problem),即多个父类拥有同名方法时导致的语义歧义。
- 继承链:虽然不支持直接多继承,但支持多层继承(例如 C 继承 B,B 继承 A)。
2. 接口的多实现(多继承的替代方案)
- 类型层面:一个类可以实现(implements)多个接口。这在类型层面实现了多继承,一个对象可以拥有多种身份(类型)。
- 行为层面(Java 8+):接口引入了
default方法。这使得 Java 在行为层面具备了类似多继承的能力,即一个类可以从多个接口中继承默认的方法实现。
3. 冲突解决机制
- 如果一个类实现的两个接口中定义了签名完全相同的
default方法,编译器会强制要求该类手动覆盖(Override)该方法。 - 在覆盖的方法内部,可以使用
接口名.super.methodName()显式指定调用哪一个接口的实现。
【延伸考点】
- 菱形继承问题:C++ 通过“虚继承”处理,而 Java 通过“单继承 + 接口”的设计从根源上规避了复杂性。
- 组合优于继承(Composition over Inheritance):在设计复杂系统时,通常推荐通过组合(成员变量引用)而非继承来实现代码复用。
【问题】接口(Interface)和抽象类(Abstract Class)的区别是什么?
【参考答案】
1. 设计理念(本质区别)
- 抽象类:是对类本质的抽象,体现的是 “is-a” 关系(例如:
Bird extends Animal)。它用于抽取子类的公共实现。 - 接口:是对行为的抽象,体现的是 “like-a” 关系(例如:
Bird implements Flyable)。它用于定义规范和能力契约。
2. 语法特性对比
- 成员变量:
- 接口:只能定义全局常量(默认
public static final)。 - 抽象类:可以定义普通实例变量、静态变量等各种类型的字段。
- 接口:只能定义全局常量(默认
- 方法实现:
- 接口:Java 8 前只能有抽象方法;Java 8+ 支持
default和static方法;Java 9+ 支持private方法。 - 抽象类:可以包含抽象方法,也可以包含普通方法的具体实现。
- 接口:Java 8 前只能有抽象方法;Java 8+ 支持
- 构造器:
- 接口:没有构造器。
- 抽象类:有构造器,供子类实例化时调用(通过
super())。
- 多实现 vs 单继承:
- 一个类可以实现多个接口,但只能继承一个抽象类。
3. 使用场景建议
- 使用 抽象类:当需要提供代码复用、需要持有状态(变量)、或者希望通过继承建立严格的层次结构时。
- 使用 接口:当需要解耦规范与实现、需要多重继承能力、或者需要定义一组不相关类的共同行为时。
【延伸考点】
- 面向对象原则:面向接口编程(Programming to Interface)是实现解耦和“开闭原则”的核心。
- Java 8 后的模糊边界:随着接口引入
default方法,接口越来越像抽象类。但不能持有实例状态仍然是接口与抽象类最本质的界限。
【问题】接口可以继承接口吗?抽象类可以实现接口吗?抽象类可以继承普通类吗?
【参考答案】
1. 接口继承接口(Interface extends Interface)
- 可以。接口支持多继承。一个接口可以继承一个或多个接口(使用
extends关键字)。 - 示例:
public interface List<E> extends Collection<E>。子接口将继承父接口所有的抽象方法和默认方法。
2. 抽象类实现接口(Abstract Class implements Interface)
- 可以。抽象类实现接口时,不需要实现接口中的所有方法。它可以将部分或全部方法留给具体的子类去实现。
- 设计模式:这常用于“适配器模式”(Adapter Pattern)或“骨架实现”,抽象类为接口提供一些通用的基础实现。
3. 抽象类继承普通类(Abstract Class extends Concrete Class)
- 可以。虽然不常见,但在语法上是完全合法的。抽象类也是类,它遵循类的单继承规则。
- 注意:由于 Java 中所有的类都默认继承自
Object(一个普通类),所以实际上所有的抽象类都在继承普通类。
【延伸考点】
- 多重继承规则:类不支持多继承,但接口支持。这体现了 Java 在设计上对“实现复用(类)”的谨慎和对“行为契约(接口)”的灵活。
- Object 类:它是所有类的根基。即使是抽象类,其构造方法也会隐式调用
super()(即Object的构造器)。 - 接口与类的混合继承:一个类可以同时
extends一个父类并implements多个接口,语法顺序必须是先extends后implements。
【问题】Java 8 之后对接口做了哪些改动?
【参考答案】
1. 默认方法(Default Methods)
- 特性:允许在接口中使用
default关键字定义带有方法体的方法。实现类可以直接继承该实现,也可以根据需要进行重写(Override)。 - 初衷:解决“接口演进”问题。在已有接口中增加新方法时,不再强制所有实现类进行修改,保证了向后兼容性(如 Java 集合框架中新增的
stream()方法)。
2. 静态方法(Static Methods)
- 特性:允许在接口中定义
static方法。这些方法直接属于接口,通过接口名.方法名()调用。 - 初衷:将原本散落在工具类(如
Collections)中的辅助方法归位到对应的接口中,提高代码的内聚性。
3. 函数式接口(Functional Interface)
- 特性:引入了
@FunctionalInterface注解,标识只有一个抽象方法的接口(可以包含多个默认/静态方法)。 - 配合 Lambda:这是 Java 8 支持 Lambda 表达式和 Stream API 的基础(如
Predicate,Consumer,Function)。
4. 私有方法(Java 9+)
- 特性:允许在接口内部定义
private或private static方法。 - 初衷:用于在接口内部封装
default或static方法中的重复逻辑,避免向外暴露。
【延伸考点】
- 接口与多态:
default方法引入了多继承的可能性,需注意方法签名冲突时的手动解决机制。 - 设计权衡:虽然接口越来越像抽象类,但核心区别(接口不能持有非静态状态)依然存在。过度使用
default方法可能导致接口职责过重。
值传递
【问题】什么是值传递和引用传递?Java 是哪一种?
【参考答案】
1. 概念界定
- 值传递(Pass-by-Value):在方法调用时,实参(Actual Parameter)将其值的拷贝传递给形参(Formal Parameter)。对形参的任何修改都不会影响原实参。
- 引用传递(Pass-by-Reference):在方法调用时,实参的内存地址(别名)被直接传递给形参。对形参的修改会直接作用于实参。
2. Java 的传递机制:只有值传递
- 基本数据类型:传递的是数值的副本。
- 引用数据类型(对象):传递的是引用(即对象在堆中的内存地址)的拷贝。
- 因为形参和实参保存的是同一个地址,所以可以通过形参修改对象的内部状态。
- 但如果对形参重新赋值(使其指向新对象),实参原有的指向不会发生改变。
3. 核心结论 Java 语言中不存在引用传递。无论是基本类型还是引用类型,传递的都是“值的拷贝”。对于对象,这个“值”就是它的引用地址。
【延伸考点】
- String 与包装类的特殊性:由于
String和包装类(如Integer)的不可变性(Immutable),在方法内对其重新赋值的表现类似于基本类型,即不会影响原对象。 - C++ 的对比:Java 的引用本质上更接近 C++ 的“指针值传递”,而不是 C++ 中的引用(
&)传递。
【问题】当一个对象被当作参数传递到方法后,方法内改变了对象的属性,那么这到底是值传递还是引用传递?
【参考答案】
结论:依然是值传递。
- 现象解释:传递的是引用的拷贝(即地址的副本)。实参和形参保存了相同的内存地址,因此通过形参修改对象属性,实际上是修改了堆中同一个对象的状态,外部实参自然也能观察到变化。
- 判断标准:如果方法能够改变实参本身的指向(即让外部变量指向另一个新对象),那才是引用传递。但在 Java 中,如果你在方法内执行
param = new Object(),外部实参的指向并不会改变,这证明了传递的是地址的拷贝,而不是原引用本身。
【延伸考点】
- 内存分析:理解栈(Stack)中存放的引用变量与堆(Heap)中存放的实际对象之间的映射关系。
- 面试陷阱:面试官可能会通过展示
StringBuilder.append()的代码来诱导你说是引用传递,务必坚持“Java 只有值传递”的核心原则。
【延伸考点】
- 典型面试代码题:交换两个对象引用为什么在 Java 中实现不了。
- 如何设计 API,避免因可变参数对象引起的副作用。
类加载
【问题】描述一下 JVM 加载 class 文件的原理机制?
【参考答案】
1. 类加载器的职责
JVM 的类加载机制负责从文件系统、网络或其他来源读取 .class 字节码文件,并将其转化为内存中的 java.lang.Class 对象。这一过程由 类加载器(ClassLoader) 及其子类协作完成。
2. 核心原则:按需加载(Lazy Loading)
Java 采用动态加载机制,即只有在程序“主动使用”某个类时(如 new 实例化、访问静态变量、调用静态方法、反射调用等),JVM 才会触发该类的加载流程。这种设计显著减少了内存占用并缩短了系统的启动时间。
3. 加载方式
- 隐式加载:代码中直接引用类(如
User user = new User()),JVM 自动触发加载。 - 显式加载:通过反射 API(如
Class.forName("com.test.User"))或直接调用ClassLoader.loadClass()手动加载。
【延伸考点】
- 主动使用 vs 被动使用:访问父类的静态变量不会导致子类初始化(被动使用);定义类数组(如
User[] users = new User[10])不会触发User类的初始化。 - 异常排查:
ClassNotFoundException(编译期存在但运行期找不到类文件)与NoClassDefFoundError(类加载过程中解析失败或静态块初始化报错)的区别。
【问题】详细描述 JVM 的类加载过程。
【参考答案】
JVM 的类加载过程主要分为五个阶段:加载 → 验证 → 准备 → 解析 → 初始化(其中中间三个阶段合称为“连接”)。
1. 加载(Loading)
- 通过类的全限定名获取定义此类的二进制字节流。
- 将字节流代表的静态存储结构转化为方法区(Metaspace)的运行时数据结构。
- 在堆中生成一个代表该类的
java.lang.Class对象,作为该类元数据的访问入口。
2. 验证(Verification)
- 目的:确保 Class 文件的字节流包含的信息符合 JVM 规范,保证安全性。
- 内容:文件格式验证、元数据验证、字节码验证、符号引用验证。
3. 准备(Preparation)
- 内存分配:为类变量(静态变量,被
static修饰)分配内存并设置初始零值(如int为 0)。 - 特殊情况:如果是
final static修饰的常量,会在准备阶段直接赋值为代码中定义的值。
4. 解析(Resolution)
- 将常量池内的符号引用替换为直接引用(即指向目标内存地址的指针)。
5. 初始化(Initialization)
- 执行类构造器
<clinit>()方法的过程。该方法由编译器自动收集类中所有静态变量的赋值动作和静态代码块中的语句合并而成。 - 执行顺序:父类的
<clinit>()保证在子类之前执行完毕。
【延伸考点】
- 线程安全性:JVM 保证一个类的
<clinit>()方法在多线程环境下被正确地加锁、同步。 - 类卸载条件:类加载器被回收、对应的 Class 对象没被引用、该类的所有实例已被回收。
【问题】Java 中的类加载器有哪些?什么是双亲委派模型?
【参考答案】
1. 常见的类加载器(JDK 8 及以前)
- Bootstrap ClassLoader(启动类加载器):由 C++ 实现,负责加载
JAVA_HOME/lib目录下的核心类库(如rt.jar)。 - Extension ClassLoader(扩展类加载器):加载
JAVA_HOME/lib/ext目录下的扩展包。 - App ClassLoader(系统类加载器):加载用户路径(Classpath)下的所有类库。
- Custom ClassLoader(自定义类加载器):用户通过继承
ClassLoader类自定义加载逻辑。
2. 双亲委派模型(Parent Delegation Model)
- 工作过程:当一个类加载器收到类加载请求时,它首先不会自己尝试去加载这个类,而是把请求委派给父类加载器去完成。每一层都是如此,因此所有的请求最终都会传送到顶层的启动类加载器中。只有当父加载器反馈无法加载(找不到类)时,子加载器才会尝试自己去加载。
- 核心意义:
- 安全性:防止核心 API 被篡改。例如,用户自定义一个
java.lang.String,最终会由启动类加载器加载官方版本,从而保证核心类库的统一。 - 唯一性:确保同一个类不会被重复加载。
- 安全性:防止核心 API 被篡改。例如,用户自定义一个
【延伸考点】
- 如何打破双亲委派模型?
- SPI 机制(Service Provider Interface):如 JDBC 驱动。由于
java.sql.DriverManager是由启动类加载器加载的,它无法访问用户 Classpath 下的具体驱动类。Java 引入了“线程上下文类加载器”来打破这一规则。 - 热部署/模块化:如 Tomcat(Web 容器隔离)、OSGi(插件化),为了实现类隔离,往往需要打破原有的委派链。
- SPI 机制(Service Provider Interface):如 JDBC 驱动。由于
- JDK 9 后的模块化变化:扩展类加载器被重命名为平台类加载器(Platform ClassLoader),双亲委派的委派逻辑在模块化环境下变得更为复杂。
对象与常量池
【问题】String s = new String(“xyz”); 创建了几个对象?
【参考答案】
结论:1 个或 2 个对象。
- 第 1 个对象:
"xyz"。在类加载阶段,如果字符串常量池(String Pool)中不存在该字面量,JVM 就会在常量池中创建一个对象。 - 第 2 个对象:
new String("xyz")。在代码运行阶段,使用new关键字强制在堆(Heap)内存中再创建一个新的String对象,并拷贝常量池中字符串的值。
一句话总结:如果常量池中已经存在 "xyz",则只在堆上创建 1 个对象;如果不存在,则总共创建 2 个对象。
【延伸考点】
- 内存分布:常量池中的对象引用指向全局共享的字符串;
new出来的对象引用指向当前线程栈私有的局部变量。 - intern() 方法:显式地将字符串加入常量池。如果常量池已存在,则返回池中引用;如果不存在,则将当前对象的引用添加到池中并返回。
- Java 7+ 变化:字符串常量池从永久代(PermGen)移到了堆(Heap)内存中。
【问题】怎样创建一个 Immutable(不可变)类?
【参考答案】
1. 核心步骤
- 类声明为 final:确保类不能被继承,防止子类通过重写方法来破坏不可变性。
- 成员变量私有化且 final:使用
private final修饰所有属性,确保变量在构造后不可更改。 - 不提供 Setter 方法:只提供 Getter 方法,不提供任何可以修改内部状态的接口。
- 防御性拷贝(Defensive Copy):
- 构造器中:如果构造器参数包含可变对象(如
Date、List),不要直接引用,而是存入其副本。 - Getter 中:如果需要返回可变对象成员,应返回其克隆副本或只读视图,防止外部通过引用修改内部状态。
- 构造器中:如果构造器参数包含可变对象(如
2. 示例代码
public final class ImmutableUser {
private final String name;
private final List<String> roles;
public ImmutableUser(String name, List<String> roles) {
this.name = name;
this.roles = new ArrayList<>(roles); // 防御性拷贝
}
public List<String> getRoles() {
return Collections.unmodifiableList(roles); // 返回只读视图
}
}
【延伸考点】
- 不可变性的好处:天然线程安全(无需加锁)、易于缓存(如
String的hash缓存)、可靠性高。 - 常见不可变类:
String、Integer、BigDecimal、LocalDate(Java 8 新日期类)。 - 性能权衡:每次“修改”都会产生新对象,在大规模操作时可能带来 GC 压力(此时应考虑使用对应的可变类,如
StringBuilder)。
【问题】String s = “Hello”; s = s + “ world!”; 执行后,原始的 String 对象内容变了吗?
【参考答案】
结论:没有变。
- 原因:
String是不可变的(Immutable)。 - 内存分析:
- 执行
String s = "Hello":在内存中创建了一个"Hello"对象。 - 执行
s = s + " world!":JVM 并不是修改了原有的"Hello"对象,而是新创建了一个内容为"Hello world!"的新对象,并让s指向它。
- 执行
- 结果:原来的
"Hello"对象在内存中依然存在(如果没有被 GC),只是不再被s引用。
【延伸考点】
- 性能隐患:在循环中使用
+拼接字符串会频繁创建大量的中间临时对象,导致内存占用升高。 - 优化方案:建议使用
StringBuilder或StringBuffer(线程安全)进行可变字符串操作。
【问题】分析下面字符串比较代码的输出结果。
String str1 = "hello"; // 常量池
String str2 = "he" + new String("llo"); // 运行期拼接,结果在堆中
String str3 = "he" + "llo"; // 编译期常量折叠,结果在常量池中
System.out.println(str1 == str2); // 输出?
System.out.println(str1 == str3); // 输出?
【参考答案】
1. str1 == str2 输出 false
str1指向常量池中的"hello"。str2中包含了new String(),这是一个运行时操作。即使拼接后的结果是"hello",它也是在堆上新创建的一个对象。两个引用的内存地址不同,因此为false。
2. str1 == str3 输出 true
- 常量折叠(Constant Folding):对于
"he" + "llo"这种字面量拼接,编译器在编译阶段就会将其优化为"hello"。 - 因此,
str3最终指向的也是常量池中已有的"hello"对象。两个引用指向同一个内存地址,因此为true。
【延伸考点】
- 变量拼接:如果代码是
String s1="a"; String s2=s1+"b";,由于s1是变量,编译器无法在编译期确定其值,因此s2会在运行时通过StringBuilder拼接并在堆上创建新对象。 - final 优化:如果变量被声明为
final String s1 = "a";,编译器会将其视为常量,此时s1 + "b"依然会触发常量折叠。
运算符
| 【问题】介绍一下 Java 中的位运算符(^、&、 | 、«、»、»>)。 |
【参考答案】
1. 基础位运算
&(按位与):对应位均为 1 时结果为 1,否则为 0。|(按位或):对应位只要有一个为 1,结果就为 1。^(按位异或):对应位相同为 0,不同为 1(“不进位加法”)。
2. 移位运算
<<(左移):二进制位整体向左移动,右侧补 0。相当于乘以 (2^n)。>>(有符号右移):整体向右移动,左侧补符号位(正数补 0,负数补 1)。相当于除以 (2^n) 并向下取整。>>>(无符号右移):整体向右移动,左侧一律补 0。常用于处理负数。
【延伸考点】
- 位运算的高级应用:
- 快速计算:
hash & (length - 1)用于HashMap中计算桶下标(前提是length为 2 的幂次)。 - 权限管理:使用位掩码(Bitmask)表示多种权限的组合。
- 变量交换:使用
^可以在不使用临时变量的情况下交换两个数(a ^= b; b ^= a; a ^= b;)。
- 快速计算:
| 【问题】” | ” 与 “ | ” 的区别是什么? |
【参考答案】
1. 逻辑行为(核心区别)
||(逻辑或/短路或):具有短路特性。如果左侧表达式结果为true,则不再计算右侧表达式,直接返回true。|(按位或/逻辑或):无论左侧结果如何,都会完整执行右侧表达式。
2. 适用场景
- 在布尔逻辑判断中,通常推荐使用
||,因为它可以避免不必要的计算,甚至能防止空指针异常(例如if (obj != null || obj.doSomething()))。 |更多用于位运算,处理二进制位的合并。
【延伸考点】
&与&&:同理,&&具有短路特性(左侧为false则不看右侧),而&总是完整计算。- 副作用风险:如果在逻辑判断中包含带副作用的操作(如自增
i++或方法调用),短路行为会导致该操作可能不被执行,需在设计时留意。
【问题】int 型与 double 型进行运算,结果是什么类型?有哪些自动类型转换规则?
【参考答案】
结论:结果类型是 double。
1. 自动类型提升规则(Numerical Promotion) 当不同类型的数值参与算术运算或比较运算时,Java 会自动将它们提升为同一种类型:
- 规则 1:如果两个操作数中有一个是
double,另一个就会被提升为double。 - 规则 2:否则,如果有一个是
float,另一个提升为float。 - 规则 3:否则,如果有一个是
long,另一个提升为long。 - 规则 4:否则,两个操作数都将被提升为
int。
2. 特殊情况:byte, short, char
- 这三种类型在进行任何算术运算(如
+,-,*,/)之前,都会被先提升为int型,即使是两个byte相加,结果也是int。
【延伸考点】
- 精度丢失风险:将
long提升为float或将int提升为float时,虽然是自动转换,但可能会因为有效数字位数限制而导致精度丢失。 - 强制类型转换(Narrowing Conversion):从高精度向低精度转换(如
double转int)必须显式强转,且会发生截断或溢出。
【问题】三目运算符引发的空指针异常(NPE)是怎么回事?
【参考答案】
1. 现象复现
boolean flag = true;
Boolean nullBoolean = null;
boolean result = flag ? nullBoolean : false; // 这里会抛出 NullPointerException
2. 根本原因:自动拆箱(Auto-unboxing)
- 类型推导规则:当三目运算符(
? :)的第二、第三个操作数中,一个是包装类型(如Boolean),另一个是基本类型(如boolean)时,JVM 会根据 JLS(Java Language Specification)的规则将包装类型自动拆箱为基本类型进行计算。 - 异常触发:在上例中,
nullBoolean为null,JVM 尝试执行nullBoolean.booleanValue(),从而导致NullPointerException。
【延伸考点】
- 安全编码建议:
- 类型统一:尽量确保三目运算符的两个返回分支类型一致。
- 显式判空:如果可能涉及包装类,应先做判空,或使用
Boolean.TRUE.equals(nullBoolean)。 - Java 8+ 行为变化:在某些复杂的泛型推导场景中,Java 8 引入的目标类型推断可能会使结果表现不同,但自动拆箱导致的 NPE 风险依然普遍存在。
对象拷贝
【问题】深拷贝(Deep Copy)和浅拷贝(Shallow Copy)的区别是什么?
【参考答案】
1. 浅拷贝(Shallow Copy)
- 特性:只复制当前对象本身以及对象中的基本数据类型字段。对于对象中的引用类型字段,仅复制其内存地址(引用),而不复制指向的具体对象。
- 后果:新旧对象内部的引用指向的是堆中同一个子对象。修改其中一个对象的子对象属性,会同步影响另一个对象。
2. 深拷贝(Deep Copy)
- 特性:不仅复制当前对象,还会递归地复制对象中所有的引用类型字段指向的对象,直到整个对象树都被完整复制。
- 后果:新旧对象在堆内存中完全独立,互不影响。修改拷贝后的对象,原对象保持不变。
【延伸考点】
- 如何实现深拷贝?
- 实现
Cloneable接口:并在clone()方法中手动克隆内部所有的引用对象(代码繁琐)。 - 序列化机制:利用
ObjectOutputStream将对象写入流再读出,是实现深拷贝最简便的方式(性能略低)。 - 第三方工具类:如 Apache Commons Lang 的
SerializationUtils.clone()或 Google Guava。
- 实现
- BeanUtils 拷贝机制:Spring 和 Apache 的
BeanUtils.copyProperties()通常都是浅拷贝,在复杂对象映射时需格外注意。
【问题】解析 XML 文档有哪几种常用方式?
【参考答案】
1. DOM(Document Object Model)
- 原理:将整个 XML 文档加载到内存中,构建成一颗树(Tree)结构。
- 优点:支持随机访问,可以方便地遍历、修改节点。
- 缺点:内存消耗大,不适合处理超大型 XML 文件。
2. SAX(Simple API for XML)
- 原理:基于事件驱动的流式解析。从头到尾读取文档,每遇到一个标签或内容就触发一个事件(回调方法)。
- 优点:内存占用极低,适合处理海量数据的 XML 文件。
- 缺点:不支持随机访问,只能顺序读取,编程逻辑较为复杂(需要自己维护状态)。
【延伸考点】
- StAX(Streaming API for XML):JDK 6 引入的“拉(Pull)”模式解析,比 SAX(推模式)更灵活,开发者可以主动控制解析进度。
- JAXB(Java Architecture for XML Binding):将 XML 直接映射为 Java 对象(对象/XML 映射),在现代企业级应用中(如 WebService)非常常用。
final 关键字
【问题】final 关键字有哪些具体用法?
【参考答案】
1. 修饰类
- 特性:类不能被继承(如
String,Integer等)。 - 目的:保护类的完整性,防止子类修改原有逻辑。
2. 修饰方法
- 特性:方法不能被子类重写(Override),但可以被重载(Overload)。
- 目的:锁定方法逻辑,防止子类恶意篡改或破坏父类的核心流程(如模板方法模式)。
3. 修饰变量
- 成员变量:必须在声明时或构造方法中完成初始化。一旦赋值,不可更改。
- 局部变量:在使用前必须赋值,且仅能赋值一次。
- 参数:方法内部不能修改参数的值(如果是引用类型,则不能改变其指向)。
【延伸考点】
- 性能优化:在老版本 JVM 中,
final方法可能触发内联优化(Inline),现代 JVM 会自动进行这种优化。 - 并发安全:
final关键字在多线程下具有“安全发布”语义,即 JVM 保证在构造函数执行完毕后,其他线程看到的final字段一定是初始化后的值。
【问题】final 是不是等同于 Immutable(不可变)?
【参考答案】
结论:不等同。
- final 的作用:
- 修饰基本类型:值不可变。
- 修饰引用类型:引用(地址)不可变。即该变量不能再指向另一个新对象,但它指向的对象内部状态(属性、内容)依然是可以修改的。
- Immutable 的作用:指的是对象本身的内容不可变(如
String)。无论你用什么引用指向它,都无法修改对象内部的数据。
代码示例:
final List<String> list = new ArrayList<>();
list.add("hello"); // 正常运行,对象内部内容被修改了
// list = new ArrayList<>(); // 编译报错,引用不可变
【延伸考点】
- 如何真正实现不可变? 需要结合
final关键字、私有化属性、不提供修改接口、防御性拷贝等多种手段。 - 只读集合:
Collections.unmodifiableList(list)只是返回一个视图,如果原list改变,视图也会变。而 Java 9 的List.of()返回的是真正的不可变集合。
Java 8 新特性
【问题】如何取得当前日期的年、月、日、时、分、秒?(Java 8 前后对比)
【参考答案】
1)Java 8 之前:使用 Calendar
Calendar cal = Calendar.getInstance();
System.out.println(cal.get(Calendar.YEAR));
System.out.println(cal.get(Calendar.MONTH)); // 0 - 11
System.out.println(cal.get(Calendar.DATE));
System.out.println(cal.get(Calendar.HOUR_OF_DAY));
System.out.println(cal.get(Calendar.MINUTE));
System.out.println(cal.get(Calendar.SECOND));
2)Java 8 之后:使用 java.time
LocalDateTime dt = LocalDateTime.now();
System.out.println(dt.getYear());
System.out.println(dt.getMonthValue()); // 1 - 12
System.out.println(dt.getDayOfMonth());
System.out.println(dt.getHour());
System.out.println(dt.getMinute());
System.out.println(dt.getSecond());
【延伸考点】
LocalDate/LocalTime/LocalDateTime/ZonedDateTime的区别。- 时区与夏令时场景建议使用
ZonedDateTime或Instant。
【问题】如何格式化日期?(Java 8 前后对比)
【参考答案】
1. Java 8 之前:SimpleDateFormat
- 特性:基于模式字符串进行格式化。
- 缺点:线程不安全。在多线程环境下共享同一个
SimpleDateFormat实例会导致解析错误或抛出异常。通常需要使用ThreadLocal来保证线程安全。 - 代码示例:
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String result = sdf.format(new Date());
2. Java 8 之后:DateTimeFormatter
- 特性:线程安全且不可变。可以直接定义为静态常量在全局共享。
- 代码示例:
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"); String result = LocalDateTime.now().format(dtf);
【延伸考点】
- 性能对比:
DateTimeFormatter不仅线程安全,其内部实现也经过优化,在高并发场景下性能优于SimpleDateFormat。 - 解析操作:
LocalDate.parse("2026-03-02", dtf)。 - 最佳实践:在生产环境中,应始终优先使用 Java 8 的日期时间 API。
【问题】如何打印“昨天的当前时刻”?(Java 8 前后对比)
【参考答案】
1. Java 8 之前:使用 Calendar
Calendar cal = Calendar.getInstance();
cal.add(Calendar.DATE, -1);
System.out.println(cal.getTime());
2. Java 8 之后:使用 LocalDateTime
LocalDateTime yesterday = LocalDateTime.now().minusDays(1);
System.out.println(yesterday);
【延伸考点】
- 链式操作:Java 8 API 支持链式调用,如
LocalDateTime.now().minusDays(1).minusHours(2)。 - 时区问题:如果涉及跨时区时间计算,应使用
ZonedDateTime或Instant。
Java 线程基础
【问题】进程和线程的区别是什么?
【参考答案】
1. 基本定义
- 进程(Process):操作系统资源分配和调度的基本单位。每个进程都有独立的内存空间、文件描述符等。
- 线程(Thread):进程内部的一个执行单元。一个进程可以包含多个线程,这些线程共享所属进程的资源(如堆、方法区)。
2. 核心区别对比
- 资源占用:进程独立,线程共享。
- 切换成本:线程切换比进程切换快得多(上下文切换开销较小)。
- 稳定性:一个进程崩溃不会影响其他进程;但一个线程崩溃可能导致所属进程下的所有线程全部崩溃。
- 通信方式:进程间通信(IPC)较复杂(信号、管道、Socket);线程间通信(Wait/Notify、共享内存)相对简单。
【延伸考点】
- 轻量级进程(LWP):在现代 JVM 中,Java 线程通常是直接映射到操作系统的内核线程上的。
- 并发 vs 并行:
- 并发:多个任务在同一时间段内交替执行。
- 并行:多个任务在同一时刻真正同时执行(多核 CPU)。
- 上下文切换:当 CPU 从一个线程切换到另一个线程时,需要保存当前线程的执行上下文,这是有开销的。
【问题】并发编程的优势与挑战(风险)分别有哪些?
【参考答案】
1. 并发编程的优势
- 充分利用多核 CPU 性能:提高系统的吞吐量和处理能力。
- 提高响应速度:例如在 Web 服务器中,可以同时处理多个用户的请求。
- 改善资源利用率:在等待 I/O、网络传输时,CPU 可以转而执行其他线程的任务。
2. 并发编程面临的挑战(风险)
- 安全性(Thread Safety):多个线程同时读写共享资源,可能导致数据不一致(竞态条件)。
- 活跃性(Liveness):
- 死锁(Deadlock):两个或多个线程互相持有对方需要的锁而永久等待。
- 活锁、饥饿:线程虽然在运行但无法推进任务,或长期得不到 CPU 时间片。
- 性能开销:线程的创建、销毁以及频繁的上下文切换会带来额外的 CPU 和内存开销。
【延伸考点】
- 如何衡量并发性能? 通常关注吞吐量(Throughput)和响应延迟(Latency)。
- 阿姆达尔定律(Amdahl’s Law):描述了系统中串行部分比例如何限制程序能达到的最大加速比。
【问题】创建线程有几种方式?为什么推荐使用线程池?
【参考答案】
1. 创建线程的三种主要方式
- 继承
Thread类:重写run()方法。简单直观,但受 Java 单继承限制。 - 实现
Runnable接口:解耦了任务和线程执行器。推荐这种方式。 - 实现
Callable接口:配合FutureTask或线程池使用。可以获取返回值,并抛出异常。
2. 为什么推荐使用线程池(ThreadPoolExecutor)?
- 降低资源消耗:重用已创建的线程,避免频繁创建和销毁线程带来的性能开销。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:可以统一分配、调优和监控线程,防止因无限制创建线程导致系统崩溃。
【延伸考点】
- 线程池的核心参数:
corePoolSize(核心线程数)、maximumPoolSize(最大线程数)、keepAliveTime(空闲存活时间)、workQueue(阻塞队列)、handler(拒绝策略)。 - Executors 的局限性:不建议使用
Executors.newFixedThreadPool等快捷方法,因为其队列长度为Integer.MAX_VALUE,容易导致 OOM。应通过ThreadPoolExecutor手动配置。
【问题】如何正确地停止(终止)一个正在运行的线程?
【参考答案】
1. 推荐方式:协作式中断(Interruption)
Java 并没有提供一种“暴力”终止线程的方法。正确的做法是使用 thread.interrupt() 发出中断信号,并由线程内部通过检查中断标志位来决定何时停止。
- 检查方式:循环中使用
Thread.currentThread().isInterrupted()。 - 响应异常:如果线程处于
sleep或wait状态,会抛出InterruptedException,此时应清理资源并退出。
2. 为什么不能使用 stop() 方法?
- 不安全:
stop()会立即强行停止线程,不给线程释放锁和清理资源的机会,容易导致对象状态不一致或死锁。
3. 使用标志位
- 定义一个
volatile boolean类型的变量(如exit),通过修改该变量的值来通知线程退出。
【延伸考点】
- 两阶段终止模式(Two-Phase Termination):第一阶段发送中断信号,第二阶段线程响应信号并优雅退出。
- 线程池的停止:
shutdown():不再接收新任务,但会执行完已提交的任务。shutdownNow():尝试中断正在执行的任务,并返回未执行的任务列表。
【问题】实现 Runnable 接口和 Callable 接口的区别是什么?
【参考答案】
1. 返回值
Runnable的run()方法没有返回值。Callable的call()方法有返回值,通常配合Future或FutureTask获取异步执行的结果。
2. 异常处理
Runnable内部只能捕获异常,不能向上抛出受检异常(Checked Exception)。Callable允许在方法签名上声明抛出受检异常。
3. 方法名
Runnable的核心方法是run()。Callable的核心方法是call()。
【延伸考点】
- 适配器模式:可以使用
Executors.callable(Runnable task)将Runnable转换为Callable。 - Future 机制:通过
future.get()获取结果时,如果任务未完成,当前线程会进入阻塞状态。
【问题】详细描述 Java 线程的几种状态。
【参考答案】
根据 java.lang.Thread.State 枚举,Java 线程共有 6 种状态:
- NEW(新建):线程刚被创建,但尚未启动(未调用
start()方法)。 - RUNNABLE(可运行):线程正在 JVM 中执行,但可能正在等待操作系统的资源(如 CPU 时间片)。
- BLOCKED(阻塞):线程正在等待获取一个监视器锁(Monitor Lock)以进入同步块或方法。
- WAITING(等待):线程无限期地等待另一个线程执行特定操作(如通过
wait(),join(),LockSupport.park())。 - TIMED_WAITING(计时等待):在指定时间内等待(如
sleep(ms),wait(ms),join(ms))。 - TERMINATED(终止):线程执行完毕或因异常退出。
【延伸考点】
- 状态切换图:理解
wait()(进入 WAITING)与sleep()(进入 TIMED_WAITING)在锁释放行为上的差异。 - 监控工具:使用
jstack命令可以实时查看进程中所有线程的具体状态。
【问题】synchronized 修饰方法和修饰代码块的区别是什么?
【参考答案】
1. 同步范围
- 同步方法:锁定整个方法体。
- 同步代码块:锁定指定的代码段,粒度更细,灵活性更高。
2. 锁的对象
- 非静态同步方法:锁的是当前的实例对象(
this)。 - 静态同步方法:锁的是当前类的 Class 对象(
XXX.class)。 - 同步代码块:可以自定义锁对象,如
synchronized(lock) { ... }。
3. 性能影响
- 同步代码块通常比同步方法性能更好,因为它能尽量缩小锁的持有时间,减少不必要的线程阻塞。
【延伸考点】
- 可重入性(Reentrant):同一个线程获取锁后,可以再次获取同一把锁而不会被阻塞(通过锁计数器实现)。
- 锁消除与锁粗化:JVM 在 JIT 编译阶段会根据逃逸分析等手段优化
synchronized的性能。
【问题】描述 synchronized 的实现原理(监视器 Monitor 机制)。
【参考答案】
1. 字节码层面
- 同步代码块:通过
monitorenter和monitorexit指令实现。当执行monitorenter时,线程尝试获取对象的 Monitor 所有权。 - 同步方法:通过方法标志位
ACC_SYNCHRONIZED标识。
2. 核心组件:Monitor 每个 Java 对象在 JVM 内部都关联着一个 Monitor(管程/监视器):
- Owner:记录当前持有锁的线程。
- WaitSet:存放调用了
wait()方法而进入 WAITING 状态的线程。 - EntryList:存放正在尝试获取锁而处于 BLOCKED 状态的线程。
- Count:锁计数器,用于实现可重入锁。
3. 工作流程 线程进入同步块时尝试获取 Monitor,成功则 Count+1 并将 Owner 设为自己;退出时 Count-1,Count 为 0 时释放锁。
【延伸考点】
- 锁升级(Lock Inflation):为了提高性能,JVM 对
synchronized进行了优化,经历了:无锁 → 偏向锁 → 轻量级锁 → 重量级锁 的升级过程。 - ObjectMonitor:这是 JVM(HotSpot)中 C++ 实现的具体监视器对象。
【问题】程序计数器(Program Counter Register)为什么是线程私有的?
【参考答案】
1. 核心作用
程序计数器记录了当前线程所执行的字节码的行号或地址。它是唯一一个在 JVM 规范中没有规定任何 OutOfMemoryError 情况的区域。
2. 私有化的必要性 在多线程环境下,CPU 会通过时间片轮转(Round Robin)频繁切换线程执行:
- 上下文恢复:当线程被切回时,必须知道上一次执行到了哪一行。
- 独立性:每个线程执行的逻辑不同,如果共享计数器,会导致执行逻辑混乱。
结论:为了保证每个线程在切换后能恢复到正确的执行位置,程序计数器必须是线程私有的。
【延伸考点】
- Native 方法:如果执行的是本地(Native)方法,计数器的值为空(Undefined)。
- 内存分布图:理解哪些区域是线程私有的(PC、虚拟机栈、本地方法栈),哪些是线程共享的(堆、方法区/元空间)。
【问题】并发编程的三个核心特性是什么?
【参考答案】
1. 原子性(Atomicity)
- 定义:一个或多个操作在执行过程中不被中断。要么全部执行成功,要么全部执行失败。
- 保证方式:
synchronized、Lock、原子类(AtomicInteger等)。
2. 可见性(Visibility)
- 定义:一个线程修改了共享变量的值,其他线程能够立即看到这个修改。
- 保证方式:
volatile关键字、synchronized、显式锁。 - 原因:CPU 缓存和 JMM(Java 内存模型)的本地内存机制。
3. 有序性(Ordering)
- 定义:程序执行的顺序应当按照代码的先后顺序。为了性能,编译器和处理器可能会进行指令重排序(Instruction Reordering)。
- 保证方式:
volatile(禁止指令重排)、synchronized、happens-before规则。
【延伸考点】
- JMM(Java 内存模型):理解主内存与线程工作内存的交互。
- happens-before 规则:是 JVM 提供的保证有序性的基本原则(如程序次序规则、锁定规则、volatile 变量规则等)。
【问题】Java 中常见的线程安全类有哪些?
【参考答案】
1. 早期的同步容器(已不推荐)
Vector/Hashtable:通过对每个方法加synchronized锁来实现线程安全。StringBuffer:线程安全的字符串拼接类(建议在单线程下使用StringBuilder)。
2. JUC 原子类(基于 CAS)
AtomicInteger/AtomicLong/AtomicReference:利用底层 CPU 的 CAS 指令实现无锁并发,性能极高。
3. JUC 并发容器
ConcurrentHashMap:高并发下的首选 Map。采用分段锁(JDK 7)或 Node 锁+CAS(JDK 8+)实现。CopyOnWriteArrayList:适合读多写少的场景。写操作会复制一份新数组,不影响读操作。BlockingQueue:如ArrayBlockingQueue、LinkedBlockingQueue。常用于生产者-消费者模型。
4. 同步包装器
Collections.synchronizedList/Map():将非线程安全的集合包装成线程安全的(内部使用互斥锁,性能一般)。
【延伸考点】
ConcurrentHashMap的演进:JDK 1.7 使用 Segment 分段锁;JDK 1.8 使用synchronized+ CAS,且引入了红黑树优化长链表。- 快速失败(Fail-Fast) vs 安全失败(Fail-Safe):普通集合在遍历时修改会抛出
ConcurrentModificationException,而并发容器通常支持安全失败。
死锁(Deadlock)
【问题】什么是死锁(Deadlock)?
【参考答案】
1. 定义 死锁是指两个或多个线程(进程)在执行过程中,因争夺共享资源而造成的一种相互等待的状态。如果没有外部干预,这些线程都将永远处于阻塞状态,无法继续推进。
2. 典型场景
- 线程 T1 持有锁 A,请求锁 B。
- 线程 T2 持有锁 B,请求锁 A。
- 结果:T1 等待 T2 释放锁 B,T2 等待 T1 释放锁 A,形成死循环。
【延伸考点】
- 死锁的诊断:使用
jstack命令可以自动检测到死锁。 - 资源剥夺:有些死锁可以通过抢占对方资源来强制破解,但这在 Java 线程中通常很难做到(锁不可剥夺)。
【问题】请手写一个简单的死锁示例,并说明原因。
【参考答案(示例代码)】
public class DeadlockTest {
private static final Object A = new Object();
private static final Object B = new Object();
public static void main(String[] args) {
new Thread(DeadlockTest::lockAThenB, "T1").start();
new Thread(DeadlockTest::lockBThenA, "T2").start();
}
static void lockAThenB() {
synchronized (A) {
System.out.println(Thread.currentThread().getName() + " 获取到 A 锁");
try {
Thread.sleep(500);
} catch (InterruptedException ignored) {}
synchronized (B) {
System.out.println(Thread.currentThread().getName() + " 获取到 B 锁");
}
}
}
static void lockBThenA() {
synchronized (B) {
System.out.println(Thread.currentThread().getName() + " 获取到 B 锁");
try {
Thread.sleep(500);
} catch (InterruptedException ignored) {}
synchronized (A) {
System.out.println(Thread.currentThread().getName() + " 获取到 A 锁");
}
}
}
}
- 线程 T1:先持有 A 再请求 B;线程 T2:先持有 B 再请求 A;
- 当 T1 拿到 A、T2 拿到 B 后,双方都在等待对方释放资源,形成循环等待,产生死锁。
【延伸考点】
- 调试死锁:使用
jstack或 IDE 线程分析工具查看线程堆栈与锁等待。 - 尽量避免嵌套锁,或在设计时统一加锁顺序。
【问题】如何预防和避免死锁?
【参考答案】
1. 破坏“循环等待”条件(最常用)
- 固定加锁顺序:所有线程都按照相同的顺序(如先 A 后 B)去获取锁,这样就不会出现 T1 拿 A 等 B、T2 拿 B 等 A 的情况。
2. 破坏“请求与保持”条件
- 一次性申请所有资源:在开始执行任务前,先尝试一次性获取所有需要的锁。
3. 破坏“不可剥夺”条件
- 使用超时锁:使用
ReentrantLock的tryLock(long time, TimeUnit unit)方法。如果尝试获取锁超时,则释放已持有的所有锁并稍后重试。
4. 降低锁的粒度
- 尽量不要在大代码块上加锁,只对必要的共享资源进行同步,减少发生死锁的概率。
【延伸考点】
- 银行家算法:操作系统中经典的死锁避免算法(通过计算资源分配后的安全性来决定是否分配)。
- 无锁编程:尽量使用原子类、线程本地变量(
ThreadLocal)或不可变对象来规避锁的使用。
【问题】产生死锁的四个必要条件是什么?
【参考答案】
- 互斥(Mutual Exclusion):资源在同一时刻只能被一个线程占用。
- 请求与保持(Hold and Wait):线程已经持有了至少一个资源,但又请求新的资源,而新资源已被其他线程占有。此时请求线程阻塞,但对已获得的资源保持不放。
- 不可剥夺(No Preemption):资源在被持有的过程中不能被强行剥夺,只能由持有者自愿释放。
- 循环等待(Circular Wait):存在一个线程等待链,每个线程都在等待下一个线程持有的资源,形成环路。
结论:只要破坏其中任何一个条件,死锁就不会发生。
同步与协作机制
【问题】Java 线程同步有哪些常见机制?
【参考答案】
1. 互斥锁(Mutex)
synchronized:JVM 提供的原生同步机制,支持方法级和代码块级锁定。ReentrantLock:JUC 包提供的显式锁,功能更强大(支持公平锁、可中断获取锁、多条件变量)。
2. 信号量(Semaphore)
- 用于控制同时访问特定资源的线程数量。常用于限流场景。
3. 屏障与倒计数器
CountDownLatch:让一个线程等待一组线程执行完后再继续(不可重用)。CyclicBarrier:让一组线程相互等待,直到所有线程都到达某个屏障点再一起继续(可重用)。
4. 线程协作
wait() / notify() / notifyAll():基于 Object 的监视器通信(必须在synchronized内部使用)。Condition:基于 Lock 的多条件变量通信。
【延伸考点】
- 同步 vs 异步:同步指调用者必须等待结果返回;异步指调用者触发后立即返回,通过回调或轮询获取结果。
- CAS(Compare And Swap):乐观锁的一种实现,JUC 原子类和并发集合的基础。
【问题】同步(Sync)和异步(Async)的区别?
【参考答案】
- 同步调用:
- 发出调用后,调用方在结果返回前一直等待,不能继续后续操作;
- 调用方与被调用方在“时间上强耦合”。
- 异步调用:
- 发出调用后,调用方可以立即返回,继续处理其他事情;
- 被调用方完成任务后,通过回调、事件、Future 等方式通知结果。
【延伸考点】
- 异步 + 非阻塞 I/O 在高并发系统中的应用(如 Netty、Reactor 模式)。
- 不要把“同步/异步”与“阻塞/非阻塞”混为一谈,它们是两个维度。
【问题】阻塞(Blocking)和非阻塞(Non-blocking)的区别是什么?
【参考答案】
1. 阻塞(Blocking)
- 行为:调用结果返回前,当前线程会被挂起。调用线程只有在得到结果之后才会继续执行。
- 场景:传统的
InputStream.read(),在没有数据可读时,线程会一直阻塞在那里。
2. 非阻塞(Non-blocking)
- 行为:如果不能立即得到结果,该调用不会阻塞当前线程,而是立即返回一个状态码或错误。
- 场景:NIO(New I/O)中的通道读取。如果没有数据,它会立即返回 0,线程可以去做其他事情,稍后再回来检查。
【延伸考点】
- 同步/异步 vs 阻塞/非阻塞:
- 同步/异步关注的是消息通信机制(调用者是否主动等待结果)。
- 阻塞/非阻塞关注的是程序在等待调用结果时的状态(线程是否被挂起)。
- I/O 多路复用(select/poll/epoll):是现代高性能网络编程(如 Netty, Redis)实现非阻塞的核心技术。
线程唤醒与阻塞
【问题】sleep() 和 wait() 的区别是什么?
【参考答案】
1. 来源不同
sleep():属于Thread类的静态方法。wait():属于Object类的方法(这意味着所有 Java 对象都有这个方法)。
2. 锁释放行为(核心区别)
sleep():不会释放锁。线程休眠期间,其他线程依然无法进入同步代码块。wait():会释放锁。线程进入等待池,允许其他线程获取锁。
3. 使用条件
sleep():可以在任何地方使用。wait():必须在同步块(synchronized)内部使用,否则会抛出IllegalMonitorStateException。
4. 唤醒方式
sleep():指定时间到期后自动苏醒。wait():需要由其他线程调用同一个对象的notify()或notifyAll()来唤醒。
【延伸考点】
- 为什么
wait()放在Object里? 因为 Java 的锁是对象级别的(Monitor),wait()需要释放的是对象锁,因此作为Object的方法更符合逻辑。 - 虚假唤醒(Spurious Wakeup):为了防止虚假唤醒,
wait()必须放在while循环中检查条件,而不是if中。
【问题】启动线程为什么调用 start() 而不是直接调用 run()?
【参考答案】
1. start() 方法
- 作用:通知 JVM 启动一个新的线程。
- 行为:JVM 会通过操作系统的底层指令创建新线程,并在新线程中执行该线程对象的
run()方法。这实现了真正的并发执行。
2. run() 方法
- 作用:只是一个普通的成员方法。
- 行为:如果直接调用
run(),它会在当前线程(通常是主线程)中顺序执行方法内的逻辑。这与调用普通 Java 对象的方法没有任何区别,不会启动新线程。
【延伸考点】
- 线程状态变化:调用
start()后,线程从 NEW 变为 RUNNABLE 状态。 - 重复调用:同一个线程对象的
start()方法只能被调用一次。重复调用会抛出IllegalThreadStateException。
【问题】导致线程阻塞的方法有哪些?
【参考答案】
1. Thread.sleep(ms)
- 使线程休眠指定时间,不释放锁。
2. Object.wait()
- 使线程进入等待状态,释放持有的对象锁。
3. Thread.join()
- 等待目标线程执行结束。本质上是通过目标线程对象的
wait()方法实现的。
4. LockSupport.park()
- 挂起当前线程。不需要持有锁即可调用。
5. 阻塞式 I/O
- 如
Socket.read(),在没有数据到达时,线程会被操作系统挂起。
6. 获取锁失败
- 进入
synchronized块或调用lock.lock()时,如果锁被占用,线程会进入阻塞状态(BLOCKED 或 WAITING)。
【延伸考点】
- 如何恢复? 对应的操作分别是:时间到期、
notify()、任务结束、unpark()、数据到达、获取到锁。
【问题】什么是上下文切换(Context Switch)?
【参考答案】
1. 定义 在多线程环境下,CPU 会通过时间片轮转(Round Robin)机制让多个线程交替执行。当 CPU 从一个线程切换到另一个线程执行时,这个过程就称为上下文切换。
2. 核心步骤
- 保存现场:保存当前线程的执行状态(寄存器、程序计数器等)。
- 恢复现场:加载目标线程的执行状态。
3. 对性能的影响 上下文切换是有开销的。频繁的切换会消耗大量的 CPU 时间,降低系统的有效吞吐量。
【延伸考点】
- 如何减少上下文切换?
- 减少线程数量:避免创建过多的线程,建议使用线程池。
- 使用 CAS 算法:减少不必要的锁竞争导致的线程挂起。
- 协程(Coroutine):在用户态进行切换,开销远小于内核态的线程切换。
- 过多线程、锁竞争、过细粒度任务可能导致上下文切换频繁。
- 使用合适的线程池大小、减少不必要的线程创建有助于降低切换成本。
线程池(ThreadPool)
【问题】为什么要使用线程池?
【参考答案】
1. 降低资源消耗 通过重用已创建的线程,降低线程创建和销毁造成的性能开销。
2. 提高响应速度 当任务到达时,任务可以不需要等到线程创建就能立即执行。
3. 提高线程的可管理性 线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
4. 提供更强大的功能 线程池具备可拓展性,允许添加更多功能,比如延时定时执行任务、监控任务状态等。
【延伸考点】
- 线程池的三个重要参数:核心线程数、最大线程数、工作队列。
- 资源限制:如果线程池配置不当(如队列过长),可能会导致内存溢出(OOM)。
【问题】线程池中的 execute() 和 submit() 有什么区别?
【参考答案】
1. 返回值
execute():没有返回值。submit():返回一个Future对象,可以通过它获取任务执行的结果(future.get())。
2. 任务类型
execute():只能接收Runnable类型的任务。submit():既可以接收Runnable,也可以接收Callable类型的任务。
3. 异常处理
execute():如果任务执行中抛出异常,线程会直接崩溃(如果是ThreadPoolExecutor会重新创建一个线程),异常信息会打印到控制台。submit():任务抛出的异常会被捕获并封装在Future中,只有当调用future.get()时才会抛出。
【延伸考点】
- 如何选择? 如果不需要获取结果,且不希望异常被吞掉,用
execute();如果需要结果,或者需要更精细地控制异常,用submit()。
【问题】如何优雅地终止线程池?
【参考答案】
1. shutdown() 方法
- 作用:启动有序关闭。
- 行为:线程池不再接受新任务,但会继续处理已提交到队列中的任务。当所有任务执行完成后,线程池正式关闭。
- 特点:这是一种“平滑”的关闭方式,不会导致正在处理的任务中断。
2. shutdownNow() 方法
- 作用:启动强制关闭。
- 行为:线程池不再接受新任务,并尝试中断正在执行的任务,同时丢弃队列中等待的任务(并返回这些未执行的任务列表)。
- 特点:这是一种“快速”的关闭方式,但要求任务代码能够响应中断信号,否则可能无法立即停止。
3. awaitTermination() 方法
- 作用:检测关闭状态。
- 行为:阻塞当前线程,等待线程池完成关闭,或者达到指定的超时时间。
- 场景:通常配合
shutdown()使用,用于确保在主流程继续之前线程池已经彻底清理完毕。
【延伸考点】
- 最佳实践(两阶段关闭):先调用
shutdown(),然后调用awaitTermination()等待一段时间。如果超时仍未关闭,再调用shutdownNow()强制终止。 - 任务中断支持:为了让
shutdownNow()生效,业务代码中必须正确处理InterruptedException或定期检查Thread.currentThread().isInterrupted()。
【问题】如何创建线程池?为什么不推荐直接用 Executors?
【参考答案】
1. 推荐创建方式
- 显式使用
ThreadPoolExecutor:这是《阿里巴巴 Java 开发手册》强制要求的做法。 - 核心理由:通过构造函数明确指定核心线程数、最大线程数、工作队列类型、拒绝策略等参数,能够让开发人员清楚地知道线程池的运行规则,规避隐藏的资源耗尽风险。
2. 为什么不推荐直接用 Executors?
FixedThreadPool/SingleThreadExecutor的风险:- 问题:它们底层使用了
LinkedBlockingQueue,其默认容量为Integer.MAX_VALUE。 - 后果:在高并发场景下,如果任务处理速度慢,请求会不断堆积在队列中,导致内存溢出(OOM)。
- 问题:它们底层使用了
CachedThreadPool/ScheduledThreadPool的风险:- 问题:它们的
maximumPoolSize设置为Integer.MAX_VALUE。 - 后果:会尝试创建大量的线程,导致 CPU 占用过高或直接抛出
OutOfMemoryError(由于无法创建更多本地线程)。
- 问题:它们的
【延伸考点】
- 线程池核心三要素:线程数、队列类型、拒绝策略。这三者共同决定了系统的吞吐量和稳定性。
- 动态化配置:在生产实践中,建议将线程池核心参数(如
corePoolSize)接入动态配置中心(如 Apollo、Nacos),支持在不重启服务的情况下实时调整性能。 - 监控报警:应定期监控线程池的活跃线程数、队列积压程度、拒绝策略触发次数,并设置相应的阈值报警。
【问题】ThreadPoolExecutor 构造函数重要参数有哪些?分别代表什么?
【参考答案】
1. 核心参数详解
corePoolSize(核心线程数):线程池维护的最小线程数量。即使这些线程处于空闲状态,也不会被回收(除非设置了allowCoreThreadTimeOut)。maximumPoolSize(最大线程数):线程池允许创建的最大线程数量。当工作队列满且已创建线程数小于此值时,会创建新线程执行任务。keepAliveTime(空闲存活时间):当线程数大于corePoolSize时,多余的空闲线程在终止前等待新任务的最长时间。unit(时间单位):keepAliveTime的时间单位(如TimeUnit.SECONDS)。workQueue(任务队列):用于保存等待执行任务的阻塞队列(如ArrayBlockingQueue、LinkedBlockingQueue)。threadFactory(线程工厂):用于创建新线程的工厂。可以通过它为线程设置有意义的名字,方便线上排查问题。handler(拒绝策略):当线程池和队列都满了,对新提交任务的处理策略(如AbortPolicy)。
2. 线程池任务提交流程(重要)
- Step 1:如果当前运行的线程数少于
corePoolSize,则直接创建新线程执行任务。 - Step 2:如果运行线程数大于等于
corePoolSize,则尝试将任务放入workQueue。 - Step 3:如果
workQueue已满,且运行线程数少于maximumPoolSize,则创建非核心线程执行任务。 - Step 4:如果线程数已达到
maximumPoolSize且队列已满,则触发handler拒绝策略。
【延伸考点】
allowCoreThreadTimeOut(true):默认情况下核心线程不会被回收,开启此配置后,核心线程在空闲超过keepAliveTime后也会被回收,适用于资源敏感的非核心业务场景。- 线程池预热:可以使用
prestartAllCoreThreads()方法在任务到达前就启动所有核心线程,减少首次任务执行的延迟。
【问题】ThreadPoolExecutor 的拒绝策略有哪些?
【参考答案】
1. AbortPolicy(中止策略)
- 行为:直接抛出
RejectedExecutionException异常。 - 特点:这是线程池的默认策略。它能够让调用者立即知道任务提交失败,从而进行相应的处理(如重试或记录日志)。
2. CallerRunsPolicy(调用者运行策略)
- 行为:由提交任务的线程(调用
execute的那个线程)来执行该任务。 - 特点:这种策略既不会丢弃任务,也不会抛出异常。它能有效降低任务提交的速度(因为调用线程被占去执行任务了),起到一种负反馈调节的作用。但要注意,如果调用线程是主线程,可能会导致主流程阻塞。
3. DiscardPolicy(丢弃策略)
- 行为:直接静默丢弃新提交的任务,不抛出任何异常。
- 特点:风险较高,除非业务场景允许任务丢失(如某些不重要的日志记录),否则不建议使用。
4. DiscardOldestPolicy(弃老策略)
- 行为:丢弃队列中最前面的(即最旧的)任务,然后尝试重新提交当前任务。
- 特点:适用于对实时性要求较高的场景,即“比起旧数据,我更在乎新数据”。
【延伸考点】
- 自定义拒绝策略:通过实现
RejectedExecutionHandler接口,可以自定义处理逻辑。例如:将任务持久化到数据库、发送告警邮件、或者放入一个自定义的备用队列中。 - 线上最佳实践:无论选择哪种策略,建议都要在策略触发时打印一条包含线程池关键指标(如当前线程数、队列长度等)的告警日志,方便事后分析。
【问题】如何合理设置线程池参数?
【参考答案】
1. 区分任务类型
- CPU 密集型(Calculation Intensive):
- 特点:任务主要进行逻辑运算、加解密、压缩等,对 CPU 资源消耗极高。
- 设置建议:线程数 = CPU 核心数 + 1。
- 理由:额外的 “+1” 是为了防止线程偶发的页缺失(Page Fault)或其他原因导致的中断,此时多出的一个线程可以顶上,确保 CPU 始终满载。
- I/O 密集型(I/O Intensive):
- 特点:任务涉及大量网络请求、磁盘读写、数据库操作等,线程大部分时间处于等待状态。
- 设置建议:线程数 = 2 × CPU 核心数 或更高(如 50~100)。
- 理由:由于 CPU 在等待 I/O 时是闲置的,可以配置更多线程来充分利用 CPU 资源。
2. 进阶估算公式 在实际生产中,更科学的计算公式为:线程数 = CPU 核心数 × CPU 利用率 × (1 + 等待时间/计算时间)
- 等待时间:线程处于非运行状态的时间(如等待数据库返回数据)。
- 计算时间:线程实际占用 CPU 执行逻辑的时间。
【延伸考点】
- 动态调整是王道:理论公式只能提供一个参考起点。真实场景下,必须通过压测(Load Test)观察系统的响应时间(RT)和吞吐量(TPS),结合监控指标(如 CPU 使用率、Load)来动态调整。
- 资源隔离:建议为不同的业务逻辑(如发送短信、处理订单)创建独立的线程池,避免某个耗时业务把整个系统的公共线程池撑爆,实现故障隔离。
- 获取核心数:Java 中通过
Runtime.getRuntime().availableProcessors()获取,但要注意在 Docker 容器环境下可能获取的是宿主机的核心数(Java 8u191 以后已修复此问题)。
【问题】线程池中的阻塞队列有哪些?各自特点是什么?
【参考答案】
1. ArrayBlockingQueue
- 特点:基于数组实现的有界阻塞队列,按照 FIFO(先进先出)原则排序。
- 性能:必须在创建时指定容量。内部使用单个锁(
ReentrantLock)来控制生产者和消费者的并发访问。 - 场景:适用于能够预估任务量、需要强制限流以保护系统的场景。
2. LinkedBlockingQueue
- 特点:基于链表实现的阻塞队列,同样遵循 FIFO 原则。
- 风险:如果不指定容量,默认值为
Integer.MAX_VALUE(接近无界)。在高并发下容易导致任务堆积,引发 OOM。 - 性能:内部使用了两个独立的锁(
takeLock和putLock),使得生产者和消费者可以并行操作,吞吐量通常高于ArrayBlockingQueue。 - 场景:
FixedThreadPool和SingleThreadExecutor默认使用此队列。
3. SynchronousQueue
- 特点:一个不存储元素的阻塞队列。每个插入操作必须等待一个移除操作,反之亦然。
- 性能:吞吐量极高,因为它直接在线程间传递任务,省去了入队出队的开销。
- 场景:适用于“直接移交”的任务模型。
CachedThreadPool默认使用此队列,能够根据压力快速快速切换或创建新线程。
4. PriorityBlockingQueue
- 特点:支持优先级的无界阻塞队列。元素按照其自然顺序或指定的
Comparator进行排序。 - 注意:由于是无界队列,任务处理速度跟不上提交速度时,可能会导致内存耗尽(OOM)。
【延伸考点】
- 有界 vs 无界:在生产环境中,强烈建议使用有界队列。无界队列虽然能缓冲瞬间的高并发,但本质是将压力转移到了内存,容易导致系统因 OOM 崩溃。
- 延迟队列(DelayQueue):也是一种阻塞队列,其中的元素只有在延迟期满时才能被提取。常用于定时任务调度、缓存失效等场景。
- 选择策略:
- 追求高吞吐量 ->
LinkedBlockingQueue(务必指定容量)。 - 低延迟、直接移交 ->
SynchronousQueue。 - 需要优先级调度 ->
PriorityBlockingQueue。
- 追求高吞吐量 ->
【问题】Java 线程池底层是如何实现的?
【参考答案】
Java 线程池的核心实现类是 ThreadPoolExecutor。其底层设计巧妙地结合了状态控制、工作线程复用、阻塞队列以及拒绝策略:
1. 状态与数量控制(ctl)
- 核心设计:线程池使用一个名为
ctl的AtomicInteger变量来同时维护两个信息:- 高 3 位:表示线程池的运行状态(RUNNING, SHUTDOWN, STOP, TIDYING, TERMINATED)。
- 低 29 位:表示线程池中当前有效的工作线程数量。
- 优势:通过一个原子变量完成状态和数量的同步更新,极大地提升了并发性能。
2. 工作线程(Worker)
- 内部结构:线程池维护了一个
HashSet<Worker> workers集合。 - 双重身份:
Worker类既实现了Runnable接口,又继承了AQS。- 继承 AQS:是为了利用其锁机制,在执行任务时加锁,确保线程在处理任务期间不会被中断(除非调用了
shutdownNow)。 - 实现 Runnable:每个
Worker启动后会执行其run()方法。
- 继承 AQS:是为了利用其锁机制,在执行任务时加锁,确保线程在处理任务期间不会被中断(除非调用了
3. 核心运行逻辑(runWorker)
当通过 execute() 提交任务后,Worker 会进入一个无限循环,不断执行以下逻辑:
- 执行当前任务:如果
firstTask不为空,则直接执行。 - 获取队列任务:如果
firstTask为空,则调用getTask()从阻塞队列中take()(核心线程阻塞等待)或poll()(非核心线程限时等待)下一个任务。 - 退出与回收:如果
getTask()返回 null(如超时或线程池关闭),Worker会安全地退出循环并从workers集合中移除。
【延伸考点】
- Worker 为什么要继承 AQS? 主要是为了实现不可重入锁。这样在线程池管理操作(如
interruptIdleWorkers)中,可以通过tryLock()判断该线程是否正在执行任务,从而避免中断正在运行中的任务。 - getTask() 的重要性:它是线程池能够复用线程且能回收空闲线程的核心所在。在这里实现了
keepAliveTime的超时逻辑。 - 线程池的 5 种状态转换:了解 RUNNING -> SHUTDOWN -> STOP -> TIDYING -> TERMINATED 的流转条件。
【问题】Java 中常见的线程池实现及其区别?
【参考答案】
通过 Executors 工具类可以快速创建多种预定义配置的线程池。虽然生产环境不推荐直接使用,但了解它们的区别对理解线程池运行机制至关重要:
1. FixedThreadPool(固定大小线程池)
- 特点:核心线程数与最大线程数相等。
- 实现:使用
LinkedBlockingQueue(无界队列)作为任务缓冲区。 - 风险:由于队列无界,当任务处理速度跟不上提交速度时,任务会无限堆积,最终导致 OOM (OutOfMemoryError)。
- 场景:适用于负载较重且相对稳定的服务器环境。
2. SingleThreadExecutor(单线程池)
- 特点:只有一个核心线程(且不可扩展)。
- 实现:同样使用
LinkedBlockingQueue(无界队列)。 - 风险:与
FixedThreadPool一样,存在 OOM 风险。 - 场景:适用于需要保证任务按顺序执行(FIFO/LIFO/优先级)的场景。
3. CachedThreadPool(可缓存线程池)
- 特点:核心线程数为 0,最大线程数为
Integer.MAX_VALUE。 - 实现:使用
SynchronousQueue(直接移交队列)。 - 风险:由于最大线程数几乎无上限,在瞬时高并发下会疯狂创建新线程,导致 CPU 占用过高或耗尽内存。
- 场景:适用于执行大量短期、高频且耗时极短的小任务。
4. ScheduledThreadPool(定时线程池)
- 特点:核心线程数固定,最大线程数无限制。
- 实现:使用
DelayedWorkQueue存储任务。 - 场景:适用于执行周期性任务或需要延迟执行的场景。
【延伸考点】
- 为什么不推荐使用
Executors?:阿里巴巴开发手册强制规定,必须通过ThreadPoolExecutor手动创建线程池。核心原因在于Executors的默认参数(无界队列或无限线程)隐藏了系统资源耗尽的巨大风险。 - 线程池选型:在生产中,我们通常会根据 CPU 核心数和任务类型(CPU 密集型 vs I/O 密集型)来显式配置
corePoolSize和workQueue的大小。 - ForkJoinPool:Java 7 引入的一种特殊的线程池,采用“工作窃取(Work-Stealing)”算法,特别适合处理递归拆分的小任务(分治算法)。
【问题】如何在 Java 线程池中提交任务?execute() 和 submit() 有什么区别?
【参考答案】
在 Java 线程池中,提交任务主要有两种方式:execute() 和 submit()。它们在返回值、异常处理和任务类型上存在显著区别:
1. execute() 方法
- 任务类型:只能接收
Runnable类型的任务。 - 返回值:没有返回值(void),调用后无法得知任务是否执行成功。
- 异常处理:如果任务在执行过程中抛出未捕获的异常,线程会直接终止,异常堆栈信息会打印到控制台。线程池会检测到线程死亡并创建一个新线程来替换它。
2. submit() 方法
- 任务类型:既可以接收
Runnable,也可以接收Callable类型的任务。 - 返回值:返回一个
Future<?>对象。通过该对象可以获取任务执行的结果(future.get())或判断任务是否完成(future.isDone())。 - 异常处理:任务执行中抛出的异常会被线程池捕获并封装在
Future中。只有当调用者执行future.get()时,才会抛出ExecutionException。这意味着如果不检查返回值,异常可能会被“吞掉”。
3. 核心区别对比表
| 特性 | execute() |
submit() |
|---|---|---|
| 所属接口 | Executor |
ExecutorService |
| 参数类型 | Runnable |
Runnable / Callable |
| 返回值 | void |
Future<?> |
| 异常感知 | 直接抛出到控制台 | 封装在 Future 中,需调用 get() 获取 |
【延伸考点】
- Future 的阻塞性:调用
future.get()是一个阻塞操作,如果任务未完成,调用线程会一直等待。建议使用带超时的版本future.get(timeout, unit)。 - CompletableFuture:Java 8 引入的增强版
Future,支持异步回调、任务编排等功能,解决了传统Future难以手动触发回调的问题。 - 异常处理最佳实践:在
submit提交的任务内部,建议使用try-catch显式捕获并记录日志,避免异常被无声无息地忽略。
原子类CAS
【问题】介绍一下 Atomic 原子类?
【参考答案】
1. 基本定义
- 原子性更新:Atomic 原子类位于
java.util.concurrent.atomic包下,提供了一组能够在多线程环境下进行无锁(Lock-free)原子操作的工具类。 - 核心原理:主要依赖 CAS(Compare And Swap) 乐观锁机制、volatile 关键字(保证可见性)以及 CPU 层面的原子指令(如
cmpxchg)。
2. 常见分类
- 基本类型:
AtomicInteger、AtomicLong、AtomicBoolean。用于对单个基本变量进行原子增减或设置。 - 数组类型:
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray。可以原子地更新数组中的特定索引元素。 - 引用类型:
AtomicReference:原子更新引用类型。AtomicStampedReference:带版本号的引用,用于解决 ABA 问题。AtomicMarkableReference:带标记位的引用。
- 字段更新器:
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater。利用反射机制,原子地更新某个类中被volatile修饰的字段,节省了创建原子对象本身的内存开销。
3. 核心优势
- 性能优越:在竞争不激烈的情况下,相比
synchronized重量级锁,原子类通过自旋重试避免了线程上下文切换的开销。 - 使用简便:提供了丰富的 API(如
incrementAndGet),代码更加简洁易读。
【延伸考点】
- 适用场景:适用于计数器、序列号生成、布尔标记位更新等临界区极小的场景。
- 性能瓶颈:在高并发热点竞争下,CAS 会频繁失败并陷入自旋(死循环),导致 CPU 占用过高。
- LongAdder 的演进:Java 8 引入了
LongAdder,通过“分段累加”的思想减少了高并发下的竞争冲突,在纯计数场景性能远超AtomicLong。
【问题】介绍下 AtomicInteger 的使用与常见方法?
【参考答案】
1. 常用核心方法
- 读取与设置:
get():获取当前值(具有volatile读语义)。set(newValue):设置新值(具有volatile写语义)。
- 原子更新(返回新值/旧值):
incrementAndGet()/getAndIncrement():原子自增 1。decrementAndGet()/getAndDecrement():原子自减 1。addAndGet(delta)/getAndAdd(delta):原子增加指定增量。
- 条件更新:
compareAndSet(expect, update):核心方法。如果当前值等于期望值expect,则原子更新为update。成功返回true。
- 复杂更新(Java 8+):
updateAndGet(IntUnaryOperator):通过函数式编程接口,实现更复杂的原子更新逻辑。
- 弱内存语义设置:
lazySet(newValue):最终会设置成功,但允许短时间内其他线程看不到。性能高于set(),因为它减少了内存屏障(Store-Load)的开销。
2. 代码示例
class AtomicCounter {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
// 相当于 count++
count.incrementAndGet();
}
public boolean compareAndSwap(int expect, int update) {
// 只有当前值是 expect 时才更新为 update
return count.compareAndSet(expect, update);
}
public int getCount() {
return count.get();
}
}
【延伸考点】
volatile语义:AtomicInteger内部通过一个volatile int value字段来保证变量在线程间的可见性。lazySet的原理:它使用的是StoreStore屏障,而不是代价更高的StoreLoad屏障。这在某些对实时性要求不高、但对性能极其敏感的队列实现(如 LMAX Disruptor)中非常有用。- CAS 自旋:
getAndIncrement等方法底层是一个do-while循环,直到 CAS 成功为止。如果竞争剧烈,会导致循环次数增加,消耗 CPU。
【问题】AtomicInteger 的 getAndIncrement 用到 CAS,原理是什么?
【参考答案】
1. CAS 核心机制
- 定义:CAS 全称 Compare And Swap(比较并交换),是一种实现并发算法时常用的乐观锁技术。
- 三个操作数:
- V (Value):内存中的当前实际值。
- A (Address/Expect):预期原值(旧值)。
- B (Update):拟写入的新值。
- 执行逻辑:当且仅当 V == A 时,处理器会自动将 V 更新为 B。否则,处理器不做任何操作。无论哪种情况,它都会返回 V 的原始值(或返回是否成功的布尔值)。
2. getAndIncrement 的实现流程
- 读取:从内存中读取当前值
A。 - 计算:计算目标值
B = A + 1。 - 尝试更新:调用 CAS 指令,尝试将内存值从
A改为B。 - 自旋(Spin):如果失败(说明有其他线程修改了值),则重新回到第一步进行循环重试,直到成功为止。
3. 底层硬件支持
- 在 Java 中,CAS 是通过
sun.misc.Unsafe类提供的原生(native)方法实现的。 - 在 CPU 层面,这对应着一条原子指令(如 x86 架构下的
LOCK CMPXCHG),由硬件保证了“比较并交换”过程的原子性,不会被中途打断。
【延伸考点】
- 乐观锁思想:CAS 假设竞争不激烈,因此不加锁直接尝试更新。这种无锁化设计避免了线程挂起和恢复的开销。
- Unsafe 类:它是 Java 留给开发者的“后门”,可以直接操作内存、挂起线程等,虽然强大但极其危险。
- VarHandle (Java 9+):Java 9 引入了
VarHandle作为Unsafe的更安全、更高效的替代方案,用于处理原子访问。
【问题】CAS 会带来什么问题?
【参考答案】
1. ABA 问题
- 现象:一个变量的值从 A 变为 B,随后又变回 A。此时 CAS 检查发现值仍为 A,从而误认为“该值从未被修改过”。
- 风险:在某些场景(如栈/队列的内存复用、指针操作)下,这会导致严重的逻辑错误。
- 对策:引入版本号(Version)或时间戳,将 A→B→A 变为 1A→2B→3A。
2. 自旋开销(CPU 性能损耗)
- 现象:在高并发、竞争激烈的环境下,多个线程同时尝试更新同一个变量。失败的线程会通过
do-while循环不断重试(自旋)。 - 风险:大量的无效自旋会占用极高的 CPU 时间片,导致系统有效吞吐量下降。
- 对策:使用
LongAdder(分段累加)或在长时间失败后挂起线程。
3. 只能保证单个共享变量的原子操作
- 现象:CAS 只能针对内存地址上的某一个变量进行原子操作。
- 风险:当需要同时更新多个共享变量(如“转账”操作涉及两个账号)时,CAS 无法保证跨变量的整体原子性。
- 对策:
- 将多个变量封装进一个对象,使用
AtomicReference。 - 改用
synchronized或ReentrantLock等传统锁机制。
- 将多个变量封装进一个对象,使用
【延伸考点】
- LongAdder 的原理:它是 Java 8 针对 CAS 高并发竞争瓶颈的优化,内部维护了一个
Cell数组,将竞争分散到不同的 Cell 上,最后求和。 - 悲观锁 vs 乐观锁:CAS 是典型的乐观锁思想(认为冲突少,先尝试再重试);锁是悲观锁思想(认为冲突多,先锁定再操作)。根据冲突频率选择合适的方案。
【问题】什么是 ABA 问题?如何解决?
【参考答案】
1. ABA 问题定义
- 现象描述:在 CAS 操作中,线程 1 读取到内存值为 A。此时线程 2 将该值修改为 B,随后又修改回 A。当线程 1 再次执行 CAS 时,发现值仍为 A,于是认为“期间没有任何修改”,并成功执行了更新。
- 核心风险:虽然数值没变,但对象的状态或属性可能已经发生了变化。例如在栈或链表中,A 节点虽然还在,但其指向的后续节点(Next)可能已被替换,导致结构被破坏(著名的 A-B-A 悬挂指针问题)。
2. 解决方案:版本号机制
- 核心思想:通过引入一个递增的版本号(或时间戳),让 A 节点的每次修改都留下“痕迹”。比较时不仅比对数值,还比对版本号。
- Java 实现:
AtomicStampedReference:最常用的解决方案。内部维护了一个Pair对象,包含reference(数据引用)和stamp(整数版本号)。只有当引用和版本号同时匹配时,CAS 才会成功。AtomicMarkableReference:简化版。内部使用一个boolean标记位来记录“是否被修改过”。适用于只关心“变没变过”而不关心“变了几次”的场景。
【延伸考点】
- ABA 是否一定是问题? 不一定。在简单的数值累加(如
AtomicInteger)场景中,ABA 通常不会影响最终结果。但在涉及内存管理(如无锁队列的节点复用)或状态机转换时,ABA 则是致命的。 - 性能权衡:
AtomicStampedReference每次更新都需要创建新的Pair对象,这会增加 GC 压力。因此,在不敏感的场景下,可以容忍 ABA 以换取更高性能。
【问题】 在秒杀活动中,商品数量可以用atomicInteger吗,如果调用CAS的方法compareAndSet(expect, update)时传入的期望值是5,更新值是4。但是因为是秒杀活动,业务是用多线程处理的,假设已经有线程把商品数量改为了4,那本线程的compareAndSet岂不是会一直循环?
【参考答案】
可以用AtomicInteger实现秒杀库存扣减,但需要正确编写CAS逻辑,并且要理解CAS在并发下的行为。你描述的情况正是CAS的典型工作方式:当多个线程同时尝试更新库存时,只有其中一个能成功将值从5改为4,其他线程会发现当前值已经不是期望的5(而是4),于是compareAndSet返回false。这些失败的线程通常会采用自旋重试(即循环不断尝试直到成功),而不会“一直循环”下去,因为每次重试都会重新获取当前库存值,并判断库存是否还有剩余。如果库存变为0,则线程可以退出循环,返回库存不足。因此,只要正确实现,就不会出现无限循环。
关键点:
- 在秒杀场景下,库存是递减的,不会出现ABA问题(即值从A变成B再变回A的情况,因为库存只减不增)。
- 通常我们会编写类似下面的代码:
public boolean decreaseStock(int stockId, int delta) { AtomicInteger stock = stockMap.get(stockId); while (true) { int current = stock.get(); //当前数量小于要扣减的数量,直接返回false if (current < delta) { return false; // 库存不足,退出 } int newValue = current - delta; if (stock.compareAndSet(current, newValue)) { return true; // 扣减成功 } // 否则循环重试 } }这样,当库存变为4后,其他线程会看到current=4,如果它们期望扣减1,则newValue=3,然后执行CAS(期望4,设为3),只有一个线程能成功,其余继续循环。循环次数有限,因为库存总量有限,且每次成功都会减少库存。
为什么不会无限循环?
- 因为每次循环都会重新读取最新库存,当库存被扣减到0后,所有后续线程都会因
current < delta而直接返回false,不再尝试CAS。 - 即使在极端并发下,CAS自旋的次数也有限,通常不会造成CPU过大压力(除非库存极大且并发极高,但秒杀场景库存一般较小)。
优点:
- 轻量级,无需锁,利用CPU的CAS指令,性能高。
- 适合单机环境下的高并发扣减。
缺点与注意事项:
- 自旋消耗CPU:如果库存较大且竞争激烈,大量线程可能空转,但秒杀库存通常较小,影响可接受。
- 仅限于单JVM:如果秒杀系统是分布式的(多台服务器),则AtomicInteger无法跨进程同步,需要使用分布式锁或Redis原子操作。
- 需处理ABA问题:对于只减不增的业务,ABA不影响结果,但如果业务复杂(如库存可能增加),则需要考虑。
改进方案:
- 使用
LongAdder或LongAccumulator等高并发计数器,但它们是用于统计而非精确扣减。 - 在分布式环境中,使用Redis的
DECR或Lua脚本实现原子扣减,或使用数据库乐观锁。 - 使用
AtomicInteger的updateAndGet方法简化代码:stock.updateAndGet(s -> { if (s < delta) throw new RuntimeException("库存不足"); return s - delta; });但需注意异常处理。
【大白话解释于举例说明】 想象你正在抢购一个限量5个的杯子,大家都在手机上点“抢购”。服务器里的库存就是一个数字(AtomicInteger)。你的请求到达时,服务器会执行一个“检查-更新”操作:
- 先看库存:当前是5(期望值)。
- 然后尝试改为4(新值)。这个操作是原子性的,如果在你执行期间没人改过,你就成功。
- 如果在你检查库存的瞬间,别人已经改成了4,那么你的“检查-更新”就会失败,因为当前库存已经是4而不是你期望的5。
- 失败后,你的手机会自动重试(循环):再读一次库存,现在看到是4,如果4大于等于你需要的数量(比如你只需要1个),就尝试改为3。如此反复,直到成功或者发现库存不够了。
这个过程就像大家轮流喊“我要改库存”,谁喊的时候值正好是他看到的那个数,谁就成功。失败了就重新喊一次,直到成功或发现没货了。这种机制保证了数据的一致性,并且不会出现两个人同时买到最后一件的情况。
【扩展知识点详解】
-
CAS原理:CAS(Compare-And-Swap)是硬件层面的原子指令,包含三个操作数:内存位置V、期望值A、新值B。当且仅当V的值等于A时,才将V更新为B,否则不做任何操作。整个过程是原子的。Java中的
AtomicInteger等类封装了CAS操作。 -
ABA问题:如果变量值从A变成B再变回A,那么CAS会误认为它没有变化而成功更新。在秒杀库存递减场景下,值只会减少,不会增加,所以不存在ABA问题。但如果业务中有增减操作(如库存退还),则需要通过版本号或
AtomicStampedReference来解决。 -
自旋开销与优化:高并发下大量CAS失败会导致CPU空转,称为“自旋”。如果自旋时间过长,会浪费CPU。可以通过
Thread.yield()或LockSupport.parkNanos()短暂休眠来降低竞争,但秒杀场景库存小,通常无需优化。 - 分布式秒杀方案:
- 使用Redis:将库存存储在Redis中,利用
DECR或Lua脚本保证原子性。例如:local stock = redis.call('get', KEYS[1]) if stock and tonumber(stock) > 0 then redis.call('decr', KEYS[1]) return 1 end return 0 - 使用数据库行锁:
UPDATE stock SET count = count - 1 WHERE id = ? AND count > 0,但性能较低。 - 使用ZooKeeper等分布式协调服务,但性能不如Redis。
- 使用Redis:将库存存储在Redis中,利用
-
乐观锁 vs 悲观锁:AtomicInteger属于乐观锁(无锁编程),假设冲突少,失败重试。秒杀是典型的写冲突激烈场景,但乐观锁通过CAS仍然可行,因为库存有限,最终成功线程数等于库存数。
-
AtomicInteger的局限性:它只能保证单个变量的原子操作,无法保证多个操作(如先扣库存再生成订单)的整体原子性,此时需要结合事务或分布式锁。 -
性能对比:在单机高并发下,CAS比
synchronized锁性能高,因为CAS是硬件级别的无锁操作,而锁涉及线程上下文切换。但在冲突极高时,CAS的自旋开销可能超过锁,需根据实际压测选择。 - Java 8中的
LongAdder:适用于统计场景,它通过分段减少竞争,但无法保证精确的减操作,因为它的值是近似值,不适合库存扣减。
综上所述,在单机秒杀场景中,使用AtomicInteger配合正确自旋逻辑是完全可行的,但需注意分布式环境下的局限性。
volatile
【问题】volatile 关键字有哪些特性?
【参考答案】
volatile 是 Java 虚拟机(JVM)提供的轻量级同步机制。它主要具备以下三大特性:
1. 保证可见性
- 现象:当一个线程修改了被
volatile修饰的变量值,其他线程能够立即感知到这一修改,并获取到最新的值。 - 原理:根据 JMM(Java 内存模型)的规定,对
volatile变量的写操作会强制将修改后的值刷新到主内存,并导致其他线程工作内存中对应的缓存行失效。其他线程在读取该变量时,必须重新从主内存中拉取。 - 底层:涉及 CPU 的缓存一致性协议(如 MESI 协议)。
2. 不保证原子性
- 现象:对于复合操作(如
i++),volatile无法保证操作的完整性。 - 原因:
i++实际上包含“读取、加一、写回”三个独立步骤。即使读取时是最新的,但在执行加一或写回时,其他线程可能已经修改了主内存的值。由于volatile没有加锁机制,无法阻止这种竞态条件的发生。 - 对策:对于原子性需求,应使用
AtomicInteger或synchronized。
3. 禁止指令重排序
- 现象:编译器和处理器为了优化性能,往往会调整指令的执行顺序。
volatile可以确保代码的执行顺序与程序员编写的顺序一致。 - 实现:通过插入内存屏障(Memory Barrier)来禁止特定类型的处理器重排序。
- 经典应用:在单例模式的双重检查锁(DCL)中,必须使用
volatile防止对象初始化过程中的指令重排。
【延伸考点】
- Happens-before 规则:
volatile变量规则规定,对一个volatile变量的写操作,总是先行发生(Happens-before)于后面对该变量的读操作。 - 内存屏障详解:
- 在写操作前插入
StoreStore屏障,写操作后插入StoreLoad屏障。 - 在读操作后插入
LoadLoad和LoadStore屏障。
- 在写操作前插入
- 与 synchronized 的区别:
volatile是线程同步的轻量级实现,性能更好,但不支持原子性。volatile只能修饰变量,而synchronized可以修饰方法和代码块。volatile不会造成线程阻塞,而synchronized可能会。
【问题】如何使用 volatile 实现单例模式的双重检查锁(DCL)?
【参考答案】
双重检查锁(Double-Check Locking)是实现单例模式的一种高效方式,其标准模板如下:
public class VolatileSingleton {
// 1. 必须使用 volatile 修饰,防止指令重排
private static volatile VolatileSingleton instance = null;
private VolatileSingleton() {}
public static VolatileSingleton getInstance() {
// 2. 第一重检查:避免不必要的同步开销
if (instance == null) {
synchronized (VolatileSingleton.class) {
// 3. 第二重检查:确保多线程环境下只创建一次实例
if (instance == null) {
instance = new VolatileSingleton();
}
}
}
return instance;
}
}
核心问题:为什么一定要加 volatile?
instance = new VolatileSingleton(); 这行代码在 JVM 中实际上分为三步执行:
- 分配内存空间(
memory = allocate();) - 初始化对象(
ctorInstance(memory);) - 将引用指向内存地址(
instance = memory;)
如果没有 volatile,JVM 为了优化性能可能会发生指令重排序(如执行顺序变为 1 -> 3 -> 2)。
- 风险场景:当线程 A 执行完第 3 步(指向地址)但尚未执行第 2 步(初始化)时,线程 B 进入
getInstance()。 - 后果:线程 B 在第一重检查时发现
instance != null,于是直接返回了该实例。但此时对象尚未初始化完成(是一个“半成品”),线程 B 使用该对象时就会抛出异常。 - 解决:
volatile通过插入内存屏障,禁止了上述指令重排,确保“初始化”一定发生在“指向地址”之前。
【延伸考点】
- DCL 的演进:早期的 Java 内存模型不完善,即使加了
volatile也可能失效,但在 Java 5 之后已彻底解决。 - 更优雅的替代方案:
- 静态内部类:利用类加载机制保证线程安全且实现懒加载。
- 枚举单例:天然防反射、防序列化破坏,是《Effective Java》作者推荐的写法。
- 局部变量优化:在一些高性能库中,常看到
VolatileSingleton temp = instance;这样的局部变量写法,可以减少对volatile变量的读取次数,略微提升性能。
【问题】如何通过代码验证 volatile 的可见性?
【参考答案】
1. 验证思路 通过一个简单的“标志位”实验:创建一个子线程循环读取共享变量,主线程在延迟一段时间后修改该变量。观察子线程是否能感知变化并退出循环。
2. 验证代码
class ShareData {
// 关键:如果不加 volatile,子线程可能会陷入死循环
volatile boolean flag = true;
public void stop() {
this.flag = false;
}
}
public class VolatileVisibilityTest {
public static void main(String[] args) {
ShareData data = new ShareData();
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 开始执行,等待 flag 变为 false...");
while (data.flag) {
// 如果没有 volatile,JIT 编译器可能会将此循环优化为 while(true)
// 因为它认为在当前线程内 flag 的值永远不会改变
}
System.out.println(Thread.currentThread().getName() + " 感知到了 flag 变化,顺利退出!");
}, "SubThread").start();
// 确保子线程已经启动并进入循环
try { Thread.sleep(1000); } catch (InterruptedException e) {}
data.stop();
System.out.println(Thread.currentThread().getName() + " 已将 flag 修改为 false");
}
}
3. 现象剖析
- 加了
volatile:主线程修改flag后,会强制刷新回主内存,并失效子线程的缓存。子线程下次读取时从主内存获取最新值false,循环终止。 - 不加
volatile:子线程可能会一直处于死循环。这是因为 JMM 允许线程在自己的工作内存中缓存变量,且 JIT 编译器为了优化性能,可能会认为flag在该循环中是不可变的,从而不再去主内存读取。
【延伸考点】
- 工作内存 vs 主内存:理解 JMM 的抽象结构,这是并发编程的理论基石。
- MESI 协议:在硬件层面,这涉及到 CPU 的缓存一致性协议。当一个核修改了数据,会通知其他核该数据所在的缓存行已失效。
- 打印语句的影响:注意在
while循环中如果加入System.out.println,可能会导致即便不加volatile也能退出循环。因为println内部有synchronized同步块,它会触发内存屏障,强制刷新内存。
【问题】为什么 volatile 不能保证原子性?如何验证?
【参考答案】
1. 原因剖析
volatile 仅保证了变量在线程间的可见性,但无法保证对变量操作的原子性。
以 i++ 为例,它在字节码层面实际上包含三个步骤:
- Read:从主内存读取
i的值到工作内存。 - Add:在工作内存中执行加 1 操作。
- Write:将修改后的值写回主内存。
- 即使
i被volatile修饰,如果线程 A 在执行完 Step 1 或 Step 2 时被挂起,线程 B 进入并完成了完整的三个步骤。当线程 A 恢复执行 Step 3 时,它会直接将自己工作内存中的旧值写回主内存,从而覆盖了线程 B 的修改,导致“丢失更新”。 - 那线程A在Step 3写入时,难道不会先检查主内存的最新值吗?不会。volatile的可见性保证是单向的,它只保证”写后立即对其他线程可见”,但不保证”写前读取最新值”。当线程B完成写入时,确实会使线程A工作内存中的i缓存行失效。但线程A已经在执行i++的中间状态,它的工作内存中保存的是读取时的快照(i=0)和计算后的结果(i=1)。线程A恢复执行时,只是简单地将工作内存中的i=1写回主内存,不会重新读取主内存来做校验或合并。
- AtomicInteger的秘诀在于:它不使用”读取-修改-写入”的分离模式,而是使用CPU原子的CAS(Compare-And-Swap)指令。
- 谁遵守JMM?—— 整个Java执行引擎;JMM(Java内存模型)是JVM规范定义的抽象规则,实际执行由JVM + 操作系统 + CPU 三层协同完成。
- 缓存行失效针对的是”缓存中的变量副本”,但线程A被挂起时,i的值已经加载到CPU寄存器中!JMM的缓存失效无法使寄存器中的值失效。线程A恢复执行时,直接从寄存器继续运算,根本不会再去检查缓存或主内存。
- JMM的缓存失效确实会被遵守,但它只能让”缓存中的副本”失效,不能让”CPU寄存器中的值”失效。线程被挂起恢复后,是从寄存器继续执行,而非重新读取缓存。这就是volatile不能保证原子性的根本原因。
2. 验证代码
public class VolatileAtomicityTest {
// 即使加了 volatile,最终结果也很难达到 20000
public static volatile int count = 0;
public static void add() {
count++;
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[20];
for (int i = 0; i < 20; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
add();
}
});
threads[i].start();
}
// 等待所有线程执行结束
for (Thread t : threads) {
t.join();
}
System.out.println("最终期望结果: 20000, 实际运行结果: " + count);
}
}
3. 解决方案
- 使用
synchronized:对add()方法加锁,确保同一时刻只有一个线程能执行i++。 - 使用原子类(推荐):改用
AtomicInteger,利用其底层的 CAS 机制保证原子性。
【延伸考点】
- 字节码分析:可以使用
javap -c命令查看i++对应的指令(getstatic,iadd,putstatic),直观感受其非原子性。 - 内存屏障的局限:
volatile插入的屏障只能保证读写的顺序 and 可见性,无法将多个指令打包成一个不可分割的原子单元。
【问题】volatile 是如何禁止指令重排的?其底层原理是什么?
【参考答案】
1. 核心手段:内存屏障(Memory Barrier)
volatile 禁止指令重排的核心底层原理是插入了内存屏障。内存屏障是一组特殊的 CPU 指令,它能够强制限制屏障前后的指令执行顺序,并确保内存数据的可见性。
2. 为什么需要禁止重排序?
- 编译器重排:编译器在不改变单线程语义的前提下,为了提高运行效率而调整指令顺序。
- 处理器重排:现代处理器采用乱序执行(Out-of-Order Execution)技术,利用并行的硬件资源来加速程序运行。
- 在多线程环境下,这种优化可能会破坏程序的逻辑一致性(如 DCL 单例中的“半成品”对象问题)。
3. JMM 的四种内存屏障策略
Java 内存模型(JMM)为 volatile 变量定义了极严苛的屏障插入策略:
- 写操作(Write):
- StoreStore 屏障:在
volatile写之前插入。确保屏障前的所有普通写操作已刷新到主内存。 - StoreLoad 屏障:在
volatile写之后插入。防止volatile写与后面可能有的volatile读/写重排序(这是代价最高、功能最全的屏障)。
- StoreStore 屏障:在
- 读操作(Read):
- LoadLoad 屏障:在
volatile读之后插入。确保屏障后的所有普通读操作都在volatile读之后执行。 - LoadStore 屏障:在
volatile读之后插入。确保屏障后的所有普通写操作都在volatile读之后执行。
- LoadLoad 屏障:在
【延伸考点】
- as-if-serial 语义:指的是不管怎么重排序,单线程程序的执行结果不能被改变。编译器和处理器必须遵守这一语义。
- Happens-before 规则:
volatile变量规则是其核心子规则之一。它规定:对一个volatile域的写,happens-before 于任意后续对这个volatile域的读。 - 硬件层面的实现:在 x86 架构下,JVM 常通过插入带
lock前缀的指令(例如lock addl $0,(%rsp)这类“空操作”)来提供接近全栅栏(尤其是 StoreLoad)的效果:保证写入对其他核尽快可见,并禁止与后续读写重排序;其同步依赖缓存一致性协议作用于相关缓存行,而不是“失效整块 Cache”。
【问题】既然 volatile 不保证原子性,为什么在并发编程中仍广泛使用?
【参考答案】
虽然 volatile 的功能不如 synchronized 全面,但由于其轻量级和无锁的特性,在特定场景下具有不可替代的优势:
1. 性能开销极低
volatile不会引起线程的阻塞和唤醒,也不涉及锁的竞争和上下文切换。- 它仅通过内存屏障和 CPU 缓存一致性协议来保证可见性和有序性,执行效率远高于
synchronized。
2. 核心应用场景
- 状态标记位:这是最经典、最广泛的用法。例如,一个工作线程通过检查
volatile boolean stop标志位来优雅地退出循环。 - 单例模式的双重检查锁(DCL):利用
volatile禁止指令重排,确保对象在多线程环境下被正确初始化(解决“半成品对象”问题)。 - 一写多读场景:当系统中只有一个线程负责更新某个变量(如配置参数),而多个线程负责读取时,
volatile能确保所有读线程始终看到最新值,且无需任何锁开销。
3. 使用限制(核心前提)
- 对变量的写操作不依赖当前值(例如
count++是依赖当前值的,而flag = true则不是)。 - 变量不参与其他状态变量的不变性约束。
【延伸考点】
- 开销对比:
volatile的写操作开销通常大于读操作,因为写操作需要触发 StoreLoad 屏障来刷新缓存。 - 读写分离策略:
volatile本质上提供了一种极其轻量级的“读写分离”机制。 - MESI 协议影响:在多核 CPU 架构下,频繁修改
volatile变量会触发大量缓存行失效的消息,产生所谓的“伪共享(False Sharing)”或总线风暴问题,需谨慎处理热点变量。
AQS
【问题】什么是 AQS(AbstractQueuedSynchronizer)?
【参考答案】
1. 基本定义
AQS(AbstractQueuedSynchronizer)即抽象队列同步器,是整个 java.util.concurrent (JUC) 包的核心基石。它提供了一个构建锁和同步组件的通用框架,极大地简化了并发编程的复杂度。
2. 核心架构设计 AQS 的核心实现依赖于以下三个关键组件:
- 同步状态(State):使用一个
volatile int state来表示共享资源的状态(如 0 表示空闲,1 表示占用)。 - FIFO 等待队列(CLH 队列):一个虚拟的双向队列,用于存放因获取资源失败而被阻塞的线程。
- CAS 操作:利用底层硬件的原子指令,确保对
state和队列节点更新的原子性。
3. 工作逻辑
- 资源空闲:当一个线程请求共享资源时,如果
state为 0,则通过 CAS 将其置为 1,并将该线程设为当前工作线程。 - 资源占用:如果资源已被占用,AQS 会将该线程封装成一个
Node节点,加入到 CLH 队列的末尾,并挂起该线程。 - 资源释放:当工作线程释放资源时,AQS 会负责唤醒等待队列中头节点的下一个节点。
【延伸考点】
- CLH 队列的“虚拟”性:CLH 队列并不是一个真实的队列实例,它只是由各个节点(Node)通过前后指针相互关联构成的逻辑链表。
- 双重资源共享模式:
- 独占模式(Exclusive):只有一个线程能执行(如
ReentrantLock)。 - 共享模式(Shared):多个线程可同时执行(如
Semaphore、CountDownLatch、ReadWriteLock的读锁)。
- 独占模式(Exclusive):只有一个线程能执行(如
- 模板方法模式:AQS 采用了典型的设计模式。它定义了同步组件的骨架流程,而具体的资源获取/释放逻辑(如
tryAcquire)则交给子类去实现。
【问题】请详细谈谈 AQS 的底层实现原理。
【参考答案】
AQS 的底层实现主要依赖于以下三个核心机制的有机结合:
1. 状态管理(State Management)
- 核心变量:使用
volatile int state成员变量表示同步状态。 - 原子更新:通过
getState()、setState()获取/设置状态,利用compareAndSetState()(CAS)原子地修改状态。 - 语义示例:在
ReentrantLock中,state = 0表示锁未被占用;state = 1表示已被占用;state > 1则表示当前线程的重入次数。
2. 线程排队与挂起(Wait Queue)
- CLH 变体队列:当线程获取锁失败时,会被封装成一个
Node节点,加入到 FIFO 双向同步队列的末尾。 - 节点结构:每个节点包含线程引用、等待状态(
waitStatus)以及prev、next指针。 - 自旋与阻塞:入队的线程会进入一个死循环(自旋),不断检查自己的前驱节点是否为头节点(Head)。如果是,则尝试获取锁;如果不是,则通过
LockSupport.park()挂起。
3. 唤醒与传播(Wakeup & Propagation)
- 释放锁:当工作线程调用
release()释放资源后,会通过unparkSuccessor()唤醒头节点(Head)的第一个有效后继节点。 - 共享传播:在共享模式(Shared Mode)下,一个节点的唤醒还可能触发后继节点的连锁唤醒(Propagation),实现高并发下的快速响应。
【延伸考点】
- 模板方法设计模式:AQS 定义了通用的骨架流程(如
acquire、release),具体逻辑(如tryAcquire、tryRelease)交由子类(如Sync)去重写,这是典型的开闭原则应用。 - CLH 队列的节点状态(waitStatus):
SIGNAL (-1):表示后继节点需要被唤醒。CANCELLED (1):表示节点已被取消(超时或中断)。
- 自旋锁 vs 互斥锁:AQS 的设计在性能和资源开销之间做了权衡,通过“有限自旋 + 挂起”的方式减少了 CPU 空转和频繁的系统调用开销。
【问题】基于 AQS 实现的常见同步组件有哪些?
【参考答案】
AQS 提供了构建同步器的通用机制,通过子类对 state 变量的不同语义定义,实现了多种功能的同步组件:
1. ReentrantLock(可重入锁)
- 模式:独占模式(Exclusive)。
- State 语义:
state = 0表示锁空闲;state > 0表示锁被占用,数值代表同一个线程的重入次数。 - 特点:完全替代了
synchronized,支持公平/非公平选择、响应中断、超时获取等高级特性。
2. Semaphore(信号量)
- 模式:共享模式(Shared)。
- State 语义:
state表示剩余可用许可数(Permits)。 - 特点:允许多个线程同时访问特定数量的资源,常用于流量控制(限流)。
3. CountDownLatch(倒计时器)
- 模式:共享模式(Shared)。
- State 语义:
state表示初始计数值。每调用一次countDown(),state减 1;当state = 0时,唤醒所有在await()处阻塞的线程。 - 特点:一次性的,不可重用。适用于“主线程等待多个子线程完成任务”的场景。
4. ReentrantReadWriteLock(读写锁)
- 模式:独占 + 共享混合模式。
- State 语义:将 32 位的
state切分为两部分:高 16 位表示读锁状态(共享锁,记录获取读锁的线程数),低 16 位表示写锁状态(独占锁,记录写锁重入次数)。 - 特点:实现了“读读并发、读写互斥、写写互斥”,极大地提升了读多写少场景下的系统吞吐量。
5. CyclicBarrier(循环栅栏)
- 说明:虽然它本身没有直接继承 AQS,但其内部是基于
ReentrantLock和Condition实现的,而ReentrantLock正是 AQS 的典型实现。 - 特点:让一组线程相互等待,直到全部到达屏障点。与
CountDownLatch不同的是,它是可以循环重用的。
【延伸考点】
- 公平与非公平策略:AQS 的子类通常提供两种实现。非公平锁性能更佳(减少了线程挂起与唤醒的切换开销),但可能导致线程饥饿。
- Condition 机制:AQS 内部通过
ConditionObject(等待队列)实现了类似Object.wait/notify的功能,支持更精细的线程间协作。 - State 的原子性保证:所有对
state的修改均通过底层的 Unsafe.compareAndSwapInt(CAS)来确保在多线程环境下的绝对安全。
synchronized
【问题】深入谈谈 synchronized 关键字的用法及其底层实现原理。
【参考答案】
synchronized 是 Java 提供的最基本的线程同步机制。它能够保证在同一时刻,只有一个线程可以执行某个代码块或方法,从而确保了操作的原子性、可见性和有序性。
1. 三种主要用法
- 修饰实例方法:锁定当前对象实例(
this)。线程进入方法前必须获得当前对象实例的锁。 - 修饰静态方法:锁定当前类的
Class对象。由于静态方法属于类而不属于某个实例,因此它锁定的是整个类。 - 修饰代码块:手动指定锁对象(如
synchronized(lockObj) { ... })。这种方式比同步方法更灵活,可以只对核心临界区代码加锁,减少同步范围,提升性能。
2. 底层实现原理(JVM 层面)
synchronized 的底层实现主要依赖于 JVM 层面上的 Monitor(监视器锁) 机制:
- 代码块同步:通过
monitorenter和monitorexit字节码指令实现。当执行monitorenter时,线程尝试获取对象的 Monitor 所有权(即获取锁);执行monitorexit时释放所有权。 - 方法同步:JVM 通过方法常量池中的
ACC_SYNCHRONIZED标志来区分同步方法。当方法调用时,调用指令会检查该标志,如果设置了,执行线程将先持有 Monitor 锁,然后执行方法,最后释放。 - 对象头(Object Header):锁的信息实际上存储在 Java 对象的对象头中(Mark Word 区域)。它记录了锁的状态、线程 ID 等关键信息。
3. 锁的升级与优化(Java 6+)
为了提高性能,Java 6 对 synchronized 进行了大量优化,引入了锁升级机制:
- 无锁 -> 偏向锁:当只有一个线程访问同步块时,直接在对象头记录线程 ID,后续该线程进入无需 CAS 操作。
- 偏向锁 -> 轻量级锁:当出现轻微竞争时,升级为轻量级锁,线程通过 CAS 自旋尝试获取锁,避免线程挂起。
- 轻量级锁 -> 重量级锁:当竞争激烈或自旋次数达到上限时,升级为重量级锁,此时未获取锁的线程会被阻塞(挂起),交给操作系统处理。
【延伸考点】
- 可重入性:
synchronized是可重入锁。同一个线程在持有锁的情况下可以再次进入同一个锁保护的其他代码块(通过 Monitor 内部的计数器实现)。 - 异常自动释放:与
ReentrantLock不同,synchronized在发生异常且未处理时,JVM 会自动释放该线程持有的锁,防止死锁。 - 悲观锁特性:它属于一种典型的悲观锁。在 JDK 6 优化之前,由于重量级锁涉及内核态切换,性能较差,但优化后其性能已与
ReentrantLock基本持平。
【问题】synchronized 和 ReentrantLock 有什么区别?
【参考答案】
虽然两者都是可重入锁,但它们在实现机制、功能灵活性以及锁的释放方式上存在显著区别:
1. 实现层面(核心区别)
synchronized:是 JVM 层面的关键字,由 C++ 实现。它通过字节码指令(monitorenter/monitorexit)或方法修饰符(ACC_SYNCHRONIZED)由 JVM 自动管理。ReentrantLock:是 JDK 提供的 API 层面的类。它是基于 Java 实现的(核心依赖 AQS 框架),通过调用类方法来控制锁的获取与释放。
2. 锁的获取与释放
synchronized:隐式释放。线程进入同步块自动加锁,退出(正常结束或抛出异常)时由 JVM 自动释放。ReentrantLock:显式释放。必须手动调用unlock()。通常需要放在finally块中,以确保在发生异常时也能正确释放锁,否则会导致死锁。
3. 功能灵活性
- 公平锁支持:
ReentrantLock构造函数可指定公平锁或非公平锁(默认非公平);synchronized只能是非公平锁。 - 等待可中断:
ReentrantLock提供了lockInterruptibly(),允许在等待锁的过程中响应Thread.interrupt();synchronized一旦进入阻塞状态则不可被中断。 - 条件变量(Condition):
ReentrantLock可以绑定多个Condition对象,实现分组唤醒;synchronized只能通过wait/notify进行全量或随机唤醒。 - 超时获取:
ReentrantLock支持tryLock(time, unit),在规定时间内未获取锁可放弃等待。
4. 性能优化
synchronized:在 Java 6 之后引入了偏向锁、轻量级锁等优化,在低竞争场景下表现极佳。ReentrantLock:在高并发、高竞争的极端场景下,由于其基于 AQS 的设计减少了不必要的内核态切换,性能通常更稳定。
【延伸考点】
- 锁的选型建议:如果只需要基本的同步功能,优先使用
synchronized(代码简洁且由 JVM 优化);如果需要高级特性(如超时、中断、公平性、多条件变量),则必须使用ReentrantLock。 - AQS 框架:理解
ReentrantLock如何利用 AQS 的state变量和 CLH 队列来实现排队与唤醒。 - 读写分离:如果读多写少,可以考虑使用基于 AQS 的
ReentrantReadWriteLock进一步提升并发性能。
【问题】synchronized 和 volatile 的区别与联系?
【参考答案】
synchronized 和 volatile 是 Java 并发编程中最重要的两个关键字。它们既有联系又有区别,共同构成了 Java 并发安全的基石:
1. 核心区别对比
| 特性 | volatile |
synchronized |
|---|---|---|
| 原子性 | 不保证(如 i++ 非原子) |
保证(通过锁机制实现) |
| 可见性 | 保证(通过内存屏障刷新主存) | 保证(通过 Monitor 锁的获取/释放刷新) |
| 有序性 | 保证(禁止指令重排序) | 保证(单线程语义保证结果一致) |
| 阻塞性 | 非阻塞(轻量级,无锁开销) | 会阻塞(重量级锁涉及线程挂起/唤醒) |
| 修饰范围 | 仅修饰变量 | 修饰方法和代码块 |
2. 核心联系与互补
- 可见性保证:两者都能确保一个线程对共享变量的修改对其他线程可见,但
volatile更轻量,因为它不需要上下文切换。 - 有序性保证:两者都能防止指令重排。
volatile是通过插入内存屏障实现的硬限制;而synchronized是通过锁的独占性,保证了同一时刻只有一个线程执行,从而在逻辑上实现了有序性。
3. 典型应用场景(DCL 单例模式) 在双重检查锁(DCL)中,两者必须配合使用:
synchronized:确保创建对象的过程是原子的,防止多个线程同时执行new操作。volatile:防止指令重排。如果不加volatile,由于new操作非原子,可能会发生重排导致其他线程拿到一个尚未初始化完成的“半成品”对象。
【延伸考点】
- 性能考量:
volatile的执行开销极低,适用于状态标记位等简单场景;synchronized适用于复杂的临界区保护。 - JMM 交互原理:
volatile变量的读写直接与主内存交互;synchronized则是在获取锁时清空工作内存,释放锁时将工作内存刷新回主内存。 - 锁消除与锁粗化:JVM 对
synchronized做的自动优化手段,了解这些有助于编写更高效的同步代码。
ThreadLocal
【问题】谈谈你对 ThreadLocal 的理解。
【参考答案】
ThreadLocal 是 Java 提供的线程本地存储机制。它允许每个线程维护一个属于自己的变量副本,从而实现线程之间的数据隔离。
1. 核心作用与场景
- 线程隔离:确保每个线程只能访问自己的数据,不与其他线程共享。这是一种无锁实现线程安全的方式。
- 典型场景:数据库连接管理(
Connection)、用户 Session 信息存储、格式化工具(如SimpleDateFormat,它不是线程安全的)。
- 典型场景:数据库连接管理(
- 跨层传递:在同一个线程执行的不同方法或模块间传递参数(如 TraceID、用户信息),避免了繁琐的参数透传。
2. 实现原理(底层机制)
ThreadLocal 的实现并非在内部维护一个 Map,而是反其道而行之:
- 持有关系:每个
Thread对象内部都持有一个名为threadLocals的成员变量,其类型为ThreadLocalMap。 - 存储结构:
ThreadLocalMap是ThreadLocal的内部类,它维护了一个Entry数组。 - Key-Value:
Entry的 Key 是ThreadLocal对象的弱引用(WeakReference),Value 是真正存储的变量副本。 - 读写流程:当调用
set()时,当前线程会获取自己的ThreadLocalMap,并以当前ThreadLocal对象为 Key 存入数据。
3. 与 synchronized 的区别
- synchronized:通过加锁让多个线程排队访问共享资源,是“以时间换空间”。
- ThreadLocal:为每个线程提供独立的变量副本,不存在竞争,是“以空间换时间”。
【延伸考点】
- 内存泄漏风险:这是最核心的面试点。由于 Key 是弱引用而 Value 是强引用,若不手动调用
remove(),可能导致 Value 长期驻留在内存中无法回收。 - InheritableThreadLocal:如果需要在子线程中继承父线程的本地变量,可以使用该子类。
- Netty 的 FastThreadLocal:在高性能框架中,由于原生
ThreadLocalMap采用线性探测法处理哈希冲突效率较低,常会对其进行优化。
【问题】ThreadLocal 为什么会产生内存泄漏?如何避免?
【参考答案】
ThreadLocal 内存泄漏是 Java 并发编程中的高频面试点。其根源在于 ThreadLocalMap 中 Entry 对象的生命周期管理:
1. 核心原因剖析
- 弱引用的 Key:
ThreadLocalMap的Entry继承自WeakReference<ThreadLocal<?>>。这意味着,如果外部没有对ThreadLocal实例的强引用,那么在下一次 GC 时,这个 Key 会被回收,变为null。 - 强引用的 Value:虽然 Key 被回收了,但
Entry中的 Value 却是强引用。由于ThreadLocalMap是Thread对象的成员变量,只要当前线程(Thread)不销毁,这条从Thread -> ThreadLocalMap -> Entry -> Value的引用链就一直存在。 - 泄漏场景:在使用线程池的情况下,线程通常是长期驻留的。如果任务执行完没有清理
ThreadLocal,那么随着任务不断提交,失效的 Value 会在内存中不断堆积,最终导致 OOM (OutOfMemoryError)。
2. 解决方案:主动清理
- 调用
remove():这是避免内存泄漏的唯一标准做法。在使用完ThreadLocal变量后,务必在finally代码块中显式调用threadLocal.remove()方法。该方法会清除ThreadLocalMap中对应的Entry。
3. JVM 的自愈机制(辅助)
- 在调用
ThreadLocal的set()、get()或rehash()方法时,ThreadLocalMap内部会尝试清理 Key 为null的失效 Entry。但这属于“被动清理”,不能完全依赖它来防止泄漏。
【延伸考点】
- 为什么 Key 要设计成弱引用?:这是一种保护机制。如果 Key 是强引用,那么只要线程不销毁,
ThreadLocal对象就永远无法被回收(即使外部已不再引用它)。设计成弱引用,至少能保证 Key 被回收,从而触发 JVM 的被动清理机制。 - Java 8 的改进:虽然底层逻辑没变,但理解
ThreadLocal在高版本 Java 中的优化有助于写出更健壮的代码。 - 全链路追踪(TraceID):在分布式系统中,
ThreadLocal常用于存储 TraceID,内存泄漏会导致日志上下文混乱甚至系统崩溃,因此规范使用remove()是生产环境的硬性要求。
【问题】 在各个JDK版本中对ThreadLocal分别是怎么优化的?解决了哪些问题?
【参考答案】 ThreadLocal自JDK 1.2引入以来,其核心设计(每个线程维护一个ThreadLocalMap,键为弱引用的ThreadLocal)基本保持稳定。但随着JDK版本的演进,对ThreadLocal的优化主要集中在内存泄漏治理、性能提升和易用性改进三个方面。以下是各主要版本中的优化点及解决的问题:
JDK 1.5
- 优化:引入泛型,使得
ThreadLocal<T>可以指定类型,避免了强制类型转换,提升了类型安全性。 - 解决的问题:使用原生类型带来的类型不安全问题。
JDK 1.6
- 优化:改进了
ThreadLocalMap的清理机制。在getEntry()方法中,当遇到key为null的Entry(即ThreadLocal已被GC回收)时,会主动调用expungeStaleEntry()方法清理该Entry以及后续连续的无效Entry,减少内存泄漏。 - 解决的问题:初步缓解了因
ThreadLocal对象被回收而value仍被强引用导致的内存泄漏问题。但清理时机仅限于get操作,若不再访问该ThreadLocal,则仍需依赖后续操作或线程销毁。
JDK 1.7
- 优化:对
ThreadLocal的初始值设置方式进行了内部优化,但外部感知不大。主要调整了ThreadLocalMap的哈希种子生成逻辑,减少哈希冲突概率。 - 解决的问题:微调性能,但未解决根本问题。
JDK 1.8
- 优化:
- 增加
ThreadLocal.withInitial(Supplier<? extends S> supplier)工厂方法,支持Lambda表达式创建带初始值的ThreadLocal,简化了代码。 - 优化
ThreadLocalMap的扩容和rehash逻辑,提高了空间利用率和访问效率。 - 在
set()、remove()等方法中也加强了清理无效Entry的动作,例如在replaceStaleEntry()中会清理过期条目。 - 调整了
ThreadLocalMap的初始容量和负载因子,减少冲突。
- 增加
- 解决的问题:
- 内存泄漏:通过更主动的清理(在每次
set、remove时也会清理部分无效Entry),降低了内存泄漏的可能性。 - 性能:减少哈希冲突,提高并发访问速度。
- 易用性:提供了便捷的创建方式。
- 内存泄漏:通过更主动的清理(在每次
JDK 9 / 10 / 11
- 优化:
- 进一步改进了
ThreadLocalMap的哈希算法,使用更均匀的哈希分布,减少碰撞。 - 优化了
ThreadLocal的随机种子生成,降低多线程下因哈希竞争带来的性能损耗。 - 对JDK内部大量使用
ThreadLocal的模块(如ForkJoinPool、CompletableFuture等)进行了针对性调优,减少上下文切换和内存占用。 - 增强了对无效
Entry的清理,例如在Thread退出时,对ThreadLocalMap进行更彻底的清理(虽然主要依赖线程销毁,但内部做了优化)。
- 进一步改进了
- 解决的问题:
- 提升了高并发场景下的性能,尤其在大规模线程池应用中,减少了
ThreadLocalMap的查询时间。 - 进一步降低了内存泄漏风险,尤其在复杂应用中的长期存活线程中表现更优。
- 提升了高并发场景下的性能,尤其在大规模线程池应用中,减少了
JDK 12 及以后
- 优化:持续进行微小调优,如调整
ThreadLocalMap的阈值参数,以及优化对WeakReference的处理。但核心设计已趋于稳定。 - 解决的问题:保持性能与内存安全的最佳平衡。
总结 ThreadLocal的优化演进始终围绕两个核心问题:
- 内存泄漏:通过弱引用+主动清理机制,逐步降低了因疏忽调用
remove()导致的内存泄漏风险。 - 性能:通过哈希算法优化、扩容策略改进和内部调优,使ThreadLocal能支撑更高并发的访问。
尽管JDK不断优化,开发者仍需养成良好的习惯:在线程池等长期存活的线程中使用完ThreadLocal后,务必调用remove()方法,以避免潜在的内存泄漏。
【大白话解释于举例说明】
- JDK 1.5:给ThreadLocal穿上了“类型衣服”,原来存东西像乱扔麻袋,现在能分门别类,不会拿错。
- JDK 1.6:开始定期打扫卫生,当你开门(get)时,顺手把门口发霉的垃圾(key为null的entry)扔掉,但角落里的垃圾还留着。
- JDK 1.8:每次进出(set/remove)都会顺手打扫,还提供了“一键初始化”工具(withInitial),方便又干净。
- JDK 11:升级了扫地机器人,路线更智能,连墙角都不放过,而且跑得更快,不干扰你做事。
【扩展知识点详解】
- 弱引用的作用:
ThreadLocalMap的Entry继承自WeakReference<ThreadLocal<?>>,使得ThreadLocal对象没有强引用时可被GC回收,从而key变为null。但value仍是强引用,因此需要清理。 - 清理算法:
expungeStaleEntry()会遍历从某个位置开始的连续Entry,清理key为null的项,并重新哈希后续未清理的Entry以保持数组稳定。 - 哈希冲突处理:
ThreadLocalMap采用线性探测法解决冲突,而非链地址法。因此哈希函数均匀性至关重要。 - 内存泄漏的真实案例:在Web应用中使用线程池处理请求,若在请求中设置了
ThreadLocal但未移除,线程复用会导致旧数据污染新请求,并可能造成内存泄漏(value永远无法被回收)。 InheritableThreadLocal的优化:在JDK 1.8中,InheritableThreadLocal在子线程创建时复制父线程的值,但复制过程也有优化,减少了对象拷贝开销。- 与
FastThreadLocal的对比:Netty等框架实现了FastThreadLocal,通过数组索引代替哈希查找,进一步提升了性能,但JDK原生未采用,因为需要破坏与Thread的内部结构。
JMM
【问题】为什么需要 Java 内存模型(JMM)?它有哪些特性?
【参考答案】
JMM(Java Memory Model)是 Java 并发编程的底层规范。它不是真实存在的物理内存,而是一组抽象的协议与规范。
1. 为什么需要 JMM?
- 硬件差异性:不同的硬件架构(如 x86, ARM)和操作系统对内存的并发访问逻辑各不相同。JMM 屏蔽了这些底层差异,确保 Java 程序在各种平台上都能表现出一致的并发行为(“一次编写,到处运行”)。
- 性能与安全的平衡:JMM 允许编译器和处理器为了性能进行指令重排序,但同时规定了哪些重排序是禁止的,从而在提升性能的同时保证了并发安全。
2. JMM 的三大特性 并发编程的核心问题(原子性、可见性、有序性)正是由 JMM 来规范和解决的:
- 原子性(Atomicity):指一个操作是不可中断的。即使在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
- 保证手段:
synchronized、各种 Lock、原子类。
- 保证手段:
- 可见性(Visibility):指当一个线程修改了共享变量的值,其他线程能够立即得知这个修改。
- 原因:每个线程有自己的工作内存,修改后需刷新回主内存,其他线程再从主内存读取。
- 保证手段:
volatile、synchronized、final。
- 有序性(Ordering):在本线程内观察,所有操作都是有序的;但在多线程环境下,由于指令重排序,观察另一个线程的执行顺序可能是乱序的。
- 保证手段:
volatile、synchronized、Happens-Before 原则。
- 保证手段:
3. JMM 的抽象结构
- 主内存(Main Memory):存储所有的共享变量。
- 工作内存(Working Memory):每个线程私有的内存空间。线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,不能直接读写主内存。
【延伸考点】
- 指令重排序:包括编译器重排、处理器重排。JMM 通过插入内存屏障来禁止特定的重排序。
- Happens-Before 原则:这是 JMM 中最核心的概念。它定义了操作之间的偏序关系,如果 A happens-before B,那么 A 的结果对 B 是可见的。
- AS-IF-SERIAL 语义:不管怎么重排序,单线程下的执行结果不能被改变。
【问题】JMM 定义了哪些关于变量同步的 8 种原子操作?
【参考答案】
为了实现主内存与工作内存之间的交互,Java 内存模型(JMM)定义了 8 种原子操作。这些操作是不可分割的,确保了多线程环境下数据传递的准确性:
1. 作用于主内存(Main Memory)的操作
lock(锁定):将主内存中的变量标识为一条线程独占的状态。unlock(解锁):将主内存中处于锁定状态的变量释放出来,释放后才能被其他线程锁定。read(读取):将变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。write(写入):将store操作从工作内存得到的变量值放入主内存的变量中。
2. 作用于工作内存(Working Memory)的操作
load(载入):将read操作从主内存得到的变量值放入工作内存的变量副本中。use(使用):将工作内存中一个变量的值传递给执行引擎。每当虚拟机遇到一个需要使用变量值的字节码指令时执行。assign(赋值):将从执行引擎接收到的值赋给工作内存的变量。每当虚拟机遇到一个给变量赋值的字节码指令时执行。store(存储):将工作内存中一个变量的值传送到主内存中,以便随后的write操作使用。
3. 操作执行的同步规则
- 不允许
read和load、store和write操作之一单独出现(即必须成对出现,且中间不能插入其他操作)。 - 不允许一个线程丢弃其最近的
assign操作(即工作内存改变后必须同步回主内存)。 - 一个新的变量只能在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化的变量。
【延伸考点】
- volatile 的特殊规则:对于
volatile变量,JMM 规定use动作必须紧跟在load之后,store动作必须紧跟在assign之后。这确保了线程每次使用变量前都必须从主内存刷新,每次修改后都必须立即同步回主内存。 - long 和 double 的非原子性协定:在 32 位虚拟机上,对 64 位数据的
read、load、store、write操作可能被拆分为两次 32 位的操作,但这在现代 64 位虚拟机上已不再是问题。 - synchronized 的原理:底层对应
lock和unlock操作,确保了同步块的独占性。
JVM
【问题】JVM 是如何处理泛型的?什么是类型擦除?
【参考答案】
Java 泛型的实现机制被称为伪泛型,其核心处理方式是类型擦除(Type Erasure)。这意味着泛型仅存在于源码和编译阶段,而在运行期间是不存在的。
1. 类型擦除的过程
- 编译期处理:Java 编译器在编译过程中,会将所有的泛型参数信息擦除掉。
- 类型替换:
- 如果没有指定边界(如
<T>),则替换为Object。 - 如果指定了上限(如
<T extends Comparable>),则替换为上限类型Comparable。
- 如果没有指定边界(如
- 插入强制转型:在调用泛型方法或访问泛型成员时,编译器会自动插入 Checkcast 指令进行强制类型转换,以确保类型安全。
- 生成桥接方法(Bridge Method):为了保持多态性,编译器可能会自动生成桥接方法来处理擦除后的方法签名冲突。
2. 为什么是“伪泛型”?
- 运行期无感知:JVM 在运行时完全不知道泛型的具体类型。例如,
List<String>和List<Integer>在运行时的Class对象是同一个,即ArrayList.class。 - 无法实例化:由于类型被擦除,你不能直接执行
new T()或instanceof T,因为运行时T已经消失了。
3. 类型擦除的约束与影响
- 基本类型限制:泛型参数不能是基本类型(如
int,double),必须使用其对应的包装类(如Integer)。 - 数组限制:不能创建泛型数组(如
new T[10]是非法的)。 - 反射逃逸:由于运行时不进行类型检查,通过反射可以绕过编译器的泛型限制,向
List<String>中添加Integer对象。
【延伸考点】
- 泛型元信息保留:虽然类型被擦除,但泛型的元数据(如类定义上的泛型声明)仍保留在类文件的
Signature属性中。可以通过ParameterizedType在运行时获取部分泛型信息(常用于框架开发)。 - C++ 模板 vs Java 泛型:C++ 模板是“真泛型”,会为每种类型生成一份独立的代码副本(代码膨胀);Java 泛型则通过类型擦除实现,保持了字节码的简洁和向前兼容性。
- 桥接方法的原理:理解编译器如何通过自动生成方法来解决接口实现类在擦除后的签名匹配问题。
【问题】请解释 JVM 运行时数据区中栈、堆和方法区的用途及区别。
【参考答案】
JVM 在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域。其中堆、栈和方法区是最核心的组成部分:
1. Java 虚拟机栈(JVM Stack)
- 用途:它是线程私有的,生命周期与线程相同。每个方法被执行的时候,JVM 都会同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。
- 特点:访问速度快(仅次于寄存器)。如果线程请求的栈深度大于 JVM 所允许的深度,将抛出
StackOverflowError;如果栈扩展时无法申请到足够内存,将抛出OutOfMemoryError。
2. Java 堆(Java Heap)
- 用途:它是所有线程共享的一块内存区域,在虚拟机启动时创建。几乎所有的对象实例以及数组都在这里分配内存。
- 特点:是垃圾收集器(GC)管理的主要区域。根据分代收集算法,堆通常被细分为新生代(Young Generation)和老年代(Old Generation)。如果堆中没有内存完成实例分配,并且堆也无法再扩展时,将抛出
OutOfMemoryError。
3. 方法区(Method Area) / 元空间(Metaspace)
- 用途:它是所有线程共享的内存区域。用于存储已被虚拟机加载的类信息(类结构、字段、方法数据)、常量、静态变量、即时编译器编译后的代码缓存等数据。
- 演进:在 JDK 8 之前,方法区是通过“永久代(PermGen)”实现的;在 JDK 8 及之后,永久代被移除,取而代之的是使用本地内存实现的元空间(Metaspace),这解决了永久代容易发生 OOM 的问题。
4. 核心区别对比
| 特性 | 虚拟机栈 | Java 堆 | 方法区 (元空间) |
|---|---|---|---|
| 线程共享 | 线程私有 | 线程共享 | 线程共享 |
| 存储内容 | 局部变量、栈帧 | 对象实例、数组 | 类信息、常量、静态变量 |
| 内存回收 | 随方法结束自动释放 | 由 GC 垃圾回收 | 回收频率极低(类卸载) |
| 异常类型 | StackOverflowError |
OutOfMemoryError |
OutOfMemoryError |
【延伸考点】
- 本地方法栈(Native Method Stack):与虚拟机栈作用相似,区别在于它是为虚拟机使用到的 Native 方法服务。
- 程序计数器(Program Counter Register):一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。它是唯一一个在 JVM 规范中没有规定任何
OutOfMemoryError情况的区域。 - 直接内存(Direct Memory):不属于 JVM 运行时数据区,但 NIO 常通过
DirectByteBuffer使用它,能显著提升 I/O 性能(减少了数据在内核态与用户态之间的拷贝)。
【问题】常见的 JVM 启动参数有哪些?各有什么作用?
【参考答案】
JVM 启动参数主要分为三类:标准参数(-)、非标准参数(-X)和高级选项(-XX)。这些参数是调优和故障排查的核心工具:
1. 堆内存与空间设置
-Xms:设置堆内存的初始大小。建议与-Xmx设为相同,以减少内存伸缩带来的性能损耗。-Xmx:设置堆内存的最大上限。-Xmn:设置新生代(Young Generation)的大小。-XX:NewRatio:设置老年代与新生代的比例(如2表示比例为 2:1)。-XX:SurvivorRatio:设置 Eden 区与单个 Survivor 区的比例(如8表示 8:1:1)。
2. 元空间(Metaspace)设置
-XX:MetaspaceSize:触发首次 GC 的元空间阈值。-XX:MaxMetaspaceSize:元空间的最大限制。若不设置,默认会使用所有可用的系统物理内存。
3. 垃圾回收器(GC)选型
-XX:+UseG1GC:开启 G1 垃圾回收器(适用于大内存、低延迟场景)。-XX:+UseConcMarkSweepGC:开启 CMS 垃圾回收器(JDK 9 已标记废弃)。-XX:+UseParallelGC:开启吞吐量优先的并行垃圾回收器。
4. 故障排查与诊断
-XX:+HeapDumpOnOutOfMemoryError:当发生 OOM 时,自动生成堆转储文件(Dump)。-XX:HeapDumpPath=/path/to/dump:指定 Dump 文件的保存路径。-XX:+PrintGCDetails/-Xloggc:filename:打印详细的 GC 日志或将其输出到指定文件。
【延伸考点】
-Xss:设置每个线程的栈大小。过大会导致创建线程数减少,过小易导致StackOverflowError。-XX:MaxDirectMemorySize:设置直接内存的最大容量(NIO 常用)。- 参数前缀含义:
-:标准参数,所有 JVM 实现都必须支持。-X:非标准参数,通常是特定版本的 JVM 优化指令。-XX:高级选项,通常用于系统性能调优。其中+表示开启,-表示关闭。
【问题】如何排查生产环境中的 CPU 占用过高或内存飙升问题?
【参考答案】
这是生产运维中的核心技能,通常需要结合 Linux 命令与 JVM 工具进行协同诊断:
1. 排查 CPU 占用过高(经典 5 步法)
- 定位进程:使用
top命令找到占用 CPU 最高的 Java 进程 PID。 - 定位线程:执行
top -Hp <PID>,找出该进程下占用 CPU 最高的线程 TID。 - 进制转换:使用
printf "%x\n" <TID>将线程 ID 转换为 16 进制(如1234转为4d2),因为 JVM 线程栈信息中线程 ID 是以 16 进制显示的。 - 导出栈快照:执行
jstack <PID> > jstack.txt导出线程栈信息。 - 锁定代码:在
jstack.txt中搜索 16 进制的 TID,找到该线程对应的代码行,分析是否存在死循环、频繁 GC 或热点计算。
2. 排查内存飙升/溢出(OOM)
- 实时观察:使用
jstat -gc <PID> 1000每秒观察一次 GC 情况。如果老年代(OU)持续上涨且 Full GC 频繁,说明存在内存泄漏。 - 对象统计:执行
jmap -histo <PID> | head -20快速查看堆中占用空间最大的前 20 个类,定位可能的异常对象。 - 导出堆转储:执行
jmap -dump:live,format=b,file=heap.hprof <PID>导出当前存活对象的堆快照。 - 离线分析:使用专业工具(如 MAT (Memory Analyzer Tool) 或 VisualVM)分析
heap.hprof文件。- 查看 Leak Suspects(泄漏嫌疑报告)。
- 通过 Dominator Tree 查看占用内存最大的引用路径。
【延伸考点】
- 常见的内存泄漏根源:静态集合持有长生命周期对象、未关闭的资源流、未移除的
ThreadLocal、JNI 导致的本地内存泄漏。 - Arthas (阿尔萨斯):阿里开源的诊断利器。可以使用
thread -n 3快速定位最忙的前三个线程,使用dashboard实时查看内存和 GC 指标,极大简化了手动排查流程。 - CPU 飙升的非业务原因:频繁的 Full GC 本身也会消耗大量 CPU,此时根因可能是内存问题而非纯计算逻辑。
- JIT 编译热点:在系统启动初期,JIT 实时编译可能导致短暂的 CPU 飙升。
内存泄露溢出
【问题】内存泄漏(Memory Leak)与内存溢出(OutOfMemoryError)有什么区别?
【参考答案】
内存泄漏和内存溢出是两个既有区别又紧密相关的概念。简单来说,内存泄漏是因,内存溢出是果。
1. 内存泄漏(Memory Leak)
- 定义:指程序中已动态分配的堆内存由于某种原因(通常是错误的逻辑)程序未释放或无法释放,导致这部分内存被永久占用。
- 本质:对象不再被程序使用,但由于还存在强引用链(GC Root 可达),导致垃圾回收器(GC)无法将其回收。
- 表现:内存占用率像“阶梯状”或“斜坡状”缓慢上涨,即便频繁触发 Full GC,内存也无法降回正常水平。
- 常见原因:静态集合类持有大对象、未关闭的资源流(IO/数据库连接)、未移除的
ThreadLocal、内部类持有外部类引用等。
2. 内存溢出(OOM)
- 定义:指程序申请内存时,没有足够的内存空间供其使用。
- 本质:JVM 尝试为新对象分配内存,但在回收了所有能回收的对象并尝试扩展堆空间后,仍然无法满足分配需求。
- 表现:程序直接抛出
java.lang.OutOfMemoryError异常并可能崩溃。 - 常见原因:
- 堆溢出:内存泄漏积压、瞬时创建海量大对象(如查询数据库未加 limit)。
- 元空间溢出:动态生成了过多的类(如频繁使用 CGLIB 代理)。
- 栈溢出:无限递归或局部变量过多导致栈深度超过限制(
StackOverflowError)。
3. 核心区别对比
| 特性 | 内存泄漏 (Leak) | 内存溢出 (OOM) |
|---|---|---|
| 可回收性 | 逻辑上应回收,物理上不可回收 | 物理上已无空间可分配 |
| 发生过程 | 缓慢积累,具有隐蔽性 | 瞬间爆发或积累到临界点爆发 |
| 关联性 | 持续的泄漏最终会导致 OOM | OOM 不一定是由泄漏引起的 |
| 解决难度 | 较难,需分析引用链(MAT/VisualVM) | 相对容易,增加内存或优化大对象 |
【延伸考点】
- 软引用与弱引用:在缓存场景下使用
SoftReference或WeakReference可以有效降低内存泄漏演变为 OOM 的风险。 - 诊断工具:发生 OOM 时,通过
-XX:+HeapDumpOnOutOfMemoryError生成的 Dump 文件是分析内存泄漏的唯一“第一现场”。 - 伪溢出:有时 CPU 负载过高导致 GC 时间过长,也会触发
GC overhead limit exceeded异常,这属于一种特殊的 OOM。
逃逸分析
【问题】Java 对象一定分配在堆上吗?什么是逃逸分析?
【参考答案】
不一定。虽然 Java 虚拟机规范中描述“所有的对象实例以及数组都应当在堆上分配”,但随着 JIT 编译器的不断优化,通过逃逸分析(Escape Analysis)技术,现代 JVM 已经可以实现对象在栈上分配或进行其他高性能优化。
1. 什么是逃逸分析? 逃逸分析是一种由 JIT 编译器在编译期执行的算法。它会分析一个对象的作用域:
- 方法逃逸:当一个对象在方法中被定义后,它可能被外部方法引用(如作为返回值)。
- 线程逃逸:对象可能被外部线程访问到(如赋值给类变量或被其他线程持有的对象属性)。
- 不逃逸:如果对象仅在当前方法内部可见,且不会被外部引用,则称该对象“没有逃逸”。
2. 基于逃逸分析的优化手段 如果 JIT 编译器通过分析确定一个对象没有逃逸,则可以执行以下三种优化:
- 栈上分配(Stack Allocation):
- 原理:直接在当前线程的虚拟机栈中分配内存,而不是堆。
- 优势:对象随方法结束(栈帧销毁)自动回收,极大减轻了垃圾收集(GC)的压力。
- 标量替换(Scalar Replacement):
- 原理:将一个对象拆解为若干个原始类型的成员变量(称为“标量”),直接在栈上或寄存器中操作这些变量。
- 优势:完全消除了创建对象的内存开销,甚至可以提高 CPU 缓存命中率。
- 同步消除(Lock Elimination):
- 原理:如果对象不会逃逸出当前线程,说明不存在多线程竞争,编译器会移除对该对象的所有同步锁(
synchronized)操作。 - 优势:消除了无意义的锁竞争开销,提升执行速度。
- 原理:如果对象不会逃逸出当前线程,说明不存在多线程竞争,编译器会移除对该对象的所有同步锁(
【延伸考点】
- JIT(即时编译器):它是逃逸分析的执行主体。了解 C1(Client)和 C2(Server)编译器的区别,通常 C2 才会进行复杂的逃逸分析。
- 默认开启状态:在 Java 6u23 及以后的 64 位 JVM 中,逃逸分析默认是开启的。可以通过
-XX:+DoEscapeAnalysis显式控制。 - 局限性:逃逸分析本身也需要消耗 CPU 资源。如果分析发现绝大部分对象都会逃逸,那么开启逃逸分析反而会降低性能。因此,这是一种基于运行情况的动态优化。
故障分析工具
【问题】你常用的 JVM 故障诊断工具有哪些?
【参考答案】
JVM 故障诊断工具可以分为命令行工具、可视化分析工具以及第三方开源利器三大类:
1. JDK 自带命令行工具(生产环境常用)
jps(JVM Process Status):查看正在运行的 Java 进程 ID (PID) 及主类信息。jstat(JVM Statistics Monitoring Tool):实时监视虚拟机各种运行状态信息(如 GC 情况、类加载、JIT 编译等)。常用命令:jstat -gc <PID> 1000。jstack(Stack Trace for Java):生成虚拟机当前时刻的线程快照。主要用于排查线程死锁、死循环、请求占用时间过长等问题。jmap(Memory Map for Java):用于生成堆转储快照(Heap Dump)或查看堆内存细节(如-histo查看对象统计)。jinfo(Configuration Info for Java):实时地查看和调整虚拟机的各项参数。
2. 可视化分析工具(本地离线分析)
jvisualvm(All-in-One):JDK 自带的全能型图形化工具,集成了线程分析、内存监控、性能采样等功能。MAT(Memory Analyzer Tool):基于 Eclipse 的专业内存分析工具。它是分析大规模堆转储文件(Heap Dump)的首选,能自动生成泄漏嫌疑报告(Leak Suspects)。JConsole:基于 JMX 的早期监控管理控制台,主要用于实时监控内存、线程和类。
3. 第三方在线诊断利器(推荐掌握)
Arthas(阿尔萨斯):阿里开源的 Java 诊断工具。支持实时查看 Dashboard、反编译代码、在线热更新、监控方法入参及出参、监控 GC 及内存指标等,极大地提升了生产环境的排查效率。
【延伸考点】
- 排查死锁的工具:
jstack是最常用的手段,它能直接定位到发生死锁的线程及对应的代码行。 - 排查 OOM 的工具:通常先用
jstat观察 GC 趋势,再用jmap导出 Dump,最后用MAT进行深度分析。 - Arthas 的核心优势:无需重启 JVM 即可进行动态诊断,对生产环境非常友好。常用命令包括
thread -n 3(查看最忙线程)、watch(观察方法执行)、trace(分析方法耗时)等。
垃圾回收
【问题】JVM 垃圾回收(GC)的目的及触发时机?
【参考答案】
垃圾回收(Garbage Collection)是 JVM 的核心特性之一,它将开发者从繁琐的内存管理中解放出来,专注于业务逻辑。
1. 垃圾回收的目的
- 释放内存资源:自动识别并回收程序中不再使用的对象所占用的堆内存,防止内存泄漏。
- 整理内存碎片:通过特定的算法(如标记-整理),消除因频繁分配和回收产生的碎片,确保大对象能申请到连续的内存空间。
- 提升开发效率:降低了手动管理内存(如 C++ 中的
free/delete)带来的风险(如悬挂指针、重复释放等)。
2. 核心触发时机 JVM 的 GC 触发通常分为三个层次:
- Minor GC / Young GC(新生代回收):
- 触发条件:当 Eden 区空间不足时立即触发。
- 特点:执行频繁且速度极快。
- Major GC / Old GC(老年代回收):
- 触发条件:当老年代空间不足时触发。通常会伴随着至少一次 Minor GC。
- 注意:在某些收集器(如 CMS)中,Major GC 专门指老年代回收。
- Full GC(全堆回收):
- 触发条件:
- 老年代空间不足或元空间(Metaspace)空间不足。
- 显式调用
System.gc()(建议 JVM 执行,但不保证立即执行)。 - Minor GC 后晋升到老年代的对象平均大小大于老年代的剩余空间(空间分配担保失败)。
- 后果:会引起长时间的 STW(Stop The World),严重影响系统吞吐量。
- 触发条件:
【延伸考点】
- STW (Stop The World):指在垃圾回收算法执行过程中,必须暂停所有的用户线程。这是调优时的重点关注指标,目标是尽量缩短 STW 的时长。
- 对象晋升机制:了解对象如何从新生代跨越到老年代(如达到年龄阈值、大对象直接进入等)。
- 元空间的 GC:虽然元空间使用本地内存,但当类加载器过多或元空间达到
MaxMetaspaceSize时,依然会触发 Full GC 来回收废弃的类元数据。
【问题】请总结 JVM 常用的垃圾回收算法及其优缺点。
【参考答案】
JVM 的垃圾回收算法是内存管理的核心,主要经历了从简单到复杂、从单一到分代的发展过程:
1. 标记-清除算法(Mark-Sweep)
- 过程:分为“标记”和“清除”两个阶段。首先标记出所有需要回收的对象,标记完成后统一回收掉所有被标记的对象。
- 优点:实现最简单、最基础。
- 缺点:
- 效率问题:标记和清除两个过程的效率都不高。
- 空间问题:清除之后会产生大量不连续的内存碎片,导致大对象无法找到足够的连续空间而提前触发另一次 GC。
2. 复制算法(Copying)
- 过程:将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当这一块用完了,就将还存活着的对象复制到另一块上面,然后再把已使用过的内存空间一次清理掉。
- 优点:实现简单,运行高效,且没有内存碎片问题。
- 缺点:内存利用率低(只有一半)。
- 应用:现代 JVM 改进了此算法(Appel 式回收),将新生代内存分为 Eden 和两个 Survivor 区(8:1:1),极大提升了空间利用率。
3. 标记-整理算法(Mark-Compact)
- 过程:标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
- 优点:无内存碎片,且内存利用率高。
- 缺点:在存活对象较多时(如老年代),移动对象并更新引用地址的开销非常大,会造成较长的 STW。
- 应用:主要用于老年代。
4. 分代收集算法(Generational Collection)
- 核心思想:根据对象存活周期的不同将内存划分为几块。一般是把 Java 堆分为新生代和老年代。
- 新生代:对象存活率低,选用复制算法。
- 老年代:对象存活率高,选用标记-清除或标记-整理算法。
【延伸考点】
- 可达性分析算法:JVM 通过 GC Roots(如栈帧中的局部变量、静态属性、常量等)作为起点,向下搜索,如果一个对象到 GC Roots 没有任何引用链相连,则证明此对象是不可用的。
- 引用计数法的局限:Java 没有采用引用计数法,是因为它无法解决对象之间循环引用的问题。
- 增量收集与分区收集:了解 G1 和 ZGC 采用的分区(Region)思想,旨在将整堆划分为小区域进行局部回收,从而精准控制 STW 时间。
【问题】 常见的 JVM 垃圾回收器都是使用的什么垃圾回收算法?
【参考答案】 JVM 中的垃圾回收器通常针对不同代(新生代、老年代)采用不同的垃圾回收算法以适应不同的业务场景(如高吞吐量、低延迟、大内存等)。主流垃圾回收器的算法组合如下:
1. 常见的垃圾回收器分类
- 串行收集器 (Serial / Serial Old):
- 特点:单线程执行,进行 GC 时必须暂停所有用户线程(STW)。
- 场景:简单高效,适合内存较小的 Client 模式或单核 CPU 环境。
- 并行收集器 (Parallel Scavenge / Parallel Old):
- 特点:多线程并行收集,目标是达到一个可控制的吞吐量(Throughput)。
- 场景:JDK 8 的默认组合。适合后台计算、不需要太多交互的场景。
- 并发标记扫描 (CMS, Concurrent Mark Sweep):
- 特点:以获取最短回收停顿时间(低延迟)为目标。大部分阶段与用户线程并发执行。
- 缺点:基于“标记-清除”算法,会产生内存碎片;对 CPU 资源敏感;无法处理“浮动垃圾”。
- G1 (Garbage-First):
- 特点:面向服务端应用,将堆内存划分为多个大小相等的 Region。支持可预测的停顿时间模型。
- 优势:JDK 9+ 的默认选择。能同时兼顾吞吐量和低延迟,且能有效规避碎片。
- ZGC (Z Garbage Collector):
- 特点:JDK 11 引入的革命性收集器。无论堆多大,都能将停顿时间控制在 10ms 以内。
- 技术:使用了着色指针(Colored Pointers)和读屏障(Load Barriers)。
2. 经典的组合配置方案
| 场景需求 | 新生代收集器 | 老年代收集器 | JVM 参数配置 |
|---|---|---|---|
| 单核/小内存 | Serial | Serial Old | -XX:+UseSerialGC |
| 追求吞吐量 | Parallel Scavenge | Parallel Old | -XX:+UseParallelGC |
| 追求低延迟 | ParNew | CMS | -XX:+UseConcMarkSweepGC |
| 全能/大内存 | G1 (统一管理) | G1 (统一管理) | -XX:+UseG1GC |
3.新生代垃圾回收器 新生代一般采用复制算法(Copying),因为新生代对象存活率低,复制算法效率高,且只需复制少量存活对象。
- Serial 回收器(新生代):复制算法。单线程工作,在回收时需要暂停所有用户线程(Stop-The-World)。
- ParNew 回收器(新生代):复制算法。Serial 的多线程版本,同样采用复制算法,多线程并行回收。
- Parallel Scavenge 回收器(新生代):复制算法。与 ParNew 类似,但更注重吞吐量,可动态调整停顿时间。
4.老年代垃圾回收器 老年代一般采用标记-清除(Mark-Sweep)或标记-整理(Mark-Compact)算法,因为老年代对象存活率高,复制算法开销大。
- Serial Old 回收器(老年代):标记-整理算法。单线程,主要用于 CMS 的后备方案。
- Parallel Old 回收器(老年代):标记-整理算法。Parallel Scavenge 的老年代版本,多线程,注重吞吐量。
- CMS 回收器(老年代):标记-清除算法。并发收集,以最短回收停顿时间为目标,会产生内存碎片,最终可能导致 Full GC 时使用 Serial Old 进行整理。
5.混合回收器 部分回收器同时管理新生代和老年代,采用不同算法的组合。
- G1 回收器:整体采用分代+分区思想,逻辑上仍分新生代和老年代,但物理上不连续。G1 的回收过程结合了复制算法和标记-整理算法。在年轻代回收使用复制算法;老年代回收(混合回收)中,将存活对象复制到新的 Region,本质上也是复制算法,但避免了全堆的标记-整理,实现了局部整理。
- ZGC 回收器:采用标记-整理(压缩)算法,但通过染色指针、读屏障等技术实现几乎全并发的整理,无碎片,停顿时间极短。
- Shenandoah 回收器:与 ZGC 类似,采用标记-整理算法,也通过并发压缩减少停顿。
6.算法总结
| 回收器 | 新生代算法 | 老年代算法 | 备注 |
|---|---|---|---|
| Serial | 复制 | - | 新生代 |
| ParNew | 复制 | - | 新生代 |
| Parallel Scavenge | 复制 | - | 新生代 |
| Serial Old | - | 标记-整理 | 老年代 |
| Parallel Old | - | 标记-整理 | 老年代 |
| CMS | - | 标记-清除 | 老年代,配合 ParNew 使用 |
| G1 | 复制 | 复制(局部整理) | 分代,分区 |
| ZGC | - | 标记-整理 | 全堆,并发整理 |
| Shenandoah | - | 标记-整理 | 全堆,并发整理 |
7.算法原理简述
- 复制算法:将内存分为两块,每次只使用一块,回收时将存活对象复制到另一块,然后清理原块。适用于新生代。
- 标记-清除算法:先标记所有存活对象,然后统一清除未标记对象。会产生内存碎片,但效率较高。
- 标记-整理算法:标记存活对象后,将所有存活对象向内存一端移动,然后清理边界以外的内存。解决碎片问题,但移动对象开销大。
【大白话解释】
- 复制算法:好比你有两个箱子,一个装东西,一个空着。当箱子快满时,把有用的东西搬到空箱子,然后清空原箱子。新生代对象大多生命周期短,所以搬运成本低。
- 标记-清除:如同打扫房间,先标记哪些家具要留,然后扔掉没标记的垃圾。但垃圾扔掉后,房间会变得稀疏,容易产生碎片(小空隙),以后放新家具可能放不下。
- 标记-整理:标记后不仅扔垃圾,还会把留着的家具往一边推,挤在一起,腾出连续空间,这样放新家具就方便了。
【扩展知识点详解】
- 分代收集:基于对象存活周期的不同,将堆划分为新生代和老年代,采用不同算法。
- 并发与并行:Parallel 系列强调并行(多个 GC 线程同时工作),CMS、G1 等强调并发(GC 线程与用户线程同时运行)。
- 停顿时间与吞吐量:复制算法和标记-整理算法通常需要 Stop-The-World,而 CMS、ZGC 通过并发减少停顿。
- ZGC 的染色指针:通过指针中的元数据标记对象状态,实现并发整理,无需对象头。
- G1 的 Region:将堆划分为多个大小相等的 Region,避免全堆回收,可预测停顿时间。
- 并发(Concurrent)与并行(Parallel):
- 并行:多条垃圾收集线程并行工作,但此时用户线程仍处于等待状态。
- 并发:垃圾收集线程与用户线程同时执行(但不一定是并行的,可能会交替执行)。
- 吞吐量优先 vs 响应时间优先:根据业务类型(如离线报表 vs 实时 Web 服务)选择不同的回收器。
- JDK 版本的默认回收器:
- JDK 8:Parallel GC (Parallel Scavenge + Parallel Old)
- JDK 9 及以后:G1 GC。
- JDK 15:ZGC 成为正式版(不再是实验性功能)。
【问题】请分析 Java 对象的各种可达性状态(强、软、弱、虚引用)。
【参考答案】
在 Java 中,引用的强度决定了对象在垃圾回收(GC)过程中的“生存机率”。通过灵活运用不同强度的引用,开发者可以更好地控制对象的生命周期,实现高效的内存管理。
1. 强引用(Strong Reference)
- 定义:最常见的引用方式,如
Object obj = new Object()。 - 回收机制:只要强引用还存在,垃圾回收器绝不会回收被引用的对象。即便内存不足,JVM 宁愿抛出
OutOfMemoryError导致程序崩溃,也不会回收强引用对象。 - 生命周期:取决于变量的作用域。
2. 软引用(Soft Reference)
- 定义:通过
SoftReference<T>类实现。 - 回收机制:描述一些有用但非必需的对象。在系统内存不足(即将发生 OOM)时,垃圾回收器会尝试回收这些对象。如果回收后内存依然不足,才会抛出异常。
- 应用场景:实现内存敏感型缓存(如图片缓存、网页缓存)。
3. 弱引用(Weak Reference)
- 定义:通过
WeakReference<T>类实现。 - 回收机制:强度比软引用更弱。无论内存是否充足,只要垃圾回收器开始工作并发现了弱引用对象,就一定会将其回收。
- 应用场景:防止内存泄漏。典型案例包括
ThreadLocal中的ThreadLocalMap的 Key,以及WeakHashMap。
4. 虚引用(Phantom Reference)
- 定义:通过
PhantomReference<T>类实现。也称为“幻象引用”。 - 回收机制:最弱的引用。无法通过虚引用获取对象实例。它的唯一目的就是在这个对象被垃圾回收器回收时收到一个系统通知。
- 必要条件:必须与 引用队列(ReferenceQueue) 联合使用。
- 应用场景:管理堆外内存(如
DirectByteBuffer的回收通知)。
核心对比总结
| 引用类型 | 回收时机 | 生存时间 | 常见用途 |
|---|---|---|---|
| 强引用 | 永远不回收(直到不可达) | 随作用域结束 | 普通对象引用 |
| 软引用 | 内存不足时 | 内存溢出前 | 缓存(内存敏感) |
| 弱引用 | GC 发现即回收 | 下一次 GC 前 | 防止内存泄漏、缓存 |
| 虚引用 | 随时(无法获取实例) | 对象销毁时通知 | 堆外内存管理 |
【延伸考点】
- 引用队列(ReferenceQueue):当软引用、弱引用或虚引用所引用的对象被回收时,JVM 会自动将该引用对象加入到关联的引用队列中,方便程序进行后续清理工作。
- ThreadLocal 内存泄漏风险:理解为什么
ThreadLocalMap的 Key 使用弱引用(为了防止 Key 泄漏),但 Value 是强引用(可能导致 Value 无法回收,需手动调用remove())。 - Cleaner (Java 9+):Java 9 引入了
java.lang.ref.Cleaner来替代已废弃的finalize()方法,其底层正是基于虚引用和引用队列实现的。
java集合类
collection
【问题】Java 集合框架有哪些核心接口?
【参考答案】
Java 集合框架(Java Collections Framework)主要由两大顶层接口派生而成:Collection 和 Map。
1. Collection 接口(存储一组对象)
它是单列集合的根接口,派生出三个核心子接口:
List(列表):- 特性:有序、可重复。支持通过索引精确访问元素。
- 典型实现:
ArrayList(动态数组,查询快)、LinkedList(双向链表,增删快)。
Set(集):- 特性:无序(指存取顺序不一致)、不可重复。
- 典型实现:
HashSet(哈希表,效率高)、TreeSet(红黑树,支持自然排序或比较器排序)。
Queue(队列):- 特性:遵循先进先出(FIFO)原则,用于在处理前保存元素。
- 典型实现:
PriorityQueue(优先级队列)、ArrayDeque(双端队列)。
2. Map 接口(存储键值对)
它是双列集合的根接口,用于存储具有映射关系的数据。
- 特性:存储 Key-Value 对,其中 Key 必须唯一且不可重复,Value 可重复。
- 典型实现:
HashMap:最常用的实现,非线程安全,允许 null 键值。TreeMap:基于红黑树实现,Key 处于有序状态。LinkedHashMap:维护了插入顺序或访问顺序。ConcurrentHashMap:高性能的线程安全实现。
【延伸考点】
- 集合 vs 数组:数组长度固定且可存储基本类型;集合长度可变且只能存储引用类型(基本类型通过自动装箱处理)。
- Iterable 接口:
Collection继承了Iterable,这意味着所有单列集合都支持for-each循环和迭代器遍历。 - 线程安全集合:了解
Vector、Hashtable等古老集合与Collections.synchronizedXxx以及java.util.concurrent包下并发容器的区别。
【问题】为什么 Collection 接口没有继承 Cloneable 和 Serializable 接口?
【参考答案】
这是一个关于 Java 集合框架设计哲学的问题。Collection 接口及其子接口(如 List, Set)没有继承这两个接口,主要基于以下考虑:
1. 职责分离与灵活性
- 接口的纯粹性:
Collection接口的核心职责是定义一组对象的存储、查询和操作规范。克隆(Clone)和序列化(Serialization)属于对象的具体实现属性,而不是所有集合都必须具备的共性行为。 - 实现自由度:具体的实现类(如
ArrayList,HashSet)可以根据其内部数据结构的特点,自主决定是否支持克隆或序列化。例如,某些特殊的集合实现(如基于硬件资源的集合)可能根本无法被序列化。
2. 语义不确定性
- 深拷贝 vs 浅拷贝:克隆操作在集合中存在“深浅”之争。如果由接口强制定义,很难规定统一的克隆语义。由实现类自行定义,可以根据业务需求选择最合适的拷贝策略。
- 成员约束:序列化要求集合中的所有元素也必须是可序列化的。如果接口强制要求序列化,那么在使用该接口引用时,编译器将无法在编译期保证其存储的元素是否真的能被成功序列化。
3. 减少耦合
- 强制继承会导致所有实现类都必须负担这两个接口的实现成本,增加了不必要的类层次复杂度和维护开销。
【延伸考点】
- 克隆的陷阱:大多数标准集合实现类(如
ArrayList)的clone()方法执行的都是浅拷贝(Shallow Copy)。这意味着集合本身是新的,但其中的元素对象依然是旧的引用。 - 序列化的 ID:在实现自定义集合并支持序列化时,务必定义
serialVersionUID,以防止类结构微调导致的兼容性问题。 - Collections 工具类:虽然接口没继承,但
Collections工具类提供的许多不可变视图或同步包装器,通常会根据原集合的情况来动态支持这些特性。
迭代器
【问题】什么是 Iterator?它的作用是什么?
【参考答案】
Iterator(迭代器)是 Java 集合框架中的一个核心接口。它是迭代器模式在 Java 中的具体实现,专门用于顺序访问集合中的元素,而无需暴露集合的内部表示。
1. 核心作用
- 解耦(统一遍历方式):迭代器提供了一种通用的遍历接口。无论底层是数组(
ArrayList)、链表(LinkedList)还是树结构(TreeSet),开发者都可以使用统一的hasNext()和next()方法进行遍历,实现了算法与容器的分离。 - 安全删除元素:在遍历过程中,如果直接调用集合的
remove()方法修改结构,会触发 fail-fast 机制并抛出ConcurrentModificationException。而使用iterator.remove()则是安全的,因为它在删除后会同步更新迭代器内部的状态。
2. 核心方法详解
boolean hasNext():判断是否还有下一个可访问的元素。E next():返回下一个元素,并将指针后移一位。void remove():删除最后一次返回的元素。必须在调用next()后才能调用,且每调用一次next()只能调用一次remove()。void forEachRemaining(Consumer action)(Java 8+):对剩余的所有元素执行给定的操作。
3. 迭代器的工作原理
迭代器通常作为集合类的内部类实现。它内部维护了一个游标(cursor),记录当前遍历到的位置。在遍历期间,它会持续检查集合的 modCount(修改次数),以确保遍历过程中集合没有被非法篡改。
【延伸考点】
ListIterator:专门用于List的增强型迭代器。它支持双向遍历(hasPrevious/previous)、修改元素(set)以及添加元素(add)。- 与 Enumeration 的区别:
Iterator是 JDK 1.2 引入的,相比古老的Enumeration,它增加了删除元素的能力,且方法名更加简洁。 - forEach 循环的本质:Java 的
for-each增强型循环底层正是通过Iterator实现的(对于数组则是通过普通的 for 循环)。因此,在for-each循环中删除元素同样会报错。
【问题】fail-fast 与 fail-safe 机制的区别是什么?
【参考答案】
在 Java 集合遍历过程中,为了应对并发修改可能带来的数据一致性问题,存在两种核心的应对机制:fail-fast(快速失败) 和 fail-safe(安全失败)。
1. fail-fast(快速失败)
- 核心机制:在遍历过程中,如果发现集合的结构发生了变化(如添加、删除元素),会立即抛出
ConcurrentModificationException。 - 实现原理:集合内部维护一个
modCount变量。迭代器在初始化时会记录当时的modCount(记为expectedModCount)。在每次调用next()或remove()时,都会检查两者是否相等。若不等,说明集合已被外部篡改,立即抛出异常。 - 典型代表:
java.util包下的非线程安全容器,如ArrayList、HashMap、LinkedList等。 - 优缺点:性能高,能及时发现并发修改错误;但在多线程环境下不能保证绝对可靠,且无法处理并发修改。
2. fail-safe(安全失败)
- 核心机制:在遍历时不是直接在原集合上操作,而是先复制一份原集合的副本(Snapshot),在副本上进行遍历。
- 实现原理:由于遍历的是副本,因此在遍历过程中对原集合的修改不会影响迭代器的行为,也就不会抛出
ConcurrentModificationException。 - 典型代表:
java.util.concurrent包下的并发容器,如CopyOnWriteArrayList、ConcurrentHashMap。 - 优缺点:避免了并发修改异常,适合高并发场景;但由于需要拷贝副本,内存开销较大,且迭代器只能反映创建瞬间的集合状态,存在弱一致性问题。
3. 核心区别对比表
| 特性 | fail-fast (快速失败) | fail-safe (安全失败) |
|---|---|---|
| 抛出异常 | 抛出 ConcurrentModificationException |
不抛出异常 |
| 操作对象 | 直接在原集合上操作 | 在原集合的副本/视图上操作 |
| 数据一致性 | 强一致性(虽不能处理并发修改) | 弱一致性(可能读到过期数据) |
| 性能/开销 | 内存开销小,性能高 | 内存开销大(需拷贝),性能相对低 |
| 应用场景 | 单线程环境或对实时性要求高的场景 | 高并发环境 |
【延伸考点】
- ConcurrentHashMap 的迭代器:虽然常被归类为 fail-safe,但它的实现并不是简单的全量拷贝,而是利用了 弱一致性(Weakly Consistent) 迭代器,能反映迭代器创建后的部分修改。
- 避免 fail-fast 的正确姿势:在单线程遍历中删除元素,应始终使用
iterator.remove()而非list.remove()。 - CopyOnWrite 思想:理解“写时复制”在 fail-safe 中的应用及其对读写性能的影响。
Map
【问题】请详细阐述 HashMap 的底层工作原理(JDK 1.8)。
【参考答案】
JDK 1.8 中的 HashMap 进行了重大的性能优化,其核心结构为数组 + 链表 + 红黑树。
1. 核心数据结构
- Node 数组:底层是一个
Node<K,V>[] table,它是存储数据的哈希桶。 - 链表与红黑树:当发生哈希冲突时,数据存储在桶中的链表里。当链表长度达到 8 且数组容量达到 64 时,链表会进化为红黑树以提升查询效率(时间复杂度从 O(n) 降至 O(logn))。
2. 核心操作流程
- 哈希计算(扰动函数):通过
(h = key.hashCode()) ^ (h >>> 16)计算哈希值。将高 16 位与低 16 位异或,目的是为了在数组容量较小时,也能让高位参与下标运算,从而减少哈希冲突。 - 下标寻址:使用
(n - 1) & hash代替取模运算,效率更高(前提是数组长度 n 必须是 2 的幂次方)。 - Put 流程:
- 若
table为空,先执行resize()初始化。 - 根据寻址找到桶位,若为空则直接插入。
- 若不为空且 Key 相同,则覆盖 Value。
- 若 Key 不同,则判断当前桶是红黑树还是链表,进行对应的插入操作(链表采用尾插法)。
- 插入后若超过阈值
threshold,则执行扩容。
- 若
3. 扩容机制(Resize)
- 触发时机:当元素个数超过
capacity * loadFactor(默认 0.75)时。 - 扩容策略:数组容量翻倍。JDK 1.8 优化了迁移逻辑:不需要重新计算哈希值,只需通过
(e.hash & oldCap)的值(0 或 1)来判断节点是停留在原位置还是移动到“原位置 + oldCap”的位置,这大大减少了扩容时的计算开销。
【延伸考点】
- 线程安全问题:
HashMap是非线程安全的。在多线程环境下扩容可能导致数据丢失(JDK 1.7 还会导致死循环,1.8 已修复死循环但仍不安全)。并发场景应使用ConcurrentHashMap。 - 为什么容量必须是 2 的幂次方?:为了能使用位运算
(n - 1) & hash进行快速寻址,且能保证哈希值在数组中分布更均匀。 - 红黑树退化:当扩容或删除导致红黑树节点减少到 6 时,会退化回链表(中间留有 7 作为缓冲,防止频繁转换)。
- LoadFactor 为什么是 0.75?:这是根据泊松分布进行的权衡,旨在减少哈希冲突的频率与节省空间之间取得最佳平衡。
【问题】为什么重写 equals() 时必须重写 hashCode()?在 HashMap 中有何体现?
【参考答案】
这是 Java 编程中的一条基本准则,旨在保证逻辑相等的对象必须具有相同的哈希值。如果违反这一准则,会导致集合类(如 HashMap, HashSet)的行为出现异常。
1. 逻辑一致性原则(Object 规范)
根据 Object 类的协定:
- 如果两个对象通过
equals()比较相等,那么它们的hashCode()必须返回相同的结果。 - 如果两个对象的
hashCode()相同,它们并不一定equals()相等(这被称为哈希冲突)。
2. 在 HashMap 中的核心体现
HashMap 及其相关集合的工作机制高度依赖这两个方法的配合:
- 第一步:找桶位。当调用
put(key, value)或get(key)时,HashMap首先调用key.hashCode()计算哈希值,进而确定该 Key 应该存放在数组的哪个下标(桶)中。 - 第二步:找元素。定位到桶后,如果桶内有多个元素(链表或红黑树),
HashMap会遍历这些元素,通过equals()方法逐一对比,找到真正匹配的 Key。
3. 不重写的后果
如果只重写了 equals() 而没重写 hashCode():
- 无法找回数据:你存入了一个 Key,随后用一个逻辑相等(
equals为 true)的新对象去获取,但因为hashCode不同,HashMap会去另一个桶位寻找,导致结果为null。 - 破坏唯一性:在
HashSet中,逻辑相等的对象会因为hashCode不同而被存储在不同的位置,导致集合中出现了重复的“相等”对象,违背了Set的设计初衷。
【延伸考点】
- 哈希冲突(Hash Collision):理解
hashCode相同但equals不同时的处理方式(链表/红黑树)。 - 性能考量:优秀的
hashCode实现应尽量分散,减少冲突,从而将查询效率维持在 O(1)。 - 不可变性:作为
HashMap的 Key,对象的hashCode最好在对象创建后不再改变(通常通过final字段和缓存hash值实现)。
【问题】HashMap 和 Hashtable 的区别有哪些?
【参考答案】
HashMap 和 Hashtable 都是 Java 中用于存储键值对的数据结构,但它们在设计理念、性能和线程安全性上存在巨大差异。如今,Hashtable 已基本被废弃,仅作为历史遗留类存在。
1. 核心区别对比
| 特性 | HashMap |
Hashtable |
|---|---|---|
| 线程安全性 | 线程不安全(非同步) | 线程安全(方法级 synchronized) |
| Null 值支持 | 允许一个 null 键和多个 null 值 | 完全不允许 null 键或 null 值 |
| 初始容量 | 默认 16 | 默认 11 |
| 扩容机制 | 翻倍(2n) | 翻倍并加一(2n + 1) |
| 迭代器 | Iterator (fail-fast) |
Enumerator (非 fail-fast) |
| 底层结构 | 数组 + 链表 + 红黑树 (JDK 1.8+) | 数组 + 链表 |
2. 详细差异剖析
- 线程安全性与性能:
Hashtable通过在几乎所有方法上加synchronized锁来实现线程安全。这导致了极其严重的锁竞争,在高并发下性能低下。HashMap则专注于单线程性能。 - 哈希算法:
HashMap对 Key 的hashCode()进行了二次哈希(扰动函数),以减少冲突;Hashtable则直接使用原始哈希值。 - Null 处理机制:
Hashtable在处理 put 操作时,如果 Key 或 Value 为 null,会直接抛出NullPointerException。而HashMap对 null 键做了特殊处理(通常存放在数组的第 0 个桶位)。
3. 历史地位与选型
Hashtable:属于 JDK 1.0 的遗留类,不建议在任何新项目中使用。- 并发场景替代方案:如果需要线程安全,不应选择
Hashtable,而应选择ConcurrentHashMap(高性能分段/节点锁)或Collections.synchronizedMap()。
【延伸考点】
- Dictionary 类:
Hashtable继承自过时的Dictionary类,而HashMap继承自AbstractMap并实现了Map接口。 - 扩容公式差异的原因:
Hashtable的 2n+1 旨在尽量使容量保持为质数,以减少哈希冲突;而HashMap的 2n 配合位运算(n-1) & hash则追求极致的索引计算性能。 - ConcurrentHashMap 的崛起:理解为什么
ConcurrentHashMap能在保证线程安全的同时,提供远超Hashtable的吞吐量。
【问题】为什么 HashMap 的数组长度必须是 2 的幂次方?
【参考答案】
在 HashMap 的设计中,将数组长度(容量)限制为 2 的幂次方是一项极其精妙的优化,主要目的在于追求索引计算的高效性与哈希分布的均匀性。
1. 性能优化:将取模运算转化为位运算
- 数学原理:当数组长度
n为 2 的幂次方时,对于任意整数hash,满足:hash % n == hash & (n - 1)。 - 效率对比:在计算机中,位运算(
&)的指令周期远少于除法和取模运算(%)。通过将取模操作转化为位运算,HashMap在高频的寻址操作中节省了大量的 CPU 开销。
2. 减少冲突:确保哈希分布均匀
- 全 1 特性:如果
n是 2 的幂次方,那么n-1的二进制表示形式一定是全 1(例如n=16,二进制为10000;n-1=15,二进制为1111)。 - 离散性保证:当进行
hash & (n - 1)运算时,由于n-1的低位全是 1,哈希值的低位能够完全参与运算,从而使得计算结果能均匀地落在数组的每一个桶位。 - 反面教材:如果长度
n不是 2 的幂次方(如n=10,二进制1010;n-1=9,二进制1001),那么在进行&运算时,中间两位永远会被屏蔽(由于0 & bit == 0),这将导致部分桶位永远无法被访问到,从而大幅增加哈希冲突。
3. 扩容效率提升
- 当容量为 2 的幂次方时,扩容(翻倍)后的节点迁移逻辑变得非常简单。由于原容量
n的二进制位只有一位是 1,扩容后节点要么留在原位置,要么移动到原位置 + oldCap,无需重新计算哈希值,只需通过位运算即可快速完成迁移。
【延伸考点】
- 扰动函数(Perturbation Function):即便容量是 2 的幂次方,如果原始
hashCode的低位分布不均,依然会冲突。HashMap通过(h = k.hashCode()) ^ (h >>> 16)混合了高位信息,进一步增强了随机性。 - Hashtable 的对比:
Hashtable采用质数(默认 11)作为初始容量,配合传统的取模运算。质数虽然能天生减少哈希冲突,但索引计算性能较差。 - 容量修正逻辑:即便用户在构造函数中传入非 2 的幂次方的数字,
HashMap也会通过tableSizeFor()方法将其修正为大于该值的最小 2 的幂次方(如输入 7 变为 8,输入 10 变为 16)。
【问题】为什么 ConcurrentHashMap 在 JDK 1.8 中放弃了分段锁?
【参考答案】
JDK 1.7 的 ConcurrentHashMap 使用了 Segment 分段锁机制,而 JDK 1.8 彻底重构了其实现,改用 Node 级别的锁(synchronized + CAS)。这一转变主要基于以下核心考量:
1. 锁粒度的极度细化
- JDK 1.7:锁的粒度是
Segment(默认 16 个)。这意味着即使两个线程操作的是不同的桶(Bucket),只要它们落在了同一个 Segment 中,依然需要竞争同一把锁。 - JDK 1.8:锁的粒度细化到了每个桶的头节点(Node)。只有当多个线程同时竞争同一个桶时才会发生阻塞。只要哈希不冲突,并发写入性能得到了指数级的提升。
2. 内存开销的显著降低
- JDK 1.7:每个
Segment都是一个独立的对象,继承自ReentrantLock,会消耗额外的内存空间。 - JDK 1.8:不再使用
Segment,而是直接在Node数组的头节点上使用synchronized。这种方式大幅减少了内存占用,且在初始化时更加轻量。
3. JVM 对 synchronized 的深度优化
- 随着 JVM 的演进,
synchronized已经不再是那个笨重的“重量级锁”。通过锁升级机制(偏向锁 -> 轻量级锁 -> 重量级锁),在低竞争场景下其性能已能与ReentrantLock持平。 - 此外,使用内置锁能让 JVM 进行更多的自动优化(如锁消除、锁粗化)。
4. 数据结构带来的性能红利
- JDK 1.8 引入了红黑树。当哈希冲突严重时,查询效率从 O(n) 降至 O(logn)。在红黑树状态下,
synchronized依然锁定根节点,保证了高并发下的稳定性。
【延伸考点】
- CAS(Compare And Swap)的应用:在
put操作中,如果桶为空,ConcurrentHashMap会优先尝试使用 CAS 无锁操作来插入节点,只有在发生冲突时才升级为synchronized。 - size() 的并发统计:JDK 1.8 放弃了 1.7 中通过两次不加锁、一次加锁的复杂统计方式,转而借鉴了
LongAdder的思想,利用CounterCell数组来分摊并发压力,实现了高性能的元素计数。 - 扩容时的并发迁移:了解
ForwardingNode在多线程并发扩容中的作用,它是如何支持多个线程同时参与数据迁移的。
数组array与列表list
【问题】Array 和 ArrayList 的区别及适用场景?
【参考答案】
Array(数组)和 ArrayList(动态数组)是 Java 中最基础的数据结构,它们在存储方式、灵活性和性能上各有侧重。
1. 核心区别对比
| 特性 | Array (数组) |
ArrayList (动态数组) |
|---|---|---|
| 大小固定性 | 创建时固定长度,不可更改 | 动态扩容,可根据需要自动增长 |
| 数据类型支持 | 支持基本类型(int, double 等)和引用类型 | 仅支持引用类型(基本类型需自动装箱) |
| 功能丰富度 | 仅支持 length 属性和索引访问 |
提供丰富的 API(如 add, remove, contains 等) |
| 性能效率 | 内存连续,执行效率更高,无装箱开销 | 略低,涉及扩容时的数组拷贝及装箱操作 |
| 多维支持 | 原生支持多维数组(如 int[][]) |
不直接支持(需通过嵌套 ArrayList<ArrayList<T>>) |
2. 核心原理剖析
- ArrayList 的扩容机制:
ArrayList底层依然是Array。当元素个数达到容量上限时,它会创建一个新的数组,容量通常为原数组的 1.5 倍(newCapacity = oldCapacity + (oldCapacity >> 1)),然后通过System.arraycopy()将旧数据迁移过去。 - 泛型限制:由于 Java 泛型的类型擦除机制,
ArrayList无法直接存储基本类型,必须使用其对应的包装类,这在处理海量数据时会带来额外的内存开销和 GC 压力。
3. 适用场景建议
- 优先选择
Array的场景:- 元素个数已知且固定(如一周有 7 天)。
- 追求极致性能,且数据量极大(避免频繁装箱/拆箱)。
- 需要使用多维矩阵计算时。
- 优先选择
ArrayList的场景:- 元素个数不确定,需要频繁进行增删操作。
- 需要利用 Java 集合框架提供的丰富工具(如排序、流处理等)。
【延伸考点】
Arrays.asList()的坑:该方法返回的是java.util.Arrays$ArrayList,它是Arrays的内部类,不支持add或remove操作,会抛出UnsupportedOperationException。- 线程安全:
ArrayList是线程不安全的。在并发场景下,应考虑使用CopyOnWriteArrayList或Collections.synchronizedList()。 - Fast-fail 机制:
ArrayList的迭代器在遍历过程中,如果检测到集合结构被修改(通过modCount判断),会立即抛出异常。
【问题】Vector、ArrayList 和 LinkedList 的异同?
【参考答案】
这三者都是 List 接口的实现类,用于存储有序、可重复的元素,但在底层数据结构、线程安全性和性能表现上存在显著差异。
1. 核心对比表
| 特性 | Vector |
ArrayList |
LinkedList |
|---|---|---|---|
| 底层数据结构 | 动态数组 (Object 数组) | 动态数组 (Object 数组) | 双向链表 |
| 线程安全性 | 线程安全 (方法级同步) | 线程不安全 | 线程不安全 |
| 查询效率 | 快 (支持随机访问 O(1)) | 快 (支持随机访问 O(1)) | 慢 (需遍历 O(n)) |
| 增删效率 | 慢 (涉及元素移动 O(n)) | 慢 (涉及元素移动 O(n)) | 快 (首尾极快 O(1)) |
| 扩容机制 | 默认翻倍 (2.0 倍) | 默认 1.5 倍 | 无需扩容 (随节点动态增减) |
| 内存占用 | 较低 | 较低 | 较高 (需存储前后指针) |
2. 核心差异剖析
- Vector vs ArrayList:
Vector是 JDK 1.0 的遗留类,其所有方法都加了synchronized锁。虽然线程安全,但在单线程环境下性能远低于ArrayList。Vector的扩容步长(capacityIncrement)可以自定义,默认是原容量的 2 倍;而ArrayList固定为 1.5 倍。
- ArrayList vs LinkedList:
- 随机访问:
ArrayList实现了RandomAccess接口,支持 O(1) 的下标寻址。LinkedList则需要从头或尾开始遍历,性能较差。 - 中间插入/删除:
ArrayList需要移动后续所有元素;LinkedList虽然插入操作本身是 O(1),但如果是在中间操作,定位目标位置仍需 O(n) 的开销。 - 空间开销:
ArrayList的开销主要在于数组末尾预留的空闲空间;LinkedList则是因为每个节点都需要额外存储prev和next指针。
- 随机访问:
3. 选型建议
- 高频随机读取:首选
ArrayList。 - 频繁在首尾进行增删:考虑使用
LinkedList或ArrayDeque。 - 多线程并发环境:不推荐
Vector。应优先考虑CopyOnWriteArrayList或Collections.synchronizedList()。
【延伸考点】
- RandomAccess 接口:这是一个标识接口(Marker Interface)。实现了该接口的类在进行遍历时,推荐使用普通的
for循环(带索引)而非迭代器,因为前者性能更好。 - 双向链表结构:
LinkedList同时实现了Deque接口,因此它也可以被当作双端队列或栈来使用。 - 内存连续性:
ArrayList的内存是连续分配的,对 CPU 缓存更友好(利用预读机制);而LinkedList的节点散落在堆内存中。
【问题】Comparable 和 Comparator 接口有什么区别?
【参考答案】
在 Java 中,Comparable 和 Comparator 都是用于实现对象排序的接口,但它们的设计意图和使用场景有显著区别。
1. 核心区别对比
| 特性 | Comparable (内部比较器) |
Comparator (外部比较器) |
|---|---|---|
| 定义位置 | 定义在类的内部(实现该接口) | 定义在类的外部(独立的比较类) |
| 比较方法 | public int compareTo(T o) |
public int compare(T o1, T o2) |
| 侵入性 | 有侵入性(需修改类的源代码) | 无侵入性(无需修改类的源代码) |
| 灵活性 | 单一排序规则(类只能有一种实现) | 多种排序规则(可定义多个比较器) |
| 适用场景 | 对象本身具有“天生”的排序属性(如 String, Integer) | 无法修改源码的类,或需要根据不同维度排序 |
2. 详细特性剖析
- Comparable(自然排序):
- 实现
Comparable接口的类意味着该类的实例支持“自我比较”。 - 例如,
String实现了Comparable<String>,因此Collections.sort(list)可以直接对字符串列表进行字典序排序。
- 实现
- Comparator(定制排序):
- 当一个类没有实现
Comparable,或者其默认的排序规则不符合当前需求(如:想按长度而非字典序排字符串)时,应使用Comparator。 - 它体现了策略模式,允许在运行时动态指定排序策略。
- 当一个类没有实现
3. 返回值的含义 两者方法的返回值逻辑一致:
- 返回负数:表示当前对象(或 o1)小于目标对象(或 o2)。
- 返回零:表示两者相等。
- 返回正数:表示当前对象(或 o1)大于目标对象(或 o2)。
【延伸考点】
- Java 8 的增强:
Comparator接口在 Java 8 中引入了大量静态和默认方法(如comparing(),thenComparing(),reversed()),极大地简化了链式比较器的编写。 - 排序算法底层:
Arrays.sort()和Collections.sort()在 JDK 7 之后默认使用 TimSort 算法(一种结合了合并排序和插入排序的混合算法),它在处理部分有序的数据时表现极佳。 - 与 equals 的一致性:虽然不是强制要求,但通常建议
compareTo的结果应与equals保持一致(即(x.compareTo(y)==0) == (x.equals(y))),以避免在TreeSet或TreeMap中出现意外行为。
set
【问题】HashSet 和 TreeSet 的区别是什么?
【参考答案】
HashSet 和 TreeSet 都是 Set 接口的实现类,用于存储不重复的元素,但它们在底层实现、排序行为和性能特征上完全不同。
1. 核心区别对比
| 特性 | HashSet |
TreeSet |
|---|---|---|
| 底层实现 | 基于 HashMap 实现 |
基于 TreeMap (红黑树) 实现 |
| 排序行为 | 无序 (不保证存取顺序) | 有序 (自然排序或定制排序) |
| 时间复杂度 | O(1) (理想情况下) | O(log n) |
| Null 值支持 | 允许一个 null 元素 | 不允许 null (由于需要比较操作) |
| 主要用途 | 快速查找、去重 | 需要元素处于排序状态时 |
2. 详细特性剖析
- HashSet(追求速度):
- 内部实际上是一个
HashMap,元素存储在 Map 的 Key 中,Value 则统一使用一个固定的 Object 对象(PRESENT)。 - 通过
hashCode()和equals()保证唯一性。
- 内部实际上是一个
- TreeSet(追求有序):
- 内部是一个
TreeMap,元素以红黑树的形式存储。 - 元素必须实现
Comparable接口,或者在创建TreeSet时提供Comparator。 - 通过
compareTo()或compare()的返回结果是否为 0 来保证唯一性,而不是equals()。
- 内部是一个
3. 选型建议
- 如果没有排序需求,应优先选择
HashSet,因为其查找和插入效率更高。 - 如果需要集合始终处于有序状态(如展示排行榜),则选择
TreeSet。
【延伸考点】
- LinkedHashSet:它是
HashSet的子类,底层使用LinkedHashMap。它通过维护一个双向链表,记录了元素的插入顺序。如果你既需要去重,又希望保持存入时的顺序,它是最佳选择。 - 性能考量:
TreeSet的操作涉及树的旋转和平衡,因此开销远大于HashSet。 - 线程安全:两者都是线程不安全的。并发环境下应使用
Collections.synchronizedSet()或CopyOnWriteArraySet。
【问题】Set 是如何保证元素不重复的?
【参考答案】
Set 接口保证元素唯一性的方式取决于其具体的实现类。最常用的 HashSet 和 TreeSet 分别采用了哈希对比和排序对比两种完全不同的机制。
1. HashSet:哈希表机制(hashCode + equals)
HashSet 内部利用 HashMap 的 Key 来存储元素。当调用 add(obj) 时,其校验流程如下:
- 哈希计算:首先调用
obj.hashCode()计算对象的哈希值,从而确定元素在数组中的位置(桶位)。 - 快速检查:如果该位置为空,直接存入。
- 冲突对比:如果该位置已有元素(即发生了哈希冲突),则调用
obj.equals(existingObj)。- 如果
equals返回true,则认为元素重复,拒绝存入。 - 如果
equals返回false,则以链表或红黑树的形式存储在该桶位。
- 如果
2. TreeSet:排序对比机制(compareTo / compare)
TreeSet 内部利用 TreeMap 实现,它并不依赖哈希值,而是通过比较器来判断唯一性:
- 有序对比:在插入元素时,会调用元素实现的
Comparable.compareTo()方法或提供的Comparator.compare()方法与树中已有的节点进行比较。 - 唯一性判定:如果比较结果返回 0,则认为两个元素相等(重复),不予存入。
- 注意:这意味着在
TreeSet中,即使两个对象equals()返回false,只要compareTo()返回 0,它们也会被视为重复元素。
- 注意:这意味着在
3. 核心总结
| 实现类 | 判定依据 | 核心方法 |
|---|---|---|
HashSet |
哈希冲突 + 逻辑相等 | hashCode() & equals() |
TreeSet |
排序结果为 0 | compareTo() / compare() |
【延伸考点】
- 重写原则:对于放入
HashSet的自定义对象,必须同时重写hashCode()和equals(),并确保逻辑一致性(即 equals 相等的对象 hashCode 必须相等)。 - 与 equals 的一致性:在使用
TreeSet时,强烈建议compareTo的结果与equals保持一致,否则会出现集合行为与Map/List不一致的诡异 Bug。 - 不可变性:如果一个对象已经存入
Set,修改其参与哈希或比较运算的属性,可能会导致该对象“丢失”在集合中(无法被查询或删除),造成内存泄漏。
异常处理
【问题】Java 中的受检异常(Checked)与非受检异常(Unchecked)的区别?
【参考答案】
Java 将异常分为两大类,主要区别在于编译器是否强制要求处理,这反映了 Java 对不同严重程度问题的设计哲学。
1. 受检异常(Checked Exception)
- 定义:编译器在编译期间会检查的代码。除了
RuntimeException及其子类以外的所有Exception及其子类都属于受检异常。 - 处理机制:程序必须显式处理。要么使用
try-catch捕获并处理,要么在方法签名上使用throws关键字声明抛出,否则编译无法通过。 - 设计初衷:用于描述那些在合理情况下可以预见并恢复的意外情况。例如网络连接失败、文件不存在等,程序员必须编写应对预案。
- 典型示例:
IOException、SQLException、ClassNotFoundException。
2. 非受检异常(Unchecked Exception)
- 定义:编译器在编译期间不进行检查的异常。包括所有的
RuntimeException及其子类,以及所有的Error。 - 处理机制:不强制要求处理。虽然也可以捕获,但通常建议通过代码逻辑改进来预防。
- 设计初衷:通常用于描述编程逻辑错误或不可恢复的严重问题。例如空指针、数组越界等,这些问题应该通过代码规范和逻辑判断来避免,而不是依赖异常捕获。
- 典型示例:
NullPointerException、ArrayIndexOutOfBoundsException、ClassCastException、IllegalArgumentException。
核心对比表
| 特性 | 受检异常 (Checked) | 非受检异常 (Unchecked) |
|---|---|---|
| 编译器检查 | 强制检查 | 不检查 |
| 处理要求 | 必须 try-catch 或 throws |
可选处理 |
| 本质区别 | 外部环境导致的、可恢复的意外 | 编程逻辑错误、不可恢复的故障 |
| 继承体系 | Exception 及其子类(非运行时) |
RuntimeException 及其子类、Error |
【延伸考点】
- 异常处理的原则:优先使用
try-with-resources关闭资源;不要捕获Throwable或Error;捕获异常后不要“吞掉”(即空的 catch 块),应记录日志或向上抛出。 - 自定义异常:如果是由于外部业务规则导致的、需要调用方处理的情况,建议继承
Exception;如果是由于内部状态错误、属于编程逻辑问题,建议继承RuntimeException。 - JVM 对 RuntimeException 的处理:如果运行时异常未被捕获,最终会由 JVM 默认的异常处理器处理(通常是打印堆栈信息并终止当前线程)。
【问题】Exception 与 Error 的区别是什么?
【参考答案】
Exception 和 Error 都继承自 java.lang.Throwable 类,是 Java 异常处理体系的两大支柱。它们的核心区别在于程序对问题的可控性和严重程度。
1. Exception(异常)
- 定义:指程序本身可以处理的意外情况。通常是由外部环境或编程逻辑导致的非致命性问题。
- 处理机制:开发者可以通过
try-catch块捕获这些异常,并采取补救措施(如重试、报错提示、回滚事务等),使程序能够继续运行。 - 分类:
- 受检异常 (Checked):编译器强制要求处理(如
IOException)。 - 非受检异常 (Unchecked):通常是编程错误(如
NullPointerException)。
- 受检异常 (Checked):编译器强制要求处理(如
2. Error(错误)
- 定义:指程序无法处理的严重问题。通常与 JVM 运行环境、底层资源或硬件故障有关。
- 处理机制:一旦发生,程序通常无法通过代码逻辑进行自我恢复,最终会导致 JVM 崩溃或线程终止。因此,不建议也不应该尝试捕获
Error。 - 典型示例:
OutOfMemoryError(OOM):堆内存不足。StackOverflowError:栈溢出(通常由无限递归引起)。NoClassDefFoundError:类定义找不到。
核心对比表
| 特性 | Exception (异常) |
Error (错误) |
|---|---|---|
| 可恢复性 | 可恢复 (通过处理可继续运行) | 不可恢复 (通常导致程序崩溃) |
| 处理建议 | 必须/应该 处理 | 不建议 捕获处理 |
| 发生原因 | 业务逻辑错误、环境因素 | JVM 故障、系统资源耗尽 |
| 典型代表 | IOException, NPE, SQLException |
OOM, StackOverflowError |
【延伸考点】
- try-with-resources:Java 7 引入的语法糖,能够确保实现了
AutoCloseable接口的资源(如流、连接)在try块结束后自动关闭,避免因异常导致的资源泄漏。 - NoClassDefFoundError vs ClassNotFoundException:
ClassNotFoundException是一个 Exception,发生在显式加载类(如Class.forName())且找不到类时。NoClassDefFoundError是一个 Error,发生在编译期能找到类,但运行时类路径下该类消失了(如 Jar 包冲突或缺失)。
- OOM 的排查:发生
OutOfMemoryError时,通常需要结合堆转储文件(Heap Dump)进行离线分析。
【问题】finally 与 finalize() 的区别?如何替代 finalize()?
【参考答案】
尽管名称相似,但 finally 和 finalize() 在 Java 中承担着完全不同的职责。一个是异常处理的保障,另一个则是已废弃的资源清理机制。
1. finally 关键字
- 用途:作为
try-catch-finally结构的一部分,用于确保无论是否发生异常,某些关键代码(如释放资源、关闭连接、解锁等)都一定会执行。 - 执行时机:在
try或catch块执行完毕后,方法返回前执行。 - 特殊情况:除非在
try/catch块中调用了System.exit(0)终止了 JVM,否则finally块始终会执行。
2. finalize() 方法
- 用途:它是
Object类的一个受保护方法。在垃圾回收器(GC)确定对象没有被引用、准备回收其内存之前,由 GC 线程调用。 - 现状:由于其执行时机极度不确定、容易导致内存泄漏及死锁,Java 9 已将其标记为废弃(Deprecated),不建议使用。
- 局限性:每个对象的
finalize()最多只会被调用一次。如果执行过程中发生异常,该异常会被忽略,且对象可能因此“复活”但状态异常。
3. 如何替代 finalize()?
现代 Java 推荐以下两种更安全、更可控的资源管理方式:
- 实现
AutoCloseable接口:配合 try-with-resources 语法。这是目前管理文件流、数据库连接等外部资源的标准做法。 - 使用
java.lang.ref.Cleaner(Java 9+):它比finalize()更轻量且安全。Cleaner在对象不可达时触发清理动作,且清理逻辑在独立的线程中执行,不会阻塞 GC。
核心对比表
| 特性 | finally |
finalize() |
|---|---|---|
| 本质 | Java 关键字(流控语句) | Object 类的方法 |
| 触发者 | 程序执行流(编译器保证) | 垃圾回收器 (GC) |
| 确定性 | 高度确定 (一定会执行) | 极不确定 (不保证何时执行) |
| 主要用途 | 资源释放、状态清理 | 废弃的扫尾工作(不建议使用) |
【延伸考点】
- try 块中的 return:如果
try块中有return,finally仍会执行。如果finally块中也有return,它会覆盖try块中的返回值。 - 对象“复活”:在
finalize()中将this赋值给某个静态变量可以使对象在本次 GC 中幸存,但这被视为一种极差的编程实践。 - 资源泄漏风险:依赖
finalize()释放资源是极其危险的,因为 GC 的触发频率不确定,可能导致文件描述符或连接池耗尽。
RMI
【问题】什么是 Java RMI(远程方法调用)?
【参考答案】
Java RMI(Remote Method Invocation,远程方法调用)是 Java 提供的一种 RPC(Remote Procedure Call)机制。它允许一个 Java 虚拟机(JVM)中的对象像调用本地方法一样,调用另一个 JVM 中对象的方法,从而实现了分布式计算。
1. 核心架构与角色
- 客户端 (Client):调用远程方法的程序。
- 服务端 (Server):提供远程对象并实现具体业务逻辑的程序。
- 注册表 (RMI Registry):一个特殊的命名服务,用于服务端注册远程对象,以及客户端根据名称查找(Lookup)远程对象。
2. 核心工作原理 RMI 的实现依赖于代理模式,主要包含两个关键组件:
- Stub(存根):位于客户端。它是远程对象的本地代理,负责将方法调用及其参数序列化并通过网络发送给服务端。
- Skeleton(骨架):位于服务端(JDK 1.2 以后被整合进服务端实现中)。负责接收请求、反序列化参数、调用实际的本地方法,并将结果序列化后传回给客户端。
3. 实现 RMI 的必要步骤
- 定义一个继承自
java.rmi.Remote的接口,并声明远程方法。 - 服务端实现该接口,并继承
UnicastRemoteObject。 - 服务端通过
Naming.rebind()或Registry.rebind()将对象绑定到注册表。 - 客户端通过
Naming.lookup()获取远程对象的 Stub,并像本地对象一样调用。
4. 优点与局限性
- 优点:强类型检查、原生支持 Java 对象传输(序列化)、易于集成。
- 局限性:语言绑定性强(仅限于 Java 之间通信)、防火墙穿透性差(使用随机端口)、在大规模高并发场景下性能表现平平。
【延伸考点】
- 序列化的重要性:由于参数和返回值需要在网络中传输,所有涉及的对象必须实现
java.io.Serializable接口。 - RMI 与 Spring 的集成:Spring 提供了
RmiServiceExporter和RmiProxyFactoryBean来简化 RMI 的配置和使用。 - 现代替代方案:在微服务时代,RMI 已逐渐被更通用的 RESTful API (HTTP/JSON)、gRPC 或 Dubbo 等跨语言、高性能的通信框架所取代。
- 动态代理的应用:理解 RMI 是如何利用动态代理(JDK Dynamic Proxy)在运行时生成 Stub 的。
数据结构
【问题】请对比二叉树、BST、AVL 树及红黑树的特点与应用。
【参考答案】
这四种树形结构是计算机科学中处理有序数据的基石,它们在平衡性、查找效率和维护成本之间做了不同的权衡。
1. 二叉树 (Binary Tree)
- 特点:每个节点最多有两个子节点。没有任何顺序约束。
- 缺点:查找效率极低(无序),且极易退化为链表(
O(n))。 - 应用:作为更复杂树结构的基础。
2. 二叉搜索树 (BST, Binary Search Tree)
- 特点:左子树所有节点值 < 根节点值 < 右子树所有节点值。支持中序遍历得到有序序列。
- 性能:理想情况下查找效率为
O(log n)。 - 致命缺陷:当插入的数据是有序的(如 1, 2, 3, 4),树会退化为单向链表,查找复杂度变为
O(n)。
3. 平衡二叉搜索树 (AVL Tree)
- 特点:严格平衡。任何节点的两个子树的高度差(平衡因子)最多为 1。
- 性能:查找效率极其稳定,始终为
O(log n)。 - 缺点:为了维持严格平衡,在插入或删除节点后,可能需要进行多次旋转(旋转开销大)。
- 应用:适用于查询频繁、修改极少的场景。
4. 红黑树 (Red-Black Tree)
- 特点:近似平衡。它通过五个颜色约束(红/黑)来保证从根到叶子的最长路径不超过最短路径的两倍。
- 性能:查找效率略逊于 AVL 树,但插入和删除的综合性能更高(最多只需 3 次旋转即可恢复平衡)。
- 应用:Java 中的
TreeMap、HashMap(JDK 1.8+ 桶位进化)、Linux 内核的进程调度(CFS)、虚拟内存管理。
核心对比表
| 树类型 | 平衡程度 | 查找效率 | 维护成本 (旋转) | 典型应用 |
|---|---|---|---|---|
| BST | 不保证平衡 | O(log n) ~ O(n) |
无 | 基础排序 |
| AVL | 严格平衡 | 极快 (O(log n)) |
高 (频繁旋转) | 读多写少场景 |
| 红黑树 | 近似平衡 | 较快 (O(log n)) |
低 (性能稳定) | 通用型、写多读多 |
【延伸考点】
- B 树 / B+ 树:与二叉树不同,它们是多路平衡搜索树。主要用于数据库索引(如 MySQL 的 InnoDB),旨在通过降低树的高度来减少磁盘 I/O 次数。
- 二叉树的遍历:掌握前序、中序、后序遍历的递归与非递归实现,以及层序遍历(BFS)。
- 左旋与右旋:理解平衡树维持平衡的基本操作原理。
IO流
【问题】字节流与字符流的区别及适用场景?
【参考答案】
Java 中的 IO 流分为字节流和字符流,这种划分主要是为了高效处理不同类型的数据(尤其是文本数据)。
1. 核心区别对比
| 特性 | 字节流 (Byte Stream) | 字符流 (Character Stream) |
|---|---|---|
| 基本单位 | 字节 (byte, 8-bit) | 字符 (char, 16-bit) |
| 顶层基类 | InputStream / OutputStream |
Reader / Writer |
| 缓冲区 | 默认不使用缓冲区(直接操作) | 默认使用缓冲区(提升效率) |
| 编解码 | 不涉及编解码,直接传输二进制 | 涉及编解码(将字节转为指定字符集) |
| 处理对象 | 所有二进制文件(图片、视频、exe等) | 纯文本文件(txt、java、html等) |
2. 关键差异深度解析
- 编解码过程:字节流是计算机最底层的传输方式,它不关心数据的具体含义。而字符流是在字节流的基础上,结合了特定的字符集(Charset),将字节序列转换为人类可读的字符。
- 缓冲区与
flush():字符流在写出数据时,通常会先存入内部缓冲区,只有当缓冲区满、显式调用flush()或关闭流时,才会真正写入目的地。如果忘记flush(),可能会导致数据丢失。而字节流(非 Buffered 类型)通常直接写入文件。
3. 适用场景建议
- 优先使用字节流:
- 处理非文本文件(如:复制图片、上传视频、序列化对象)。
- 需要极高性能且不涉及文本解析的场景。
- 优先使用字符流:
- 处理纯文本数据,尤其是涉及多语言/乱码处理时。
- 字符流能自动处理字符集转换,避免手动处理字节偏移导致的乱码(如一个中文占 3 字节,按单字节读取会乱码)。
【延伸考点】
- 转换流:
InputStreamReader和OutputStreamWriter是连接两者的桥梁,它们可以将字节流按指定的字符编码包装成字符流。 - 装饰器模式:Java IO 体系大量使用了装饰器模式(如
BufferedReader包装FileReader),通过嵌套流来增强功能(如增加缓冲、按行读取等)。 - 乱码根因:通常是因为读取时使用的字符集与写入时不一致导致的。推荐在 IO 操作中显式指定编码格式(如
StandardCharsets.UTF_8)。
【问题】BIO, NIO, AIO 有什么区别?
【参考答案】
这三者代表了 Java 对 IO 处理模型的演进,主要区别在于阻塞模式与同步机制的不同。
1. BIO (Blocking I/O):同步阻塞
- 模型:一个连接对应一个线程。当没有数据可读时,线程会阻塞在
read操作上,直到有数据到达。 - 缺点:在高并发场景下,需要创建大量线程,导致系统开销巨大且易崩溃。
- 场景:适用于连接数较少且架构固定的场景。
2. NIO (Non-blocking I/O):同步非阻塞
- 模型:基于 Selector(多路复用器)、Channel(通道) 和 Buffer(缓冲区)。一个线程可以管理多个通道,通过轮询(Poll)机制查看哪些通道有就绪事件。
- 特点:虽然 IO 操作本身是非阻塞的,但线程仍需同步等待 Selector 返回就绪结果,因此属于“同步非阻塞”。
- 场景:适用于高并发、短连接、且连接数较多的场景(如聊天服务器、Netty)。
3. AIO (Asynchronous I/O):异步非阻塞
- 模型:基于事件和回调机制。程序发起 IO 请求后立即返回,由操作系统完成实际的 IO 操作。当操作完成后,操作系统会通知程序或触发回调。
- 特点:真正的异步处理。程序不需要主动轮询,效率最高。
- 场景:适用于高并发、长连接、且连接数极多的场景。但在 Linux 下 AIO 底层实现仍不尽完善,实际应用不如 NIO 广泛。
核心对比总结
| 特性 | BIO | NIO | AIO |
|---|---|---|---|
| IO 模型 | 同步阻塞 | 同步非阻塞 | 异步非阻塞 |
| 线程模型 | 一个连接一个线程 | 一个线程多个连接 (Reactor) | 一个有效请求一个线程 (Proactor) |
| 编程难度 | 简单 | 复杂 | 复杂 |
| 可靠性 | 低 | 高 | 高 |
| 吞吐量 | 低 | 高 | 极高 |
【延伸考点】
- Selector, Channel, Buffer:理解 NIO 的三大核心组件及其协作方式。
- Reactor 与 Proactor 模式:NIO 是 Reactor 模式的实现,而 AIO 则是 Proactor 模式。
- Netty 的地位:由于原生 NIO API 极其复杂且存在 Epoll Bug,实际开发中几乎都使用 Netty 框架来处理高性能网络通信。
- 零拷贝 (Zero-Copy):NIO 引入了
mmap和sendfile等技术,减少了内核态与用户态之间的数据拷贝,极大提升了 IO 效率。
反射与动态代理
【问题】什么是反射机制?什么是动态代理?
【参考答案】
反射和动态代理是 Java 语言中极具灵活性和强大扩展性的特性,它们是许多框架(如 Spring、MyBatis)实现的基石。
1. 反射机制 (Reflection)
- 定义:指程序在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性。这种动态获取信息以及动态调用对象方法的功能称为反射。
- 核心功能:
- 在运行时判断任意一个对象所属的类。
- 在运行时构造任意一个类的对象。
- 在运行时获取和调用任意一个类的成员变量和方法(包括私有成员)。
- 优缺点:
- 优点:增加了程序的灵活性和自适应能力,是通用框架设计的核心。
- 缺点:性能开销较大(需解析元数据);破坏了类的封装性(可以访问私有成员)。
2. 动态代理 (Dynamic Proxy)
- 定义:在程序运行期间,根据需要动态地创建代理对象。代理对象作为原对象的媒介,可以在不修改源码的情况下,对原有的方法进行增强(如日志记录、事务控制、权限检查)。
- 主要实现方式:
- JDK 动态代理:利用反射机制生成一个实现代理接口的匿名类。前提条件:被代理类必须实现至少一个接口。
- CGLIB 动态代理:利用字节码生成技术(ASM),通过继承被代理类并覆盖其方法来实现。前提条件:被代理类不能被
final修饰。
核心对比总结
| 特性 | JDK 动态代理 | CGLIB 动态代理 |
|---|---|---|
| 实现原理 | 基于 接口 实现(反射) | 基于 继承 实现(字节码) |
| 被代理类限制 | 必须实现接口 | 不能是 final 类 |
| 性能 | 较快(现代 JDK 已大幅优化) | 较快(生成子类) |
| 适用场景 | 接口导向的编程 | 没有实现接口的普通类 |
【延伸考点】
- Spring AOP 的选型:Spring 默认优先使用 JDK 代理;如果被代理类没有实现接口,则自动切换为 CGLIB。
- setAccessible(true):反射中的“暴力访问”,通过设置该标志可以绕过 Java 的访问检查,访问
private成员。 - 反射与泛型擦除:反射是在运行时进行的,可以绕过编译期的泛型检查(例如通过反射向
List<String>中添加Integer对象)。 - AOP(面向切面编程):理解动态代理是如何支撑起 AOP 的核心理念——将业务逻辑与系统服务(日志、安全等)解耦。
网络
【问题】详述 TCP 三次握手与四次挥手的过程及原因。
【参考答案】
TCP 协议通过三次握手建立连接,四次挥手释放连接,其核心目标是确保在不可靠的网络环境下实现可靠的、全双工的通信。
1. 三次握手(Connection Establishment)
- 过程:
- 第一次握手:客户端发送
SYN包(序列号seq=x)到服务器,进入SYN_SENT状态。 - 第二次握手:服务器收到
SYN包,返回SYN+ACK包(ack=x+1, seq=y),进入SYN_RCVD状态。 - 第三次握手:客户端收到
SYN+ACK包,返回ACK包(ack=y+1, seq=x+1),双方进入ESTABLISHED状态。
- 第一次握手:客户端发送
- 原因:
- 确认双方收发能力:三次握手才能确保客户端和服务器都具备发送和接收的能力。
- 防止失效的连接请求突然传到服务器:避免因网络延迟导致的重复连接请求误导服务器建立无效连接。
- 同步初始序列号 (ISN):确保数据包的顺序性和重传机制。
2. 四次挥手(Connection Termination)
- 过程:
- 第一次挥手:客户端发送
FIN包,进入FIN_WAIT_1状态。 - 第二次挥手:服务器收到
FIN,返回ACK,进入CLOSE_WAIT状态。此时客户端进入FIN_WAIT_2(半关闭状态,仍可接收数据)。 - 第三次挥手:服务器发送完剩余数据后,发送
FIN包,进入LAST_ACK状态。 - 第四次挥手:客户端收到
FIN,返回ACK,进入TIME_WAIT状态。经过 2MSL 后,客户端关闭连接,服务器收到ACK后立即关闭。
- 第一次挥手:客户端发送
- 原因:
- 全双工特性:TCP 是全双工的,每一端都需要独立关闭。当一端发送
FIN时,仅代表它不再发送数据,但仍能接收数据。 - 确保数据完整传输:通过中间的
CLOSE_WAIT状态,确保服务端在关闭前能处理完缓冲区中的剩余数据。
- 全双工特性:TCP 是全双工的,每一端都需要独立关闭。当一端发送
【延伸考点】
- TIME_WAIT 的意义:
- 确保最后的 ACK 到达:防止服务器因没收到 ACK 而重传 FIN。
- 防止“旧连接”干扰:让旧连接产生的所有报文都在网络中消失,避免干扰后续建立的新连接。
- SYN 泛洪攻击:攻击者发送大量 SYN 包而不进行第三次握手,导致服务器资源耗尽。防御手段包括
SYN Cookie。 - 2MSL (Maximum Segment Lifetime):报文在网络中生存的最长时间。2MSL 确保了报文在往返路径上都能彻底消失。
【问题】HTTP 与 HTTPS 的区别及加密原理?
【参考答案】
HTTP(超文本传输协议)和 HTTPS(超文本传输安全协议)是互联网通信的基础,其本质区别在于安全性和数据传输的加密机制。
1. 核心区别对比
| 特性 | HTTP | HTTPS |
|---|---|---|
| 安全性 | 明文传输,数据易被窃听、篡改 | 加密传输,身份验证,保证数据完整性 |
| 默认端口 | 80 | 443 |
| 证书要求 | 无需证书 | 需要向 CA(证书颁发机构)申请 SSL/TLS 证书 |
| 性能开销 | 较低(仅需三次握手) | 较高(需进行 SSL/TLS 握手,增加计算开销) |
| SEO 排名 | 普通 | 更友好(搜索引擎会优先收录 HTTPS 站点) |
2. HTTPS 的加密原理(混合加密) HTTPS 并不是一种全新的协议,而是 HTTP + SSL/TLS。它结合了对称加密的高效和非对称加密的安全:
- 非对称加密(建立连接阶段):
- 服务端将公钥发送给客户端。客户端使用公钥加密一个随机生成的“对称密钥”(Pre-Master Secret),并传回给服务端。
- 服务端使用私钥解密,从而双方安全地交换了对称密钥。
- 对称加密(通信阶段):
- 一旦连接建立,双方都持有相同的对称密钥。后续的所有业务数据都使用该对称密钥进行加解密。
- 数字证书(身份验证):
- 为了防止“中间人攻击”,服务端发送公钥时会附带数字证书。客户端通过内置的 CA 根证书验证该证书的合法性,确保公钥确实属于该服务端。
3. HTTPS 握手流程(简述)
- 客户端发起请求,发送支持的加密算法列表。
- 服务端返回证书(含公钥)及选择的加密算法。
- 客户端验证证书合法性,生成随机密钥,用服务端公钥加密后发送。
- 服务端用私钥解密获取随机密钥。
- 后续通信使用该随机密钥进行对称加密。
【延伸考点】
- TLS 1.3 的优化:了解 TLS 1.3 相比 1.2 如何通过减少往返次数(1-RTT)来提升握手速度。
- HSTS (HTTP Strict Transport Security):强制浏览器使用 HTTPS 访问站点的安全策略。
- 中间人攻击 (MITM):如果客户端不校验服务器证书的合法性,攻击者可以伪造证书拦截并修改传输数据。
- 数据完整性:HTTPS 通过 MAC(消息认证码)机制确保数据在传输过程中没有被第三方篡改。
【延伸考点】
- TLS 1.3 的优化:了解 TLS 1.3 相比 1.2 如何通过减少往返次数(1-RTT)来提升握手速度。
- HSTS (HTTP Strict Transport Security):强制浏览器使用 HTTPS 访问站点的安全策略。
- 中间人攻击 (MITM):如果客户端不校验服务器证书的合法性,攻击者可以伪造证书拦截并修改传输数据。
- DNS 解析过程:本地缓存 -> ISP DNS -> 根域名服务器 -> 顶级域名服务器 -> 权威域名服务器。
- OSI 七层模型与 TCP/IP 四层模型:理解 HTTP/HTTPS 处于应用层,而 TCP 处于传输层。